
Extractive Summarization Based on Dynamic Memory Network


Abstract
1. Introduction
- We propose an extractive summarization model that achieves the comparable result against other baselines.
- We propose a simple and effective sentence label method used in the extractive summarization problem.
- We incorporate the positional encoding to a dynamic memory network.
- We propose to use a dynamic memory network method for extractive summarization.
2. Materials and Methods
2.1. Problem Formulation
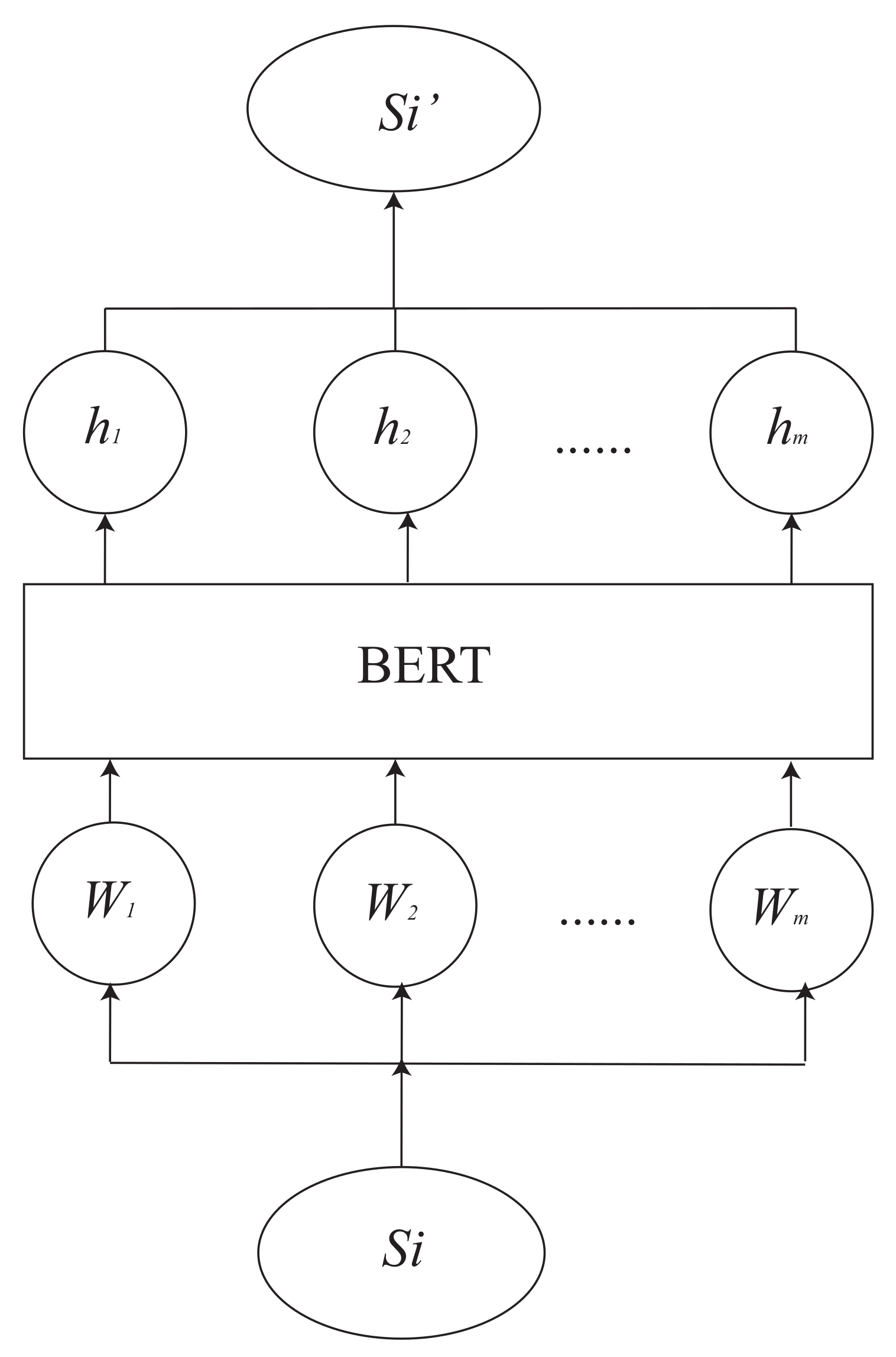
2.2. Extractive Summarization Based on Bert
2.2.1. Sentence Encoder
2.2.2. Label Training Set
2.2.3. Sentence Extractor
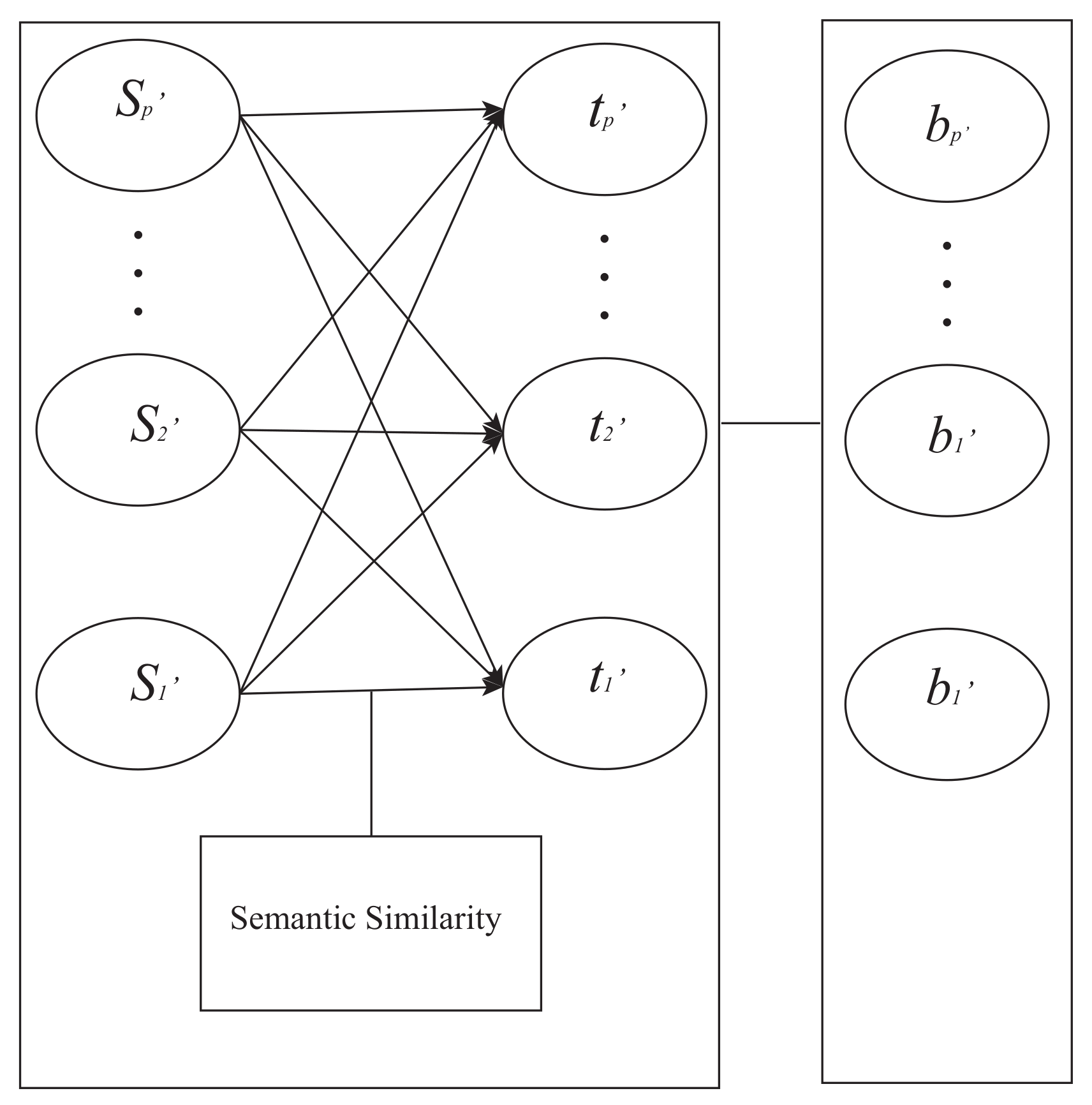
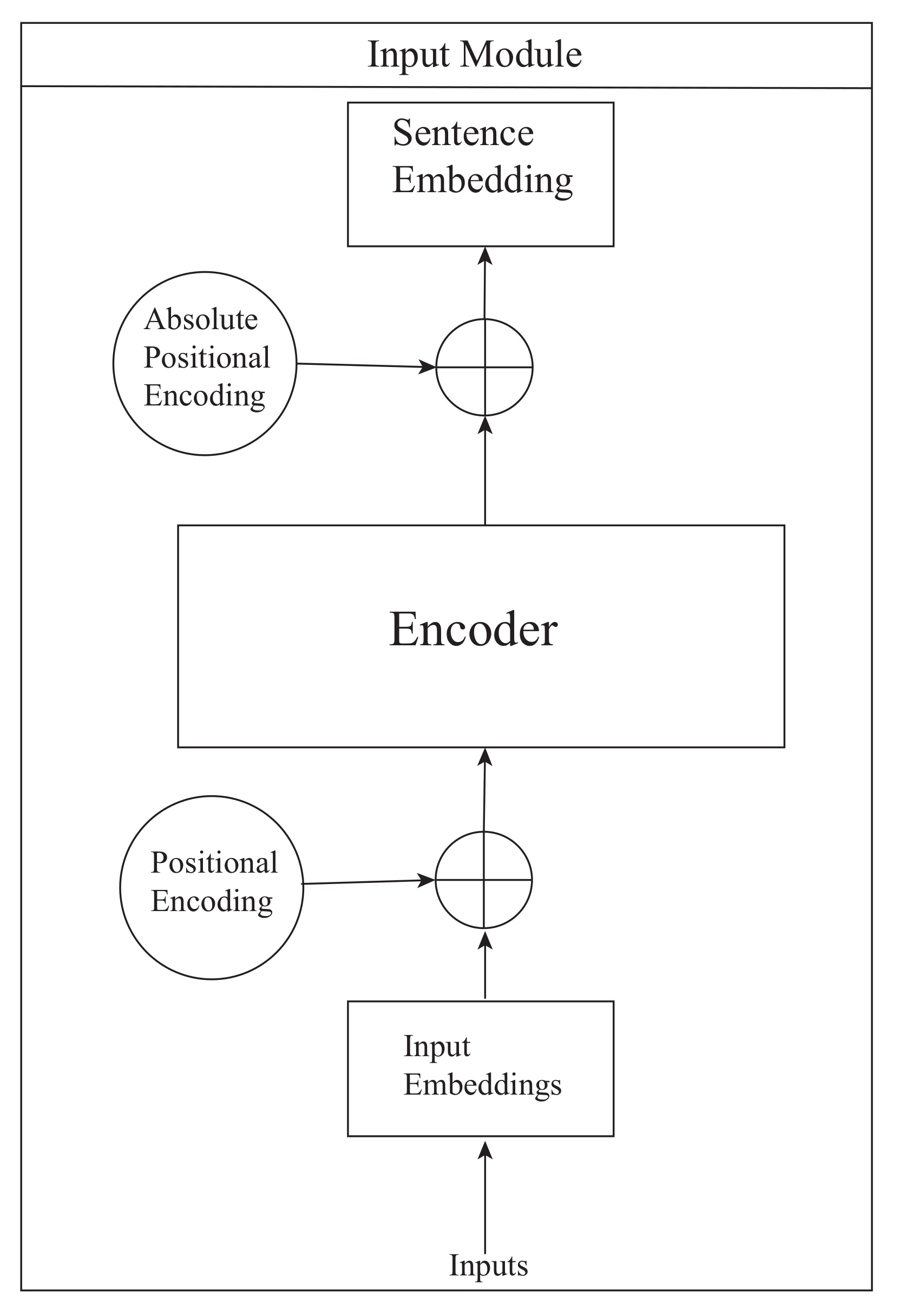
2.3. Extractive Summarization Based on the Dynamic Memory Network
Dynamic Memory Network
3. Experimental Setup
3.1. Datasets
3.2. Baselines
- (1)
- Leading three sentences (Lead-3). This method constructs the summary by extracting the first three sentences of the document. We have given our lead-3 result and the Lead3 result of [23].
- (2)
- Cheng and Lapata [15]. Cheng and Lapata propose an extractive model which consist of the hierarchical document encoder and an attention-based extractor.
- (3)
- SummaRuNNer [8]. This model is based on a recurrent neural network.
- (4)
- REFRESH [11]. Narayan makes the extractive summarization task as a sentence ranking task and optimizes the rouge metrics through the reinforcement learning object.
- (5)
- NEUSUM [27]. This model makes the sentence scoring and sentence selection to an end-to-end neural network framework.
- (6)
- BANDITSUM [28]. In the field of text summarization, many methods have been proposed with reinforcement learning. In this model, a policy gradient reinforcement learning algorithm is used to train to select the summarization sentences.
3.3. Implementation Details
3.4. Evaluation
4. Results
4.1. Results on CNN/Daily Mail
4.2. Results on WikiHow and XSum
5. Analysis
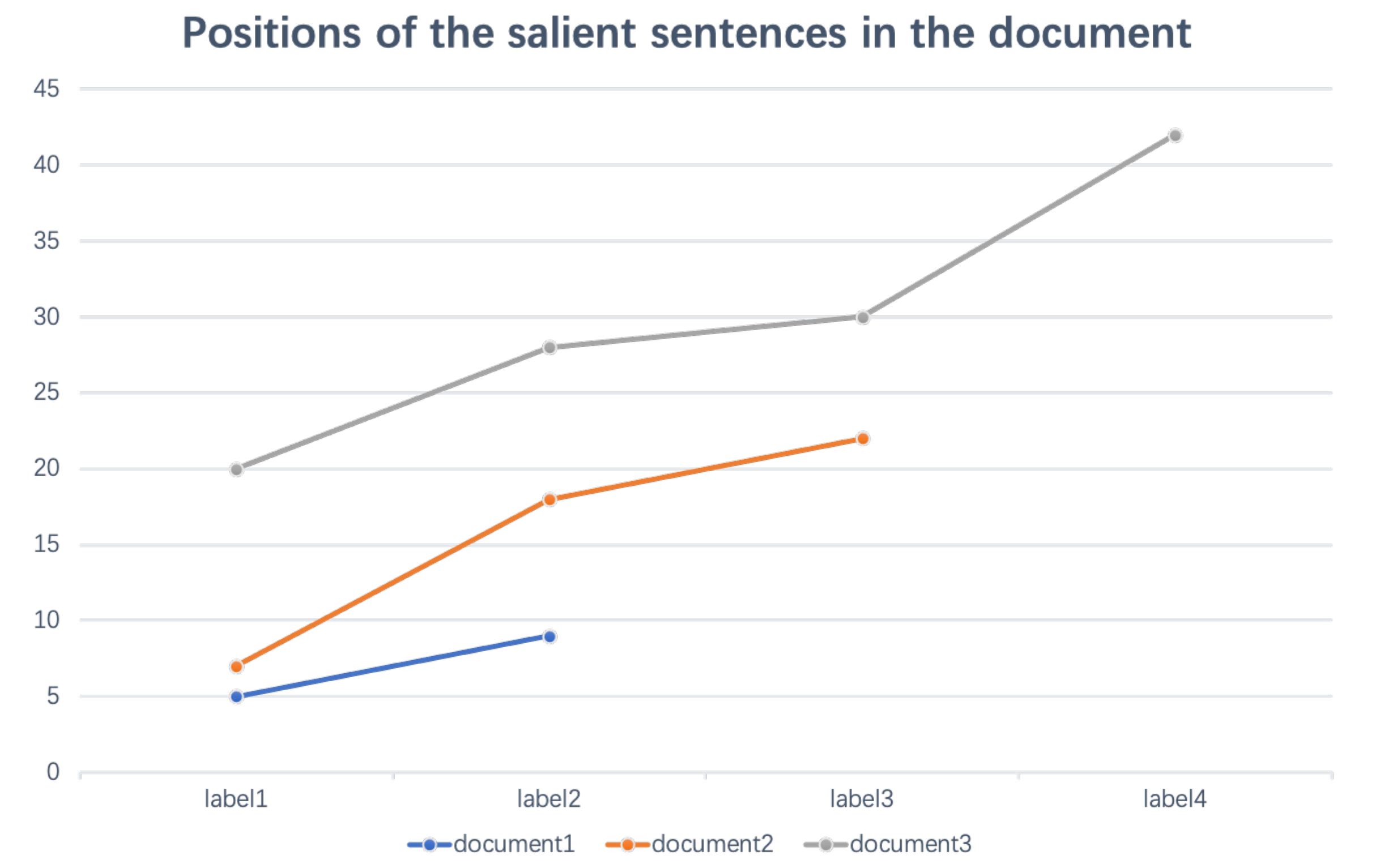
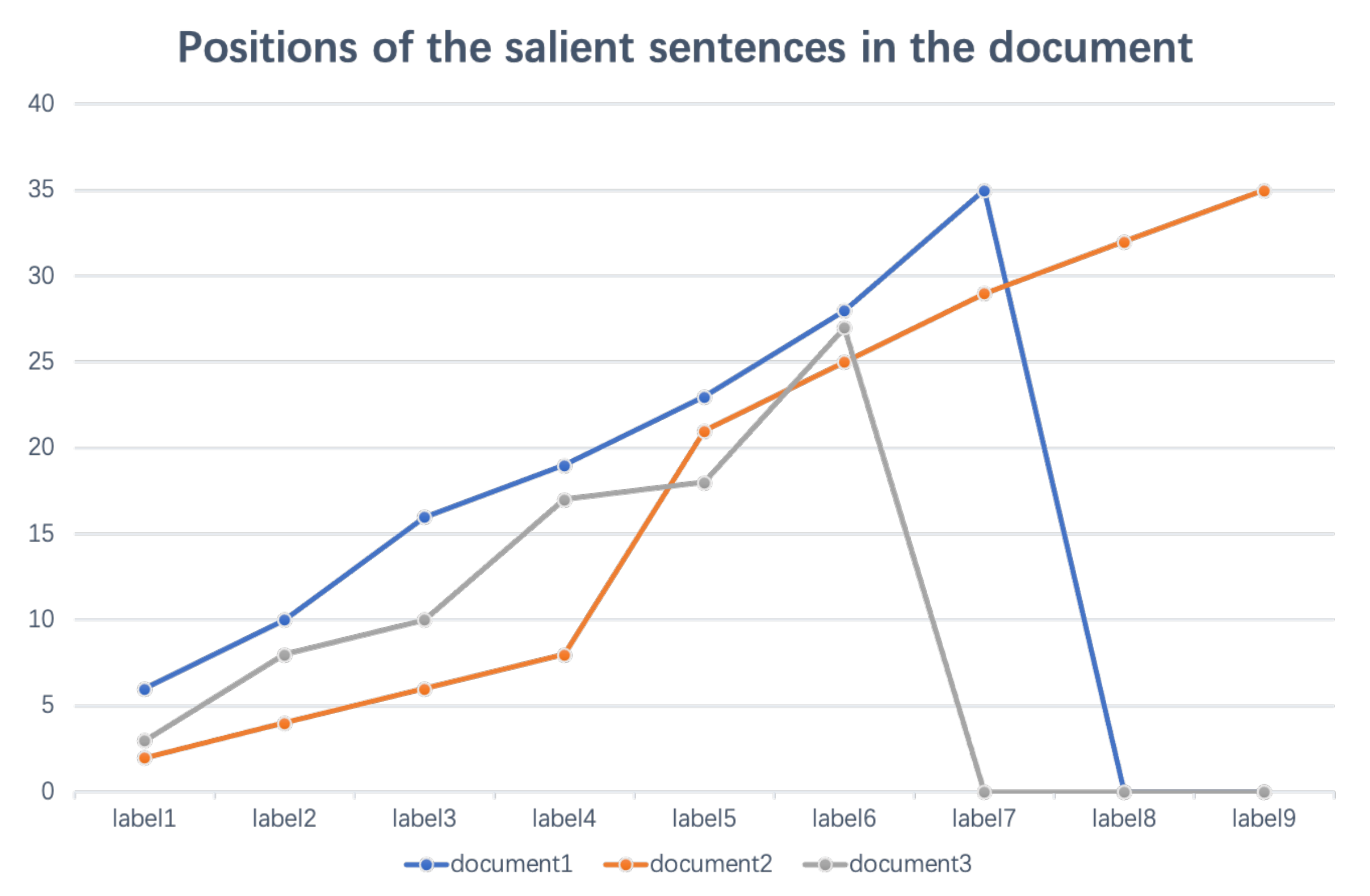
- (1)
- Where are the salient sentences in the document?
- (2)
- Why is our method effective compared with other methods?
6. Related Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Edmundson, H.P. New Methods in Automatic Extracting. J. ACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Lin, C.Y.; Hovy, E. Identifying Topics by Position. In Proceedings of the Fifth Conference on Applied Natural Language Processing, Washington, DC, USA, 31 March–3 April 1997; Association for Computational Linguistics: Stroudsburg, PA, USA, 1997; pp. 283–290. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Cao, Z.; Li, W.; Li, S.; Wei, F.; Li, Y. AttSum: Joint Learning of Focusing and Summarization with Neural Attention. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 547–556. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhai, F.; Zhou, B. SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3075–3081. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Huang, S.; Zhou, M.; Zhao, T. Neural Document Summarization by Jointly Learning to Score and Select Sentences. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, (Volume 1: Long Papers). Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 654–663. [Google Scholar]
- Carbonell, J.; Goldstein, J. The Use of MMR, Diversity-based Reranking for Reordering Documents and Producing Summaries. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; ACM: New York, NY, USA, 1998; pp. 335–336. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking Sentences for Extractive Summarization with Reinforcement Learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). New Orleans, Louisiana, 1–6 June2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1747–1759. [Google Scholar] [CrossRef]
- ColloBert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Cheng, J.; Lapata, M. Neural Summarization by Extracting Sentences and Words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, (Volume 1: Long Papers). Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 484–494. [Google Scholar] [CrossRef]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1693–1701. [Google Scholar]
- Kumar, A.; Irsoy, O.; Ondruska, P.; Iyyer, M.; Bradbury, J.; Gulrajani, I.; Zhong, V.; Paulus, R.; Socher, R. Ask me anything: Dynamic memory networks for natural language processing. In Proceedings of the 33rd International Conference on Machine Learning, New York, USA, 19–24 June 2016; pp. 1378–1387. [Google Scholar]
- Xiong, C.; Merity, S.; Socher, R. Dynamic memory networks for visual and textual question answering. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2397–2406. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhou, B.; dos Santos, C.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 280–290. [Google Scholar] [CrossRef]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, (Volume 1: Long Papers). Vancouver, Canada, July 30–August 4 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1073–1083. [Google Scholar] [CrossRef]
- Gehrmann, S.; Deng, Y.; Rush, A. Bottom-Up Abstractive Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 4098–4109. [Google Scholar]
- Koupaee, M.; Wang, W.Y. WikiHow: A Large Scale Text Summarization Dataset. arXiv 2018, arXiv:1810.09305. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1797–1807. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Huang, S.; Zhou, M.; Zhao, T. Neural Document Summarization by Jointly Learning to Score and Select Sentences. arXiv 2018, arXiv:1807.02305. [Google Scholar]
- Dong, Y.; Shen, Y.; Crawford, E.; van Hoof, H.; Cheung, J.C.K. BanditSum: Extractive Summarization as a Contextual Bandit. In Proceedings of the EMNLP 2018: 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3739–3748. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Montague, P. Reinforcement Learning: An Introduction, by Sutton, R.S. and Barto, A.G. Trends Cogn. Sci. 1999, 3, 360. [Google Scholar] [CrossRef]
- Zhang, X.; Wei, F.; Zhou, M. HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Florence, Italy, 2019; pp. 5059–5069. [Google Scholar] [CrossRef]
- Zhong, M.; Liu, P.; Wang, D.; Qiu, X.; Huang, X. Searching for Effective Neural Extractive Summarization: What Works and What’s Next. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1049–1058. [Google Scholar] [CrossRef]
- Bae, S.; Kim, T.; Kim, J.; Lee, S.G. Summary Level Training of Sentence Rewriting for Abstractive Summarization. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 10–20. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3730–3740. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| SDMN + BiGRU + pe | 36.69 | 15.53 | 33.14 |
| SDMN + BiLSTM + pe | 40.24 | 17.53 | 36.49 |
| SDMN + trans + pe | 40.2 | 17.5 | 36.48 |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| LEAD3 (ours) | 39.89 | 17.24 | 36.12 |
| LEAD3 (See et al.) | 40.3 | 17.7 | 36.6 |
| SemanticSim | 50.54 | 27.63 | 46.77 |
| Cheng and Lapata | 35.5 | 14.7 | 32.2 |
| SummaRuNNer * | 39.6 | 16.2 | 35.3 |
| REFRESH | 40.0 | 18.2 | 36.6 |
| NEUSUM | 41.59 | 19.01 | 37.98 |
| BANDITSUM | 41.5 | 18.7 | 37.6 |
| SDMNTransPe | 40.2 | 17.5 | 36.48 |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Lead | 24.97 | 5.83 | 23.24 |
| oracle | 35.59 | 12.98 | 32.68 |
| SDMN | 30.23 | 7.58 | 27.34 |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| SDMN (1) | 21.15 | 4.11 | 15.23 |
| SDMN (2) | 22.82 | 4.21 | 16.54 |
| SDMN (all) | 23.51 | 4.35 | 17.43 |
| Doc | Title|First, Sentence|Labeled Sentence |
|---|---|
| doc1 | Spend £3.3 m fund on Wales-based stars, says Gareth Davies |
| doc2 | Alliance Party east Belfast alert was a hoax, PSNI say |
| doc3 | UK energy policy ‘deters investors’ |
| doc1 | New Welsh Rugby Union chairman Gareth Davies believes a joint £3.3 m WRU-regions fund should be used to retain home-based talent |
| such as Liam Williams, not... | |
| doc2 | A suspicious package left outside an Alliance Party office in east Belfast has been declared a hoax |
| doc3 | The UK’s international reputation for a strong and well-balanced energy policy has taken another knock |
| doc1 | 3 m should be spent on ensuring current Wales-based stars remain there |
| doc2 | Condemning the latest hoax, Alliance MLA Chris Lyttle said: “It is a serious incident for the local area, it causes serious disruption, |
| it puts people’s lives at risk, ...” | |
| doc3 | A spokesman for her department, commenting on the WEC report, said: “We’ve made record investments in renewables and are |
| committed to lower-carbon ...” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Yu, J. Extractive Summarization Based on Dynamic Memory Network. Symmetry 2021, 13, 600. https://doi.org/10.3390/sym13040600
Li P, Yu J. Extractive Summarization Based on Dynamic Memory Network. Symmetry. 2021; 13(4):600. https://doi.org/10.3390/sym13040600
Chicago/Turabian StyleLi, Ping, and Jiong Yu. 2021. "Extractive Summarization Based on Dynamic Memory Network" Symmetry 13, no. 4: 600. https://doi.org/10.3390/sym13040600
APA StyleLi, P., & Yu, J. (2021). Extractive Summarization Based on Dynamic Memory Network. Symmetry, 13(4), 600. https://doi.org/10.3390/sym13040600