
Object–Part Registration–Fusion Net for Fine-Grained Image Classification



Abstract
:1. Introduction
- A multi-stream fine-grained features network, which considers the global (object) and local (parts) features, is designed to generate fine-grained features of objects.
- A mechanism of registration–fusion features calculates the dimension and location relationships between global (object) regions and local (parts) regions to generate the registration information and fuses the local features into the global features with registration information to generate the fine-grained feature.
- The proposed method surpasses the state-of-the-art methods on the three popular datasets, including CUB200-2011, Stanford Cars, and FGVC-Aircraft datasets in both quantitative and qualitative evaluation.
2. Methodology
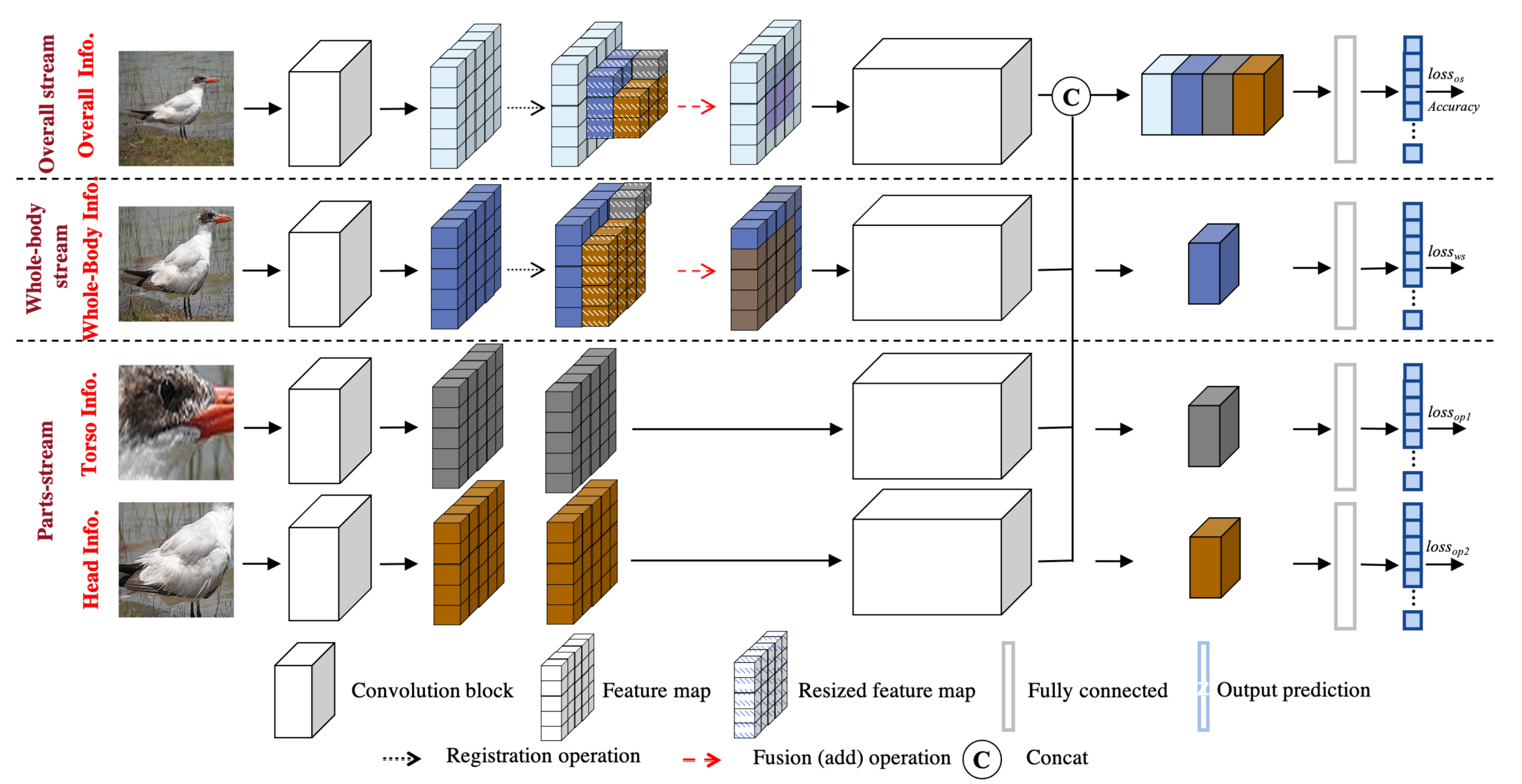
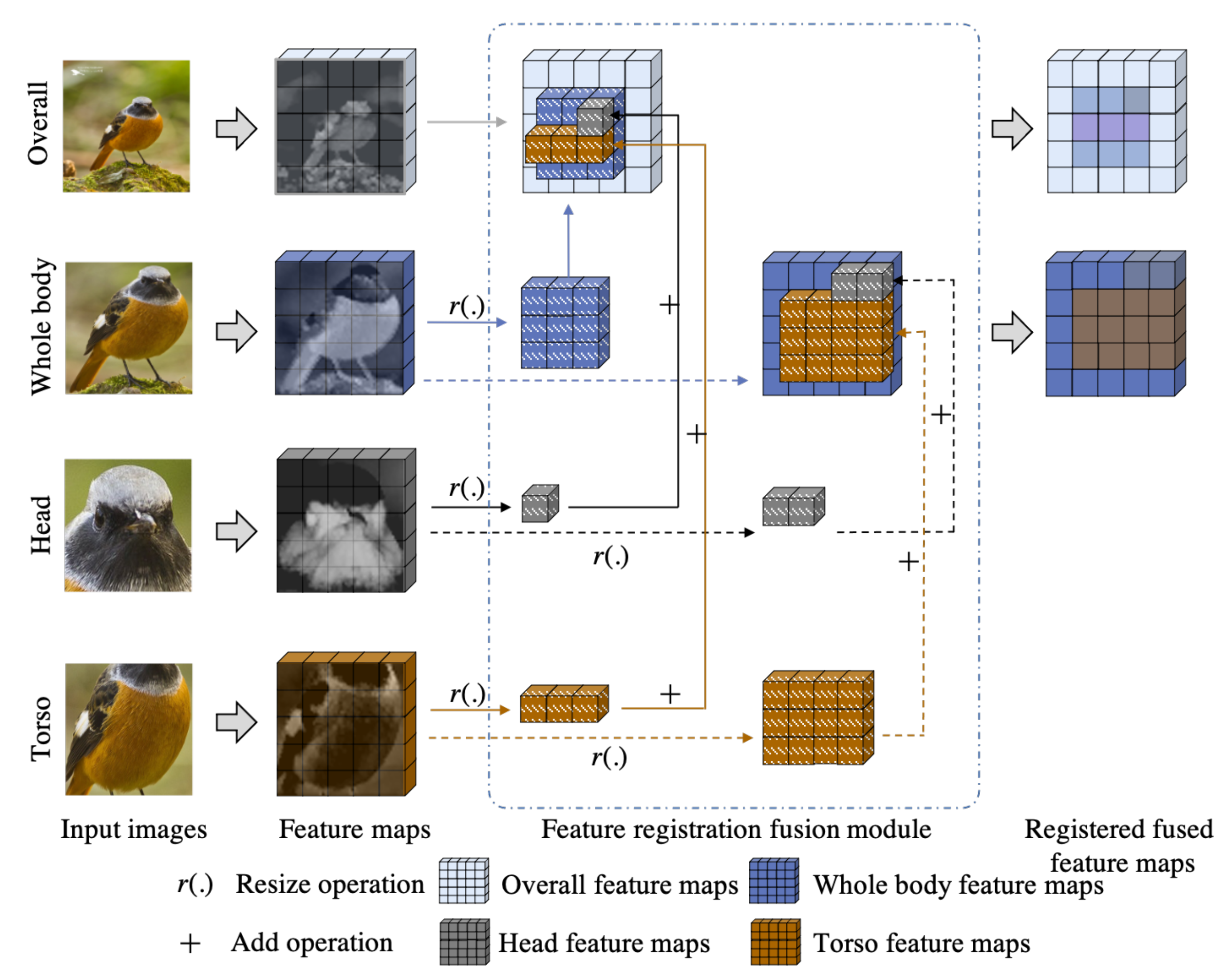
2.1. Feature Registration–Fusion Module
2.2. Network Architecture
2.3. Procedure of the Proposed OR-Net
| Algorithm 1: An algorithm of the proposed object–part registration–fusion Net (OR-Net). |
 |
3. Experiment
3.1. Experimental Datasets and Implementation Details
3.2. Diagnostic and Ablation Experiments
3.2.1. Diagnostic Experiments
3.2.2. Ablation Experiments
3.3. Experimential Analysis on the Popular Datasets
3.3.1. Quantitative Evaluation
3.3.2. Qualitative Evaluation
3.3.3. Qualitative Analysis with Benchmarked Model
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OR-Net | Object-part registration-fusion Net |
| DCNN | Deep Convolutional Neural Network |
References
- Lin, C.W.; Ding, Q.; Tu, W.H.; Huang, J.H.; Liu, J.F. Fourier dense network to conduct plant classification using UAV-based optical images. IEEE Access 2019, 7, 17736–17749. [Google Scholar] [CrossRef]
- Qian, W.; Huang, Y.; Liu, Q.; Fan, W.; Sun, Z.; Dong, H.; Wan, F.; Qiao, X. UAV and a deep convolutional neural network for monitoring invasive alien plants in the wild. Comput. Electron. Agric. 2020, 174, 105519. [Google Scholar] [CrossRef]
- Hiary, H.; Saadeh, H.; Saadeh, M.; Yaqub, M. Flower classification using deep convolutional neural networks. IET Comput. Vis. 2018, 12, 855–862. [Google Scholar] [CrossRef]
- Bae, K.I.; Park, J.; Lee, J.; Lee, Y.; Lim, C. Flower classification with modified multimodal convolutional neural networks. Expert Syst. Appl. 2020, 159, 113455. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic fruit classification using deep learning for industrial applications. IEEE Trans. Ind. Inform. 2018, 15, 1027–1034. [Google Scholar] [CrossRef]
- Steinbrener, J.; Posch, K.; Leitner, R. Hyperspectral fruit and vegetable classification using convolutional neural networks. Comput. Electron. Agric. 2019, 162, 364–372. [Google Scholar] [CrossRef]
- Obeso, A.M.; Benois-Pineau, J.; Acosta, A.Á.R.; Vázquez, M.S.G. Architectural style classification of Mexican historical buildings using deep convolutional neural networks and sparse features. J. Electron. Imaging 2016, 26, 011016. [Google Scholar] [CrossRef]
- Yi, Y.K.; Zhang, Y.; Myung, J. House style recognition using deep convolutional neural network. Autom. Constr. 2020, 118, 103307. [Google Scholar] [CrossRef]
- Lin, C.W.; Lin, M.; Yang, S. SOPNet Method for the Fine-Grained Measurement and Prediction of Precipitation Intensity Using Outdoor Surveillance Cameras. IEEE Access 2020, 8, 188813–188824. [Google Scholar] [CrossRef]
- Lin, C.W.; Yang, S. Geospatial-Temporal Convolutional Neural Network for Video-Based Precipitation Intensity Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1119–1123. [Google Scholar]
- Wei, C.C.; Huang, T.H. Modular Neural Networks with Fully Convolutional Networks for Typhoon-Induced Short-Term Rainfall Predictions. Sensors 2021, 21, 4200. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.C.; Hsieh, P.Y. Estimation of hourly rainfall during typhoons using radar mosaic-based convolutional neural networks. Remote Sens. 2020, 12, 896. [Google Scholar] [CrossRef] [Green Version]
- Branson, S.; Van Horn, G.; Belongie, S.; Perona, P. Bird species categorization using pose normalized deep convolutional nets. arXiv 2014, arXiv:1406.2952. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear cnn models for fine-grained visual recognition. In Proceedings of the IEEE ICCV, Santiago, Chile, 13–16 December 2015; pp. 1449–1457. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June–01 July 2016; pp. 1933–1941. [Google Scholar]
- Zheng, H.; Fu, J.; Mei, T.; Luo, J. Learning multi-attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE ICCV, Venice, Italy, 22–29 October 2017; pp. 5209–5217. [Google Scholar]
- Wu, L.; Wang, Y.; Li, X.; Gao, J. Deep attention-based spatially recursive networks for fine-grained visual recognition. IEEE Trans. Cybern. 2018, 49, 1791–1802. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse Attention for Salient Object Detection. In Proceedings of the The European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhao, B.; Wu, X.; Feng, J.; Peng, Q.; Yan, S. Diversified visual attention networks for fine-grained object classification. IEEE Trans. Multimed. 2017, 19, 1245–1256. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; He, X.; Zhao, J. Object-part attention model for fine-grained image classification. IEEE Trans. Image Process. 2017, 27, 1487–1500. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; Technical Report; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Li, F.F. 3d object representations for fine-grained categorization. In Proceedings of the IEEE ICCV Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Wei, X.S.; Xie, C.W.; Wu, J.; Shen, C. Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognit. 2018, 76, 704–714. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE CVPR, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-Based R-CNNs for Fine-Grained Category Detection. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Lin, D.; Shen, X.; Lu, C.; Jia, J. Deep lac: Deep localization, alignment and classification for fine-grained recognition. In Proceedings of the IEEE CVPR, Boston, MA, USA, 7–12 June 2015; pp. 1666–1674. [Google Scholar]
- Wang, D.; Shen, Z.; Shao, J.; Zhang, W.; Xue, X.; Zhang, Z. Multiple granularity descriptors for fine-grained categorization. In Proceedings of the IEEE ICCV, Santiago, Chile, 13–16 December 2015; pp. 2399–2406. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE CVPR, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Zhou, F.; Lin, Y. Fine-grained image classification by exploring bipartite-graph labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June–1 July 2016; pp. 1124–1133. [Google Scholar]
- Zhang, Y.; Wei, X.S.; Wu, J.; Cai, J.; Lu, J.; Nguyen, V.A.; Do, M.N. Weakly supervised fine-grained categorization with part-based image representation. IEEE Trans. Image Process. 2016, 25, 1713–1725. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Luo, T.; Wang, D.; Hu, Z.; Gao, J.; Wang, L. Learning to navigate for fine-grained classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 420–435. [Google Scholar]
- Dubey, A.; Gupta, O.; Guo, P.; Raskar, R.; Farrell, R.; Naik, N. Pairwise confusion for fine-grained visual classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 70–86. [Google Scholar]
- Zheng, H.; Fu, J.; Zha, Z.J.; Luo, J. Looking for the devil in the details: Learning trilinear attention sampling network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5012–5021. [Google Scholar]
- Huang, Z.; Li, Y. Interpretable and Accurate Fine-grained Recognition via Region Grouping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Liu, X.; Xia, T.; Wang, J.; Lin, Y. Fully convolutional attention localization networks: Efficient attention localization for fine-grained recognition. arXiv 2016, arXiv:1603.06765. [Google Scholar]
- Huang, S.; Xu, Z.; Tao, D.; Zhang, Y. Part-stacked cnn for fine-grained visual categorization. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1173–1182. [Google Scholar]
- Moghimi, M.; Belongie, S.J.; Saberian, M.J.; Yang, J.; Vasconcelos, N.; Li, L.J. Boosted Convolutional Neural Networks. In Proceedings of the the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; pp. 24.1–24.13. [Google Scholar]
- Wang, Y.; Choi, J.; Morariu, V.; Davis, L.S. Mining discriminative triplets of patches for fine-grained classification. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1163–1172. [Google Scholar]
- Li, Z.; Yang, Y.; Liu, X.; Zhou, F.; Wen, S.; Xu, W. Dynamic computational time for visual attention. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1199–1209. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Cai, S.; Zuo, W.; Zhang, L. Higher-order integration of hierarchical convolutional activations for fine-grained visual categorization. In Proceedings of the IEEE ICCV, Venice, Italy, 22–29 October 2017; pp. 511–520. [Google Scholar]
- Wang, Y.; Morariu, V.I.; Davis, L.S. Learning a discriminative filter bank within a cnn for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4148–4157. [Google Scholar]
- Li, P.; Xie, J.; Wang, Q.; Gao, Z. Towards faster training of global covariance pooling networks by iterative matrix square root normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 947–955. [Google Scholar]
- Xin, Q.; Lv, T.; Gao, H. Random Part Localization Model for Fine Grained Image Classification. In Proceedings of the IEEE ICIP, Taipei, Taiwan, 22–25 September 2019; pp. 420–424. [Google Scholar]
- Chen, Y.; Bai, Y.; Zhang, W.; Mei, T. Destruction and construction learning for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5157–5166. [Google Scholar]
- Ji, R.; Wen, L.; Zhang, L.; Du, D.; Wu, Y.; Zhao, C.; Liu, X.; Huang, F. Attention convolutional binary neural tree for fine-grained visual categorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10468–10477. [Google Scholar]
- Li, X.; Monga, V. Group based deep shared feature learning for fine-grained image classification. In Proceedings of the the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019; pp. 143.1–143.13. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | CUB200-2011 | Stanford Cars | FGVC Aircraft | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plans | I | II | I | II | I | II | |||||||||||||
| Sample | X(%) | Y(%) | (%) | X(%) | Y(%) | (%) | X(%) | Y(%) | (%) | X(%) | Y(%) | (%) | X(%) | Y(%) | (%) | X(%) | Y(%) | (%) | |
| #Fold | |||||||||||||||||||
| 1 | 89.63 | 89.45 | 0.18 | 86.78 | 86.57 | 0.21 | 95.82 | 95.73 | 0.09 | 94.40 | 94.14 | 0.26 | 93.75 | 93.45 | 0.30 | 91.50 | 90.70 | 0.80 | |
| 2 | 89.63 | 89.32 | 0.31 | 87.34 | 86.91 | 0.43 | 95.16 | 95.06 | 0.10 | 94.52 | 94.08 | 0.44 | 93.95 | 93.25 | 0.70 | 91.20 | 91.00 | 0.20 | |
| 3 | 89.20 | 88.72 | 0.48 | 86.35 | 86.22 | 0.13 | 95.50 | 95.47 | 0.03 | 94.40 | 94.37 | 0.03 | 94.05 | 93.10 | 0.95 | 90.80 | 90.65 | 0.15 | |
| 4 | 89.32 | 89.24 | 0.08 | 86.44 | 86.10 | 0.34 | 95.57 | 95.35 | 0.22 | 95.09 | 94.71 | 0.38 | 94.00 | 93.65 | 0.35 | 91.05 | 90.65 | 0.40 | |
| 5 | 90.40 | 90.27 | 0.13 | 87.56 | 87.26 | 0.30 | 95.47 | 95.25 | 0.22 | 94.71 | 94.21 | 0.50 | 94.75 | 94.20 | 0.55 | 91.90 | 91.10 | 0.80 | |
| Sig. (2-tailed) | 0.031 | 0.006 | 0.025 | 0.018 | 0.009 | 0.029 | |||||||||||||
| Registering Stream | None | OS | WS | OS + WS |
|---|---|---|---|---|
| Accuracy (Top-1, %) | 87.2 | 87.5 | 87.5 | 87.7 |
| Registering Position | Conv.-1 | DB-1 | DB-2 | DB-3 | DB-4 |
|---|---|---|---|---|---|
| Size of feature map | 112 × 112 | 56 × 56 | 28 × 28 | 14 × 14 | 7 × 7 |
| Accuracy (Top-1, %) | 86.8 | 87.7 | 87.2 | 87.4 | 86.9 |
| Method | Year | Source | Dimension | Size | Accuracy | ||
|---|---|---|---|---|---|---|---|
| CUB200-2011 | Stanford Cars | FGVC-Aircraft | |||||
| PB R-CNN [26] | 2014 | ECCV[C] | 12,288 | 224 × 224 | 82.0% | - | - |
| Pose Normalized CNNs [13] | 2014 | CVPR[C] | 13,512 | - | 85.4% | - | - |
| Deep-LAC [27] | 2015 | CVPR[C] | 12,288 | 227 × 227 | 80.3% | - | - |
| MG-CNN [28] | 2015 | ICCV[C] | 12,288 | 224 × 224 | 83.0% | - | 86.6% |
| Two-level Attention [29] | 2015 | CVPR[C] | - | 224 × 224 | 77.9% | - | - |
| VGG-BGL [30] | 2016 | CVPR[C] | 4096 | 224 × 224 | 80.4% | 90.5% | - |
| Weakly Supervised FG [31] | 2016 | TIP[J] | - | 224 × 224 | 79.3% | - | - |
| NTS [32] | 2018 | ECCV[C] | 10,240 | 224 × 224 | 87.5% | 93.9% | 91.4% |
| PC [33] | 2018 | ECCV[C] | - | 224 × 224 | 86.9% | 92.9% | 89.2% |
| TASN [34] | 2019 | CVPR[C] | 2048 | 224 × 224 | 87.0% | 93.8% | - |
| Interp [35] | 2020 | CVPR[C] | 2048 | 256 × 256 | 87.3% | - | - |
| ST-CNN [36] | 2015 | NIPS[C] | 4096 | 448 × 448 | 84.1% | - | - |
| Bilinear CNN [14] | 2015 | ICCV[C] | 262,144 | 448 × 448 | 85.1% | 91.3% | 84.1% |
| FCAN [37] | 2016 | CVPR[C] | 1,536 | 448 × 448 | 84.3% | 91.3% | - |
| Part-Stacked CNN [38] | 2016 | CVPR[C] | 4096 | 454 × 454 + 227 × 227 | 76.6% | - | - |
| Boost-CNN [39] | 2016 | BMVC[C] | 262,144 | 448 × 448 | 86.2% | 92.1% | 88.5% |
| MDTP [40] | 2016 | CVPR[C] | 4096 | 500 × 500 | - | 92.5% | 88.4% |
| DT-RAM [41] | 2017 | ICCV[C] | 2048 | 448 × 448 | 86% | 93.1% | - |
| RA-CNN [42] | 2017 | CVPR[C] | 4096 | 448 × 448 + 224 × 224 | 85.3% | 92.5% | - |
| HIHCA [43] | 2017 | ICCV[C] | - | 448 × 448 | 85.3% | 91.7% | 88.3% |
| Mask-CNN [24] | 2018 | PR[J] | 12,288 | 448 × 448 | 87.3% | - | - |
| DFL [44] | 2018 | CVPR[C] | 2048 | 448 × 448 | 87.4% | - | - |
| iSQRT-COV [45] | 2018 | CVPR[C] | 32,896 | 448 × 448 | 88.7% | 93.3% | 91.4% |
| RP-CNN [46] | 2019 | ICIP[C] | 4096 | 448 × 448 + 224 × 224 | 84.5% | 93.0% | 89.9% |
| DCL [47] | 2019 | CVPR[C] | 2048 | 448 × 448 | 87.8% | 94.5% | 93.0% |
| ACNet [48] | 2020 | CVPR[C] | 8192 | 448 × 448 | 87.6% | 93.5% | 90.4% |
| GSFL-Net [49] | 2020 | BMVC[C] | 12,801 | 448 × 448 | 87.6% | 93.9% | 88.2% |
| Ours | 2021 | - | 4096 | 224 × 224 | 87.7% | 94.5% | 93.8% |
| Dataset | CUB200-2011 | Stanford Cars | FGVC Aircraft | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Information | Overall Info. | Whole-Body Info. | Torso Info. | Head Info. | Overall Info. | Whole-Body Info. | Side Info. | Back Info. | Overall Info. | Whole-body Info. | Head Info. | Back Info. | |
| Visualization | |||||||||||||
| Input images |  |  |  |  |  |  |  |  |  |  |  |  | |
| Feature maps |  |  |  |  |  |  |  |  |  |  |  |  | |
| Registering feature maps |  |  |  | ||||||||||
| Dataset | Model | Original Image | DB-1 | RF | DB-2 | DB-3 | DB-4 |
|---|---|---|---|---|---|---|---|
| CUB200-2011 | Ours |  |  |  |  |  |  |
| DenseNet |  |  |  |  |  | ||
| Stanford Cars | Ours |  |  |  |  |  |  |
| DenseNet |  |  |  |  |  | ||
| FGVC Aircraft | Ours |  |  |  |  |  |  |
| DenseNet |  |  |  |  |  |
| Input Information | Model | Top-1 (%) |
|---|---|---|
| Overall | DenseNet-121 | 76.7 |
| Whole-body | DenseNet-121 | 83.4 |
| Head | DenseNet-121 | 76.6 |
| Torso | DenseNet-121 | 71.6 |
| All | DenseNet-121 | 87.2 |
| All | OR-Net | 87.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-W.; Lin, M.; Liu, J. Object–Part Registration–Fusion Net for Fine-Grained Image Classification. Symmetry 2021, 13, 1838. https://doi.org/10.3390/sym13101838
Lin C-W, Lin M, Liu J. Object–Part Registration–Fusion Net for Fine-Grained Image Classification. Symmetry. 2021; 13(10):1838. https://doi.org/10.3390/sym13101838
Chicago/Turabian StyleLin, Chih-Wei, Mengxiang Lin, and Jinfu Liu. 2021. "Object–Part Registration–Fusion Net for Fine-Grained Image Classification" Symmetry 13, no. 10: 1838. https://doi.org/10.3390/sym13101838
APA StyleLin, C.-W., Lin, M., & Liu, J. (2021). Object–Part Registration–Fusion Net for Fine-Grained Image Classification. Symmetry, 13(10), 1838. https://doi.org/10.3390/sym13101838