An Adaptive Face Image Inpainting Algorithm Based on Feature Symmetry


Abstract
1. Introduction
- Firstly, the position of the facial feature information points is determined in the face image, and the face is divided into a circular domain of four characteristic parts according to the distribution of the feature points to define the feature search range.
- Then, by introducing feature symmetry, the priority calculation is improved and the reliability of priority calculation is increased.
- After that, the search area of the matching block is determined according to the relative position of the repair area and each feature part.
- Finally, the HSV (Hue, Saturation, Value) color space is introduced, and the best matching block is searched according to the chroma and brightness of the sample to reduce the inpainting error and complete the face inpainting image of the facial structure features.
2. Related Work
2.1. Image Inpainting Based on Graphics
2.2. Image Inpainting Based on Deep Learning
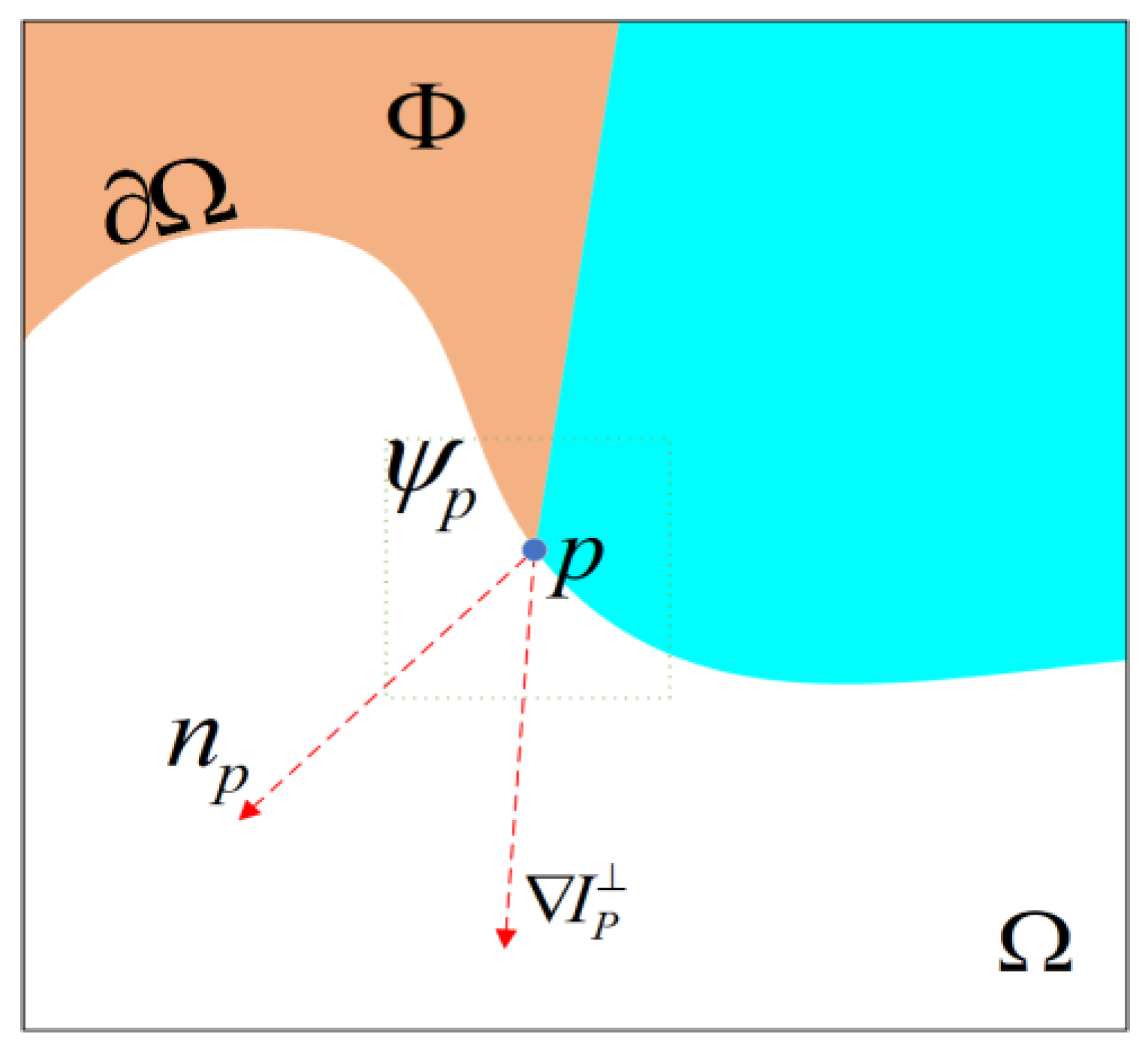
2.3. The Principle and Research of Criminisi Algorithm
2.3.1. Priority Calculation
2.3.2. Sample Block Matching
| Algorithm 1. Criminisi Algorithm. |
| Extract the boundary line ∂Ω of the target area Ω |
| While∂Ω: |
| Calculate the priority of all blocks on the boundary line ∂Ω: P(p), ∀p ∈ ∂Ω. |
| Search for the block with the highest priority . |
| Search for the exemplar from Φ where it minimizes . |
| Copy image data from to the missing point p on |
| Update C(p), , update the boundary line ∂Ω. |
| End |
2.3.3. Research Based on Criminisi Algorithm
3. Method
3.1. Face Local Feature Area Location
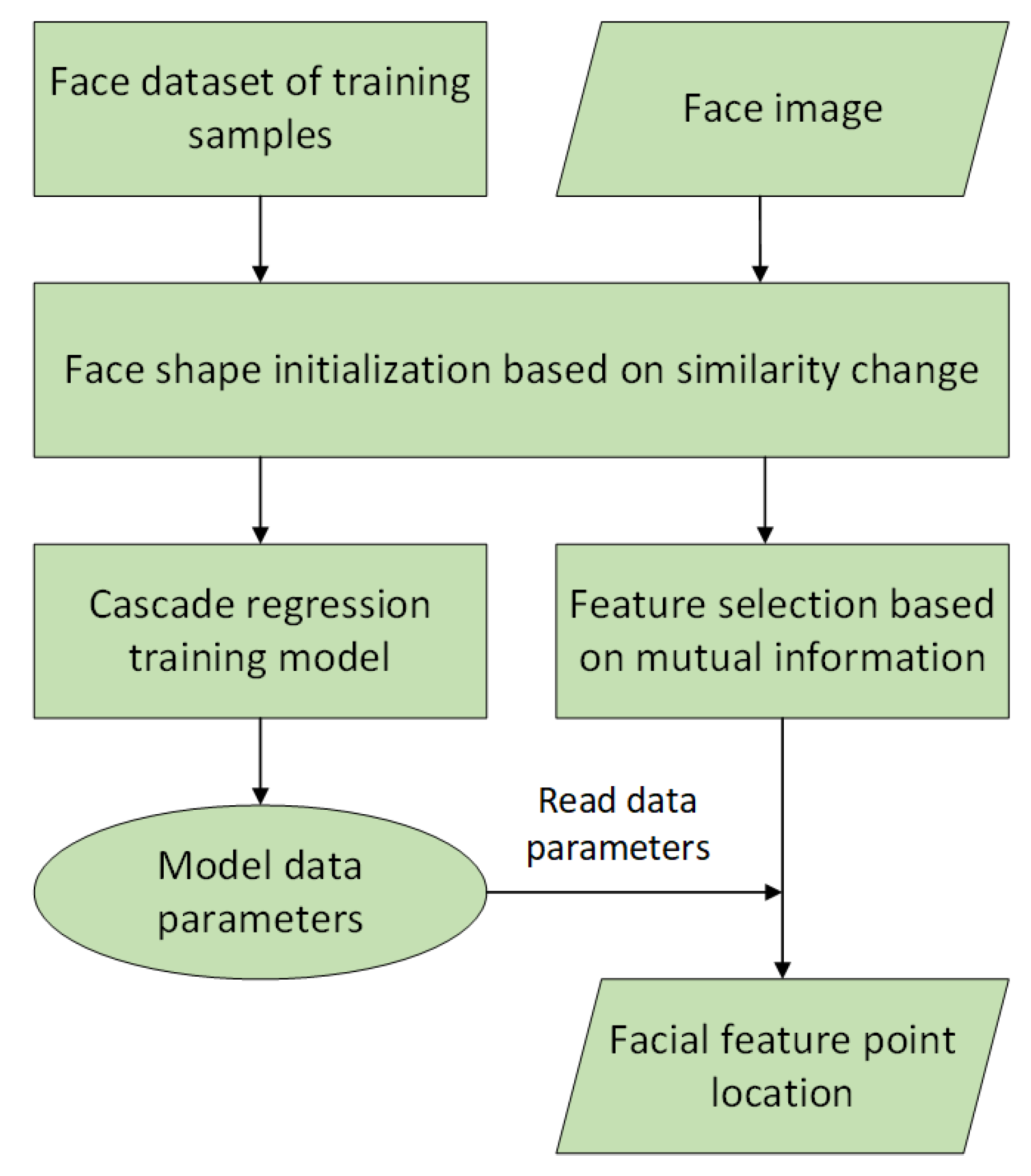
3.1.1. Facial Feature Point Location
3.1.2. Identifying Facial Feature Areas
3.2. Calculation of Priority Function Based on Feature Symmetry
3.3. Adaptive Selection Method of Sample Block Size
3.4. Sample Matching Method Based on HSV Color Space
3.5. Algorithm Implementation
- The face image and the inpainting area are input in the image.
- The feature point set is determined by the adaptive window regression model of facial feature point location, and the feature point set is classified as , representing the left eyebrow feature area, right eyebrow feature area, nose feature area, mouth feature area, and face contour region, respectively.
- The center of each set is calculated. The Euclidean distance between the points in and is calculated, and the maximum radius of the circular domain is determined using Equation (8), where represents the number of feature points in . Taking as the center of the circle and as the maximum radius, a circle with a maximum radius of the characteristic part is obtained.
- The confidence of all pixels in the image to be repaired is initialized according to Equation (4).
- The highest-priority weight is obtained by Equation (9) and filled in the boundary of the area to be repaired.
- The sizes of the sample block and the matching block are adaptively selected according to Equations (15)–(18).
- According to the matching principle of Equation (22), multiple parameters are used to find the sample block with the highest symmetry.
- The boundary information of the repaired area is updated, and the confidence of the pixel values of the image is updated. The confidence of the pixels in the repaired area is mainly updated, and then the next pixel is prepared for inpainting. Steps (2–8) are repeated until the face image is repaired.
- The face image is output after inpainting is accomplished.
4. Experiments and Results
4.1. Experimental Method and Environment
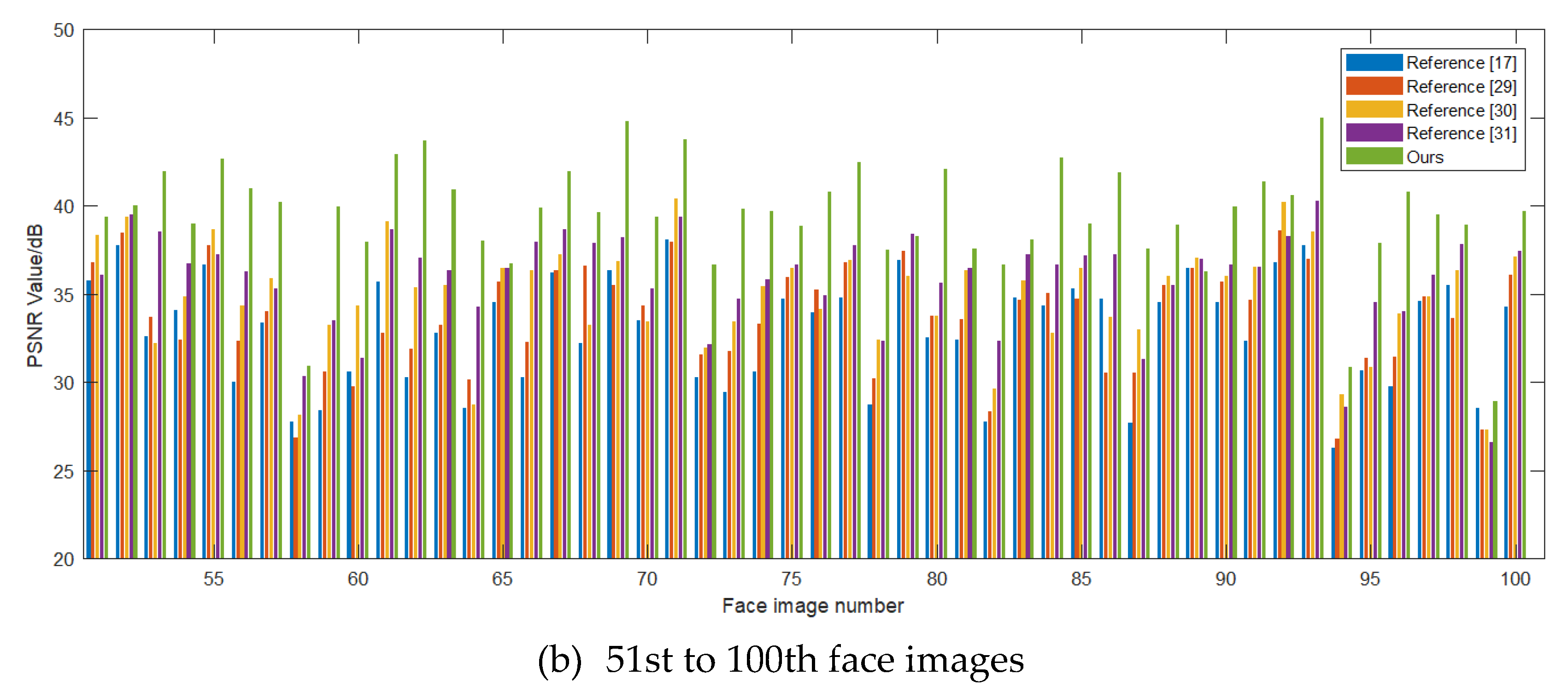
4.2. Result
5. Discussion
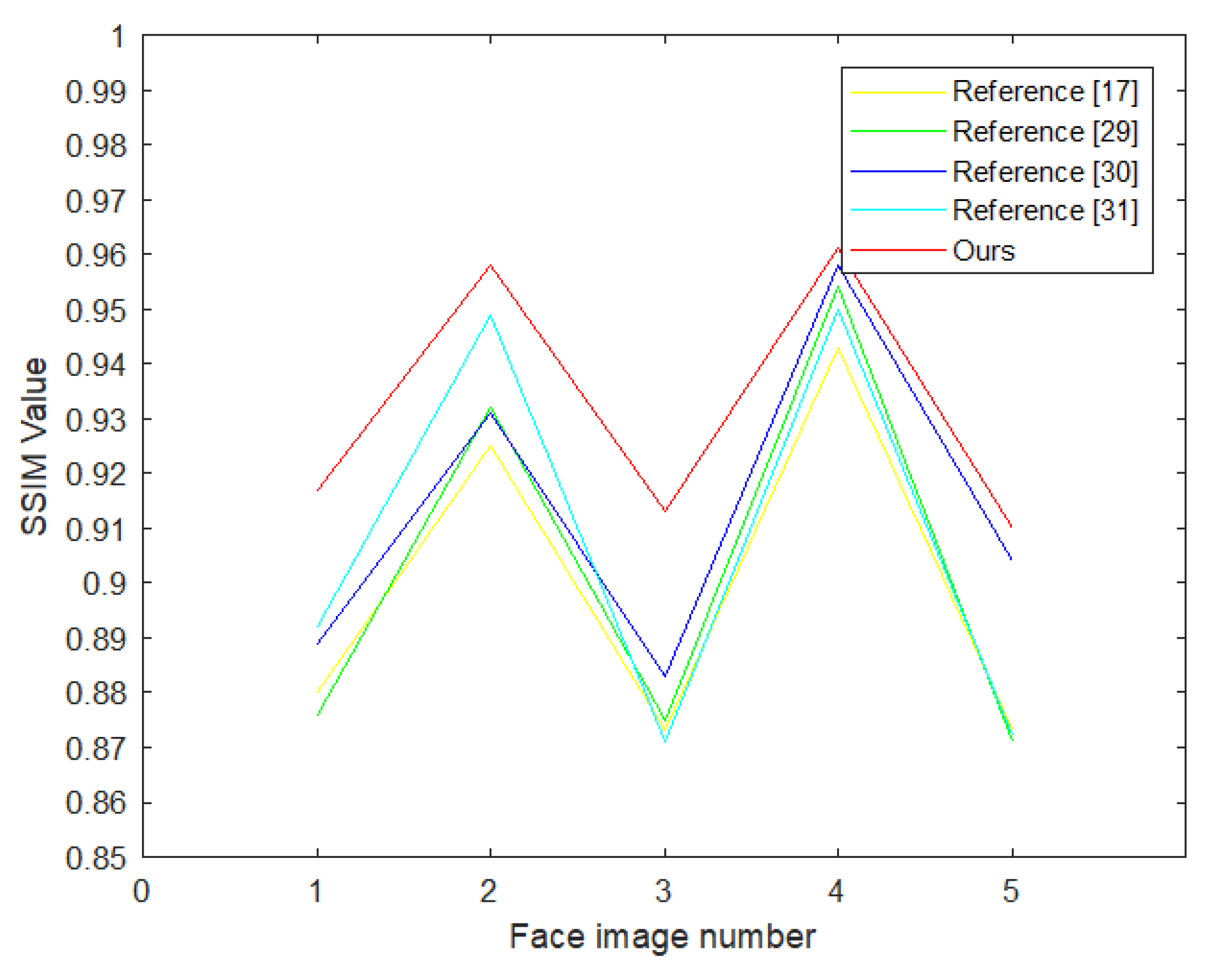
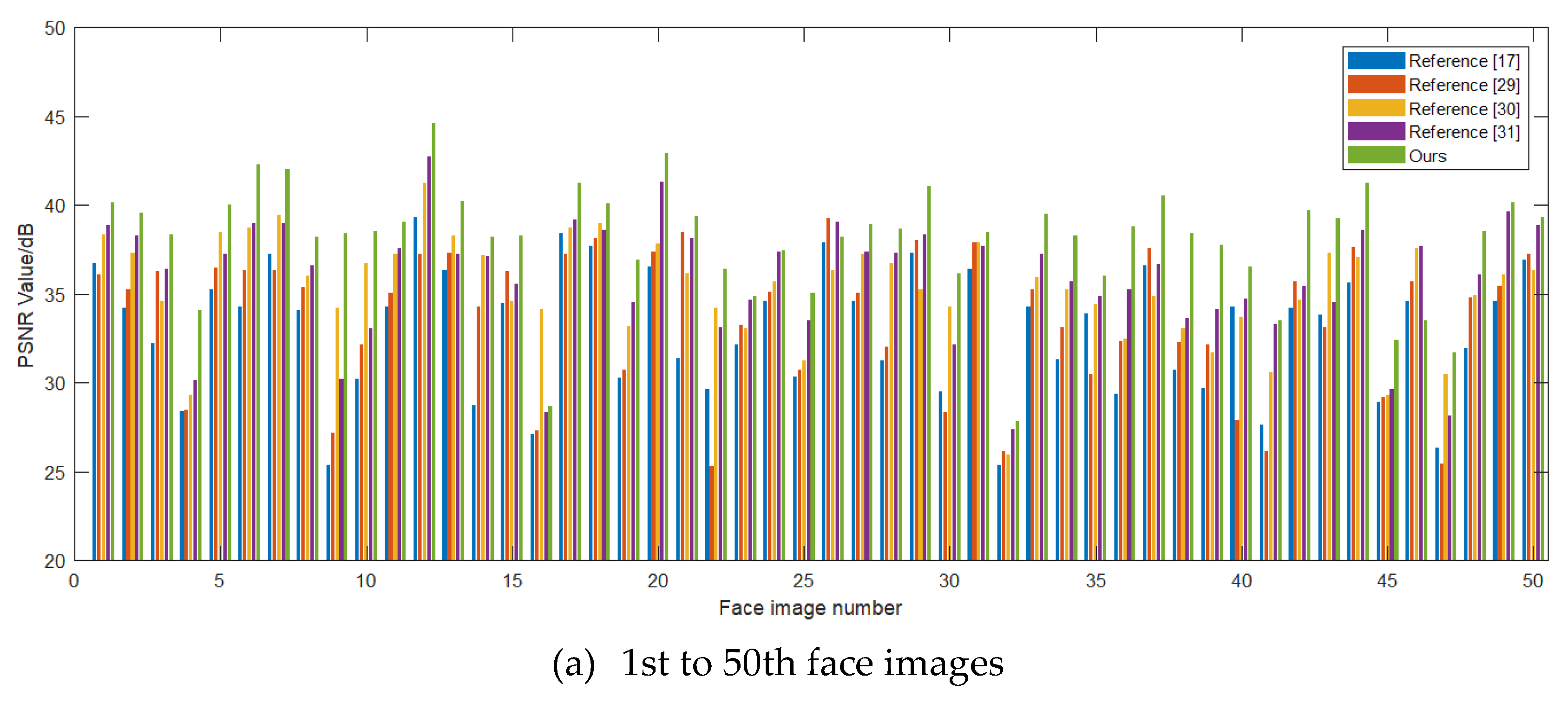
5.1. Discussion on the Validity of Our Algorithm
5.2. Discussion on the Efficiency of Our Algorithm
5.3. Discussion on the Comparison with GAN
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yang, W.K.; Zhang, X.; Li, J. A local multiple patterns feature descriptor for face recognition. Neurocomputing 2020, 373, 109–122. [Google Scholar] [CrossRef]
- Ma, L.; Deng, Z. Real-time facial expression transformation for monocular RGB video. Comput. Graph. Forum. 2019, 38, 470–481. [Google Scholar] [CrossRef]
- Li, H.; Yu, J.H.; Ye, Y.T.; Bregler, C. Realtime facial animation with on-the-fly correctives. ACM Trans. Graph. 2013, 4, 42. [Google Scholar] [CrossRef]
- Mousas, C.; Anagnostopoulos, C.N. Structure-aware transfer of facial blendshapes. In Proceedings of the 31st Spring Conference on Computer Graphics, Smolenice, Slovakia, 22–24 April 2015; pp. 55–62. [Google Scholar]
- Zhang, D.; Tang, X.H. Image inpainting based on combination of wavelet transform and texture synthesis. J. Image Graph. 2015, 20, 882–894. [Google Scholar]
- Guo, Q.; Gao, S.; Zhang, X. Patch-based image inpainting via two-stage low rank approximation. IEEE Trans. Vis. Comput. Graph. 2017, 24, 2023–2036. [Google Scholar] [CrossRef] [PubMed]
- Hoeltgen, L.; Mainberger, M.; Hoffmann, S. Optimising spatial and tonal data for PDE-based inpainting. Mathematics 2017, 18, 35–83. [Google Scholar]
- Kumar, V.; Mukherjee, J.; Mandal, S.K.D. Image Inpainting Through Metric Labeling via Guided Patch Mixing. IEEE Trans. Image Process. 2016, 25, 5212–5226. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Yeh, R.A.; Chen, C.; Lim, T.Y. Semantic image inpainting with deep generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6882–6890. [Google Scholar]
- Van de oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2611–2620. [Google Scholar]
- Hasegawa, M.; Kako, T.; Hirobayashi, S. Image inpainting on the basis of spectral structure from 2-D nonharmonic analysis. IEEE Trans. Image Process. 2013, 22, 3008–3017. [Google Scholar] [CrossRef]
- Wu, X.L. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar] [CrossRef]
- Chan, T.F.; Shen, J. Variational image inpainting. Commun. Pure Appl. Math. 2010, 58, 579–619. [Google Scholar] [CrossRef]
- Memg, H.Y.; Zhai, D.H.; Li, M.X. Image inpainting algorithm based on pruning samples referring to four-neighborhood. J. Comput. Appl. 2018, 38, 1111–1116. [Google Scholar]
- Wang, J.; Lu, K.; Pan, D. Robust object removal with an exemplar-based image inpainting approach. Neurocomputing 2014, 123, 150–155. [Google Scholar] [CrossRef]
- Criminisi, A.; Patrick, P.; Toyanma, K. Object Removal by Exemplar-Based Inpainting. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; pp. 721–728. [Google Scholar]
- Yang, C.; Lu, X.; Lin, Z. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4076–4084. [Google Scholar]
- Li, Y.J.; Liu, S.F.; Yang, J.M. Generative face completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5892–5900. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107. [Google Scholar] [CrossRef]
- Yu, J.H.; Lin, Z.; Yang, J.M. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Image Inpainting Using Pre-Trained Classification CNN. Available online: https://www.researchgate.net/publication/325471259_Image_Inpainting_Using_Pre-Trained_Classification_CNN (accessed on 31 May 2018).
- Altinel, F.; Ozay, M.; Okatani, T. Deep structured energy-based image inpainting. In Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 423–428. [Google Scholar]
- Siadat, S.Z.; Yaghmaee, F.; Mahdav, P. A new exemplar-based image inpainting algorithm using image structure tensors. In Proceedings of the 24th Iranian Conference on Electrical Engineering, Shiraz, Iran, 10–12 May 2016; pp. 995–1001. [Google Scholar]
- Kui, L.; Jie, Q.T.; Ben, Y.S. Exemplar-based image inpainting using structure tesnor. In Proceedings of the International Conference on Advanced Computer Science and Electronics Information, Beijing, China, 25–26 July 2013; pp. 18–24. [Google Scholar]
- Liang, J.D.; Ting, Z.H.; Xi, L.Z. Exemplar-Based Image Inpainting Using a Modified Priority Definition. PLoS ONE 2015, 10, e0141199. [Google Scholar]
- Liu, H.B.; Ye, X.H.; Wang, Z.F. Arc promoting image inpainting using exemplar searching and priority filling. J. Image Grapgics 2018, 21, 993–1003. [Google Scholar]
- Yue, T.Z.; Yu, S.W.; Timonthy, S. Patch-guided facial image inpainting by shape propagation. J. Zhejiang Univ. Sci. A 2009, 10, 232–238. [Google Scholar]
- Sulam, J.; Elad, M. Large inpainting of face images with trainlets. IEEE Signal Process. Lett. 2016, 23, 1839–1843. [Google Scholar] [CrossRef]
- Jampour, M.; Li, C.; Yu, L.F.; Zhou, K.; Lin, S.; Bischof, H. Face inpainting based on high-level facial attributes. Comput. Vis. Image Underst. 2017, 161, 29–41. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y. Weak Texture Face Image Local Damage Point Repair Method. Comput. Simul. 2018, 35, 429–432. [Google Scholar]
- Cao, X.; Wei, Y.; Wen, F. Face Alignment by Explicit Shape Regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Wei, J.W.; Wang, X.; Yuan, Y.B. Adaptive window regression method for face alignment. J. Comput. Appl. 2019, 39, 1459–1465. [Google Scholar]
- Su, Y.; Liu, Z.; Ban, X. Symmetric Face Normalization. Symmetry 2019, 11, 96. [Google Scholar] [CrossRef]
- Prateek, G.; Priyanka, S.; Satyam, B.; Vikrant, B. A modified PSNR metric based on HVS for quality assessment of color images. In Proceedings of the International Conference on Communication and Industrial Application, Kolkata, West Bengal, 26–28 December 2011; pp. 1–4. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Alain, H.; Djemel, Z. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Model | Parameter |
|---|---|---|
| Operating system | Windows 10 | Professional 64-bit |
| Programming tool | MATLAB | R2017b 64-bit |
| CPU(central processing unit) | Intel (R) Core (TM) | I7-9700K 3.6 GHz |
| RAM(Random Access Memory) | HyperX Predator | DDR4 16 G |
| GPU(Graphics Processing Unit) | NVIDIA GeForce | RTX 1080 Ti, 1480 MHz, 11 GB |
| Algorithms | Face 1 | Face 2 | Face 3 | Face 4 | Face 5 |
|---|---|---|---|---|---|
| Reference [17] | 33.027 | 35.761 | 33.946 | 35.742 | 31.412 |
| Reference [29] | 32.426 | 35.804 | 33.241 | 35.867 | 29.884 |
| Reference [30] | 35.188 | 36.672 | 35.614 | 37.240 | 34.291 |
| Reference [31] | 36.052 | 38.524 | 33.354 | 38.061 | 32.177 |
| Our method | 38.324 | 39.060 | 36.842 | 39.552 | 35.017 |
| Images | Inpainting Pixels (dpi) | Reference [17] (s) | Reference [29] (s) | Reference [30] (s) | Reference [31] (s) | Our Method (s) |
|---|---|---|---|---|---|---|
| Face 1 | 6500 | 82.54 | 71.59 | 65.82 | 108.05 | 56.83 |
| Face 2 | 3925 | 47.80 | 42.23 | 39.16 | 74.38 | 34.31 |
| Face 3 | 4225 | 54.97 | 47.78 | 41.38 | 78.18 | 35.07 |
| Face 4 | 2700 | 35.27 | 27.81 | 26.81 | 52.13 | 22.37 |
| Face 5 | 4550 | 59.04 | 51.42 | 45.27 | 81.92 | 36.86 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, Z.; Li, H.; Li, Y.; Mei, Y.; Yang, J. An Adaptive Face Image Inpainting Algorithm Based on Feature Symmetry. Symmetry 2020, 12, 190. https://doi.org/10.3390/sym12020190
Niu Z, Li H, Li Y, Mei Y, Yang J. An Adaptive Face Image Inpainting Algorithm Based on Feature Symmetry. Symmetry. 2020; 12(2):190. https://doi.org/10.3390/sym12020190
Chicago/Turabian StyleNiu, Zuodong, Handong Li, Yao Li, Yingjie Mei, and Jing Yang. 2020. "An Adaptive Face Image Inpainting Algorithm Based on Feature Symmetry" Symmetry 12, no. 2: 190. https://doi.org/10.3390/sym12020190
APA StyleNiu, Z., Li, H., Li, Y., Mei, Y., & Yang, J. (2020). An Adaptive Face Image Inpainting Algorithm Based on Feature Symmetry. Symmetry, 12(2), 190. https://doi.org/10.3390/sym12020190