Attentive Gated Graph Neural Network for Image Scene Graph Generation


Abstract
1. Introduction
2. Related Work
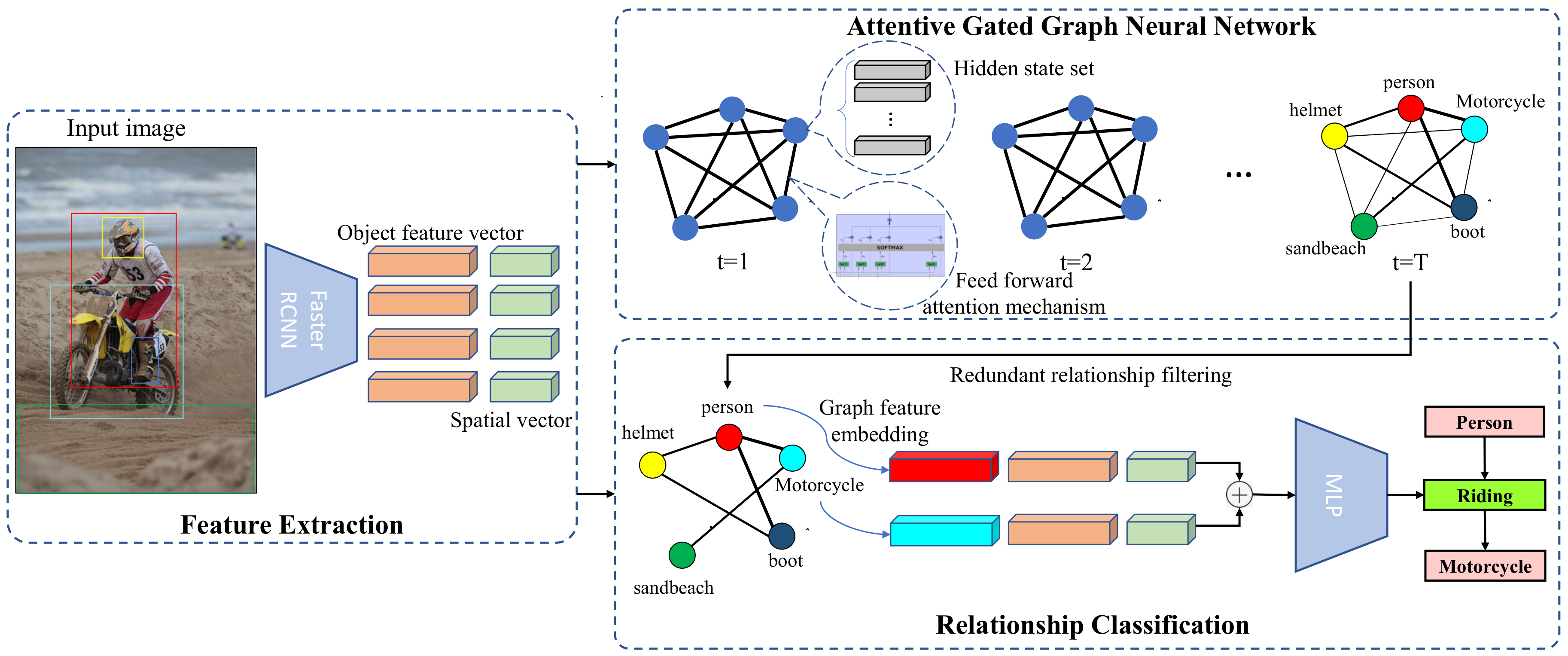
3. Methodology
3.1. Feature Extraction
3.2. Attentive Gated Graph Neural Network
3.3. Relationship Classification
4. Results
4.1. Dataset and Implementation Details
4.2. Evaluation Metrics and Tasks
4.3. Quantitative Comparisons
4.4. Qualitative Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, J.; Lu, J.; Lee, S.; Batra, D.; Parikh, D. Graph r-cnn for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–685. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5831–5840. [Google Scholar]
- Li, Y.; Ouyang, W.; Wang, X.; Tang, X. Vip-cnn: Visual phrase guided convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1347–1356. [Google Scholar]
- Klawonn, M.; Heim, E. Generating triples with adversarial networks for scene graph construction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Johnson, J.; Krishna, R.; Stark, M.; Li, L.J.; Shamma, D.; Bernstein, M.; Fei-Fei, L. Image retrieval using scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3668–3678. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Li, X.; Jiang, S. Know more say less: Image captioning based on scene graphs. IEEE Trans. Multimed. 2019, 21, 2117–2130. [Google Scholar] [CrossRef]
- Johnson, J.; Gupta, A.; Fei-Fei, L. Image generation from scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1219–1228. [Google Scholar]
- Teney, D.; Liu, L.; van Den Hengel, A. Graph-structured representations for visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1–9. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Xu, D.; Zhu, Y.; Choy, C.B.; Fei-Fei, L. Scene graph generation by iterative message passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Wang, K.; Wang, X. Scene graph generation from objects, phrases and region captions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1261–1270. [Google Scholar]
- Galleguillos, C.; Rabinovich, A.; Belongie, S. Object categorization using co-occurrence, location and appearance. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting visual relationships with deep relational networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3076–3086. [Google Scholar]
- Gkioxari, G.; Girshick, R.; Malik, J. Contextual action recognition with r* cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1080–1088. [Google Scholar]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual Relationship Detection with Language Priors. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 852–869. [Google Scholar]
- Plummer, B.A.; Mallya, A.; Cervantes, C.M.; Hockenmaier, J.; Lazebnik, S. Phrase localization and visual relationship detection with comprehensive image-language cues. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1928–1937. [Google Scholar]
- Ben-Younes, H.; Cadene, R.; Thome, N.; Cord, M. Block: Bilinear superdiagonal fusion for visual question answering and visual relationship detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8102–8109. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Wang, L.; Schwing, A.; Lazebnik, S. Diverse and accurate image description using a variational auto-encoder with an additive gaussian encoding space. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5756–5766. [Google Scholar]
- Chen, C.; Mu, S.; Xiao, W.; Ye, Z.; Wu, L.; Ju, Q. Improving image captioning with conditional generative adversarial nets. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8142–8150. [Google Scholar]
- Divvala, S.K.; Farhadi, A.; Guestrin, C. Learning everything about anything: Webly-supervised visual concept learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3270–3277. [Google Scholar]
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1974–1982. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Woo, S.; Kim, D.; Cho, D.; Kweon, I.S. Linknet: Relational embedding for scene graph. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; pp. 560–570. [Google Scholar]
- Chen, T.; Yu, W.; Chen, R.; Lin, L. Knowledge-embedded routing network for scene graph generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Cardiff, UK, 9–12 September 2019; pp. 6163–6171. [Google Scholar]
- Qi, M.; Li, W.; Yang, Z.; Wang, Y.; Luo, J. Attentive relational networks for mapping images to scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Cardiff, UK, 9–12 September 2019; pp. 3957–3966. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Liang, X.; Shen, X.; Feng, J.; Lin, L.; Yan, S. Semantic object parsing with graph lstm. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 125–143. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. arXiv 2019, arXiv:1901.00596. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Herzig, R.; Raboh, M.; Chechik, G.; Berant, J.; Globerson, A. Mapping images to scene graphs with permutation-invariant structured prediction. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; pp. 7211–7221. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Models | PredCls | SGCls | Mean | ||
|---|---|---|---|---|---|---|
| Recall@50 | Recall@100 | Recall@50 | Recall@100 | |||
| Original VG | VRD [12] | 27.9 | 35.0 | 11.8 | 14.1 | 22.2 |
| MSDN [14] | 56.0 | 61.0 | 25.8 | 27.8 | 42.7 | |
| CVG | IMP [13] | 44.8 | 53.0 | 21.7 | 24.4 | 36.0 |
| IMP+ [4] | 59.3 | 61.3 | 34.6 | 35.4 | 47.6 | |
| MotifNet [4] | 65.2 | 67.1 | 35.8 | 36.5 | 51.1 | |
| Graph R-CNN [3] | 54.2 | 59.1 | 28.5 | 35.9 | 44.4 | |
| KERN [28] | 65.8 | 67.6 | 36.7 | 37.4 | 51.9 | |
| GPI [34] | 65.1 | 66.9 | 36.5 | 38.8 | 51.8 | |
| ARN [29] | 56.6 | 61.3 | 38.2 | 40.4 | 49.1 | |
| Ours w/o att+emb | 57.3 | 59.8 | 31.7 | 33.8 | 45.7 | |
| Ours w/ att | 63.5 | 65.9 | 35.4 | 37.1 | 50.5 | |
| Ours w/ emb | 59.1 | 61.8 | 33.6 | 35.3 | 47.4 | |
| Ours full | 65.1 | 67.2 | 36.8 | 38.2 | 51.8 | |
| DCVG | Ours w/o att+emb | 58.6 | 61.3 | 33.9 | 35.8 | 47.4 |
| Ours w/ att | 65.3 | 67.2 | 37.2 | 38.5 | 52.0 | |
| Ours w/ emb | 60.7 | 63.2 | 36.3 | 37.7 | 49.5 | |
| Ours full | 66.2 | 68.3 | 38.5 | 40.1 | 53.3 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Tang, M.; Zhang, J.; Jiang, L. Attentive Gated Graph Neural Network for Image Scene Graph Generation. Symmetry 2020, 12, 511. https://doi.org/10.3390/sym12040511
Li S, Tang M, Zhang J, Jiang L. Attentive Gated Graph Neural Network for Image Scene Graph Generation. Symmetry. 2020; 12(4):511. https://doi.org/10.3390/sym12040511
Chicago/Turabian StyleLi, Shuohao, Min Tang, Jun Zhang, and Lincheng Jiang. 2020. "Attentive Gated Graph Neural Network for Image Scene Graph Generation" Symmetry 12, no. 4: 511. https://doi.org/10.3390/sym12040511
APA StyleLi, S., Tang, M., Zhang, J., & Jiang, L. (2020). Attentive Gated Graph Neural Network for Image Scene Graph Generation. Symmetry, 12(4), 511. https://doi.org/10.3390/sym12040511