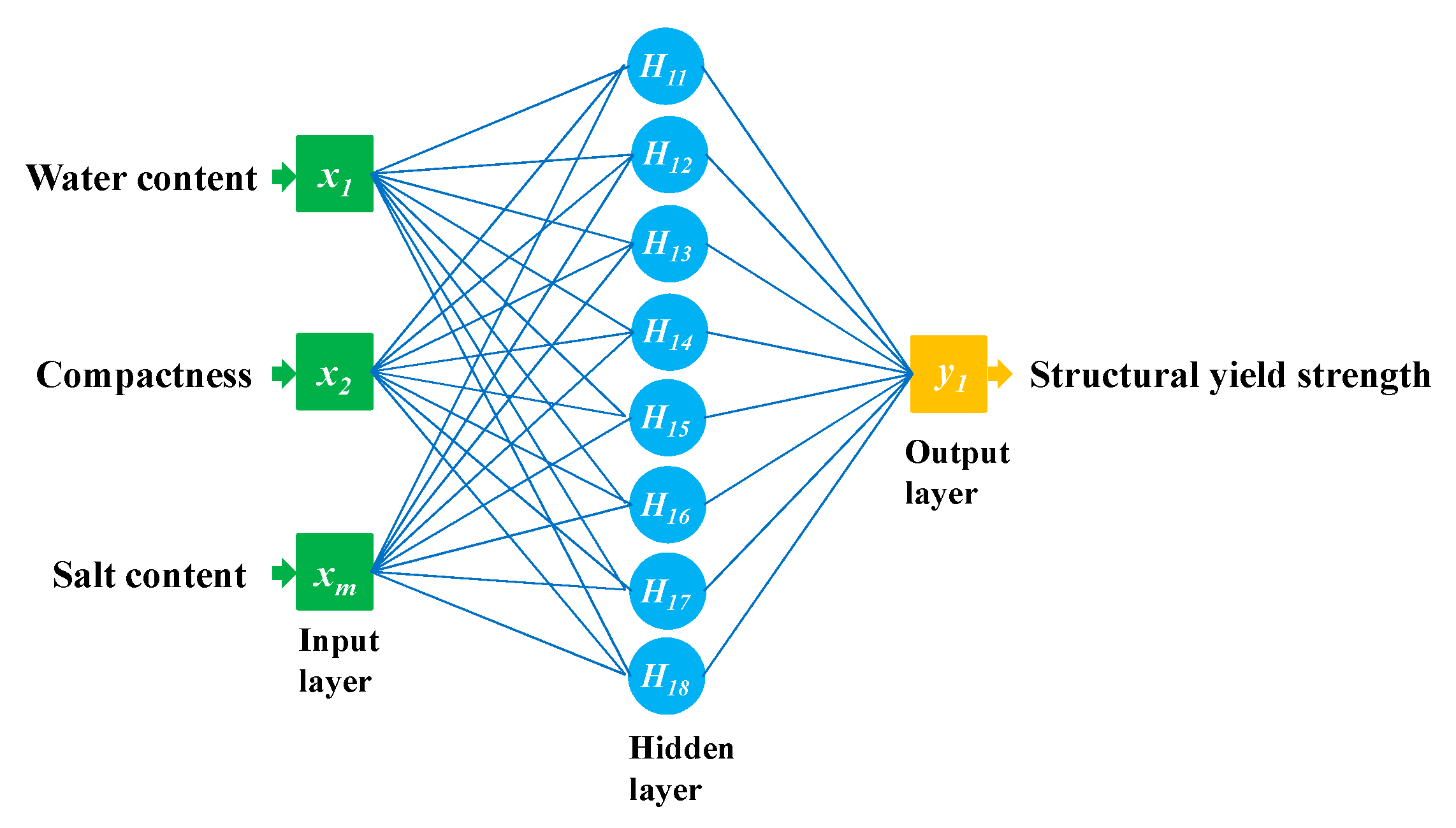
4.1. Model Performance Comparison
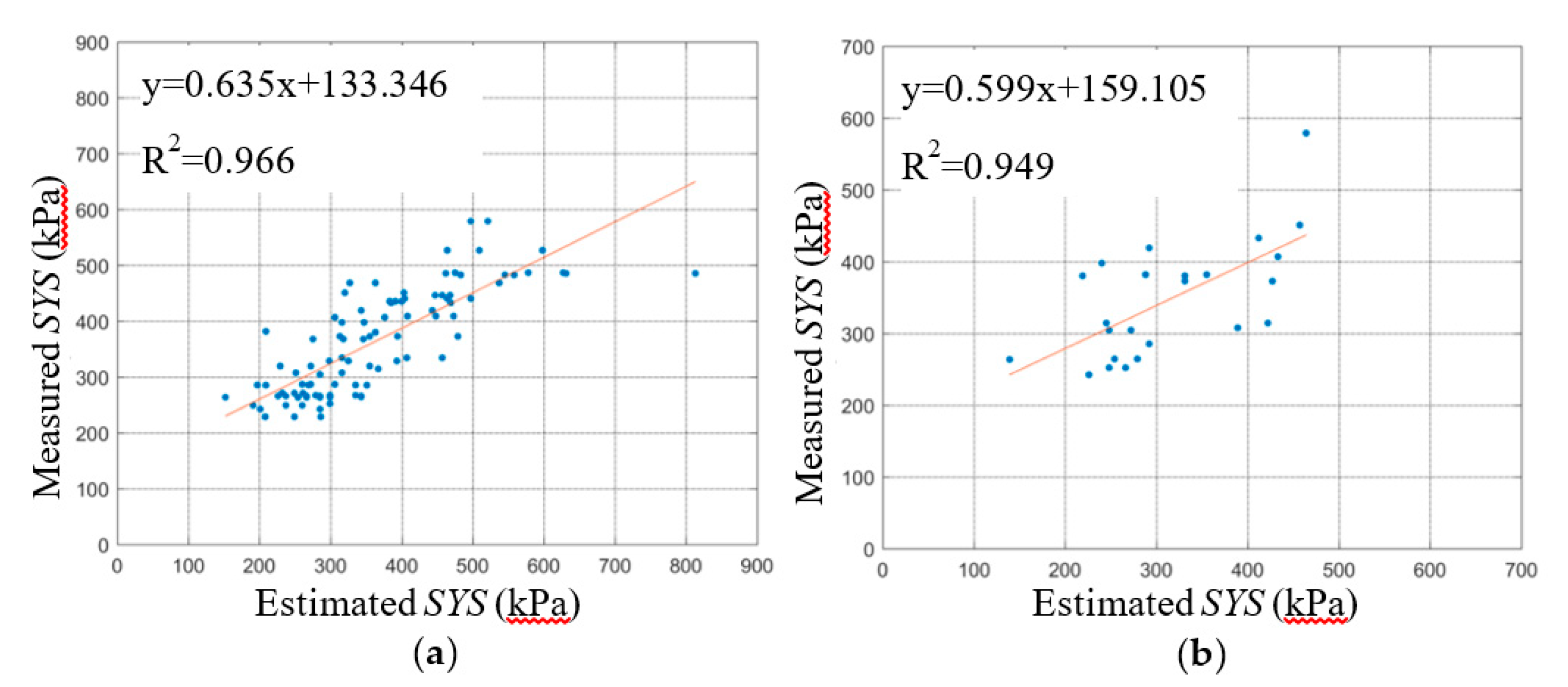
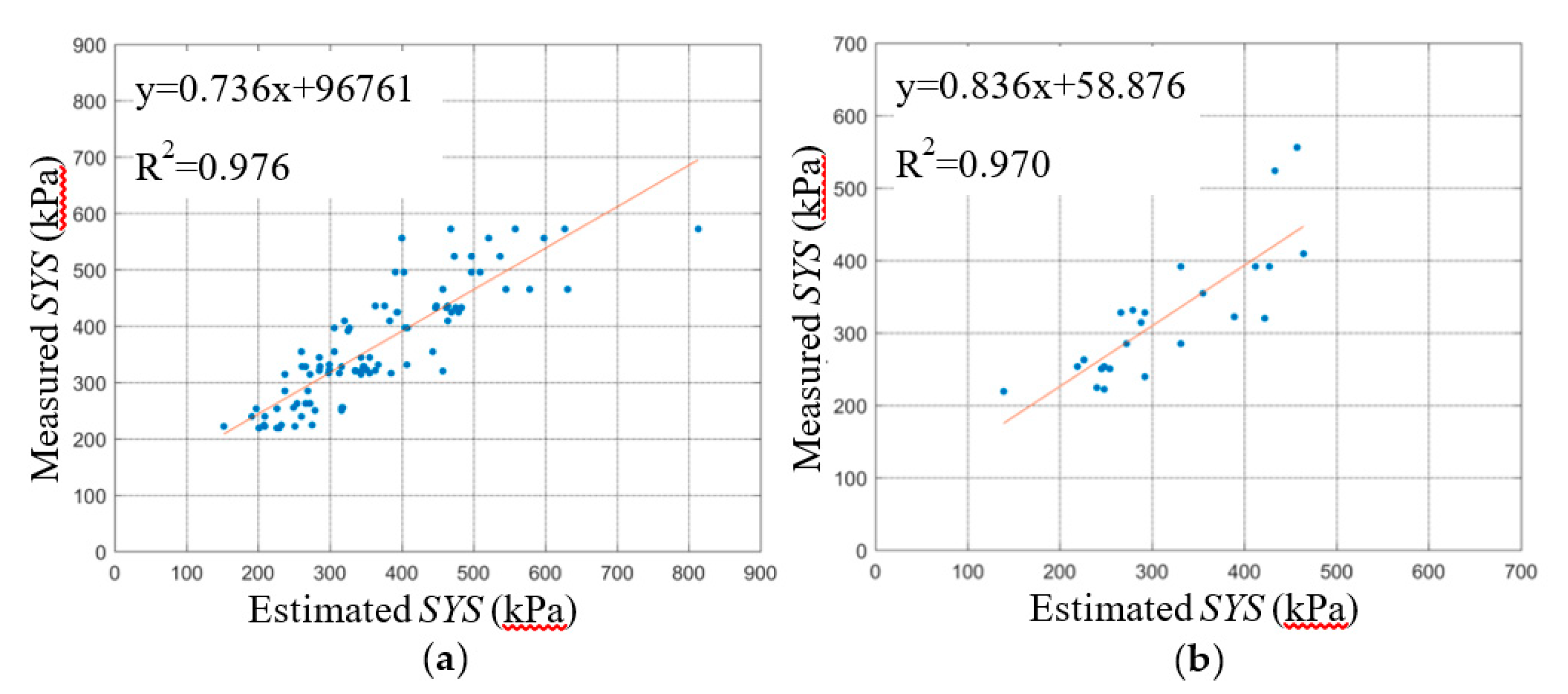
The regression relationships between the predicted SYS and measured SYS of the BPNN and SVM are shown in
Figure 7 and
Figure 8, respectively, including the training stage and testing stage. A comparison of the BPNN and SVM evaluation parameters in the training stage is shown in
Table 6, and a comparison of BPNN and SVM evaluation parameters in the testing stage is shown in
Table 7.
First, the three statistical indicators of each group of the dataset are analyzed in this section. The R2 ranges of the five BPNN models during the training and testing stage were 0.974~0.986 and 0.943~0.986, respectively. The R2 ranges of the five SVM models during the training and testing stage were 0.961~0.976 and 0.931~0.983, respectively. The R2min and R2max values of the BPNN models during the training and testing stage were greater than those of the SVM models, and the R2 ranges of BPNN models were smaller than those of the SVM models. The difference between the R2max and R2min of the BPNN and SVM models during the training stage was 0.012 and 0.015 respectively. The difference between the R2max and R2min of the BPNN and SVM models during the testing stage was 0.043 and 0.052, respectively. This shows that the R2 fluctuation of the BPNN model is smaller than that of the SVM model under different dataset grouping conditions. The explanation degree of independent variable to dependent variable is less affected by dataset grouping.
The RMSE ranges of the five BPNN models during the training and testing stage were 41.809~57.946 and 41.554~90.967, respectively. The RMSE ranges of the five SVM models during training and testing stage were 52.294~68.578 and 42.370~99.438, respectively. The RMSEmax and RMSEmin of the BPNN models during the training and testing stage were less than those of the SVM models. The difference between the RMSEmax and RMSEmin of the BPNN and SVM models during the training stage was 16.137 and 16.284, respectively. The difference between the RMSEmax and RMSEmin of the BPNN and SVM models during the testing stage was 49.413 and 57.068, respectively. The RMSE range of BPNN models is smaller than that of SVM models. The RMSE of the SVM models for the K-2 group of testing dataset was 99.438, which indicates that the prediction error of the SVM models for K-2 group of the testing dataset was greater than other dataset group. Under different dataset grouping conditions, the RMSE fluctuation of the BPNN models was smaller, and the prediction errors of the BPNN models ware less affected by grouping.
The MAPDs of the five BPNN models during the training and testing stage were 0.091~0.120 and 0.102~0.168, respectively. The MAPDs of the five SVM models during the training and testing stage were 0.116~0.133 and 0.109~0.177, respectively. The MAPDmax and MAPDmin of the BPNN models during the training and testing stage were less than or that of SVM models. The MAPDs of the five SVM models during the training stage and the testing stage were all bigger than that of BPNN models. which indicates that the prediction errors of the SVM models were all greater than BPNN models.
The R2 and RMSE ranges of the five BPNN models during the training and testing stage were more concentrated than that of the SVM models, which shows that the statistical parameters of the SVM models fluctuate greatly with different dataset groupings. The performance of the SVM models is greatly affected by different dataset groupings. This illustrates that the stability of the BPNN model is better than that of the SVM model.
Next, the average values of the three statistical indicators were analyzed. The average R2 of the BPNN models during the training and testing stages was closer to 1 than that of SVM models. The average RMSE of the BPNN during the training and testing stage were 11.805 and 7.035 smaller than that of SVM, respectively. This showed that the prediction error of the BPNN models was smaller than that of SVM models. This indicates that the predicted data for the BPNN models match the experimental data well. The average MAPDs of the BPNN during training and testing stages were 0.022% and 0.024% smaller than that of SVM, respectively. This shows that the relative error of the BPNN model is less than that of the SVM model, so the prediction effects of the BPNN models are better.
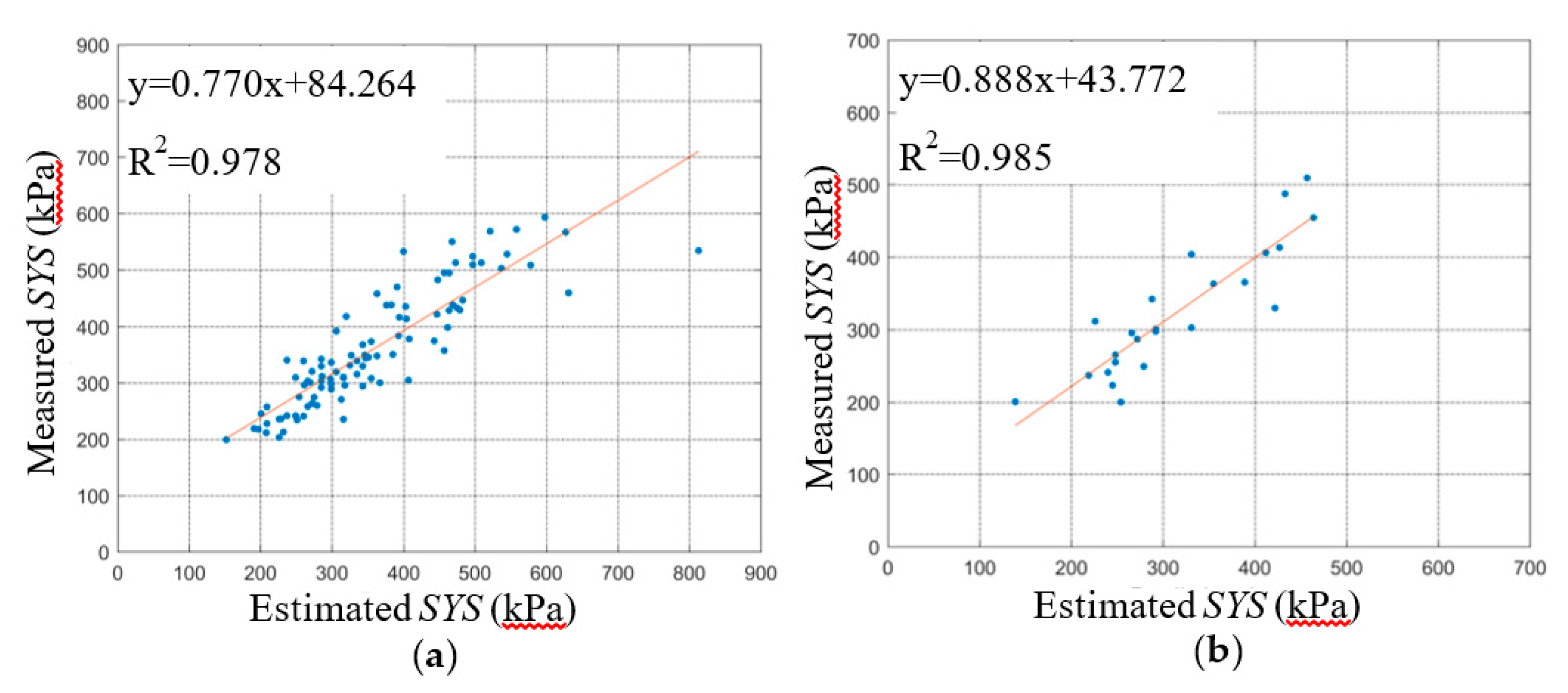
The fitting curves between the predicted data of the BPNN and SVM models and the experimental data are shown in
Figure 7 and
Figure 8. The slope and intercept of the fitting curves also reflect the accuracy of the prediction effect of the model. The closer the slope of the fitting curves is to 1 and the closer the intercept is to 0, the smaller the deviation between the predicted data and the experimental data, and the better the prediction effect of the model. By comparing the fitting lines of the predicted data and the experimental value of the BPNN and SVM model, the predicted effect of the BPNN model is shown to be better overall than that of the SVM. In order to avoid overfitting, the K-fold cross-validation method was used in this study. From the results of the BPNN model parameters, the R
2 of K-2, K-3, and K-5 datasets in the testing stage are only slightly lower than those in the training stage, and even the R
2 of K-1 and K-4 datasets in the testing stage are higher than those in the training stage. The results of RMSE and MAPD showed opposite regularity. And the results of the SVM model parameters showed the similar regularity. Moreover, the model parameters of BPNN and SVM models are very stable, neither excellent nor poor. Thus, the performance of BPNN and SVM models is stable, the generalization ability of the model is good for the data of this study, and the generalization ability for external data needs to be explored and improved in future research.
Kogure (1977) [
52], Stas (1984) [
53], and Degroot (1999) [
54] established the empirical models to predict the clay pre-consolidation pressure, and the R
2 values were all less than 0.80. The model performance was poor and the generalization ability was weak. Karim (2016) proposed a two-fold simple empirical model with
R2 = 83%, which greatly improved the performance of the model [
55]. In this study, the R
2 results of the pre-consolidation pressure prediction models are all above 90%. Therefore, compared with the existing empirical formula model, the performance of the BPNN and SVM models established in this study are much better.
In the learning process of the BPNN model, the gradient search algorithm is used to correct the weight through error propagation, so that the MSE between the actual output and the expected output is minimized. Because of its strong learning ability, the fitting accuracy of the BPNN model is high. The SVM model is based on the principle of structural risk minimization, which transforms the plane nonlinear problem into a linear problem by mapping data to the high-dimensional feature space. The three independent variables have medium and extremely strong correlation with the dependent variables in this study, and there is no redundancy feature. Therefore, the BPNN and SVM models have good performance and stability. However, the main drawbacks of the BPNN model are that it cannot give a clear mathematical relationship and the results are not interpretable. The performance of the support vector machine mainly depends on the selection of the kernel function, but there is no good method to solve the problem of kernel function selection in different fields.
In addition, in the studies of basic properties, ignoring scale-dependence will make the experimental results deviate from the practical engineering [
56]. Considering scale-dependence in the establishment of the model, the prediction results of the model will be closer to the reality and the generalization ability will be better [
57,
58,
59,
60]. But the size effect is not taken into account in this study, which may affect the generalization ability of the model. This problem should be fully considered in future research to improve the generalization ability of the model.
4.2. Sensitivity Analysis
Because the BPNN model is superior to the SVM model, we used it to explore the influence of water content, compactness, and salt content on the SYS. The first model takes compactness and salinity as the input variables, which are recorded as BPNN-1; the second model takes moisture content and salinity as the input variables, which are recorded as BPNN-2; and the third model takes moisture content and compactness as the input variables, which are recorded as BPNN-3. Similarly, according to the K-fold cross-validation method, the datasets are divided into five groups of training datasets and test datasets, and the BPNN models are established and simulated. The statistical evaluation parameters of the three models are shown in
Table 8.
As shown in
Table 8, the average R
2 of the BPNN-3 during the training and testing stages were greater than 0.969 and were closer to 1 than the average R
2 of the other two models. This shows that the proportion of variance in the dependent variable that is explained by the independent variable is high in BPNN-3. The R
2 of BPNN-1 was the smallest, and the average R
2 value during the training and testing stages was about 0.9. This shows that the proportion of variance in the dependent variable which is explained by the independent variable decreases obviously when the water content of the input variable is removed.
The RMSE average value of BPNN-3 during the training and testing stages was the smallest, which indicates that the error of BPNN-3 was the smallest, so the BPNN-3 matching degree of experimental data and prediction data is the highest. The average RMSE of BPNN-2 during the training and testing stages was 1.186 and 1.296 times that of BPNN-3, respectively. The RMSE average value of BPNN-1 was the largest. The RMSE average value during the training and testing stage was 1.800 and 1.818 times higher than that of BPNN-3, respectively.
The average MAPD of BPNN-3 during the training and testing stages was the smallest, which indicates that the relative error of BPNN-3 was the smallest. The average MAPD of BPNN-2 during the training and testing stages is 1.187 and 1.228 times higher than that of BPNN-3, respectively. The average MAPD of the BPNN-1 model was the largest, and the average MAPD during the training and testing stage was 1.991 and 1.915 times higher than that that of BPNN-3, respectively.
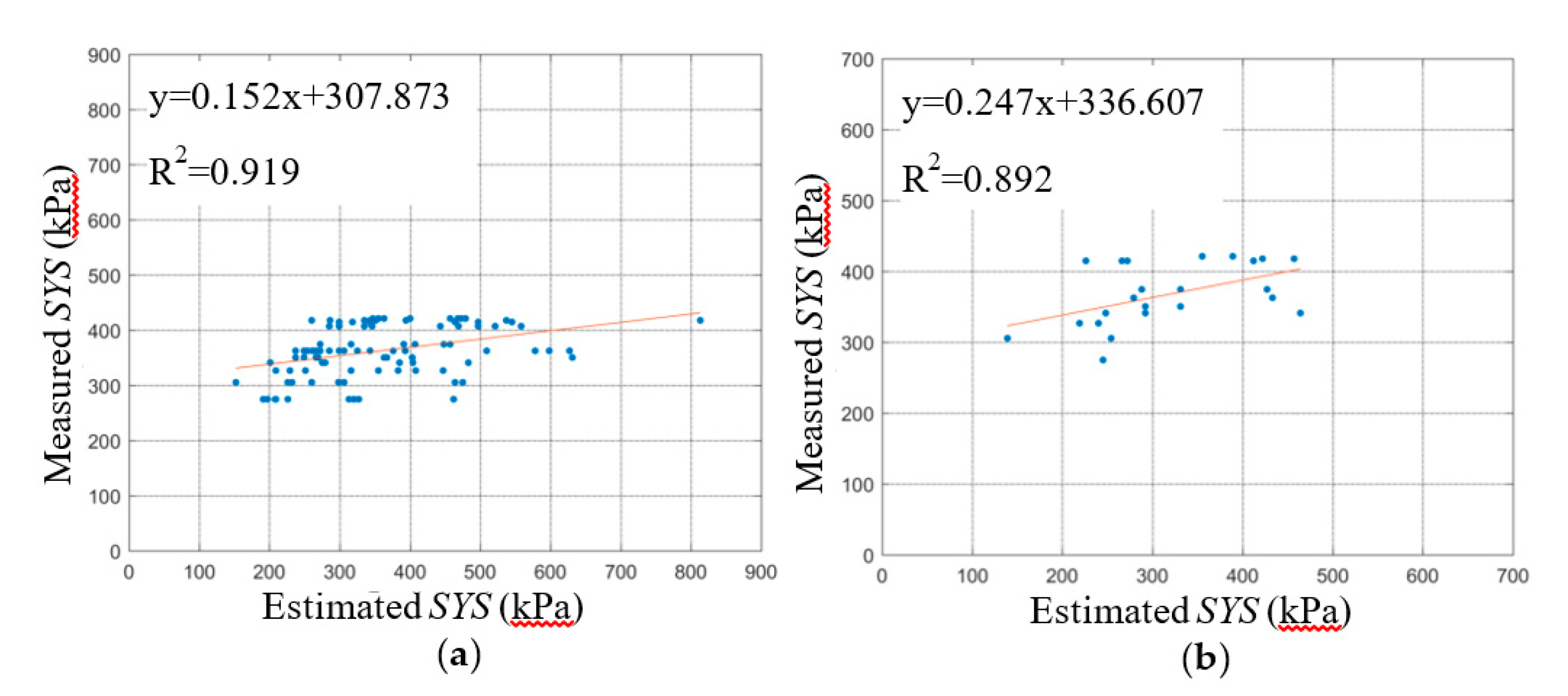
The average values of the three statistical parameters of the BPNN-3 model are the best. The statistical parameters of the BPNN-2 model are better than those of BPNN-1. Because the R2 average value of the BPNN-1 model is the smallest when removing the water content of the input variable, and the RMSE and MAPD average values are also larger than BPNN-2 and BPNN-3, the proportion of variance in the dependent variable that is predicted or explained by the independent variable of the model is reduced significantly, and the prediction error and relative error increase significantly when removing the water content of the input variable. Therefore, it can be concluded that the influence degree of each variable is as follows: water content > compaction degree > salt content.
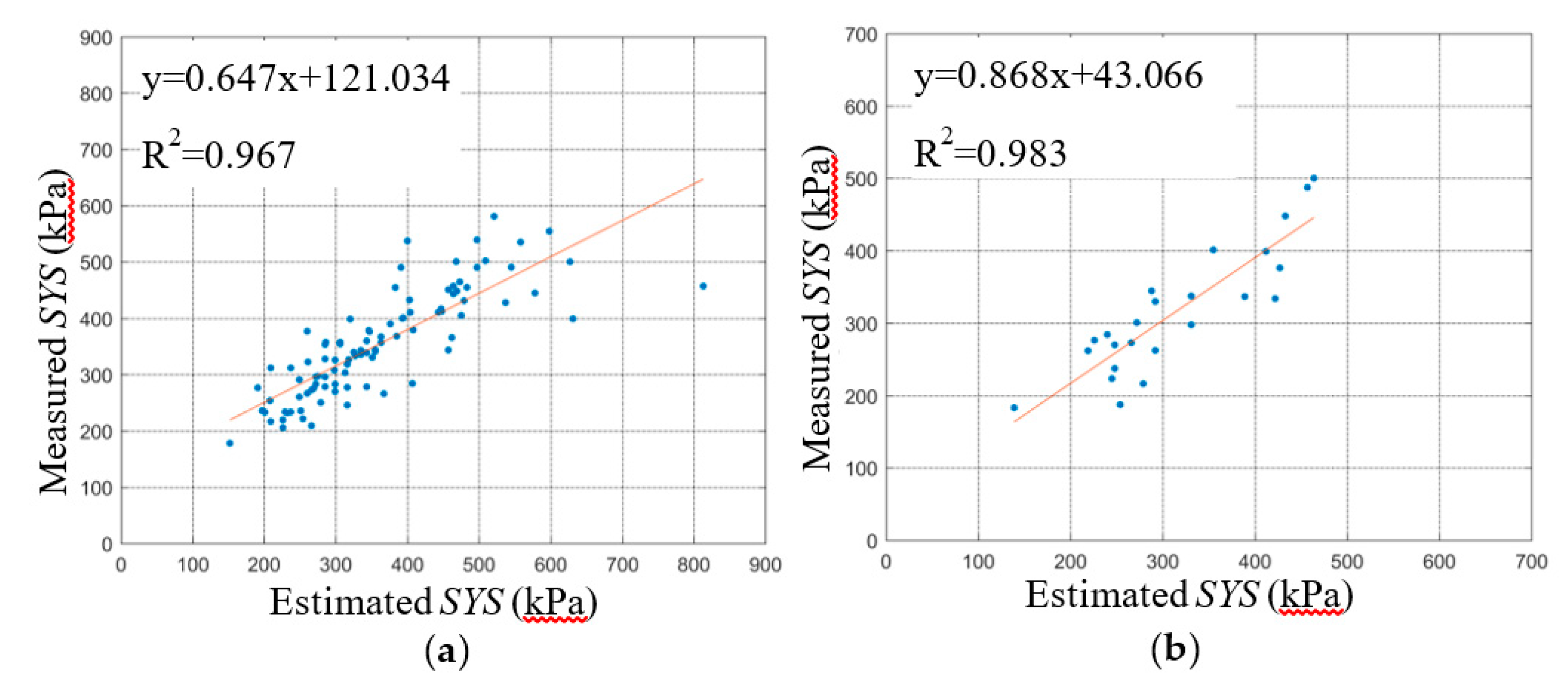
The relationship curve between the estimated SYS and the measured SYS of the BPNN model is shown in
Figure 9,
Figure 10 and
Figure 11. The slope and intercept of the fitting curve also reflect the prediction effect of the model. By comparing the fitting lines between the predicted data of the BPNN-1, BPNN-2, and BPNN-3 models and the experimental data, we found that the predicted results of the BPNN-1 model are the worst, while those of the BPNN-3 model are the best.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}