1. Introduction
Dynamic multi-objective optimization problems (DMOOPs) belong to a kind of time-varying multi-objective optimization problems that is frequently encountered in the disciplines of science and engineering. These problems not only display the conflict in optimization targets and high dimension in solution space, but also have the time-varying characteristics in optimization objective, constraints, and decision space [
1,
2,
3,
4,
5,
6,
7]. As a result, the high conditionality of traditional algorithms makes it difficult to meet requirements about large-scale, high timeliness and complex non-deterministic polynomial (NP) hard problems. Compared with traditional algorithms, evolution methods have low requirements in problem model, high efficiency, as well as embarrassingly parallel self-organizing and self-adaption, so they have been widely used in the modern industry and scientific research field [
8,
9,
10].
The easiest way is to keep the diversity of the population in evolution methods used to solve DMOOPs. For example, DNSGA-II (dynamic multi-objective optimization and decision-making using the modified NSGA-II) proposed by Deb [
11] uses partial random initialization or random variation in order to enhance the flexibility of the population in the changed environment. Moreover, three immigration schemes proposed by Azevedo are used to initialize the population in the changed environment [
12], as well as the immune clonal algorithm proposed by Shang Rong-hua [
13]. Because of the unknown variation trend for the dynamic environment, those methods can be formulated into an attempted exploration method, which could ensure the superiority individual could be reserved in the changed environment. The upside for these methods is that they can adapt to a variety of changing environments, while their downside is that advantages of search before environmental change would be difficult to keep after change. Thus, the characteristics of this kind of methods are their powerful environmental adaptability and poor prediction accuracy.
Compared with the early methods, by maintaining the diversity of the population, historical information from multiple environmental changes is used to predict the position of the population in the next environmental change. That is, it is a type of statistical method to study the non-dominate solution set. There are two solutions for this, namely the memory strategy and the prediction strategy.
The memory strategy predicts the position of the population in the next environmental change by rules, which stores a lot of information about non-dominate solution set. The memory strategy is suited to solve the dynamic problem of “short periodicity”. Here, “Periodicity” could be described by the historical information, and “short” indicates less storage [
14,
15,
16].
However, this has several drawbacks, namely large memory consumption and incorrect predictions to solve time-varying nonlinear problems or more frequent environmental changes.
The prediction strategy uses historical information by statistical analysis and predicts the possible direction of population migration using prediction theory (for example, linear regression, autoregressive model, etc.), relative to the memory strategy. The FPS (feed-forward prediction strategy) proposed by Hatzakis [
17] is used to predict the migration locations of the non-dominant solution set, which is based on an autoregressive model. Because of the incomplete statistical analysis about historical information, the FPS is weak and ineffective. The PPS (population prediction strategy) proposed by Zhou [
18] uses an autoregressive model to predict the central migration locations of the population, and shape estimation to migrate the whole population. Compared with the FPS, the PPS has mainly two characteristics: (1) further treatment of historical information, which is used to predict the central locations of the population; and (2) shape estimation, which is better than estimation one by one. All of these methods based on autoregressive model have a fundamental disadvantage, namely, a large amount of statistical information is needed to construct the model. Moreover, if the prediction error is increasing repeatedly, the prediction error will be amplified. As a result, it is difficult to adjust when the change rule of the environment is changed.
In short, the autoregressive model is widely used to solve regular change problems, but has the problems of slow response speed and large amounts of statistical data. To compensate, the diversity-keeping strategy is widely used. The DSS (directed search strategy) proposed by Wu [
19] is used to solve the dynamic problem, which uses both central population prediction and cross search. Moreover, the method of population center prediction is a linear prediction. Compared with MLR (multiple linear regression), it needs less historical information and has a better adaptive capacity to the environment. For DMOOPS, a method proposed by Rong [
20] is used to predict the changes, which uses a linear model based on segmentation of the optimal front. Furthermore, the linear model used by Li [
21] is based on the prediction of the autoregressive model. It predicts the key points of the optimal front, such as the boundary point, inflection point, etc. Also, the linear model is used by Ruan [
22] to predict the position of the optimal front. In maintaining population diversity, the changes in population are predicted based on the extreme point of the previous generation [
20]. However, it is worth noting that the prediction error should always exist in the linear model when solving dynamic problems (progressive increase, progressive decrease, or more complex changes). Therefore, all the literature above employs the diversity keeping scheme to redress prediction errors.
According to the problem of remedying the shortage of the linear model, the segmentation cloud predict strategy (SCPS) is proposed in this paper to improve the precision of prediction. First, the searched optimal front would be segmented to divide the population. Second, a new linear prediction analysis is applied to each part of the population, which would draw on the thoughts of the cloud model. According to the notion of uncertain time in the cloud model, entropy (or super entropy) would be used to redress the prediction errors. Moreover, for some abrupt nonlinear changes in dynamic problems, the extra angle search strategy is used to ensure the diversity of the population during the prediction process.
The rest of this paper is organized as follows. The problem of dynamic multi-objective is described in
Section 2. The segmentation cloud prediction strategy is proposed in
Section 3. Benchmark problems are applied in
Section 4 to show the performance of the proposed method, together with related experimental analysis. Conclusions are provided in the last section.
2. Description of Dynamic Multi-Objective Problem
Considering the symmetry between minimum and maximum under symmetric environments, the optimization problem can be normalized to a unit form. Generally, the DMOP could be described as follows,
where the decision variables are
,
is the
n dimension decision space, and the time variable is
t.
is the equality constraint, while
is the inequality constraint. The objective function vector is
, and
is the
m dimension decision space. The evaluation function
would define the mapping from decision space to object space [
23].
Definition 1. (Pareto domination). For some time t, if individual p, it can as . If and only if : , :.
Definition 2. (Pareto optimal solution set, PS)
. Let , which is the decision variable. PS could be defined as follows, Definition 3. (Pareto optimal front, PF)
. Let , which is the decision variable. PF could be defined as follows, 3. Segmentation Cloud Prediction Strategy
First, the optimal front is segmented into multiple fragments, and the segmentation result can be used to divide the population in the decision space. Second, certain individuals are chosen to search the change directions of the optimal front by extra angle search strategy. At last, some add search is conducted to search for the possible offset position of the optimal front by extra angle search.
3.1. Population Segmentation
For the DMOOPs, the optimal front might be deflected or deformed. In order to predict the variation of PF more accurately, the PF is segmented into multiple fragments, and each fragment is used to make predictions. Compared with the linear prediction for the population center, this method would have a more accurate predictive ability of PF deformation and nonlinear migration.
First, for PF, a boundary point is chosen as the first key point, and the distance between this point and the others is calculated. Then, the point with the maximum distance is the second key point. In the same manner of choosing second key point, the third key point would be the point with maximum sum of distance between the two key points, and so on for m+1 key points of the m objective functions (). As a result, each individual would choose the key point with minimum distance to constitute m+1 fragments. Thus, populations would be segmented according to m+1 key points.
This method has simple computational properties and low complexity. The time complexity for choosing each key point is O(N), where N is the population size. The computation complexity of this method is O(N(m+2)/2)=O(Nm), while the computation complexity of the clustering method is O(N2). Therefore, the proposed method of segmentation is simpler for population segmentation and has lower computation complexity.
3.2. Directional Cloud Prediction Strategy
Suppose the population size is
N, and the
ith population
Popi contains
Ki individuals. The center of sub-population
Popi could be described as follows,
where
are all the individuals of the population, the
kth individual is
,
is the center position of population at time t, and
is the cardinality of set.
The predicted migration vector of the population
di(
t) and the predicted error of two migrations
at time
t+1 could be calculated as follows, based on the predictions of center positions of populations at time t and time
t-1.
The prediction of the migration position of the population is based on the normal cloud model. Suppose the moving direction of the population is expectation, the Euclidean distance of motion vector
is entropy, and the deviation
between two moving direction of the population is super entropy. The normal cloud generator could be built by expectation, entropy, and super entropy. First, we generate normal random vectors
whose expectation is
and standard deviation is
, where
. Then, we generate normal random vectors
, whose expectation is
and standard deviation is
. Therefore, the optimal solution position of predicted sub-population could be shown as follows,
where the individual position before change is x, the direction of prediction is
v1, and the individual position of prediction after change is
y.
Figure 1 shows the schematic diagram of directional cloud search, where the direction of directional prediction is
, and the possible direction of cloud prediction is
. That is, the main search direction of directional cloud prediction is based on
, and it could search at a certain probability to predict the position for the last offset direction
.
3.3. Extra Angle Search
Directional cloud prediction contains the error compensation of linear prediction. However, this is only effective for gradual and regular changes. If the dynamic problem shows inverted reciprocating or non-gradual changes, the direction of directional cloud prediction would be opposite or vertical to the change direction of the dynamic problem. To deal with this problem, the extra angle search strategy would be purposed. That is, based on some random chosen individuals, it would search all possible directions in a stated angle.
Figure 2 shows the schematic diagram of the extra angle search strategy.
First, the random vectors are constructed, perpendicular to
. Based on the random vector
within the scope of [−1, 1], the
jth dimension of
r would be assigned as Equation (7),
The direction vector of extra angle search would be calculated as follows,
where
is deflection angel, which means the possible range of search and can be calculated as
When the direction vector of extra angle search is determined, we use the normal cloud model the to search the angular deviation of in all individuals. The normal random vector
is generated, whose expectation is
and standard deviation is
and
En* = (
En1*, …,
Enn*). Then, the normal random vector
can be generated, whose expectation is
and standard deviation is
. The position of prediction from the angular deviation search can be calculated as follow,
where the position of individuals before change is
x, the direction of prediction is
v2, and the position of prediction after change is
y*.
3.4. Environmental Detection
The sensitivity of the environment is very important for the algorithm. The computational efficiency of DMOP will decrease if the sensitivity is excessive or insufficient. Moreover, each DMOP might not change at the same time, and a different objective function would have different amplitude of variation. Therefore, the change in values of each objective function would be overall considered and normalized. The environmental sensitivity can be calculated as follows
where
H is the number of individuals is randomly selected for the population. Random selection mainly reduces the computing cost for environment detection. The vector of the objective function for individual
at time
t is
. Generally, the proportion of the population selected for environment detection is 5%.
3.5. SCPS Framework
The SCPS will iterate over the basic algorithm framework of the dynamic multi-objective evolutionary algorithm (MOEA). The basic algorithm framework of the dynamic MOEA (DMOEA) mainly includes two parts: dynamic prediction and static MOEA search. This paper mainly focused on the prediction performance of DMOEA, so the classical NSGA--II [
24] can be selected as static MOEA search. The SCPS is described in detail as below.
Input: When enough historical information cannot be collected, the proportion of the population in random initialization is , the proportion of directional prediction population is L1, the population size is N, and the final time of environmental change is Tmax, t:= 0, d(t − 1):= 0.
Output: PS.
Step 1: Randomly initialize the population.
Step 2: According to Equation (11), detect if the environment changes or not. If change, turn to Step 3; otherwise, turn to Step 8.
Step 3: If the value of d(t − 1) is 0, turn to Step 4; otherwise turn to Step 5.
Step 4: Randomly select N individuals to evolve, let d(t − 1) = d(t).
Step 5: According to
Section 1, segment the population into
m + 1 parts. Calculate the center of the population by Equation (4), and calculate the moving direction of population at time
t. Then select
L1 ×
N individuals with the binary tournament selection model and predict the position with the cloud model.
Step 6: Select N(1 − L1) individuals with the binary tournament selection model and calculate the search vector of extra angle search for these individuals using Equation (7) to Equation (9).
Step 7: Boundary detect for new individuals.
Step 8: Calculate the non-dominated sort and crowding distance. Hold the first n individuals.
Step 9: Termination conditional judgment. If meet, turn to Step 10. Otherwise turn to Step 2.
Step 10: End, output the population PS.
One-step prediction (Step 5) and search of deflection angle (Step 6) would randomly select
K1 N and
N (1 −
K1) individuals to predict, respectively. As the predicted individuals might be beyond the decision space, the Step 7 is to boundary detect new individuals, and revise the ones beyond.
where the
ith dimension of individual
x before prediction is
, the
ith dimension predicted position of individual is
,
, and
and
are the upper and lower bound of the
ith dimension of the decision variable, respectively.
4. Experimental Analysis
4.1. Benchmark Problems
In [
25], a new dynamic benchmark problem (generator) was constructed. Many dynamic benchmark problems grown from this generator are related to various practical engineering problems such as the greenhouse system, hydraulic and hydroelectric engineering, and line scheduling.
4.2. Parameter Setting
In order to test the searching performance of the proposed algorithm in dynamic problems more effectively, the environmental change degree and frequentness of 3 groups were set as benchmark problems, and
respectively were (5,10), (10,10), (10,20). Multi-objective evolutionary algorithms based on decomposition (MOEA/D) [
26], PPS [
18], multi-direction prediction (MDP) [
20], and SCPS were chosen as the comparing algorithms in the test. The population sizes of all the comparing algorithms were 200 (
N = 200), and the evolution termination time
Tmax = 10.
(1) MOEA/D: T = 20.
(2) PPS: retain number of population center M = 23, and the model is p linear regression model, p = 3.
(3) SCPS: = 0.2, and the chosen individual number of prediction models K1 = 0.5N.
4.3. Metrics
There are numerous metrics for dynamic MOEA. The inverted generational distance (IGD) is chosen as the evaluative criteria of each iteration, and the modified IGD (MIGD) is used to evaluate each algorithm running several times in each benchmark problem [
18].
where the equally distributed ideal PF solution set at time
t is
, and the result of the algorithm is
. The distance between individual
x and solution set
P(
t) is
, and the cardinality of set
is
. The mean IGD of the algorithm, which would run in the benchmark problem for a period of time is evaluated by MIGD. MIGD is defined as follows,
where a group of discrete points in time is
T, and the potential of
T is
.
4.4. Test and Analysis
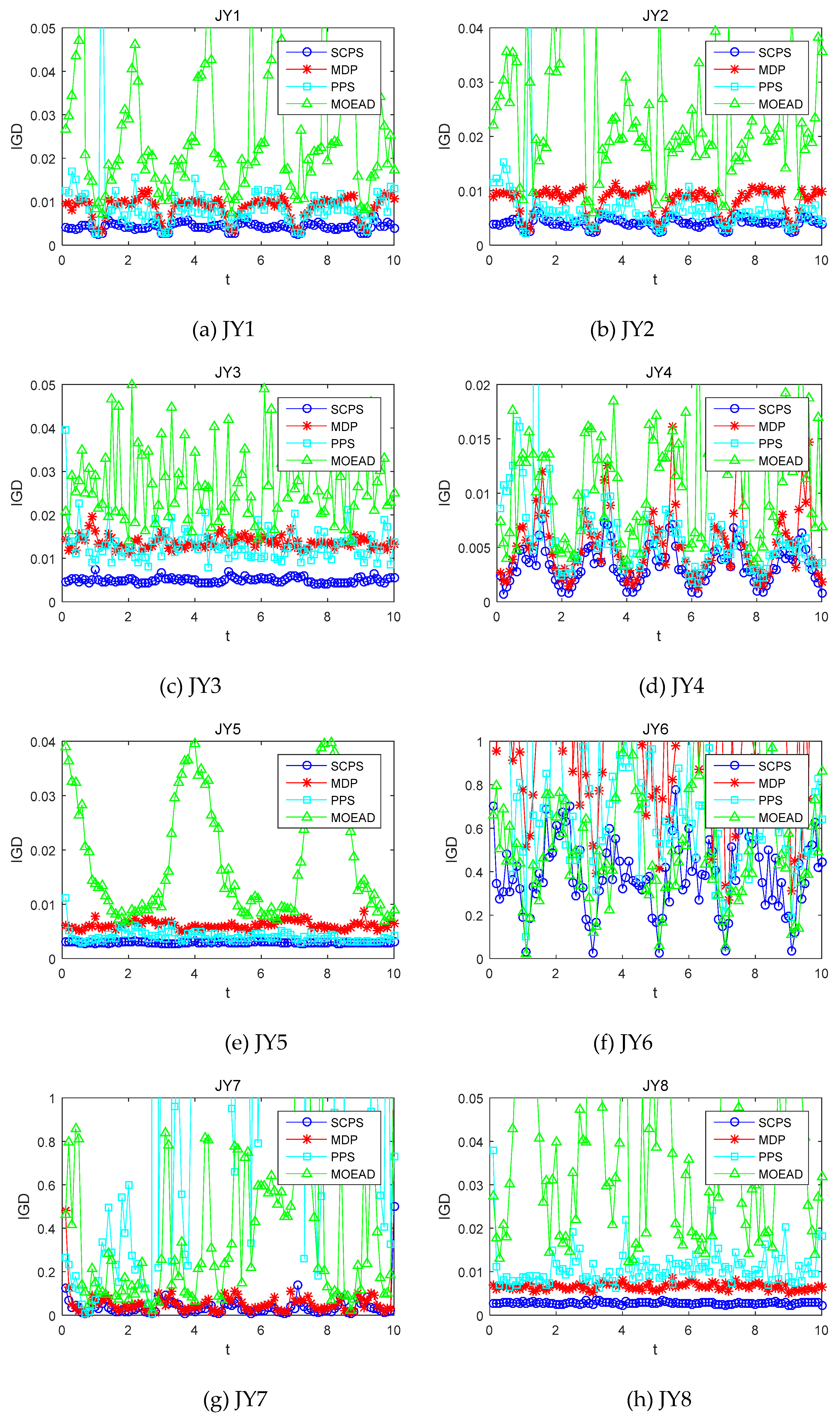
Table 1 shows the mean MIGD results of SCPS and other compared methods running 20 times in eight benchmark problems. The smaller the value of MIGD, the higher the average prediction accuracy. The optimal values are highlighted in bold.
SCPS has strong searching ability for the eight dynamic test problems. Only on the test problem JY4 (), the PPS method is slightly better than the SCPS. For all the test problems, four algorithms have strong searching ability on JY1-JY5 as well as JY8. Their MIGDs reached the 10−2 magnitude. That is, all these four algorithms have good ability to track the dynamic front.
JY6 is a Type III dynamic problem as shown in [
25], where the multimodal PS and PD change over time, and the distribution of the optimal solution would be also in a constant process of change. Although the SCPS would be better than the other three algorithms on this problem, its MIGD is unsatisfactory.
JY7 is also a multimodal problem, and its PF shape is in a constant process of change. As the number of local optimum is fixed, JY7 is relatively simpler than JY6. Thus, the four algorithms running in JY7 are better than that in JY6. According to the standard deviation of MIGD, SCPS has better stability than the other 3 algorithms and a higher solution.
In order to analyze the dynamic searching ability of the four algorithms, eight group benchmark problems were chosen, and under the condition that
, the time-varying characteristic of IGD of algorithms was analyzed.
Figure 3 shows the timely varying curves of IGD of the four algorithms running in the benchmark problem. Each time the environment changes, the smaller the IGD value is, and the more accurate the prediction of the algorithm.
It is indicted that the MOEA/D has a good searching performance in the static problem, but it could not dynamically predict. Thus, MOEA/D has an inadequate capability to solve the dynamic problem in bounded time. For the problems JY2 and JY5, PPS is better than MDP. However, for the problems JY7 and JY8, MDP is better than PPS. Especially, for JY7, large errors of the prediction might exist and keep increasing in PPS. In all eight benchmark problems, SCPS is better than the other three algorithms.
In order to further analyze the experimental results, the distribution of predicted results at five moments was compared for JY4, JY5, JY7, and JY8.
Figure 4 shows the distribution of predicted results at five moments for the four algorithms running in four benchmark problems.
The discrete area of JY4 is time-varying. And the concavity of PF in JY5 changes over time. Although the PF changes of these two benchmark problems are different, they are both the unimodal problem. Thus, their results have good distribution and convergence. The PF shape of JY7 and JY8 would be changed all the time, so optimization is rather difficult. The points shown in
Figure 4 are the non-dominant solution set of the population, and the number of these points reflects the performance of the algorithm. MDP and PPS have good distribution and convergence at the first moment, but the distribution of non-dominant solution set for these two algorithms is not satisfactory at the next four moments. That is, some points are far from the true PF. In comparison to the other three algorithms, SCPS performs particularly well in distribution and convergence. Moreover, in JY8, all four algorithms have good distribution, but SCPS performs better than the others in convergence.
According to the scatter distribution, SCPS has better searching performance. Its population segment provides an accurate shape change prediction. The cloud prediction strategy is the basic prediction strategy, and extra angle search is the main prediction angle error compensation.
Depending on the results of the IGD mean, IGD change with iterations, and scatter prediction results, the proposed algorithm is stable and has good predictive ability. Its prediction is more reasonable and closer to the population in the last moment.







{kind=link}
{kind=link}
{kind=link}
{kind=link}