1. Introduction
Data envelopment analysis (DEA) has been regarded as a powerful technique to select and combine models for general k-class classification problems in machine learning [
1,
2]. The application of DEA as an ensemble for classifiers in machine learning is inspired by the ROCCH (receiver operating characteristics convex hull) [
3] which was mainly for the two-class classification problem. DEA was first proposed by [
1] to construct ensembles for classifiers and they showed that DEA identified a convex hull that is identical to that of ROCCH for a classification problem with two classes. From then onwards, DEA has been utilized as an ensemble of classifiers that can be applicable to problems with multiple classes [
2]. Baumgartner and Serpen [
4] had further shown that integrating multiple base classifiers into an aggregated outcome (or ensemble) has turned out to be an efficient strategy for achieving superior prediction performance.
The underlying fundamentals of DEA is based on a nonparametric approach that addresses the issue of determining the efficiency of various “decision-making units” (DMUs) based on how inputs are converted into outputs [
5]. A DMU is rated as fully efficient (100%) if and only if the performance of other DMUs does not show that some of its inputs or outputs can be improved without worsening some of its other inputs or outputs [
6]. DEA, which is extensively used to investigate a wide range of industries [
7,
8] and has lately been implemented in the big-data toolbox [
9], employs mathematical programming to discover efficient DMUs, which constitute an efficient frontier. The efficiency score in DEA analysis highly relies on the set of input and output variables used in the efficiency measure. Hence, if DEA is to be fully utilized in evaluating as many different classifiers as possible, inputs and outputs variables selection in a DEA model is critical. We therefore expect to address this problem of DEA by developing a global search method (GSM) for optimizing variables selection.
The contributions of this paper are as follows. Firstly, this study enhances DEA for efficiency measurement which is the key concept for performance. Secondly, this paper generates a searching algorithm for variables selection that include variables with the largest impact on the DEA results, in which the algorithm is grounded on optimization approach. Finally this study yields useful managerial insights for decision-makers to make reliable judgements and to be used as guidelines to adjust or balance (symmetrize) their strategies and needs with proper allocation of resources.
This paper is organized as follows.
Section 2 presents the literature on variables selection in DEA.
Section 3 presents the methodology of the global search method (GSM). In
Section 4, we illustrate this method using sample datasets and discuss the new managerial insights resulting from the GSM. In
Section 5, further illustration and validations on GSM are presented using two established numerical examples and a case study on US banks. Concluding remarks are presented in
Section 6.
2. Past Research on Variables Selection in DEA
It is very important to select the potential variables to be considered in a DEA model. In general, any resource used by a DMU should be treated as an input variable, and the outputs come from the performance and activity measures when the DMU converts its resources to produce products or services. However, how to choose the right input and output variables has attracted only little attention in the existing literatures. Most of the existing studies on DEA simply treat the input and output variables as “givens” and then go on to deal with the analysis. As it was until 1989, Golany and Roll [
10] gave an overall view of DEA that should focus on the choice of variables in addition to the methodology itself. The attention to variable selection is important because the increasing number of input and output variables will constrain the weights assigned to the variables, and the analysis of the results will become less discerning. Jenkins and Anderson [
11] applied regression and correlation analysis to identify which variables were to be omitted from the DEA model on the basis of the minimum loss of information. Information was related to the variance of an input or output variable about its mean value. Morita and Avkiran [
12] proposed a statistical approach to find an optimal inputs/outputs combination by using diagonal layout experiments.
While there is no consensus on how best to select the variables, many guidelines have been proposed in the literature suggesting limiting the number of variables relative to the number of DMUs. In general, a rough rule of thumb in the envelopment model of DEA is to choose
n (= the number of DMUs) equal to or greater than max{m × s, 3 × (m + s)}, where m and s are the inputs and outputs variables respectively (see [
13] for more details). The challenge in DEA is to find a ‘parsimonious’ model, using as many input and output variables as needed but as few as possible. The greater the number of input and output variables in a DEA, the higher is the dimensionality of the linear programming solution space, and the less discerning is the analysis [
11].
Several methods have been proposed that involve the analysis of correlation among the variables, with the goal of choosing a set of variables that are not highly correlated with one another. These methods purport those variables which are highly correlated with existing model variables are merely redundant and should be omitted from further analysis. Unfortunately, Nunamaker [
14] figured out that these methods yield results which are often inconsistent in the sense that removing variables that are highly correlated with others can still have a large effect on the analysis results. In addition, a parsimonious model typically shows generally low correlations among the input and output variables, respectively [
15,
16]. Appa et al. [
17] proposed a method of adding variables to the DEA model one at a time. They claimed that high statistical correlation was an indicator that a particular variable influenced the performance. The authors did note that the observation of high statistical correlation alone was not sufficient. After that, Jenkins and Anderson [
11] applied regression and correlation analysis to identify which variables were to be omitted from the DEA model on the basis of the minimum loss of information. Information was related to the variance of an input or output variable about its mean value. Their statistical approach using partial correlation analysis resulted in a measure of information contained in each variable. The authors found that the DEA results could vary greatly according to which highly correlated variables were included or omitted from the DEA model.
At the same time, some investigations start to evaluate the marginal impact on the efficiencies of an adding or omitting a given variable, and focusing on evaluating the statistical significance of the changes in the efficiencies [
18]. Another statistical approach for variable selection was developed by [
19]. They focused on the inner models which data differed in one single input or output variable. They evaluated a reduced DEA model without one particular variable, and an extended model that included one variable. Then, for each DMU, the efficiency scores were calculated under both the reduced and extended model. A statistical test was conducted to determine the significance of the efficiency contribution of the particular variable being evaluated. Amirteimoori et al., [
20] developed an approach that aggregates selected high correlated inputs/outputs to reduce the total number of variables and increase the degree of discrimination. While Ref. [
21] pointed out that such approach is unstable due to the epsilon is not unique, they have improved the approach to only one step iteration.
In contrast to correlation based methods, which look at the input and output variables before applying DEA to determine the likely effect on the efficiency scores after the application of DEA, other approaches examine directly the effect on the efficiency scores when the input and output DEA variables are changed. The initial model was compared with those of a new model in which one additional variable was added. Ref. [
22] developed a “stepwise” selection approach to examine the changes in the efficiencies as variables are added and removed from the DEA model, often with a focus on determining when the changes in the efficiencies can be considered statistically significant.
In addition, their approach has not considered the rule of thumb, and each selection step is only based on the minimum efficiency change with the last step that is just local optimal—it may not lead to the optimal global decision. Toloo et al. [
21] developed selecting models of performance measures in DEA; their models applied the rule of thumb to keep the balance between the number of DMUs and the number inputs/outputs by solving a series of mixed-integer linear programming (MILP) model. However, whether viewing from individual DMU or aggregate, such a model is still unable to determine exactly which variables should be selected, because they consider those performance measures “appear the most often” and take the risk of losing important managerial information.
In this study, we advance the work on variable reduction methods in DEA by formalizing a “global search method (GSM)” for the selection process, and examine the managerial insights gained from using this method. Our proposed GSM measures the effect of influence of variables directly on the efficiencies by considering their average change as variables are added or removed from the analysis. This method is intended to produce DEA models that include only those variables with the largest impact on the DEA results. Moreover, it is useful for models which do not have sufficient number of DMUs and violate the rules of DEA. This can happen in niche classifications (e.g., markets) where the number of comparable DMUs is few, or new classifications (e.g., industries) where the number of measures far exceeds the total number of DMUs. This method is easy to understand, and therefore, it is useful to managers and decision-makers, as it does not need extensive additional calculations.
3. A Global Search Method for Selecting Variables in DEA
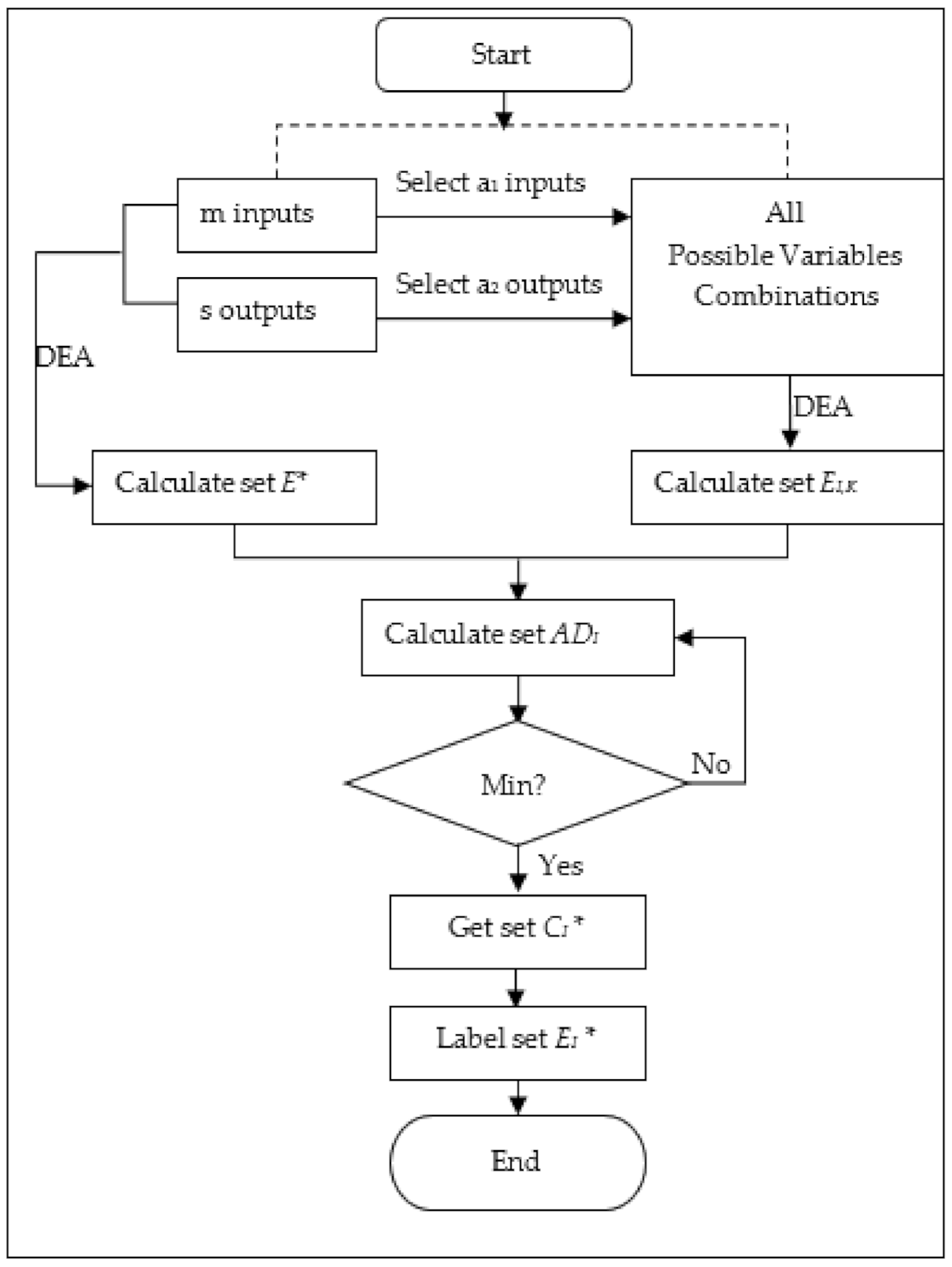
We begin by describing the procedures of GSM. The GSM aims to optimize the number of DEA variables and to find the key input and output variables which influence the efficiency scores. We now explain in detail the GSM procedure for effective omission of DEA inputs and outputs.
This approach starts by considering all possible combinations of input and output variables in the DEA model. Assume an original DEA model that has
m inputs and
s outputs, the total number of DMUs is
n. The rule of thumb in [
13] provides a guidance for determining a numerical relation between the number of DMUs and number of inputs/outputs, i.e.,
Set
a1 input variables and
a2 output variables are planned to be kept in the model, where
. The selection procedure will be divided into
N cases that depends on the condition of formula (1).
where card(A) denotes to count the number of elements in a set A. For each case
I, where
I = {1, 2, 3, … ,
N}.
NI represents the number of possible combinations of inputs and outputs, where:
The algorithm for selection procedure is conducted by the following steps.
Step 1: Run the original DEA model that includes the full set of m input variables and s output variables. Record the efficiency scores of each DMU for this run (set ).
Step 2: Run a set of k = 1, ... , NI DEA analyses, keep setting a1 input variables and a2 output variables at a time in each run. For each analysis, record the efficiency scores of each DMU (set ) for all k runs.
Step 3: Calculate, for each DMU, the average differences
ADI in the respective DMU efficiency scores by
Step 4: Choose the optimal variables combination
CI * to be kept by selecting the variable with the minimum average difference in the efficiency scores from above.
Step 5: For the variables selected to be kept, label the DEA results EI* based on the efficiency scores of the DMUs for the remaining input and output variables.
Through steps 1 to 5, the optimal variables combination
CI* and the corresponding DEA results
EI * are worked out by searching through all the variables’ combinations for case
I, which means the optimal
a1 input variables and
a2 output variables have been selected to remain in the model with the minimum average difference in the efficiency scores.
Figure 1 shows the flow chart of the GSM algorithm for case
I.
Then, for all
N cases, calculate all the possible efficiency scores under all combinations of the input and output variables by comparing the changes in efficiency with that of the original model. The total number of possible combinations of the input is:
Theoretically, the method reiterates until only one input and one output variable remain in the model (i.e., for case
I = 1). From the practical viewpoint, how many cases should be evaluated depends on the decision criterion to create a parsimonious DEA model. It should also be noted that the GSM procedure does not rely on the particular form of the DEA model. This procedure can be used with either CRS or VRS, or with static or stochastic data, as long as the same model is used consistently in all steps. The complexity analysis of this method is attached in
Appendix A.
5. Further Illustration and Validations
In this section, the proposed GSM method is further tested and validated using two established numerical examples then followed by a case study. The examples from [
11,
22] are used here.
5.1. Example 1: Compared with Partial Correlation in Jenkins and Anderson
We begin with a simple exercise using the CCR-I primal model and compare our results with Jenkins and Anderson [
11]. In
Table 5, there are six inputs, two outputs and only eight DMUs.
In order to compare with the method of partial correlation in [
11], we omitted the same number of input variables and kept all outputs.
Table 6 shows the results of GSM and Jenkins and Anderson’s [
11].
From
Table 6, we can see the advantage of the GSM model with less efficiency change. If considering two input variables to be kept, the GSM model selects I3 and I5, the partial correlation model selects I1 and I3. However, the GSM analysis shows that if I3 and I5 are to be kept as to retain as much information as possible (measured by average efficiency change), I3 and I5 are the best pair to be kept. The most surprising result is perhaps the choice of variables to keep, which is certainly not accurate from the partial correlation, and how much information is retained by a judicious choice of fewer variables. The partial correlation is indirectly related to the resulting changes in efficiencies, while the GSM model can retain as much as information when choosing the same number of input variables.
5.2. Example 2: Compared with Wagner and Shimsak
In this section, we conduct a further analysis by comparing our GSM model with other related variables selection methods, i.e., stepwise [
22] and selective measures [
21]. Using the data provided earlier in
Table 1 above, we obtain the following results.
Table 7 shows the results of GSM and stepwise. As a general view, GSM model is able to choose the more important variables with less efficiency change, and the results of GSM have 5.63% improvement compared with stepwise model. If we want to choose the ‘core’ variable of the DEA model, which means to select one representative input and output variable with least information lost. The GSM model selects I6 and O2 with average efficiency change of 0.302, which is less than 0.304 from the stepwise method that chooses I4 and O2. In addition, the GSM method can provide valuable and accurate managerial information to the decision-maker that is not available from traditional DEA analysis.
To compare with selective measures method [
21], for instance now, here if managers choose to keep five input/output variables, then the results are shown in
Table 8.
The results in
Table 8 indicate that, when choosing five variables to keep, the GSM model gives three alternative options: four inputs and one output, three inputs and two outputs, two inputs and three outputs, while the stepwise model and selective measures can give only one choice. Overall, if the manager chooses four inputs and one output to keep, both GSM and stepwise selected inputs: “total capital”, “total current liabilities”, “total operating expenses, selling, general & administrate” and output: “net sales or revenues”. This option is the best choice because it has smallest information lost and kept 99.47% information compared with original model. However, stepwise does not consider the rule of thumb, and each selection step is only based on the minimum efficiency change with the last step that is just local optimal, so it may not lead to the optimal global decision in some cases. As for selective measures, it has greater efficiency change and may lose more managerial information, because this approach mainly focuses on maximizing its individual or aggregate efficiency, not considering the information losing from the global views. In addition, selective measures cannot determine exactly which variables and how many should be selected, because they consider those performance measures “appear the most often”, while, here, in order to compare the result, we choose the result case with smallest efficiency change, even though doing so may incur the risk of losing important information.
From the above analysis, we can see that our GSM model has shown a great advance in performance variables selection in the normal DEA model. First, it has considered the rule of thumb to keep the balance between the number of DMUs and the number of variables. Second, it can determine the exactly which variables to be selected and alternative options for different decision-making. Third, it can help decision-makers to find the key input and output variables that make the main contribution to improving efficiency.
5.3. Case Study: US Banks
The GSM model helps to select variables in DEA and provides a framework for a number of alternative implementations. As previously mentioned, as long as a normal DEA model is used in each step, the GSM algorithm can be used with a variety of efficiency models. In this section, we conduct the analysis in the banking industry using the model by [
23]. The data used in this model were captured from fifteen US banks with six ratios in 2011. The GSM is suitable to be applied to this US banks example because there are many ratios in the analysis of efficiency. Most of the time, the number of DMUs is not enough to meet the minimum criteria. Therefore, the use of GSM here helps greatly to overcome this problem.
Table 8 shows the fifteen US banks with six ratios. The ratios are as follows.
Table 9 shows the ratios of the banks and
Table 10 shows the efficiency scores of each DMU. The last row in
Table 10 indicates the average change in the efficiency score. At the beginning, the analysis of the ratio model containing all six ratio variables yields four efficient banks (B6, B12, B14, and B15). For Case 1, removing “Current Ratio” shows the smallest average change in the efficiency scores (2.62E−10). When it is omitted from the model, the same four banks remain efficient. For Case 2 with four ratio variables, “Current Ratio” and “Profit Margin” are selected to be dropped with an average change in efficiency score of 0.008 resulting in the same efficient banks.
For Case 3, the ratio variables of “Return on Total Assets”, “Price Earning Ratio” and “Dividend Pay-Out” are kept and the average change in the efficiency score is 0.0223. For Case 4 with two ratio variables, “Return on Total Assets” and “Price Earning Ratio” are kept and the average change in the efficiency score is 0.0457. For Case 5 with only one variable (“Dividend Pay-Out”) kept, a fairly large average change in the efficiency score of 0.094 occurs. The efficiency scores for some DMUs (e.g., B6) are reduced by as much as 59%. In this case, there is only one efficient bank, i.e., B15. When the GSM algorithm is taken to its conclusion, there will always be one ratio variable identified as the most important for the efficiency score. In this US banks analysis, the key variable that has been identified for these banks is “Dividend Pay-Out” (the single remaining ratio). Managerially, we interpret this result as indicating that the core strategy for banks is to focus their capability of making profits, therefore gaining greater “Dividend Pay-Out”.




{kind=link}
{kind=link}