4.1. Comparison of the Monolithic and Structured Approaches
The decision models obtained, although they concern the same issue, have different numerical scales. The values obtained by using the structured approach, in addition to the final preferences, contain additional information on partial preferences for the evaluation of the performance, engine, and batteries of the considered freight vehicles, and the results are presented in the
Table 4.
An important issue is to know which of the analyzed approaches is more accurate. It may seem that the monolithic model could give more accurate results, but this way needs more pairwise comparisons than the structured approach. Moreover, creating intermediate models provides us with more information about the modeled decision problem. However, a large number of comparisons can influence the accuracy negatively.
Table 5 provides a complete list of reference values, obtained preferences, and rankings. The obtained preference results differ, which is natural with two different operational approaches. It should be noted, however, that the final ranking match is at a very high level. In the case of the monolithic approach, there have been two order replacements between the alternatives
and
. Besides, in the case of structured approach it was only one pair
. In both of these cases, we have quite small differences in the value of preferences, and at the same time the correlation of preferences results in both models are highly correlated with each other and amount to 0.9756, which indicates an almost linear relationship.
However, the values of preferences alone are not enough because, for the decision support system, it is more important to map the rankings correctly. Therefore, the final rankings of both approaches were compared with a reference ranking using a
and
ratio (see
Table 6). The structural approach proved to be slightly more similar to the reference ranking than the monolithic approach. However, from the results obtained, it can be concluded that both models return very strongly correlated results with reference results.
Therefore, this example proves that the structured approach does not necessarily have to be worse than the monolithic one. The high matching of rankings shows that it is important to focus on the right hierarchy of criteria. Next, it is necessary to ensure that the MEJ matrix is correctly completed. In our work, we used the knowledge from the reference article and several approaches to reduce the number of queries, which guaranteed high quality of the received models. In the next section, we propose a new way of examining the relevance of the decision criteria used.
4.2. Significance Analysis of Criteria
For a monolithic approach the most significant criteria were
,
,
,
, and
. This is important because this approach does not use the intermediate criteria
and
, and has stronger correlations than the structured approach they have. On the other hand, the least important criteria are
,
,
,
, and
. However, using the monolithic approach, another interesting study can be done by eliminating the individual criteria. In this case, it should be expected that if the change was significant, the ranking should be disturbed more strongly than in the case of an insignificant criterion. The monolithic approach will be used for this task because in the case of the structured approach it would involve a change in the hierarchy of criteria, which would be another element that could disturb the final ranking.
Figure 7 presents the visualization of correlation coefficients.
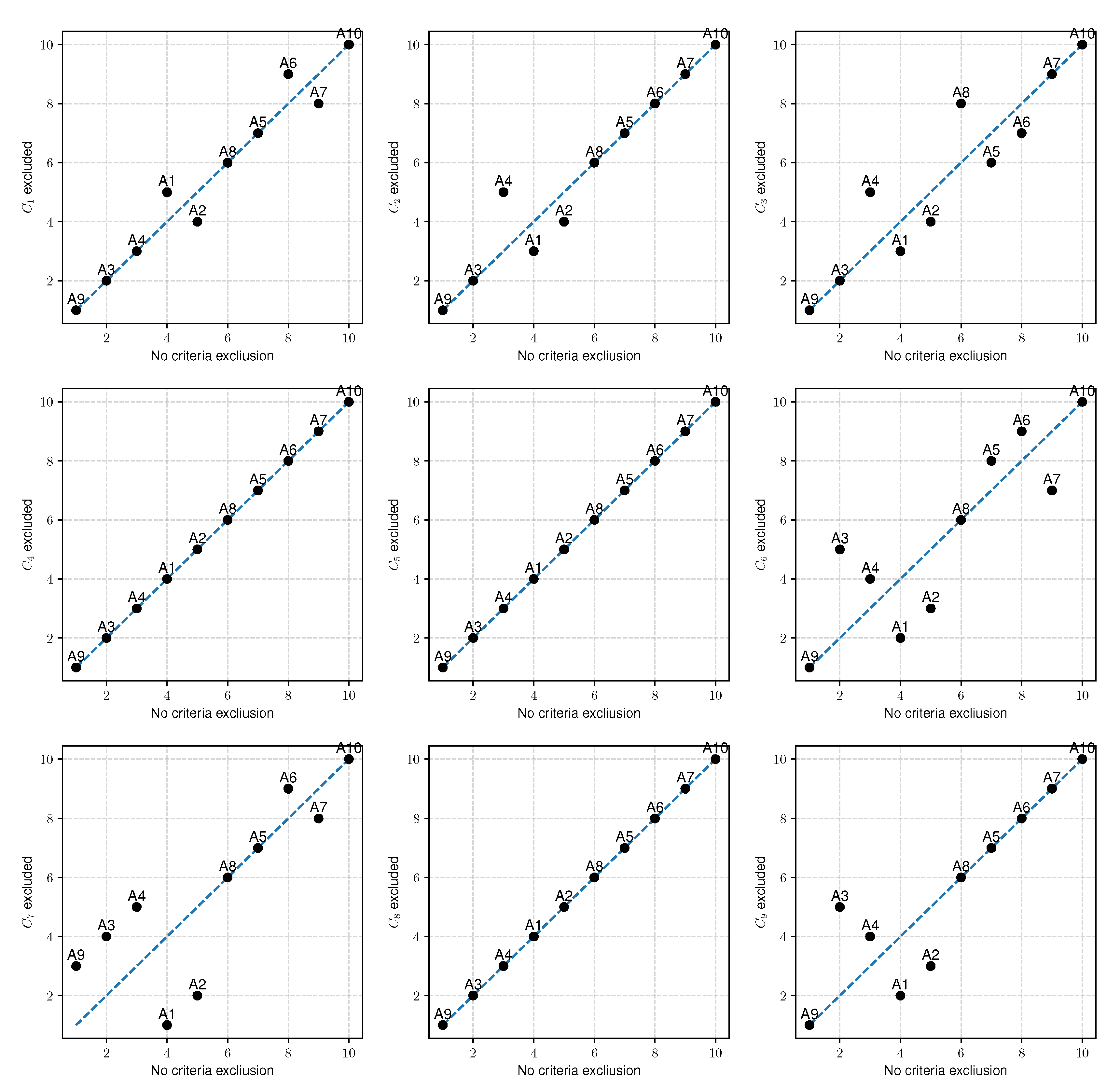
First, we build nine rankings using the monolith COMET approach, one for each criterion excluded, and we calculate
and
correlations between these rankings and ranking obtained with none criterion excluded. We also calculate the euclidean distance between vectors of the preference values, i.e., between the full set of criteria and a set of criteria with exclusions. Results are presented in
Table 7.
After the elimination of one criterion, it turned out that excluding criteria , , or does not influence the ranking. This is surprising because criterion and were indicated as the criteria with the highest relevance for the Pearson correlation coefficient analysis. However, after removing one of them, the ranking remains unchanged, and the value of and is 1. The most important criterion, i.e., the one that has the most significant influence on the change of the ranking, turned out to be the criterion , which has the smallest value in the Pearson coefficient analysis.
The second most important decision criterion is the criterion, which was also considered to be one of the less important in the Pearson’s coefficient analysis. The criteria and refer to the battery charge time, with the more critical parameter being the time it takes for the cells to recharge to 80% and the less critical parameter being a 100% charge. This is by common sense and the literature on the subject, where the most important challenge for the electric vehicles is the charging time. It depends on it whether the vehicle can move or will stand idle. The third most important criterion is , which is the cost of purchase. When we additionally analyze the distances between the vectors of the obtained preferences before and after the reduction of the number of criteria, it turns out that these criteria have the most outstanding value of distance. However, the distance itself seems to be a non-prejudicative predictor as the distance values vary from 0.1600 to 0.2093 for criteria that have not changed the ranking. It is also interesting that the ranking was not influenced by criteria related to engine parameters and battery capacity.
The next step of our analysis is to check the exclusion of all combinations for criteria
,
, and
. Despite the lack of their strong relevance, it turns out that in case of exclusion of two combinations, the model deteriorates significantly and reaches
values close to the situation when only the
criterion was excluded. In the case of subsequent exclusions, i.e., the three criteria, we have assumed results identical to those of two
and
. However, further analysis of
Table 7 shows us that distance between preference vectors is increasing with a number of criteria excluded. Therefore, the excluded triple criteria have equal rankings, but the distance between preference vectors is almost twice time bigger.
Excluding even three criteria from the monolithic COMET proved to be no more significant than removing the
criterion.
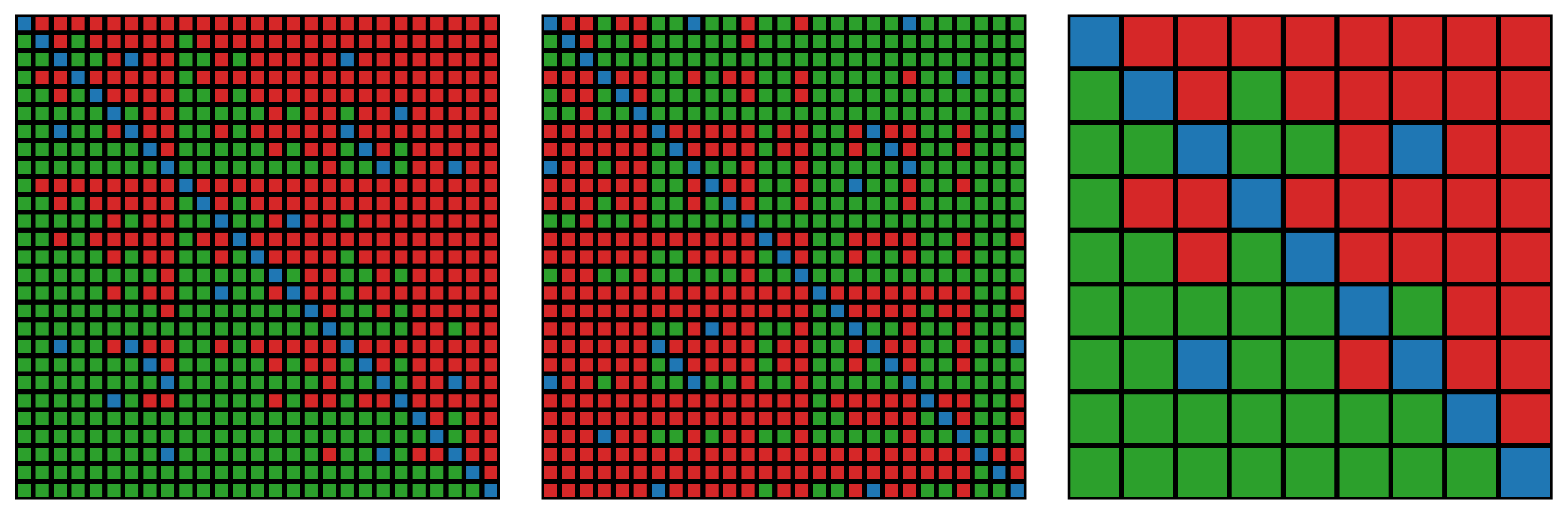
Figure 8 shows the visualization of changes taking place in the initial ranking when eliminating three criteria from the set of criteria. As it turns out, only the alternatives
and
remained in their places.
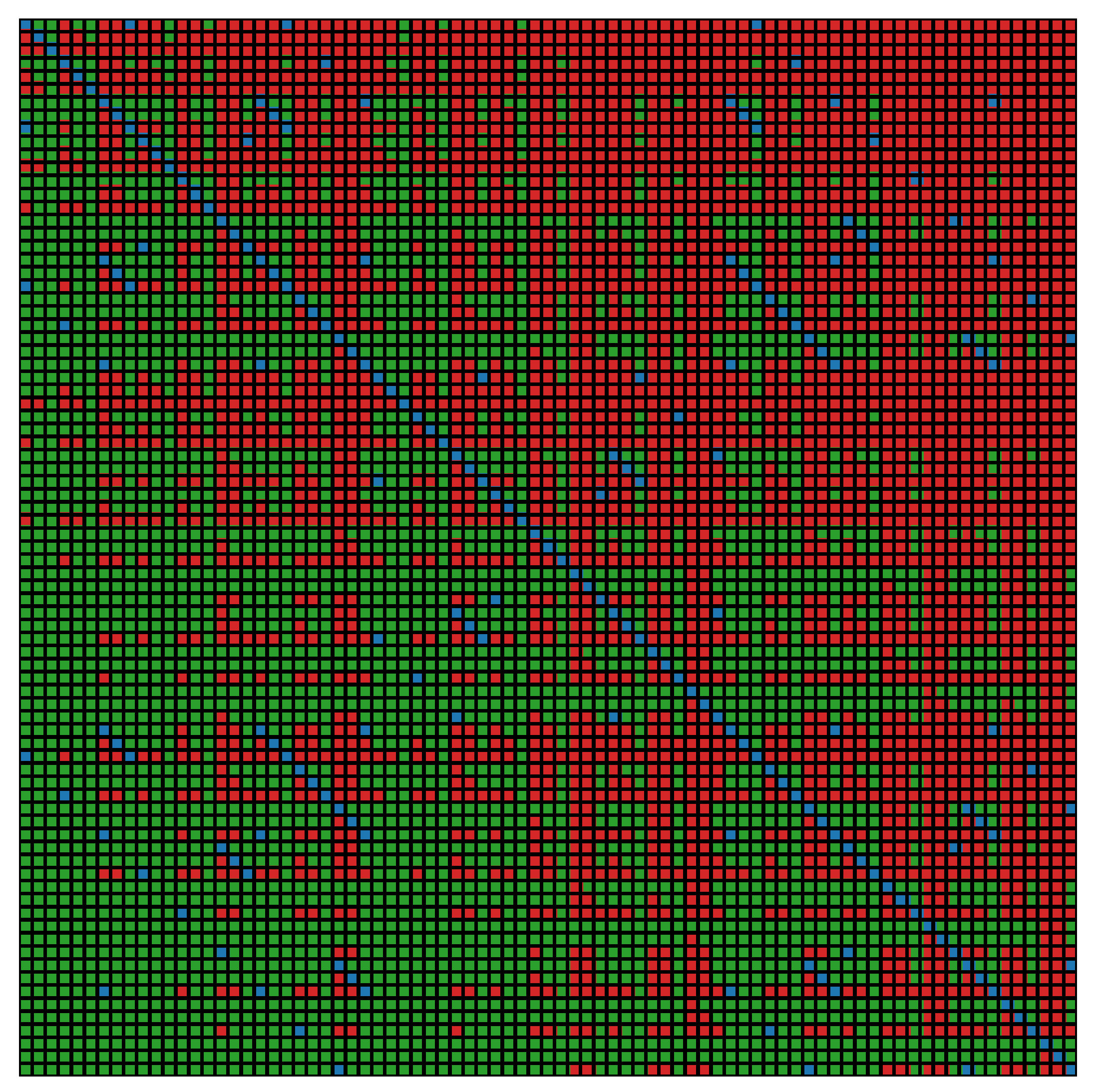
The exclusions of single criteria are presented in
Figure 9. The exclusion of criterion
causes greater changes at the top of the ranking, while the alternatives
,
, and
remain in place.
Figure 8,
Figure 9 and
Figure 10 show visualization of
and
coefficients, where we can quickly make a comparison between disordered levels.
Figure 10 shows the difference between
and
. In all three presented cases, the
ratio has a similar value. This is completely different in the case of the
coefficient, where when excluding the
and
criteria, we get a relatively high value of 0.9229.
Figure 10 shows that is because both rankings have the same top three alternatives in the ranking (
also does not change position but its importance is marginal and does not exceed
). In the other two cases, only the alternatives
and
do not change their order with respect to initial raking.
In conclusion, the most significant potential in determining the relevance of criteria has an approach in which we exclude individual criteria from the model and check the impact of this on the similarity of the obtained rankings. Useful indicators for this purpose are both the and ratio. The distance between the preference vectors may be helpful, but it is certainly not the most critical factor.
4.3. Incomplete Data
Let us assume that the decision alternative is described with partially incomplete data. There are three examples of alternatives in
Table 8, where we do not know the values for criteria
,
, and
for the alternatives
,
, and
respectively. Incomplete data makes calculations impossible in this situation because one of the input signals is missing. The only thing we can assume in such a situation is that the value of the attributes is within the scope of our model. Therefore, instead of missing data, we insert intervals that are equal to the extreme characteristic values. Data has already been entered in
Table 8. We then calculate preference values using a monolithic and structural approach by calculating all possible combinations. As a result, we get the interval of the lowest and highest possible preference.
In the purpose of ordering the alternatives evaluated by using the interval values, we will use Ishibuchi and Tanaka’s approach [
61], where if A =
and B =
are two interval profits, then the order relation
for maximization problems is defined as (
28)
We also use the order relation
for maximization problems. Let A =
and B =
be two intervals in center and radius form, then the order relation
for maximization problems is defined as (
29)
Figure 11 shows the interval results for the monolithic and structured approaches. It seems that we have achieved two different results, i.e., results with different ranking orders. However, applying the approach (
28) and (
29), respectively, we get two identical rankings, where for monolithic approach we get
and for structured approach
. Both approaches can be used for calculations with partially incomplete data. However, it should be remembered that these calculations only contain the correct result and do not represent it. This means that only one value in the interval is the real final preference.















{kind=link}
{kind=link}
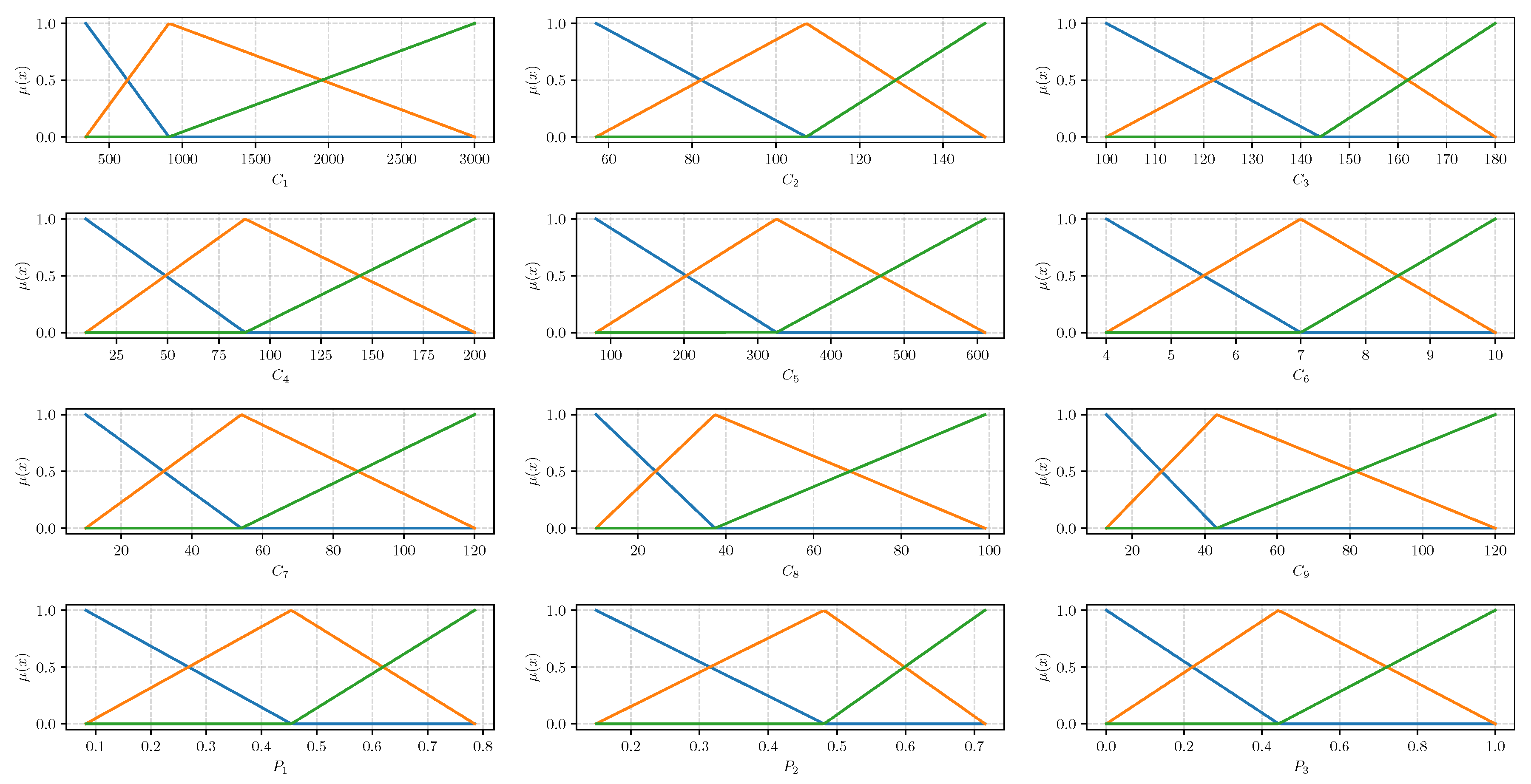{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}