1. Introduction
Nonparametric lack-of-fit tests where the constant regression is assumed for the null hypothesis have been considered by many authors. The order selection test [
1], the rank-based order selection test [
2], and the Bayes sum test [
3] are among the top few that are intuitive and easy to compute. A classical textbook review of extensive efforts in nonparametric lack-of-fit tests based on smoothing methods is available in Reference [
4]. Hart [
2] extended the order selection method of Reference [
1] to rank-based test under the constant variance assumption so that the test statistic is relatively insensitive to misspecification of distributional assumptions. These two order selection tests show excellent performance under low frequency alternatives. However, they may have low power under high frequency alternatives.
In another paper, Hart proposed several new tests based on Laplace approximations to better handle the high frequency alternatives [
3]. In particular, one test with overall good power is the Bayes sum test. It is a modified cusum statistic with a better use of the sample Fourier coefficients arranged in the order of increasing frequency. Two versions of approximating the critical values were given in Reference [
3], one based on normally generated data, and the other based on bootstrap resampling of the residuals under the null hypothesis of constant regression. It is interesting to note that, even though the response variable may not be from the normal distribution, the normal approximation approach tends to give even higher power than the bootstrap approach. An explanation for this is that the Bayes sum test starts with the canonical model that the estimators of the Fourier coefficients are normally distributed, and here the sample Fourier coefficients are approximately normally distributed for large sample sizes. Thus, the Bayes sum test works well for large sample sizes and is more powerful than the order selection test and the rank-based order selection test.
A major motivation for the current work is that the practical data may have variances vary with the covariate, whereas the order selection (OS), rank-based order selection (ROS), and Bayes sum test were derived for homoscedastic regression problems. The scale parameter of the error term is assumed to be a constant in these three tests. Even in such a case, different estimators of the scale parameter may be used assuming either the null or alternative hypothesis is true.
To deal with the presence of heteroscedasticity for testing the no-effect null hypothesis, Chen et al. [
5] proposed another test statistic in addition to bootstrapping the [
6] version of the order selection test. The approximate sampling distribution of that test statistic was obtained using the wild bootstrap method. In the case of heteroscedasticity, it was shown in Reference [
5] that the asymptotic distribution of the [
6] version of the order selection test depends on the unknown variance function of the errors. Moreover, they showed that their statistic is more robust than that of Reference [
6] to heteroscedasticity and has better level accuracy. It was further shown in Reference [
5] that the wild bootstrap technique has an overall good performance in terms of level accuracy and power properties in the case of heteroscedasticity.
Other consistent nonparametric lack-of-fit tests using some smoothing techniques have been proposed (cf. References [
7,
8,
9,
10,
11,
12,
13,
14]). Some of them are difficult to compute in addition to complicated conditions that are hard to justify. All of the aforementioned methods require the response variable to be continuous.
In this paper, we consider a nonparametric lack-of-fit test of constant regression in presence of heteroscedastic variances. This test has better power for data from high frequency alternatives than the four tests reviewed above. In addition, our test can also be applied to discrete data. The test statistic is derived using the
k-nearest neighbor augmentation defined through the ranks of the predictor. This idea was first proposed in Reference [
15] for analysis of covariance model, and further used in Reference [
16] for a diagnostic test and in Reference [
17] for a test of independence between a response variable and a covariate in presence of treatments. A test statistic was defined in Reference [
16] for lack-of-fit test in the present regression setting. The authors considered each distinct covariate value as a factor level. Then, they augmented the observed data to construct what they called an artificial balanced one-way ANOVA (see
Section 2.1 for further description of the augmentation). This way of constructing test statistics has great potential to gain power over smoothing-based methods. However, we found that their asymptotic variance estimator of the test statistic in Reference [
16] seriously underestimates the true variance for intermediate sample sizes. As a consequence, regardless of the error distribution, their test has highly inflated type I error rates when
k is small and becomes very conservative when
k gets large.
In this paper, we present a very different asymptotic variance formula for the test statistic. In the special case of homoscedastic variance, our derived asymptotic variance contains one more term (a function of
k) than that in Reference [
16]. This explains the unstable behavior of the type I error pattern of their test. On the other hand, our test has consistent type I error rates across different sample sizes and different
k values, and they are very close to the nominal alpha levels.
In
Section 2, we state the hypotheses and define the test statistic as a difference of two quadratic forms, both of which estimate a common quantity but one under the null hypothesis and the other under the alternatives. Then, the asymptotic distribution of the test statistic is obtained under the null and the local alternatives for a fixed number of nearest neighbors. Moreover, we consider the idea of the Least Squares Cross-Validation (LSCV) procedure of Reference [
18] to estimate the number of nearest neighbors. In
Section 3, we present simulation studies with data generated having symmetric normal, light-tailed uniform, heavy-tailed T, and asymmetric heteroscedastic error distributions. The numerical results show that our test has encouragingly better performance in terms of type I error and power compared to the existing tests. In addition to the simulation comparisons, we present in
Section 4 an application to gene expression data from patients undergoing radical prostatectomy and an application to assess COVID-19 model fit. A summary is given in
Section 5. Technical proofs are provided in
Appendix A.
2. Theoretical Results
2.1. The Hypotheses and Test Statistic
Let , , be an independent and identically distributed random sample. Let and denote the marginal probability density function and cumulative distribution function of , respectively. Denote Var and .
We wish to test the hypotheses:
This formulation works for both continuous and categorical response variable
Y. For simplicity in the presentation, we assume that there are no duplicated observations for each value of covariate
X. If there are duplicated observations, we can use the middle ranks to take care of this issue. In regression settings, the nonlinear conditional mean regression
is often estimated through pooling observations from neighbors by one of the smoothing methods, such as loess, smoothing spline, kernel estimation, etc. For smoothing spline or kernel method, the number of observations in a window essentially needs to go to infinity as the sample size goes to infinity. The
k-nearest neighbor approach is a popular method for classification, but the theory for a fixed
k is very difficult for general regression. In this work, we use a fixed number of
k-nearest neighbors in the data augmentation to help define a statistic for conducting a lack-of-fit test. This augmentation is done for each unique value
of the predictor by generating a cell that contains
k values of the response
Y whose corresponding
x values are among the
k closest to
in rank. We consider
k to be an odd number for convenience so that the augmentation contains half of the (
k− 1) values symmetrically on each side of
when
is an inner point. Let
c denote an index defined by the covariate value
, where
and let
denote the empirical distribution of
X. We make the augmentation for each cell
by selecting
pairs of observations whose covariate values are among the
k closest to
in rank in addition to
. Let
denote the set of indices for the covariate values used in the augmented cell
. Thus, for any pair
to be selected in the augmentation of the cell
, the difference between the ranks of
and
is no more than
if
is an interior point whose rank is between
and
, i.e.,
. For
whose rank is less than
or greater than
, the difference between the ranks of
and
is no more than
. This idea was first proposed in [
15] and further used in References [
16,
17] for different problems. A test statistic was derived in Reference [
16] for lack-of-fit testing in the present regression setting by considering each distinct covariate value as a factor level. Then, the observed data were augmented by considering a window around each
that contains the
nearest covariate values to construct what the authors called an artificial balanced one-way ANOVA. Similar augmentation was considered in Reference [
17] when there are more than one treatment. Their results cannot be applied here since the asymptotic variance calculation is ill-defined when there is no treatment factor as in our lack-of-fit setting.
Let
, denote the augmented response values in cell
under the null hypothesis. Define
to be the indicator function that the difference between the ranks of
and
is no more than
. Let
and
denote the average between-cell and within-cell variations defined as the following:
where
,
Note that
and
can be easily calculated since they resemble the mean squares statistics for an ANOVA model. The calculation is on the augmented data. In most cases in the literature,
is used for constructing the test statistic when
has fixed degrees of freedom. However, in our case, the degrees of freedom for
is
, which goes to infinity. Therefore, the staztistic typically used in this case is
(see Reference [
19]), which involves showing that
converges in distribution to normality and
converges in probability to a constant. With augumented data, it is complicated to show that
converges in probability. So, we define the following difference-based
as our test statistic instead of using
-based one, where
is a variance estimator for
given later in (
9). This test statistic is similar to that proposed in Reference [
16], but with a different variance estimator.
To express
and
in terms of the original data, we can write
2.2. Asymptotic Distribution of the Test Statistic under the Null Hypothesis
Even though the test statistic is easy to calculate, the derivation of the asymptotic distribution is challenging since the augmented data in neighboring cells are correlated. In this subsection, we derive the asymptotic distribution of the test statistic derived with a different strategy than that proposed in Reference [
16]. We first simplify it by finding its projection. Specifically, define
where
. Then, we project
onto the space:
of the form
, where
are constants,
, and
is some function that is possibly nonlinear. This projection will help us to split
into two terms, one of which includes a summation over
c and the other over
c and
for
:
where
and
. Then,
is in the space defined in (
3) and
where
and
Note that the term in (
5) is closely related to the expected covariance between every pair of response values with correlation induced by their dependence on
. The
in (
6) serves as a weight function which associates the response locally the empirical distribution function of
X. The
term in (
5) is more intuitive than
to evaluate the lack-of-fit. However,
cannot be calculated from the sample since
is unknown. On the other hand,
can be directly obtained from the sample.
We assume the following condition to obtain the result under the null hypothesis:
Assumption 1. For all x, suppose that is differentiable, and the fourth conditional central moment of given is uniformly bounded.
The advantage of using a small or fixed k instead of a large k can be seen here. Even though is a quadratic form, only nearby cells have correlated observations due to the fixed number of nearest neighbors augmentation. On the other hand, when the number of nearest neighbors tends to infinity, the augmented data in many more cells will be correlated; therefore, might diverge, and the derivation of the asymptotic distribution will require unnecessarily strong conditions on the magnitude of the correlation. It is straightforward to show that with a small or fixed k. Hence, is asymptotically negligible. We state this result in Lemma 1 below.
Lemma 1 (Projection of
).
Let be as defined in (4). If the Assumption 1 is satisfied, thenwhere the notation denotes convergence in probability. To obtain the asymptotic distribution of the test statistic under the null hypothesis, we work with
where
is defined in (
6). We first give the large sample behavior of the variance of this term.
Theorem 1. Under Assumption 1, exists andwhereand are the ranks of and among the covariate values . To estimate the asymptotic variance, let
be the rank of
among all covariate values. Then, it is readily seen that a consistent estimator of
under
is
where
is the sample variance based on the augmented observations for the cell determined by
, i.e.,
Note that
are bounded counts and (
7) is a clean quadratic form as defined in Reference [
20]. The Central Limit Theorem for clean quadratic forms (Proposition 3.2) in Reference [
20] can be applied to obtain the following result. We omit the details of the proof.
Theorem 2. Under in (1) and Assumption 1,where the notation denotes convergence in distribution. 2.3. Results under Local or Fixed Alternatives
In this subsection, we consider the theoretical properties of the test under fixed or local alternatives in which the conditional expectation of Y given X is . Let be an univariate function of x.
Under a fixed alternative,
can be expressed as
where
is the conditional expectation of
Y given
X under the null hypothesis.
For local alternatives, consider the sequence of conditional expectations
that approach
in the order of
:
Both alternatives are valid for either discrete or continuous response variable and allow the data to have different conditional variance under the alternative hypotheses from that under the null. For example, if has a Poisson distribution with mean under the alternative, then the variance is instead of .
Suppose
,
are observed data under either the fixed alternatives in (
10) or the local alternatives in (
11). Let
be the augmented response values. Note that
is equal to the observed response variable whose covariate value is one of the following:
Then,
can be written as
, where
includes the conditional mean under the null hypothesis and departure from the null. Note that
satisfies the null hypothesis and can be viewed as the augmented data for
if
are under the fixed alternative in (
10) or for
if
are under the local alternatives in (
11). In either case, the conditional mean
given
satisfies the null hypothesis but with
equal to
under the alternative hypotheses. For convenience, define
to be the
function evaluated at the covariate value for augmented observation
. Let
,
,
,
,
, and
. Denote
and
to be the average between-cell variations and the average within-cell variations under the alternative hypotheses, respectively.
Under the local alternatives,
and
In this case, the numerator of the test statistic can be written as
where
Similarly, under the fixed alternatives,
where
,
are given in (
13)–(17).
The following additional condition is needed for the result under the alternative hypotheses:
Assumption 2. Suppose that has bounded support , and is locally Lipschitz continuous on : for each , there exists an such that is Lipschitz continuous on the neighborhood . Further, we assume that the fourth central moments of are uniformly bounded.
Before we give the asymptotic distribution of the test statistic under the alternatives, we state the following results which are valid under both the local and fixed alternative hypotheses.
Lemma 2. Under Assumptions 1 and 2, as ,where , , and are defined in (15), (16), and (17), respectively. The proof of Lemma 2 is given in
Appendix A. From this Lemma and Equations (
12) and (
18), we can see that
and
are the major terms that provide power under the alternative hypotheses. We state the results separately for fixed and local alternatives.
Theorem 3. Let be defined similarly as in Theorem 1 but with calculated under the alternatives in (11). For the sequence of local alternatives in (11) and under the Assumptions 1 and 2, the limit exists andwhere Note that
in Theorem 1 and
in Theorem 3 share the same formula, except that
in
needs to be calculated under the alternatives in (
11). For example, if
Y given
X has a Bernoulli distribution, then the conditional variance of
Y given
X under the local alternatives in (
11) is
, which is different from that under the null hypothesis
.
Theorem 4. For the fixed alternative in (10), under Assumptions 1 and 2, the power of the test using statistic goes to one as . The proofs of Theorems 3 and 4 are given in
Appendix A.
In heteroscedastic regression, it is common in the literature to write with independent of . In this formulation, the entire error term is uncorrelated with . In the ideal case that there is no lack-of-fit, such a model is reasonable. However, when there is a lack-of-fit because a wrong regression function is specified, the error term still contains some systematic information of . Then, it is possible that the error resulting from the specified regression function is still correlated with .
2.4. Selection of the Number of Nearest Neighbors
The number of nearest neighbors k in the test statistic specifies the number of values augmented in each cell. Our theory requires that it takes a finite small odd integer. In simulations, we have found that the type I error remains close to the nominal level for different small k values and stays stable for a broad range of sample sizes and error distributions. Under the alternative hypothesis, different k may lead to different power for our test statistic. This section discusses how to select the parameter k.
Under the alternative hypothesis, our
k-nearest neighbor augmentation is parallel to regression using a local constant based on
k-nearest neighbors. For a continuous response variable, Hardle et al. [
18] suggested the Least Squares Cross-Validation (LSCV) method for smoothing parameter (bandwidth) selection in kernel regression estimation. Chen et al. [
5] recommended using the one-sided cross-validation procedure of Reference [
21] to select smoothing parameter (bandwidth) for hypothesis testing. The number of nearest neighbors
k in our setting has a similar role as the smoothing parameter in kernel regression.
For a categorical response variable, Holmes et al. [
22] proposed an approach to select the parameter
k in the
k-nearest neighbor (KNN) classification algorithm using likelihood-based inference. Choosing
k in this method can be considered as a generalized linear model variable-selection problem. In particular, for multinomial data
,
, where
denotes the class label of the
ith observation, and
is a vector of
p predictor variables, they considered the probability model
where
denotes the data with the
ith observation deleted,
is a single regression parameter, and
is the difference between the proportion of observations in class
and that in class
within the
k-nearest neighbors of
, i.e.,
where the notation
denotes that the summation is over the
k-nearest neighbors of
in the set
, and the neighbors are defined based on the Euclidean distance. The prediction for a new point
is given by the most common class in the
k-nearest neighbors of
. Afterwards, the value that maximizes the profile pseudolikelihood is chosen to estimate the parameter
k. However, this method is only valid when the response variable is a categorical variable and the nearest neighbor is defined using the Euclidian distance.
In our case, the response variable could be continuous or categorical, and our nearest neighbors are defined through ranks. So, we do not recommend to use our test statistic with an estimate of
k obtained with aforementioned procedures. We consider an alternative method to estimate
k which uses ranks to define nearest neighbors and can be applied in both categorical and continuous response cases. Here, we adopt the idea of the Least Squares Cross-Validation (LSCV) procedure of Reference [
18] to select the parameter
k. Different from Reference [
18], where the regression function is estimated using kernel estimation, we consider
k-nearest neighbor estimates with the neighbors defined through the ranks of the predictor variable. In the case of categorical response variable with
Q classes, we re-code the response variable to have integer values from 1 to
Q. To estimate the class for the response variable, we use the majority vote (the most common value) from the
k-nearest neighbors. For tied situation where there are multiple classes achieving the same highest frequency, one of them is assigned randomly to be the estimated response. In the case of continuous response variable, the regression function is estimated by the average of the
k-nearest neighbors.
In a leave-one-out procedure, for each , we eliminate and use the rest of the observations to estimate the regression function which then is used to predict the response value Y at . Here are our steps:
- 1.
Find the observation in
such that the absolute difference between this observation, and
is minimized. Denote
Then,
is the closest to
.
- 2.
Find the
k-nearest neighbors of
in terms of ranks. We use the corresponding
values such that
to obtain the leave-one-out estimate of the regression function at
. That is,
where the Mode is defined as the most frequently observed value in a set of numbers. In the case where the most frequently observed values are not unique, one of them is randomly selected.
- 3.
Repeat steps 1 and 2 for to obtain all leave-one-out estimates.
Then, define the leave-one-out Least Squares Cross-Validation error as
Finally, the number of nearest neighbors is estimated by
where the set
consists of small odd integers.
When the response variable is categorical, the estimate of k from this algorithm depends on how well the covariate values from different classes are separated and how many observations are in each class. For large class sizes, it is very possible that the resulting estimate is much greater than 10 if we leave unconstrained. However, our theory requires k to be a finite, positive, and odd integer.
In the continuous case with k-nearest neighbor estimation, the average of a big proportion of Y values is used to approximate the response variable if a large k value is utilized. As a consequence, bigger k tends to give larger least squares error when the regression function is under the alternative hypothesis. This is especially true when the regression function has substantial curvature, such as in high frequency alternatives. On the other hand, larger k tends to give smaller least squares error when the data were generated under the constant regression null hypothesis.
In either case, the smallest value for k is 3 (note: corresponds to the case of no data augmentation). In order to keep the least squares error minimized under the alternative hypothesis and reasonable under the null hypothesis, we recommend to let contain a few small integer values. For example, , which is a safe choice for both moderate and large sample sizes.
Figure 1 shows the typical pattern of
as a function of
k for
when the response variable was generated as (1)
; (2)
; (3)
; and (4)
, where
and
are i.i.d
.
3. Monte Carlo Simulation Studies
In this section, we present the results of some simulation studies to investigate the type I error and power performance of our test. The test has a parameter
k to specify the number of nearest neighbors for data augmentation. The inference for our test requires the
k to be a small odd positive integer. We report the results for
and 5 and denote them as
and
, respectively. This is for the user to have an idea of how the test behaves with a given
k. Furthermore, we report the results of our test with
k selected from 3 and 5 using our considered method in
Section 2.4 and denote it as
. For the
applied to each generated data set, the value of the
k is selected using
in (
20), and our test with parameter
is used to obtain the
p-value.
For comparison, we also report the corresponding results for the test of Reference [
16], the order selection (OS) test of Reference [
1], the rank-based test (ROS) of Reference [
2], the bootstrap order selection test (BOS) of Reference [
5], and the Bayes sum test of Reference [
3]. As argued in Section 7.1 of Reference [
4], evenly spaced design points should be used for calculation of these four test statistics even when they are unevenly spaced. So, the generated covariate values in increasing order were replaced by evenly spaced design points on
for all four tests. For BOS, we apply the wild bootstrap algorithm of Reference [
5] based on the residuals
and use their test statistic with 1000 bootstrap samples for each replication. For the Bayes sum test, we use the statistic that has been reported to have good power from a comprehensive simulation study in Reference [
3]. For approximating the
p-values of the Bayes sum test, Hart [
3] gave two versions of the approximation, one assuming normality (BN) and one using the bootstrap (BB). For BN, a random sample of the same sample size as the data was generated from the standard normal distribution, and the Bayes sum test statistic was calculated from the data so generated, regardless of the actual distribution of the response variable. The process was independently repeated 10,000 times, and the
p-value was obtained based on the empirical distribution of these 10,000 values. For BB, the bootstrap samples were drawn from the empirical distribution of the residuals
,
, rather than the normal distribution, and the
p-value approximation was carried out similarly. The scale parameter
for a given data set
in both BB and BN statistics was estimated by
, as was suggested in Reference [
3]. It was reported in Reference [
3] that the results obtained using the normality assumption were in basic agreement with those obtained using the bootstrap. So, we only report the simulation results for BN.
The values for the covariate
X were independently generated from Uniform
. First, we consider the performance of different tests under the
. The data were generated from
where the error term
were independently generated with one of the four error distributions:
- 1.
Uniform
(denoted as Unif in
Table 1 and
Table 2);
- 2.
(Normal)
Normal
(denoted as Normal in
Table 1 and
Table 2);
- 3.
, where
follows
t-distribution with 5 degrees of freedom (denoted as
in
Table 1 and
Table 2); and
- 4.
, where
Uniform
. This is a heteroscedastic regression model and denoted as Heter in
Table 1 and
Table 2.
The empirical type I error rates (in percentage) under
are reported in
Table 1. It can be seen that the test of Reference [
16] with
or 5 generally has inflated type I error and is particularly serious with smaller sample sizes. For
, their test has type I error close to 0.05 when the error distribution is Normal or T(5)/30 but is as high as about twice of the significance level in the heteroscedastic case. Its performance for
is better than with other
values but still is inflated for the heteroscedastic case. The order selection test of Reference [
1] and the proposed test with different
k-values have better type I error control. Among the three
k-values, larger
k pulls more observations around each covariate value as pseudo replicates. This could lead to the test being less sensitive to curvature departure against the null hypothesis. Hence, we recommend to choose
k between 3 and 5.
Next, we consider the performance of the tests with data generated from nonlinear models. The response values were independently generated according to the following four models for , with the moderate sample size of in all cases:
Model : ,
Model : ,
Model : , and
Model : ,
where
q in Models
–
represents the frequency. We considered
and
. The case with
is a higher frequency alternative compared to those reported in Reference [
3]. The data for the error term
in each model were independently generated with one of the four error distributions listed earlier. Model
serves as the null model to obtain the type I error rates for all tests. For each error distribution, the data were generated from Models
–
, with sample size
for 2000 times, and the rejection rates (in percentage) at significance level 0.05 are reported in
Table 2.
It can be seen that the type I error estimates for all tests were below or close to the nominal level 0.05 for all models with homoscedastic errors. For the heteroscedastic regression model, the variance of the error depends on the covariate, while the conditional mean of the response variable given the covariate is a constant under Model . In this case, all the tests tend to be liberal.
The rows
to
in
Table 2 show the power comparison for the different combinations between Models
–
and the four types of the error distribution. The powers of our test with
(
) are higher than all other tests in all cases. BN has power close to our test. OS, ROS, and BOS fall far behind. The low power performance of BOS in the case of high frequency alternatives was mentioned in Reference [
5], and they suggested (without details) to use smoothing squared residuals to deal with that.
It is noticeable that the power of our test is 1 for Models and for all different types of the error distribution and very close to 1 for Models and . In addition, the power for OS was slightly higher than that for ROS in all cases.
Models
and
are similar, except that Model
has lower signal to noise ratio than Model
. With the lower signal to noise ratio, the power for ROS, OS and BOS drops drastically. To have a closer look at the numerical performance of all tests under local alternatives, we considered the model
, with
and
Uniform
. The empirical power curves are given in
Figure 2. It is obvious that our test
has consistently higher power than the other tests.
The discussions above are for high frequency alternatives with and moderate sample size . When sample size increases, while the frequency stays the same, the power of each test also increases. For sample size of 100, the empirical power is 1 for all the compared tests of NB, OS, ROS, and under Models –. Under Model , OS and ROS have power slightly below 1 for the case with uniform error. The rest of the tests have power close to 1. Similarly, for lower frequency alternatives, for example, when and , all these tests have power close to 1.
To examine how the power of these tests changes with the sample size, we generated data with model
, where
,
Uniform
, for
. The empirical power of these tests is presented in
Figure 3, where
is our test with
selected from
and 5 based on (
20). It is obvious that the proposed test
consistently has the highest power over all the sample sizes considered.
Even though BN showed a comparable performance to our test in many cases, the running time of BN is much longer than . In particular, the average running time from 10,000 runs from BEOCAT cluster machines for is 0.03 s, while that for BN is 9.7 s. So, is more than 300 times faster than BN.



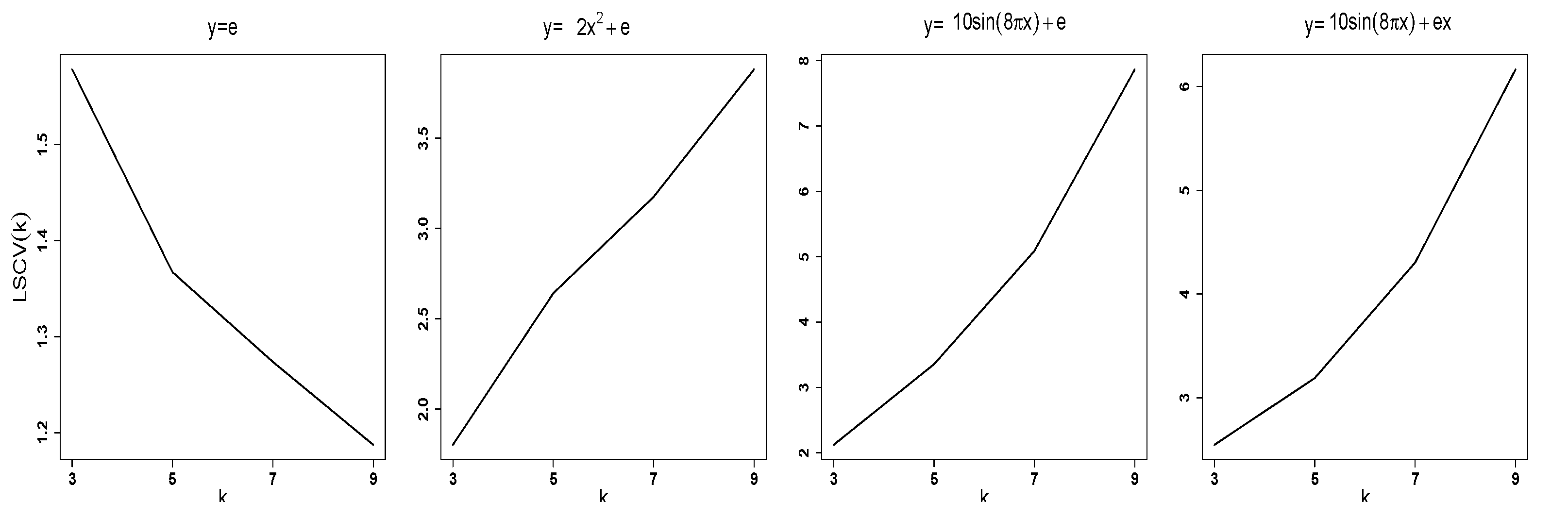





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}