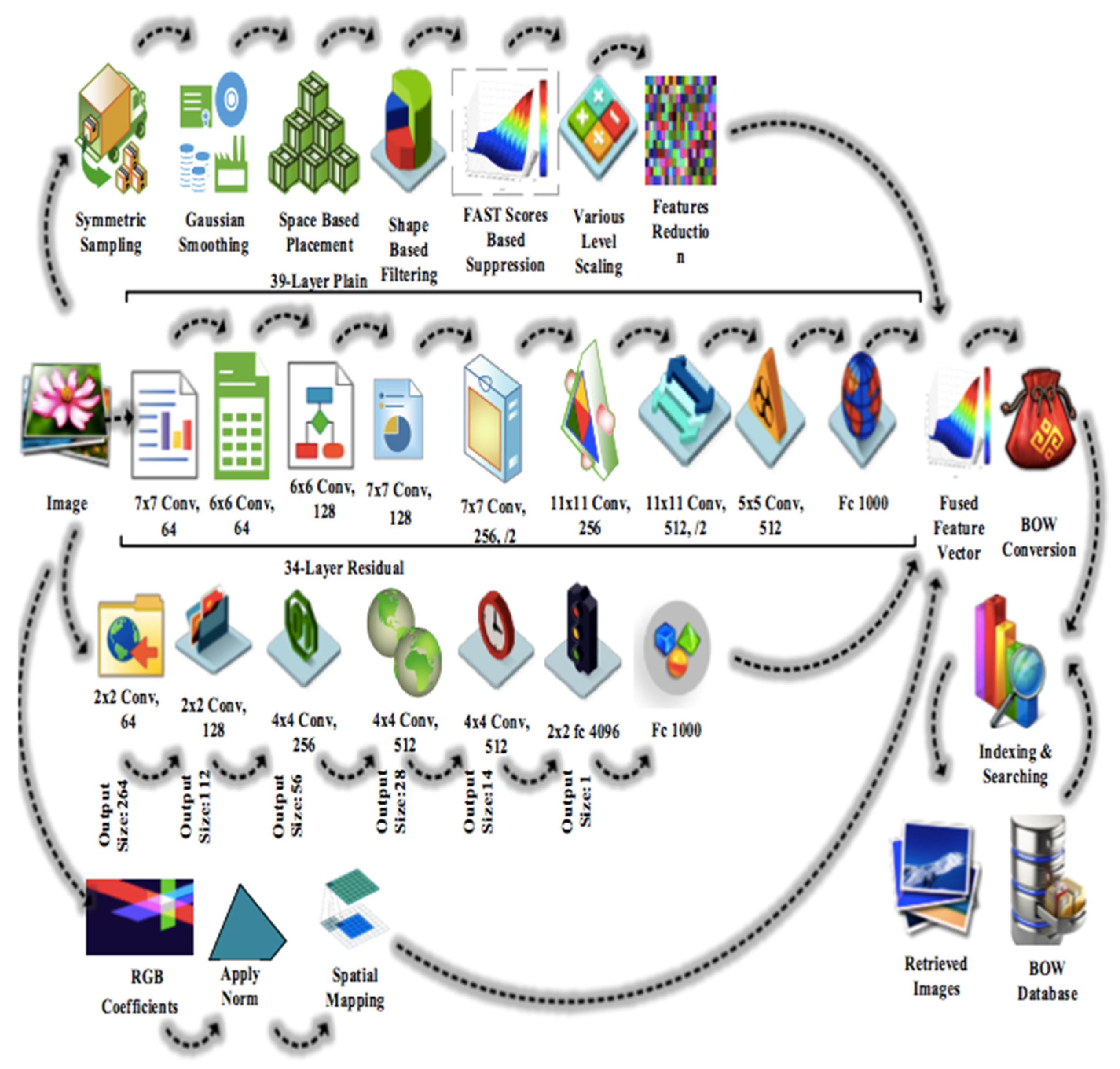
The experimentation was performed on a Core i7 machine (GPU) with 8 GB RAM. MATLAB R2019a provided the testing and training environment with CNN toolbox. Extensive experiments were performed on a variety of datasets to endorse the validity of results.
4.2.1. Results on Large Data
Experiments were performed on large datasets such as Cifar-10 and Cifar-100 to test the effectiveness of the proposed method. The Cifar-10 database contains 60,000 images with 10 different categories of 32 × 32 RGB color images [
63]. The Cifar-10 dataset contains various semantic groups such as birds, frogs, ships, dogs, cars, cats, airplanes, horses, deer and trucks. It consists of 6000 images in each category. It is therefore inevitable to produce the retrieval results with the highest throughput. The computational load is an important impact factor at this stage. Our technique adjusted it by applying proper sampling and reduction of features in three stages as follows: first, at symmetry of sampling (
Section 3.1) to maintain harmony of samples, secondly at subsampling of features (
Section 3.3) and finally by applying principal component analysis (
Section 3.7). These three levels of work resulted in prompt feature extraction and quick user response with low computational load. This was endorsed by the statistical fact that aggregate time for feature detection, extraction, fusion, CNN extraction and BoW indexing of an image was ~0.01 to 0.015 s.
The proposed method showed the highest average precision ratios in seven categories of the Cifar-10 dataset.
Figure 2 shows the sample images of different categories in which the proposed method shows the highest average precision rates. The images were classified correctly due to deep learning feature used in the proposed method. Image sampling and scaling integration with CNN features made it possible to correctly classify the images from a large range of image semantic groups, such as airplane, deer, ship, truck, horse, dog and bird. The proposed method provided above 95% mean average precision for these categories. The proposed method also showed better average precision results in some other categories, such as frog, cars and cats.
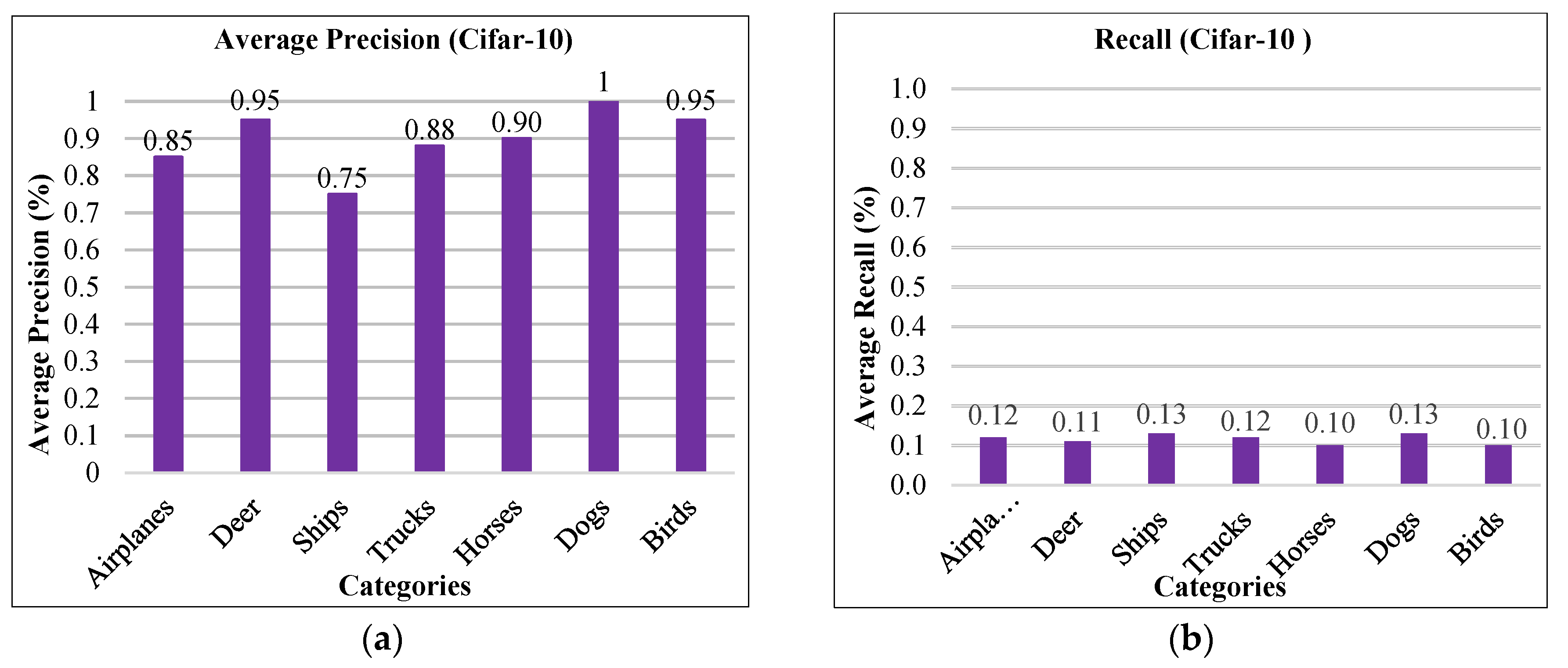
Figure 3 is the graphical representation of average precision (AP) rates in seven categories of the Cifar-10 dataset.
Figure 3a reports the highest AP rates in some categories and
Figure 3b reports outstanding recall ratio.
The tabular representation of AP rates for the Cifar-10 dataset is shown in
Table 1. The proposed method showed above 90% average precision ratio for image categories such as deer, horses, dogs and birds and above 85% average precision results in airplanes and trucks. The category dogs reported a 100% AP rate, which showed the strength of the proposed method. The proposed method showed above 70% AP rates for some other categories. The mAP was 88% in 10 categories of the Cifar-10 dataset.
Figure 4a shows average retrieval precision (ARP) for 10 categories of the Cifar-10 dataset. The proposed method reported the highest ARP ratio for the categories of airplanes and frogs. Other categories also showed above 90% ARP rates, which showed the outstanding performance of the Cifar-10 dataset.
Figure 4b shows the f-measure rate for the proposed method. A pie-chart is used to represent the f-measure. The categories airplanes, frogs, trucks, horses and dogs reported 9% f-measure rate. Other categories showed 11% f-measure rate.
The Cifar-100 dataset is the same as the Cifar-10 dataset with 32 × 32 RGB color images except that it contains 100 different categories. The Cifar-100 dataset contains various semantic groups such as bowls, rabbit, clock, lamp, tiger, forest, mountain, butterfly, elephant, willow, bus, person, house, road, palm, tractor, rocket, motorcycle, etc. It consists of 600 images in each category. The proposed method showed remarkable average precision ratios in most of the Cifar-100 categories. Sample images of Cifar-100 dataset are shown in
Figure 5.
The proposed method achieved up to 80% AP in most of the complex image categories of the Cifer-100 dataset, as shown in
Table 2. The images were classified well by the presented method. The prosed method used image sampling and shape-based smoothing with a combination of CNN features to classify images of different semantic groups. Different semantic groups of the Cifar-100 dataset include rabbit, whale, trout, flatfish, otter, sunflower, roses, apple, orange, mushroom, bottle, cups, plates, chair, wardrobe, bridge, house, camel, elephant, kangaroo, girl, man, palm, pine, willow, bus, train, rocket, tank, tractor, spider, snail, lizard and turtle. The proposed method reported 100% average precision ratios for many categories, which are mentioned in
Table 2. The proposed method showed above 84% mean average precision (mAP) rate for all categories. The proposed method provided significant ARP ratios for most of the categories. The presented technique showed f-measures between 18% and 30% for all categories.
The proposed method reported significant average precision rates for the large size dataset Cifar-100. The proposed method showed excellent performance with 100% average precision rate in most of the categories. It was also observed that the presented method showed more than 80% results in other categories. The strength of the proposed method was its significant average precision results for large datasets such as Cifar-10 and Cifar-100.
The average retrieval precision (ARP) for the Cifar-100 dataset is shown in
Figure 6. The proposed method showed outstanding ARP rates for the Cifar-100 dataset. It was observed that above 80% results were achieved in all categories.
4.2.2. Results on Texture Datasets
The ALOT (250) and Fashion (15) datasets are challenging benchmarks for image categorization and classification. These datasets are mainly used to classify texture images from semantic groups. Moreover, the number of categories is an important factor in the domain of content-based image retrieval. For this challenging reason, a large database consisting of 250 categories, the ALOT dataset, was used to test the effectiveness and versatility of the proposed method. The ALOT database [
19] contains 250 categories with 100 samples for each. ALOT dataset images have a 384
235 pixel resolution [
19]. The various semantic groups in the ALOT dataset include fruit, vegetables, clothes, spices, stones, cigarettes, sands, leaves, coins, sea shells, seeds and fabrics, bubbles, embossed fabrics, vertical and horizontal lines, small repeated patterns, etc. These categories contribute different spatial information, objects, object shapes and texture information to classify images. The presented method effectively classified the texture images from semantically similar groups with similar foreground and background objects. Symmetric sampling and norm steps were applied by the proposed method to achieve remarkable results for images with different textures. The images were effectively classified using CNN features with image sampling, scaling integration and shape-based filtering by the proposed method. Scaling on different levels and symmetric sampling were used to achieve significant AP rates for various texture images. In the ALOT dataset, most of the categories contain texture images with similar patterns and colors, whereas other categories contain different object patterns. The presented method showed significant results with up to 80% average precision rates in most of the challenging categories. Sample images for the ALOT dataset with similar colors and similar patterns are shown in
Figure 7.
The proposed method showed significant average precision results for images with similar colors and patterns, as shown in
Figure 8. It was observed that the texture images in vertical lines with the same color and with different line directions were efficiently classified and showed significant results for different image categories. Gaussian smoothing and shape-based filtering with CNN features made it possible to efficiently classify the texture images from different image categories.
The proposed method showed remarkable average precision ratios in texture images due to Gaussian smoothing and spatial mapping, applied in the presented technique. Most of the categories showed above 80% AP rates, as shown in
Figure 8a. Only one category reported 70% AP rate for the proposed method.
Figure 8b shows outstanding mean average precision rate for the image categories leaf, stone and fabric. All three categories showed between 90% and 100% mAP rates. Sample images of the ALOT dataset with different color and texture are shown in
Figure 9. The RGB coefficient step was used by the proposed method to classify different color images.
Table 3 shows the average precision ratios for the ALOT dataset with different image categories with leaf texture, stone texture, bubble texture, spices texture, sea shells texture, vegetables texture, fruit texture, seeds texture, beans texture, coins texture and fabric texture. It was observed that the proposed method showed above 90% AP rate in most of the bubble texture categories. The proposed method provided outstanding AP ratios in stone texture categories. The category leaf texture also showed significant results with 90% or more AP in most of the categories. Moreover, above 85% AP was achieved in the fabric texture category. The proposed method was also experimentally used for some other categories such as stones, cigarettes, vegetables, beans, coins, spices and fruit. Above 90% results were achieved in most of these categories by the proposed method. Moreover, above 93% mAP was achieved in all categories of the ALOT (250) dataset.
It is noticed that the proposed method showed improved performance for most of the image categories with different shapes and colors. Image sampling, shape-based filtering, RGB coefficients and spatial mapping with CNN features made it possible to effectively and efficiently classify the images. The images were with different categories such as spices, seeds, vegetables and fruit, with different colors. The proposed method showed above 90% results for most of these types of image categories. Similarly, the image categories for embossed fabrics, bubble textures and others were subjected to experiment and classified accurately. Overall, mean average precision was above 93% for all categories of the ALOT (250) dataset.
The versatility and superiority of the proposed method was tested by experimenting with the fashion dataset. The fashion dataset is more suitable for texture analysis, since it contains images with various type of texture, shapes and color objects. The fashion dataset is a challenging set of 15 object categories, which includes 293,800 HD images. The object categories contain different types of fabrics such as uniform, jacket, long dress, shirt, suit, cloak, blouses, sweater, jersey t-shirt, polo-sport shirt, robe, undergarments, vest–waistcoat and coat [
64]. In the fashion dataset, there are more than 260 thousand images with different foreground and background textures. The proposed method outperforms for the cluttered and complex objects for the reason of its object recognition capability. The image classification performed remarkably with the proposed method and showed improved AP and AR rates for overlapping, complex and cluttered objects.
Figure 10 shows sample images of the fashion dataset.
Figure 11 shows average precision and average recall rates for the fashion dataset. The proposed method was used to experiment with all 15 categories of the fashion dataset.
Figure 11a shows the significant results for AP. Three out of 15 categories show 100% AP, whereas other categories also show remarkable results with more than a 70% AP rate. Only one category, vest–waist coat, showed 40% AP rate due to the complex background and fake color images. The proposed method also showed improved results for overlay and complex images, as shown in
Figure 11b. The categories coat and uniform reported significant AR rates. The performance of the proposed method was also measured using mean average precision. More than 80% mAP was achieved by the proposed method.
Figure 12a shows ARP for the fashion (15) dataset. The proposed method showed significant ARP rates for the fashion dataset as it used the L2 color coefficient to effectively index and classify the images. Most of the categories, including bloused, jacket, coat, jersey t-shirt, long dress, robe and uniform texture, showed outstanding performance of the proposed method. The ARP rate was above 85% in many categories. The results obtained by f-measure for the fashion dataset are graphically represented in
Figure 12b. The proposed method reported encouraging f-measure results. The category vest–waistcoat showed the highest f-measure at 10%. Shirt and Polo-sport shirt reported 8% f-measure, whereas cloak and short dress showed 7% f-measure. All other categories reported 6% f-measure. The significant f- measure results showed the superiority of the presented method for the fashion (15) dataset.
4.2.3. Results on Blobs
The Corel-1000 dataset is commonly used for image classification and retrieval [
38,
67,
68]. Corel datasets consist of various image categories containing plain background images of complex objects. The dataset contains 1000 images in ten categories. The Corel-1000 dataset contains various semantic groups such as food, flowers, animals, natural scenes, buses, buildings, mountains and people. For the object detection and versatility of the image semantics, Corel-1000 was tested. The 100 images had a resolution of 256 × 384 pixels or 384 × 256 pixels for every semantic group.
Figure 13 shows sample images of the Corel-1000 dataset.
The average precision results for Corel-1000 dataset are shown in
Figure 14a. The proposed method effectively classified the blob images from semantically different groups containing different foreground and background images. The Corel-1000 dataset efficiently classified images due to the deep learning feature of the proposed methods. Image sampling, scaling, integration, shape-based filtering, RGB coefficients and spatial mapping with CNN features made it possible to effectively classify the images. The average precision results for the Corel-1000 dataset show the superiority of the proposed method in blob images due to symmetric sampling, shape-based filtering and RGB coefficient mapping. The proposed method showed significant performance in most of the categories, such as beaches, buildings, buses, dinosaurs, flowers, mountains, horses and food. For complex categories including dinosaurs, flowers and horses, the proposed method reported 100% AP rates. The category buses and mountains showed 97% and 95% AP rate, respectively. Other categories showed above 75% AP rates. The mean average precision for the proposed method was more than 89%. The presented method also showed remarkable results for average recall, as shown in
Figure 14b. The categories buses, dinosaurs, flowers and horses reported significant performance with 0.10 AR rate.
The ARP for the Corel-1000 dataset is shown in
Figure 15a. The proposed method showed remarkable ARP results for the Corel-1000 dataset.
Figure 15b shows f-measure results of the proposed method for Corel-1000 dataset. The categories African, buildings, elephants and food show 11% f-measure, whereas mountains and beaches reported a 10% f-measure, and other categories showed 9% results.
4.2.4. Results for Small and Tiny Images
The Corel 10,000 dataset [
19] contains various image categories. The Corel-10000 database is comprised of hundreds of categories where each category contains 100 images. The image size is 128 × 85 pixels or 85 × 128 pixels for every semantic group. The image size of the Corel-10000 dataset is small. The Corel-10000 dataset contains various semantic groups such as butterfly, ketch, cars, planets, flags, texture, shining stars, text, hospital, flowers, food, sunset, animals, human texture and trees etc.
Figure 16 is shown sample images of Corel-10000.
Table 4 shows average precision, average recall, ARP and F-measure of the proposed method for the Corel-10000 dataset. The proposed method showed outstanding performance in most of the image categories. The average precision rate was between 70% and 100%. The proposed method showed significant average recall rates. Most of the complex categories reported better performance with 0.10 AR rate. The proposed method showed improved performance for different categories with images of various shape and color. ARP results showed outstanding performance of the proposed method. The proposed method provided above 85% ARP ratios for most of the image categories. The proposed method also showed significant f-measure results for many categories.
The Cifar-100 dataset contains tiny images. The proposed method reported outstanding average precision and f-measure results for tiny and complex images. However, the proposed method provided significant results for tiny images of the Cifar-100 database.
4.2.5. Results of the Corel-1000 Dataset with Existing State-of-the-Art Methods
To test the effectiveness and accuracy of the proposed method, the results of the Corel-1000 dataset were compared with the existing state-of-the-art methods. The existing methods include CDLIR [
69], CBSSC [
70], CRHOG [
71], GRMCB [
72], RLMIR [
73], IKAMC [
74], AMCI [
75] and IRMSR [
76]. A graphical representation of average precision of the proposed method as compared with existing state-of-the-art methods is shown in
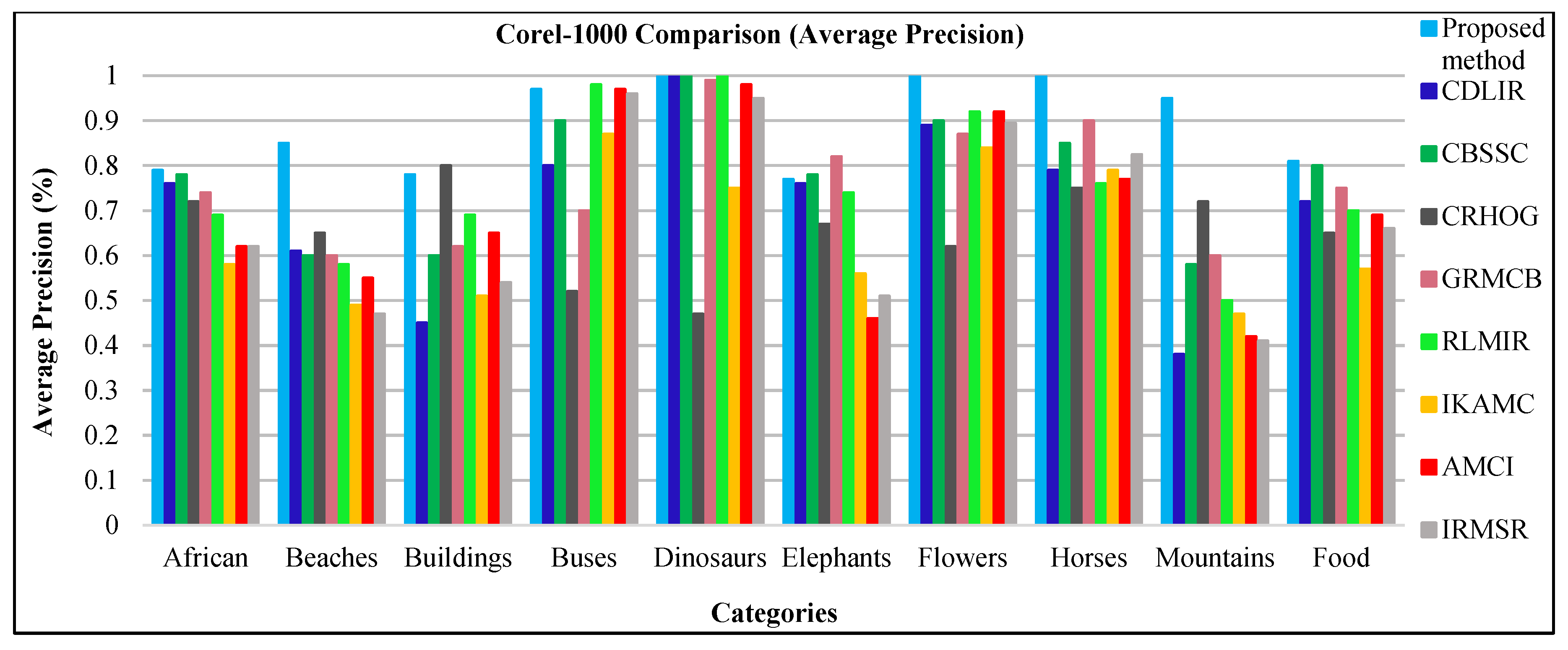
Figure 17. The proposed method showed outstanding performance in most of the categories, as compared with other methods. The presented method reported the highest average precision rates in the categories African, beaches, dinosaurs, flowers, horses, mountains and food. However, existing state-of-the-art methods showed better average precision results in some categories including buildings, buses and elephants. The proposed method also showed better accuracy in these three categories. RLMIR [
73] reported better AP for the category of buses. CRHOG [
71] shows improved AP for the category buildings and GRMCB [
72] provides better result for the category Elephants.
Table 5 shows the average precision ratio of the proposed method compared with other existing state-of-the-art methods. The performance of the proposed method showed significant average precision rates in African, food, buses, dinosaurs, flowers, horses, mountains and beaches categories.
Figure 18 shows the comparison of the proposed method with other existing methods for mean average precision. The proposed method showed highest mAP with 0.89. CBSSC [
70] reports second highest mAP as 78%. GRMCB [
72] and RLMIR [
73] provide mAP as 76%. CDLIR [
69], AMCI [
75], IRMSR [
76] and CRHOG [
71] show mAP between 0.66 and 0.76. IKAMC [
74] reports lowest mAP as 0.64.

 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}