
An Effective Naming Heterogeneity Resolution for XACML Policy Evaluation in a Distributed Environment



Abstract
:1. Introduction
- We have proposed a naming heterogeneity resolution model with the main aim to resolve naming heterogeneity, which may arise due to syntactic variations and terminological variations during policy evaluation.
- Several matching functions have been proposed. Each matching function has been designed to cater to certain type of variation (syntactic and/or terminological) by analyzing the terms that appeared in the attribute values of a request and a policy. N-gram and WordNet are utilized to provide the syntactic similarities and semantic relationships (synonym, hypernym, and hyponym) between terms, respectively.
- The experimental results of the proposed solution are presented to prove its capability of identifying and resolving naming heterogeneity due to syntactic and terminological variations during policy evaluation.
2. Related Works
3. Preliminaries
3.1. Definitions and Notations
3.2. Illustrative Example
- A compound noun is a noun that is made of two or more words. For instance, referring to Table 3, the term in the resource attribute of is a compound noun.
- An abbreviation is a shortened or contracted form of a word or phrase. For instance, referring to Table 8, the term which is part of the term in the subject attribute of is a shortened form of .
- A word may appear at the beginning of another word which is in the form of a compound noun. For instance, referring to Table 9, in the action attribute of occurs at the beginning of in the action attribute of .
- A word may appear at the end of another word which is in the form of a compound noun. For instance, referring to Table 6, in the resource attribute of occurs at the end of in the resource attribute of .
- A word may contain delimiter characters (i.e., dash, underscore, capital letters, etc.). For example, referring to Table 2, the term in the subject attribute of contains “_” as delimiter.
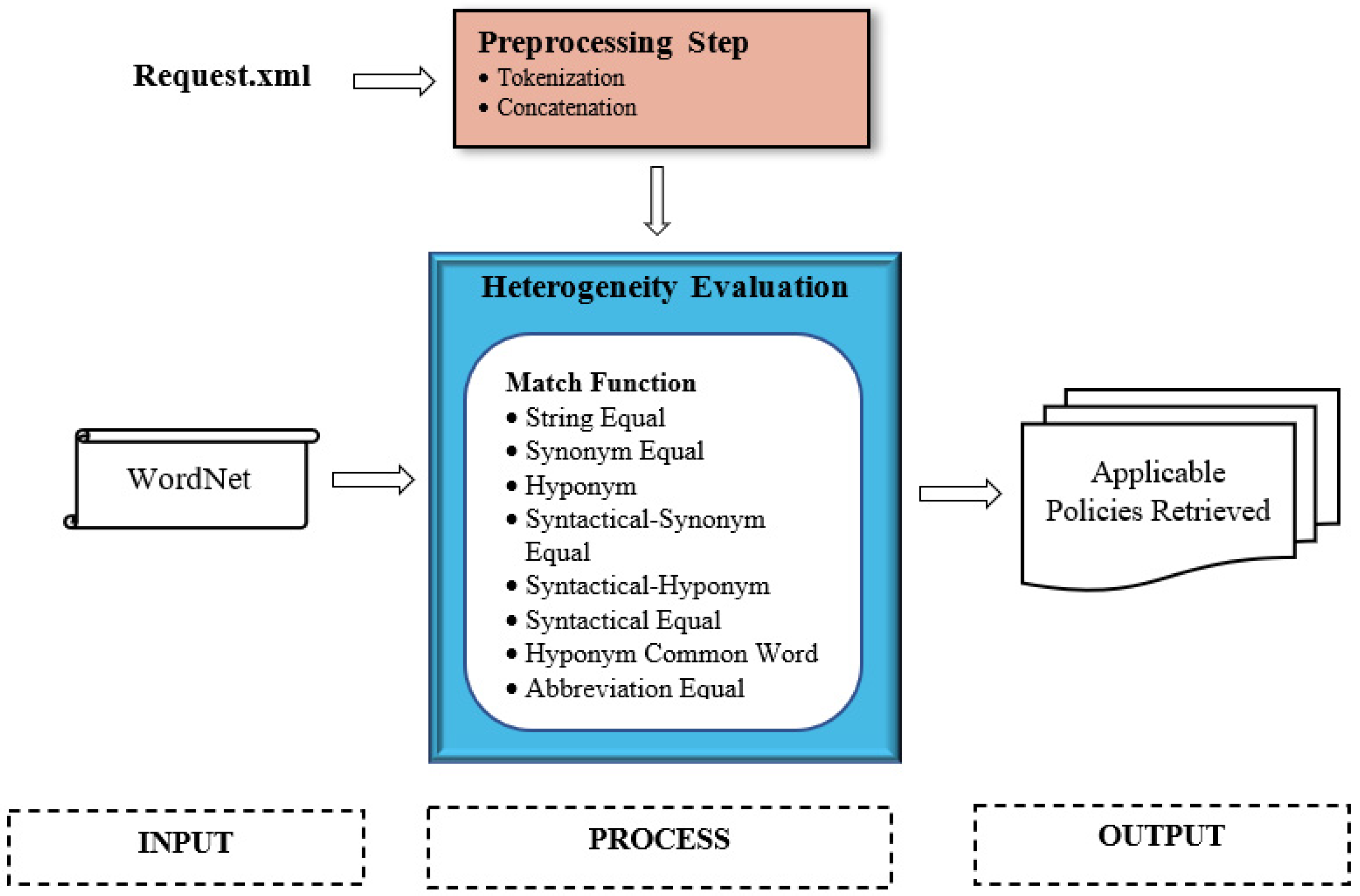
4. Naming Heterogeneity Resolution
- Space concatenation is performed on the tokens of the and . The tokens of the are concatenated with an intervening space and stored into . is further checked by WordNet as to whether it is a non-vague term. The same process goes for . For example, the tokens of , and , are concatenated with an intervening space to form a new meaningful term, , which is a non-vague term, as gloss is returned from WordNet.
- In contrast, if the new term is a vague term, abuttal concatenation is performed by concatenating the tokens into a single term without an intervening space. Take , as an example. is tokenized into and is further concatenated with an intervening space to form a new term, , . However, is apparently a vague term, thus, , , and are concatenated into a single term without an intervening space, . Intuitively, N-gram is applied during the matching process.
| Algorithm 1: Preprocessing Steps Algorithm |
 |
4.1. String Equal
| Algorithm 2: String Equal Function Algorithm |
 |
4.2. Synonym Equal
| Algorithm 3: Synonym Equal Function Algorithm |
 |
4.3. Hyponym
| Algorithm 4: Hyponym Function Algorithm |
 |
4.4. Syntactical Synonym Equal
4.5. Syntactical Hyponym
| Algorithm 5: Syntactical Synonym Equal Function Algorithm |
 |
| Algorithm 6: Syntactical Hyponym Function Algorithm |
 |
4.6. Syntactical Equal
| Algorithm 7: Syntactical Equal Function Algorithm |
 |
4.7. Hyponym Common Word
| Algorithm 8: Hyponym Common Word Function Algorithm |
 |
4.8. Abbreviation Equal
| Algorithm 9: Abbreviation Equal Function Algorithm |
 |
5. Results and Discussion
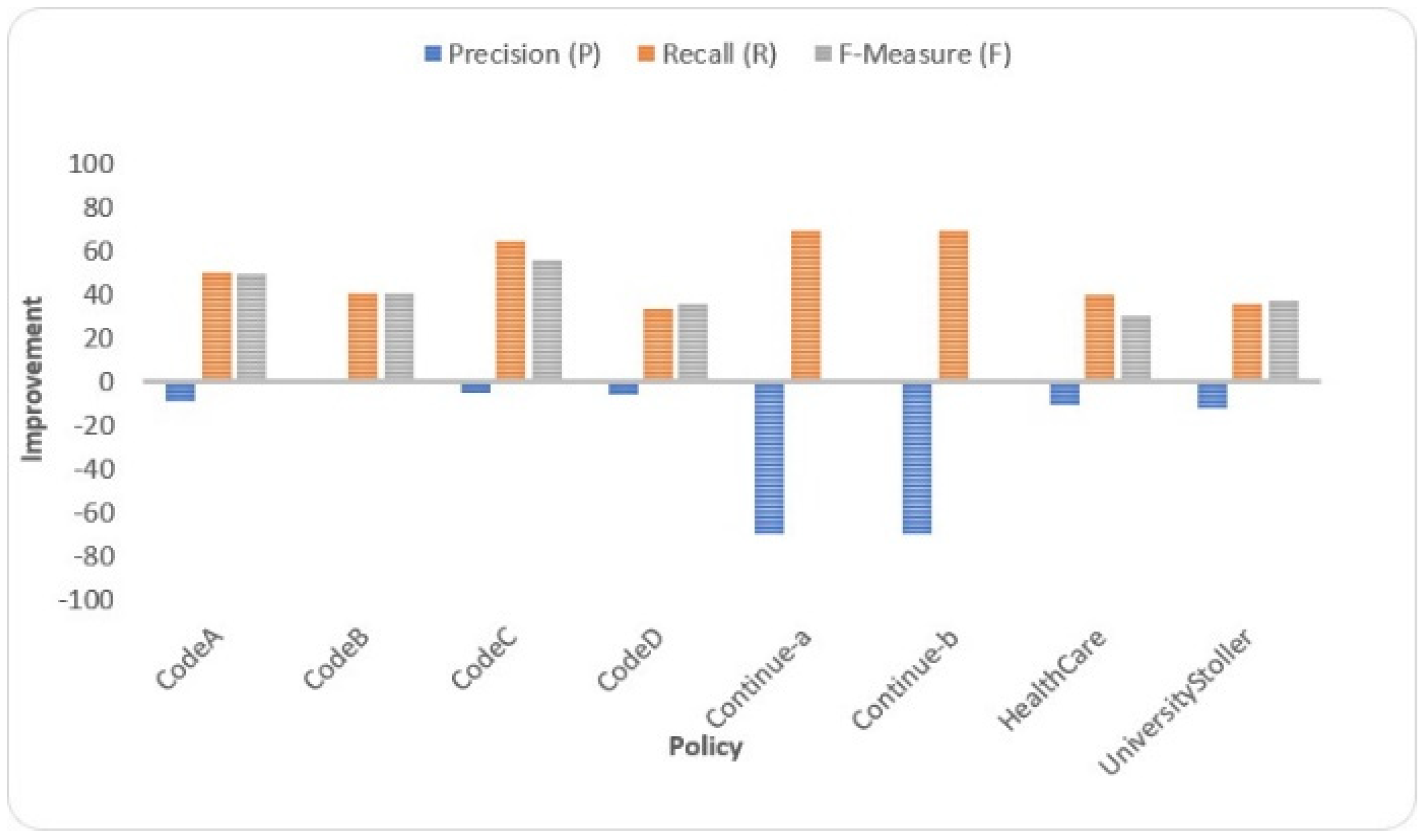
- The proposed solution could not produce accurate match results when there are similarities in terms of characters presented in the terms being matched while these terms are actually not matched. For example, the terms and that appeared in the Continue-a policy are considered matched in the proposed solution. The application of N-gram with trigram (3) on the strings and gained a similarity score of 0.6, which satisfied the similarity threshold when it was set to at least 0.6. However, and are considered not matched by the human experts. Referring to Table 16 and Table 17, the proposed solution achieved a low value of P in matching the resource attribute of a request and a policy when the similarity threshold is 0.2. This is because the terms in the resource attribute of Continue-a and Continue-b policies have some similarities in terms of characters presented, thus making N-gram produce a higher similarity score than the similarity threshold 0.2 but lower than 0.4. In another example, and are considered matched by the proposed solution since the similarity score of these terms is 0.27, which is higher than the similarity threshold 0.2. However, and are considered not matched by the human experts. Thus, the proposed solution produced a false positive in this case.
- The proposed solution failed to match the terms that contain semantic relationship but do not have similarities in terms of characters presented. However, these terms are in fact matched. For example, in a request and in a policy. In this case, the proposed solution returned false match. Based on the human experts, is a hyponym of .
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tejada, S.; Knoblock, C.A.; Minton, S. Learning object identification rules for information integration. Inf. Syst. 2001, 26, 607–633. [Google Scholar] [CrossRef]
- Thilakanathan, D.; Chen, S.; Nepal, S.; Calvo, R. SafeProtect: Controlled Data Sharing With User-Defined Policies in Cloud-Based Collaborative Environment. IEEE Trans. Emerg. Top. Comput. 2015, 4, 301–315. [Google Scholar] [CrossRef]
- Toosi, A.N.; Calheiros, R.N.; Buyya, R. Interconnected Cloud Computing Environments: Challenges, Taxonomy, and Survey. J. ACM Comput. Surv. 2014, 7, 1–47. [Google Scholar] [CrossRef]
- Trivellato, D.; Zannone, N.; Glaundrup, M.; Skowronek, J.; Etalle, S. A Semantic Security Framework for Systems of Systems. Int. J. Coop. Inf. Syst. 2013, 22, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Trivellato, D.; Spiessens, F.; Zannone, N.; Etalle, S. POLIPO: Policies & Ontologies for Interoperability, Portability, and Autonomy. In Proceedings of the 10th IEEE International Conference on Policies for Distributed Systems and Networks (POLICY), London, UK, 20–22 July 2009; pp. 110–113. [Google Scholar]
- Castano, S.; Ferrara, A.; Montanelli, S.; Racca, G. Semantic Information Interoperability in Open Networked Systems. In Proceedings of the International Conference on Semantics of a Networked World (LCSNW), Paris, France, 17–19 June 2004; pp. 215–230. [Google Scholar]
- Drozdowicz, M.; Ganzha, M.; Paprzycki, M. Semantically Enriched Data Access Policies in eHealth. J. Med. Syst. 2016, 40, 238. [Google Scholar] [CrossRef] [Green Version]
- Ammar, N.; Malik, Z.; Bertino, E.; Rezgui, A. XACML Policy Evaluation with Dynamic Context Handling. J. IEEE Trans. Knowl. Data Eng. 2015, 27, 2575–2588. [Google Scholar] [CrossRef]
- Liu, A.X.; Chen, F.; Hwang, J.; Xie, T. Designing Fast and Scalable XACML Policy Evaluation Engines. IEEE Trans. Comput. 2010, 60, 1802–1817. [Google Scholar] [CrossRef] [Green Version]
- Ngo, C.; Demchenko, Y.; de Laat, C. Decision Diagrams for XACML Policy Evaluation and Management. J. Comput. Secur. 2015, 49, 1–16. [Google Scholar] [CrossRef]
- Proctor, S. Sun’s XACML Implementation. 2004. Available online: http://sunxacml.sourceforge.net (accessed on 29 March 2017).
- Ciuciu, I.; Zhao, G.; Chadwick, D.W.; Reul, Q.; Meersman, R.; Vasquez, C.; Hibbert, M.; Winfield, S.; Kirkham, T. Ontology based Interoperation for Securely Shared Services: Security Concept Matching for Authorization Policy Interoperability. In Proceedings of the 4th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 7–10 February 2011; pp. 1–5. [Google Scholar]
- Ferrini, R.; Bertino, E. Supporting RBAC with XACML+OWL. In Proceedings of the 14th ACM Symposium on Access Control Models and Technologies (SACMAT), Stresa, Italy, 3–5 June 2009; pp. 145–154. [Google Scholar]
- Hu, L.; Ying, S.; Jia, X.; Zhao, K. Towards an Approach of Semantic Access Control for Cloud Computing. In Proceedings of the 1st IEEE International Conference on Cloud Computing, Beijing, China, 1–4 December 2009; pp. 145–156. [Google Scholar]
- Husain, M.F.; Al-Khateeb, T.; Alam, M.; Khan, L. Ontology based policy interoperability in geo-spatial domain. Comput. Stand. Interfaces 2011, 33, 214–219. [Google Scholar] [CrossRef]
- Mohan, A.; Blough, D.M.; Kurc, T.; Post, A.; Saltz, J. Detection of Conflicts and Inconsistencies in Taxonomy based Authorization Policies. In Proceedings of the 2011 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Atlanta, GA, USA, 12–15 November 2011; pp. 590–594. [Google Scholar]
- Priebe, T.; Dobmeier, W.; Schläger, C.; Kamprath, N. Supporting Attribute based Access Control in Authorization and Authentication Infrastructures with Ontologies. J. Softw. 2007, 2, 27–38. [Google Scholar] [CrossRef]
- Takabi, H. A Semantic based Policy Management Framework for Cloud Computing Environments. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 12 July 2013. [Google Scholar]
- Zhao, H. Security Policy Definition and Enforcement in Distributed Systems. Ph.D. Thesis, Columbia University, New York, NY, USA, 12 September 2012. [Google Scholar]
- Dia, O.A.; Farkas, C. A Practical Framework for Policy Composition and Conflict Resolution. Int. J. Secur. Softw. Eng. 2012, 3, 1–26. [Google Scholar] [CrossRef]
- Duan, L.; Zhang, Y.; Chen, S.; Zhao, S.; Wang, S.; Liu, D.; Liu, R.P.; Cheng, B.; Chen, J. Automated Policy Combination for Secure Data Sharing in Cross-Organizational Collaborations. IEEE Access 2016, 4, 3454–3468. [Google Scholar] [CrossRef]
- Haguouche, S.; Jarir, Z. Generic Access Control Model and Semantic Mapping Between Heterogeneous Policies. Int. J. Technol. Diffus. 2018, 9, 52–65. [Google Scholar] [CrossRef]
- Ioannidis, S. Security Policy Consistency and Distributed Evaluation in Heterogeneous Environments. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2005. [Google Scholar]
- Mazzoleni, P.; Crispo, B.; Sivasubramanian, S.; Bertino, E. XACML Policy Integration Algorithms. ACM Trans. Inf. Syst. Secur. 2008, 11, 1–29. [Google Scholar] [CrossRef]
- Rao, P.; Lin, D.; Bertino, E.; Li, N.; Lobo, J. Fine-grained integration of access control policies. Comput. Secur. 2011, 30, 91–107. [Google Scholar] [CrossRef]
- Shafiq, B.; Joshi, J.B.D.; Bertino, E.; Ghafoor, A. Secure interoperation in a multidomain environment employing RBAC policies. IEEE Trans. Knowl. Data Eng. 2005, 17, 1557–1577. [Google Scholar] [CrossRef]
- Ferrini, R. EXAMS: An Analysis Tool for Multidomain Policy Sets. Ph.D. Thesis, University of Bologna, Bologna, Italy, 20 March 2009. [Google Scholar]
- Kalam, A.A.E.; Deswarte, Y.; Baina, A.; Kaaniche, M. Access Control for Collaborative Systems: A Web Services based Approach. In Proceedings of the IEEE International Conference on Web Services (ICWS), Salt Lake City, UT, USA, 9–13 July 2007; pp. 1064–1071. [Google Scholar]
- Lin, D.; Rao, P.; Ferrini, R.; Bertino, E.; Lobo, J. A Similarity Measure for Comparing XACML Policies. IEEE Trans. Knowl. Data Eng. 2012, 25, 1946–1959. [Google Scholar] [CrossRef]
- Lin, D.; Rao, P.; Bertino, E.; Lobo, J. An Approach to Evaluate Policy Similarity. In Proceedings of the 12th ACM symposium on Access Control Models and Technologies (SACMAT), Sophia Antipolis, France, 20–22 June 2007; pp. 1–10. [Google Scholar]
- Ahmadi, S.; Nassiri, M.; Rezvani, M. XACBench: A XACML policy benchmark. Soft Comput. 2020, 24, 16081–16096. [Google Scholar] [CrossRef]
- Deng, F.; Zhang, L.; Zhang, C.; Ban, H.; Wan, C.; Shi, M.; Chen, C.; Zhang, E. Establishment of rule dictionary for efficient XACML policy management. Knowl. Based Syst. 2019, 175, 26–35. [Google Scholar] [CrossRef]
- Deng, F.; Wang, S.; Zhang, L.; Wei, X.; Yu, J. Establishment of attribute bitmaps for efficient XACML policy evaluation. Knowl. Based Syst. 2018, 143, 93–101. [Google Scholar] [CrossRef]
- Dıaz-Lopez, D.; Dolera-Tormo, G.; Gomez-Marmol, F.; Martınez-Perez, G. Managing XACML Systems in Distributed Environments through Meta-Policies. Comput. Secur. 2015, 48, 92–115. [Google Scholar] [CrossRef]
- Li, Y.; Deng, F. A Graph and Clustering-Based Framework for Efficient XACML Policy Evaluation. Int. J. Coop. Inf. Syst. 2020, 29, 1–17. [Google Scholar] [CrossRef]
- Marfia, F.; Neri, M.A.; Pellegrini, F.; Colombetti, M. Using OWL Reasoning for Evaluating XACML Policies. In Proceedings of the International Conference on E-Business and Telecommunications, Colmar, France, 20–22 July 2015; pp. 343–363. [Google Scholar]
- Mourad, A.; Tout, H.; Talhi, C.; Otrok, H.; Yahyaoui, H. From model-driven specification to design-level set-based analysis of XACML policies. Comput. Electr. Eng. 2016, 52, 65–79. [Google Scholar] [CrossRef]
- Mourad, A.; Jebbaoui, H. SBA-XACML: Set-based Approach Providing Efficient Policy Decision Process for Accessing Web Services. Expert Syst. Appl. 2014, 42, 165–178. [Google Scholar] [CrossRef]
- Skandhakumar, N.; Reid, J.; Salim, F.; Dawson, E. A policy model for access control using building information models. Int. J. Crit. Infrastruct. Prot. 2018, 23, 1–10. [Google Scholar] [CrossRef]
- Turkmen, F.; Hartog, J.D.; Ranise, S.; Zannone, N. Formal analysis of XACML policies using SMT. Comput. Secur. 2017, 66, 185–203. [Google Scholar] [CrossRef]
- Shvaiko, P.; Euzenat, J. A Survey of Schema-based Matching Approaches. J. Data Semant. IV 2005, 3730, 146–171. [Google Scholar]
- Kuang, T.P.; Ibrahim, H.; Sidi, F.; Udzir, N.I. Heterogeneity XACML Policy Evaluation Engine. In Proceedings of the Malaysian National Conference of Databases (MaNCoD), Selangor, Malaysia, 17 September 2014; pp. 230–238. [Google Scholar]
- Do, H.-H.; Melnik, S.; Rahm, E. Comparison of Schema Matching Evaluations. In Proceedings of the Web, Web-Services, and Database Systems, Erfurt, Germany, 7–10 October 2003; pp. 221–237. [Google Scholar]
- Liu, L.; Zhang, S.; Diao, L.; Cao, C. An Iterative Method of Extracting Chinese ISA Relations for Ontology Learning. J. Comput. 2010, 5, 870–877. [Google Scholar] [CrossRef]
- Mohan, A.; Blough, D.M. An Attribute-based Authorization Policy Framework with Dynamic Conflict Resolution. In Proceedings of the 9th Symposium on Identity and Trust on the Internet (IDTRUST), Gaithersburg, MD, USA, 13–15 April 2010; pp. 37–50. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. J. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Sabou, M.; Lopez, V.; Motta, E. Ontology Selection for the Real Semantic Web: How to Cover the Queen’s Birthday Dinner? In Proceedings of the 15th International Conference on Managing Knowledge in a World of Networks (EKAW’06), Podêbrady, Czech Republic, 2–6 October 2006; pp. 96–111. [Google Scholar]
- Deng, F.; Zhan, L.Y. Elimination of Policy Conflict to Improve the PDP Evaluation Performance. J. Netw. Comput. Appl. 2017, 80, 45–57. [Google Scholar] [CrossRef]
- Stoller, S.D.; Yang, P.; Ramakrishnan, C.R.; Gofman, M.I. Efficient Policy Analysis for Administrative Role Based Access Control. In Proceedings of the 14th ACM Conference on Computer and Communications Security (CCS), Alexandria, VA, USA, 31 October–2 November 2007; pp. 445–455. [Google Scholar]
- Martin, E.; Xie, T.; Yu, T. Defining and Measuring Policy Coverage in Testing Access Control Policies. In Proceedings of the International Conference on Information and Communications Security (ICICS), Raleigh, NC, USA, 4–7 December 2006; pp. 139–158. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| A | I | II | III | |||||
|---|---|---|---|---|---|---|---|---|
| B | C | D | E | F | G | H | I | |
| [23] | √ | - | String Equal | Graph Matching | String Equal | String Equal | √ | √ |
| [26] | √ | - | Vector similarity, clustering, ontology graph matching | Vector similarity, clustering, ontology graph matching | String Equal | - | √ | √ |
| [24] | √ | - | Equal, not equal, intersect, subset, superset | Equal, not equal, intersect, subset, superset | Equal, not equal, intersect, subset, superset | Equal, not equal, intersect, subset, superset | √ | - |
| [25] | √ | - | Addition, subtraction, negation, domain projection | Addition, subtraction, negation, domain projection | Addition, subtraction, negation, Domain, Projection | Addition, subtraction, negation, domain projection | √ | - |
| [41] | √ | - | Addition, subtraction, intersection, precedence, negation, domain projection | Addition, subtraction, intersection, precedence, negation, domain projection | Addition, subtraction, intersection, precedence, negation, domain projection | Addition, subtraction, intersection, precedence, negation, domain projection | √ | - |
| [20] | √ | - | Intersection, scoping restriction, set difference | Intersection, scoping restriction, set difference | Intersection, scoping restriction, set difference | Intersection, scoping restriction, set difference | √ | - |
| [21] | √ | - | String Equal | String Equal | String Equal | Algebraic | √ | - |
| [22] | √ | - | Ontology graph matching | Ontology graph matching | Ontology graph matching | Ontology graph matching | √ | √ |
| [30] | √ | - | Ontology graph matching | Ontology graph matching | Ontology graph matching | Ontology graph matching | √ | - |
| [29] | √ | - | Domain specific thesauri, WordNet, ontology graph matching | Domain specific thesauri, WordNet, ontology graph matching | Domain specific thesauri, WordNet, ontology graph matching | Domain specific thesauri, WordNet, ontology graph matching | √ | √ |
| [27] | √ | - | Domain specific thesauri, WordNet, ontology graph matching | Domain specific thesauri, WordNet, ontology graph matching | Domain specific thesauri, WordNet, ontology graph matching | Domain specific thesauri, WordNet, ontology graph matching | √ | √ |
| [11] | - | √ | String Equal | String Equal | String Equal | String Equal | √ | - |
| [18] | √ | - | Jena and Pellet reasoner | Jena and Pellet reasoner | Jena & Pellet reasoner | Jena & Pellet reasoner | √ | √ |
| [8] | - | √ | String Equal | String Equal | String Equal | String Equal | √ | - |
| [9] | - | √ | String Equal | String Equal | String Equal | String Equal | √ | - |
| [10] | - | √ | String Equal | String Equal | String Equal | String Equal | √ | - |
| [12] | - | √ | JaroWinklerTF-IDF, WordNet, user dictionary, ontology graph matching | JaroWinklerTF-IDF, WordNet, user dictionary, ontology graph matching | JaroWinklerTF-IDF, WordNet, user dictionary, ontology graph matching | - | √ | √ |
| [14] | - | √ | Ontology graph matching | Ontology graph Matching | Ontology graph matching | - | √ | √ |
| [13] | - | √ | Pellet reasoner | Pellet reasoner | Pellet Reasoner | Pellet reasoner | √ | √ |
| [15] | - | √ | Ontology graph matching | Ontology graph Matching | Ontology graph matching | - | √ | √ |
| [17] | - | √ | Jena & Pellet reasoner | Jena & Pellet reasoner | Jena & Pellet Reasoner | Jena & Pellet Reasoner | √ | √ |
| [4] | - | √ | Jena reasoner | Jena reasoner | Jena reasoner | Jena Reasoner | √ | √ |
| [7] | - | √ | Ontology graph matching | Ontology graph matching | Ontology graph matching | Ontology graph matching | √ | √ |
| [42] | - | √ | WordNet, N-gram | WordNet, N-gram | WordNet, N-gram | WordNet, N-gram | √ | √ |
| Policy No. | Effect | Subject | Resource | Action | Condition |
|---|---|---|---|---|---|
| View |
| Request No. | Subject | Resource | Action | Condition |
|---|---|---|---|---|
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Terminological | ||
| Match | Terminological | ||
| Not Match | - | ||
| Match | Syntactic | ||
| Match | Terminological | ||
| Match | - | ||
| Match | Terminological |
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Syntactic | ||
| Match | Terminological | ||
| Match | Syntactic | ||
| Match | Terminological | ||
| Match | - | ||
| Match | Terminological |
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Syntactic | ||
| Match | Syntactic | ||
| Match | Syntactic | ||
| Not Match | - | ||
| Match | Terminological | ||
| Match | - | ||
| Match | Terminological |
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Syntactic | ||
| Match | Syntactic | ||
| Match | Syntactic | ||
| Not Match | - | ||
| Not Match | - | ||
| Not Match | - | ||
| Match | Syntactic | ||
| Match | - |
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Terminological | ||
| Match | Syntactic | ||
| Match | Syntactic | ||
| Not Match | - | ||
| Match | Terminological | ||
| Match | - |
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Terminological | ||
| Match | Syntactic | ||
| Match | Terminological | ||
| Not Match | - | ||
| Not Match | - | ||
| Not Match | - | ||
| Match | Terminological | ||
| Match | - |
| Result | Type of Variations | ||
|---|---|---|---|
| Match | Syntactic | ||
| Match | Syntactic | ||
| Match | Terminological | ||
| Not Match | - | ||
| Match | Syntactic | ||
| Match | - |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 56.57 * | 56.57 * | 56.57 * | 100 | 100 | 100 | [−43.43, 0] | |
| Action | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Condition | 86.67 * | 93.55 * | 100 | 100 | 100 | 100 | [−13.33, 0] | |
| Recall (R) | Subject | 52.22 | 42.22 | 42.22 | 42.22 | 42.22 | 5.56 | [36.66, 46.66] |
| Resource | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Action | 88.33 | 56.67 | 43.33 | 43.33 | 43.33 | 20.00 | [23.33, 68.33] | |
| Condition | 33.12 | 19.05 | 18.47 | 18.47 | 18.47 | 1.27 | [17.20, 31.85] | |
| F-Measure (F) | Subject | 68.61 | 59.38 | 59.38 | 59.38 | 59.38 | 10.53 | [48.85, 58.08] |
| Resource | 72.26 * | 72.26 * | 72.26 * | 100 | 100 | 100 | [−27.74, 0] | |
| Action | 93.81 | 72.34 | 60.47 | 60.47 | 60.47 | 33.33 | [27.14, 60.48] | |
| Condition | 47.93 | 31.65 | 31.18 | 31.18 | 31.18 | 2.52 | [28.66, 45.41] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 53.94 * | 53.94 * | 53.94 * | 100 | 100 | 100 | [−46.06, 0] | |
| Action | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Condition | 97.53 * | 100 | 100 | 100 | 100 | 100 | [−2.47, 0] | |
| Recall (R) | Subject | 53.92 | 45.10 | 45.10 | 45.10 | 45.10 | 12.70 | [32.40, 41.22] |
| Resource | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Action | 93.20 | 56.31 | 40.78 | 40.78 | 40.78 | 13.59 | [27.19, 79.61] | |
| Condition | 31.98 | 25.51 | 25.51 | 25.51 | 25.51 | 5.26 | [20.25, 26.72] | |
| F-Measure (F) | Subject | 70.06 | 62.16 | 62.16 | 62.16 | 62.16 | 22.61 | [39.55, 47.45] |
| Resource | 70.08 * | 70.08 * | 70.08 * | 100 | 100 | 100 | [−29.92, 0] | |
| Action | 96.48 | 72.05 | 57.93 | 57.93 | 57.93 | 23.93 | [34.00, 72.55] | |
| Condition | 48.17 | 40.65 | 40.65 | 40.65 | 40.65 | 10.00 | [30.65, 38.17] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 50.00 * | 50.00 * | 50.00 | 100 | 100 | 100 | [−50.00, 0] | |
| Action | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Condition | 92.36 * | 98.04 * | 100 | 100 | 100 | 100 | [−7.64, 0] | |
| Recall (R) | Subject | 53.92 | 45.10 | 45.10 | 45.10 | 45.10 | 12.75 | [32.35, 41.17] |
| Resource | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Action | 95.21 | 56.16 | 39.73 | 39.73 | 39.73 | 10.96 | [28.77, 84.25] | |
| Condition | 60.92 | 46.01 | 42.02 | 42.02 | 42.02 | 11.34 | [30.68, 49.58] | |
| F-Measure (F) | Subject | 70.06 | 62.16 | 62.16 | 62.16 | 62.16 | 22.61 | [39.55, 47.45] |
| Resource | 66.67 * | 66.67 * | 66.67 * | 100 | 100 | 100 | [−33.33, 0] | |
| Action | 97.54 | 71.93 | 56.86 | 56.86 | 56.86 | 19.75 | [37.11, 77.79] | |
| Condition | 73.42 | 62.63 | 59.17 | 59.17 | 59.17 | 20.38 | [38.79, 53.04] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 53.94 * | 53.94 * | 53.94 * | 100 | 100 | 100 | [−46.06, 0] | |
| Action | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Condition | 93.17 * | 98.36 * | 100 | 100 | 100 | 100 | [−6.83, 0] | |
| Recall (R) | Subject | 38.51 | 31.76 | 31.76 | 31.76 | 31.76 | 9.46 | [22.30, 29.05] |
| Resource | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Action | 91.41 | 56.44 | 41.72 | 41.72 | 41.72 | 15.95 | [25.77, 75.46] | |
| Condition | 70.22 | 47.08 | 44.12 | 44.12 | 44.12 | 13.60 | [30.52, 56.62] | |
| F-Measure (F) | Subject | 55.61 | 48.21 | 48.21 | 48.21 | 48.21 | 17.28 | [30.93, 38.33] |
| Resource | 70.08 * | 70.08 * | 70.08 * | 100 | 100 | 100 | [−29.92, 0] | |
| Action | 95.51 | 72.16 | 58.87 | 58.87 | 58.87 | 27.51 | [31.36, 68.00] | |
| Condition | 80.08 | 63.68 | 61.22 | 61.22 | 61.22 | 23.95 | [37.27, 56.13] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 65.70 * | 91.67 * | 100 | 100 | 100 | 100 | [−34.30, 0] | |
| Action | 61.07 * | 100 | 100 | 100 | 100 | 100 | [−38.93, 0] | |
| Condition | 89.69 * | 92.85 * | 98.98 * | 100 | 100 | 100 | [−10.31, 0] | |
| Recall (R) | Subject | 50.52 | 35.01 | 34.98 | 34.98 | 34.98 | 17.01 | [17.97, 33.51] |
| Resource | 43.86 | 36.11 | 33.25 | 33.25 | 33.25 | 31.33 | [1.92, 12.53] | |
| Action | 61.66 | 59.45 | 59.45 | 59.45 | 59.45 | 40.55 | [18.90, 21.11] | |
| Condition | 47.98 | 39.04 | 38.02 | 37.04 | 37.04 | 9.13 | [27.91, 38.85] | |
| F-Measure (F) | Subject | 67.12 | 51.86 | 51.83 | 51.83 | 51.83 | 29.07 | [22.76, 38.05] |
| Resource | 52.60 | 51.81 | 49.91 | 49.91 | 49.91 | 47.71 | [2.20, 4.89] | |
| Action | 61.36 | 74.57 | 74.57 | 74.57 | 74.57 | 57.70 | [3.66, 16.87] | |
| Condition | 62.52 | 54.97 | 54.93 | 54.06 | 54.06 | 16.73 | [37.33, 45.79] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 13.33 * | 62.07 * | 82.35 * | 100 | 100 | 100 | [−86.67, 0] | |
| Action | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Condition | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Recall (R) | Subject | 66.12 | 66.12 | 66.12 | 66.12 | 66.12 | 50.00 | [16.12, 16.12] |
| Resource | 100 | 100 | 77.78 | 77.78 | 77.78 | 47.22 | [30.56, 52.78] | |
| Action | 74.07 | 74.07 | 74.07 | 74.07 | 74.07 | 74.07 | [0, 0] | |
| Condition | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| F-Measure (F) | Subject | 79.60 | 79.60 | 79.60 | 79.60 | 79.60 | 99.00 | [19.40, 19.40] |
| Resource | 23.53 | 76.60 | 80.00 | 97.15 | 97.15 | 64.15 | [−40.62, 33.00] | |
| Action | 85.10 | 85.10 | 85.10 | 85.10 | 85.10 | 85.10 | [0, 0] | |
| Condition | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 13.33 * | 62.07 * | 82.35 * | 100 | 100 | 100 | [−86.67, 0] | |
| Action | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Condition | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Recall (R) | Subject | 66.12 | 66.12 | 66.12 | 66.12 | 66.12 | 50.00 | [16.12, 16.12] |
| Resource | 100 | 100 | 77.78 | 77.78 | 77.78 | 47.22 | [30.56, 52.78] | |
| Action | 74.07 | 74.07 | 74.07 | 74.07 | 74.07 | 74.07 | [0, 0] | |
| Condition | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| F-Measure (F) | Subject | 79.60 | 79.60 | 79.60 | 79.60 | 79.60 | 99.00 | [19.40, 19.40] |
| Resource | 23.53 | 76.60 | 80.00 | 97.15 | 97.15 | 64.15 | [−40.62, 33.00] | |
| Action | 85.10 | 85.10 | 85.10 | 85.10 | 85.10 | 85.10 | [0, 0] | |
| Condition | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] | |
| Evaluation Metric | Attributes | Percentage (%) | Improvement [Lowest, Highest] | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed Solution | Sun’s XACML Implementation | |||||||
| Similarity Threshold (τ) | ||||||||
| 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||||
| Precision (P) | Subject | 100 | 100 | 100 | 100 | 100 | 100 | [0, 0] |
| Resource | 68.20 * | 69.53 * | 100 | 100 | 100 | 100 | [−31.80, 0] | |
| Action | 60.71 * | 100 | 100 | 100 | 100 | 100 | [−39.29, 0] | |
| Condition | 81.04 * | 97.35 * | 100 | 100 | 100 | 100 | [−18.96, 0] | |
| Recall (R) | Subject | 88.37 | 86.82 | 82.95 | 82.95 | 82.95 | 45.51 | [37.44, 42.86] |
| Resource | 26.56 | 17.25 | 15.45 | 15.45 | 15.45 | 13.76 | [1.69, 12.80] | |
| Action | 80.68 | 80.68 | 80.68 | 80.68 | 80.68 | 80.68 | [0, 0] | |
| Condition | 45.13 | 42.69 | 42.69 | 42.69 | 42.69 | 23.20 | [19.49, 21.93] | |
| F-Measure (F) | Subject | 93.83 | 92.95 | 90.68 | 90.68 | 90.68 | 63.49 | [27.19, 30.34] |
| Resource | 38.44 | 27.53 | 26.76 | 26.76 | 26.76 | 24.19 | [2.57, 14.25] | |
| Action | 69.28 * | 89.31 | 89.31 | 89.31 | 89.31 | 89.31 | [−20.03, 0] | |
| Condition | 57.97 | 59.35 | 59.84 | 59.84 | 59.84 | 37.66 | [20.31, 22.18] | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuang, T.P.; Ibrahim, H.; Sidi, F.; Udzir, N.I.; Alwan, A.A. An Effective Naming Heterogeneity Resolution for XACML Policy Evaluation in a Distributed Environment. Symmetry 2021, 13, 2394. https://doi.org/10.3390/sym13122394
Kuang TP, Ibrahim H, Sidi F, Udzir NI, Alwan AA. An Effective Naming Heterogeneity Resolution for XACML Policy Evaluation in a Distributed Environment. Symmetry. 2021; 13(12):2394. https://doi.org/10.3390/sym13122394
Chicago/Turabian StyleKuang, Teo Poh, Hamidah Ibrahim, Fatimah Sidi, Nur Izura Udzir, and Ali A. Alwan. 2021. "An Effective Naming Heterogeneity Resolution for XACML Policy Evaluation in a Distributed Environment" Symmetry 13, no. 12: 2394. https://doi.org/10.3390/sym13122394
APA StyleKuang, T. P., Ibrahim, H., Sidi, F., Udzir, N. I., & Alwan, A. A. (2021). An Effective Naming Heterogeneity Resolution for XACML Policy Evaluation in a Distributed Environment. Symmetry, 13(12), 2394. https://doi.org/10.3390/sym13122394