1. Introduction
With the rise of China’s house prices, the issue of house price has gradually become the focus of the government, consumers, investors, and academic researchers [
1]. In urban development, house price planning is of great significance. When people conduct real estate transactions, most of them are based on field investigation and qualitative analysis, which is limited by the factors of both parties, there is no evaluation standard that can reasonably price the house itself, which will lead to unfair transaction to a certain extent [
2]. At present, China’s real estate industry is full of chaos. How to quantitatively evaluate the price of the house and determine the main factors affecting the price of the house has become a big problem [
3]. The development of public transport in the city can, to a certain extent, improve the regional economic vitality and promote the development of the real estate economy [
4]. Therefore, under the background of big data, how to use massive data to reasonably calculate the characteristic indexes to describe the real operation of public transport and subway in the city, highlight the traffic convenience of urban space area, and then explore the link between real estate economy and urban public transport development needs more in-depth research.
Traffic accessibility refers to the expression of the degree of difficulty for an object to move from one location to another through a certain mode of transportation in urban space. Different modes of travel can be subdivided into different accessibility, such as walking accessibility, bus accessibility. metro accessibility, etc. [
5]. Domestic and international scholars’ research on traffic accessibility can be traced back to the 1930s. The classical location theory provides a theoretical basis for accessibility [
6]. In 1959, Hansen proposed the gravity model method to define the concept of traffic accessibility scientifically [
7]. On the basis of this, the following scholars proposed the time–space barrier model, isoline model, competition model, spatial syntax, and other methods to define the traffic accessibility [
8]. In the application of traffic accessibility, in recent years, some researchers have introduced it into real estate economics to measure the impact of traffic facilities on real estate prices. Kangwon et al. based on the metro lines in the main urban area of Seoul, South Korea, built the Metro accessibility with the distance between the residential buildings and the metro, and studied the impact of the metro lines on the price of houses along the line [
9]. Taking Beijing as an example, Ming et al. analyzed the impact of accessibility of subway, light rail, and urban rail on land use development, and provided theoretical guidance for urban planning [
10]. Deborah et al. calculated the accessibility of public transport and subway in Guangzhou, and introduced it into the land price prediction model, and obtained good prediction accuracy [
11]. Mitra et al. studied the value of traffic accessibility in underdeveloped countries and provided suggestions for urban planning of Rajshahi city in Bangladesh [
5]. Li et al. took Beijing as an example, analyzed the relationship between subway accessibility and housing prices, and explored the impact of transportation on stabilizing housing prices and promoting residents’ employment [
12].
In model selection, in 1928, Waugh studied the price and characteristics of Boston vegetables, proposed the linear function relationship between them, and obtained the earliest Hedonic price model (HPM) [
13]. In the 1960s, Lancaster first applied HPM model to the real estate field, analyzed the relationship between user demand, house property characteristics and house price, and believed that all the property characteristics of house included the synthesis of house implied price, which provided a solid theoretical basis for the development and application of HPM in the real estate industry [
14]. In 1974, Rosen solved the problem of commodity heterogeneity through HPM and related technologies, and established the technical framework of characteristic price analysis in the real estate market [
15]. Li Xinru and others used the logarithmic HPM model to predict and analyze the house price when evaluating the benchmark price of urban land [
16]. Gao et al. found that factors including spatial features can improve the accuracy of HPM model [
17].
Since the beginning of the 21st century, thanks to the improvement of computer hardware technology and the rapid development of software technology, many machine learning algorithms have emerged in the era of big data. Random forest algorithm (RF), gradient lifting regression tree algorithm (GBDT), and lightweight gradient lift algorithm (LGBM) have very good performance in regression prediction and classification prediction. P. Durganjali et al. took the data set of the Kaggle competition website as an example, respectively constructed the logistic regression model, the stochastic forest model, the decision tree model, etc. to predict the house price, among which the prediction accuracy of the stochastic forest model is as high as 86.5% [
18]. Dong Qian et al. applied the RF model to analyze the trend of housing price changes in 16 large and medium-sized cities in China in 2011, but the research scope was too large and the amount of data was too small to obtain further accurate conclusions [
19]. Yang Bowen and others used GBDT algorithm and RF algorithm to build house price prediction models based on the house attribute data of California, USA. Although the root mean square error of the model is low and the prediction accuracy is good, it takes a long time to calculate the data and takes up more memory. At the same time, the generalization ability of the experimental results is low due to the small number of samples and feature dimensions [
20]. LGBM introduces a histogram acceleration algorithm on the basis of GBDT to ensure a certain prediction accuracy while increasing the speed of the model. Compared with GBDT that needs to load the data set every time it fits the residuals and consumes memory for a long time, LGBM performs better in terms of running time and memory usage. It is very suitable for industrial-grade massive data processing [
21]. Although the LGBM model improves the calculation speed and reduces the memory usage, the LGBM model reduces the accuracy of predicting housing prices [
22]. Based on the above considerations, in order to improve data computing efficiency, reduce memory usage, and improve housing price prediction accuracy, we merge RF, GBDT, and LGBM, and propose a model fusion model (Stacking) for housing price prediction in Xi’an, China.
Banerjee D and others summarized a variety of machine learning algorithms, and predicted the trend of urban housing prices [
23]. Vineeth N and other machine learning algorithms are applied to analyze the house price and its influencing factors [
24]. Phan et al. Used machine learning algorithm to predict the trend of house prices based on the historical transaction prices in Melbourne, Australia [
25].
In the study of housing price forecasting model, in addition to model selection, we also need to consider characteristic factors. Brueckner et al. analyzed the impact of urban planning related factors under macro policies on real estate prices in 1987 [
26]. Evans et al. analyzed the impact on the house price from the surrounding environmental factors such as the surrounding school distribution and public infrastructure construction [
27]. Malpezzi mainly studies the impact of commercial economic vitality in urban areas on housing prices [
28]. Diaz et al. analyzed the impact of rail transit layout on real estate prices [
29]. Wu Wenjie et al. studied the influence of four factors on house price in terms of transportation, life, work convenience, and environmental facility convenience [
30].
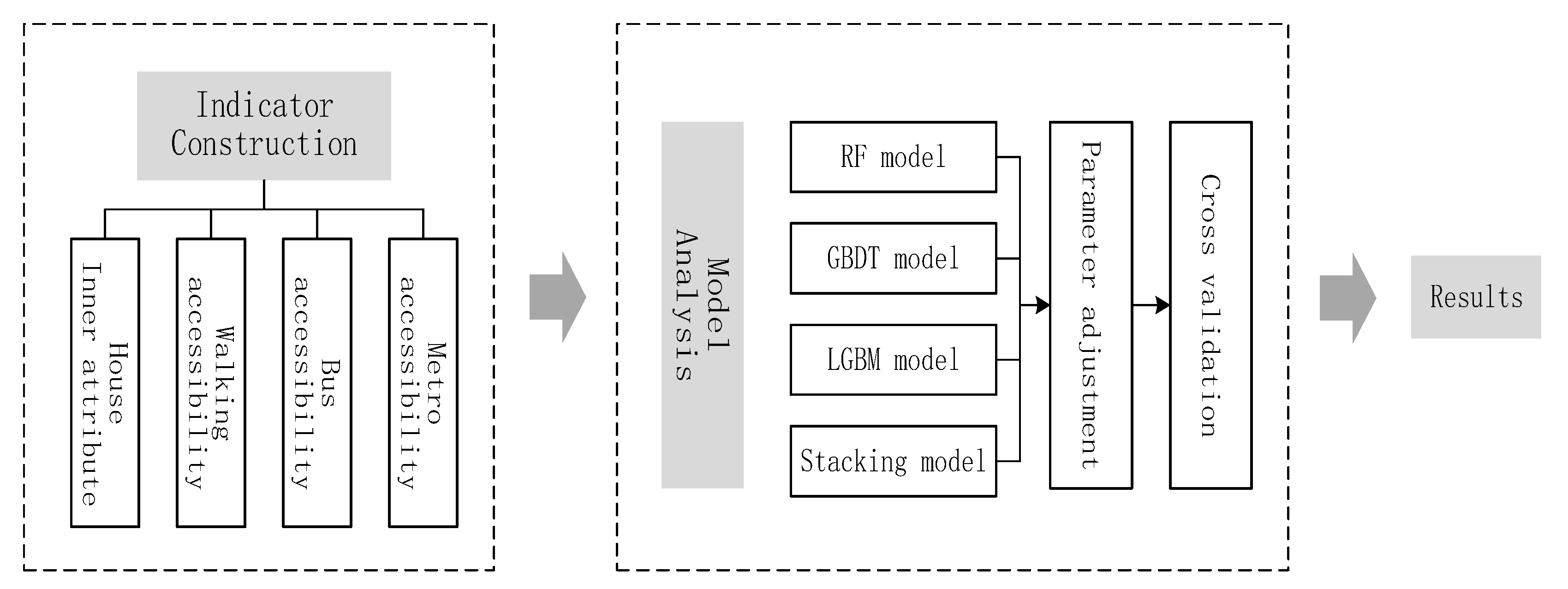
In this paper, taking Xi’an as an example, by collecting and analyzing the data of housing attributes, urban public transport and subway in Xi’an, the author constructs three kinds of characteristic indexes of house internal attribute factors, location factors, traffic accessibility factors and surrounding environment factors, with 20 kinds of characteristics, constructs the house price prediction model combining with a variety of machine learning algorithms, explores the causes and influencing factors of house price.
3. Experimental Results
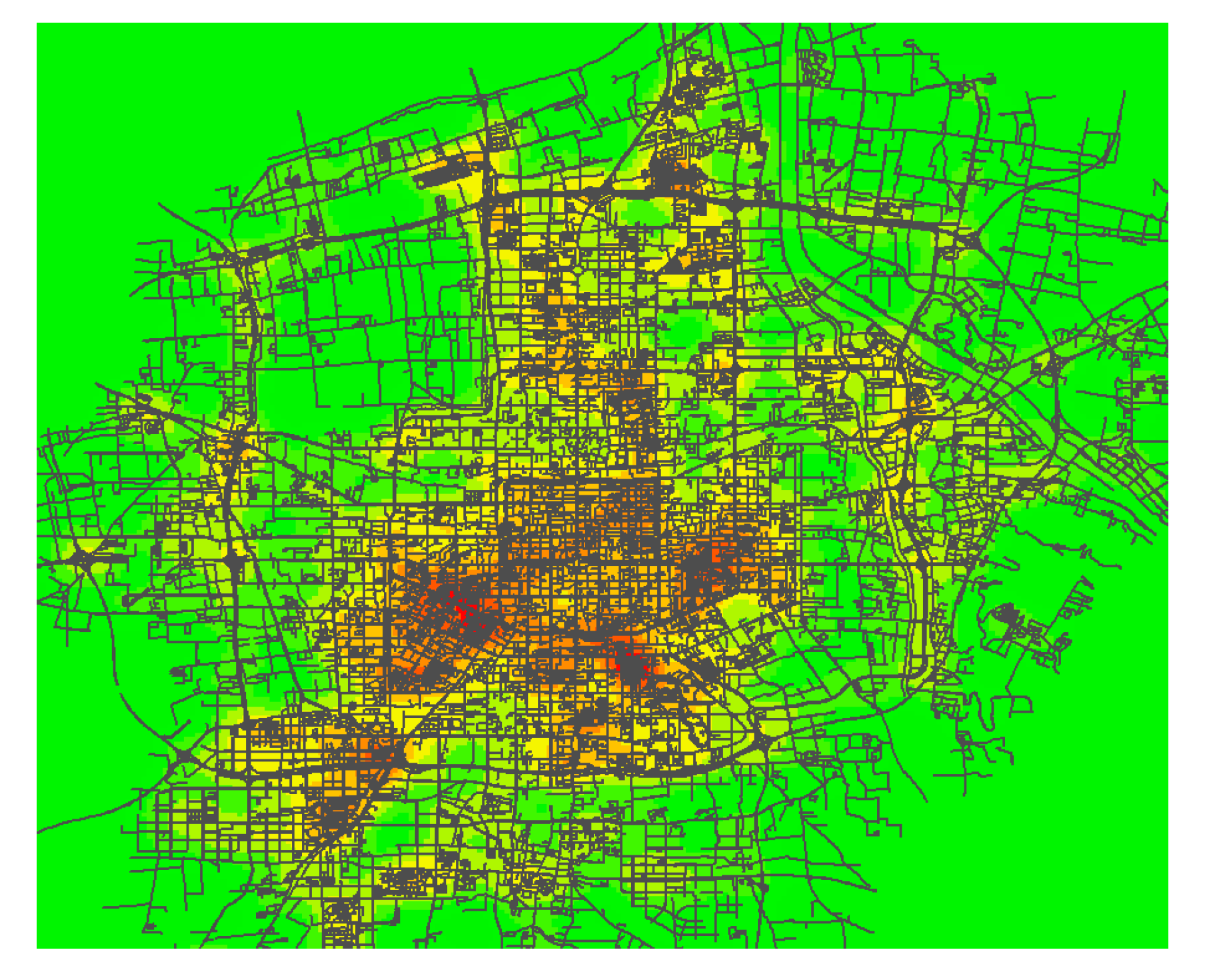
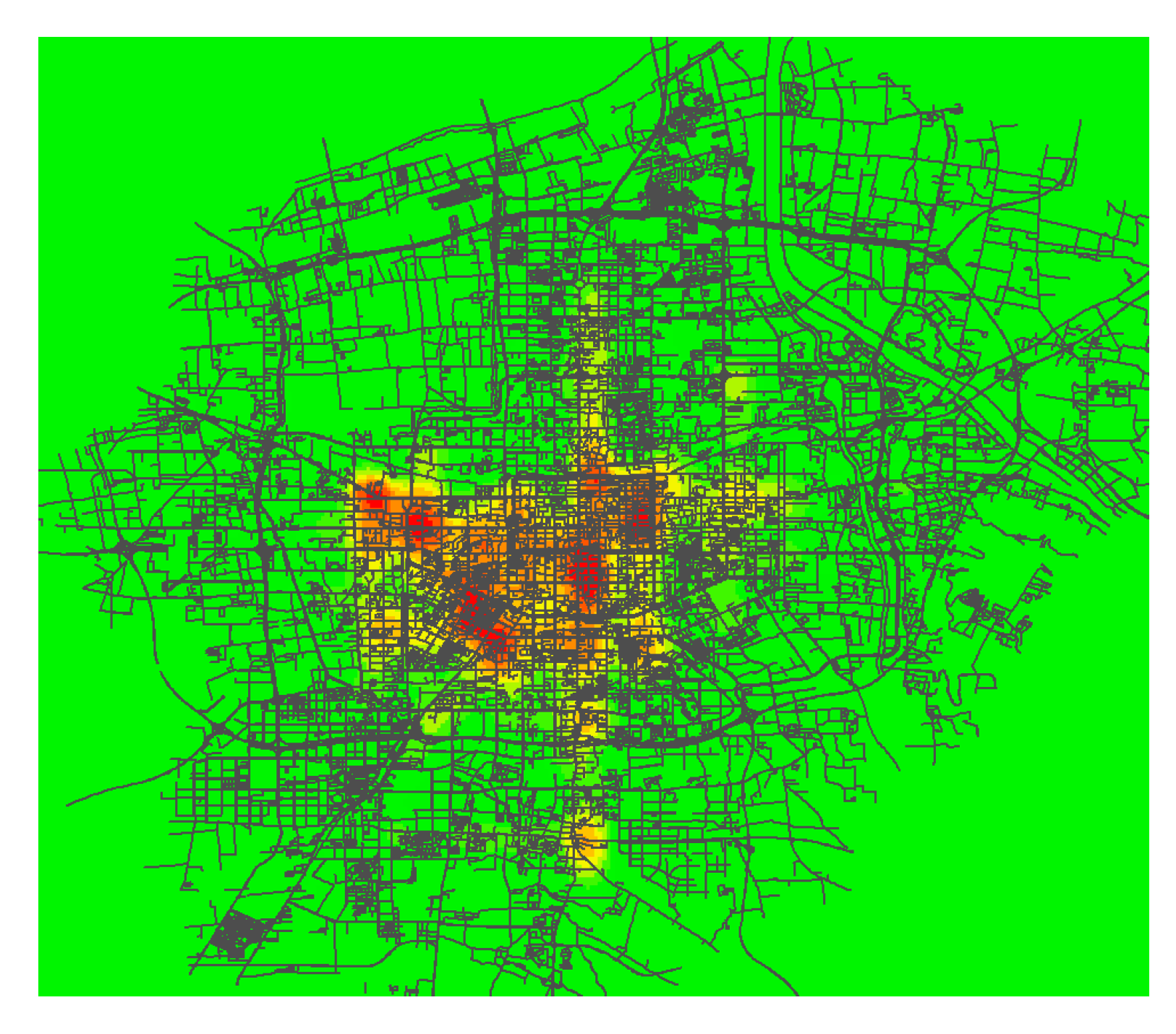
The walking accessibility, bus accessibility, and metro accessibility indexes are related to the house property form, and the data used to analyze the house price are obtained. Using the RF, GDBT, LGBM, and Stacking algorithms of machine learning algorithm to build the housing price prediction model. First of all, divide the data set into two groups, one group takes the traffic accessibility calculated by the spatial syntax theory as the traffic characteristic index. Second, the two groups of data sets are respectively applied to four machine learning algorithms to build the housing price prediction model, and the optimal model is selected through five indexes, including the prediction accuracy R², root mean square error RMSE, model volume, model training time, and prediction time. Finally, the optimal models under the two sets of data are compared and analyzed to determine the merits of the traffic accessibility calculation, and the final housing price prediction model is determined, which provides the model basis for the subsequent application research.
3.1. Real Estate Price Estimation for RF
The process of building a real estate price prediction model based on the random forest algorithm (RF) is: firstly, the training set data is put into the model, and adjust the parameters of random forest. Secondly, K-fold cross validation is introduced to judge whether the model is over fitted, and the average validation accuracy and error of the model are obtained. Finally, save the model, and the price is predicted with the test set data to get the prediction accuracy of the model. Among them, Equations (5) and (6) are used to evaluate the accuracy and error of the model.
represents the number of samples;
represents the real value of the
sample;
represents the predicted value of the
sample; and
represents the mean value of the samples.
is used to measure the prediction accuracy of the algorithm model, the closer the value is to 0, the more inaccurate it is, and the closer the value is to 1, the more accurate it is. RMSE is the root mean square error, and the smaller the value is, the better the model is.
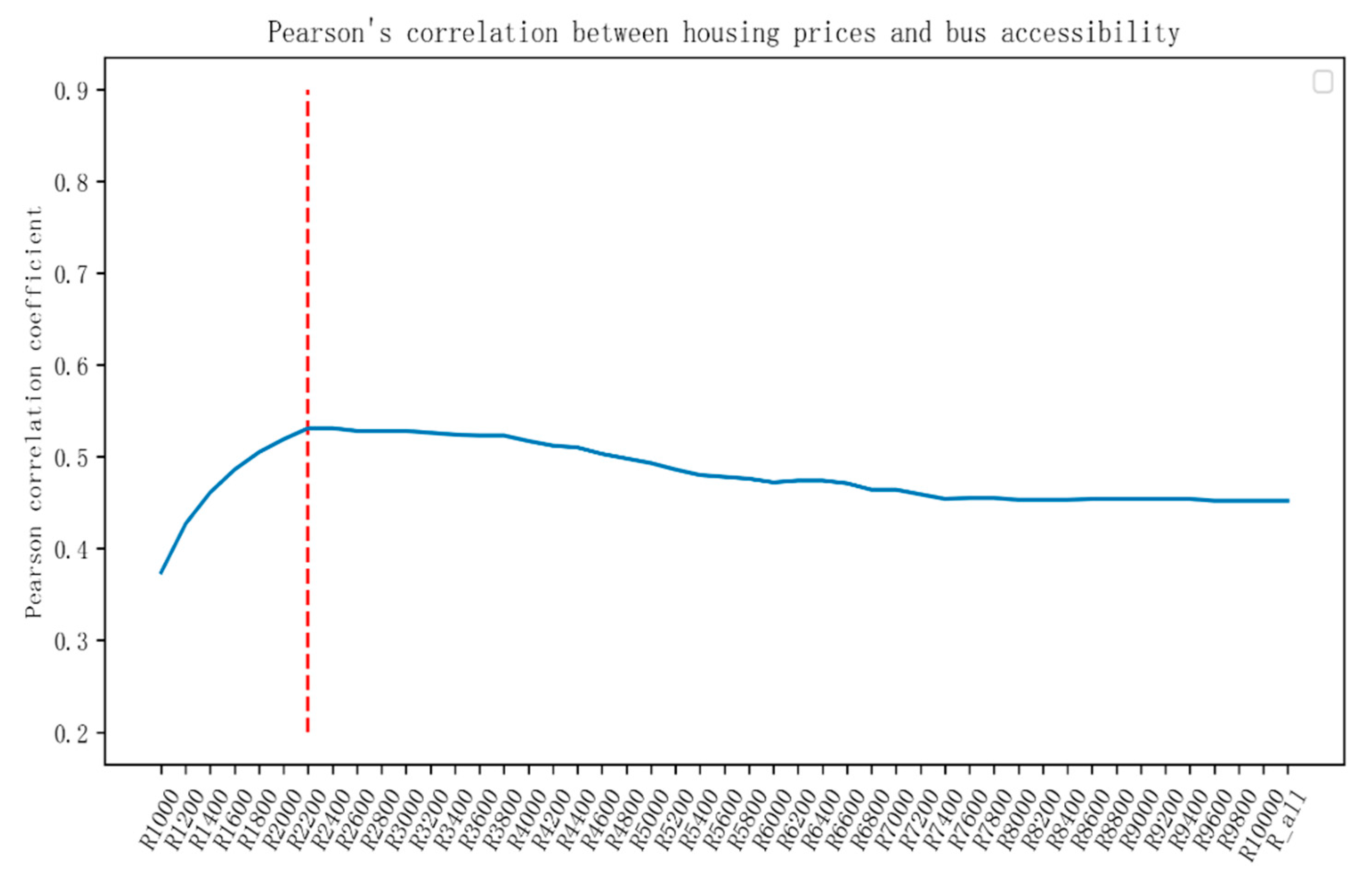
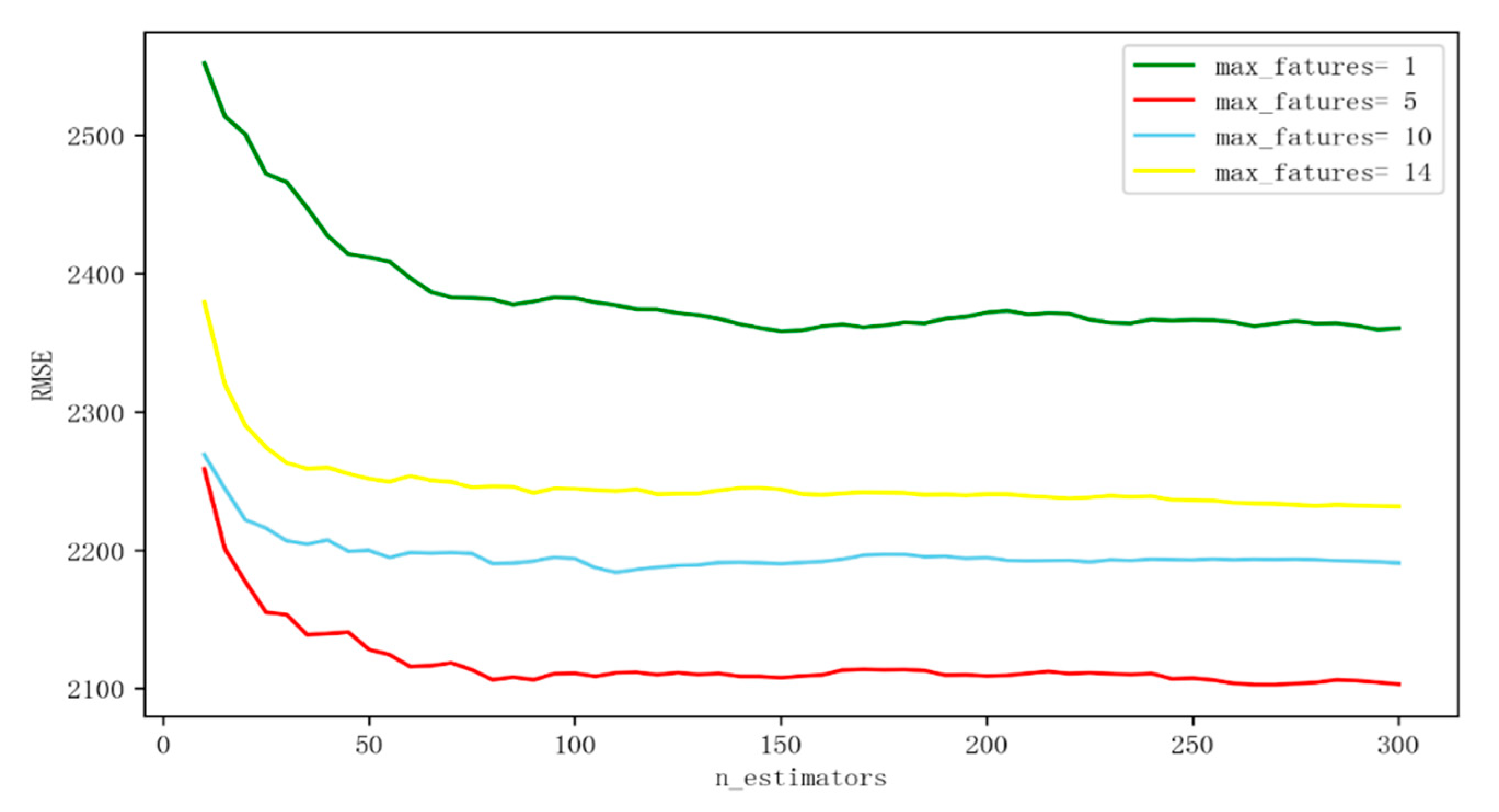
First, adjust the model parameters. In the RF algorithm, the mesh parameters of n_estimators and max_features are adjusted, and the other parameters are the default values. Based on RMSE, the parameter adjustment diagram is shown in
Figure 12.
In
Figure 12, the abscissa represents the number of trees in the random forest, and the ordinate represents the root mean square error. It can be seen that the error tends to be stable when the n_estimators is greater than 150, and the effect of the model is better when the max_features = 5. Therefore, n_estimators = 150 and max_features = 5 are selected as the fixed parameters of the RF model.
Secondly, K-fold Cross Validation is used in the process of model parameter adjustment to prevent model over fitting. In this paper, K = 10 is selected, and the training set is randomly divided into 10 parts. 9 of them are taken as the training set each time, and the remaining 1 is taken as the verification set. After training the model for 10 times, the training accuracy and root mean square error of 10 times are shown in
Table 1 below.
According to the results in
Table 1, in the 10 verifications of the model, there is no obvious low prediction accuracy, and the average prediction accuracy of the model reaches 0.8852. This shows that it has a good prediction ability, and there is no over fitting. Therefore, the current trained RF model is used as the housing price prediction model, and the model is saved.
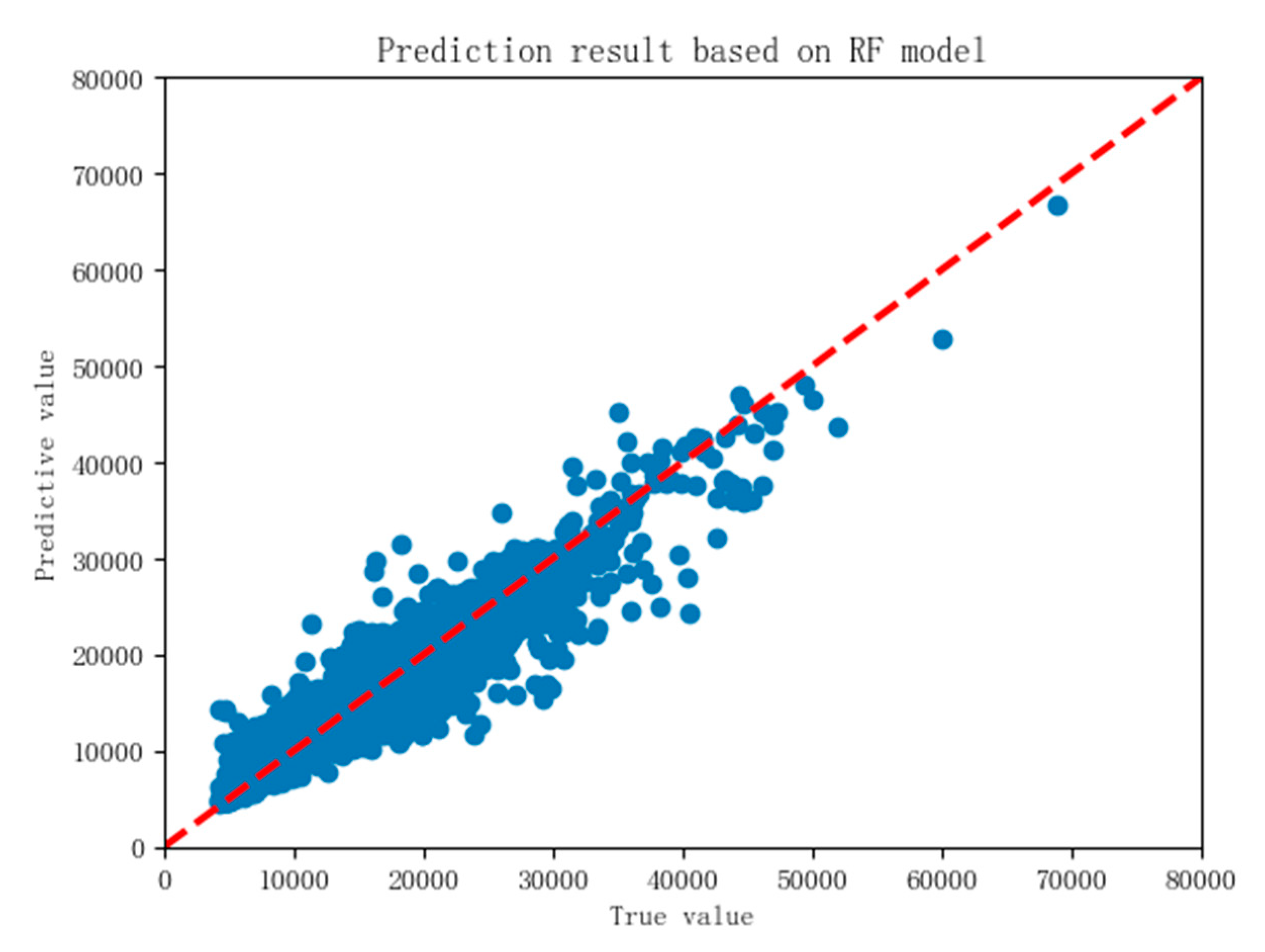
Finally, the RF model is tested with 30% of the test set data separated in advance, because the test set data does not participate in the model training at all, the data results have certain objectivity. Put the test set data into the RF housing price prediction model, and the final scatter diagram of the prediction results is shown in
Figure 13, the R² score is 0.891 and the RMSE is 1776.79.
In
Figure 13, the abscissa represents the real value of the house price, and the ordinate represents the predicted value of the house price. When the point distribution is closer to the center line, the closer the predicted value is to the real value, the smaller the error between them is, and the higher the prediction accuracy of the model is. From the prediction results, when the house price is less than 25,000, the points have a good distribution, concentrated near the middle line, and the prediction results are very good. When the house price is more than 30,000, the distribution of points is relatively discrete, which shows that the prediction results are general, which is due to the fact that the data of high house price in the sample is relatively small. From the whole point of view, the points are basically distributed along the diagonal, which shows that the predicted value is not much different from the real value, and the prediction result of the model on the test set is good.
3.2. Real Estate Price Estimation for GBDT
The process of building house price prediction model based on gradient lifting regression tree algorithm (GBDT) is similar to that of random forest. It is also divided into three parts: parameter adjustment, cross validation and result prediction. There are three parameters to be adjusted in this model, namely n_estimators, max_features, and learning_rate. The method of parameter adjustment is the same as that of random forest. Finalize n_estimators = 46, max_features = 15, learning_rate = 0.5, the model has the best performance. At the same time, through the K-fold Cross Validation, the model is judged to be over fitted, and the results under the cross validation are shown in
Table 2.
According to the results in
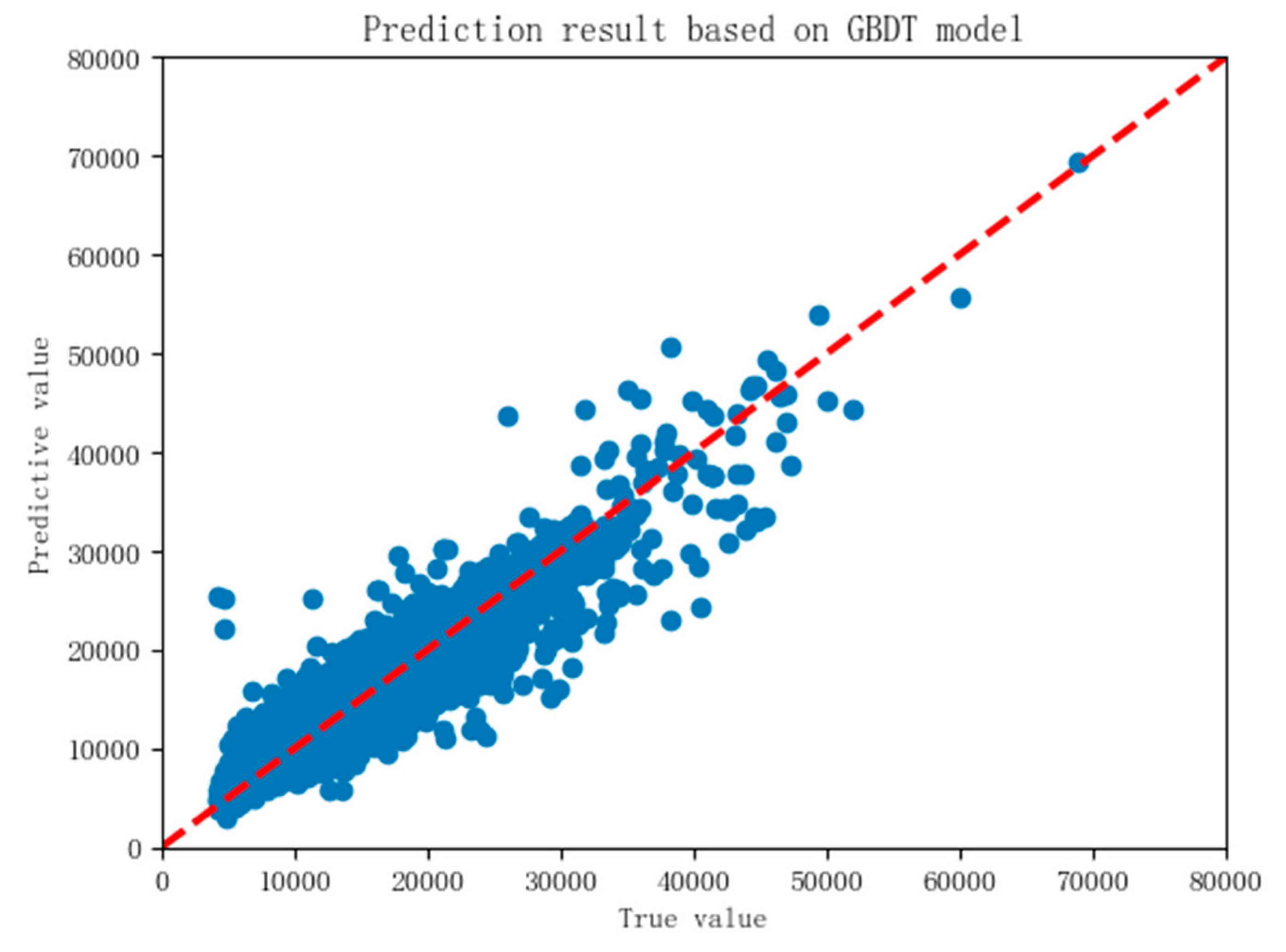
Table 2, in the 10 verifications of GBDT model, there is no obvious case of low prediction accuracy, and the average prediction accuracy of the model has reached 0.8632. This shows that it has a good prediction ability, and there is no over fitting. Therefore, the current trained GBDT model is used as the housing price prediction model, and save the model. Finally, the price prediction model based on GBDT algorithm is used to predict the test set data. The predicted results are shown in
Figure 14. The R² score is 0.863 and the RMSE is 1979.78.
In
Figure 14, scattered points are basically distributed along the middle line, showing a “shuttle” shape, which shows that GBDT algorithm can make a good prediction of house price. However, from the perspective of model accuracy, GBDT is not as good as RF in predicting housing prices.
3.3. Real Estate Price Estimation for LGBM
The building process of the housing price prediction model based on lightweight gradient lift algorithm (LGBM) is to adjust the parameters first. The three parameters to be adjusted are n_estimators, feature_fraction, and learning_rate, the rest of the parameters use the default value. After adjusting the parameters by the grid parameter adjustment method, it is found that when n_estimators = 350, feature_fraction = 0.25, learning_rate = 0.1, the model performs best. The next step is K-fold Cross Validation. The validation results are shown in
Table 3 below.
According to the results in
Table 3, the price prediction model based on LGBM has not been fitted, and the average prediction accuracy for the validation set is 0.8503, which is inferior to RF and GBDT models. Next, send the test set into the model for prediction, and the predicted results are shown in
Figure 15. The R² score was 0.873 and the RMSE was 1912.71.
It can be seen from
Figure 15 that the prediction result of the model is good, slightly lower than that of RF. In terms of accuracy and error, it deviates from the researcher’s prediction.
3.4. Real Estate Price Estimation for Stacking
When building the housing price prediction model of stacking algorithm, we need to determine the number of building layers, basic learners, and meta learners. In this paper, we used a two-tier model, and take RF, GBDT, and LGBM as the basic learners, and multiple linear regression as the meta learners to build the housing price prediction model.
Because the first three models are fused, the parameters of the model follow the previous results.
Table 4 shows the results of Stacking algorithm under K-fold (K = 10) Cross Validation.
According to the results in
Table 4, the housing price prediction model based on Stacking has not been fitted, and it performs well for the prediction of the validation set. After saving the model, because the meta model is encapsulated by multiple linear regression equation, the function expression is obtained as shown in Equation (7).
In Equation (7),
represents the housing price predicted by the Stacking algorithm,
represents the predicted value of RF model,
represents the predicted value of GBDT model, and
represents the predicted value of LGBM model. In the formula, the input features have the same dimension, so their coefficients can be considered as the proportion of each model in the Stacking algorithm. The model is used to predict the test set data. The forecast results are shown in
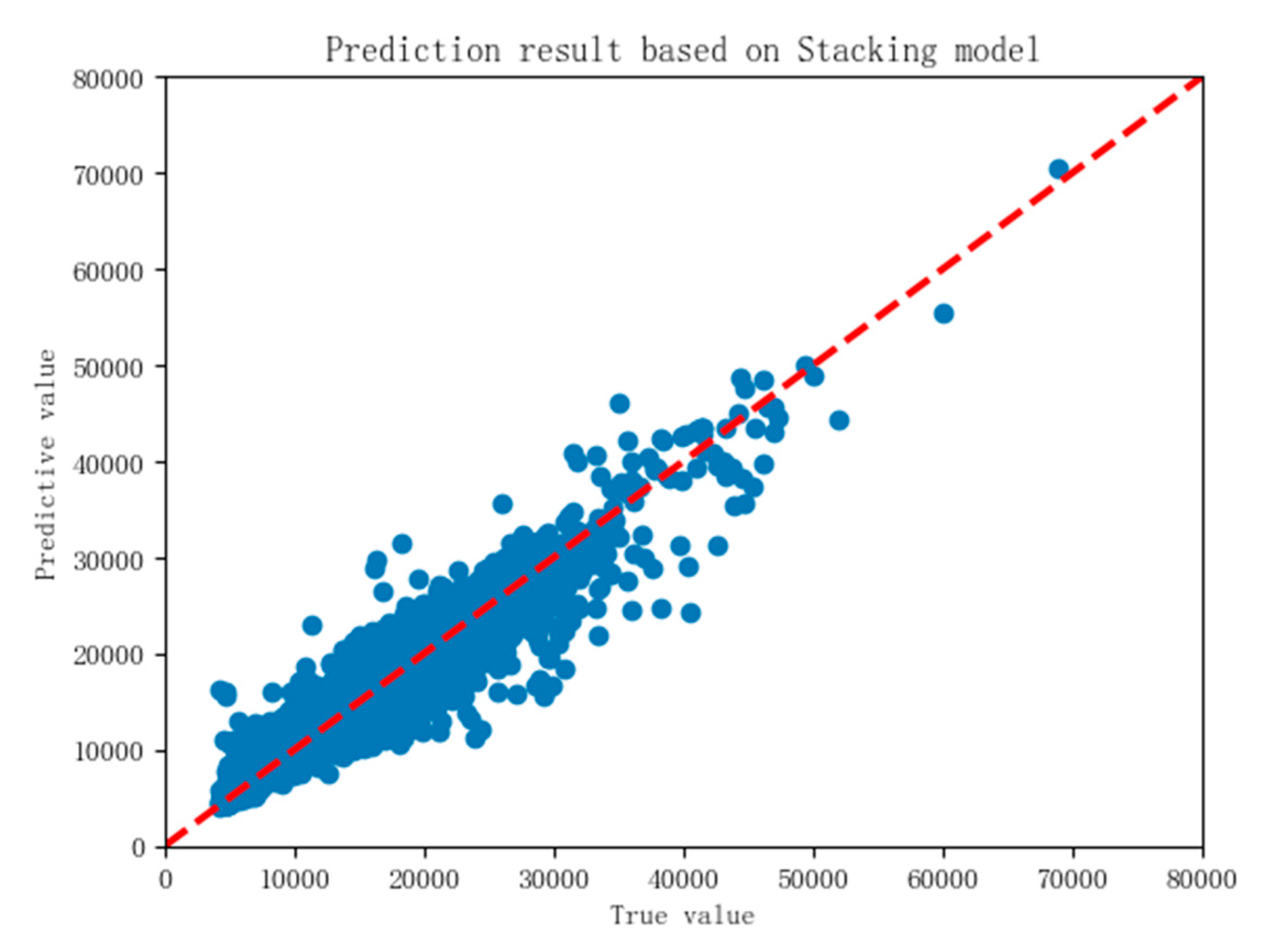
Figure 16 below, where the R²score is 0.892 and RMSE is 1761.84.
According to the prediction results in
Figure 16, the accuracy of housing price prediction model based on stacking is significantly higher than that of GBDT and LGBM single model, slightly higher than that of RF, and the error is lower. The performance of the model is better, which shows that the model stacking method can improve the accuracy of the model to a certain extent. However, in the process of model building, it takes longer.
3.5. Model Comparison
In the previous research, four kinds of house price prediction models are built according to RF algorithm, GBDT algorithm, GBDT algorithm and Stacking algorithm. Then, four models will be compared and analyzed to determine the optimal housing price prediction model. Next, we will make a comparative analysis from five aspects: model accuracy, model error, model scale, model training time, and model running time.
Table 5 shows the comparison of various effects of four models. Among them, model size refers to the space size of the generated model. Model training time refers to the time that each model uses 20,426 pieces of training data to build a model. Model running time refers to the time taken to predict 8754 test set data with the model.
In terms of model prediction accuracy and error, Stacking algorithm is superior to the other three, but in terms of real-time performance of model operation, because Stacking algorithm integrates the other three models, the complexity of the model is higher, so the real-time performance is very poor. The prediction accuracy of LGBM algorithm is slightly lower than that of Stacking algorithm, better than RF and GBDT algorithm, and it is the best in real-time performance. In practical application, although the prediction accuracy is important, but also we need to ensure the real-time prediction, so we can consider the housing price prediction model based on RF algorithm. In this paper, the analysis of housing price is still in the stage of theoretical research, it need to better ensure the accuracy of the model, so finally choose the housing price prediction model based on the stacking algorithm as the final model of the follow-up study.
4. Discussion
Although 3.5 determines the best housing price prediction model, and also proves the superiority of calculating traffic accessibility through spatial syntax, however in order to better explore the impact of traffic on housing price, the content of this section will analyze the common characteristics of the model based on the proportion of the characteristics of the four types of machine learning algorithms previously determined.
Figure 17 shows the importance percentage of each of the 20 features of the four models in the model building process.
It can be found from the characteristic importance proportion in
Figure 17 that in the four models, the importance proportion of house area is the largest. In addition, the traffic factors, which are composed of road network accessibility, bus accessibility and metro accessibility calculated by spatial syntax, also account for a large proportion of the importance of the model. After statistics, the proportion of traffic factors in the four models is 21.043%, 20.71%, 22.04%, and 21.68% respectively. This shows that in the housing price analysis, traffic has a great influence on the housing price, which is one of the important factors that cannot be ignored.
To sum up, the spatial syntax theory has more advantages than the simple distance calculation. Three indexes, pedestrian accessibility, public transportation accessibility, and subway accessibility, which are calculated by space syntax theory, cannot be ignored for the impact of house price, and they play a very important role in the building process of house price prediction model.
5. Conclusions
In this study, three characteristic indexes of walking accessibility, bus accessibility and metro accessibility are calculated, which are introduced into the influencing factors of real estate price, and four machine algorithms are used to predict the real estate price in the whole city, good prediction results have been obtained. The research results show that the traffic accessibility calculated according to the space syntax theory can truly reflect the operation of walking, bus and metro in the city, and accurately represent the convenience of public transport in different areas of the city. The walking accessibility and traffic accessibility are introduced into the housing price prediction analysis, and the prediction accuracy of the model reaches 89.2%, At the same time, the important contribution of traffic accessibility to the model reaches nearly 30%, which shows that urban public transport factors have an important impact on urban housing prices
In the model selection, only the relevant algorithms of machine learning are selected for comparative analysis. In recent years, deep learning, neural network, and other model algorithms have better development. In the follow-up research, more and more extensive algorithms will be considered to build the housing price prediction model.
In the future, the research will be carried out from three aspects: first, a more detailed description of the traffic accessibility index. In this paper, the calculation of the bus accessibility index does not fully reflect the real situation, because the actual operation route data of the bus is not obtained, so it is only replaced by the shortest path. Secondly, it is believed that the factors affecting the real estate price are far more than the 24 features mentioned in the paper, we hoped that more influencing factors can be taken into consideration to further improve the model accuracy and prediction effect. Thirdly, it is hoped that the development of urban public transport can be cross studied with other fields, such as location planning of urban business district, medical treatment, school, etc., to explore more possibilities of urban public transport for promoting the vigorous development of the city.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}