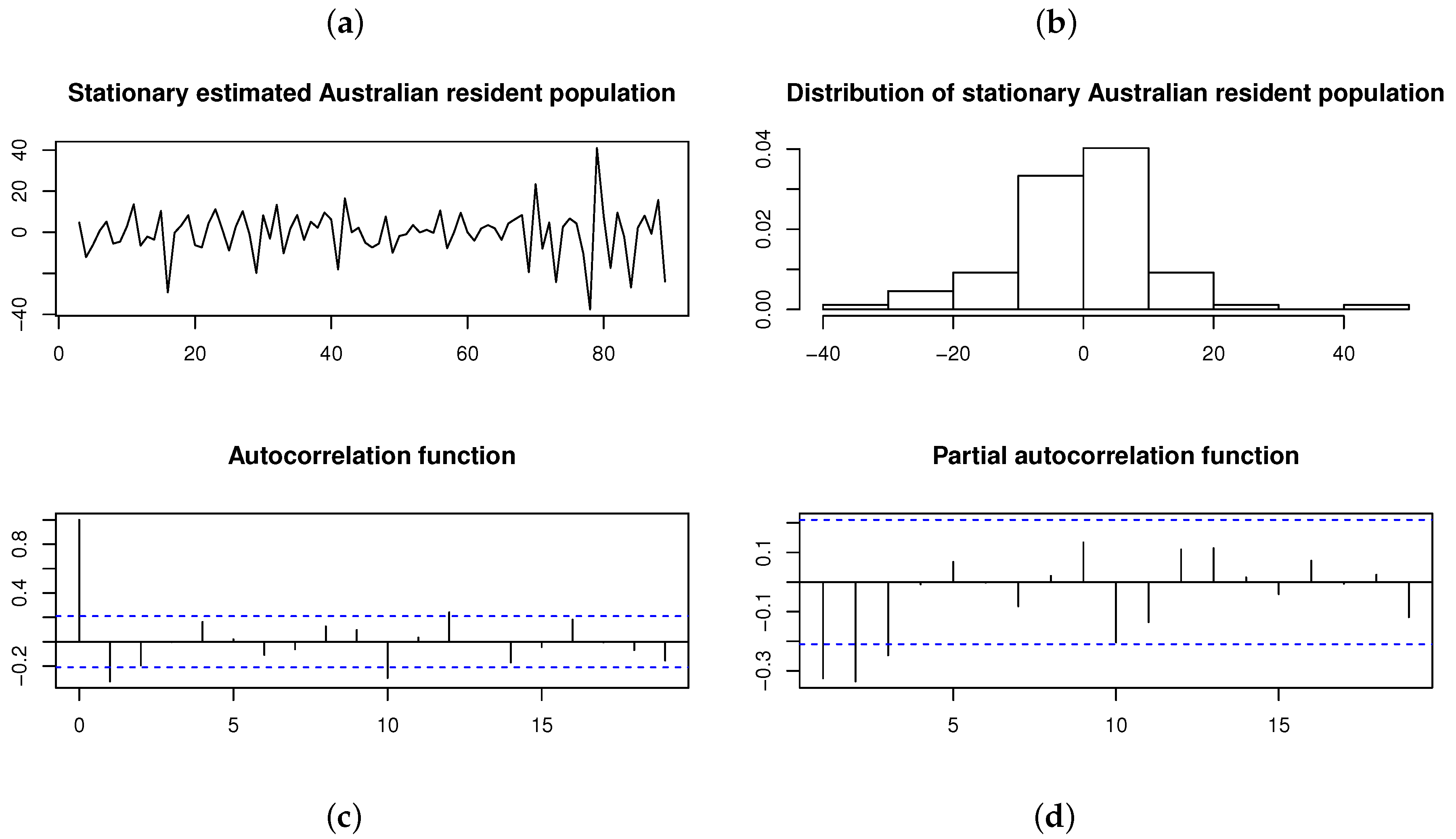
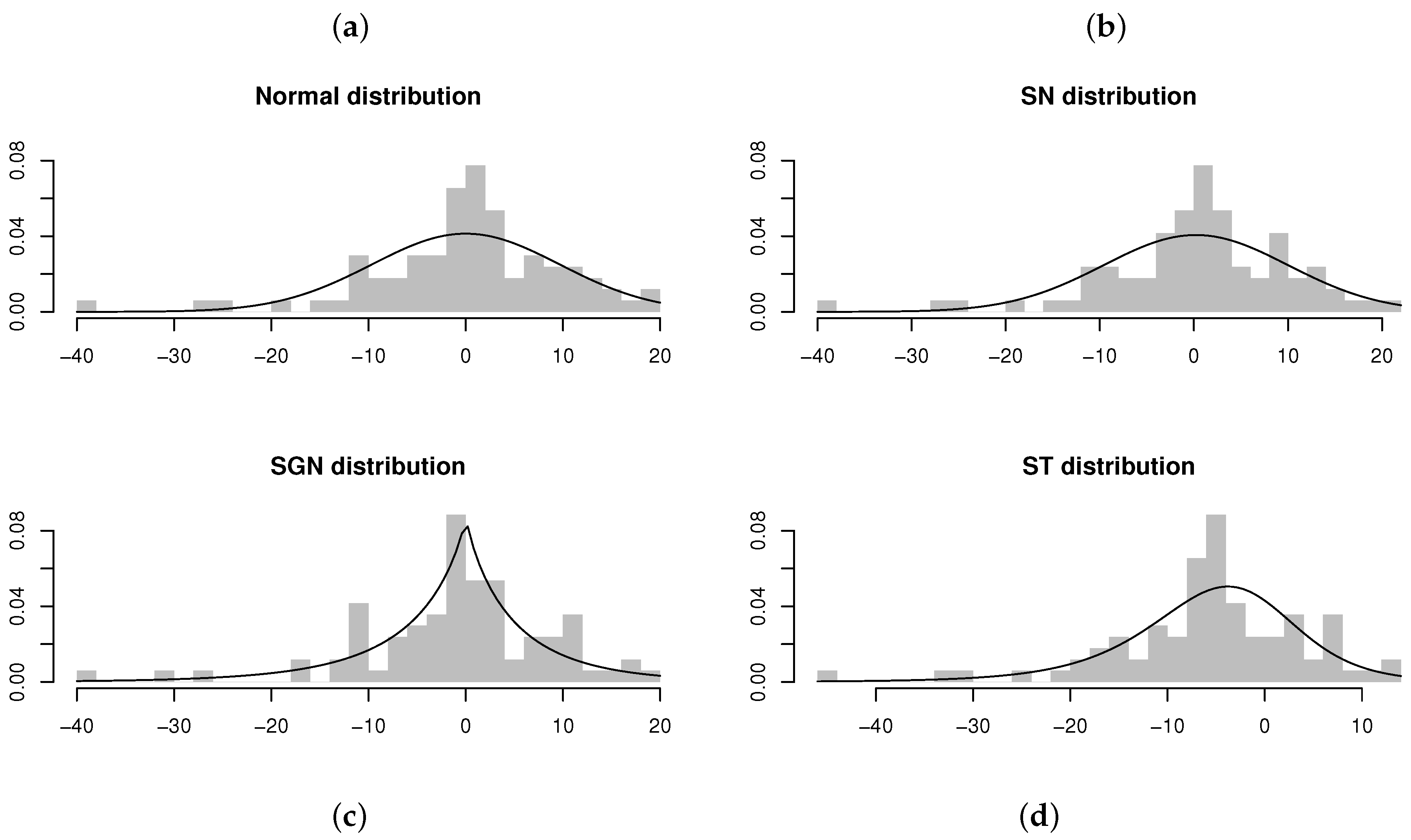
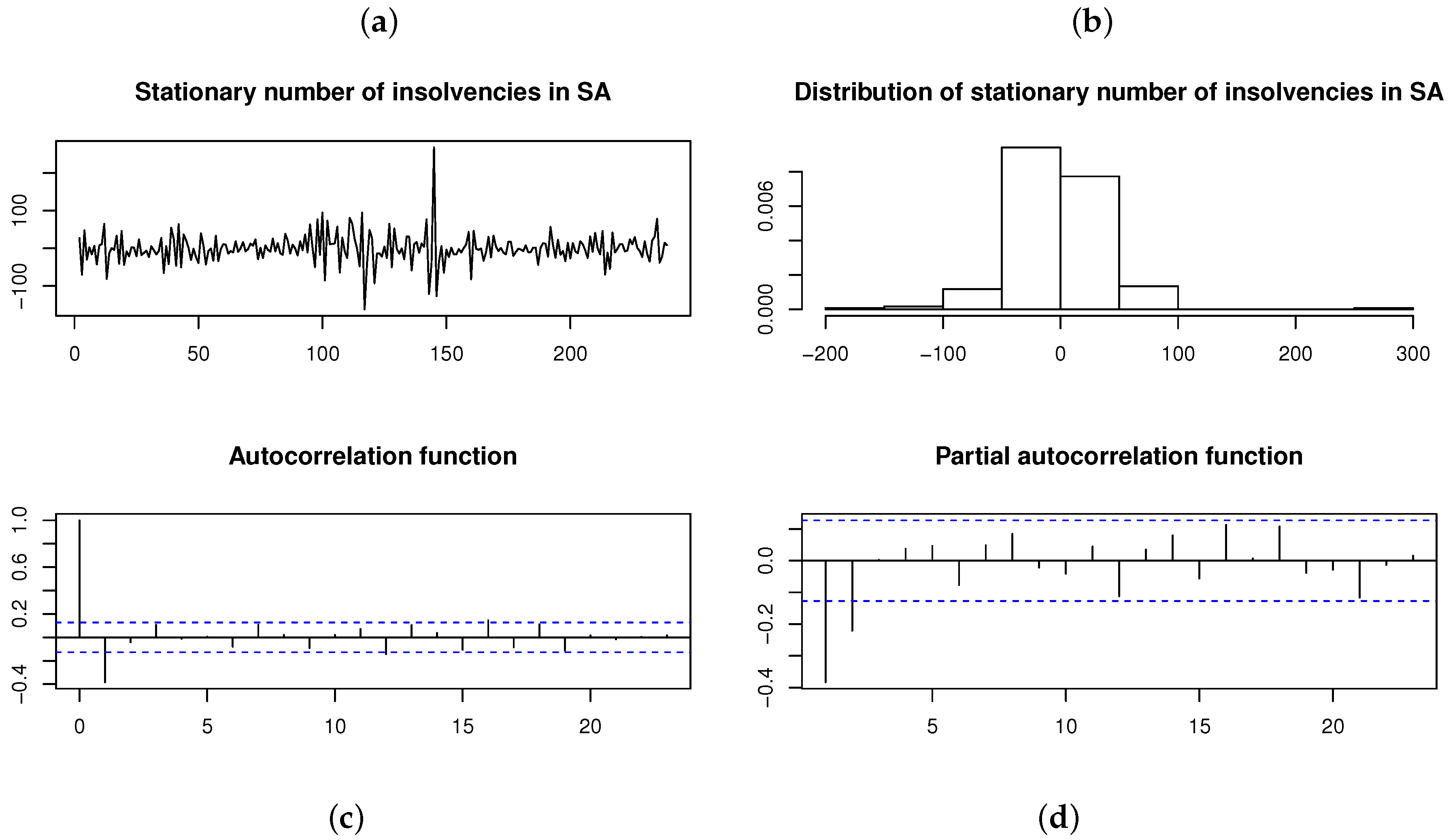
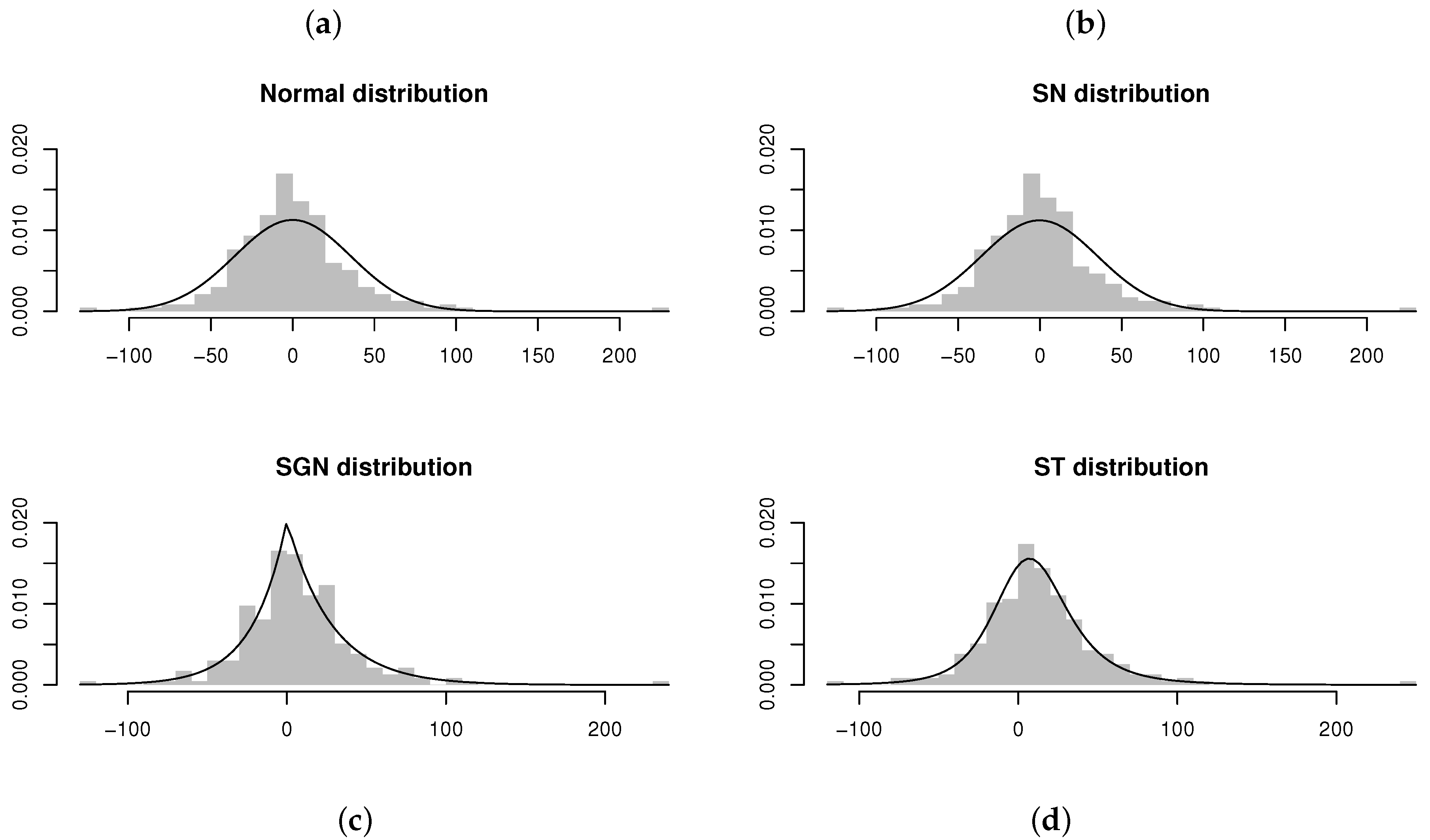
1. Introduction
The autoregressive (AR) model is one of the simplest and most popular models in the time series context. The AR(
p) time series process
is expressed as a linear combination of
p finite lagged observations in the process with a random innovation structure for
and is given by:
where
are known as the
p AR parameters. The process mean (i.e., mean of
) for the AR(
p) process in (
1) is given by
. Furthermore, if all roots of the characteristic equation:
are greater than one in absolute value, then the process is described as stationary (which is considered for this paper). The innovation process
in (
1) represents white noise with mean zero (since the process mean is already built into the AR(
p) process) and a constant variance, which can be seen as independent “shocks” randomly selected from a particular distribution. In general, it is assumed that
follows the normal distribution, in which case the time series process
will be a Gaussian process [
1]. This assumption of normality is generally made due to the fact that natural phenomena often appear to be normally distributed (examples include age and weights), and it tends to be appealing due to its symmetry, infinite support, and computationally efficient characteristics. However, this assumption is often violated in real-life statistical analyses, which may lead to serious implications such as bias in estimates or inflated variances. Examples of time series data exhibiting asymmetry include (but are not limited to) financial indices and returns, measurement errors, sound frequency measurements, tourist arrivals, production in the mining sector, and sulphate measurements in water.
To address the natural limitations of normal-behavior, many studies have proposed AR models characterized by asymmetric innovation processes that were fitted to real data illustrating their practicality, particularly in the time series environment. The traditional approach for defining non-normal AR models is to keep the linear model (
1) and let the innovation process
follow a non-normal process instead. Some early studies include the work of Pourahmadi [
2], considering various non-normal distributions for the innovation process in an AR(1) process such as the exponential, mixed exponential, gamma, and geometric distributions. Tarami and Pourahmadi [
3] investigated multivariate AR processes with the
t distribution, allowing for the modeling of volatile time series data. Other models abandoning the normality assumption have been proposed in the literature (see [
4] and the references within). Bondon [
5] and, more recently, Sharafi and Nematollahi [
6] and Ghasami et al. [
7] considered AR models defined by the epsilon-skew-normal (
), skew-normal (
), and generalized hyperbolic (
) innovation processes, respectively. Finally, AR models are not only applied in the time series environment: Tuaç et al. [
8] considered AR models for the error terms in the regression context, allowing for asymmetry in the innovation structures.
This paper considers the innovation process
to be characterized by the skew generalized normal (
) distribution (introduced in Bekker et al. [
9]). The main advantages gained from the
distribution include the flexibility in modeling asymmetric characteristics (skewness and kurtosis, in particular) and the infinite real support, which is of particular importance in modeling error structures. In addition, the
distribution adapts better to skewed and heavy-tailed datasets than the normal and
counterparts, which is of particular value in the modeling of innovations for AR processes [
7].
The focus is firstly on the
distribution assumption for the innovation process
. Following the skewing methodology suggested by Azzalini [
10], the
distribution is defined as follows [
9]:
Definition 1. Random variable X is characterized by the distribution with location, scale, shape, and skewing parameters , and λ, respectively, if it has probability density function (PDF):where , , and . This is denoted by . Referring to Definition 1,
denotes the cumulative distribution function (CDF) for the standard normal distribution, with
operating as a skewing mechanism [
10]. The symmetric base PDF to be skewed is given by
, denoting the PDF of the generalized normal (
) distribution given by:
where
denotes the gamma function [
11]. The standard case for the
distribution with
and
in Definition 1 is denoted as
. Furthermore, the
distribution results in the standard
distribution in the case of
,
and
, denoted as
[
11]. In addition, the distribution of
X collapses to that of the standard normal distribution if
[
10].
Following the definition and properties of the
distribution, discussed in [
11] and summarized in
Section 2 below, the AR(
p) process in (
1) with independent and identically distributed innovations
is presented with its maximum likelihood (ML) procedure in
Section 3.
Section 4 evaluates the performance of the conditional ML estimator for the ARSGN(
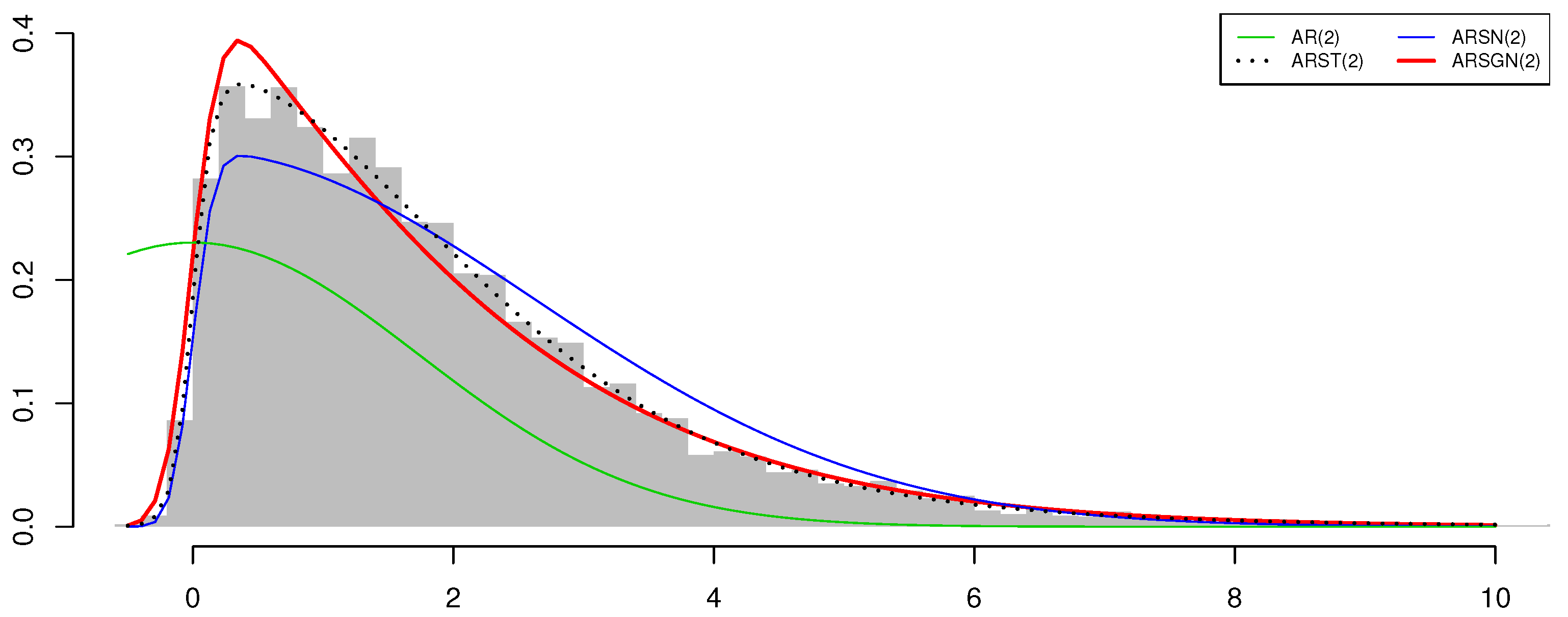
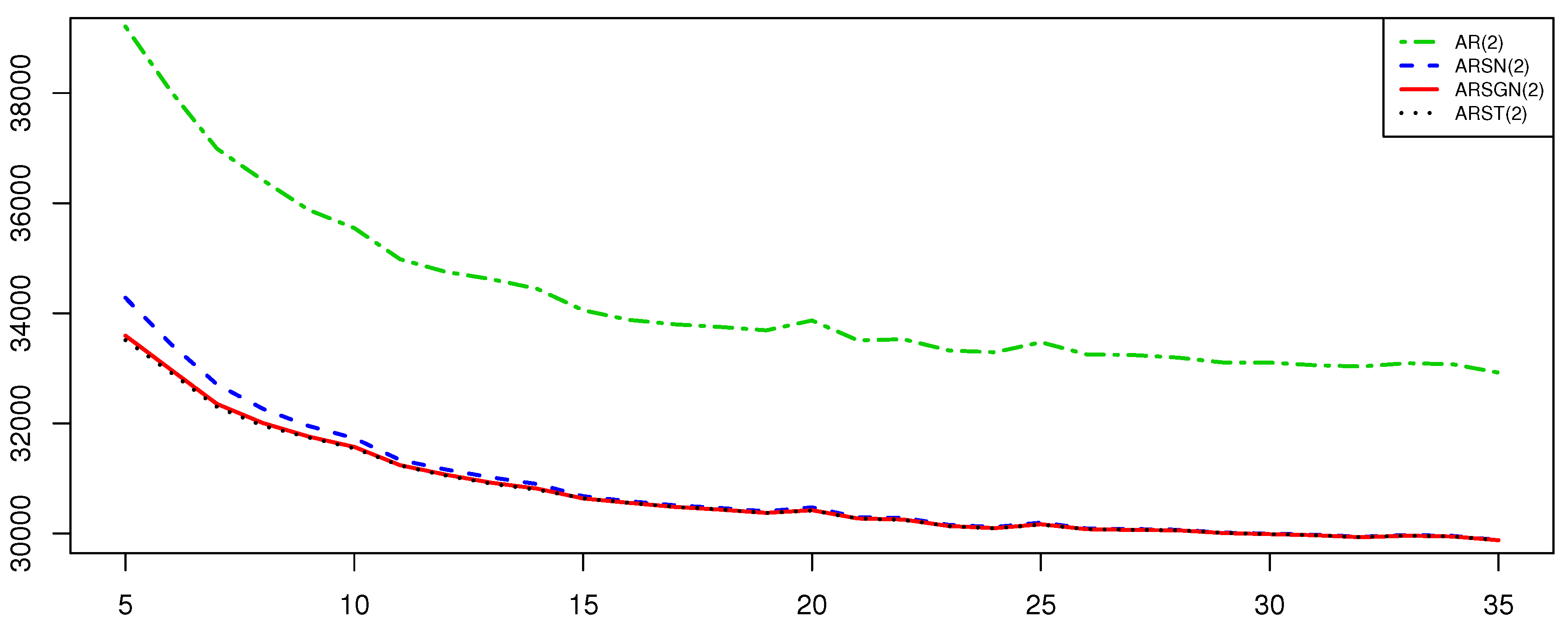
p) model through simulation studies. Real financial, chemical, and population datasets are considered to illustrate the relevance of the newly proposed model, which can accommodate both skewness and heavy tails simultaneously. Simulation studies and real data applications illustrate the competitive nature of this newly proposed model, specifically in comparison to the AR(
p) process under the normality assumption, as well as the ARSN(
p) process proposed by Sharafi and Nematollahi [
6]; this is an AR(
p) process with the innovation process defined by the
distribution such that
. In addition, this paper also considers the AR(
p) process with the innovation process defined by the skew-
t (
) distribution [
12] such that
, referred to as an ARST(
p) process. With a shorter run time, it is shown that the proposed ARSGN(
p) model competes well with the ARST(
p) model, thus accounting well for processes exhibiting asymmetry and heavy tails. Final remarks are summarized in
Section 5.
2. Review on the Skew Generalized Normal Distribution
Consider a random variable
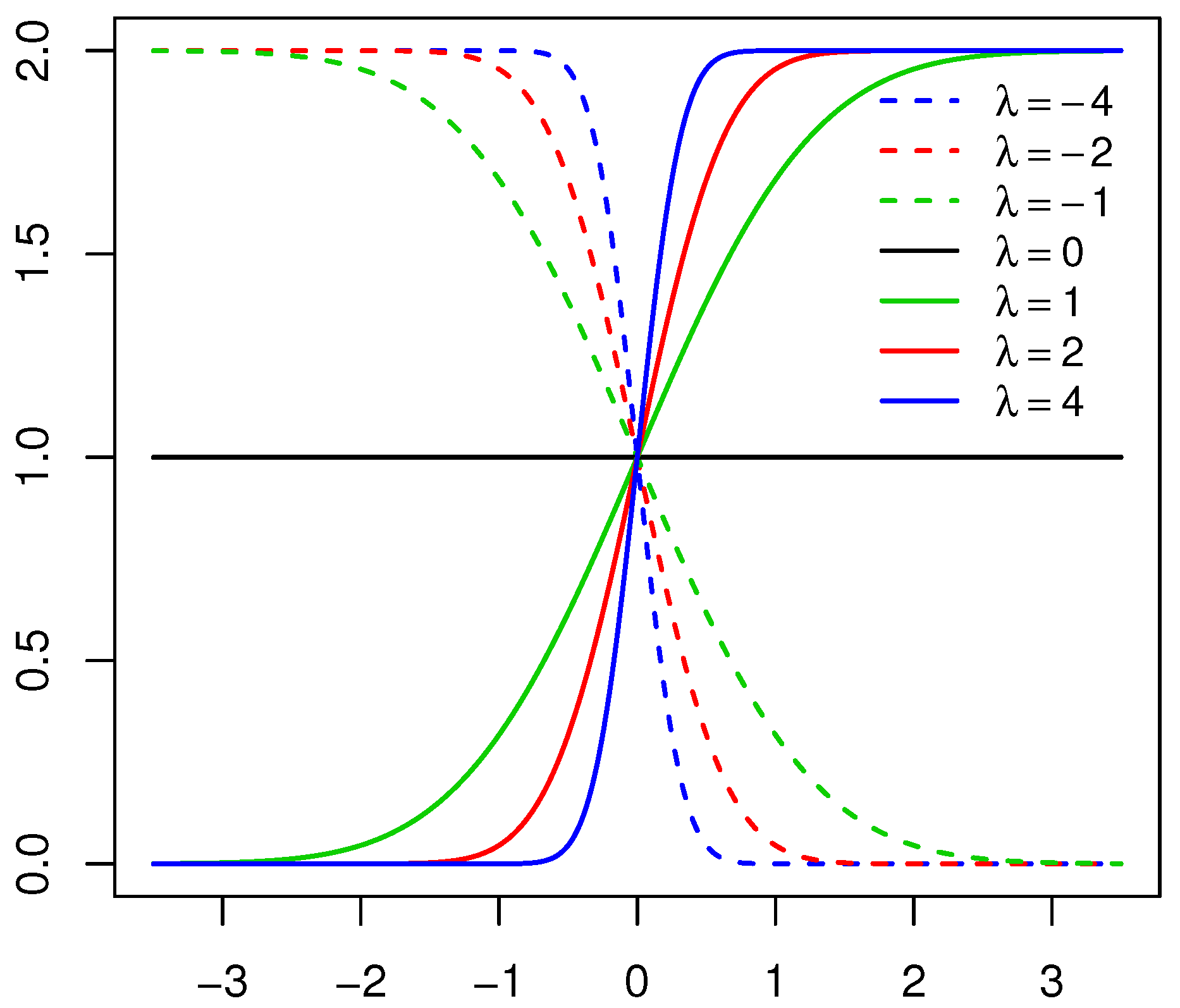
with PDF defined in Definition 1. The behavior of the skewing mechanism
and the PDF of the
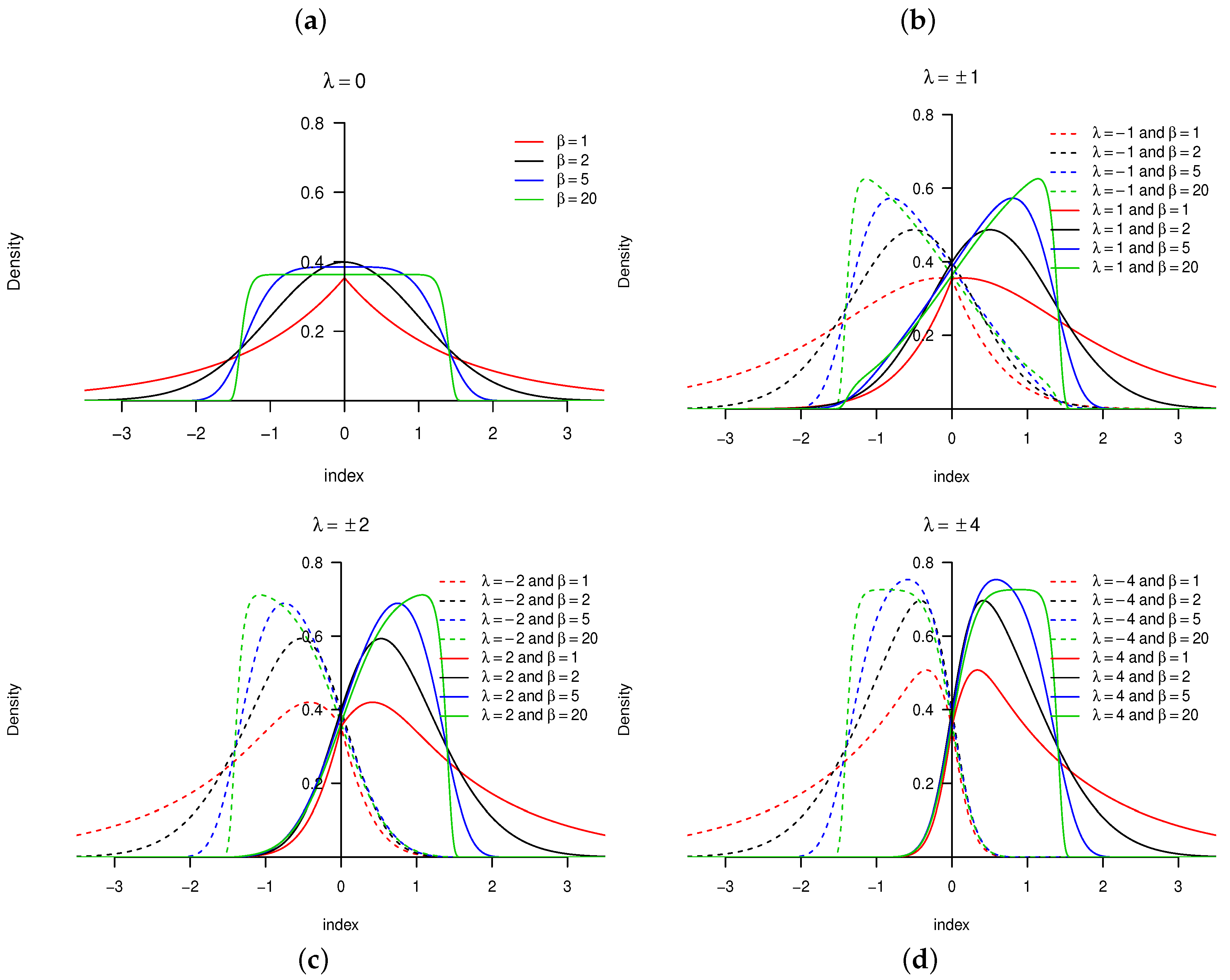
distribution is illustrated in
Figure 1 and
Figure 2, respectively (for specific parameter structures). From Definition 1, it is clear that
does not affect the skewing mechanism, as opposed to
. When
, the skewing mechanism yields a value of one, and the
distribution simplifies to the symmetric
distribution. Furthermore, as the absolute value of
increases, the range of
x values over which the skewing mechanism is applied decreases within the interval
. As a result, higher peaks are evident in the PDF of the
distribution [
11]. These properties are illustrated in
Figure 1 and
Figure 2.
The main advantage of the
distribution is its flexibility by accommodating both skewness and kurtosis (specifically, heavier tails than that of the
distribution); the reader is referred to [
11] for more detail. Furthermore, a random variable from the binomial distribution with parameters
n and
p can be approximated by a normal distribution with mean
and variance
if
n is large or
(that is, when the distribution is approximately symmetrical). However, if
, an asymmetric distribution is observed with considerable skewness for both large and small values of
p. Bekker et al. [
9] addressed this issue and showed that the
distribution outperforms both the normal and
distributions in approximating binomial distributions for both large and small values of
p with
.
In order to demonstrate some characteristics (in particular, the expected value, variance, kurtosis, skewness, and moment generating function (MGF)) of the
distribution, the following theorem from [
11] can be used to approximate the
kth moment.
Theorem 1. Suppose with the PDF defined in Definition 1 for and , then:where A is a random variable distributed according to the gamma distribution with scale and shape parameters 1 and , respectively. Proof. The reader is referred to [
11] for the proof of Theorem 1. □
Theorem 1 is shown to be the most stable and efficient for approximating the
kth moment of the distribution of
X, although it is also important to note that the sample size
such that significant estimates of these characteristics are obtained.
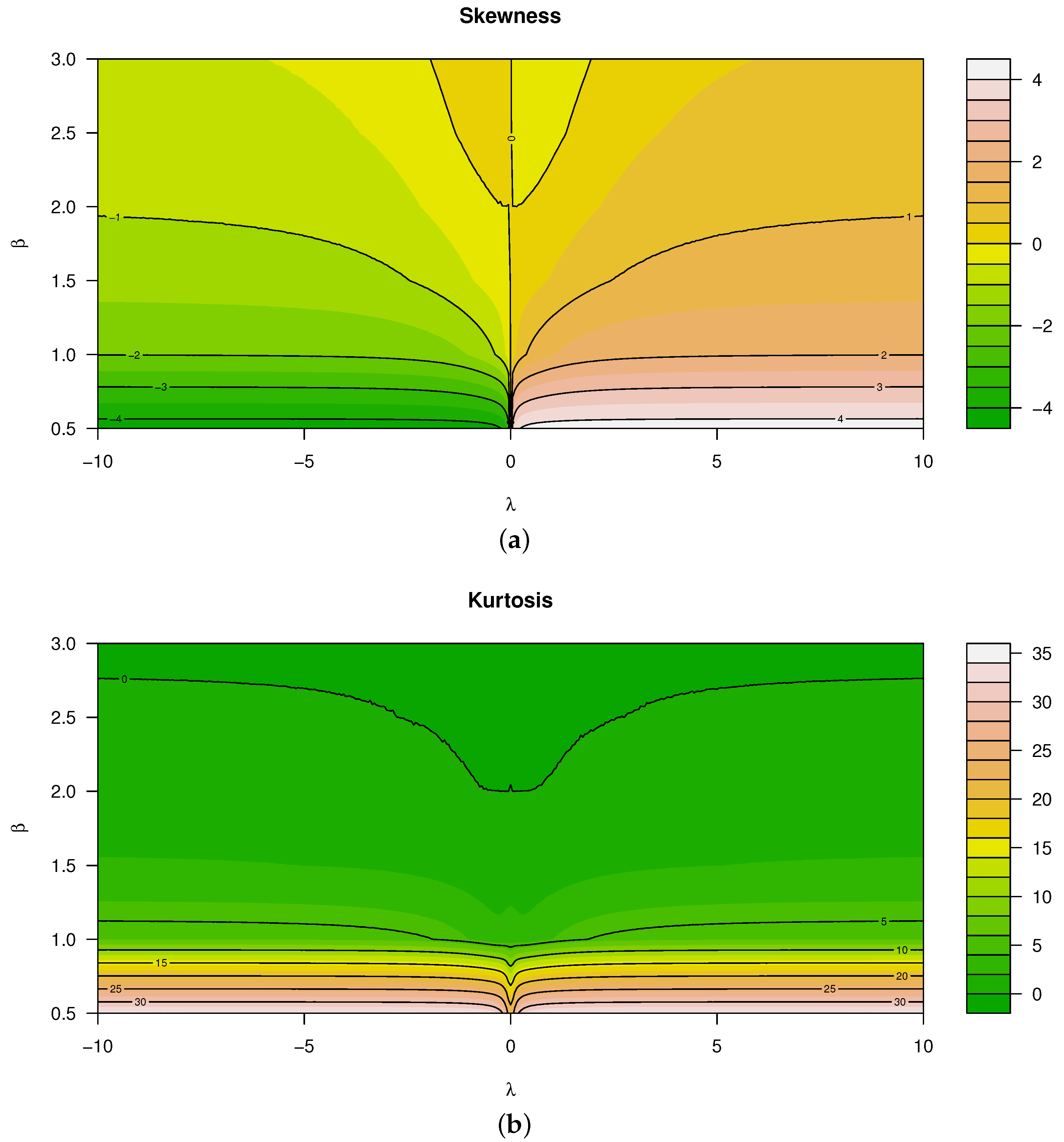
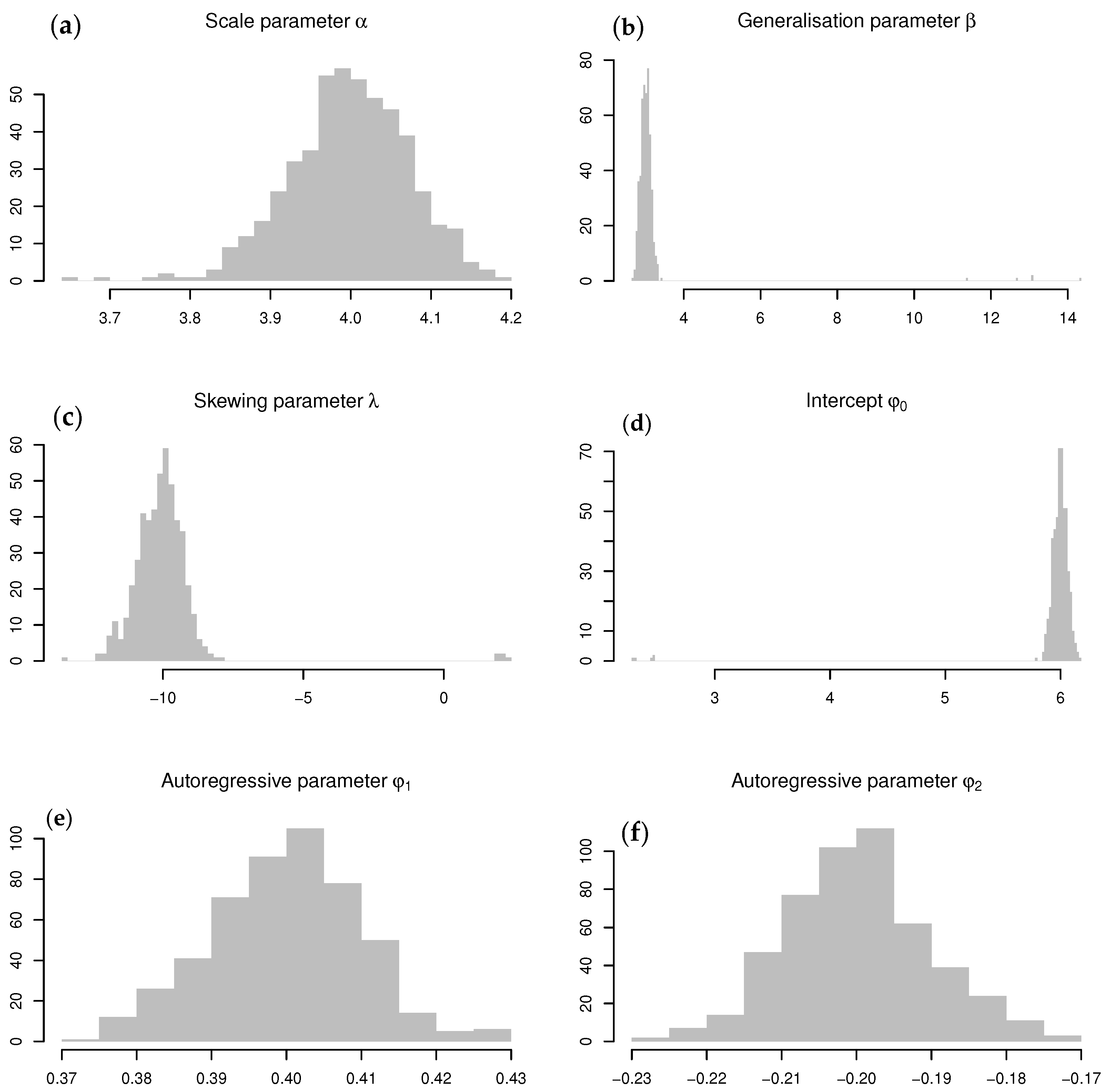
Figure 3 illustrates the skewness and kurtosis characteristics that were calculated using Theorem 1 for various values of
and
. When evaluating these characteristics, it is seen that both kurtosis and skewness are affected by
and
jointly. In particular (referring to
Figure 3):
Skewness is a monotonically increasing function for —that is, for , the distribution is negatively skewed, and vice versa.
In contrast to the latter, skewness is a non-monotonic function for .
Considering kurtosis, all real values of and decreasing values of result in larger kurtosis, yielding heavier tails than that of the normal distribution.
In a more general sense for an arbitrary and , Theorem 1 can be extended as follows:
Theorem 2. Suppose and such that , then:with defined in Theorem 1. Proof. The proof follows from Theorem 1 [
11]. □
Theorem 3. Suppose with the PDF defined in Definition 1 for and , then the MGF is given by:where W is a random variable distributed according to the generalized gamma distribution (refer to [11] for more detail) with scale, shape, and generalizing parameters 1, , and β, respectively. Proof. From Definition 1 and (
2), it follows that:
Furthermore, using the infinite series representation of the exponential function:
where
W is a random variable distributed according to the generalized gamma distribution with scale, shape, and generalizing parameters 1,
and
, respectively, and PDF:
when
, and zero otherwise. Similarly,
can be written as:
Thus, the MGF of
X can be written as follows:
□
The representation of the MGF (and by extension, the characteristic function) of the distribution, defined in Theorem 3 above, can be seen as an infinite series of weighted expected values of generalized gamma random variables.
Remark 1. It is clear that β and λ jointly affect the shape of the distribution. In order to distinguish between the two parameters, this paper will refer to λ as the skewing parameter, since the skewing mechanism depends on λ only. β will be referred to as the generalization parameter, as it accounts for flexibility in the tails and generalizing the normal to the distribution of [13]. 3. The ARSGN() Model and Its Estimation Procedure
This section focuses on the model definition and ML estimation procedure of the ARSGN(p) model.
Definition 2. If is defined by an AR(p) process with independent innovations with PDF:then it is said that is defined by an ARSGN(p) process for time and with process mean . Remark 2. The process mean for an AR(p) process keeps its basic definition, regardless of the underlying distribution for the innovation process .
With
representing the process of independent distributed innovations with the PDF defined in Definition 2, the joint PDF for
is given as:
for
. Furthermore, from (
1), the innovation process can be rewritten as:
Since the distribution for
is intractable (being a linear combination of
variables), the complete joint PDF of
is approximated by the conditional joint PDF of
, for
, which defines the likelihood function
for the ARSGN(
p) model. Thus, using (
3) and (
4), the joint PDF of
given
is given by:
where
. The ML estimator
is based on maximizing the conditional log-likelihood function, where
. Evidently, the
parameters need to be estimated for an AR(
p) model, where
m represents the number of parameters in the distribution considered for the innovation process.
Theorem 4. If is characterized by an ARSGN(p) process, then the conditional log-likelihood function is given as:for and defined in Definition 2. The conditional log-likelihood in Theorem 4 can be written as:
where
and
is defined in (
4). The ML estimation process of the ARSGN(
p) process is summarized in Algorithm 1 below.
| Algorithm 1: |
- 1:
Determine the sample mean , variance , and autocorrelations for . - 2:
Define the p Yule–Walker equations [ 14] in terms of theoretical autocorrelations for an AR( p) process: Set the theoretical autocorrelations in the Yule–Walker equations equal to the sample autocorrelations , and solve the method of moment estimates (MMEs) for the p AR parameters simultaneously in terms of . Use these MMEs as the starting values for the AR parameters . - 3:
Set starting values for the intercept and scale parameter equal to the MMEs [ 14] such that: - 4:
Set the starting values for the shaping parameters and equal to two and zero, respectively. - 5:
Use the optim() function in the software to maximize the conditional log-likelihood function iteratively and yield the most likely underlying distribution with its specified parameters.
|


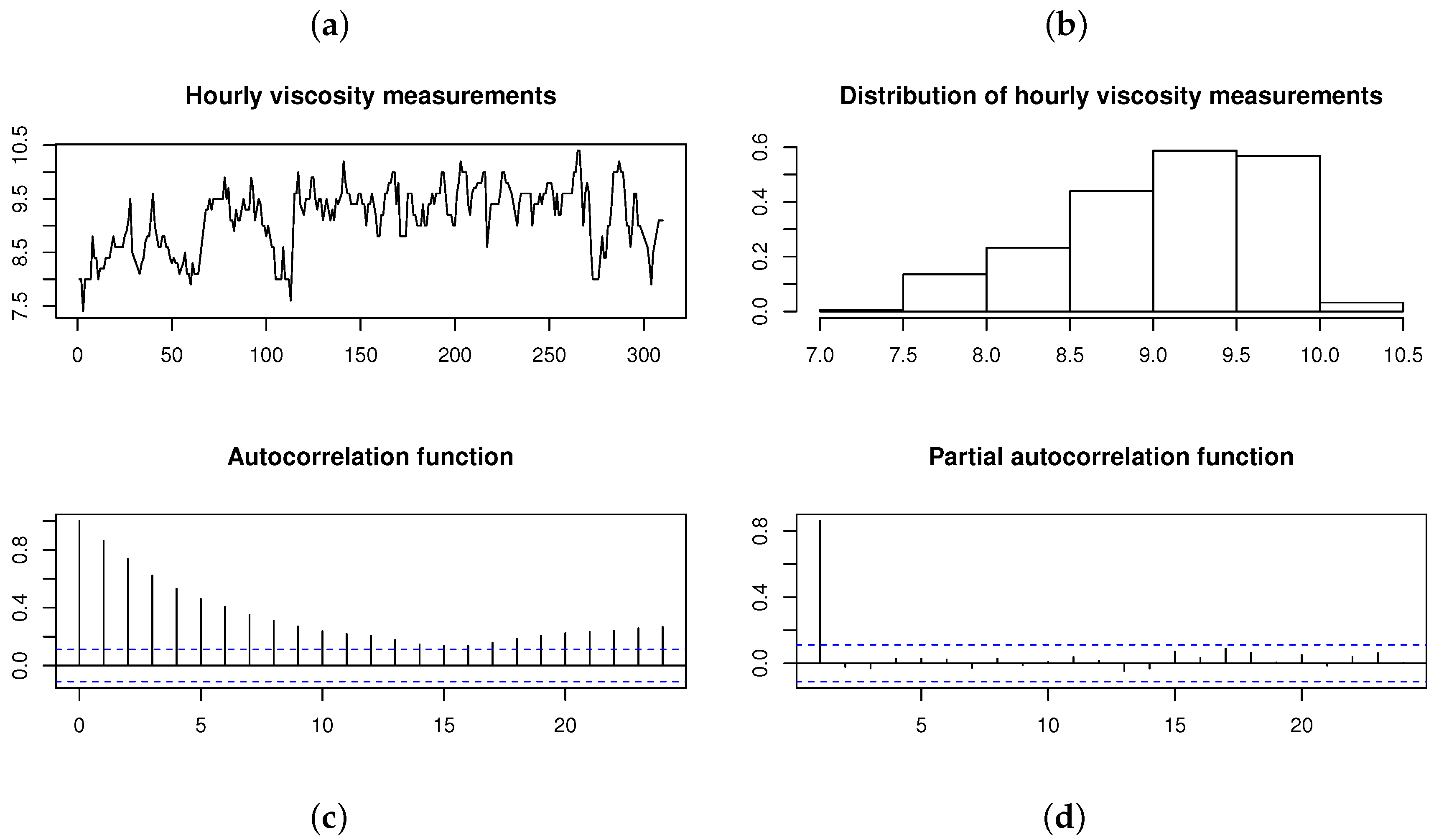
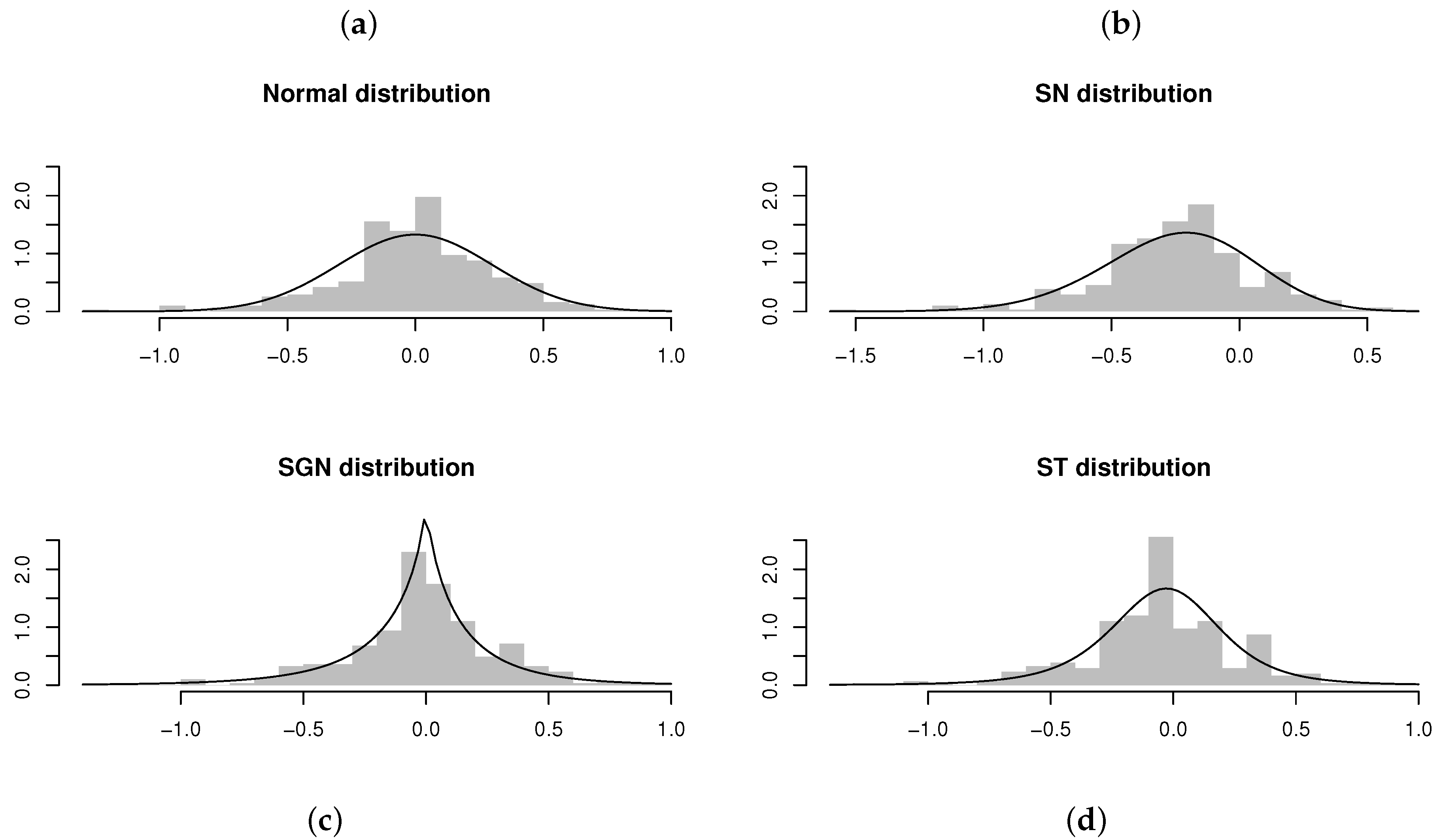
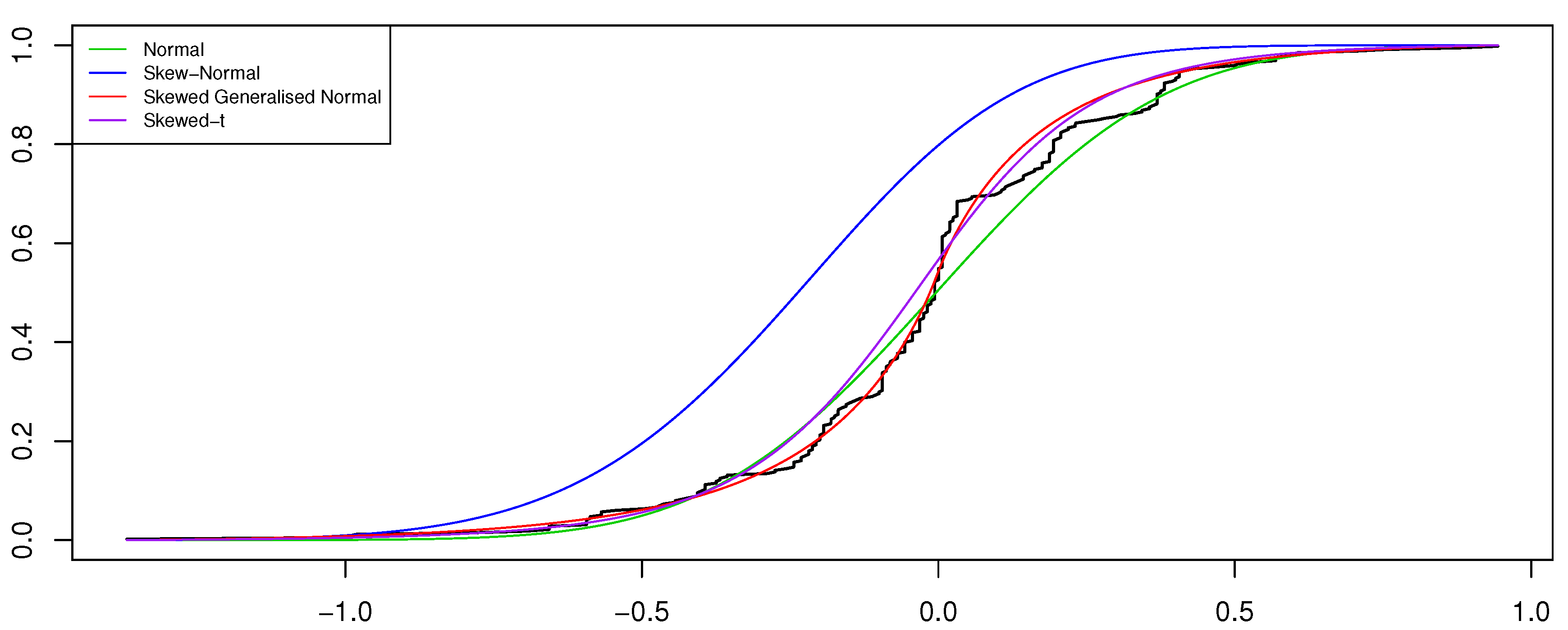
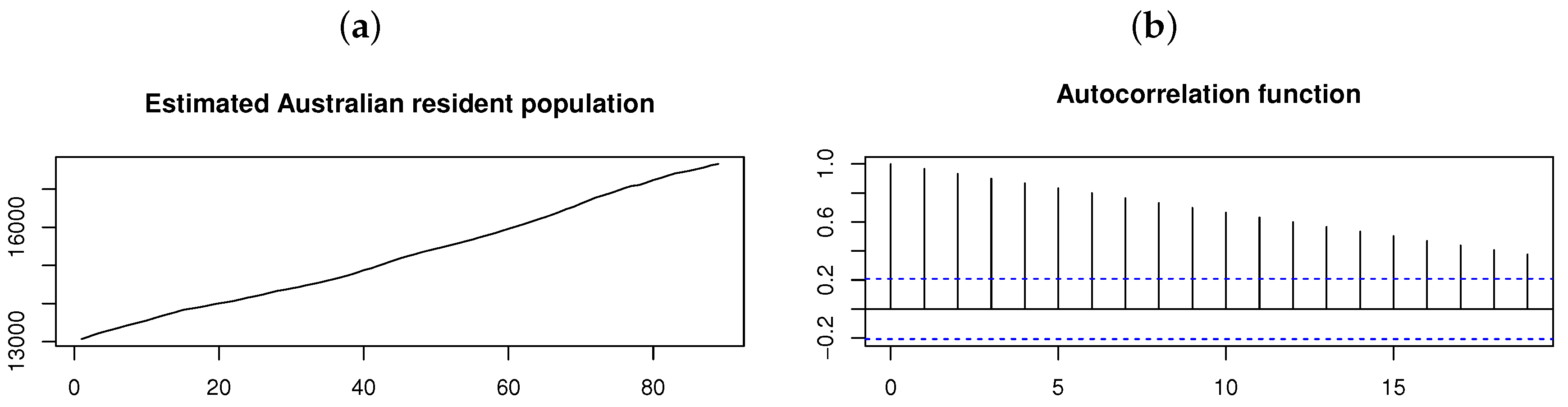


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}