Video Caption Based Searching Using End-to-End Dense Captioning and Sentence Embeddings

 , and
, and 
Abstract
1. Introduction
- A new DL-based automated approach for video searching is proposed, where two different modules work in coalesce to obtain the relevant sorted results.
- An end-to-end masked transformer-based dense video captioning model is used on a cooking-oriented dataset to perform the testing and experiments.
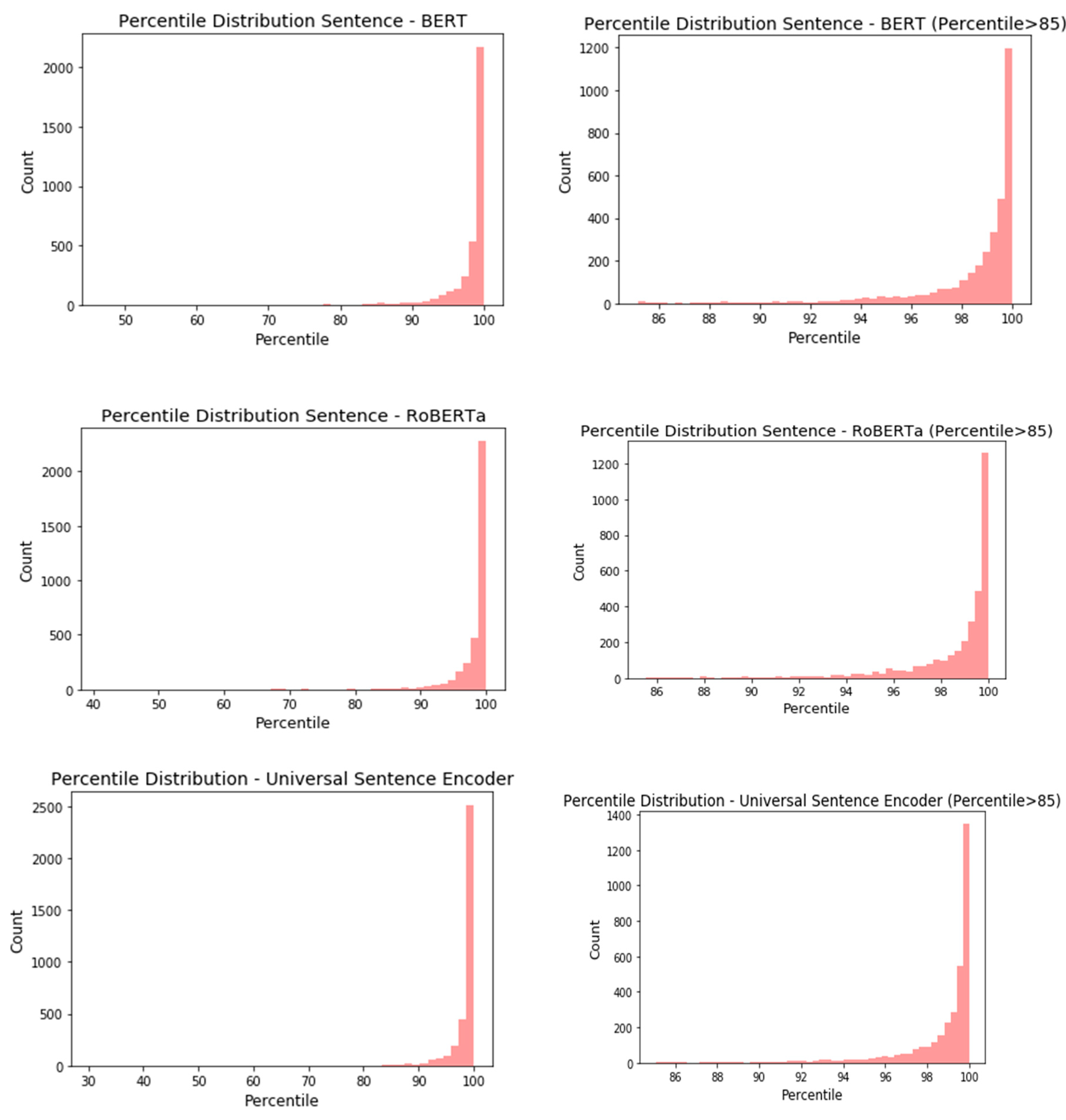
- Seven different sentence-embedding techniques are tested for encoding the captions and the queries into the same embedding space. The cosine similarity metric is used to match the queries with captions, and the same metric is used to rank the results.
2. Related Works
3. Proposed Methodology
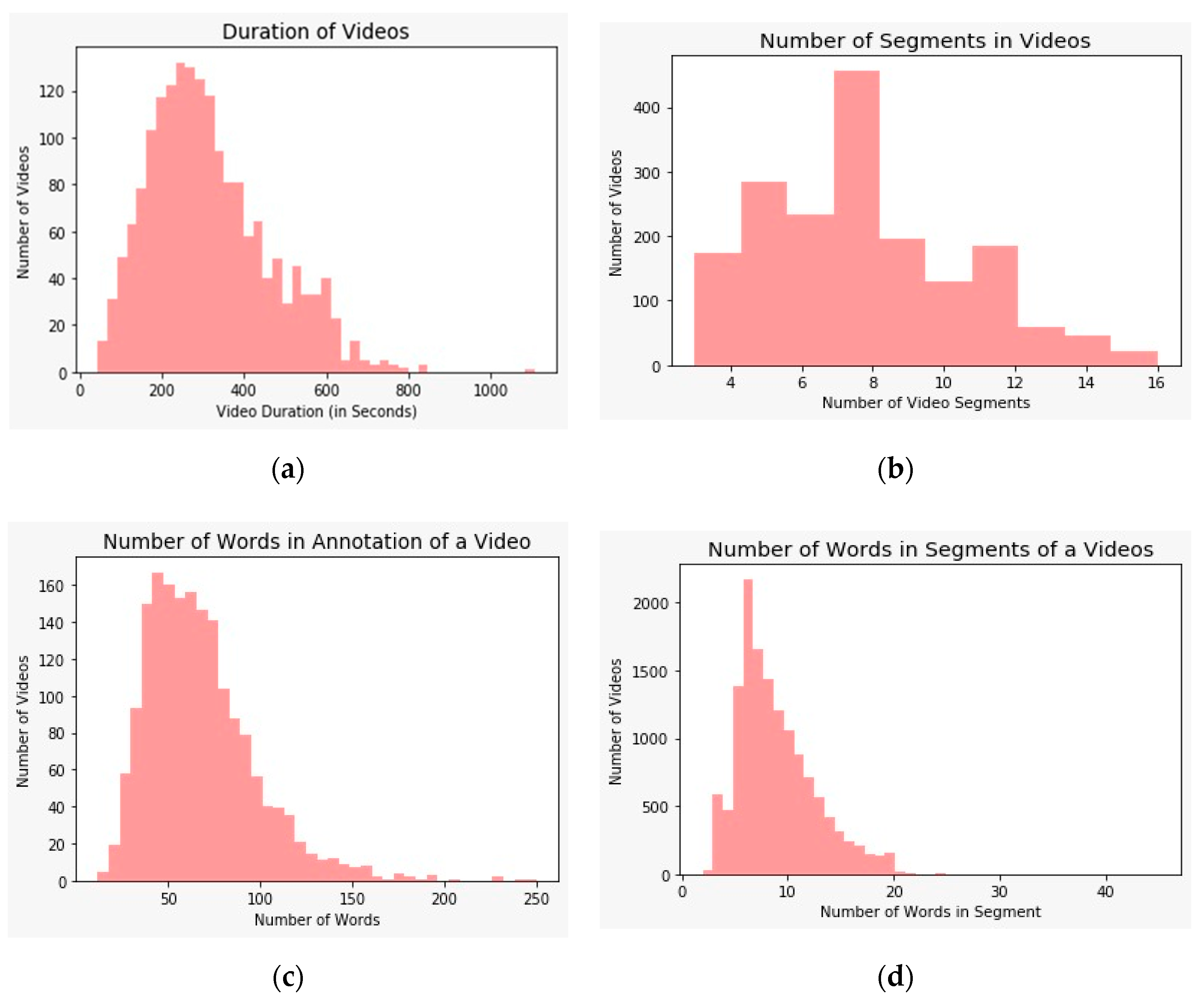
3.1. Dataset Description
3.2. Data Preprocessing
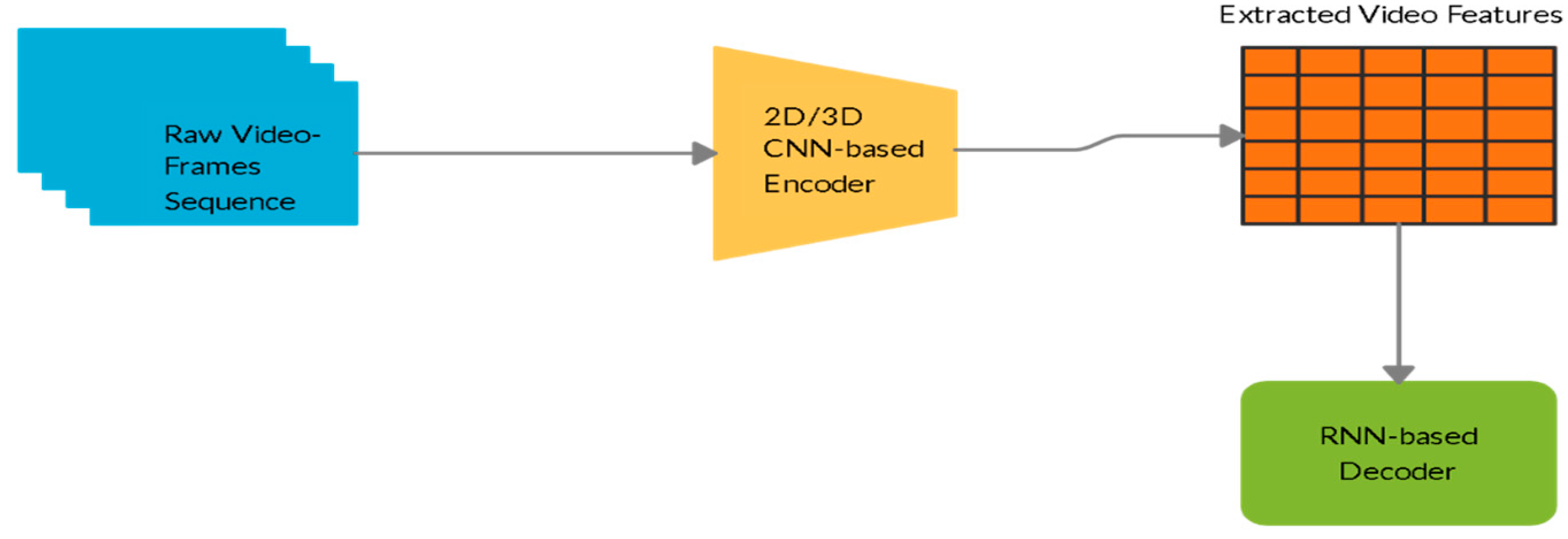
3.3. Generation of Video Captions
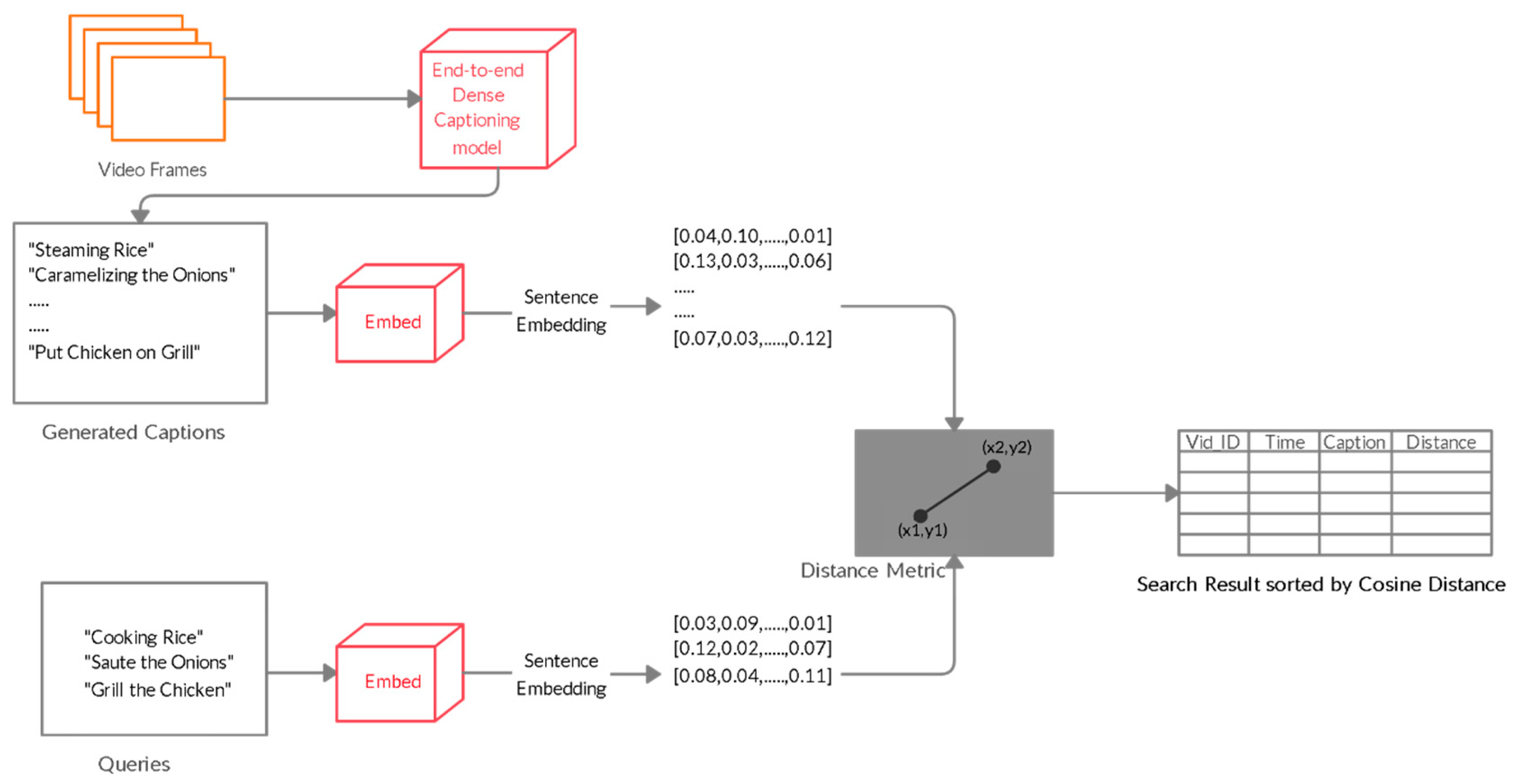
3.4. Caption Search and Sentence Embedding
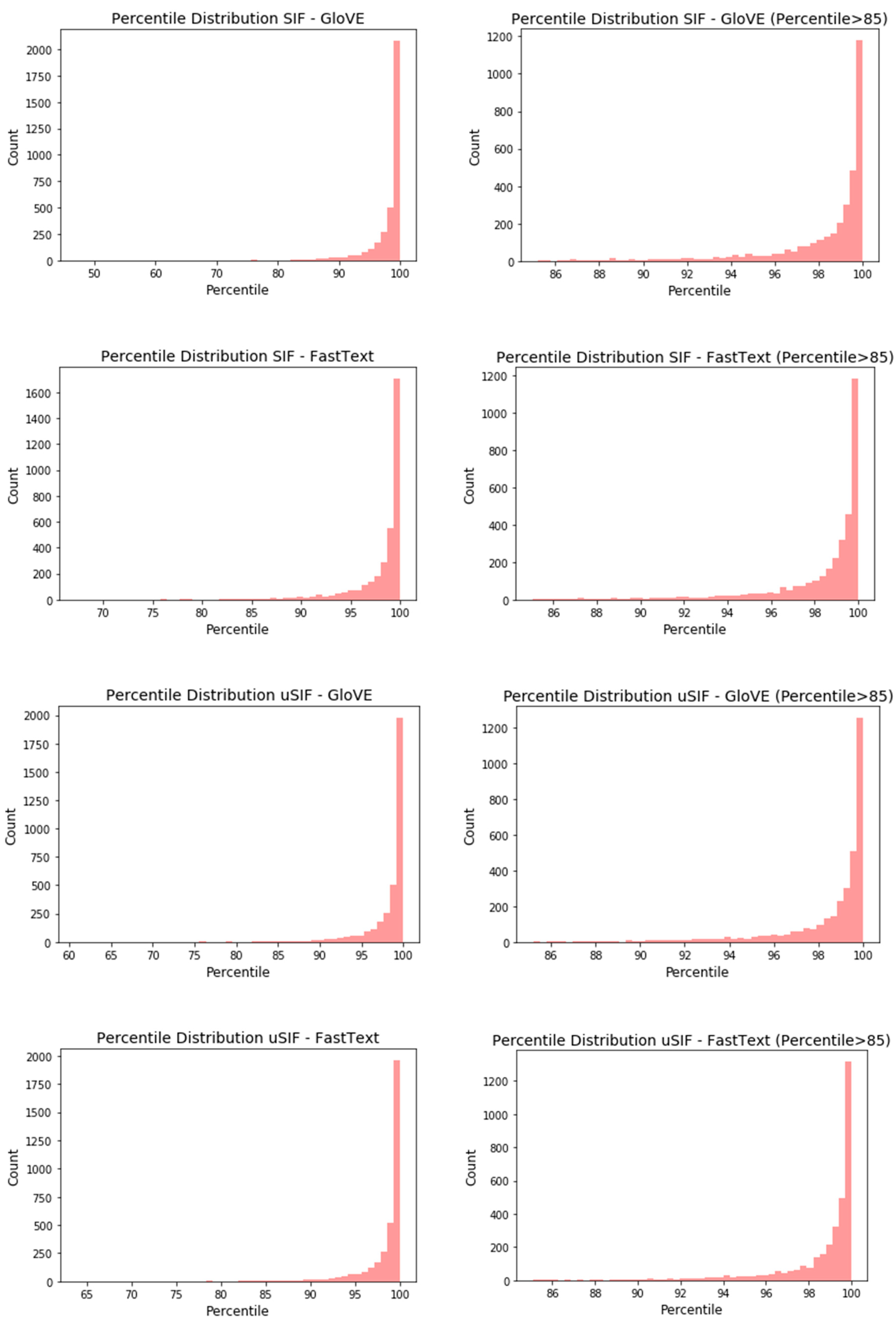
4. Results and Analysis
5. Conclusions and Future Perspective
Author Contributions
Funding
Conflicts of Interest
References
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, New York, NY, USA, 7 September 2016; pp. 191–198. [Google Scholar]
- Russakovsky, O. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Mittal, A.; Kumar, D.; Mittal, M.; Saba, T.; Abunadi, I.; Rehman, A.; Roy, S. Detecting Pneumonia Using Convolutions and Dynamic Capsule Routing for Chest X-ray Images. Sensors 2020, 20, 1068. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.-H.; Solanki, V.S.; Baraiya, H.J.; Mitra, A.; Shah, H.; Roy, S. A Smart, Sensible Agriculture System Using the Exponential Moving Average Model. Symmetry 2020, 12, 457. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26 May 2013; pp. 6645–6649. [Google Scholar]
- Hinton, G. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Process. Mag. 2012, 29. [Google Scholar] [CrossRef]
- Guadarrama, S. Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2712–2719. [Google Scholar]
- Kojima, A.; Tamura, T.; Fukunaga, K. Natural language description of human activities from video images based on concept hierarchy of actions. Int. J. Comput. Vis. 2002, 50, 171–184. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Venugopalan, S.; Rohrbach, M.; Donahue, J.; Mooney, R.; Darrell, T.; Saenko, K. Sequence to sequence-video to text. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4534–4542. [Google Scholar]
- Chen, S.; Jiang, Y.-G. Motion Guided Spatial Attention for Video Captioning; Association for the Advancement of Artificial Intelligence: Honolulu, HI, USA, 2019. [Google Scholar]
- Xu, J.; Yao, T.; Zhang, Y.; Mei, T. Learning multimodal attention LSTM networks for video captioning. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 537–545. [Google Scholar]
- Wu, Z.; Yao, T.; Fu, Y.; Jiang, Y.-G. Deep learning for video classification and captioning. In Frontiers of Multimedia Research; ACM: New York, NY, USA, 2017; pp. 3–29. [Google Scholar]
- Hershey, S.; Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; et al. CNN architectures for large-scale audio classification. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing-Proceedings, New Orleans, LA, USA, 5–7 March 2017; pp. 131–135. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Pancoast, S.; Akbacak, M. Softening quantization in bag-of-audio-words. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing-Proceedings, Florence, Italy, 4–9 May 2014; pp. 1370–1374. [Google Scholar]
- Pan, Y.; Yao, T.; Li, H.; Mei, T. Video captioning with transferred semantic attributes. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 984–992. [Google Scholar]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing videos by exploiting temporal structure. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4507–4515. [Google Scholar]
- Song, J.; Gao, L.; Guo, Z.; Liu, W.; Zhang, D.; Shen, H.T. Hierarchical LSTM with adjusted temporal attention for video captioning. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2737–2743. [Google Scholar]
- Li, X.; Zhao, B.; Lu, X. MAM-RNN: Multi-level attention model based RNN for video captioning. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2208–2214. [Google Scholar]
- Wang, H.; Xu, Y.; Han, Y. Spotting and aggregating salient regions for video captioning. In Proceedings of the MM 2018-Proceedings of the 2018 ACM Multimedia Conference, Seoul, Korea, 22–26 October 2018; pp. 1519–1526. [Google Scholar]
- Ramanishka, V.; Das, A.; Park, D.H.; Venugopalan, S.; Hendricks, L.A.; Rohrbach, M.; Saenko, K. Multimodal video description. In Proceedings of the MM 2016-Proceedings of the 2016 ACM Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 1092–1096. [Google Scholar]
- Hori, C.; Hori, T.; Lee, T.Y.; Zhang, Z.; Harsham, B.; Hershey, J.R.; Marks, T.K.; Sumi, K. Attention-Based Multimodal Fusion for Video Description. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4203–4212. [Google Scholar]
- Gkountakos, K.; Dimou, A.; Papadopoulos, G.T.; Daras, P. Incorporating Textual Similarity in Video Captioning Schemes. In Proceedings of the 2019 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Sophia Antipolis, France, 17–19 June 2019; pp. 1–6. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. Appl. Stat. 1979, 28, 100. [Google Scholar] [CrossRef]
- Xiao, H.; Xu, J.; Shi, J. Exploring diverse and fine-grained caption for video by incorporating convolutional architecture into LSTM-based model. Pattern Recognit. Lett. 2020, 129, 173–180. [Google Scholar] [CrossRef]
- Pan, Y.; Mei, T.; Yao, T.; Li, H.; Rui, Y. Jointly modeling embedding and translation to bridge video and language. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4594–4602. [Google Scholar]
- Gao, L.; Guo, Z.; Zhang, H.; Xu, X.; Shen, H.T. Video Captioning with Attention-Based LSTM and Semantic Consistency. IEEE Trans. Multimed. 2017, 19, 2045–2055. [Google Scholar] [CrossRef]
- Xiao, H.; Shi, J. Video captioning with text-based dynamic attention and step-by-step learning. Pattern Recognit. Lett. 2020, 133, 305–312. [Google Scholar] [CrossRef]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4651–4659. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. Workshop Track Proceedings. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the EMNLP 2014–2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Peters, M. Deep Contextualized Word Representations. In Proceedings of the NAACL-HLT 2018, Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. {BERT}: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kiros, R. Skip-thought vectors. In Advances in Neural Information Processing Systems 28; Curran Associates, Inc.: Montreal, QC, Canada, 7–12 December 2015; pp. 3294–3302. [Google Scholar]
- Logeswaran, L.; Lee, H. An Efficient Framework for Learning Sentence Representations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ethayarajh, K. Unsupervised Random Walk Sentence Embeddings: A Strong but Simple Baseline. In Proceedings of the Third Workshop on Representation Learning for {NLP}, Association for Computational Linguistics, Melbourne, Australia, 20 July 2018; pp. 91–100. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 670–680. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-{BERT}: Sentence Embeddings using {S}iamese {BERT}-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Cer, D. Universal Sentence Encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar]
- Zhou, L.; Xu, C.; Corso, J.J. Towards automatic learning of procedures from web instructional videos. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 7590–7598. [Google Scholar]
- Rohrbach, A.; Rohrbach, M.; Tandon, N.; Schiele, B. A dataset for Movie Description. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3202–3212. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. MSR-VTT: A large video description dataset for bridging video and language. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Heilbron, F.C.; Niebles, J.C. Collecting and annotating human activities in web videos. In Proceedings of the ICMR 2014-Proceedings of the ACM International Conference on Multimedia Retrieval 2014, Glasgow, Scotland, 1–4 April 2014; pp. 377–384. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Zhou, L.; Zhou, Y.; Corso, J.J.; Socher, R.; Xiong, C. End-to-End Dense Video Captioning with Masked Transformer. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8739–8748. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J.; Heights, Y. IBM Research Report Bleu: A Method for Automatic Evaluation of Machine Translation. Science (80-) 2001, 22176, 1–10. [Google Scholar]
- Lavie, A.; Agarwal, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 4566–4575. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Context | No. of Videos | No. of Clips | Duration (hours) | Avg. Words | No. of Words |
|---|---|---|---|---|---|---|
| YouCook2 | Cooking | 2000 | - | 176 | 8.8 | 2600 |
| MPII-MD | Movie | 94 | 68,337 | 73.6 | 9.6 | 24,549 |
| MSR-VTT | 20 Classes | 7180 | 10,000 | 41.2 | 9.3 | 29,316 |
| ActivityNet 200 | 203 Classes | 19,994 | 73,000 | 849 | 13.5 | 10,646 |
| Metric | tIoU | Average Score across All tIoUs | |||
|---|---|---|---|---|---|
| 0.3 | 0.5 | 0.7 | 0.9 | ||
| CIDEr | 16.64 | 18.57 | 21.65 | 33.84 | 22.67 |
| Bleu@4 | 1.43 | 1.35 | 1.16 | 0.70 | 1.16 |
| Bleu@3 | 4.36 | 4.20 | 3.66 | 2.74 | 3.74 |
| Bleu@2 | 10.72 | 10.84 | 10.45 | 8.06 | 10.02 |
| Bleu@1 | 24.15 | 24.29 | 23.87 | 19.40 | 22.93 |
| METEOR | 9.16 | 9.28 | 9.16 | 7.31 | 8.73 |
| Model | Top-1% | Top-5% | Top-10% | Top-15% | Median |
|---|---|---|---|---|---|
| SIF-Glove | 58.53 | 88.32 | 95.79 | 98.45 | 99.34 |
| SIF-FastText | 58.42 | 88.66 | 95.70 | 98.25 | 99.31 |
| uSIF-Glove | 61.74 | 90.38 | 97.28 | 98.85 | 99.44 |
| uSIF-FastText | 63.55 | 90.78 | 97.36 | 98.94 | 99.45 |
| Sentence-BERT | 60.85 | 90.52 | 96.99 | 98.80 | 99.37 |
| Sentence-RoBERTa | 62.23 | 91.27 | 96.91 | 98.45 | 99.42 |
| USE | 65.01 | 92.30 | 97.77 | 99.11 | 99.51 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aggarwal, A.; Chauhan, A.; Kumar, D.; Mittal, M.; Roy, S.; Kim, T.-h. Video Caption Based Searching Using End-to-End Dense Captioning and Sentence Embeddings. Symmetry 2020, 12, 992. https://doi.org/10.3390/sym12060992
Aggarwal A, Chauhan A, Kumar D, Mittal M, Roy S, Kim T-h. Video Caption Based Searching Using End-to-End Dense Captioning and Sentence Embeddings. Symmetry. 2020; 12(6):992. https://doi.org/10.3390/sym12060992
Chicago/Turabian StyleAggarwal, Akshay, Aniruddha Chauhan, Deepika Kumar, Mamta Mittal, Sudipta Roy, and Tai-hoon Kim. 2020. "Video Caption Based Searching Using End-to-End Dense Captioning and Sentence Embeddings" Symmetry 12, no. 6: 992. https://doi.org/10.3390/sym12060992
APA StyleAggarwal, A., Chauhan, A., Kumar, D., Mittal, M., Roy, S., & Kim, T.-h. (2020). Video Caption Based Searching Using End-to-End Dense Captioning and Sentence Embeddings. Symmetry, 12(6), 992. https://doi.org/10.3390/sym12060992