1. Introduction
Spoken Language Understanding (SLU) refers to converting Automatic Speech Recognition (ASR) outputs into the predefined semantic output format. The role of SLU is of great significance to a modern human–machine spoken dialog system. The purpose of SLU is to convert the user’s conversational text into a way that the computer can understand, typically a machine-interpretable and actionable sequence of labels [
1]. Therefore, the computer can perform the next correct operation based on the extracted information to help the user to meet his or her demands. The main task of SLU is generally divided into two parts: to identify the intent of the user’s command and to extract the semantic slot value in the utterance, which is, respectively, referred to as intent detection and slot filling. The intent detection task is typically treated as a semantic utterance classification problem in which contiguous sequences of words are assigned with semantic class labels. Slot filling can be treated as sequence labeling problem, which assigns jointly labels of each word in the sequence.
Even after years of research, the slot filling task for SLU is still a challenging problem [
2,
3]. Theoretically, the approaches to solve the two problems include generative models such as hidden markov models (HMM) [
4], discriminative methods [
5], such as Conditional Random Fields (CRFs) [
6,
7], Support Vector Machines (SVMs) [
8], and probabilistic context-free grammars [
9]. In recent years, neural network models such as RNN [
10] and Convolutional Neural Network (CNN) [
11] have also been successfully applied to this task [
5,
12,
13].
In some research areas such as ASR, although RNN and its variants have been successfully applied, they are more recently replaced by TDNN which is capable of processing wider context inputs. In early years, TDNN has been applied in small scale speech recognition tasks [
14,
15] and recently has shown to obtain better speech recognition results over DNN [
16] and unfolded RNN [
17]. In Kaldi [
18], perhaps the most prevalent speech recognition toolkit nowadays, the TDNN-BiLSTM framework, has been implemented as a standard recipe.
In Natural Language Processing (NLP) research, word context modeling is crucial to the performance of many sequence labeling tasks including SLU. RNN models the word contexts by indirectly learning relative positions of the target words in the sentences according to the input order of the words, which makes the current output of RNN largely depend on the last input rather than the previous input [
19]. It is difficult for RNN to capture the positional information of the current word when processing long word sequences. Although we can use context word splicing as the inputs to the RNN, this technique only provides limited contextual information. In order to improve the performance of slot filling task, we focus on modeling the context information of the target word.
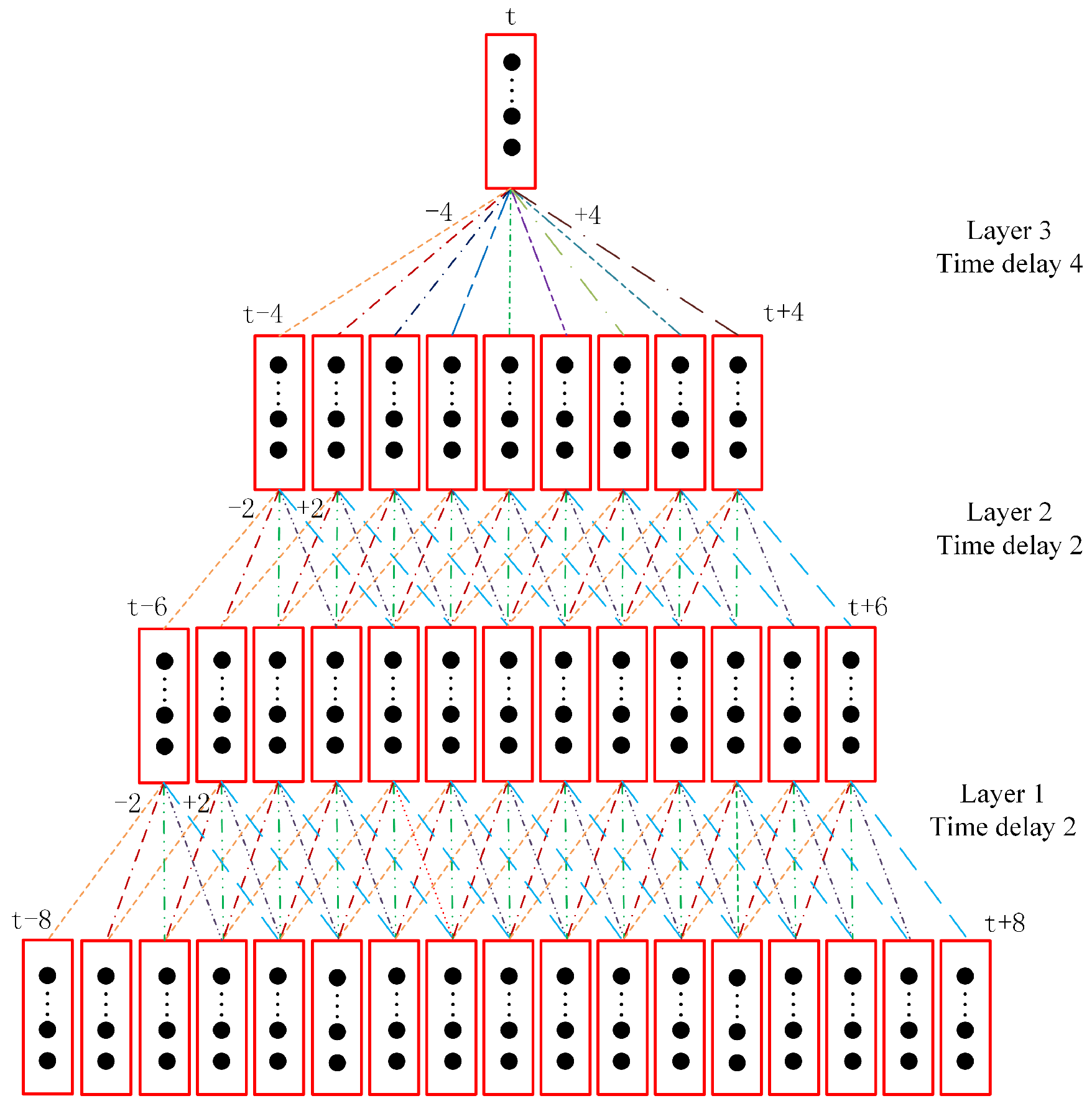
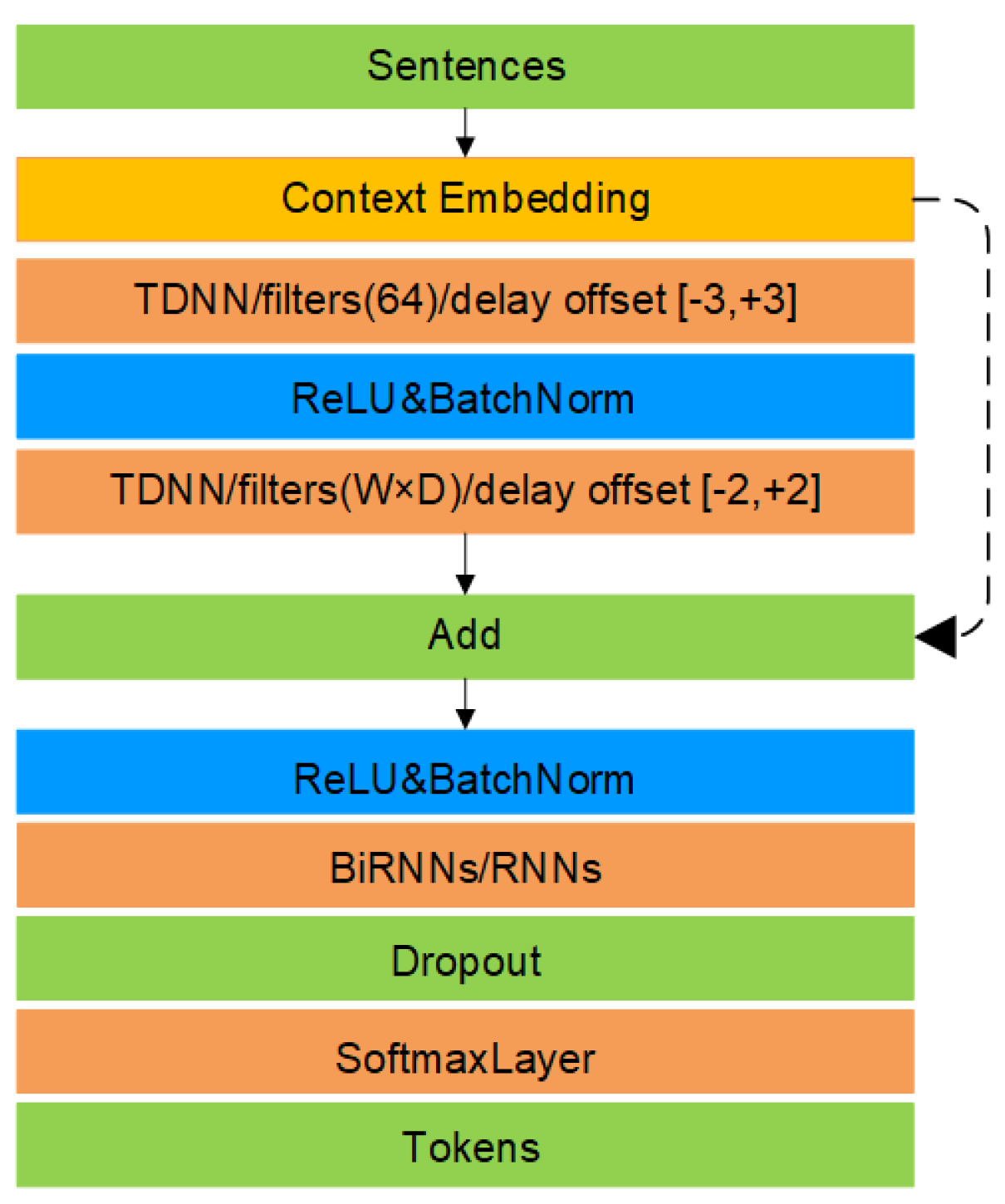
Based on the above, we explore the use of TDNN instead of RNN for slot filling. TDNN is a precursor of the convolutional network, also known as one-dimensional convolution. Especially, we used TDNN with symmetric delay offset, which can predict semantic labels by considering the same number of words before and after the target word. TDNN is a multi-layer neural network, with each layer having a strong ability for feature extraction, and also takes into account the long-term contexts. Unlike RNN, which inputs words in sentence order, TDNN is capable of simultaneously processing words that surround the target word. Moreover, TDNN is able to make use of arbitrary word contexts by setting different time delays rather than successive words with a context window. TDNN can get the contextual information of adjacent words surrounding the target word in sentence by context window and delay offsets.
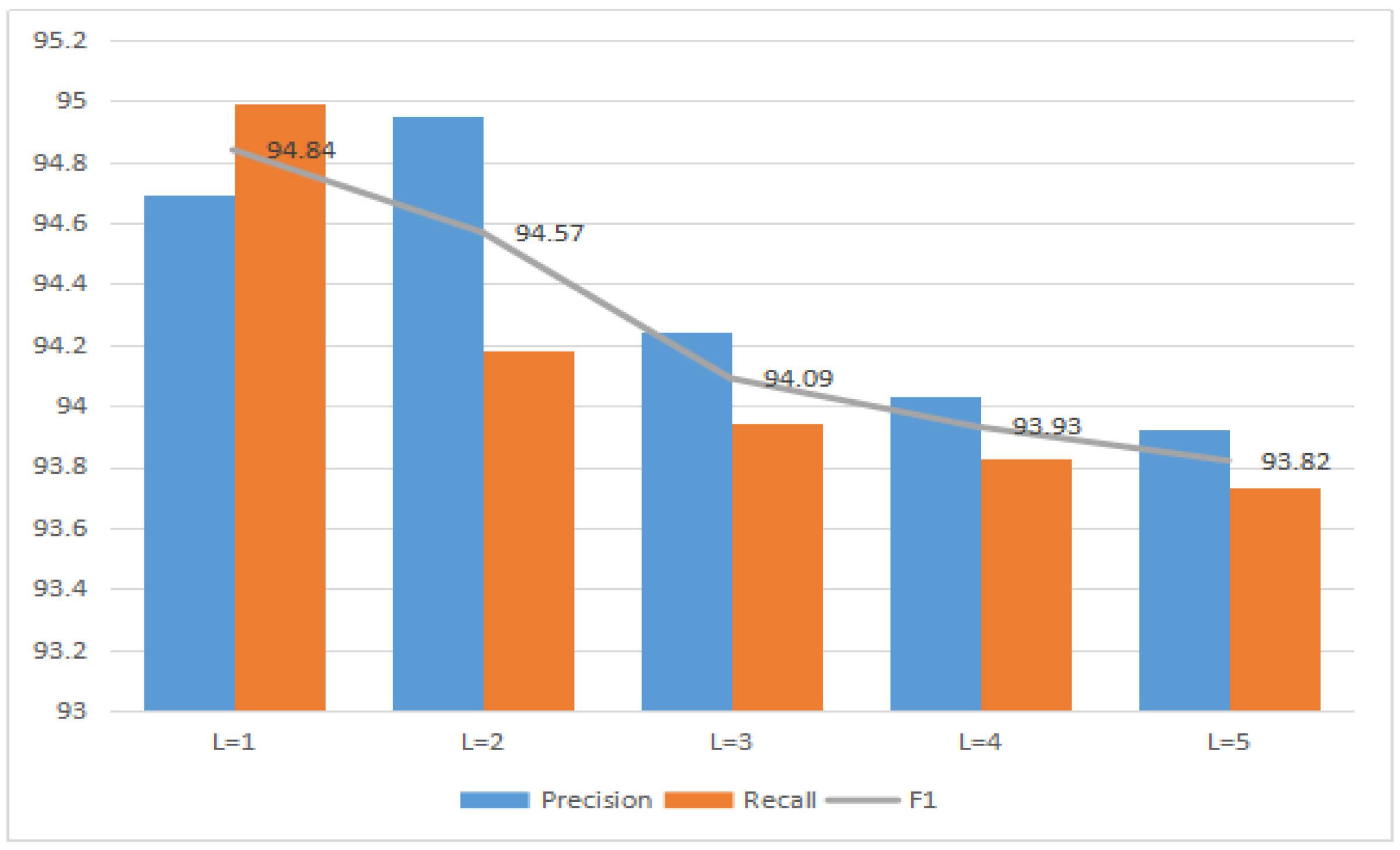
To model even longer word contexts, it is straightforward to simply stack several TDNN layers to obtain a multi-layer TDNN due to its hierarchical multi-resolution nature. Particularly, the low layers of stacked TDNN deal with a narrow time context, which expands as information flows to higher layers [
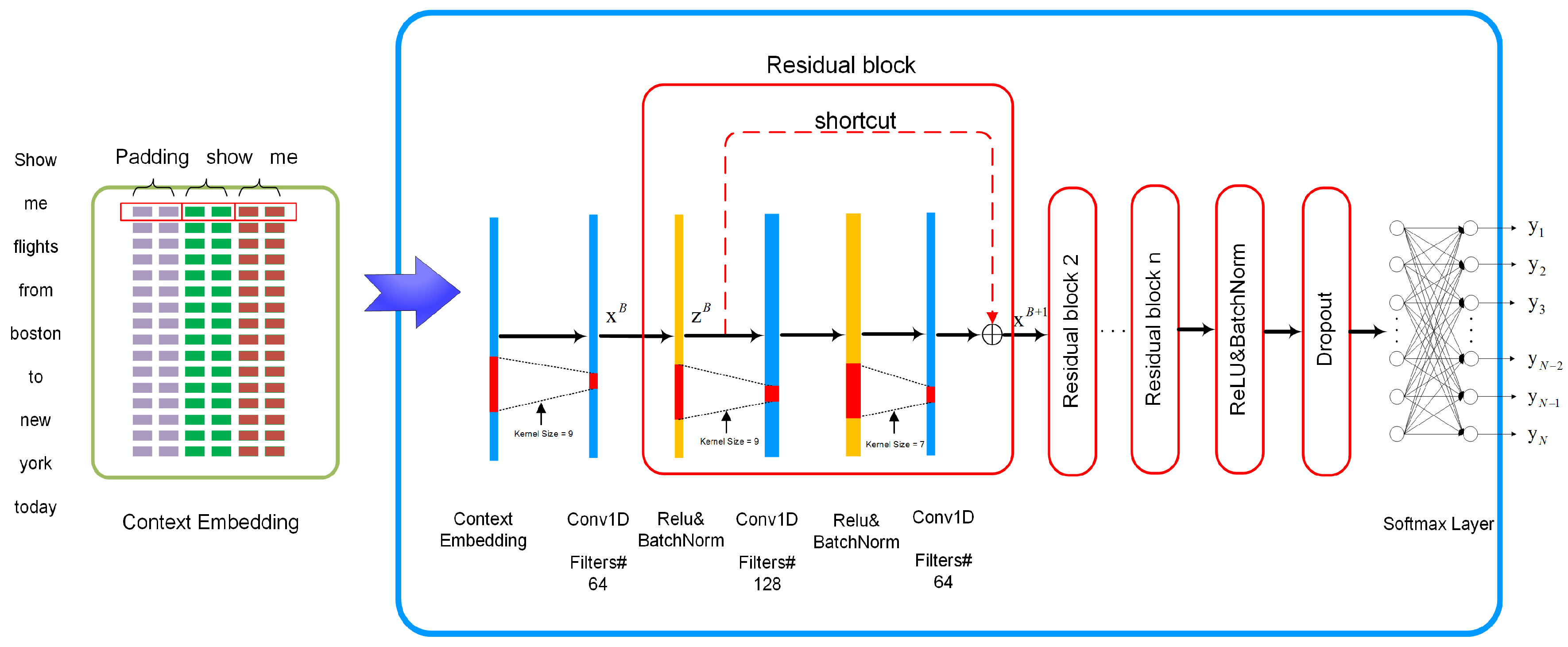
20]. Therefore, multi-layer TDNN can extract the context information of the target word from the sentence level instead of word level to predict the semantic label. However, with the deepening of the network, the gradient vanishing or exploding is an inevitable problem. Residual connection and gradient clip are two main methods to solve this problem. The residual CNN has shown to achieve good results on image classification tasks [
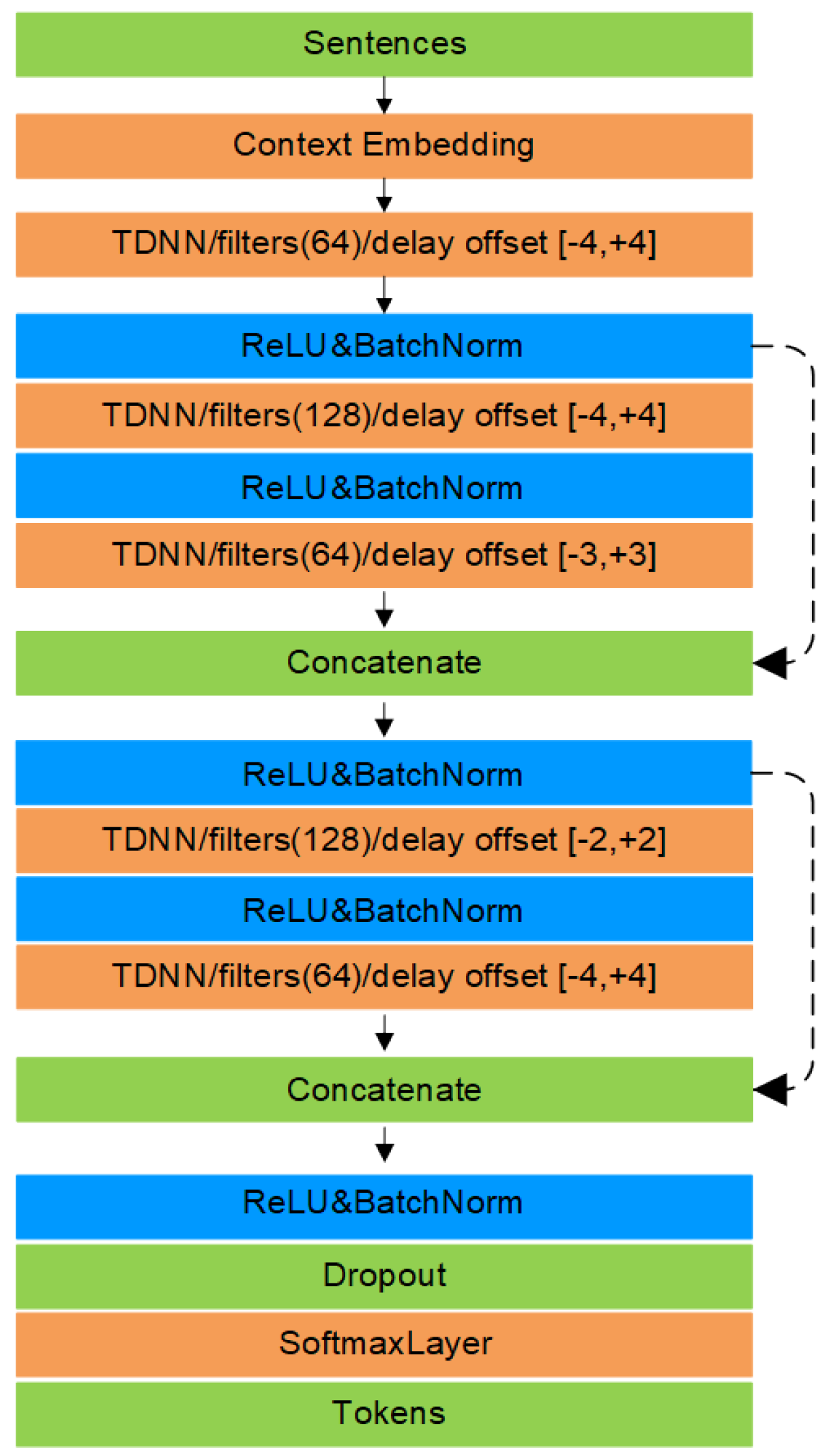
21] and it has been proved that the residual structure can alleviate the gradient vanishing or exploding problems through skip connections. Therefore, we apply the residual structure to TDNN, which is named as ResTDNN. ResTDNN can fuse features which from different TDNN layers and strengthen feature propagation. Slot filling results show the superiority of ResTDNN to conventional RNN and its variants.
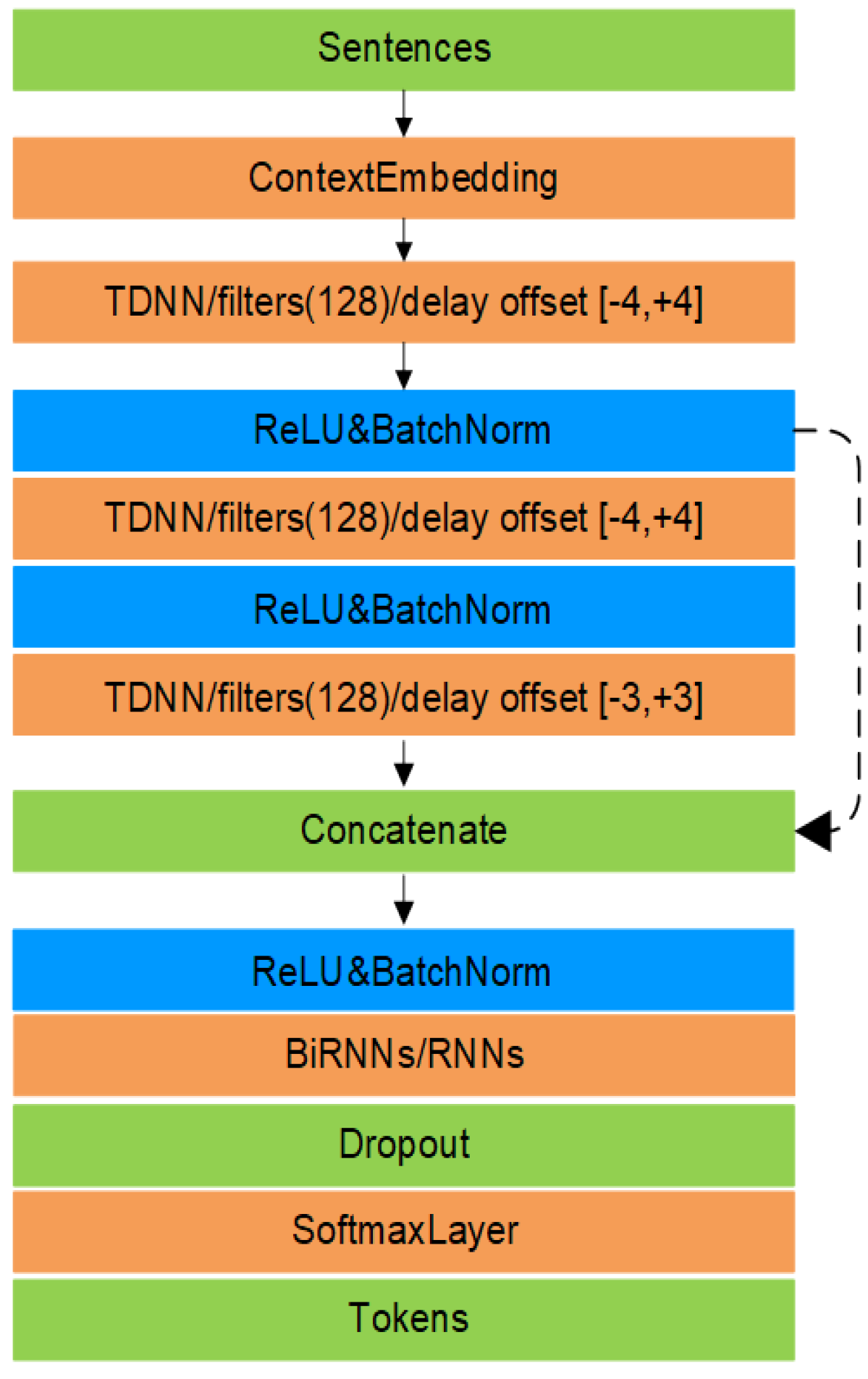
Inspired by the successful application of TDNN-BiLSTM to speech processing tasks, we combine a ResTDNN-based feature extractor with RNN (plain RNN, LSTM, GRU, and their bidirectional forms)-based classifier, to further improve the performance. Experimental results show that the combinations ResTDNN with back-end RNN achieve further improvement over the ResTDNN and RNN alone.
Recently, densely connected convolutional network (DenseNet) was proposed in [
22], which connects each layer to every other layer in a feedforward fashion. DenseNet obtained significant improvements over the state-of-the-art on four highly competitive object recognition benchmark tasks, while requiring less computation to achieve high performance in image classification tasks. DenseNets have shown several remarkable advantages: alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and enormously reduce the number of parameters.
Inspired by the DenseNets, we connect specific layers instead of every other layer in a feedforward fashion, which referred to as SC-TDNN later. Instead of using the skip connections that sums up the outputs of different TDNN layers in ResTDNN, the SC-TDNN reuses the feature from different TDNN layers, by which the representation of the target word conveys richer contextual information. Thus, the slot filling experiments yield comparable and even better performance through this method.
Similar to the aforementioned ResTDNN-RNN framework, we also experiment with the combination of SC-TDNN and RNN (and its variants as well). It is also seen that the combination of SC-TDNN with RNN achieves better results compared with those from SC-TDNN or RNN alone. In the final part of the paper, we compare the proposed models and methods with those from other literatures. We hope the experimental analysis and comparison provide useful insight for researchers in this area.
The remainder of the paper is organized as follows.
Section 2 describes the related works,
Section 3 shows the ResTDNN model,
Section 4 presents the experimental results and analysis, and
Section 5 draws the comparisons of previous results and summarizes our work.
2. Related Works
Neural network models, such as RNN and CNN, have been widely used in natural language processing (NLP) tasks. RNNs or their variants, such as LSTMs or GRUs, have been successfully applied in many different NLP tasks such as language modeling [
23] or machine translation [
24]. Deep learning has also been applied to intent detection and slot filling tasks of SLU [
25,
26]. Another important step forward is the invention of word embeddings [
27,
28], which transforms high-dimensional sparse vectors for word representations into low-dimensional dense vector representations in several natural language tasks [
29,
30]. RNN-EM [
10] used RNN with external memory architecture and got a better slot filling result than pure RNN. Using CNNs is another trend for sequence labeling [
29,
30] or modeling larger units such as phrases [
31] or sentences [
32,
33]. Distributed representations of words [
27,
28] are used as inputs for both models. Promising results were showed in the previous study [
11], which combines CNN and CRF for sentence-level optimization.
RNN-LSTM architecture was proposed in [
34] for joint modeling of slot filling, intent determination, and domain classification. They built a joint multi-domain model and investigated alternative architectures for modeling lexical context in spoken language understanding. The authors of [
35] proposed a RNN based encoder–decoder model, which sums all of the encoded hidden states through an attention weight for predicting the utterance intent. A slot-gated mechanism [
36] was proposed in order to focus on learning the relationship between intent and slot values. They obtained better semantic frame results by the global optimization. A capsule-based neural network model was proposed in [
37] for accomplishing slot filling and intent detection. They proposed a dynamic routing-by-agreement schema for the SLU task. MPT-RNN [
38] used triplets as an additional loss function based RNN model. They updated context window representation in order to make dissimilar samples more distant and similar samples close, and they got better classification results through this method. Although some pre-training models with external knowledge have worked well for many NLP tasks such as BERT-based model, large amounts of external data are often difficult to obtain and it also need large computing resources. In this paper, we study slot filling task under the single model framework and harness the time delay neural network to learn the feature representation of target word. Unlike pre-training model, our work is to conduct slot filling experiments without adding any external knowledge and additional resources. We only study the slot filling task in this work and conduct experiments with Air Travel Information System (ATIS) and SNIPS datasets.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}