1. Introduction
Sharing video in multimedia applications has become an indispensable part of people’s lives, especially in the medical industry [
1] and military applications, due to the continuous development of multimedia applications and network technologies. With the continuous maturity and in-depth application of office automation in the medical industry, as the core information assets of medical care, these data assets are intentionally or unintentionally leaked, which will cause economic and reputation loss to the continuous operation of the enterprise, and even face more strict regulatory penalties. Therefore, some researchers have invested a lot of effort to further improve the video encryption scheme to ensure the security of private video data.
We all know that video encryption is generally divided into full encryption and selective encryption [
2,
3], both of which have advantages and disadvantages. Full encryption is usually suitable for small amounts of encrypted data and it requires high security. However, selective encryption is suitable for large amounts of encrypted data and strong real-time performance. Video encryption is a very time-consuming process due to the large amount of video data. Many video encryption algorithms are proposed according to the different semantic elements of encryption. Some schemes are proposed in those articles [
4,
5] to encrypt the video by scrambling the intra prediction mode (IPM) of the intra-coded macro block. Exclusive OR (XOR) operation is usually used in intra prediction mode (IPM) to protect data privacy. In reference [
6], Khlif et al. proposed encrypting the symbol of the current motion vector (MV) of each macroblocks (MB). Scheme [
7] encrypts not only the intra prediction mode but also the motion vector difference (MVD). Lian et al. [
8] proposed encrypting intra prediction modes, motion vector differences, and residual coefficients. Shi et al. proposed other encryption parameters in scheme [
9], such as the encryption sequence parameter set and image parameter set. Jiang et al. [
10] analyzed the perception performance, plaintext scrambling space, and key security of existing encryption algorithms. Next, while considering the key distribution and synchronization, the researchers propose a new encryption algorithm. This encryption algorithm chooses all IPM as plaintext, uses key-controlled cyclic sequence to encrypt intra prediction mode (IPM) of Intra 4 × 4 twice, and chooses chaotic random sequence as key, which improves the security of the algorithm and reduces the calculation cost. Sbiaa et al. proposed an encryption system in reference [
11]. The system encrypts the alternating current (AC) and direct current (DC) coefficients generated after the quantization step, and then encodes them to encrypt and compress the video. Khlif et al. proposed a chaos-based encryption and compression scheme in reference [
12]. The scheme uses chaotic functions with two different keys to generate two renewable key streams. The first is used for encryption and the other is used to determine whether to encrypt. The scheme inserts the encryption and decryption processes into the compression and decompression processes, respectively. The semantic elements that are encrypted in the encryption process are: non-zero quantized coefficients of intra (I) and inter (P) predicted frames, symbols of motion vector differences of inter prediction frames, and intra prediction modes of intra prediction blocks. Asghar et al. [
13] proposed a new cryptanalysis method. The experiments show that video blurring can be achieved by only encrypting a few motion vector difference symbols (MVDs) in each chip. The Advanced Encryption Standard (AES) algorithm [
14] based on cipher feedback mode (CFB) mode is a symmetric encryption method with strong security. This algorithm can effectively protect data privacy. Radanliev et al. [
15,
16,
17] proposed that future developments be applied to IoT, and the main goal is to explore the development of IoT. These studies are very important for video encryption and privacy protection.
Traditional encryption algorithms are not suitable for image encryption [
18]. Chaotic systems are known for their sensitivity to initial conditions and parameters, pseudo-randomness, ergodicity, and reproducibility [
19]. It is very suitable for video image encryption. Researchers have proposed many chaotic encryption schemes based on this consideration. Cheng et al. [
20] proposed a privacy-preserving image retrieval scheme based secure kNN, DNA coding and deep hashing. In addition, the researcher proposed histopathological image retrieval that was based on asymmetric residual hash and DNA coding [
21]. In the current research, researchers have proposed some classic selective video encryption methods. Hamidouche et al. [
22] applied the hyperchaotic system to selective video encryption. Altaf et al. [
23] proposed efficient computation of selective video encryption that was based on chaotic block ciphers. Therefore, hyperchaotic encryption is also the main technology of video image encryption, and this technology has become a research focus of selective video encryption in recent years.
In this paper, a novel selective video encryption scheme is proposed, which extracts IPM, MVDs, residual coefficient (RC), and Delta quantization parameters (QP) parameters in each slice by using the slice characteristics of H.264 video coding. Then, the dynamic key generated by PRNG and the CFB of Advanced Encryption Algorithms (AES) are used to encrypt the parameters extracted from each chip. This paper proposes a new four-dimensional (4-D) hyperchaotic algorithm to protect data privacy in order to further improve the security of video encryption. Finally, the encrypted data is put back into the compressed stream. The scheme has the characteristics of real-time key updating and independent decryption between the slices, which greatly improves the security of encrypted video. The experiments confirm the effectiveness of the proposed method.
The organization of the article: In this section, we briefly introduce some application backgrounds of video encryption and some common methods of video encryption. In the next section, we will focus on H.264/AVC video encryption systems. In the third section, we will introduce our proposed selective video encryption scheme. In the fourth section, the experimental results and experimental analysis of our proposed selective encryption scheme are given. Finally, we completed the study by giving conclusions.
This paper is organized, as follows: In
Section 1, we briefly introduce some application backgrounds of video encryption and some common methods of video encryption. In
Section 2, we will focus on H.264/AVC video encryption system. In
Section 3, we will introduce our selective video encryption scheme. We present the experimental results and analyses in
Section 4. In
Section 5, we elaborate the relevant conclusions of the paper.
3. Video Selective Encryption Scheme
We know that researchers encrypt semantic elements through different combinations to make the video content as obscure as possible, according to the previous introduction. Video encryption usually needs to consider compatibility, security, and timeliness, so it is important to propose a selective encryption algorithm to protect video privacy.
3.1. Selection of Important Syntax Elements
Selective encryption is a technology that saves time by encrypting a small amount of bitstream data, but it still has sufficient security [
26]. Analyzing the research work of the predecessors, we found that important semantic elements in the video stream were encrypted in most video encryption schemes. For example, IPM, MVD, residual coefficient, and so on.
In reference [
13], Asghar et al. proposed a new cryptanalysis method. Asghar et al. believe that the probability of each syntax element obeys Poisson distribution in the video test sequence. Based on two assumptions: (1) the values of the symbols in the file are evenly distributed; and, (2) For syntax elements with a range of continuous values, it is very difficult to correctly guess the cryptographic elements on a sufficient number of elements. Asghar et al. analyzed that there are 119,904 MVD symbols in a 21.7 M video file. It is necessary to correctly guess that the MVD symbol has 2119904 possibilities, so the probability that the MVD symbol can be fully guessed is 1/2119904. Suppose that the attacker needs to correctly guess 80% of the MVD symbols to make the video visible, and guess that the combination of 80% MVD symbols has
. It is very difficult to correctly guess 80% of the MVD symbols. Moreover, the analysis given [
8] is reasonable in encrypting spatial information and motion information during H.264/AVC encoding. However, the scheme of encrypting the syntax elements only encrypts the equal-length codes to maintain the same bit rate as the original code stream [
14]. Therefore, a selective video encryption scheme with high security, high efficiency, and format compatibility is proposed in this paper. When compared with reference [
8], our proposed encryption scheme directly encrypts the semantic elements in the H.264 bitstream, thereby directly changing the code stream. From previous research work, we know that a video is encoded into multiple frames, and a frame consists of multiple fragments, and these fragments are independent of each other. According to this idea, we use the independence between video slices in the proposed encryption scheme. The AES with CFB mode is used to encrypt the IPM, MVDs, residual coefficient, and Delta QP [
27] semantic elements in video. More importantly, the key between the slices is updated in due course. This keeps the encrypted video format compatible and real-time secure. The following video semantic elements need to be encrypted.
Intra Prediction Mode (IPM): IPM supports four prediction modes of Intra_4 × 4, Intra_16 × 16, Intra chroma and I_PCM 24. The IPM in the Intra_4 × 4 and Intra_16 × 16 blocks is selected for encryption in our encryption scheme.
Motion Vector Difference symbol (MVDs): We need to encrypt motion vectors in order to destroy the movement information. In H.264/AVC, the motion vector mv is further predicted to obtain mv’, and the motion vector difference mv
d = mv − mv’. In the H.264/AVC baseline profile, the MVD is encoded while using Exp-Golomb entropy coding. The value of MVD and the corresponding Exp-Golomb codeword is indicated in the paper [
28], and the last bit of the Exp-Golomb codeword is given to affect the MVD symbol. Therefore, we only need to encrypt the last bit of the Exp-Golomb codeword in the motion vector difference.
Residual coefficient: We need to encrypt some other sensitive data, that is, residual data, in order to further promote the security of the encryption video. In the H.264/AVC baseline profile, the format of quantization coefficient [
29] used to encode residual blocks is as follows: {coeff_token, sign_of_trailing ones, level, total_zeros, run_before}. The encryption of the residual coefficients is done by modifying the trailing ones sign and the level codeword [
28,
30]. The encryption of the residual coefficients is implemented in our scheme by replacing the trailing ones sign, level, and totalzeros codewords.
Delta QP: Differences in quantization parameters (QP) can affect video quality. We need to encrypt the Delta QP parameters in order to make the texture information more distorted.
3.2. Selective Encryption Process
We select the IPM, MVDs, and the residual coefficients affecting the texture information, Delta QP [
27] to encrypt the video, by analyzing the structure of H.264/AVC video code stream.
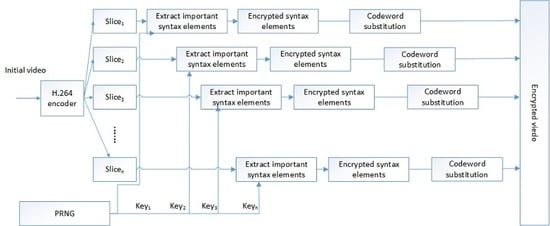
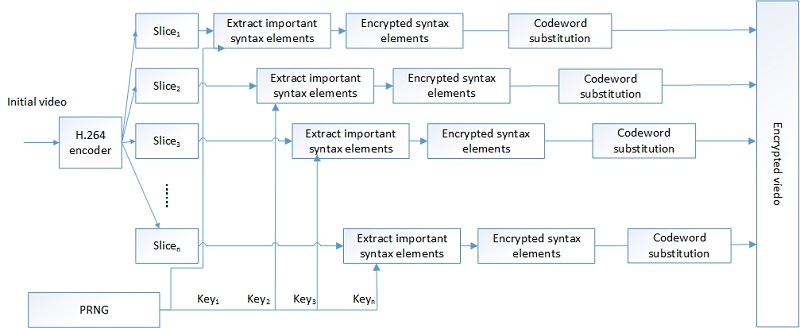
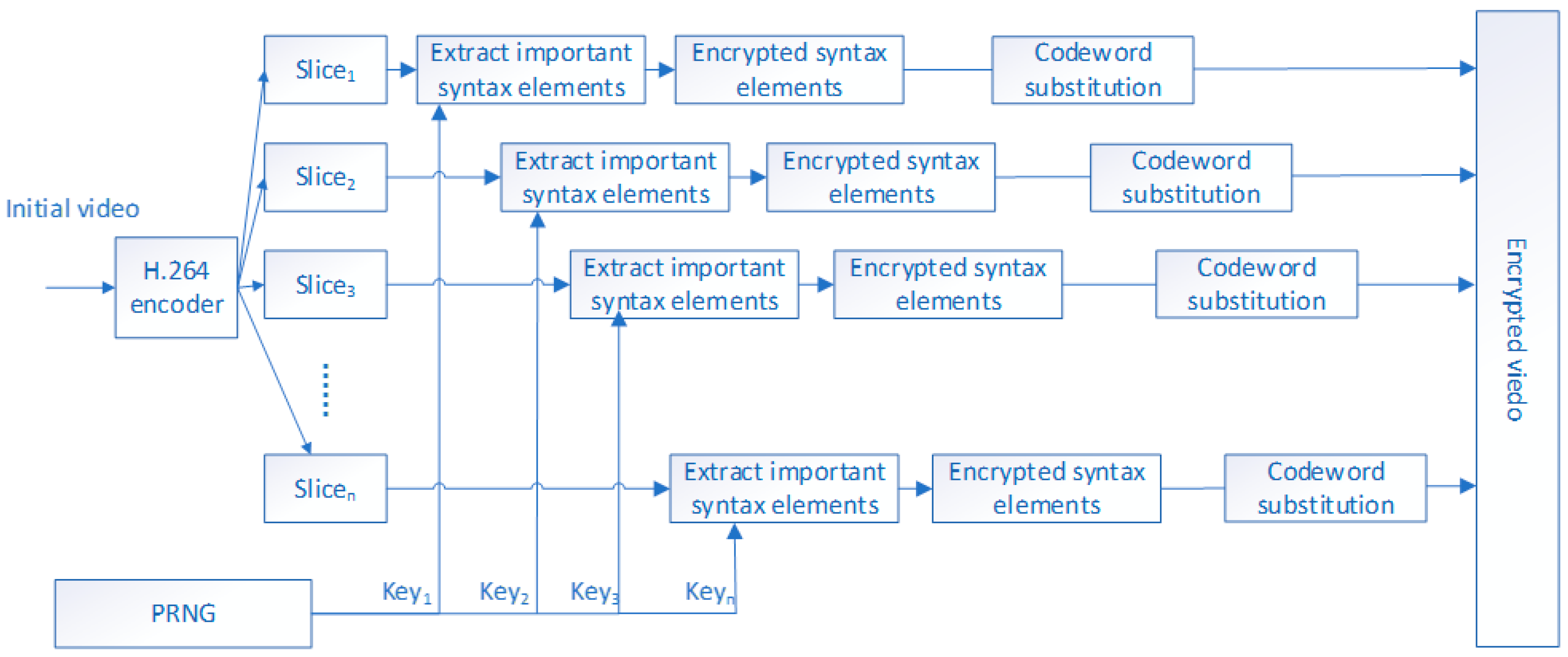
Figure 4 shows the flow chart of selective video encryption.
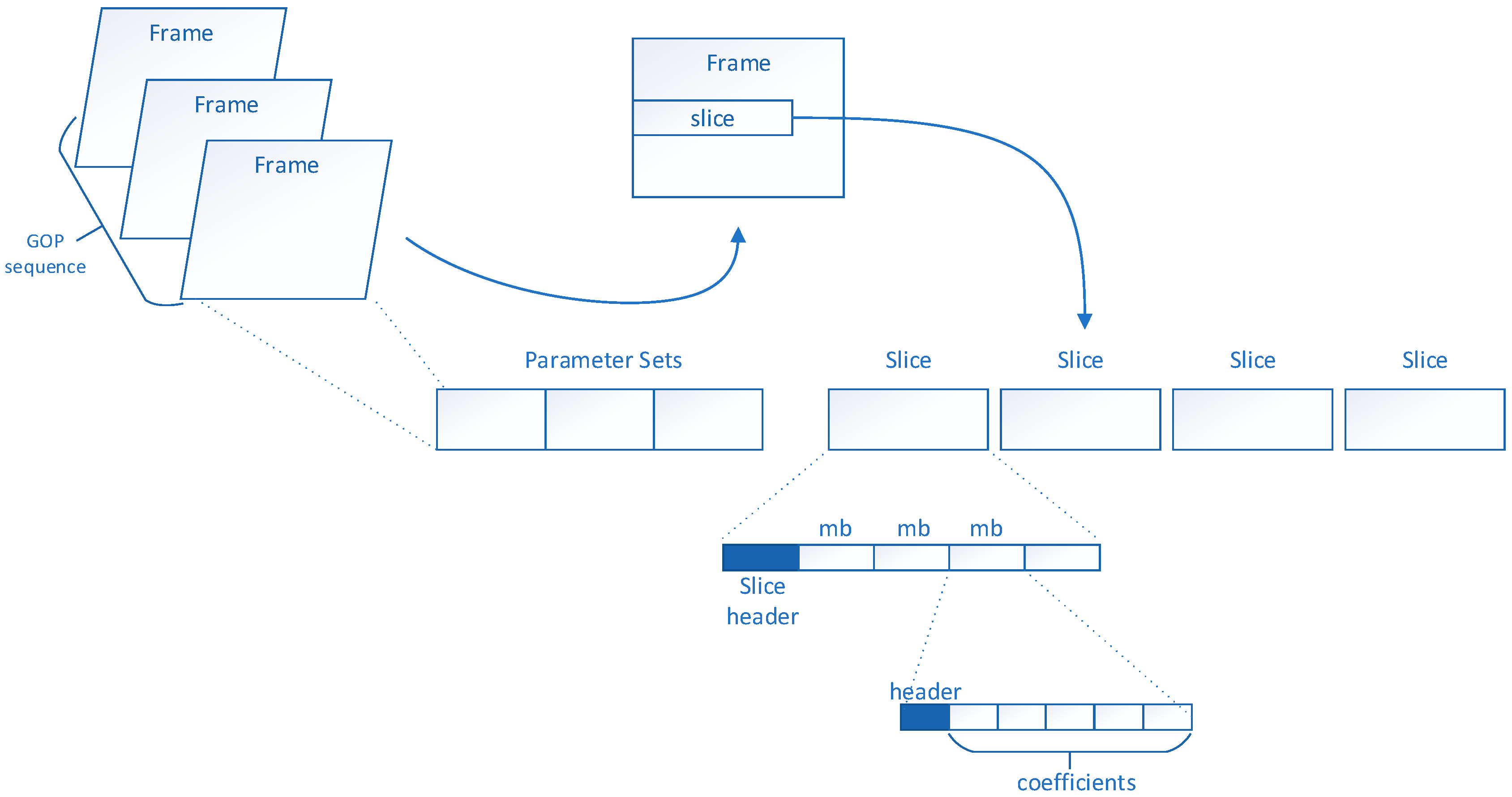
The H.264 encoder encodes a video into multiple slices, and the slices are independent of each other. We use this feature of video coding to propose an efficient and secure video encryption scheme. We regard
as the mark of the CFB mode while using key k to encrypt the n-bit
.
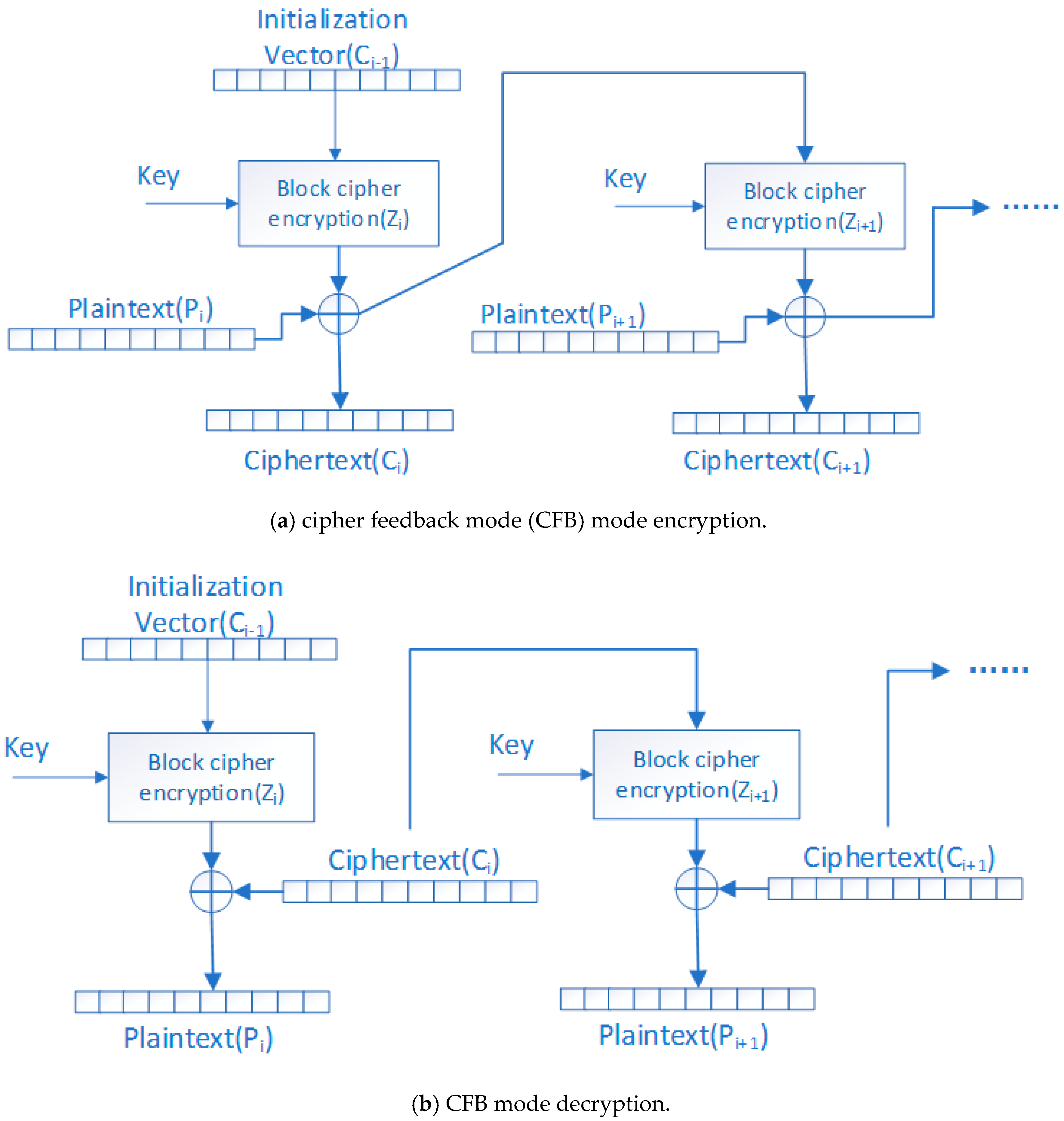
Figure 3 shows the implementation scheme. We chose to use CFB mode to maintain the compression ratio. As can be seen from
Figure 3, plaintext block
is the same size as the ciphertext block
. Furthermore, ciphertext from the previous block is directly used to encrypt the current block. The algorithm proposed in this paper has three stages: constructing the plaintext block
, encrypting the plaintext block
, and replacing the encrypted information with the original codeword.
Plaintext construction: Since the slices are independent from each other, we encrypt the important semantic elements of each slice in units of slices while using the PRNG generation key in
Section 2.2. In our scheme, we can copy the important semantic elements of each slice in the H.264 code stream directly to the vector
to create the plaintext, and until the vector
is completely filled or reaches the edge of the slice. We think that
L is the size of the vector
, and
is the length at which the vector
is filled. Where
L = 128. If
, we fill
with
, where
{
}. From the perspective of encryption algorithms, padding is to improve the security of the algorithm.
Encrypting plaintext while using CFB mode of AES.
Figure 3a shows the encryption process for CFB mode.
is created by the previous ciphertext block
. According to Formula (1), we perform xor operation between
Z and plaintext block P to achieve the encryption of the current plaintext block. In the key generation phase, we used the PRNG that was proposed by Xu et al. [
25] in
Section 2.2 to generate the key. For security reasons, we will consider the sequence after the 100th 32-bit as the key stream.
Replace the original bit: this is the last stage of encryption. In this phase, we replace the vector in the original stream with the encrypted ciphertext vector . The H.264 codestream is sequentially accessed in the plaintext construction phase, given the length of each important semantic element (,, …,). Subsequently, we replace the corresponding part of the plaintext in the H.264 stream with the ciphertext . At this point, our proposed selective encryption scheme ends.
3.3. Decryption Process
Figure 3b shows the decryption process for the CFB mode. The ciphertext
of the previous block is used as an input of the AES encryption algorithm to generate
(here, the same encryption function
and encryption key k as the encryption phase are used.), and the current ciphertext block
and
are XORed to generate a plaintext block
. Repeat the above operation until the plaintext vector
is generated. Afterwards, the plaintext vector
is divided into segments of length
,
,……,
to replace the corresponding stream in ciphertext to generate the original stream.
3.4. Introduce 4-D Hyperchaotic Selective Video Encryption Process
Figure 5 shows the encryption and decryption process of the proposed 4-D hyperchaotic system.
Figure 4 is selective video encryption, which mainly encrypts important elements in the video slice. At the same time, there is independence between video slices. It can be seen from
Figure 5 that we use the 4-D hyperchaotic system to encrypt selective video encryption results. Therefore, the selective video encryption result is the input of the 4-D hyperchaotic system for
Figure 5. At this time, the ciphertext image in
Figure 5 is a result that is based on video encoding and 4-D hyperchaotic hybrid encryption.
4. Experimental Results and Analysis
In this section, we will present the results of selective video encryption. We used the JM8.6 reference software in the video coding phase. In the experiment, we analyzed the proposed selective encryption scheme using seven reference sequences with a frame rate of 30 frames/s and a format of QCIF (176 × 144). These seven reference video sequences are combined by different motions, colors, contrasts, and objects. Each of the seven reference sequences has 300 frames for experimental analysis, and the structure of the GOP is “IPPP”.
4.1. Security Analysis of Selective Video Encryption Scheme
Perceptual security means that the video sequence after encryption cannot be correctly identified, depending on the attributes of the encryption. In this section, we will discuss the perceived security of our proposed encrypted video images from two aspects: subjective video quality and objective video quality.
4.1.1. Subjective Video Quality Analysis
In our proposed scheme, we encrypt the IPM, RC, Delta QP, and MVDs semantic elements in the video sequence by means of fragmentation, which guarantees the visual perception security of video encryption. This paper proposes a new five-dimensional (5-D) hyperchaotic algorithm to protect data privacy in order to further improve the security of video encryption. Only four benchmark sequence renderings are shown here due to space limitations (
Figure 6). This includes the original video image (OVI) (OVI 1, OVI 2, OVI 3, OVI 4), Selective video encryption output (SVEO) (SVEO 1, SVEO 2, SVEO 3, SVEO 4), Mixed encrypted output (MEO) (MEO 1, MEO 2, MEO 3, MEO 4), and the decrypted video image (DVI ) (DVI 1, DVI 2, DVI 3, DVI 4). Where, the first column in
Figure 6 is the original video image. The second column in
Figure 6 is selective video encryption output. The third column in
Figure 6 is the mixed encrypted output. The last column in
Figure 6 is the decrypted video image. The mixed encryption output is the mixed encryption result. The specific step is to perform selective encryption first and then perform 5-D hyperchaotic encryption.
In
Figure 6, if the user needs to ensure sufficient real-time and large amount of data, we recommend that the user choose a selective video encryption algorithm. This method can encrypt video data in real time to a certain extent. We recommend that users choose a hybrid encryption method, which mainly focuses on video encryption security, if the user needs sufficient security and the amount of data is small.
Figure 6 shows the subjective evaluation of the algorithm. In addition, the encrypted video sequence maintains the same size as the original video sequence (as shown in
Table 1), and the bitstream format compatibility is well accomplished.
Table 1 shows that the size of the reference video sequence is 10 KM in our encryption scheme. The video sequence size has significantly dropped after H.264 encoding. Additionally, the encrypted video bit stream is the same size as the encoding video bit stream, which retains the original bit characteristics very well.
4.1.2. Objective Video Quality Analysis
In this section, we also used Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM) to measure the perceived effect of the video. PSNR is widely used to objectively evaluate video quality. A larger value of PSNR indicates a better video quality, and vice versa. The calculation formula of PSNR is obtained according to the mean square error (MSE) of the error of two images. The calculation formula of MSE is expressed by Equation (3), and the calculation formula of PSNR is represented by Equation (4). However, PSNR does not evaluate video quality very well because of the nonlinearity of the human visual nervous system. Therefore, it has been proposed to use SSIM to evaluate the similarity of two images. The value of SSIM ranges from 0 to 1. A value that is close to 1 indicates that the reference image is more similar to the target image.
Therefore, the formula for calculating PSNR is described, as follows:
where,
H and
W indicate the height and width of the video image, respectively.
show the pixel value of the original video image, and
indicate the pixel value of the encrypted video image.
k represents the number of bits per pixel, which is generally 8.
Table 2 gives the average PSNR values of the video after encoding and after encryption. Through experiments, we know that the benchmark sequence outputs 264 streams after passing through the H.264 encoder. However, our proposed selective encryption scheme encrypts the important semantic elements in the 264 code stream, and the encrypted video file is still 264 streams. In the
Table 2, we compare the code stream after encoding with the code stream after encryption to calculate the PSNR value. Similarly,
Table 3 provides the average SSIM value of the encrypted video. We observe
Table 3 to find that the video image after encryption is quite different from the video image after encoding.
4.2. Evaluation Comparison
In this section, we will further elaborate the objective evaluation indicators of the proposed algorithm. It includes original image performance indicators, selective video encryption performance, and hybrid encryption performance. We choose information entropy, PSNR, and SSIM to evaluate the performance of the algorithm.
Table 4 shows the objective performance evaluation of the algorithm.
We randomly selected two video images to evaluate the performance of the algorithm. The hybrid encryption algorithm is superior to the original selective video encryption from a security perspective, as can be seen from
Figure 4. The closer the value of the information entropy is to 8, the better the algorithm’s encryption performance. The smaller the PSNR value, the better the algorithm’s encryption performance. The smaller the value of SSIM, the better the encryption performance of the algorithm.
We compare the encryption scheme that is presented in this article with the other seven newest video encryption schemes. These encryption schemes use different algorithms to encrypt different parameters in the video. Therefore, we mainly compare encryption parameters, encryption algorithms, format compatibility, and bit addition.
Table 5 gives the results of the comparison.
As can be seen from
Table 5, the format compatibility of the encrypted video data is a research hotspot of video encryption. We all know that the target of video encryption is to damage the economic value of video. In general, our proposed video selective encryption scheme is completely compliant with the decoder, and the compression ratio has not changed, and it has a sufficiently long key length to protect the video information.
4.3. Security Analysis
In the video selective encryption scheme, we use a pseudo-random sequence generator (PSNG) that is composed of double chaotic maps to generate an encryption key. The semantic features of the H.264 slice are used to selectively encrypt important semantic elements in the video sequence. After reading a large amount of literature, we know that the video sequence after H.264 encoding is divided into multiple slices, and the slices are independent of each other. This scheme uses this feature to achieve the selective video encryption. We will analyze the security of selective video encryption schemes from two other aspects.
4.3.1. Key Volume
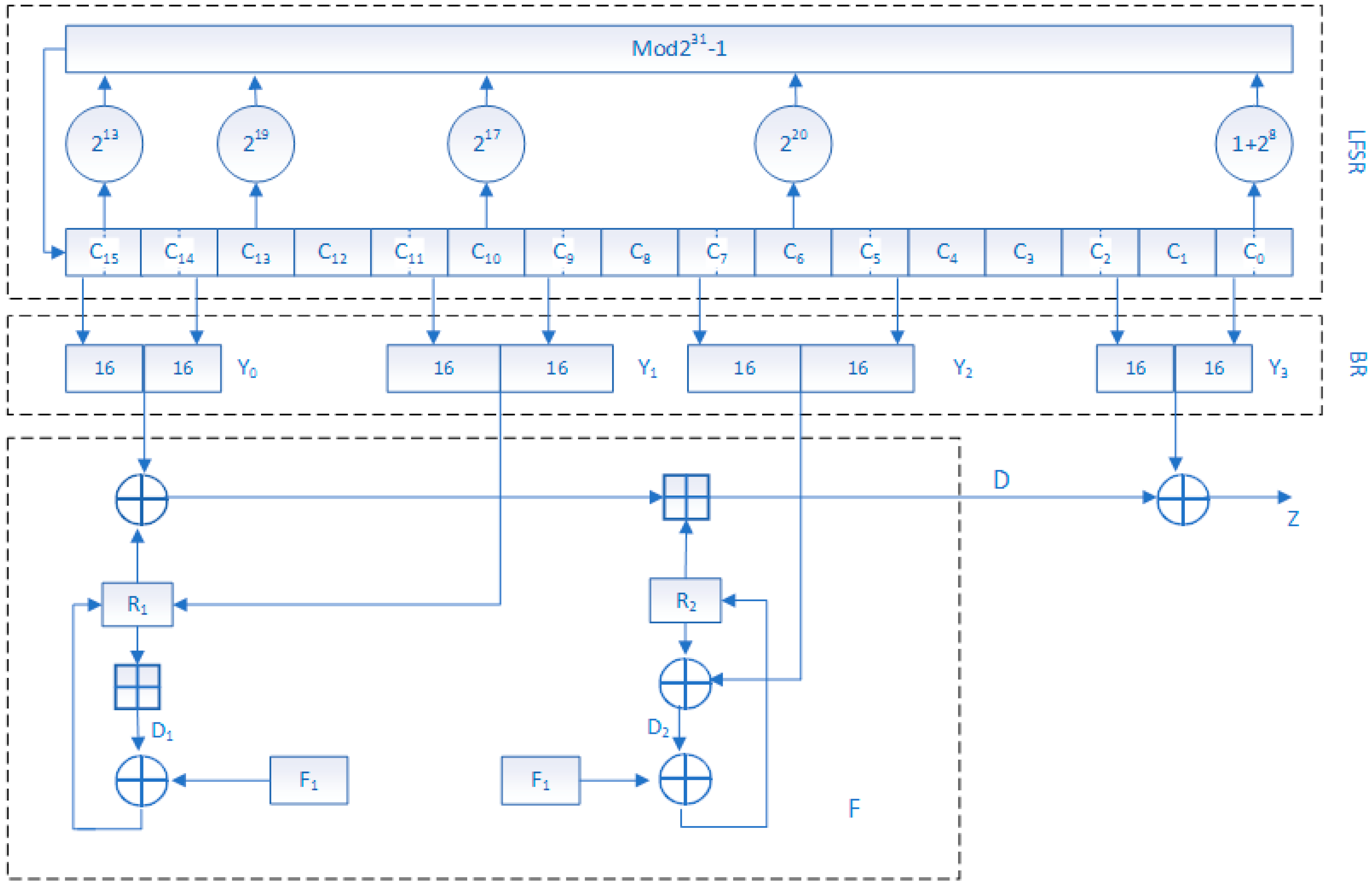
The key volume is another factor in measuring password security. In this scheme, we did not use AES’s original key generation scheme, but used the pseudo-random key generator that was proposed by Xu et al. [
25] to generate the key. The generator’s key space is
. It can be seen that the key volume is very large enough to withstand exhaustive attack. The 4-D hyperchaotic system is introduced to further protect the privacy of video images, which can meet the requirements of small amount of video data and strong security video encryption. The size of the key space of the 4-D hyperchaotic system is
. Therefore, the proposed algorithm has strong security.
4.3.2. Security Analysis of Selective Video Encryption Scheme
We use the fragmentation feature of H.264 video coding to encrypt important semantic elements in the video. In our experiments, we encode the video into 300 independent slices and encrypt the important semantic elements in each slice. The encrypted video size is the same as the encoded video size (
Table 1 has been given). The security of this scheme not only depends on the security of the encryption algorithm, but also on the security of each slice in the video. Fortunately, the slices after H.264 encoding are independent of each other. Therefore, even if one slice in the video is correctly decrypted, it will not affect the security of other video information.
For the convenience of experiment, we encrypt each video frame as a slice. The benchmark video sequence we use is 300 frames, so each video has 300 slices, so each video is encrypted with 300 keys. We know that it is very difficult to correctly guess a key, and then the probability that 300 keys are correctly guessed is almost zero. Furthermore, we know that each video frame can be encoded into a plurality of mutually independent slices. If each video frame is encoded as n (n > 1) slices, then n * 300 keys are required to encrypt a video. In this case, it is even more difficult to obtain a clear video.
In the encryption process, we choose the CFB mode of AES to ensure that the video is encrypted and it still meets the requirements of real-time and format compatibility. Furthermore, the AES algorithm for 128-bit encryption keys is a good choice compared to most encryption algorithms, because it is assumed that all possible keys are used to crack 128-bit keys at 50 billion keys per second. The required time is 5 × 1021 years. Therefore, the AES algorithm can not only guarantee the security of the encryption mean, but also ensure the real-time and format compatibility requirements after the video is encrypted. Therefore, theoretically speaking, our selective video encryption scheme is superior to other video encryption schemes.
Figure 5 depicts a subjective evaluation of the algorithm. The first column in
Figure 5 is the original video image. The middle column in
Figure 5 is the encrypted video image. The last column in
Figure 5 is the decrypted video image.
Table 2 illustrates the peak signal-to-noise ratio of the algorithm in each color space.
Table 3 shows the structural similarity index of the encryption algorithm. The smaller the peak signal-to-noise ratio and the lower the structural similarity index, the better the performance of the selected encryption algorithm.
In
Table 4, we will further elaborate the objective evaluation indicators of the proposed algorithm. It includes original image performance indicators, selective video encryption performance, and hybrid encryption performance. We choose information entropy, PSNR, and SSIM to evaluate the performance of the algorithm.
Table 5 compares the existing video encryption schemes. The algorithm performance comparison analysis is completed from the perspectives of encryption semantic elements, format complexity, bit number impact, and encryption unit. The experimental results show that the proposed selective encryption algorithm has better performance. Therefore, the security analysis of selective video encryption algorithm is given in this section.
In summary, this section mainly simulates and analyzes the proposed algorithm. From the experimental results, the performance of the proposed algorithm is better than that of most current selective video encryption algorithms.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}