
An Enhanced Spectral Clustering Algorithm with S-Distance





Abstract
1. Introduction
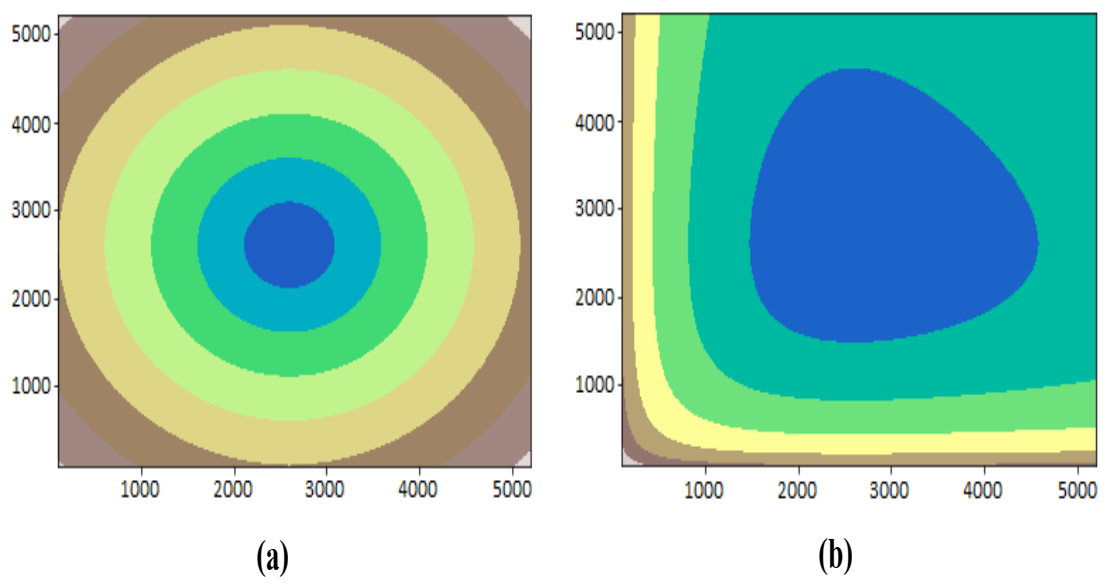
2. S-Distance and Its Properties
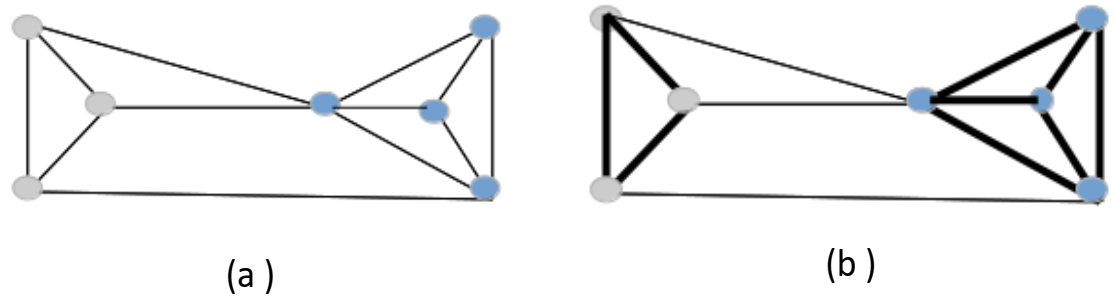
3. Graph Laplacian and Its Properties
- 1.
- We havefor every .
- 2.
- is symmetric and positive semidefinite.
- 3.
- consists of n non-negative and real-valued eigenvalues , where n is the number of points in D.
4. Proposed Spectral Clustering Algorithm and Analysis
| Algorithm 1: The proposed SC algorithm. |
Input: ℵ, , k▹ℵ—a set of points, nearest neighbors for affinity matrix and number of clusters Output: Cluster labels of all the points
|
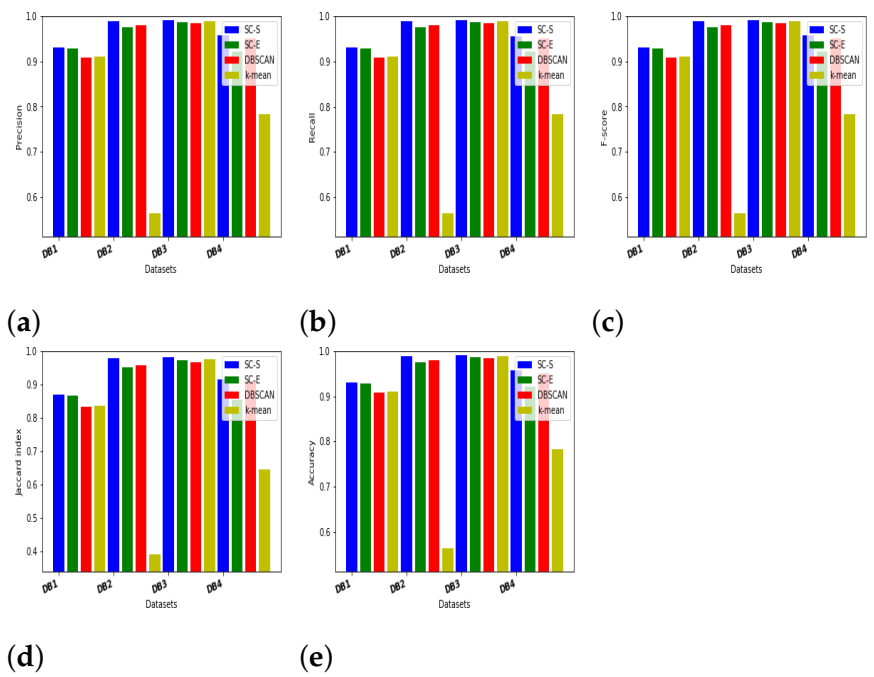
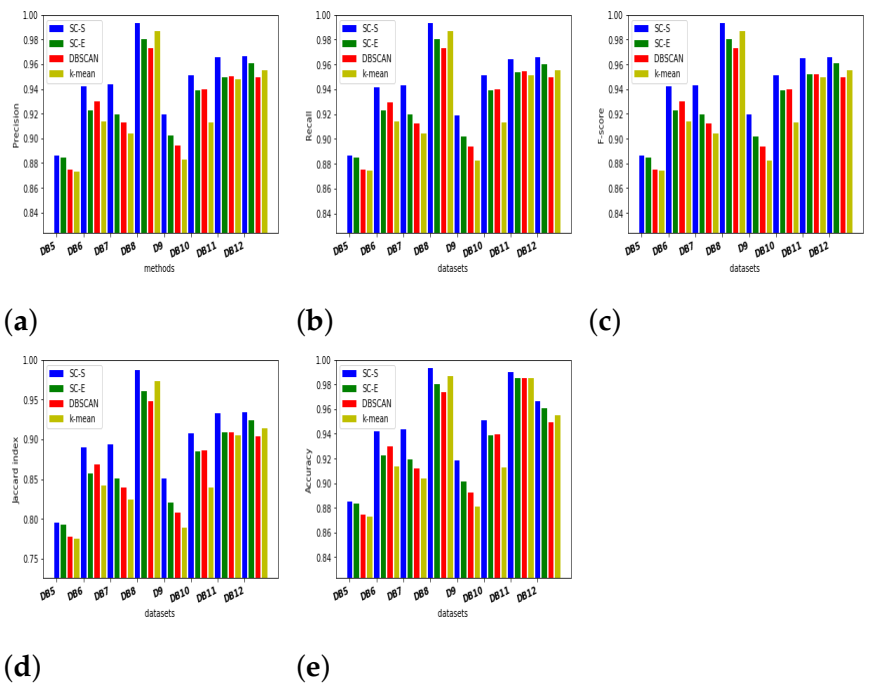
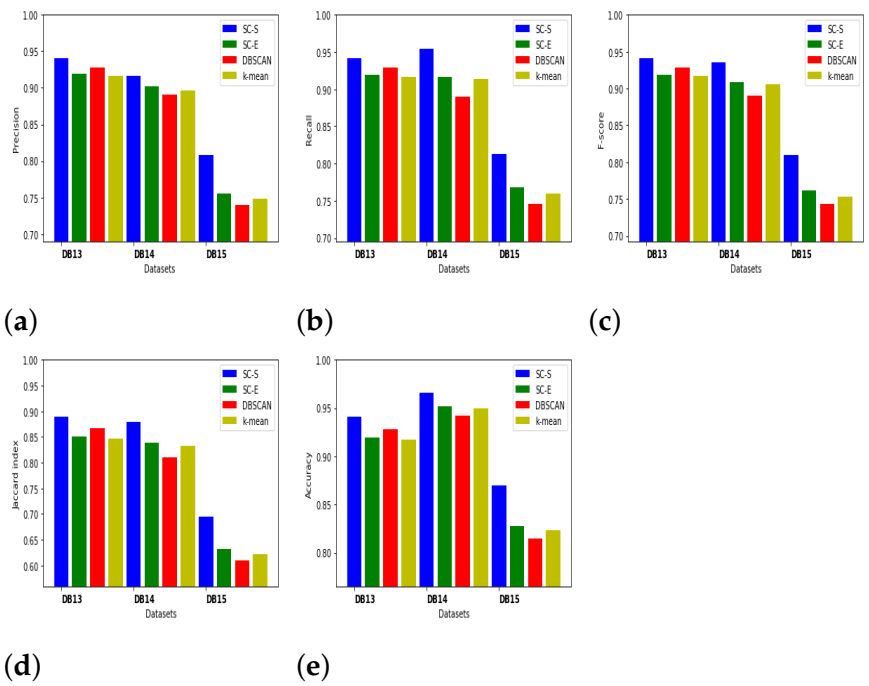
5. Experimental Results and Discussion
5.1. Database Description
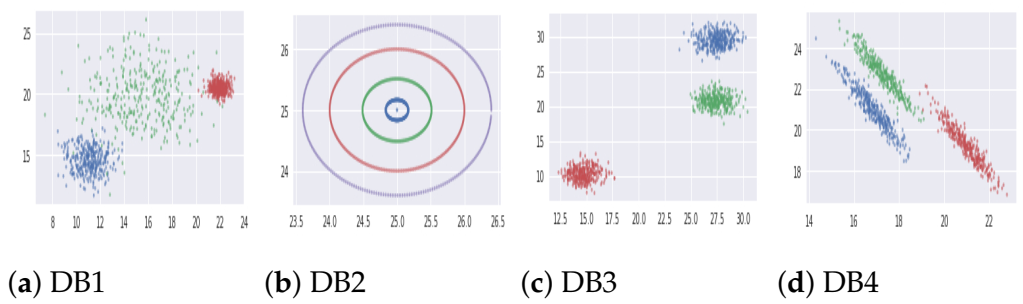
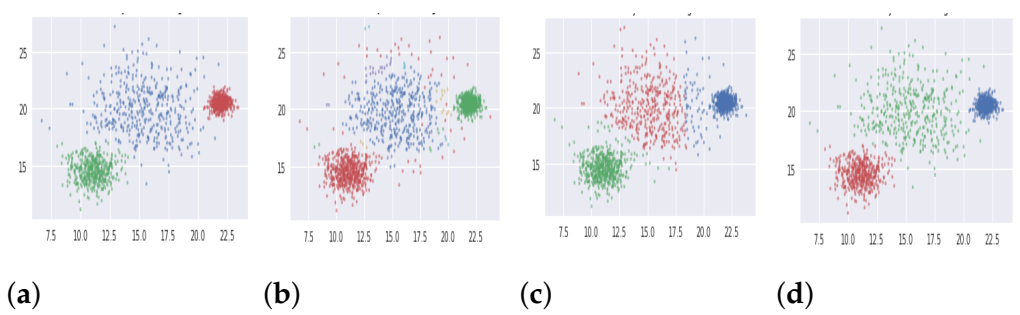
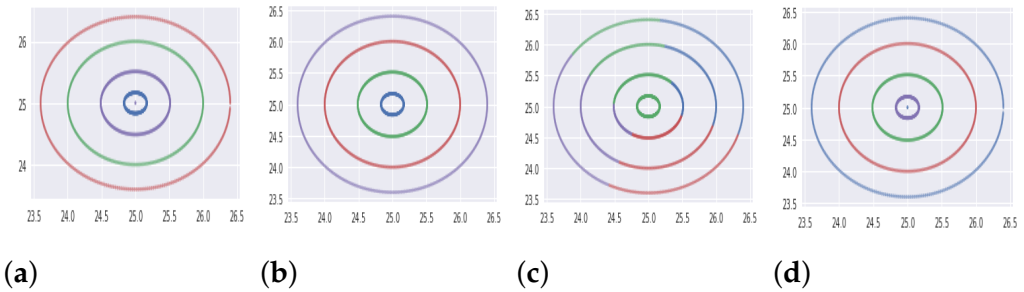
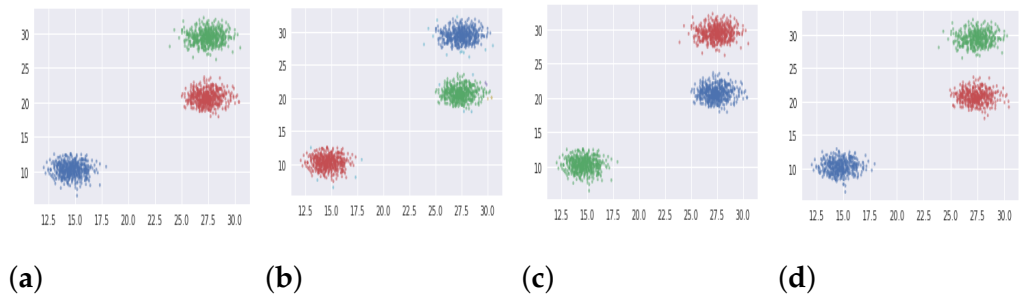
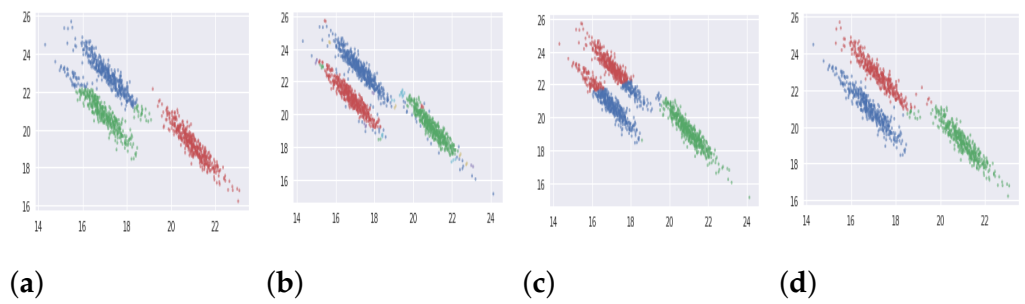
5.1.1. Synthetic Databases
5.1.2. UCI and Industrial Databases
5.2. Evaluation Indices
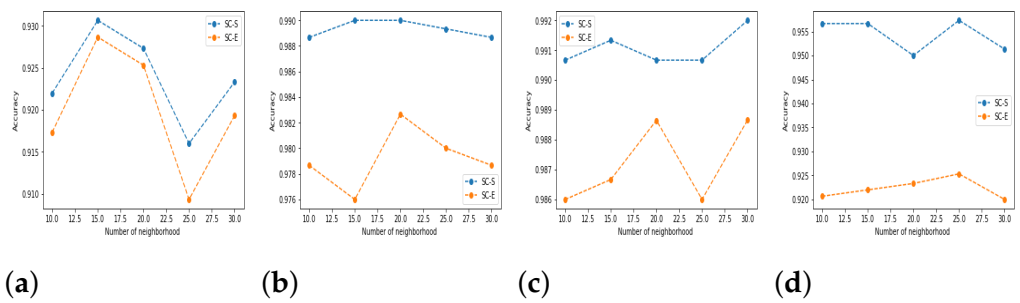
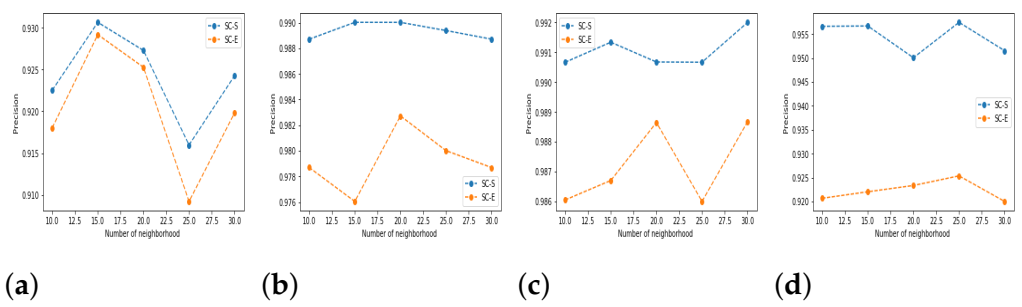
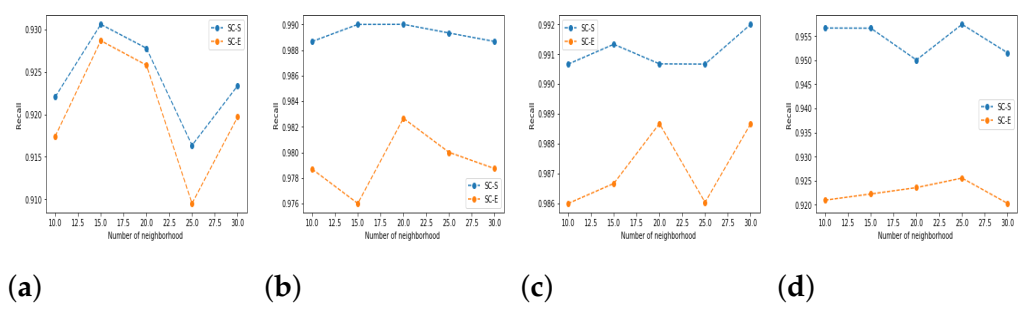
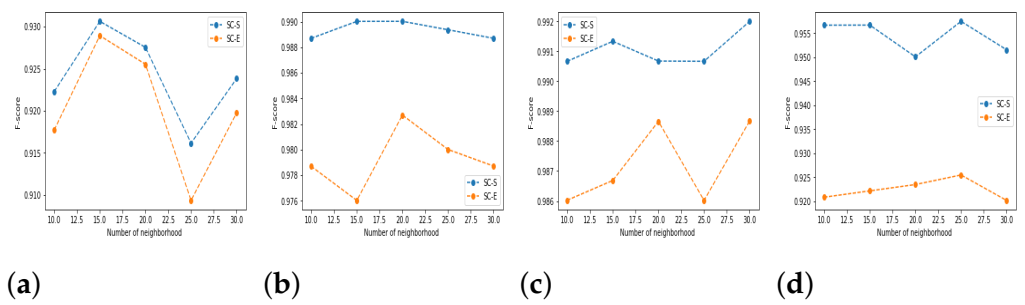
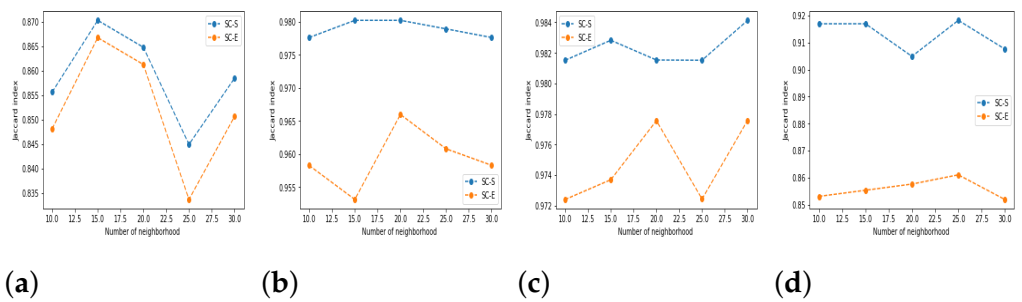
5.3. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohan, K.; Seal, A.; Krejcar, O.; Yazidi, A. Facial Expression Recognition Using Local Gravitational Force Descriptor-Based Deep Convolution Neural Networks. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar] [CrossRef]
- Rust, R.T.; Moorman, C.; Bhalla, G. Rethinking marketing. Harv. Bus. Rev. 2010, 88, 94–101. [Google Scholar]
- Nobibon, F.T.; Leus, R.; Spieksma, F.C. Optimization models for targeted offers in direct marketing: Exact and heuristic algorithms. Eur. J. Oper. Res. 2011, 210, 670–683. [Google Scholar] [CrossRef]
- Abbasi, A.A.; Younis, M. A survey on clustering algorithms for wireless sensor networks. Comput. Commun. 2007, 30, 2826–2841. [Google Scholar] [CrossRef]
- Au, W.H.; Chan, K.C.; Yao, X. A novel evolutionary data mining algorithm with applications to churn prediction. IEEE Trans. Evol. Comput. 2003, 7, 532–545. [Google Scholar]
- Hung, S.Y.; Yen, D.C.; Wang, H.Y. Applying data mining to telecom churn management. Expert Syst. Appl. 2006, 31, 515–524. [Google Scholar] [CrossRef]
- Hossein Javaheri, S. Response Modeling in Direct Marketing: A Data Mining Based Approach for Target Selection. 2008. Available online: https://www.researchgate.net/publication/292282619_Response_modeling_in_direct_marketing_A_data_mining_based_approach_for_target_selection (accessed on 25 March 2021).
- Castro, E.G.; Tsuzuki, M.S. Churn prediction in online games using players’ login records: A frequency analysis approach. IEEE Trans. Comput. Intell. Games 2015, 7, 255–265. [Google Scholar] [CrossRef]
- Sharma, K.K.; Seal, A. Clustering analysis using an adaptive fused distance. Eng. Appl. Artif. Intell. 2020, 96, 103928. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef]
- Suchacka, G.; Skolimowska-Kulig, M.; Potempa, A. Classification Of E-Customer Sessions Based On Support Vector Machine. ECMS 2015, 15, 594–600. [Google Scholar]
- Suchacka, G.; Skolimowska-Kulig, M.; Potempa, A. A k-Nearest Neighbors method for classifying user sessions in e-commerce scenario. J. Telecommun. Inf. Technol. 2015. Available online: https://yadda.icm.edu.pl/baztech/element/bwmeta1.element.baztech-40e29335-8f5f-4d8c-aa93-8c13a90d1b2d (accessed on 25 March 2021).
- Labeeuw, W.; Stragier, J.; Deconinck, G. Potential of active demand reduction with residential wet appliances: A case study for Belgium. IEEE Trans. Smart Grid 2015, 6, 315–323. [Google Scholar] [CrossRef]
- Faria, P.; Spínola, J.; Vale, Z. Aggregation and remuneration of electricity consumers and producers for the definition of demand-response programs. IEEE Trans. Ind. Inform. 2016, 12, 952–961. [Google Scholar] [CrossRef]
- Wu, B.; Wilamowski, B.M. A fast density and grid based clustering method for data with arbitrary shapes and noise. IEEE Trans. Ind. Inform. 2017, 13, 1620–1628. [Google Scholar] [CrossRef]
- Suchacka, G.; Chodak, G. Using association rules to assess purchase probability in online stores. Inf. Syst. Bus. Manag. 2017, 15, 751–780. [Google Scholar] [CrossRef]
- Bottou, L.; Bengio, Y. Convergence Properties of the K-Means Algorithms; Advances in Neural Information Processing Systems: Vancouver, BC, Canada, 1995; pp. 585–592. [Google Scholar]
- Sharma, K.K.; Seal, A. Spectral embedded generalized mean based k-nearest neighbors clustering with s-distance. Expert Syst. Appl. 2020, 169, 114326. [Google Scholar] [CrossRef]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J. Clustering with Bregman divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Nock, R.; Nielsen, F.; Amari, S.I. On conformal divergences and their population minimizers. IEEE Trans. Inf. Theory 2016, 62. [Google Scholar] [CrossRef]
- Notsu, A.; Komori, O.; Eguchi, S. Spontaneous clustering via minimum gamma-divergence. Neural Comput. 2014, 26, 421–448. [Google Scholar] [CrossRef] [PubMed]
- Chang, E.C.; Huang, S.C.; Wu, H.H. Using K-means method and spectral clustering technique in an outfitter’s value analysis. Qual. Quant. 2010, 44, 807–815. [Google Scholar] [CrossRef]
- Sra, S. Positive definite matrices and the S-divergence. Proc. Am. Math. Soc. 2016, 144, 2787–2797. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Jiao, L.; Shang, F.; Wang, F.; Liu, Y. Fast semi-supervised clustering with enhanced spectral embedding. Pattern Recognit. 2012, 45, 4358–4369. [Google Scholar] [CrossRef]
- Kim, T.H.; Lee, K.M.; Lee, S.U. Learning full pairwise affinities for spectral segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1690–1703. [Google Scholar] [PubMed]
- Chen, W.; Feng, G. Spectral clustering: A semi-supervised approach. Neurocomputing 2012, 77, 229–242. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Selim, S.Z.; Ismail, M.A. K-means-type algorithms: A generalized convergence theorem and characterization of local optimality. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 1, 81–87. [Google Scholar] [CrossRef] [PubMed]
- De Stefano, C.; Maniaci, M.; Fontanella, F.; di Freca, A.S. Reliable writer identification in medieval manuscripts through page layout features: The “Avila” Bible case. Eng. Appl. Artif. Intell. 2018, 72, 99–110. [Google Scholar] [CrossRef]
- Dheeru, D.; Karra Taniskidou, E. UCI Machine Learning Repository; UCI: Irvine, CA, USA, 2017. [Google Scholar]
- Sakar, C.O.; Polat, S.O.; Katircioglu, M.; Kastro, Y. Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 2019, 31, 6893–6908. [Google Scholar] [CrossRef]
- Sharma, K.K.; Seal, A. Modeling uncertain data using Monte Carlo integration method for clustering. Expert Syst. Appl. 2019, 137, 100–116. [Google Scholar] [CrossRef]
- Seal, A.; Karlekar, A.; Krejcar, O.; Gonzalo-Martin, C. Fuzzy c-means clustering using Jeffreys-divergence based similarity measure. Appl. Soft Comput. 2020, 88, 106016. [Google Scholar] [CrossRef]
- Sharma, K.K.; Seal, A. Multi-view spectral clustering for uncertain objects. Inf. Sci. 2021, 547, 723–745. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Karlekar, A.; Seal, A.; Krejcar, O.; Gonzalo-Martin, C. Fuzzy k-means using non-linear s-distance. IEEE Access 2019, 7, 55121–55131. [Google Scholar] [CrossRef]
- Sharma, K.K.; Seal, A. Outlier-robust multi-view clustering for uncertain data. Knowl. Based Syst. 2021, 211, 106567. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Pfeifle, M. Density-based clustering of uncertain data. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 672–677. [Google Scholar]
- Richardson, A.M. Nonparametric Statistics: A Step-by-Step Approach. Int. Stat. Rev. 2015, 83, 163–164. [Google Scholar] [CrossRef]
Short Biography of Authors
 | Krishna Kumar Sharma is currently pursuing PhD with the Computer Science and Engineering Department, PDPM Indian Institute of Information Technology, Design and Manufacturing Jabalpur, Madhya Pradesh, India and has received the M.Tech.(Information Technology) degree from IIIT Allahabad, Uttar Pradesh, India, in 2011. He is also currently an Assistant Professor with the Computer Science and Informatics Department, University of Kota, Kota, Rajasthan, India. His current research interest includes pattern recognition. |
 | Ayan Seal received the PhD degree in engineering from Jadavpur University, West Bengal, India, in 2014. He is currently an Assistant Professor with the Computer Science and Engineering Department, PDPM Indian Institute of Information Technology, Design and Manufacturing Jabalpur, Madhya Pradesh, India. He is also associated with the Center for Basic and Applied Science, Faculty of Informatics and Management, University of Hradec Králové, Hradec Králové, Czech Republic. He has visited the Universidad Politecnica de Madrid, Spain as a visiting research scholar. He is the recipient of several awards including Sir Visvesvaraya Young Faculty Research Fellowship from Media Lab Asia, Ministry of Electronics and Information Technology, Government of India. He has authored or co-authored of several journals, conferences and book chapters in the area of computer vision and machine learning. His current research interests include image processing and pattern recognition. |
 | Enrique Herrera-Viedma received the M.Sc. and Ph.D. degrees in computer science from the University of Granada, Granada, Spain, in 1993 and 1996, respectively. He is a Professor of computer science and the Vice-President for Research and Knowledge Transfer with University of Granada, Granada, Spain. His h-index is 81 with more than 23,000 citations received in Web of Science and 97 in Google Scholar with more than 37,000 cites received. He has been identified as one of the world’s most influential researchers by the Shanghai Center and Thomson Reuters/Clarivate Analytics in both computer science and engineering in the years 2014, 2015, 2016, 2017, 2018, 2019 and 2020. His current research interests include group decision making, consensus models, linguistic modeling, aggregation of information, information retrieval, bibliometric, digital libraries, web quality evaluation, recommender systems, and social media. Dr. Herrera-Viedma is Vice President for Publications in System Man & Cybernetic Society and an Associate Editor in several journals such as IEEE Transactions on Fuzzy Systems, IEEE Transactions on Systems, Man, and Cybernetics: Systems, IEEE Transactions on Intelligent Transport System, Information Sciences, Applied Soft Computing, Soft Computing, Fuzzy Optimization and Decision Making, and Knowledge-Based Systems. |
 | Ondrej Krejcar is a full professor in systems engineering and informatics at the University of Hradec Kralove, Czech Republic. In 2008 he received his Ph.D. title in technical cybernetics at Technical University of Ostrava, Czech Republic. He is currently a vice-rector for science and creative activities of the University of Hradec Kralove from June 2020. At present, he is also a director of the Center for Basic and Applied Research at the University of Hradec Kralove. In years 2016–2020 he was vice-dean for science and research at Faculty of Informatics and Management, UHK. His h-index is 19, with more than 1250 citations received in the Web of Science. In 2018, he was the 14th top peer reviewer in Multidisciplinary in the World according to Publons and a Top Reviewer in the Global Peer Review Awards 2019 by Publons. Currently, he is on the editorial board of the MDPI Sensors IF journal (Q1/Q2 at JCR), and several other ESCI indexed journals. He is a Vice-leader and Management Committee member at WG4 at project COST CA17136, since 2018. He has also been a Management Committee member substitute at project COST CA16226 since 2017. Since 2019, he has been Chairman of the Program Committee of the KAPPA Program, Technological Agency of the Czech Republic as a regulator of the EEA/Norwegian Financial Mechanism in the Czech Republic (2019–2024). Since 2020, he has been Chairman of the Panel 1 (Computer, Physical and Chemical Sciences) of the ZETA Program, Technological Agency of the Czech Republic. Since 2014 until 2019, he has been Deputy Chairman of the Panel 7 (Processing Industry, Robotics, and Electrical Engineering) of the Epsilon Program, Technological Agency of the Czech Republic. At the University of Hradec Kralove, he is a guarantee of the doctoral study program in Applied Informatics, where he is focusing on lecturing on Smart Approaches to the Development of Information Systems and Applications in Ubiquitous Computing Environments. His research interests include Control Systems, Smart Sensors, Ubiquitous Computing, Manufacturing, Wireless Technology, Portable Devices, biomedicine, image segmentation and recognition, biometrics, technical cybernetics, and ubiquitous computing. His second area of interest is in Biomedicine (image analysis), as well as Biotelemetric System Architecture (portable device architecture, wireless biosensors), development of applications for mobile devices with use of remote or embedded biomedical sensors |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.No. | Category | Databases | Samples | Features | Clusters |
|---|---|---|---|---|---|
| 1 | Synthetic | Varied Distributed Data (DB1) | 1500 | 2 | 3 |
| 2 | Synthetic | Noisy 4-Circles (DB2) | 1500 | 2 | 4 |
| 3 | Synthetic | Blobs (DB3) | 1500 | 2 | 3 |
| 4 | Synthetic | Anisotropically Distributed Data (DB4) | 1500 | 2 | 3 |
| 5 | UCI | Avila database (DB5) | 10430 | 10 | 12 |
| 6 | UCI | Breast Cancer database (DB6) | 569 | 30 | 2 |
| 7 | UCI | Digits database (DB7) | 1797 | 64 | 10 |
| 8 | UCI | Iris database (DB8) | 150 | 4 | 3 |
| 9 | UCI | Letter Recognition database (DB9) | 20000 | 16 | 26 |
| 10 | UCI | Poker Hand database (DB10) | 25010 | 10 | 10 |
| 11 | UCI | Shuttle database (DB11) | 43500 | 9 | 7 |
| 12 | UCI | Wine database (DB12) | 178 | 13 | 3 |
| 13 | Industrial | Banking marketing database (DB13) | 45211 | 12 | 2 |
| 14 | Industrial | Online Shoppers’ Purchasing Intention (DB14) | 12330 | 18 | 2 |
| 15 | Industrial | Telecommunication customer churn database (DB15) | 7044 | 21 | 2 |
| Rank-Sum | Sign-Rank | Sign Test | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Databases | M1 | M2 | M3 | M1 | M2 | M3 | M1 | M2 | M3 |
| DB1 | 0.04937 | 0.00016 | 0.00195 | 0.0047 | 0.00492 | 0.00492 | 0.00195 | 0.04937 | 0.0015 |
| DB2 | 0.00016 | 0.00016 | 0.00016 | 0.0047 | 0.00448 | 0.00448 | 0.00195 | 0.00195 | 0.00195 |
| DB3 | 0.00195 | 0.00016 | 0.00016 | 0.0047 | 0.00492 | 0.00492 | 0.00195 | 0.00016 | 0.00195 |
| DB4 | 0.28992 | 0.00016 | 0.0015 | 0.0047 | 0.00492 | 0.00492 | 0.00195 | 0.00195 | 0.0015 |
| DB5 | 0.00016 | 0.00289 | 0.00016 | 0.00492 | 0.00492 | 0.00492 | 0.00195 | 0.0015 | 0.00195 |
| DB6 | 0.00016 | 0.00016 | 0.00016 | 0.00492 | 0.00492 | 0.00492 | 0.00195 | 0.00195 | 0.00195 |
| DB7 | 0.00016 | 0.00016 | 0.00016 | 0.00492 | 0.00492 | 0.0047 | 0.0015 | 0.00016 | 0.00195 |
| DB8 | 0.00289 | 0.00016 | 0.00016 | 0.00492 | 0.00492 | 0.00492 | 0.00195 | 0.00195 | 0.00492 |
| DB9 | 0.00016 | 0.00492 | 0.0015 | 0.00448 | 0.00448 | 0.0047 | 0.00195 | 0.00195 | 0.00195 |
| DB10 | 0.00016 | 0.00016 | 0.00016 | 0.00492 | 0.00492 | 0.00492 | 0.0015 | 0.00195 | 0.00195 |
| DB11 | 0.00016 | 0.00492 | 0.00016 | 0.00492 | 0.00492 | 0.00492 | 0.00195 | 0.00195 | 0.00492 |
| DB12 | 0.00016 | 0.00016 | 0.0015 | 0.00492 | 0.00492 | 0.00492 | 0.00195 | 0.00195 | 0.00195 |
| DB13 | 0.0015 | 0.00016 | 0.00016 | 0.00407 | 0.0047 | 0.00492 | 0.00195 | 0.00195 | 0.00195 |
| DB14 | 0.00016 | 0.00016 | 0.00016 | 0.00492 | 0.00492 | 0.00492 | 0.00195 | 0.00195 | 0.00492 |
| DB15 | 0.0047 | 0.04937 | 0.00195 | 0.00492 | 0.00448 | 0.00492 | 0.00289 | 0.00195 | 0.0047 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar Sharma, K.; Seal, A.; Herrera-Viedma, E.; Krejcar, O. An Enhanced Spectral Clustering Algorithm with S-Distance. Symmetry 2021, 13, 596. https://doi.org/10.3390/sym13040596
Kumar Sharma K, Seal A, Herrera-Viedma E, Krejcar O. An Enhanced Spectral Clustering Algorithm with S-Distance. Symmetry. 2021; 13(4):596. https://doi.org/10.3390/sym13040596
Chicago/Turabian StyleKumar Sharma, Krishna, Ayan Seal, Enrique Herrera-Viedma, and Ondrej Krejcar. 2021. "An Enhanced Spectral Clustering Algorithm with S-Distance" Symmetry 13, no. 4: 596. https://doi.org/10.3390/sym13040596
APA StyleKumar Sharma, K., Seal, A., Herrera-Viedma, E., & Krejcar, O. (2021). An Enhanced Spectral Clustering Algorithm with S-Distance. Symmetry, 13(4), 596. https://doi.org/10.3390/sym13040596