1. Introduction
Recently, researchers are interested in deriving distributions with bounded support. Some of these distributions are the unit Birnbaum–Saunders (UBS) [
1], unit gamma [
2], unit Gompertz [
3], unit inverse-Gaussian [
4], unit Lindley [
5,
6], unit Weibull (UWEI) [
7,
8,
9], and trapezoidal beta [
10] models, among others.
This interest is due to several natural and anthropogenic phenomena are measured as indexes, percentages, proportions, rates and ratios, which are bounded on a certain interval, usually the unit interval. The need for modeling and analyzing bounded data occurs in many fields of real life such as in medicine [
8], politics [
11], and psychology [
12]. Hence, to statistically describe this kind of data, distributions with bounded support are needed.
A series of distributions with support on the unit interval have been proposed in the literature based on transformations of the cumulative distribution function (CDF). Among them, we can mention the log-Bilai [
13], log-shifted Gompertz [
14], unit Gompertz [
3], unit inverse-Gaussian [
4], unit Lindley [
5], and UWEI [
8] distributions.
In order to assess the influence of one or more covariates on the mean of the distribution of a response variable bounded on the unit interval, the following distributions can be used: beta [
15], beta rectangular [
16], log-Bilai [
13], log-Lindley [
17], log-weighted exponential [
18], quasi-beta [
19], simplex [
20], unit gamma [
2], and unit Lindley [
5,
6,
21]. To investigate the relationship between the response mode and covariates, we can consider the beta [
22], Kumaraswamy (KUMA), unit gamma, and unit Gompertz [
23] distributions.
The challenges in applied regression have been changing considerably, and full statistical modeling rather than predicting just means and modes is required in many applications [
24]. Some parametric quantile regression models for bounded response that are available in the literature are based on the exponentiated arcsech-normal [
25], Johnson-t [
26], KUMA [
27], log-extended exponential-geometric (LEEG) [
28], L-logistic [
29], power Johnson SB [
30], unit Chen (UCHE) [
31], unit half-normal (UHN) [
32], unit Burr-XII (UBUR) [
33], and UWEI [
8] distributions. Unlike regression models through the mean, quantile regression, introduced in [
34], allows one to model the effect of covariates across the entire response distribution. This motivates us to propose new quantile regression models.
Originated from problems of vibration in commercial aircraft that caused fatigue in the materials, Birnbaum and Saunders [
35] introduced a skew positive distribution that has been extensively studied in the statistical literature. During the last decade, the Birnbaum–Saunders (BS) distribution has received significant attention by many researchers who generalized the BS distribution [
36], studied its mathematical and statistical properties [
37,
38], estimated its parameters [
39], and conducted regression modeling [
40,
41] and its diagnostic analysis [
42]. BS quantile regression models and its diagnostics have been recently studied in [
42,
43,
44,
45].
As mentioned, an extension of the BS distribution for modeling bounded data was proposed in [
1]. The authors showed that the UBS distribution is flexible and could be a good alternative to the beta and KUMA distributions for modeling data supported on the unit interval. In this context, considering the lack of agreement on preference and advantage of a specific model to describe bounded phenomena in a full statistical fashion, based on [
42], we parameterize the UBS distribution using its quantile function (QF) to introduce a parametric quantile regression model. It is well-known that there are at least three approaches to modeling quantiles conditional on covariates, which are: (i) the distribution-free approach [
34]; (ii) the approach based on a pseudo-likelihood through an asymmetric Laplace distribution [
46]; and (iii) the parametric approach with the traditional maximum likelihood (ML) framework. The current manuscript is classified as the third category. To the best of our knowledge, quantile regression for modeling bounded data under a UBS distribution have not been proposed until now.
In this paper, we parameterize the UBS distribution in terms of its QF to evaluate the influence of one or more covariates on any quantile of the distribution of the response variable. This strategy was considered in [
8,
25,
26,
27,
28,
29,
47] also to model responses on the standard unit interval. Other strategies were considered in [
30,
48,
49]. For discrete and continuous positive responses, the literature is scarce and we can cite [
42,
50,
51], who considered the discrete generalized half-normal distribution for discrete responses. Therefore, the objective of this investigation is to propose, derive and apply a UBS quantile regression model as an alternative to the existing quantile regression models.
The remainder of the paper is as follows. In
Section 2, we introduce and characterize the UBS distribution in terms of its QF. The estimation method of parameters for the UBS distribution, based on the ML method, is discussed also here. The UBS quantile regression model is formulated in
Section 3. A simulation study is carried out to evaluate the performance of the proposed results which are presented in
Section 4. Applications considering two real data sets related to political sciences and sports medicine with seven competing models to the UBS quantile regression are analyzed in
Section 5 and
Section 6. Finally,
Section 7 provides some conclusions and limitations of this work, as well as ideas for future investigation.
2. The Unit Birnbaum–Saunders Distribution
In this section, we parameterize the BS distribution in terms of its QF.
Considering the transformation
, where
, the UBS distribution was proposed in [
1] with probability density function (PDF) and CDF written, respectively, as
and
where
,
is the shape parameter and
is the CDF of the standard normal distribution. It is noteworthy that
is a scale parameter and is also the median of the distribution of
X, since
. In addition, the
r-th moment of
X is given by
where
.
By inverting the CDF defined in (
2), we have the QF stated as
where
and
is the QF of the standard normal distribution. Now, by solving the linear equation
in
obtained from (
3), we have
where
and
is the inverse function of
g, which is assumed to be a quantile link function being strictly increasing, twice differentiable and mapping
into
.
Hence, we can parameterize (
1) and (
2), as a function of
, by means of
and
where
,
,
, and
is fixed.
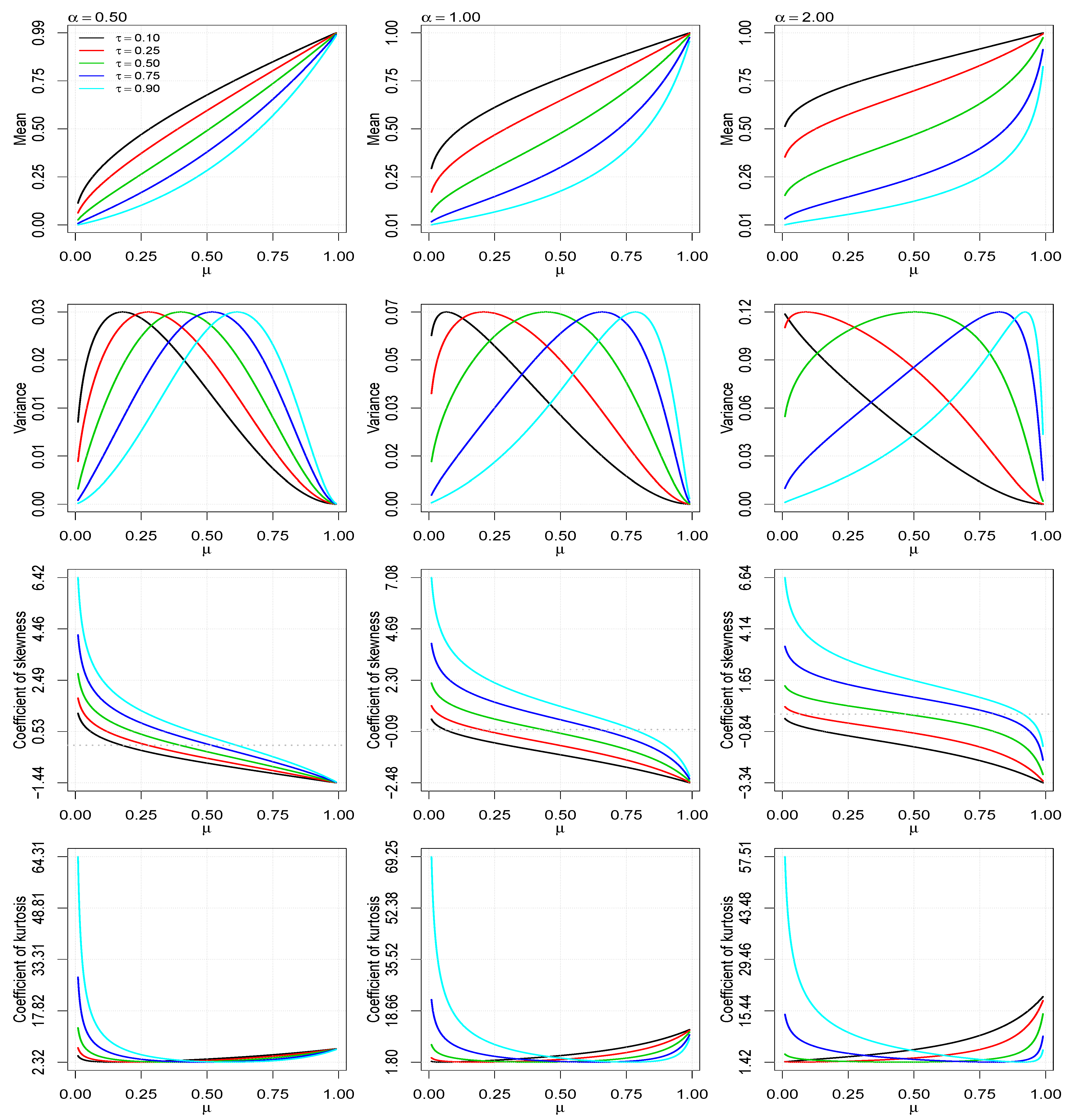
Figure 1 shows some possible shapes of the PDF of the UBS distribution for selected values of the parameters
,
and
. The behaviors of the mean, variance, coefficient of skewness and coefficient of kurtosis are shown in
Figure 2.
An advantage of the parameterization stated in (
5) and (
6) is that
is the
-th quantile and, consequently, the interpretation of this parameterization becomes more interesting in applications. Furthermore, it is possible to consider that the parameter
depends on covariates; see
Section 3.
The standard ML method can be used to estimate the UBS parameters by maximizing the corresponding log-likelihood function. Let
be a realization of the random sample
, where
are independent and identically distributed random variables according to (
1). Using (
5), the corresponding log-likelihood function, with
, is written as
Defining
, where
,
, and
, we get the associated score vector with coordinates stated as
By solving numerically the system of non-linear equations in
and
, formed by the coordinates of
defined in (
7) and (
8), we have the ML estimate of
. The asymptotic standard errors (SEs) of the corresponding estimators are obtained by inverting the Hessian matrix of the log-likelihood function. This Hessian matrix is generated by taking the second derivative of (
7), with respect to
and
.
For
, we have that
while
must be found numerically taking
in the expression defined in (
7).
3. The UBS Quantile Regression Model
In this section, considering the parameterized PDF stated in (
5), we formulate the UBS quantile regression model.
Let
be
n independent random variables, where each
, for
, follows the PDF given in (
5) with unknown quantile parameter
, unknown shape parameter
, and
is assumed as fixed, that is,
. Here, the UBS quantile regression model is defined imposing that the quantile
of
satisfies the functional relation expressed by
where
is a
p-dimensional vector of unknown regression coefficients, with
and
n being the sample size,
denotes the observations on
p known covariates, and
g is given as in (
4). There are several possibilities for the link function
g stated in (
9). For instance, the most useful well-known link functions are:
- (i)
[Logit] ;
- (ii)
[Probit] ;
- (iii)
[Complementary log-log] ;
- (iv)
[Log-log] ; and
- (v)
[Cauchit] ;
which are the inverse CDF of the logistic, standard normal, minimum extreme-value, maximum extreme-value and Cauchy distributions, respectively.
Let
be
n independent random variables such that
denotes a UBS distributed random variable and consider that
to ensure that the predicted quantiles lie within the unit interval.
For fixed
let now
be the vector of
unknown parameters to be estimated. The ML estimate
of
is obtained by the maximizing the log-likelihood function stated in (
7). It is not possible to derive analytical solution for the ML estimate
so that it must be calculated numerically using some optimization algorithm such as Newton-Raphson and quasi-Newton. Based on [
15], we suggest to use, as an initial guess for
, the ordinary least squares estimate of this parameter vector obtained from the linear regression of the transformed responses
on
, that is,
, where
.
Under mild regularity conditions and when the sample size
n is large, the asymptotic distribution of the ML estimator
is approximately multivariate normal (of dimension
) with mean vector
and variance covariance matrix
, where
is the expected Fisher information matrix. Note that there is no closed form expression for the matrix
. Nevertheless, as shown in [
52], the estimated observed Fisher information matrix
is a consistent estimator of the expected Fisher information matrix
. Therefore, for large
n, we can replace
by
.
Let be the r-th component of . The asymptotic confidence interval for is given by , with , where is the upper quantile of the standard normal distribution and is the estimated asymptotic SE of . Note that is the square root of the r-th diagonal element of the matrix .
Given n pairs of observations , the parameter estimates of and can be obtained directly through a library of the R software named unitBSQuantReg by means of its function unitBSQuantReg(formula, tau, data, link,…). For model checking, the function hnp(object, nsim = 99, halfnormal = TRUE, plot = TRUE, level = 0.95,
resid.type = c(“cox-snell”, “quantile”)) is available, which provides half-normal probability plots with simulated envelopes. A version of the
unitBSQuantReg package is available at
https://github.com/AndrMenezes/unitBSQuantReg (accessed on 9 April 2021).
Due to the direct interpretation of the parameters in terms of odds, in this paper, we consider only the logit link. When is the -th quantile, for , the interpretations are straightforward. In addition, a strictly positive link function relating the shape parameter with covariates , not necessarily equal to , can be considered. Of course, other link functions might be explored.
4. A Monte Carlo Simulation Study
In this section, we present the results of the Monte Carlo simulations used to assess the empirical bias and root mean-squared error (RMSE) of the ML estimators of the UBS quantile regression parameters. We also present the coverage probability (CP) of the confidence interval (CP) based on asymptotic normality of the ML estimators. We consider sample sizes ; ; , and two regression frameworks formulated as
- (i)
for , , with ; and
- (ii)
for , , , , with .
For each combination of
and both regression frameworks (the covariate(s) remained constant throughout the simulations),
pseudo-random samples were simulated using the
SAS Data-Step, while parameter estimates were obtained by the quasi-Newton method in
SAS PROC NLMIXED. The values of the response variable, given
n,
,
and the covariate(s), are generated from the quantile function stated as
where
and
for
defined in (
4).
The empirical bias, RMSE and CP are calculated, respectively, by
- (i)
Bias;
- (ii)
RMSE; and
- (iii)
CP, where , or , I is the indicator function, and is the corresponding estimated SE.
Table 1,
Table 2 and
Table 3 and
Table 4,
Table 5 and
Table 6 report the results for the first and second regression structures respectively. These tables reveal a low bias in the estimation of
and
for all scenarios. The empirical RMSE is also low and quickly tends to zero as the sample size increases. Higher values of bias and RMSE are observed as the quantiles are distant from
, either from the left or right. Still, for all scenarios, the CP tends to the nominal confidence coefficient as the sample size increases. In summary, the simulations reveal that the UBS quantitative regression model has its parameters well estimated according to the metrics considered and can be an alternative to other models available in the literature.
5. Empirical Application with Data from Political Sciences
In this and the following section, for illustrative purposes, we apply the UBS quantile regression model in the analysis of two real data sets. In addition to the UBS model, we also consider quantile regression models based on the KUMA, LEEG, UBUR, UCHE, UHN, unit logistic (ULOG) and UWEI, distributions. The PDF, CDF and QF for these distributions are presented in
Appendix A.
The objective of these sections is not to present all numerous approaches to variable selection, regression diagnostics, link function selection or parameter interpretation, but rather suggest the use of the UBS quantile regression as an alternative to other models available in the literature.
In this first application, the response variable indicates the proportion of voters in the 2014 Brazil presidential election, received by the elected president, Dilma Rousseff, in 74 municipalities of the state of Sergipe. This state is located in the Northeast Region of Brazil and is formed by 75 municipalities. The data set is available in the library
baquantreg [
53] from
R and was considered the human development index (HDI) in 2010 as covariate. We call this set “vote data” and assume the regression structure for
formulated as
, for
.
Table 7 reports the ML estimates and SEs for the indicated models. Note the difference between the estimates of
and
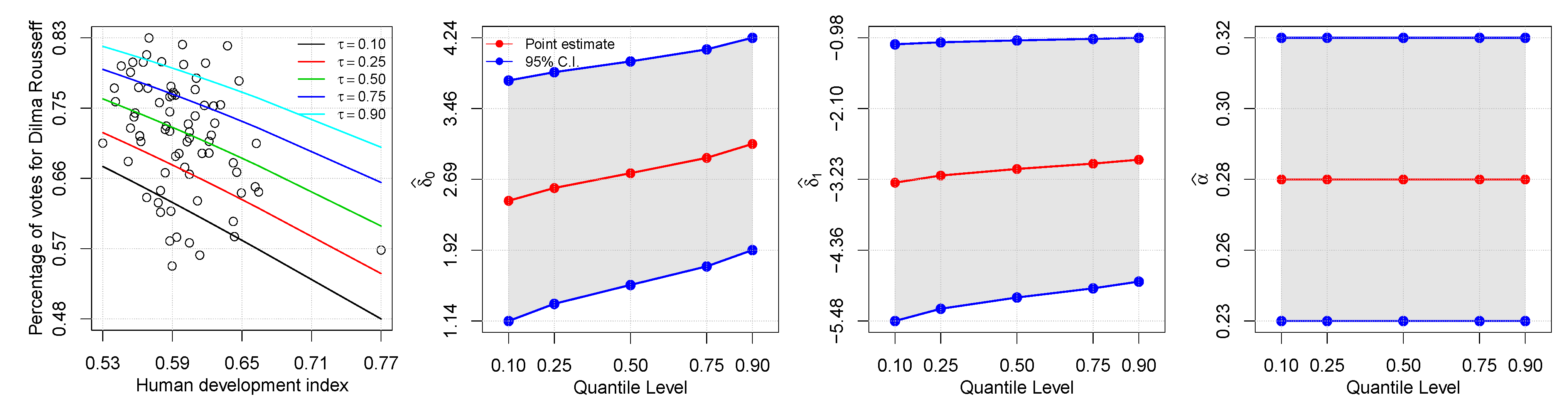
in the models. The rate of change in the conditional quantile, expressed by the estimated regression coefficients, is illustrated in
Figure 3. Observe how the rate of change in the proportion of votes depends on the quantile. As also shown in
Figure 3, the first plot on the left, a higher HDI indicates less proportion of votes received by the elected president.
ML estimates for the UBS model parameters can be obtained from the unitBSQuantReg package using the instructions:
install.packages(‘‘remotes’’)
remotes::install_github(‘‘AndrMenezes/unitBSQuantReg’’)
library(unitBSQuantReg)
data(BrazilElection2014, package = ‘‘baquantreg’’)
ind <- which(BrazilElection2014$UF_name == ‘‘SE’’)
data.se <- BrazilElection2014[ind, c(‘‘percVotes", ‘‘HDI’’)]
taus <- c(0.10, 0.25, 0.50, 0.75, 0.90)
fits <- lapply(taus, function(TAU)
unitBSQuantReg(percVotes ~ HDI, data = data.se, tau = TAU))
lapply(fits, coef)
For the other models, the ML estimates were obtained from the unitquantreg package, which is under development.
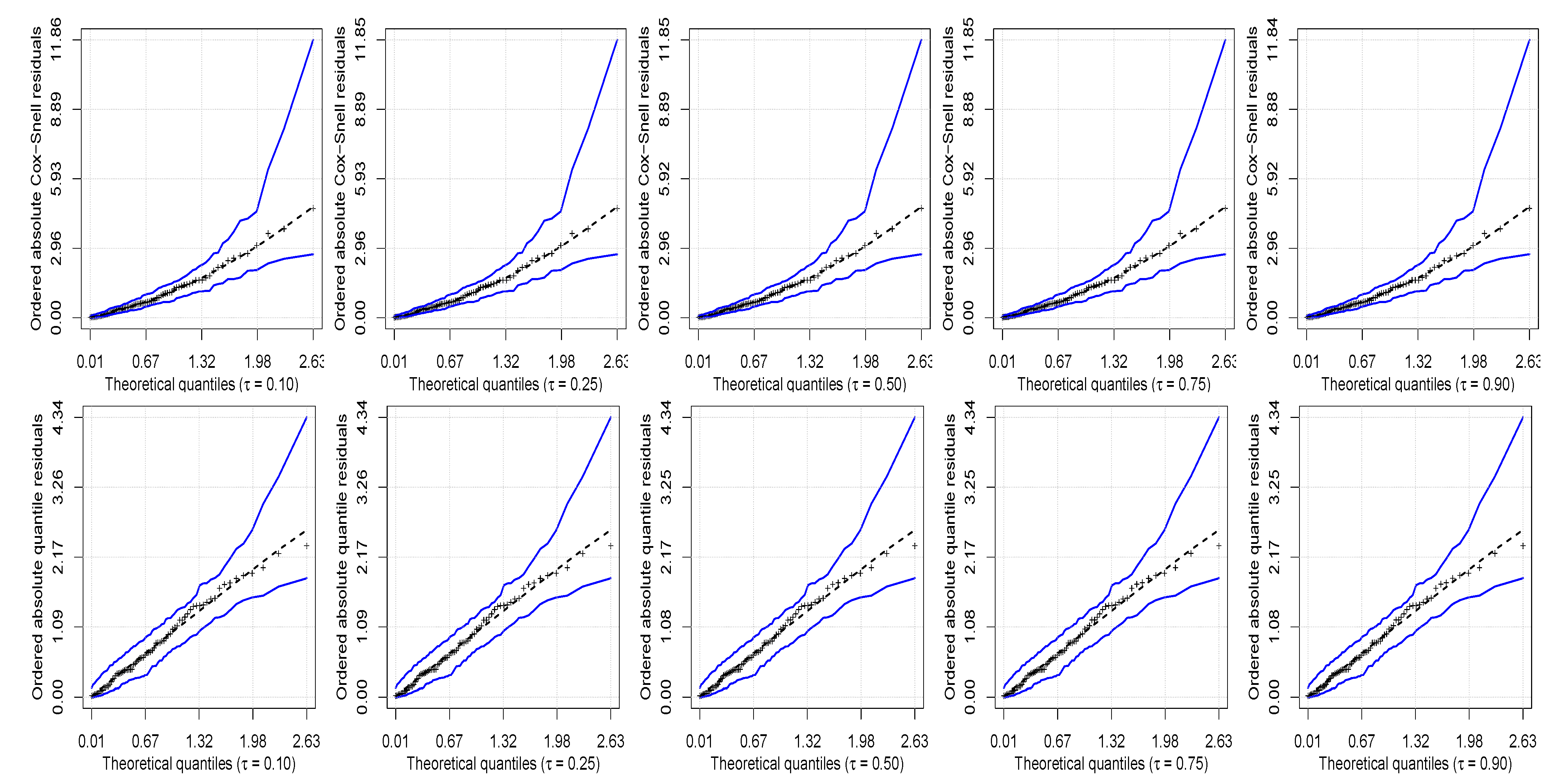
Table 8 presents the values of the Akaike information criterion used to compare various competing models. These values indicate that the UBS quantile regression model is the best one. This better performance, of course, is not a rule and depends on the data under analysis, but this fact highlights the importance of our new proposal for such data. In order to assess the goodness of fit of the UBS quantile regression model to the vote data, in
Figure 4 are shown the half-normal plots with simulated envelopes for the Cox–Snell and randomized quantile residuals. These figures indicate a good fit of the UBS quantile regression model to the
-th proportion of votes, for
.
6. Empirical Application with Data from Sports Medicine
In this second application, we consider a data set taken from [
54], also available at
http://www.leg.ufpr.br/doku.php/publications:papercompanions:multquasibeta (accessed on 9 April 2021). These data are related to the body fat percentage, which was measured at five regions: android, arms, gynoid, legs, and trunk. The fat percentages at android, arms, gynoid, legs, and trunk correspond to the five response variables considered in the original study where these data were collected. The data set contains 298 observations and the covariates are: age (in years), body mass index (in kg/m
), gender (female or male) and IPAQ (sedentary (S), insufficiently active (I), or active (A)). As described in [
55], the IPAQ is a questionnaire that allows the estimation of weekly time spent on physical activities of moderate and strong intensity, in different contexts of daily life, such as: housework, leisure, transportation, and work, as well as the time spent in passive activities performed on the seating position.
We analyze the response variable body fat percentage at arms. We call this set as “arm data”. The results of the analyses for the other four responses are available under request from the authors. For the response variable analyzed here, we assume is given by , for , where : age; : body mass index; : 0 for female, 1 for male; : 0 for IPAQ = S, 1 for IPAQ = I; and : 0 for IPAQ = S, 1 for IPAQ = A.
Table 9 reports the ML estimates and SEs for the indicated models. Note the difference between the estimates of
, for
, in the models. The rate of change in the conditional quantile, expressed by the estimated regression coefficients, is illustrated in
Figure 5. Note how the rate of change in body fat percentage at arms depends on the quantile.
Table 10 presents the values of the Akaike information criterion used to compare various models. These values indicate that the UBS quantile regression model is the best one. In order to assess if this model fits the data well, in
Figure 6 are shown the half-normal plots with simulated envelopes for the residuals. This figure displays a good fit of the UBS quantile regression model to the
-th percentage of body fat at arms, for
.
7. Conclusions, Limitations and Future Investigation
Although the quantile regression methodology appeared in 1978 [
34], few works consider it from a strictly parametric point of view. Some of these recently published works used distributions for responses restricted to the zero-one interval.
In this paper, we extended the unit Birnbaum–Saunders distribution by parameterizing its scale parameter in terms of a quantile that can depend on covariates. This extension employed a quantile parameterization that permitted us to state a setting mimicking the generalized linear models, giving wide flexibility in the formulation.
We estimated the model parameter with the maximum likelihood method and used Cox–Snell and randomized quantile residuals to assess the adequacy of our formulation to the data, as well as the Akaike information criterion for model selection.
We conducted a Monte Carlo simulation study to empirically evaluate the statistical performance of the maximum likelihood estimators of the unit Birnbaum–Saunders quantile regression parameters. We also studied coverage probabilities of the confidence intervals of the corresponding parameters based on the asymptotic normality of these estimators. This simulation study reported the good statistical performance of such estimators.
Two data analyses were conducted related to political sciences and sports medicine with seven competing models to the unit Birnbaum–Saunders quantile regression. Both of these analyses reported a suitable performance of the new regression quantile model and superior to all of the competing models, giving evidence that the unit Birnbaum–Saunders distribution is an excellent alternative for quantile modeling and for dealing with bounded data into the unit interval. Such results reported that the unit Birnbaum–Saunders quantile regression model may be a new setting for analyzing this type of data. The new approach may be a good addition to the tools of statisticians and diverse practitioners interested in the modeling of quantiles.
A limitation of our approach is that the explanatory variables may condition quantiles and also the shape parameter. Thus, the effect of this parameter is a topic to be studied in a future work based on the line presented in [
56,
57] when jointly modeling two parameters. Other topics of future research are related to studying how multivariate, spatial, temporal structures could be added into the quantile regression framework [
58,
59,
60,
61]. In addition, Tobit and Cobb-Douglas type frameworks may be analyzed in the thematic of this investigation [
62,
63]. Moreover, censored observation might be studied in the present context [
64].
The authors are working on these and other issues associated with the present investigation and the corresponding findings are expected to be reported in future works.
Author Contributions
Data curation, J.M., B.A., A.F.B.M.; formal analysis, J.M., A.F.B.M., V.L.; investigation, J.M., B.A., A.F.B.M., V.L.; methodology, J.M., B.A., A.F.B.M., V.L.; writing—original draft, J.M., B.A., A.F.B.M.; writing—review and editing, J.M., V.L. All authors have read and agreed to the published version of the manuscript.
Funding
Josmar Mazucheli gratefully acknowledges the partial financial support from Fundação Araucária (Grant 064/2019-UEM/Fundação Araucária), Brazil. The research of Víctor Leiva was partially supported by grant FONDECYT 1200525 from the National Agency for Research and Development (ANID) of the Chilean government under the Ministry of Science, Technology, Knowledge and Innovation.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would also like to thank the Editors and Reviewers for their constructive comments which led to improve the presentation of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Other Distributions for Quantile Regression
• The KUMA distribution [
65] is obtained from the transformation
, where
denotes an exponentiated-exponential distributed random variable. The corresponding PDF, CDF and QF are written, respectively, as
From (
A1), the parameter
can be expressed as
• The LEEG distribution [
28] is generated from the transformation
, where
denotes an extended exponential-geometric distributed random variable. The corresponding PDF, CDF and QF are stated, respectively, as
From (
A2), the parameter
can be expressed as
.
• The UBUR distribution [
33] is reached from the transformation
, where
denotes a Burr XII distributed random variable. The corresponding PDF, CDF and QF are given, respectively, by
From (
A3), the parameter
can be expressed as
• The UCHE distribution [
31] is get from the transformation
, where
denotes a Chen distributed random variable. The corresponding PDF, CDF and QF are expressed, respectively, as
From (
A4), the parameter
can be stated as
• The UHN distribution [
32] is obtained from the transformation
, where
denotes a half-normal distributed random variable. The corresponding PDF, CDF and QF are formulated, respectively, as
where
is the PDF of the standard normal distribution. From (
A5), the parameter
can be expressed as
• The ULOG distribution [
29] is get from the transformation
, where
denotes a logistic distributed random variable. The corresponding PDF, CDF and QF are established, respectively, by
From (
A6), the parameter
can be expressed as
• The UWEI distribution [
8] is generated from the transformation
, where
denotes a Weibull distributed random variable. The corresponding PDF, CDF and QF are written, respectively, as
From (
A7) the parameter
can be expressed as
References
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit Birnbaum-Saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Mousa, A.M.; El-Sheikh, A.A.; Abdel-Fattah, M.A. A gamma regression for bounded continuous variables. Adv. Appl. Stat. 2016, 49, 305–326. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.; Alqallaf, F. The unit inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Mazucheli, J.; Bapat, S.R.; Menezes, A.F.B. A new one-parameter unit Lindley distribution. Chil. J. Stat. 2019, 11, 53–67. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Menezes, A.F.B.; Mazucheli, J.; Bourguignon, M. A parametric quantile regression approach for modelling zero-or-one inflated double bounded data. Biometr. J. 2021, 63, 841–858. [Google Scholar] [CrossRef] [PubMed]
- Figueroa-Zuniga, J.I.; Niklitschek, S.; Leiva, V.; Liu, S. Modeling heavy-tailed bounded data by the trapezoidal beta distribution with applications. Revstat 2021, in press. [Google Scholar]
- Kieschnick, R.; McCullough, B.D. Regression analysis of variates observed on (0, 1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef]
- Smithson, M.; Verkuilen, J. A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychol. Methods 2006, 11, 54–71. [Google Scholar] [CrossRef]
- Altun, E.; El-Morshedy, M.; Eliwa, M.S. A new regression model for bounded response variable: An alternative to the beta and unit Lindley regression models. PLoS ONE 2021, 16, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Jodrá, P. A bounded distribution derived from the shifted Gompertz law. J. King Saud Univ. Sci. 2020, 32, 523–536. [Google Scholar] [CrossRef]
- Ferrari, S.; Cribari Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Bayes, C.L.; Bazán, J.L.; García, C. A new robust regression model for proportions. Bayesian Anal. 2012, 7, 841–866. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sordo, M.A.; Calderín-Ojeda, E. The log-Lindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 2014, 54, 49–57. [Google Scholar] [CrossRef]
- Altun, E. The log-weighted exponential regression model: Alternative to the beta regression model. Commun. Stat. Theory Methods 2019, 1–16. [Google Scholar] [CrossRef]
- Bonat, W.H.; Petterle, R.R.; Hinde, J.; Demétrio, C.G.B. Flexible quasi-beta regression models for continuous bounded data. Stat. Model. 2019, 19, 617–633. [Google Scholar] [CrossRef]
- Song, P.X.K.; Tan, M. Marginal models for longitudinal continuous proportional data. Biometrics 2000, 56, 496–502. [Google Scholar] [CrossRef]
- Altun, E.; Cordeiro, G.M. The unit improved second-degree Lindley distribution: Inference and regression modeling. Comput. Stat. 2020, 35, 259–279. [Google Scholar] [CrossRef]
- Zhou, H.; Huang, X.; For the Alzheimer’s Disease Neuroimaging Initiative. Parametric mode regression for bounded responses. Biometr. J. 2020, 62, 1791–1809. [Google Scholar] [CrossRef] [PubMed]
- Menezes, A.F.B.; Mazucheli, J.; Chakraborty, S. A collection of parametric modal regression models for bounded data. J. Biopharm. Stat. 2021, accepted. [Google Scholar]
- Chahuan-Jimenez, K.; Rubilar, R.; de la Fuente-Mella, H.; Leiva, V. Breakpoint analysis for the COVID-19 pandemic and its effect on the stock markets. Entropy 2021, 32, 100. [Google Scholar] [CrossRef] [PubMed]
- Korkmaz, M.Ç.; Chesneau, C.; Korkmaz, Z.S. On the arcsecant hyperbolic normal distribution. Properties, quantile regression modeling and applications. Symmetry 2021, 13, 117. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Moreno-Arenas, G. On a heavy-tailed parametric quantile regression model for limited range response variables. Comput. Stat. 2020, 35, 379–398. [Google Scholar] [CrossRef]
- Mitnik, P.A.; Baek, S. The Kumaraswamy distribution: Median-dispersion re-parameterizations for regression modeling and simulation-based estimation. Stat. Pap. 2013, 54, 177–192. [Google Scholar] [CrossRef]
- Jodrá, P.; Jiménez-Gamero, M.D. A quantile regression model for bounded responses based on the exponential-geometric distribution. Revstat 2020, 4, 415–436. [Google Scholar]
- Paz, R.F.; Balakrishnan, N.; Bazán, J.L. L-logistic regression models: Prior sensitivity analysis, robustness to outliers and applications. Braz. J. Prob. Stat. 2019, 33, 455–479. [Google Scholar]
- Cancho, V.G.; Bazán, J.L.; Dey, D.K. A new class of regression for a bounded response with application in the incidence rate of colorectal cancer. Stat. Methods Med. Res. 2020, 29, 2015–2033. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Emrah, A.; Chesneau, C.; Yousof, H.M. On the unit Chen distribution with associated quantile regression and applications. Int. J. Environ. Res. Public Health 2019, 16, 2748. [Google Scholar]
- Bakouch, H.S.; Nik, A.S.; Asgharzadeh, A.; Salinas, H.S. A flexible probability model for proportion data: Unit-half-normal distribution. Commun. Stat. Case Stud. Data Anal. Appl. 2021, in press. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 1–29. [Google Scholar] [CrossRef]
- Koenker, R.; Basset, G. Regression Quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Prob. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Gupta, R.C.; Kundu, D.; Leiva, V.; Sanhueza, A. On some mixture models based on the Birnbaum-Saunders distribution and associated inference. J. Stat. Plan. Inference 2011, 141, 2175–2190. [Google Scholar] [CrossRef]
- Patriota, A.G. On scale mixture Birnbaum-Saunders distributions. J. Stat. Plan. Inference 2012, 142, 2221–2226. [Google Scholar] [CrossRef]
- Lemonte, A.J. A note on the Fisher information matrix of the Birnbaum-Saunders distribution. J. Stat. Theory Appl. 2016, 15, 196–205. [Google Scholar]
- Kundu, D.; Kannan, N.; Balakrishnan, N. On the hazard function of Birnbaum-Saunders distribution and associated inference. Comput. Stat. Data Anal. 2008, 52, 2692–2702. [Google Scholar] [CrossRef]
- Rieck, J.R.; Nedelman, J.R. A log-linear model for the Birnbaum-Saunders distribution. Technometrics 1991, 33, 51–60. [Google Scholar]
- Lemonte, A.J. A log-Birnbaum-Saunders regression model with asymmetric errors. J. Stat. Comput. Simul. 2012, 82, 1775–1787. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Appl. Stochastic Models Bus. Ind. 2021, 37, 53–73. [Google Scholar] [CrossRef]
- Leiva, V.; Sanchez, L.; Galea, M.; Saulo, H. Global and local diagnostic analytics for a geostatistical model based on a new approach to quantile regression. Stoch. Environ. Res. Risk Assess. 2020, 34, 1457–1471. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum–Saunders quantile regression models with application to spatial data. Mathematics 2021, 8, 1000. [Google Scholar] [CrossRef]
- Saulo, H.; Dasilva, A.; Leiva, V.; Sanchez, L.; de la Fuente-Mella, H. Log-symmetric quantile regression models. Stat. Neerlandica 2021, in press. [Google Scholar] [CrossRef]
- Koenker, R.; Machado, J.A.F. Goodness of fit and related inference processes for quantile regression. J. Am. Stat. Assoc. 1999, 94, 1296–1310. [Google Scholar] [CrossRef]
- Bayes, C.L.; Bazán, J.L.; Castro, M. A quantile parametric mixed regression model for bounded response variables. Stat. Interface 2017, 10, 483–493. [Google Scholar] [CrossRef]
- Rodrigues, J.; Bazán, J.L.; Suzuki, A.K. A flexible procedure for formulating probability distributions on the unit interval with applications. Commun. Stat. Theory Methods 2020, 49, 738–754. [Google Scholar] [CrossRef]
- Smithson, M.; Shou, Y. CDF-quantile distributions for modelling random variables on the unit interval. Br. J. Math. Stat. Psychol. 2017, 70, 412–438. [Google Scholar] [CrossRef]
- Noufaily, A.; Jones, M.C. Parametric quantile regression based on the generalized gamma distribution. J. R. Stat. C 2013, 62, 723–740. [Google Scholar] [CrossRef]
- Gallardo, D.I.; Gómez-Déniz, E.; Gómez, H.W. Discrete generalized half normal distribution with applications in quantile regression. SORT 2020, 44, 265–284. [Google Scholar]
- Lindsay, B.G.; Li, B. On second-order optimality of the observed Fisher information. Ann. Stat. 1997, 25, 2172–2199. [Google Scholar] [CrossRef]
- Santos, B. Baquantreg: Bayesian Quantile Regression Methods. R Package Version 0.1. 2015. Available online: https://rdrr.io/github/brsantos/baquantreg/ (accessed on 9 April 2021).
- Petterle, R.R.; Bonat, W.H.; Scarpin, C.T.; Jonasson, T.; Borba, V.Z.C. Multivariate quasi–beta regression models for continuous bounded data. Int. J. Biostat. 2020, 1, 1–15. [Google Scholar] [CrossRef]
- Benedetti, T.R.B.; Antunes, P.C.; Rodriguez–Añez, C.R.; Mazo, G.Z.; Petroski, E.L. Reproducibility and validity of the International Physical Activity Questionnaire (IPAQ) in elderly men. Rev. Bras. Med. Esporte 2007, 13, 11–16. [Google Scholar] [CrossRef]
- Santos-Neto, M.; Cysneiros, F.J.A.; Leiva, V.; Barros, M. Reparameterized Birnbaum–Saunders regression models with varying precision. Electronic J. Stat. 2016, 10, 2825–2855. [Google Scholar] [CrossRef]
- Ventura, M.; Saulo, H.; Leiva, V.; Monsueto, S. Log-symmetric regression models: Information criteria, application to movie business and industry data with economic implications. Appl. Stoch. Models Bus. Ind. 2019, 35, 963–977. [Google Scholar] [CrossRef]
- Aykroyd, R.G.; Leiva, V.; Marchant, C. Multivariate Birnbaum–Saunders distributions: Modelling and applications. Risks 2018, 6, 21. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Uribe-Opazo, M.A.; Leiva, V.; Aykroyd, R.G. Birnbaum–Saunders spatial modelling and diagnostics applied to agricultural engineering data. Stochastic Environ. Res. Risk Assess. 2017, 31, 105–124. [Google Scholar] [CrossRef]
- Leiva, V.; Saulo, H.; Souza, R.; Aykroyd, R.G.; Vila, R. A new BISARMA time series model for forecasting mortality using weather and particulate matter data. J. Forecast. 2021, 40, 346–364. [Google Scholar] [CrossRef]
- Giraldo, R.; Herrera, L.; Leiva, V. Cokriging prediction using as secondary variable a functional random field with application in environmental pollution. Mathematics 2020, 8, 1305. [Google Scholar] [CrossRef]
- de la Fuente-Mella, H.; Rojas Fuentes, J.L.; Leiva, V. Econometric modeling of productivity and technical efficiency in the Chilean manufacturing industry. Comput. Ind. Eng. 2020, 139, 105793. [Google Scholar] [CrossRef]
- Martinez-Florez, G.; Leiva, V.; Gomez-Deniz, E.; Marchant, C. A family of skew-normal distributions for modeling proportions and rates with zeros/ones excess. Symmetry 2020, 12, 1439. [Google Scholar] [CrossRef]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. A survival model with Birnbaum–Saunders frailty for uncensored and censored cancer data. Braz. J. Probab. Stat. 2018, 32, 707–729. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
Figure 1.
PDFs of the unit UBS distribution for the indicated values of , and .
Figure 1.
PDFs of the unit UBS distribution for the indicated values of , and .
Figure 2.
Behaviors of the mean, variance, coefficient of skewness and coefficient of kurtosis for the indicated values of and in function of .
Figure 2.
Behaviors of the mean, variance, coefficient of skewness and coefficient of kurtosis for the indicated values of and in function of .
Figure 3.
Quantile regression fit plot (left) and estimated quantile process plots for (center left), (center right) and (right) with vote data.
Figure 3.
Quantile regression fit plot (left) and estimated quantile process plots for (center left), (center right) and (right) with vote data.
Figure 4.
Half-normal plots with envelopes of Cox–Snell (first row) and randomized quantile (second row) residuals for the indicated quantile level with vote data.
Figure 4.
Half-normal plots with envelopes of Cox–Snell (first row) and randomized quantile (second row) residuals for the indicated quantile level with vote data.
Figure 5.
Estimated quantile process plot for the indicated , with , and (second row right) with arm data.
Figure 5.
Estimated quantile process plot for the indicated , with , and (second row right) with arm data.
Figure 6.
Half-normal plots with envelopes of Cox–Snell (first row) and randomized quantile (second row) residuals for the indicated quantile level with arm data.
Figure 6.
Half-normal plots with envelopes of Cox–Snell (first row) and randomized quantile (second row) residuals for the indicated quantile level with arm data.
Table 1.
Empirical bias, RMSE and CP for the true values , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
Table 1.
Empirical bias, RMSE and CP for the true values , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
| n | Bias | RMSE | CP |
|---|
| | | | | | | | |
|---|
| 0.10 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.25 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.50 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.75 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.90 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
Table 2.
Empirical bias, RMSE and CP for the true values , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
Table 2.
Empirical bias, RMSE and CP for the true values , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
| n | Bias | RMSE | CP |
|---|
| | | | | | | | |
| 0.10 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.25 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.50 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.75 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.90 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
Table 3.
Empirical bias, RMSE and CP for the true values , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
Table 3.
Empirical bias, RMSE and CP for the true values , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
| n | Bias | RMSE | CP |
|---|
| | | | | | | | |
|---|
| 0.10 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.25 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.50 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.75 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
| 0.90 | 20 | | | | | | | | | |
| 50 | | | | | | | | | |
| 100 | | | | | | | | | |
| 200 | | | | | | | | | |
| 300 | | | | | | | | | |
Table 4.
Empirical bias, RMSE and CP for the true values , , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
Table 4.
Empirical bias, RMSE and CP for the true values , , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
| n | Bias | RMSE | CP |
|---|
| | | | | | | | | | | |
|---|
| 0.10 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.25 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.50 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.75 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.90 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
Table 5.
Empirical bias, RMSE and CP for the true values: , , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
Table 5.
Empirical bias, RMSE and CP for the true values: , , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
| n | Bias | RMSE | CP |
|---|
| | | | | | | | | | | |
|---|
| 0.10 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.25 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.50 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.75 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.90 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
Table 6.
Empirical bias, RMSE and CP for the true values , , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
Table 6.
Empirical bias, RMSE and CP for the true values , , and of the indicated quantile level (), sample size (n) and parameter () with simulated data.
| n | Bias | RMSE | CP |
|---|
| | | | | | | | | | | |
|---|
| 0.10 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.25 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.50 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.75 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
| 0.90 | 20 | | | | | | | | | | | | |
| 50 | | | | | | | | | | | | |
| 100 | | | | | | | | | | | | |
| 200 | | | | | | | | | | | | |
| 300 | | | | | | | | | | | | |
Table 7.
ML estimates and SEs of the indicated model, parameter and quantile level () with vote data.
Table 7.
ML estimates and SEs of the indicated model, parameter and quantile level () with vote data.
| Model | Parameter | Estimate | SE |
|---|
| Level | Level |
|---|
| 0.10 | 0.25 | 0.50 | 0.75 | 0.90 | 0.10 | 0.25 | 0.50 | 0.75 | 0.90 |
|---|
| KUMA | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| LEEG | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UBS | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UBURR | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UCHEN | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UHN | | | | | | | | | | | |
| | | | | | | | | | |
| ULOG | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| >UWEI | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
Table 8.
Values of the Akaike information criterion for the indicated model and quantile level () with vote data.
Table 8.
Values of the Akaike information criterion for the indicated model and quantile level () with vote data.
| Model | Level |
|---|
| 0.10 | 0.25 | 0.50 | 0.75 | 0.90 |
|---|
| KUMA | | | | | |
| LEEG | | | | | |
| UBS | | | | | |
| UBUR | | | | | |
| UCHE | | | | | |
| UHN | | | | | |
| ULOG | | | | | |
| UWEI | | | | | |
Table 9.
ML estimates and SEs of the indicated model, parameter and quantile level () with arm data.
Table 9.
ML estimates and SEs of the indicated model, parameter and quantile level () with arm data.
| Model | Parameter | Estimate | SE |
|---|
| Level | Level |
|---|
| 0.10 | 0.25 | 0.50 | 0.75 | 0.90 | 0.10 | 0.25 | 0.50 | 0.75 | 0.90 |
|---|
| KUMA | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| LEEG | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UBS | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UBUR | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UCHEN | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UHN | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| ULOG | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| UWEI | | | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
Table 10.
Values of the Akaike information criterion for the indicated model and quantile level () with arm data.
Table 10.
Values of the Akaike information criterion for the indicated model and quantile level () with arm data.
| Model | Level |
|---|
| 0.10 | 0.25 | 0.50 | 0.75 | 0.90 |
|---|
| KUMA | | | | | |
| LEEG | | | | | |
| UBS | | | | | |
| UBUR | | | | | |
| UCHEN | | | | | |
| UHN | | | | | |
| ULOG | | | | | |
| UWEI | | | | | |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}