1. Introduction
Context-awareness is a popular term in the context of computing, because of the popularity of Internet of Things (IoT), particularly the recent advanced features in the most popular IoT device, i.e., smartphones. In the real world, users’ interest on “Mobile Phones” is more and more than other platforms such as “Desktop Computer”, “Laptop Computer” or “Tablet Computer” over time [
1]. In addition to voice communication, people use smartphones for using various categories of apps like social networking system, tourist guide, shopping recommendation, instant messaging, medical appointment etc [
2]. Users’ behaviour with these apps may vary from user to user according to their contextual information in different dimensions such as temporal context, work status in workday or holiday, spatial context, their emotional state, Wifi status, or device related status etc. Although all these relevant contexts might have influence in apps usage behaviour of individuals, it may cause inefficient problem because of
higher dimensions of contexts. Thus, it’s important to study on
principal component analysis based on these contexts in order to build an effective and efficient context-aware apps prediction model.
Let us consider a real-world motivational example related to our ContextPCA model. Suppose, a smartphone user, Alice is a post graduate research student of Swinburne University of Technology. She has installed a large number of smartphone apps such as Facebook, LinkedIn, Twitter, Outlook email, Youtube, eHealth service, location tracking, instant messaging, read news etc. on her smartphone. Dynamic searching and efficiently finding these apps according to the needs in her various day-to-day situations would be useful. Although, homescreens of recent advanced smartphones provide easy access of the useful apps without additional searching effort, the homescreen is unaware about her current contexts, e.g., time. Consequently, the phone becomes unable to intelligently manage the useful apps according to her needs, as her current contexts may change over time. An efficient and effective context-aware apps prediction model could solve such problem and provide the required services. In the area of artificial intelligence and machine learning, tree-like model is one of the most popular approaches for predicting context-aware smartphone usage [
3,
4]. However, real-life phone usage data may contain
higher dimensions of contexts, which may cause several issues like increases model
complexity, may cause
over-fitting problem, or decreases the model
prediction accuracy. Thus, the research question is -
how to effectively minimize these issues while building a context-aware apps usage model? Therefore, in this paper, we aim to focus on effectively reducing
higher dimensions of contexts for building an intelligent context-aware smartphone
apps usage predictive model based on machine learning techniques.
In the area of machine learning, there are typically two types of dimensionality reduction approaches such as feature elimination and feature extraction. In feature elimination approach, the features that are unnecessary are simply pruning from a dataset. We may lose any potential information gained from the dropped features. On the other hand, feature extraction creates new variables by combining the existing features and allows to maintain all important information held within features. As each contextual information might have an influence on individuals apps usage behaviour, we consider
feature extraction approach rather than elimination. Principal components analysis (PCA) is an unsupervised, non-parametric statistical technique primarily used for dimensionality reduction in machine learning, that uses an orthogonal transformation which converts a set of correlated variables to a set of uncorrelated variables, which is briefly discussed in
Section 3. It thus enables to identify correlations and patterns in a data set to transform into significantly lower dimension datasets without loss of any important information.
In this paper, we present an effective
principal component analysis (PCA) based context-aware smartphone apps prediction model,
“ContextPCA” using decision tree machine learning technique. In our earlier paper, we built an apps usage prediction model based on contexts [
5]. Thus the key difference is focusing on
handling higher dimensions of contexts based on principal component analysis in an apps usage prediction model. In our ContextPCA model, we first preprocess the raw apps usage datasets of individual users, that includes missing data handling, data encoding, and data scaling for further analysis. After that, we extract the contextual features from the training dataset based on principal component analysis and create a number of principal components that are less than the number of original context dimensions. Once the contexts have been processed into the principal components, we then construct a decision tree on the processed training dataset to achieve our goal. The effectiveness of producing different number of principal components and the ContextPCA model is studied through a number of experiments.
The contributions of this work can be summarized as follows.
We first highlight the significance of Principal Component Analysis (PCA) for higher dimensions of contexts in a machine learning based context-aware smartphone apps usage prediction model.
We have collected contextual apps usage datasets consisting of different categories of apps usages in different contexts that include both the user-centric context and device-centric context form individual smartphone users. We then analyse our collected apps usage datasets in terms of context dimensions, in order to build a PCA-based context-aware prediction model “ContextPCA" using the decision tree classification approach.
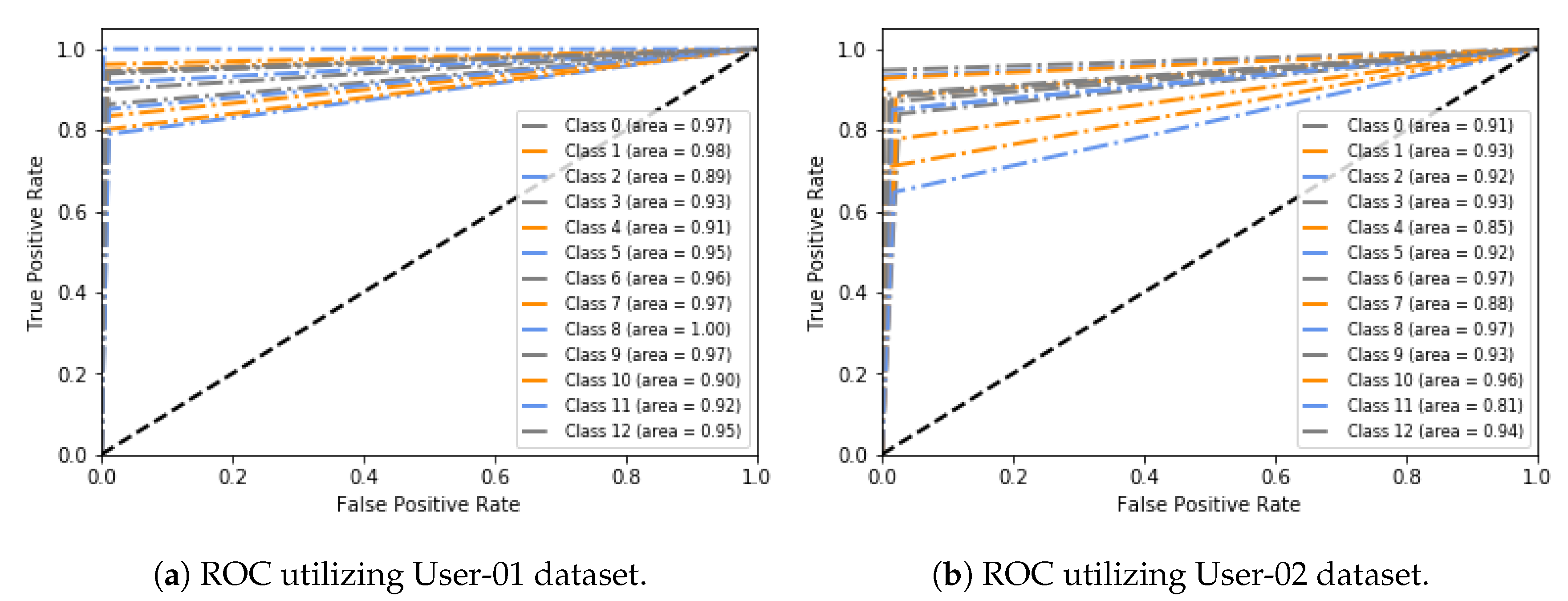
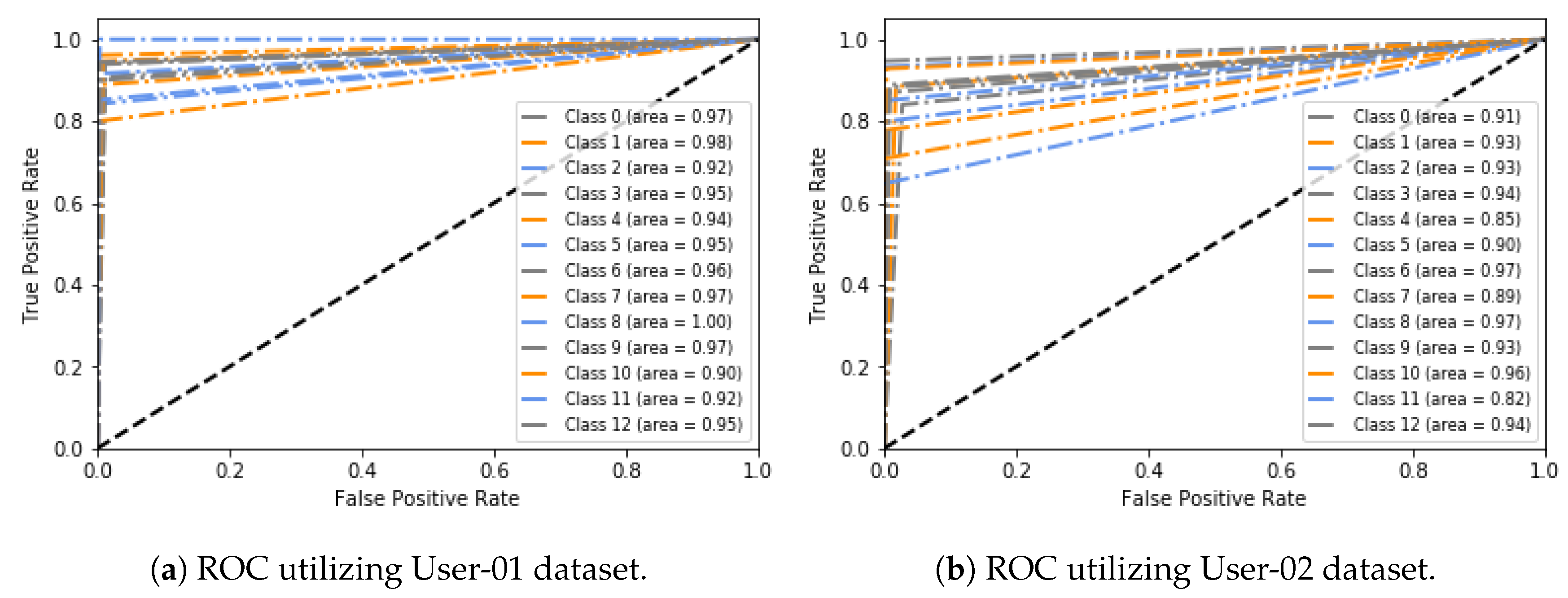
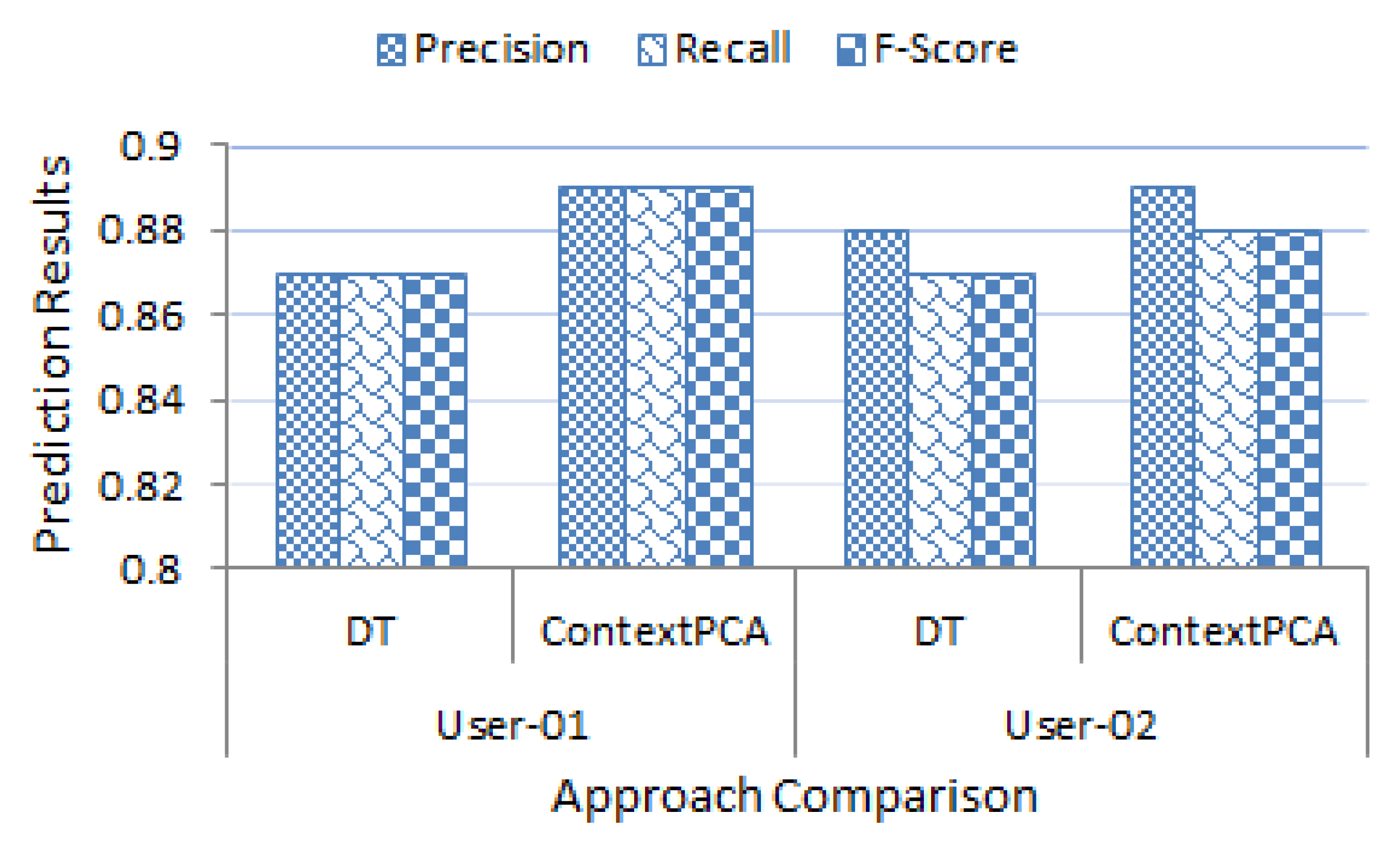
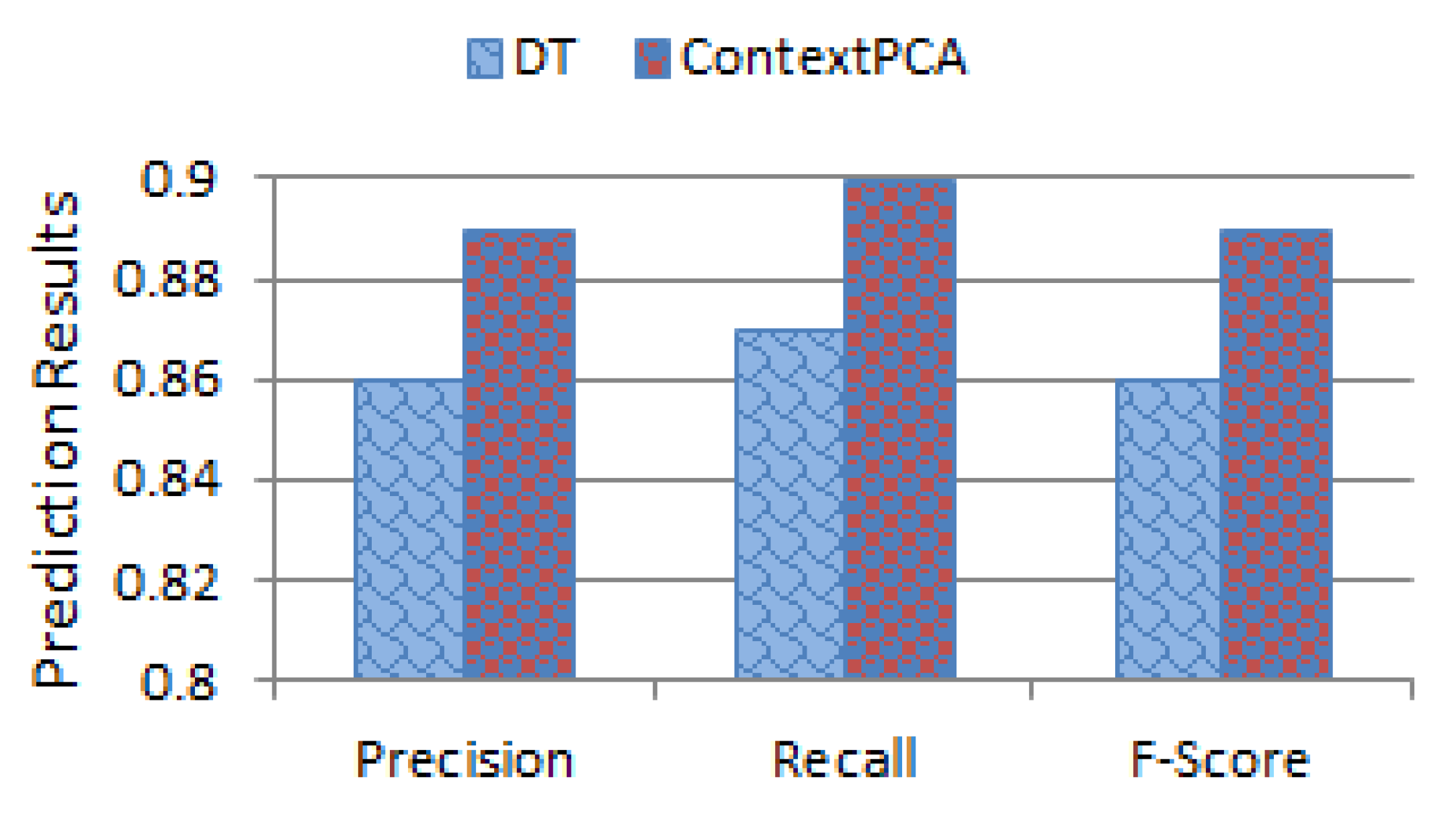
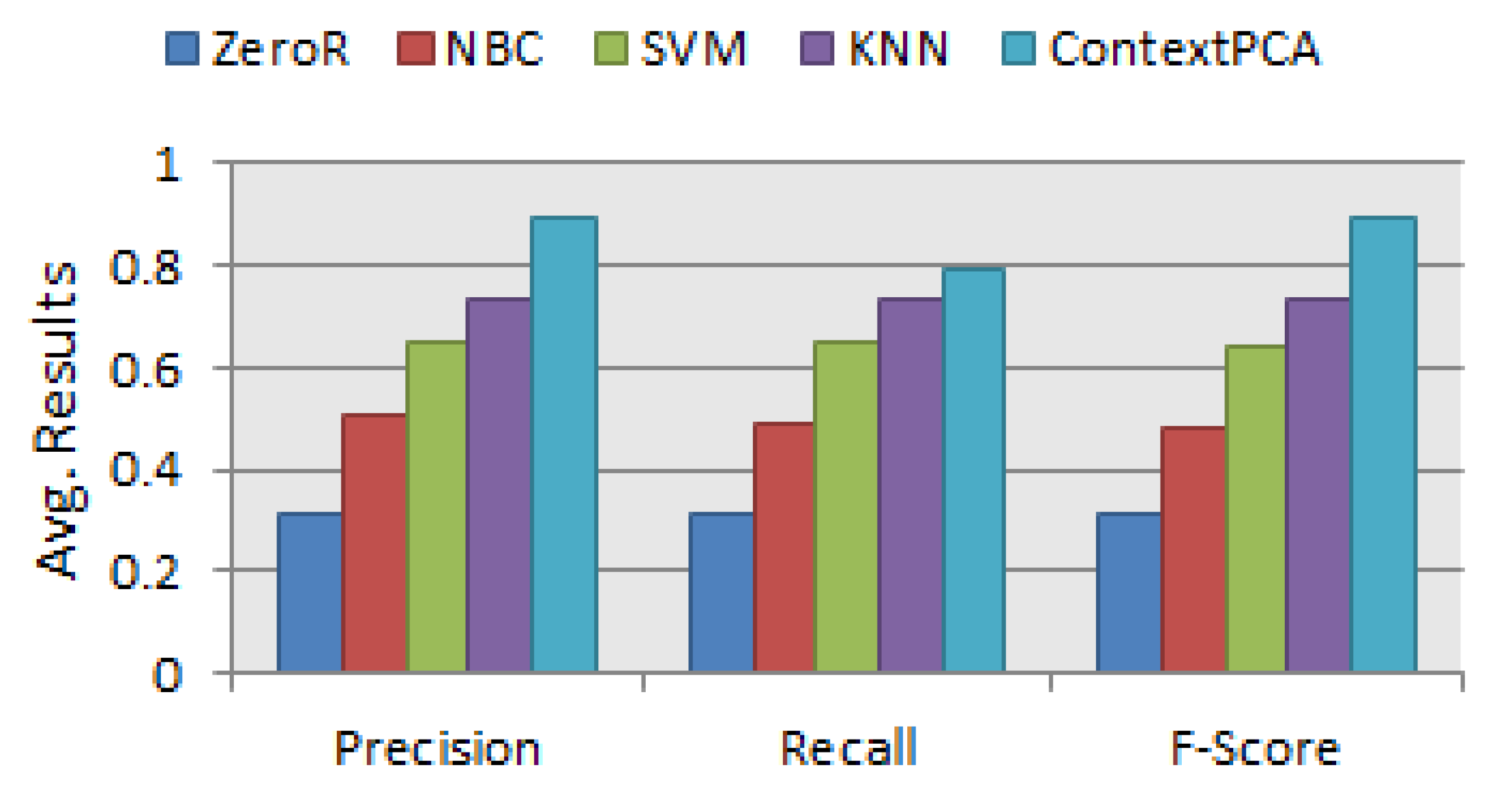
Finally, we conduct experiments to evaluate the effectiveness of different principal components in our ContextPCA model. The experimental results show that our ContextPCA model significantly outperforms for predicting context-aware smartphone apps.
The rest of the paper is organized as follows.
Section 2 provides background and related work of machine learning classification approaches, and corresponding context-aware mobile services.
Section 3 gives an overview of the principal component analysis. In
Section 4, we present our ContextPCA model based on machine learning techniques. We have shown the experimental results on phone apps usage dataset in
Section 5. Finally,
Section 6 concludes this paper and highlights the future work.
2. Background and Related Work
To solve the prediction problems, classification learning is well-known and popular technique in the area of machine learning and data science. The goal of classification typically is to accurately classify or predict the given class labels of instances, whose contextual features or attribute values are known, but class values are unknown [
6].
Although, association learning is another popular approach in the area of machine learning and data science and can be used for user behavioural analytics [
7,
8,
9,
10,
11], we particularly focus on classification approach for the purpose of building a prediction model in this work. Classification learning techniques typically build the model using a given training dataset and then the resultant model can be used to predict the class label for a test case. Effectively modelling and predicting smartphone usage behaviour various machine learning techniques can be used. For instance, to build the prediction model in the area of mobile environment, ZeroR as base classifier, probability based naive Bayes classifier, support vector machines, instance based k-nearest neighbours, logistic regression, artificial neural network or deep learning, rule-based learning like decision trees, ensemble learning like random forest have been used [
6,
12]. These machine learning classifiers are frequently used in context-aware mobile analytics [
12].
Among the traditional machine learning techniques, tree based context-aware model is more effective for predicting users’ behavioural activities in different contexts [
12]. A very well-known and mostly discussed tree based machine learning technique for building prediction model is decision trees [
13]. ID3 algorithm proposed by Quinlan et al. is known as the core algorithm for building decision trees [
14]. ID3 mainly constructs a top-down decision tree that follows a greedy searching procedure through the given training dataset. The entropy and information gain values are determined to select the best attribute or feature available in the datasets [
14]. A modified algorithm named C4.5 algorithm proposed by Quinlan later, which is based on the ID3 algorithm [
13]. This algorithm also builds decision trees using the concept of information gain mentioned earlier from a training dataset. Another gain based behavioral decision tree algorithm BehavDT has been proposed by Sarker et al. [
4]. Decision tree classification approach is frequently used in the area of context-aware systems and services [
3,
15,
16,
17]. Recently, Sarker et al. use random forest ensemble learning technique consisting of multiple decision trees for predicting context-aware smartphone usage [
5]. However, in that work, the authors particularly focus on how a single decision tree is affected by higher dimensions of contexts to build a context-aware model.
Unlike the above approaches and context-aware models, in this work, we present an effective principal component analysis (PCA) based context-aware smartphone apps prediction model, “ContextPCA” using decision tree machine learning technique. In this model, we aim to focus on reducing higher dimensions of contexts for building an effective context-aware smartphone apps usage predictive model based on machine learning techniques.
3. Principal Component Analysis
In the area of machine learning and data science, Principal Component Analysis (PCA) is a well-known unsupervised learning method. PCA is a mathematical procedure that transforms a number of correlated variables into a number of uncorrelated variables called principal components. PCA was at first presented in the area of non-arbitrary factors by Pearson [
18] and reached out to irregular one by Hotelling [
19]. Given a dataset having the number of dimensions
n, PCA intends to find a linear subspace of dimension
d, where
such that the data points exist mainly on this linear subspace.
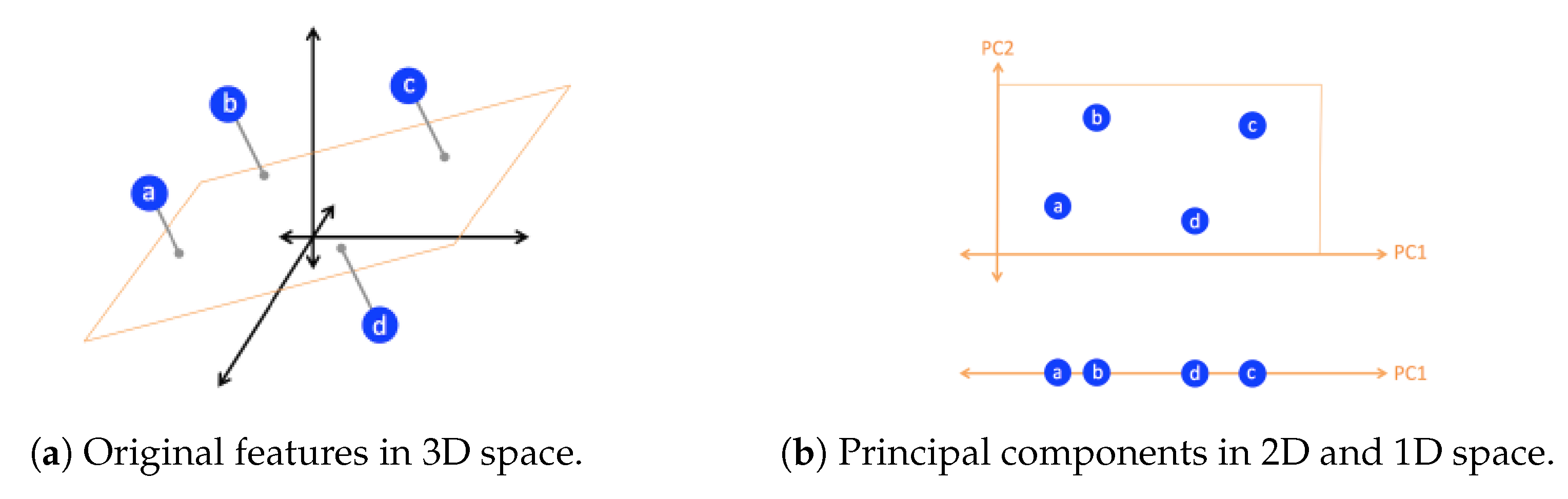
Figure 1 shows an example of - how PCA effects on the dimensions of a given dataset. For instance, the original data instances have three features that are shown in
Figure 1a with 3D space. After applying PCA, these data points can be reduced to two features shown in top of the
Figure 1b, by projecting them onto a 2D plane with the principal components PC1 and PC2. Using PCA, the data can be further reduced to only one feature shown in bottom of
Figure 1b, by projecting them onto a 1D line with the principal component PC1. The principal components mentioned above are orthogonal and linear transformations of the original data points, so that it could reduce the original dimensions
, in which we are interested in this PCA based context-aware smartphone apps usage model named “ContextPCA”.
In the following, we summarize the basics of PCA including relevant mathematical equations. Lets consider
,
a set of data vectors, PCA creates the
d principal axes based on those orthonormal axes onto which the variance retained under projection is maximal. This is known as the most common definition of PCA, due to Hotelling et al. [
19]. In order to capture the variability as much as possible, we first choose
as a principal component having maximum variance. Let the first principal component be a linear combination of
X defined by coefficients or weights
, and can be written in matrix form as
. Thus the equation can be found as:
where
S is the
sample covariance matrix of
X defined above. According to this equation
can be made arbitrarily large by increasing the magnitude of
w. Hence, above optimization problem is defined as maximization problem with respect to a constraint such that
with respect to
. To solve this optimization problem a Lagrange multiplier
is introduced and corresponding Lagrange function is constructed as:
The solution of Equation (
2) can be obtained by considering partial differentiation with respect to
w and
and further processing. Thus, the equations can be obtained as:
If
is the largest eigenvalue of
S, then
is maximized. Based on the equations involved
and
w are an eigenvalue and an eigenvector of
S. Differentiating Equation (
2) with respect to the Lagrange multiplier
results constraint as:
Thus, it has been shown that the normalized eigenvector with the largest associated eigenvalue of the sample covariance matrix S gives the first principal component. A similar argument can show that the first d principal components are determined by the d dominant eigenvectors of covariance matrix S.
4. Materials and Methods
4.1. Contextual Data Collection and Description
In this work, we take into account a number of contexts including not only the user-centric context such as spatio-temporal context of the users, their mood or preferences, etc., but also the device-centric context considering users’ influences for their usage. Hence, we summarize these contextual information that are used in our ContextPCA model. These are:
Smartphone apps: In this work, different categories of smartphones’ apps such as social networking, instant messaging, mobile communications, entertainment, or other apps related to users’ daily life services are considered in order to build our ContextPCA model. For instance,
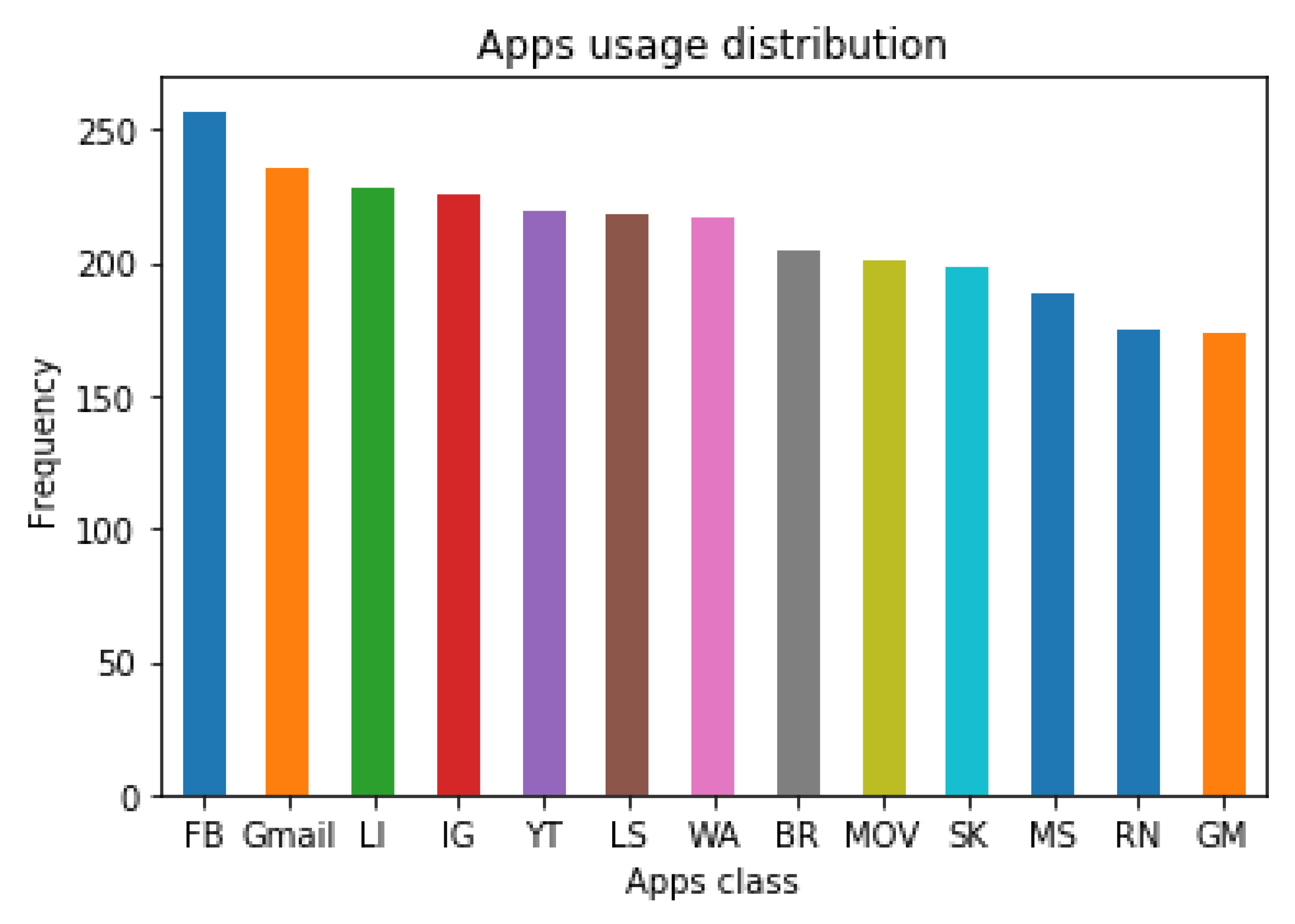
Figure 2 shows the distributions of different types of apps like Facebook (FB), Gmail, LinkedIn (LI), Instagram (IG), Youtube (YT), Live Sport (LS), Whatsapp (WA), Browsing (BR), Movie (MOV), Skype (SK), Music (MS), Read News (RN), Games (GM) of a sample user.
Contexts: According to the general definition of context, it could be anything to characterize the situation of an entity. In this work, a smartphone user can be represented as an entity. Thus, different dimensions of information might have an influence on the apps usage of smartphone users. For instance,
temporal context that represents time related information of the users’ apps usage behaviour. Temporal context is one of the significant and primary contexts that have highly influence on smartphone users for their activities with their phones [
20]. In addition to such temporal information, users’
work status could be another context heavily impacts on apps usage for many individuals. For instance, apps usage behaviour of an individual user on Saturday, say a holiday, may differ with her usage on Monday, a first working day in a week. Although, it is related to the temporal context in terms of week day and week end, however, it also represents individuals’ working status, which is significant context in order to model smartphone apps usage behaviour according to their preferences.
Spatial context could be another significant context that represents users’ spatial information, e.g., one’s current location at office. As spatio-temporal context is popular for building human-centric context-aware applications, such spatial context could play a role in our smartphone apps usage behaviour model.
User mood could be another significant context that impacts on individuals, particularly on human centric applications. For instance, one individual user typically likes to listen only her top favourite musics when her emotional state is in a happy mood, while likes to chatting with her close friends on social media when her emotional state is in a sad mood.
Besides these user-centric contexts that are related to users’ day-to-day situations or personal preferences, users’ own device related contexts also important for modelling users’ apps usage behaviourr. Such contextual information could be one’s phone profile, phone battery level or charging status etc. that might have an influence on users to use various categories of smartphone apps. For instance, if one’s device gives low power signal, she typically might not be interested to connect her device with the Internet in that context for using an entertainment app like watching Youtube video. For modelling users’ apps usage behaviour
Internet connectivity and speed might also have an impact in our real world life. Thus, in this work, we consider all these contextual information in our PCA based modelling. We have summarized the detailed picture of the contexts that are used in our ContextPCA model in
Table 1. To collect these contextual information from individual users, we have randomly chosen ten participants and collected their datasets from June 2018 to October 2018 for the purpose of doing experiments.
4.2. Preprocessing of Contextual Data
To build our ContextPCA model, we need exploratory data analysis collected by us to feed our target machine learning classification technique. In this procedure below tasks are involved for this work.
Missing data handling: In our datasets, we found only a few number of missing data that occurs during the data collection process. Thus, due to anomaly raised in contextual data collection, we first remove all the missing data and consider the relevant contextual features and corresponding data-values.
Contextual feature encoding: As we have seen that
Table 1 contains contextual information including categorical context. In order to fit these data to the machine learning based model, it is needed to convert all the categorical contextual features into vectors. To do this task, the most common approaches are “Label Encoding” and “One Hot Encoding”. In one hot encoding technique, a significant number of features increases, and consequently increases the data dimensions. On the other hand, in label encoding, the number of features remains the same as the feature-values directly converted into a specific numeric values. As we have taken into account a variety of contexts discussed above, one hot encoded features might have sparse data which could makes the model inefficient in terms of processing time because of handing additional high dimensions of data. Thus, in this ContextPCA model, we consider label encoding technique rather than one hot encoding in our pre-processing task. Lets consider an example in terms of context user mood. Label encoding can turn user diverse mode [happy, sad, normal, happy, sad] into vectors [0, 1, 2, 0, 1] representing numeric values.
Feature scaling: In data processing, it is also known as data normalization. Feature scaling is a method used to normalize the range of independent variables or contextual features of data. We use Standard Scaler that normalizes the features with the mean = 0 and standard deviation = 1.
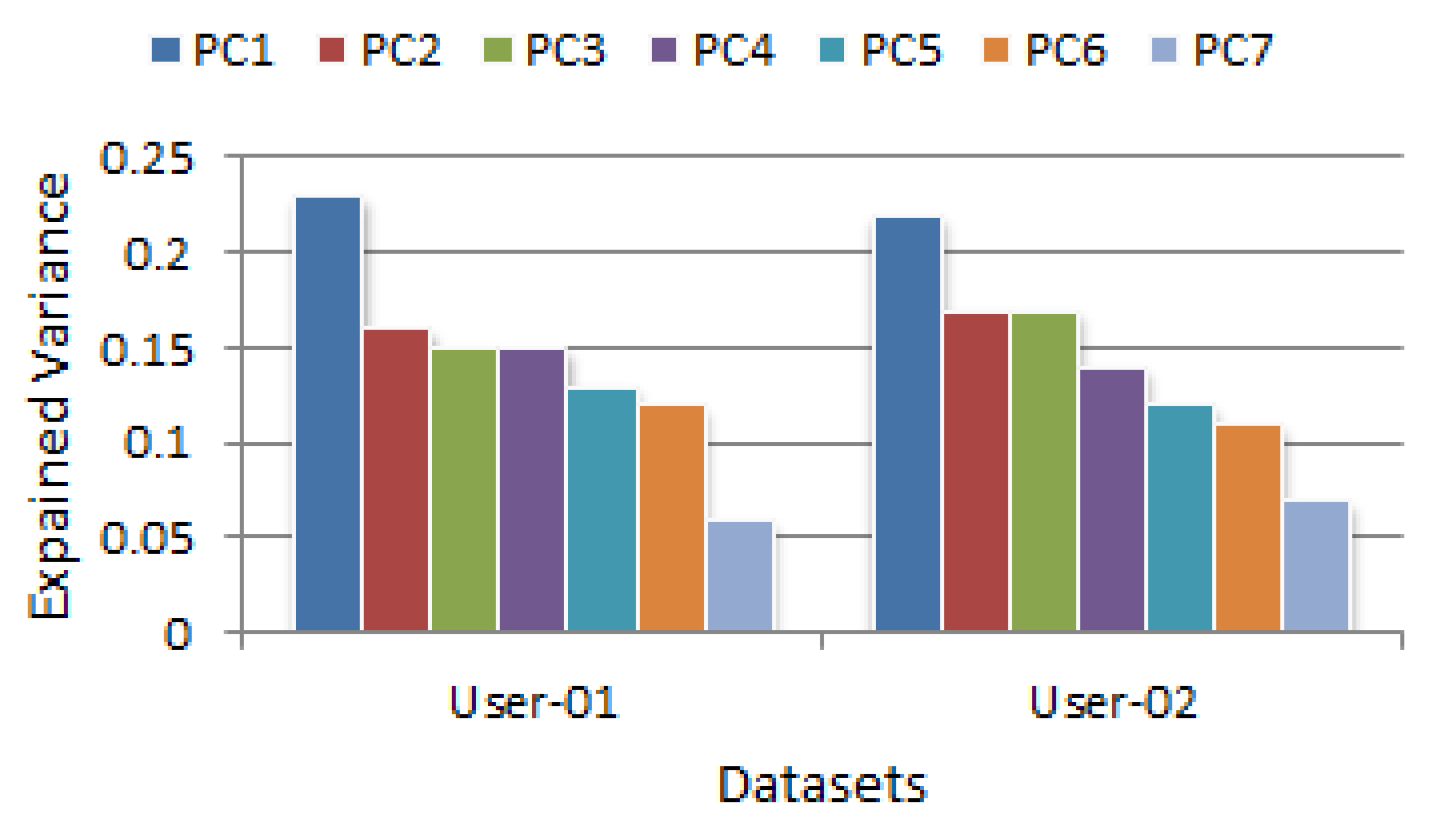
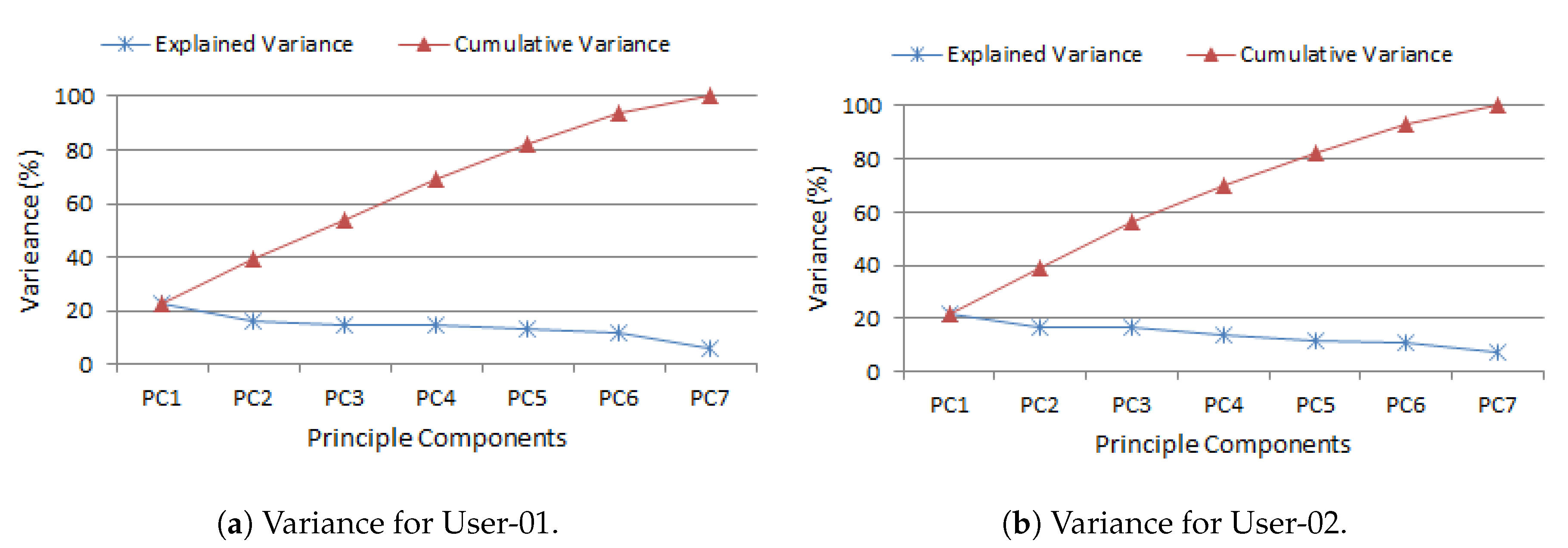
4.3. PCA-Based Decision Tree Generation
Once the preprocessing of contexts has been completed, we generate a PCA based decision tree in order to build ContextPCA model. To build a PCA based decision tree, we use the principal components rather than using all the contexts discussed above. For this, we first create a number of principal components based on principal component analysis discussed above. It thus enables to identify correlations and patterns in a data set to transform into significantly lower dimension datasets without loss of any important information. After generating the principal components, we employ the most popular machine learning algorithm decision tree on the generated components [
13]. Decision tree algorithm builds decision tree from a training dataset, using the concept of entropy and information gain [
13].
In terms of structure, a decision tree builds a tree-like model that includes a root node from where the tree starts top-down growing, a number of internal or interior nodes that represent the test cases, and corresponding leaf nodes that are generated for representing the outcome of these tests. Each interior node in our ContextPCA model denotes a context-aware test case on a particular condition, and each leaf node represents the corresponding outcome of that test which is represented by a category of apps or class label (e.g., using Facebook app). Each branch in the tree are connected with arcs, from root node to leaf node. These leaf nodes are also known as terminal nodes as the tree stops to grow after finding a leaf node. Once the tree has been built, it is used to predict each test instance. For this, it generates a number of IF-THEN logical rules and classify them. Overall, there are two basic steps for the development of our decision tree based ContextPCA model; (a) building the decision tree from a apps usage training dataset considering multi-dimensional contexts, and (b) applying the generated decision tree to measure the prediction accuracy of the context-aware test cases.
6. Conclusions and Future Work
In this paper, we have presented an effective principal component analysis based context-aware smartphone apps prediction model, ContextPCA using decision tree machine learning technique. In our ContextPCA model, we have adopted PCA to reduce the context dimensions of the original data set by producing a new set of uncorrelated components, to make the model effective and efficient. In order to build this data-driven ContextPCA model, we have taken into account a number of contextual features that might have an influence on users’ apps usage in their various day-to-day real world situations, and collected corresponding apps usage datasets from smartphone users. No assumption or prior knowledge is needed in employing our ContextPCA model as we take into account unsupervised learning technique PCA for feature extraction and supervised decision tree for building the model based on the principal components generated. Experimental results on the datasets indicate that our ContextPCA model outperforms while predicting individuals’ smartphone apps. We believe that this ContextPCA model would be helpful to application developers to build corresponding real-life applications for the end users, particularly, where higher dimensions of contexts involved.
To assess the effectiveness of our ContextPCA model by collecting more dimensions of contextual data in the domain of smart cities and Internet-of-Things, and to measure the effectiveness in application level could be a future work.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}