Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images



Abstract
1. Introduction
- Gammatone filter-related features: They are also known as dependent features. One of the popular gammatone filter-related features is the gammatone frequency cepstral coefficient (GFCC) based feature [29].
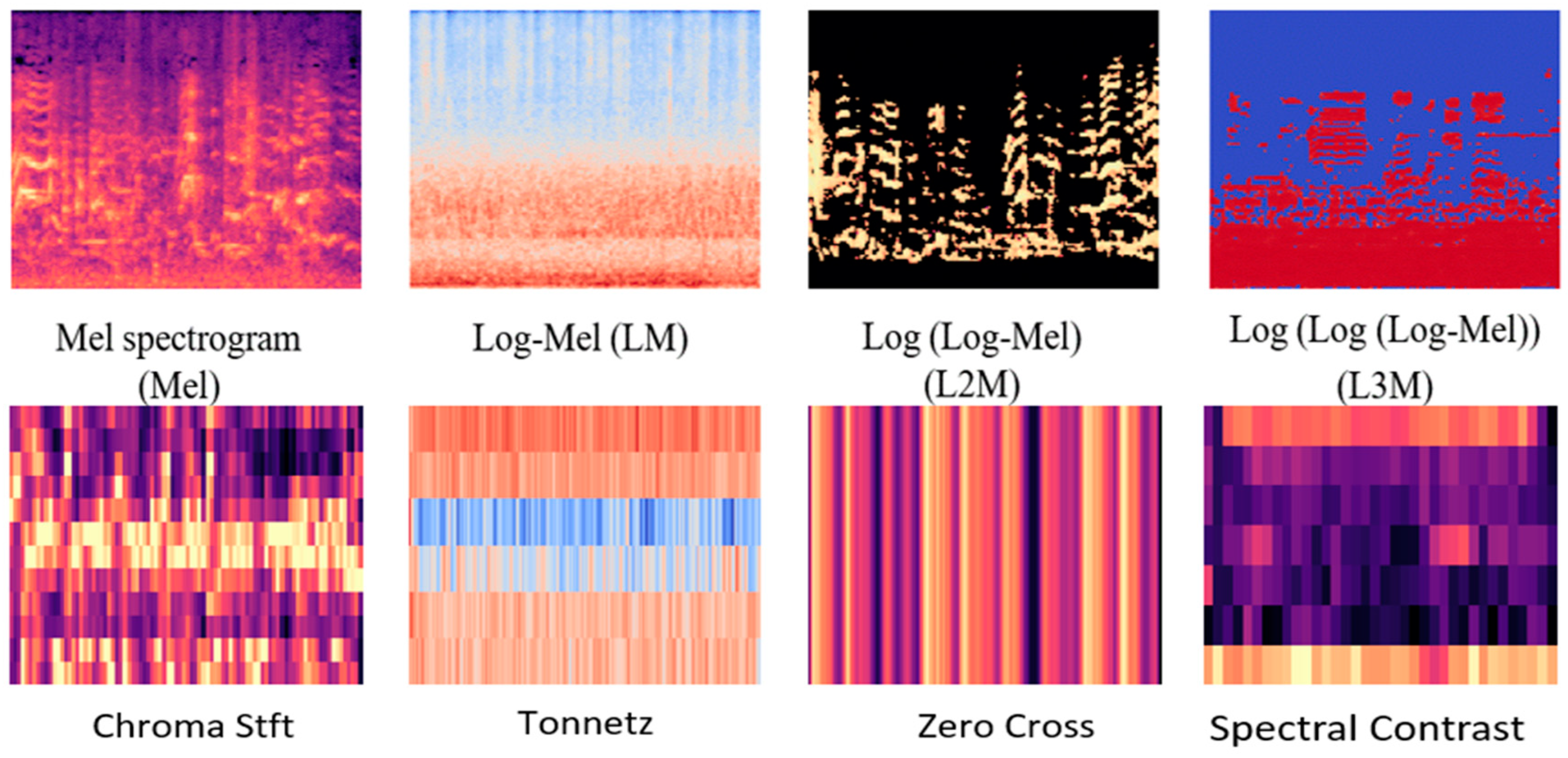
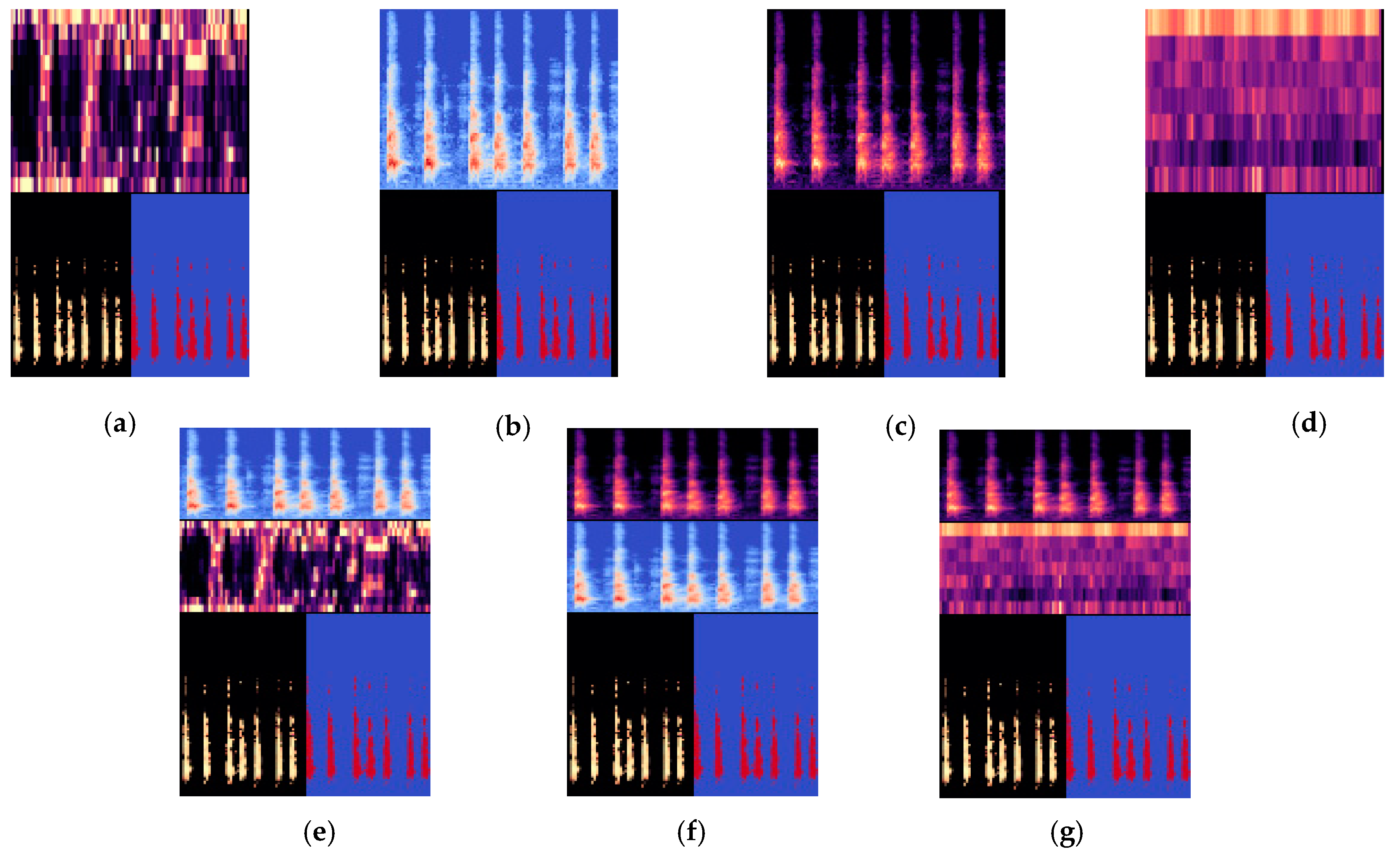
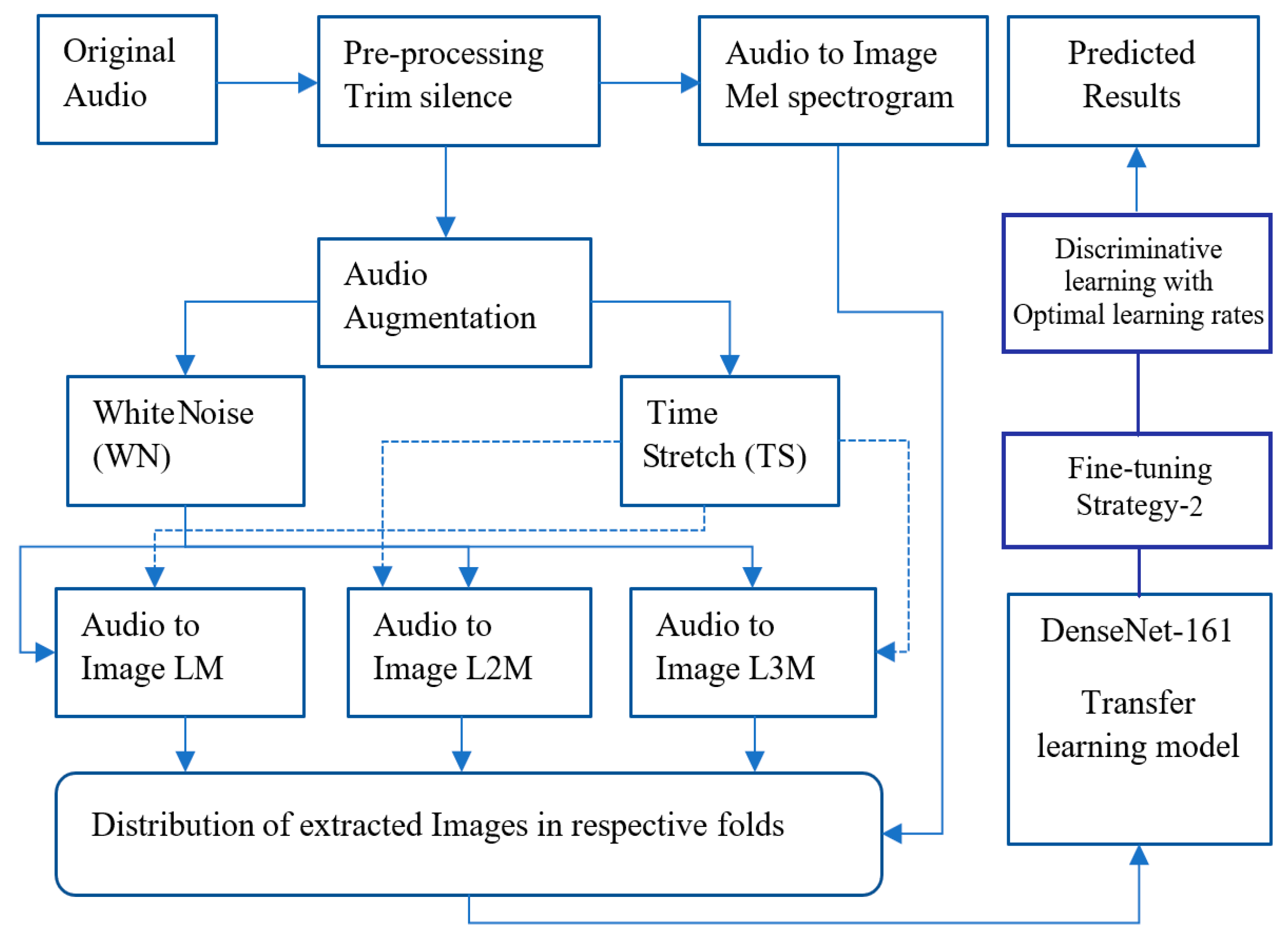
- Two new and novel auditory feature extraction techniques, named L2M and L3M are introduced for SIF, as shown in Figure 1.
- The usage of trim silence, as an influential pre-processing technique is considered. The experimentation has been done with original, noise reduction, and trim silence approaches as a pre-processing technique, the best performance was achieved by trim silence with 40 dB as shown in Figure 2.
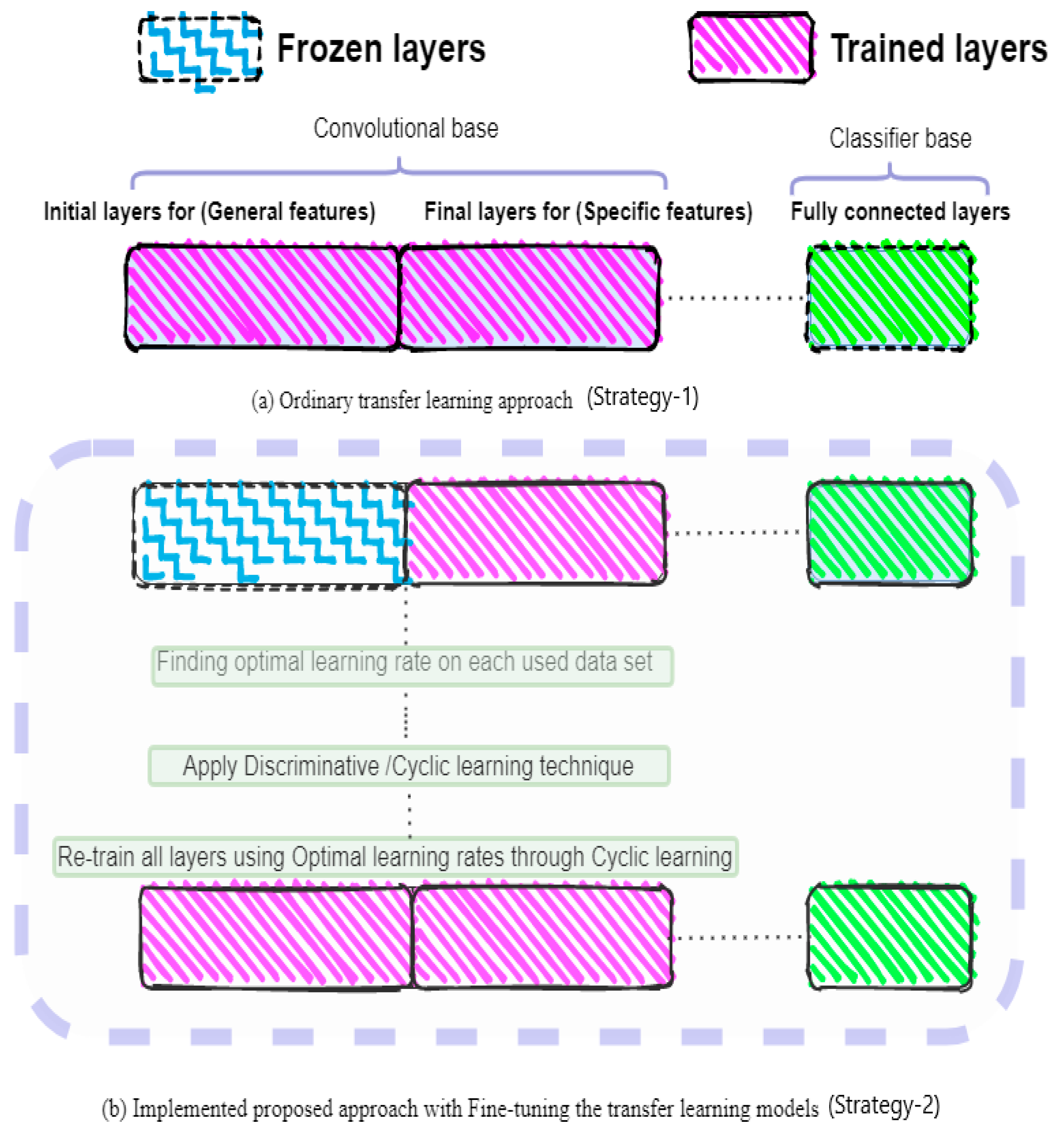
- A fine-tuning of the transfer learning model by using optimal learning rates in combination with discriminative learning is employed.
- Aggregation of various SIF in Section 3.5, which involves a total of seven aggregation schemes, including four double and three triple features accumulation approaches.
- The formulation of an exclusive new augmentation technique (named NA-1) for SIF based features is proposed. This approach is based on using a single image as a feature at a time.
- The advancement of the first data transformation capacity (NA-1) into another form (named as NA-2), which is a vertical combination of various accumulated features in the form of spectral images, is proposed.
- True testing is conducted by generating real-time audio data from YouTube for better investigation and analysis of our proposed methodologies.
- The conversion of audio to spectrogram and implementing various augmentation techniques on those SIF is very rarely applied, and according to the best of our knowledge, the data enhancement of spectrogram images for environmental sound classification task was not previously applied.
2. Related Works
3. Methodology
3.1. Spectrogram Based Acoustics Features Extraction Techniques
3.1.1. Log-Mel (LM) and Mel-spectrogram (Mel)-based Features
3.1.2. New Mel Filter Bank-Based Proposed Log2Mel (L2M) and Log3Mel (L3M) SIF Features
- Consider an audio waveform.
- Convert the audio recordings into Mel-spectrogram-based log-power spectrograms.
- The selection of reference ‘ref’ involves two possibilities. (i) The computation of decibels (dB) is comparable to peak power for reference value. (ii) Evaluate decibels (dB) relative to median power, for the consideration of reference value. We selected the decibels related to the peak power, case (i).
- After the selection of reference value ‘ref’, it returns the input power ‘S’ to decibel (dB) and is represented in Equation (4), which gives the LM SIF feature:
- The L2M feature is demonstrated as follows:
- The representation of L3M was conceived as below:where S denotes the input power, ref is the reference value, are the power spectrogram for LM, L2M, and L3M respectively. Both new features images have been exhibited in Figure 1. Although the individual performance of these L2M and L3M audio feature extraction techniques was less satisfactory in comparison with other Mel filter-based features (LM & Mel), they outperform and show competitive performance in comparison with few famous acoustics features ((S-C), Tonnetz, zero cross rate (Z-C) and chroma Stft (C-S)). These two features also play a very crucial role in our new augmentation methods to achieve a state-of-the-art result.
3.1.3. General Audio Features
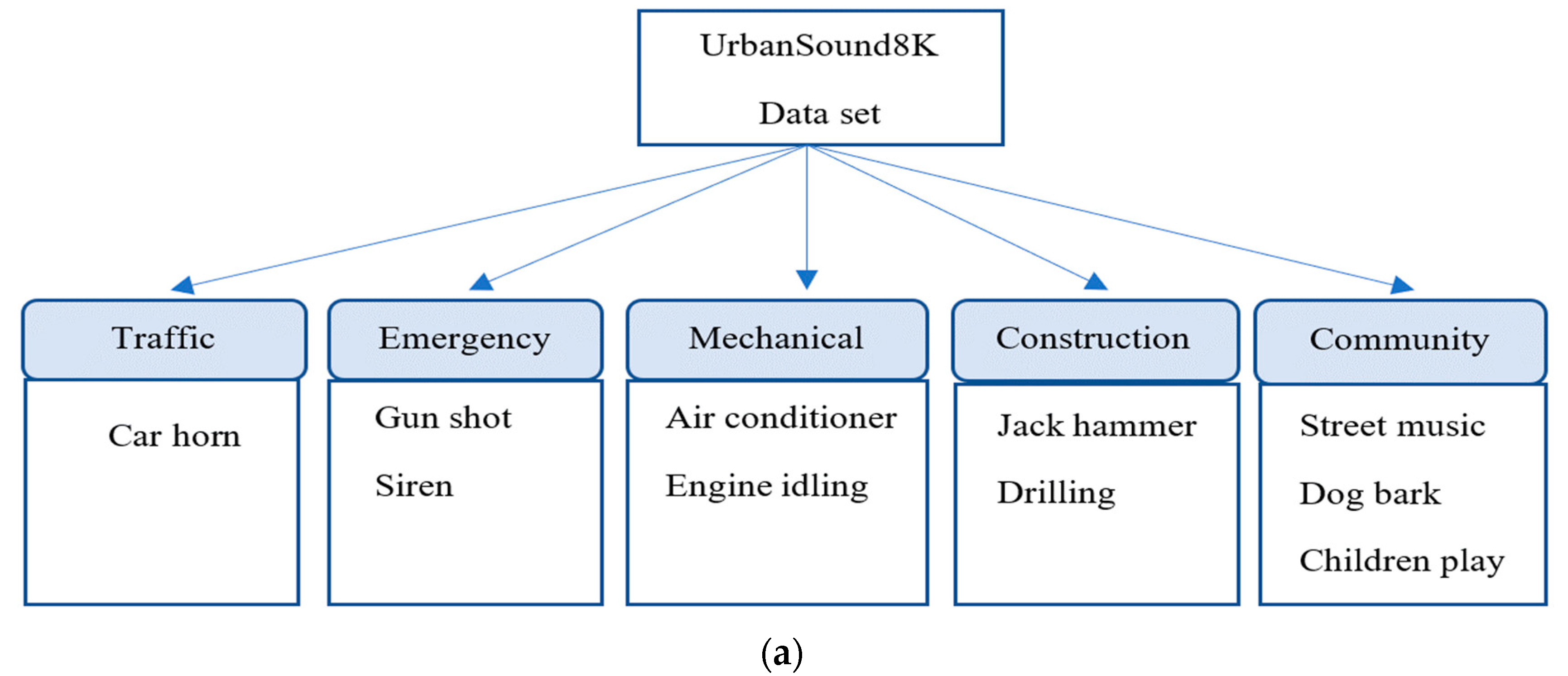
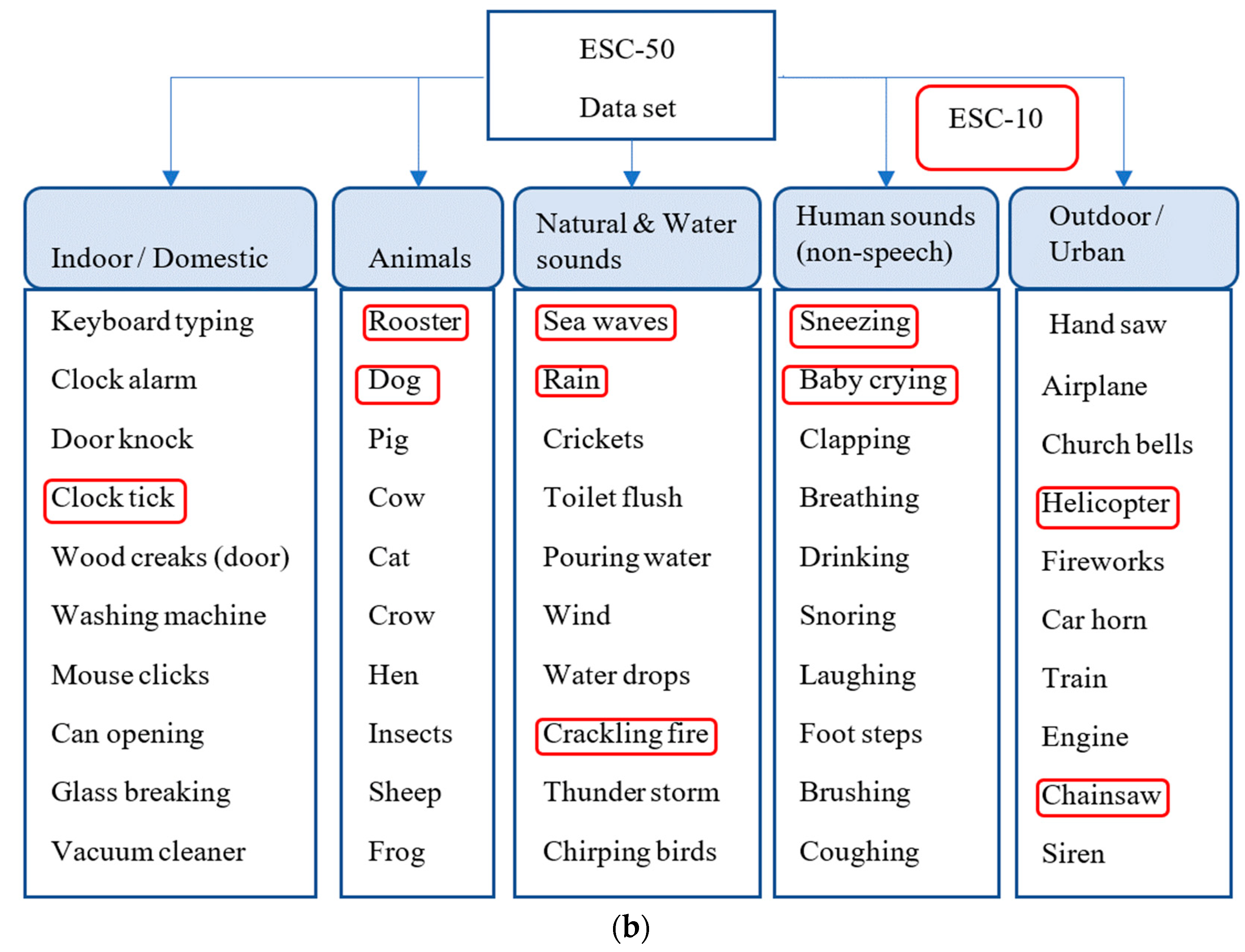
3.2. Experimental Datasets and Setup Description
Hardware and Software Specifications of the System
- Librosa: It is a Python package normally used for the analysis of audio and music signal processing [64]. Its various functions involve feature extraction, decomposition of spectrograms, filters, temporal segmentation of spectrograms, and much more. In this study, this package was used to extract spectrogram images features like Mel, LM, C-S, S-C, and other features extraction techniques-based images from audio files or clips.
- Fast.ai: It is an artificial intelligence framework that makes it easier for everyone to use deep learning effectively [65]. The main focus of this library is to advance the capacity and techniques which help the model to train quickly and effectively with limited support and resources. The implementation of transfer learning models with the help of pre-trained weights and the concepts of discriminative learning and fine-tuning have been done in this package.
- Audacity: It is an open-source digital audio recorder and editor. It is freely available with very user-friendly properties for all types of operating systems like Windows, Linux, and macOS. The YouTube-based audio dataset for the testing and evaluation of our proposed models have been recorded and edited through this package [66].
3.3. Preprocessing Technique
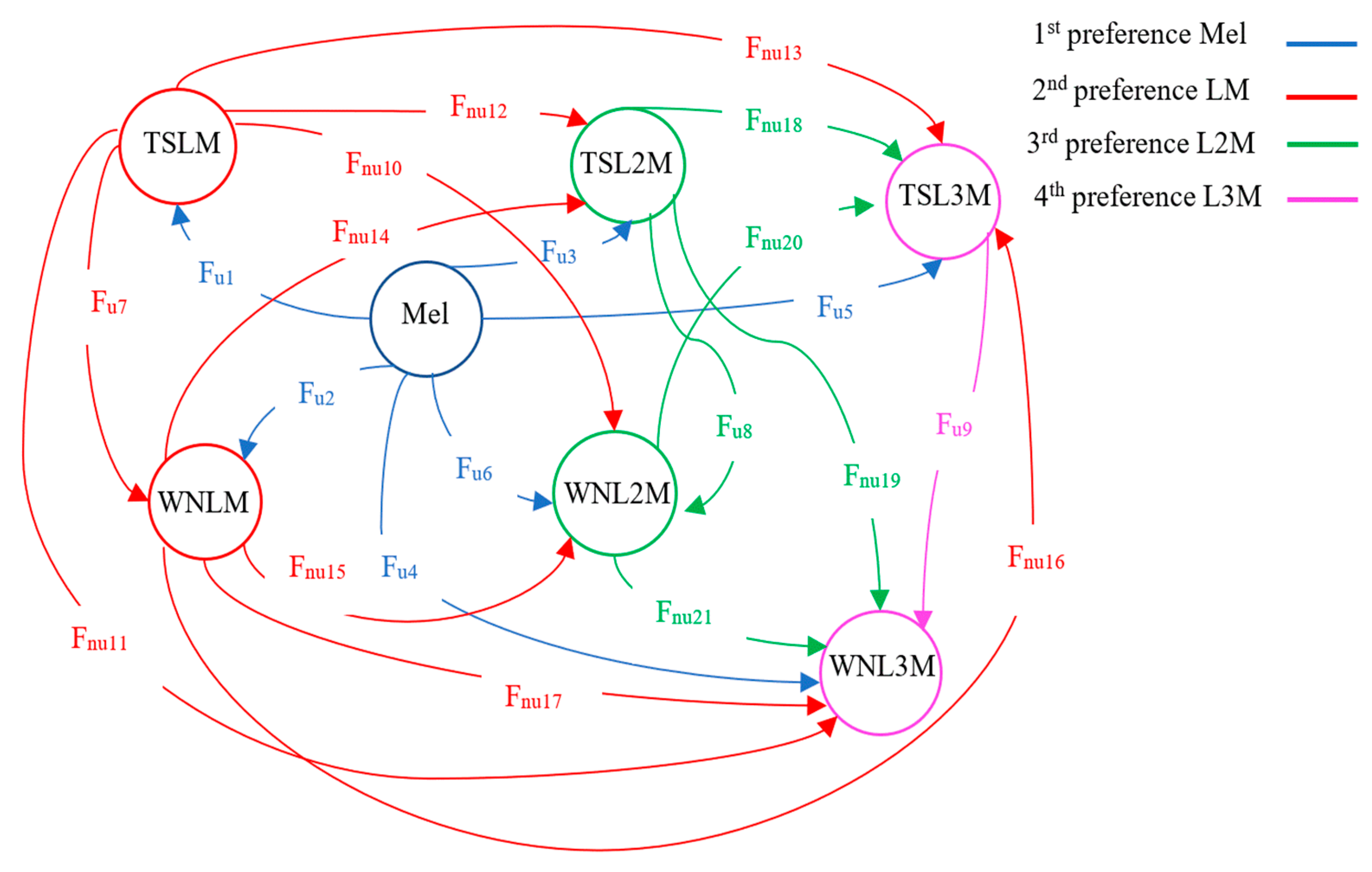
3.4. Aggregation of Different Acoustic Features
3.4.1. Double Aggregated Features
- (1)
- M-NC: The vertical combination of Mel spectrogram and NC, represented as:FtM-NC = FtM ⊕ FtNC.
- (2)
- LM-NC: The vertical combination of LM and NC, expressed as:FtLM-NC = FtLM ⊕ FtNC.
- (3)
- SC-NC: The vertical combination of S-C and NC, represented as:FtSC-NC = FtSC ⊕ FtNC.
- (4)
- CS-NC: The vertical aggregation of C-S and NC, expressed as:FtCS-NC = FtCS ⊕ FtNC.
3.4.2. Triple Aggregated Features
- (1)
- M-SC-NC: The vertical combination of Mel, S-C, and NC expressed as:FtM-SC-NC = FtM ⊕ FtSC ⊕ FtNC.
- (2)
- LM-CS-NC: The vertical combination of the LM, C-S, and NC expressed as:FtLM-CS-NC = FtLM ⊕ FtCS ⊕ FtNC.
- (3)
- M-LM-NC: The vertical combination of Mel, LM, and NC expressed asFtM-LM-NC = FtM ⊕ FtLM ⊕ FtNC.
3.5. Transfer Learning Model (DenseNet-161) with Fine-tuning (Strategy-2) and without Fine-Tuning (Strategy-1)
3.5.1. ImageNet
3.5.2. DenseNet-161
3.5.3. Explanation of Proposed Methodologies
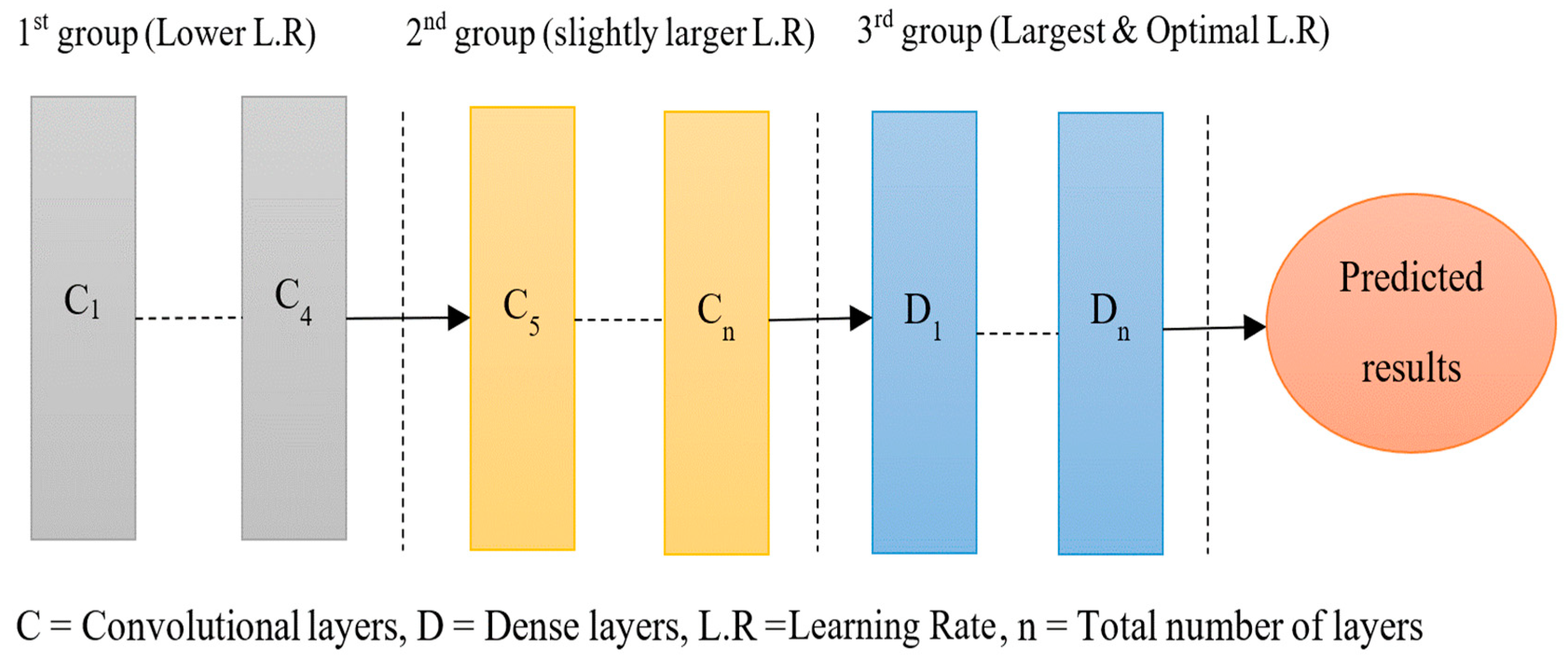
3.5.4. Discriminative/Cyclic Learning
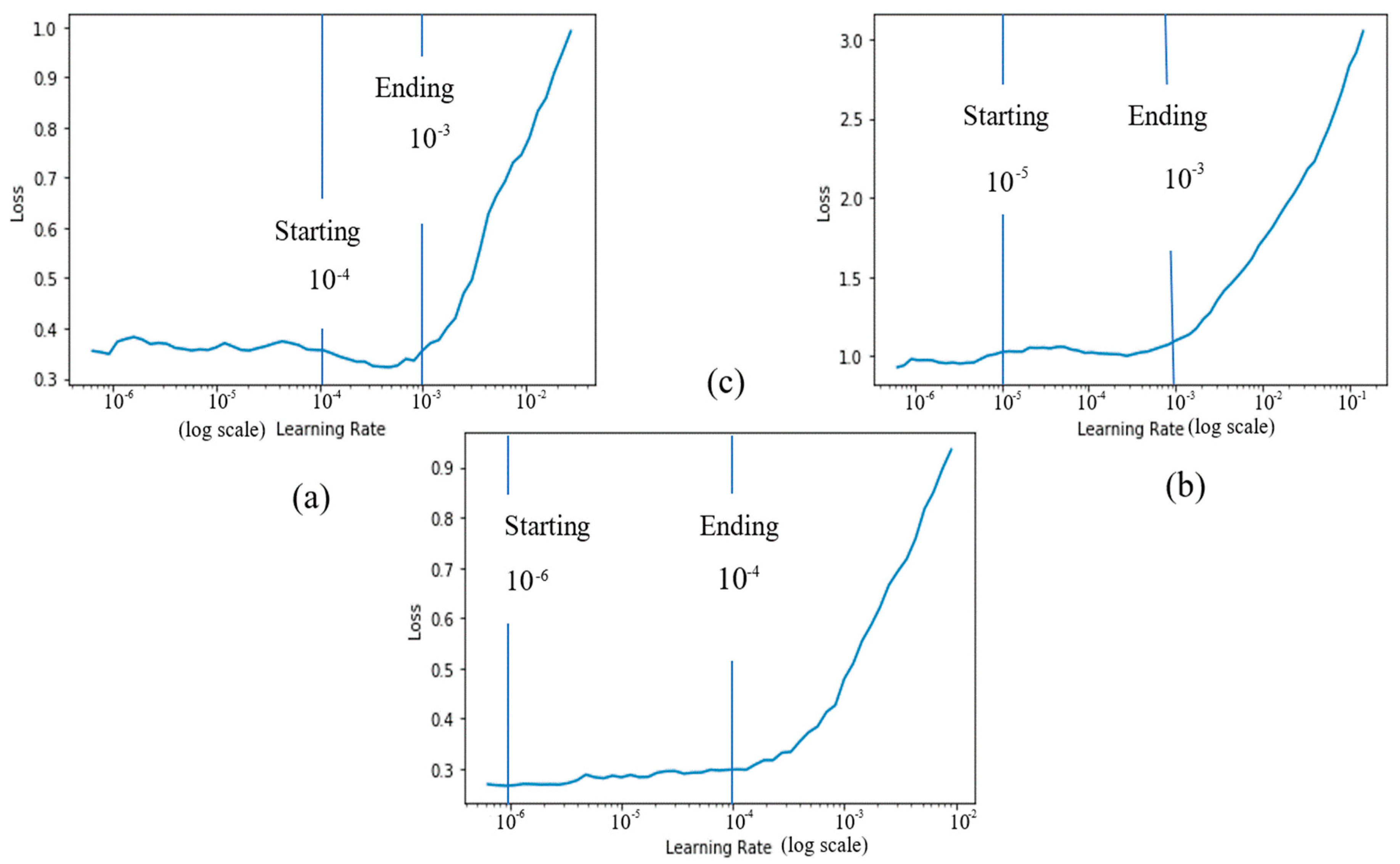
3.5.5. Determination of Optimal Learning Rates for Used Datasets
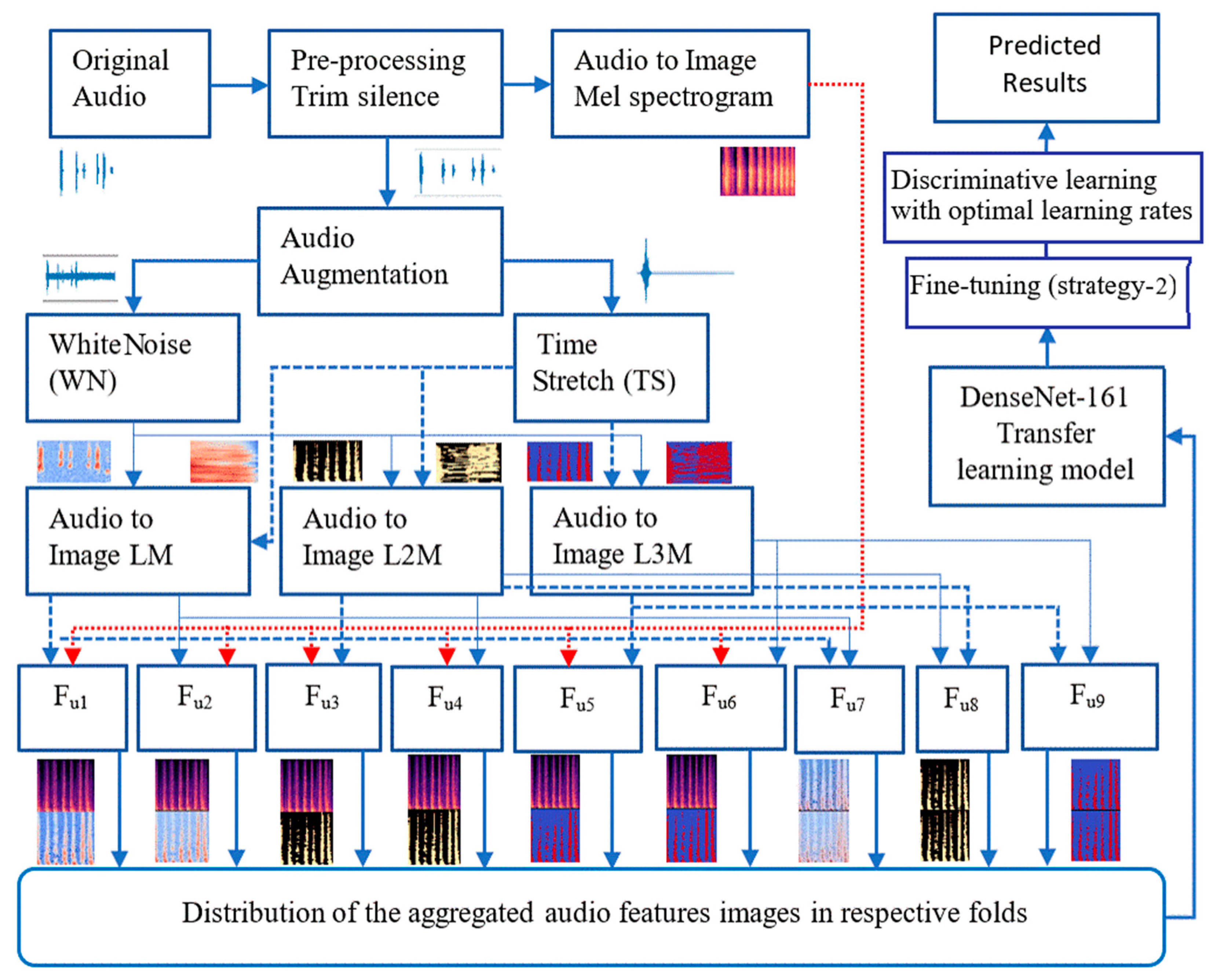
3.6. Data Enhancement Approaches
3.6.1. The First New Augmentation Technique for SIF (NA-1)
3.6.2. The Second New Transformation Approach for SIF (NA-2)
3.7. Performance Evaluation Metrics
4. Experimental Results and Analysis
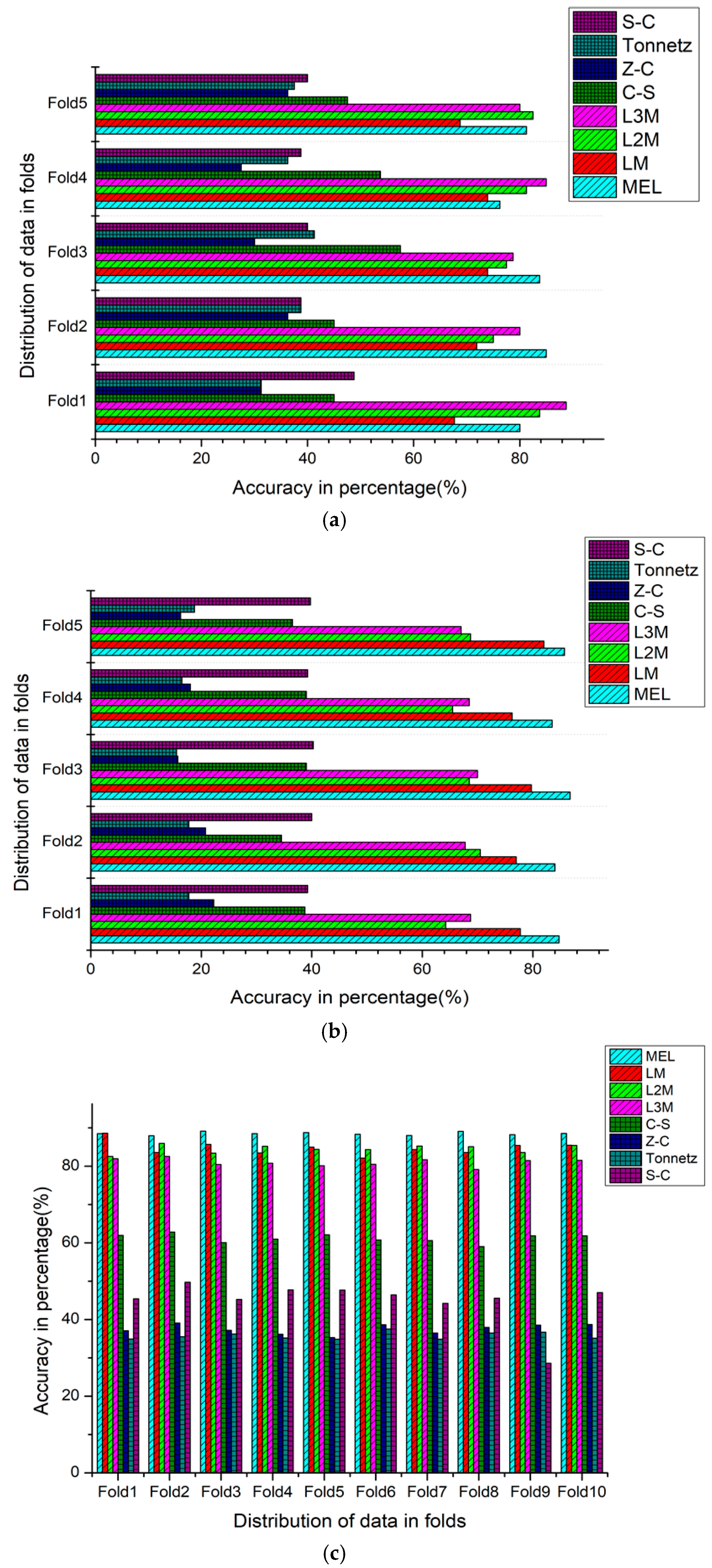
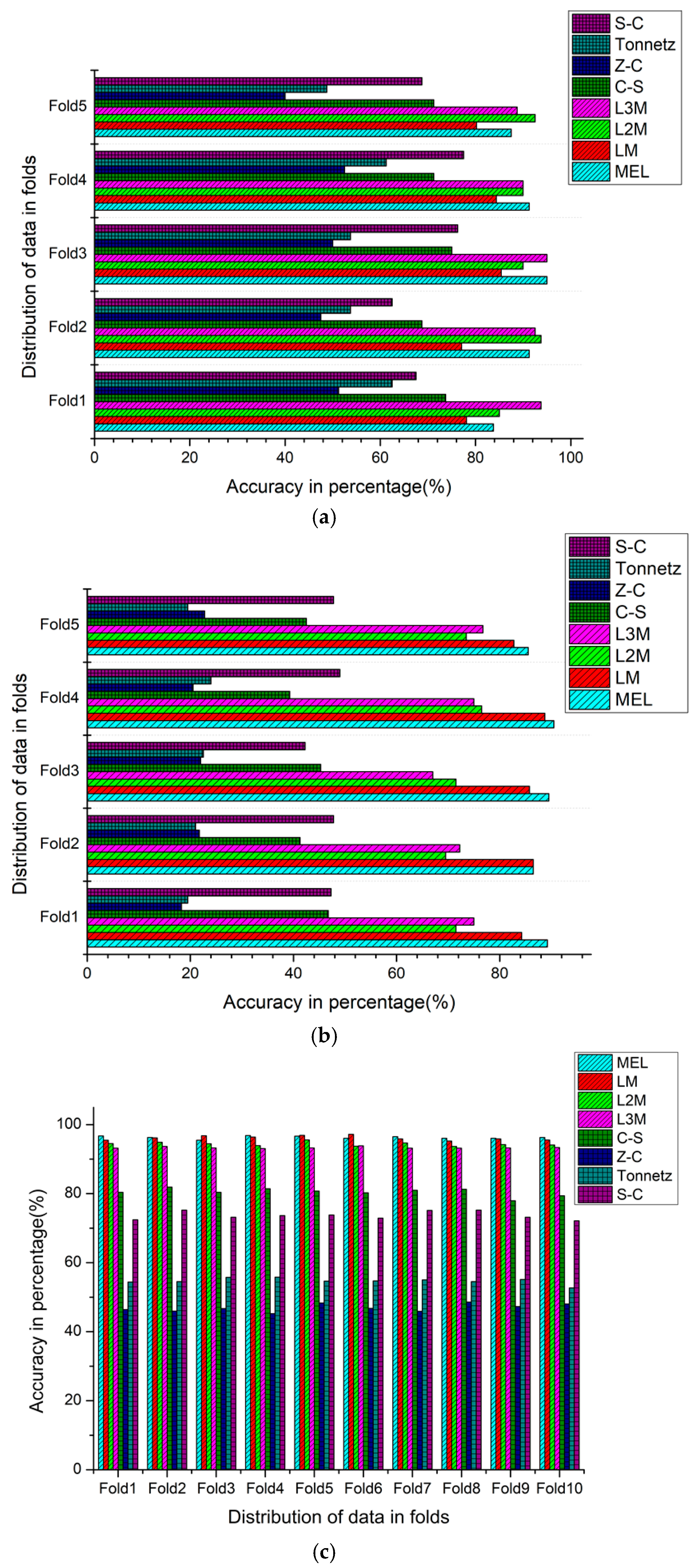
4.1. Evaluation of the Results of all Features Extraction Techniques Through (Strategy-1)
4.2. Evaluation of the Results of all Features Extraction Techniques Through (Strategy-2)
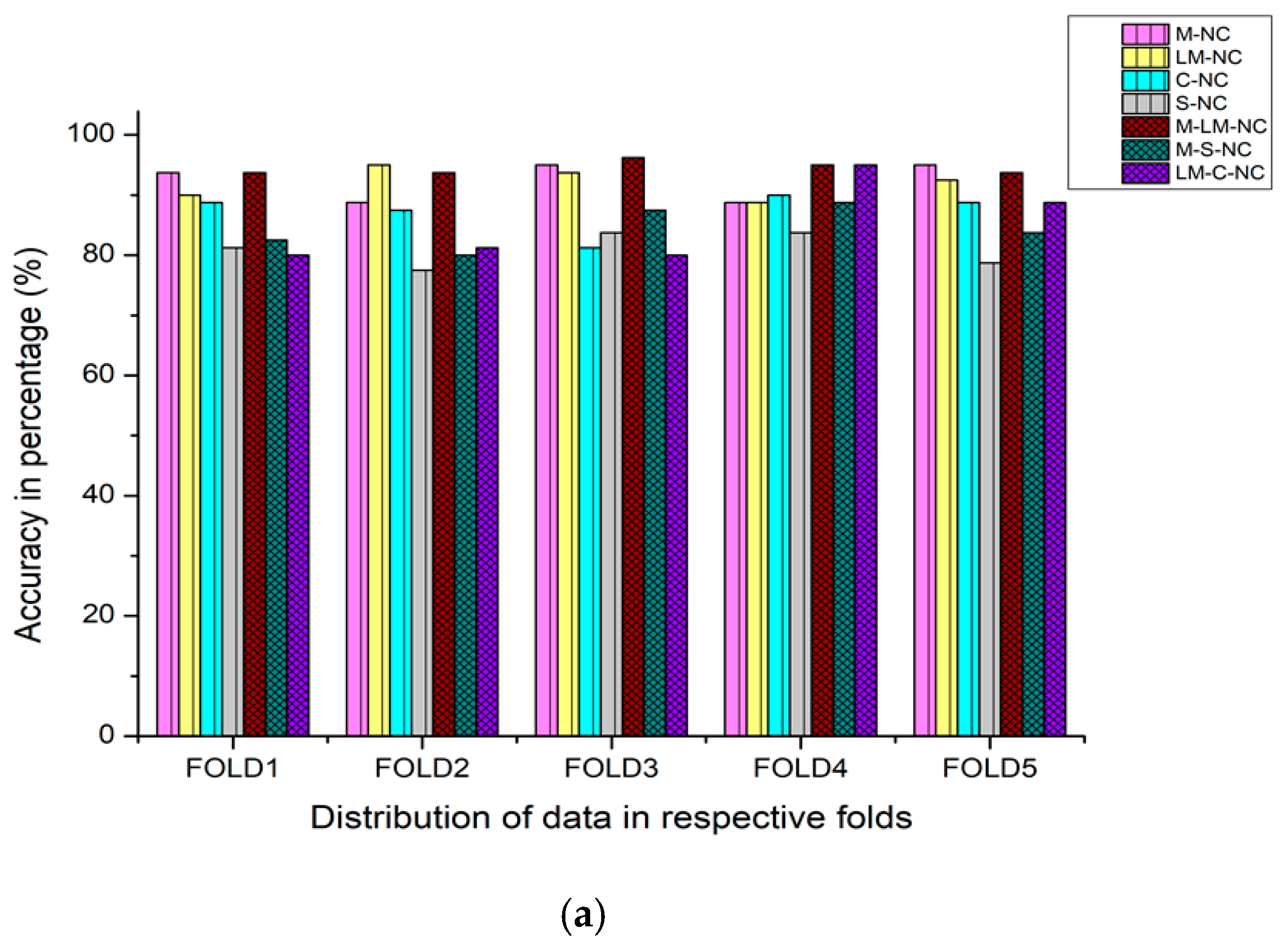
4.3. Performance Evaluation of All Features Aggregation Techniques by Using (Strategy-2)
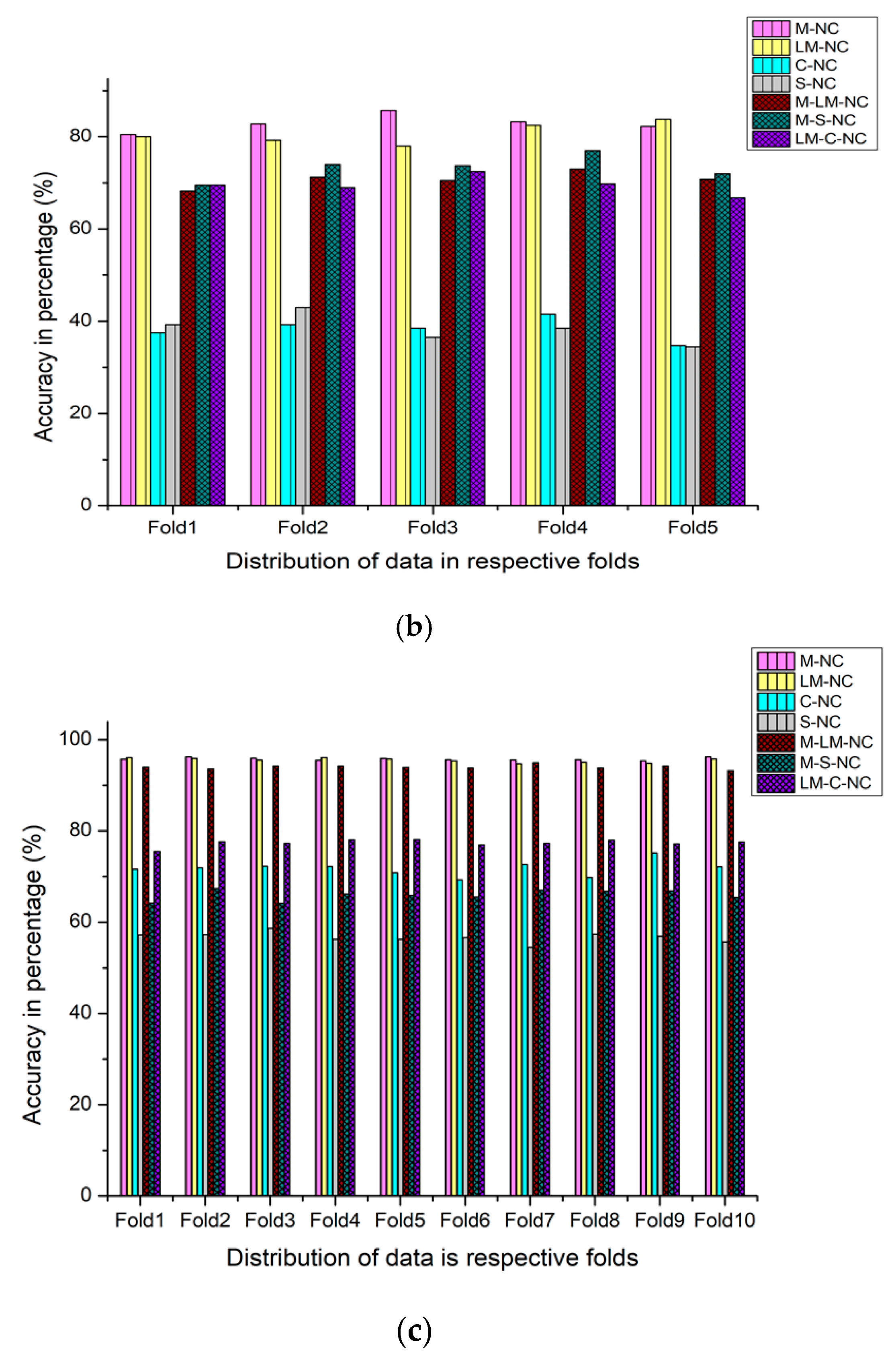
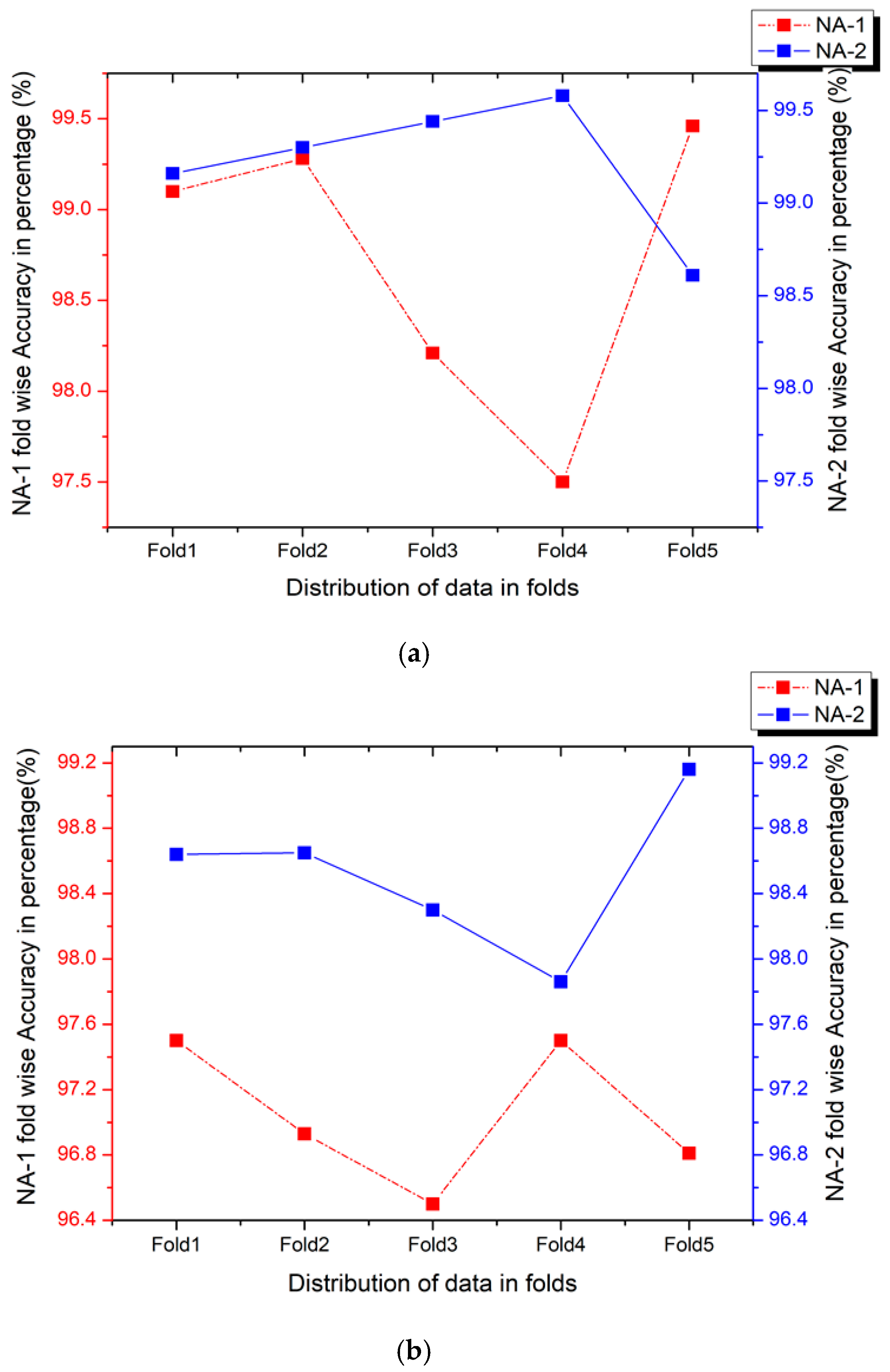
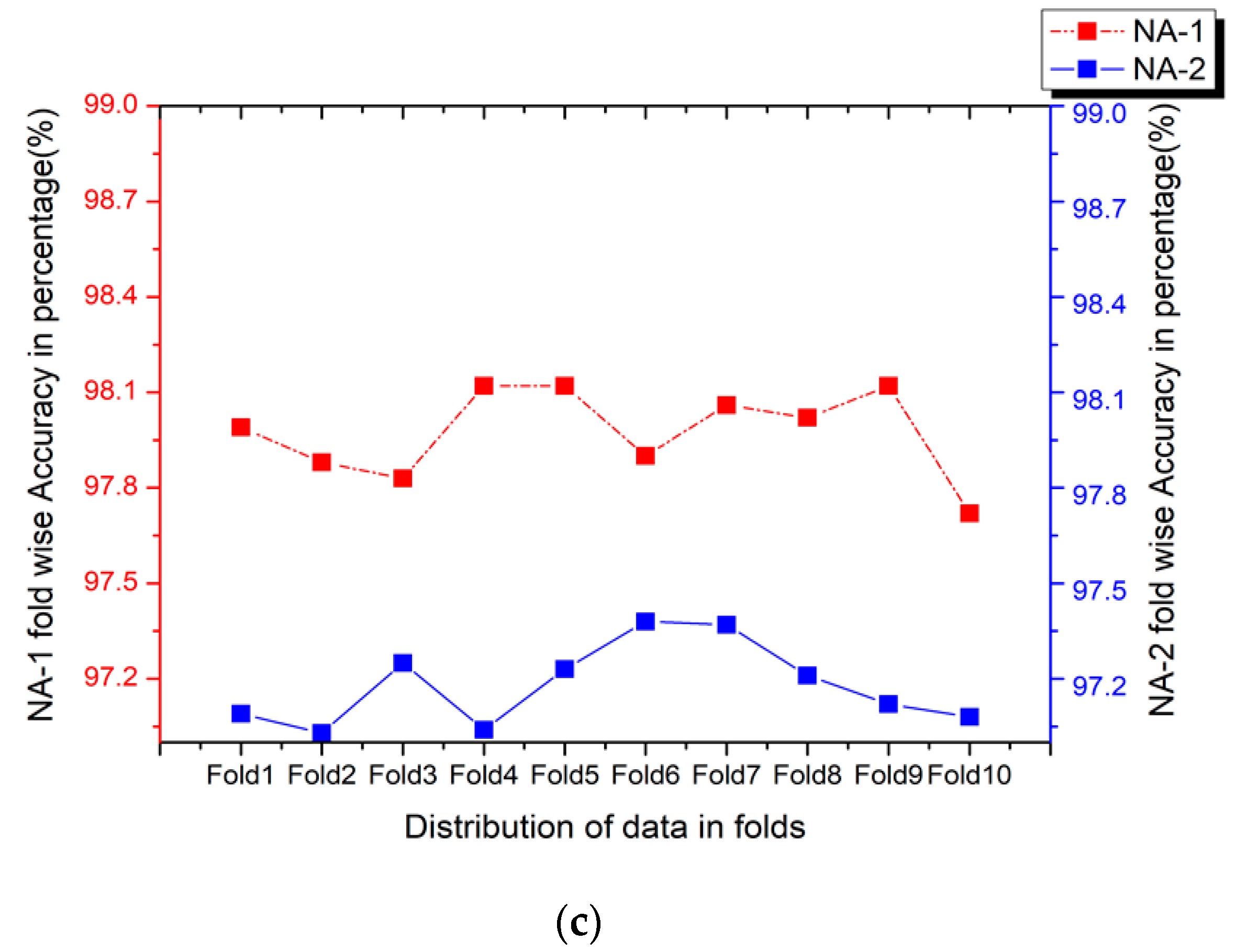
4.4. Performance Evaluation of Proposed New Augmentation Approaches NA-1 and NA-2
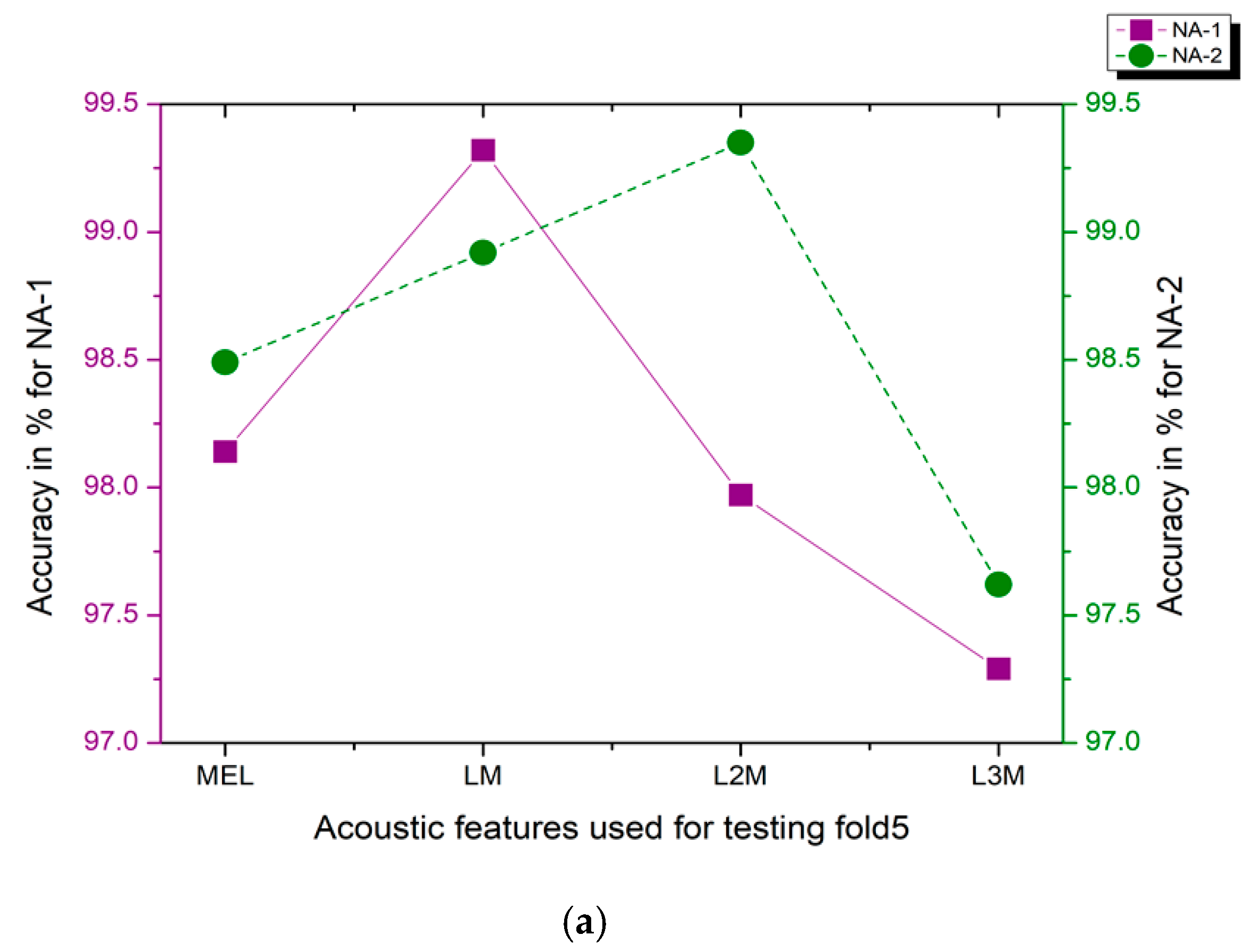
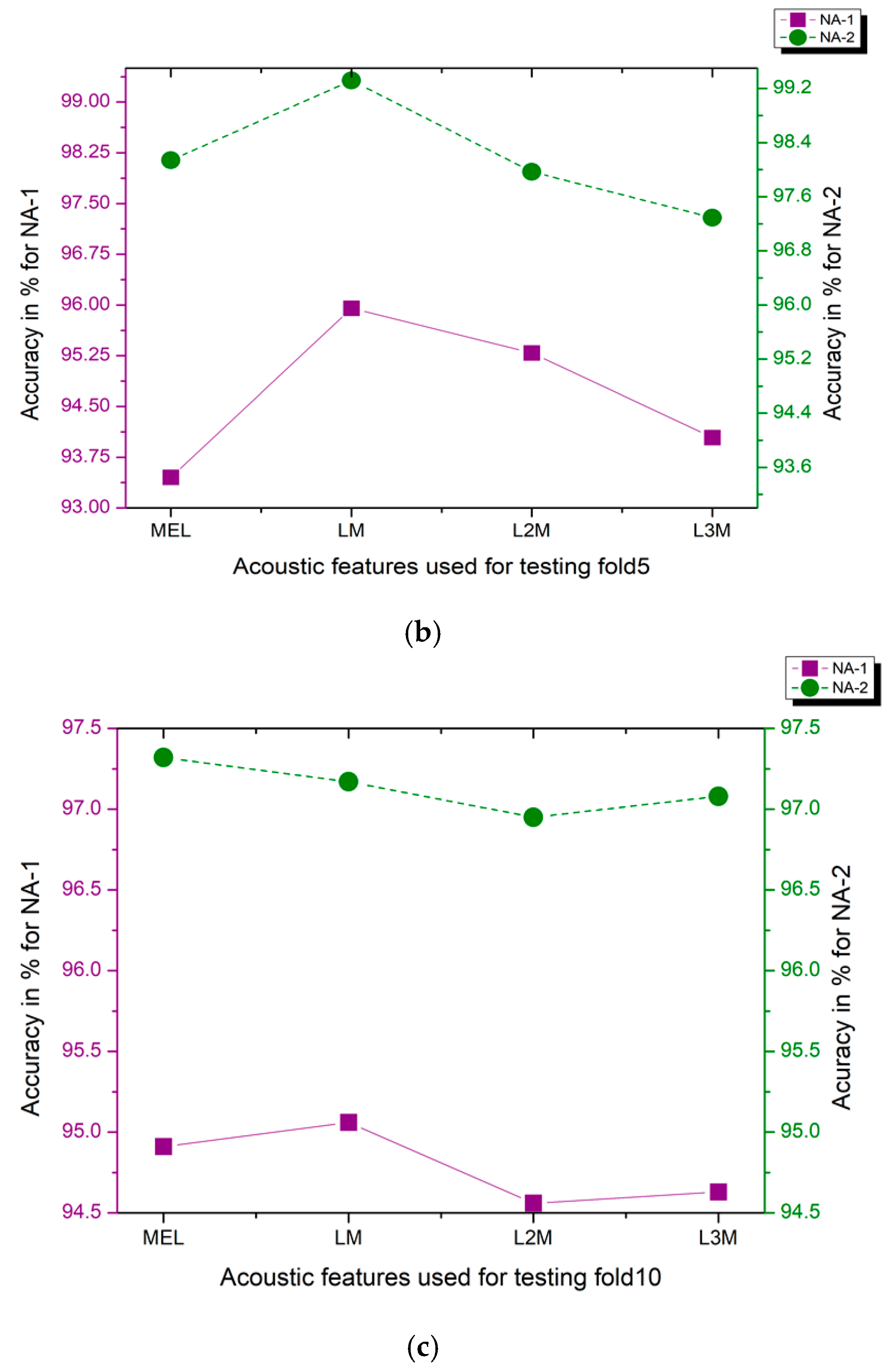
4.5. Performance Assessment of Proposed New Augmentation Approaches NA-1 and NA-2 on Real-Time Audio Data
4.6. Comparison and Analysis of Results with Previous and Baseline Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lv, T.; Zhang, H.Y.; Yan, C.H. Double mode surveillance system based on remote audio/video signals acquisition. Appl. Acoust. 2018, 129, 316–321. [Google Scholar] [CrossRef]
- Rabaoui, A.; Davy, M.; Rossignol, S.; Ellouze, N. Using one-class SVMs and wavelets for audio surveillance. IEEE Trans. Inf. Forensics Secur. 2008, 3, 763–775. [Google Scholar] [CrossRef]
- Intani, P.; Orachon, T. Crime warning system using image and sound processing. In Proceedings of the International Conference on Control, Automation and Systems (ICCAS 2013), Gwangju, Korea, 20–23 October 2013; pp. 1751–1753. [Google Scholar]
- Alsouda, Y.; Pllana, S.; Kurti, A. A Machine Learning Driven IoT Solution for Noise Classification in Smart Cities. In Proceedings of the 21st Euromicro Conference on Digital System Design (DSD 2018), Workshop on Machine Learning Driven Technologies and Architectures for Intelligent Internet of Things (ML-IoT), Prague, Czech Republic, 29–31 August 2018; pp. 1–6. [Google Scholar]
- Steinle, S.; Reis, S.; Sabel, C.E. Quantifying human exposure to air pollution-Moving from static monitoring to spatio-temporally resolved personal exposure assessment. Sci. Total Environ. 2013, 443, 184–193. [Google Scholar] [CrossRef] [PubMed]
- Chacón-Rodríguez, A.; Julián, P.; Castro, L.; Alvarado, P.; Hernández, N. Evaluation of gunshot detection algorithms. IEEE Trans. Circuits Syst. I Regul. Pap. 2011, 58, 363–373. [Google Scholar] [CrossRef]
- Vacher, M.; Istrate, D.; Besacier, L.; Serignat, J.; Castelli, E. Sound Detection and Classification for Medical Telesurvey. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014. [Google Scholar]
- Bhuiyan, M.Y.; Bao, J.; Poddar, B.; Giurgiutiu, V. Toward identifying crack-length-related resonances in acoustic emission waveforms for structural health monitoring applications. Struct. Health Monit. 2018, 17, 577–585. [Google Scholar] [CrossRef]
- Lee, C.H.; Chou, C.H.; Han, C.C.; Huang, R.Z. Automatic recognition of animal vocalizations using averaged MFCC and linear discriminant analysis. Pattern Recognit. Lett. 2006, 27, 93–101. [Google Scholar] [CrossRef]
- Weninger, F.; Schuller, B. Audio recognition in the wild: Static and dynamic classification on a real-world database of animal vocalizations. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 337–340. [Google Scholar]
- Lee, C.H.; Han, C.C.; Chuang, C.C. Automatic classification of bird species from their sounds using two-dimensional cepstral coefficients. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 1541–1550. [Google Scholar] [CrossRef]
- Baum, E.; Harper, M.; Alicea, R.; Ordonez, C. Sound identification for fire-fighting mobile robots. In Proceedings of the 2018 Second IEEE International Conference on Robotic Computing (IRC), Laguna Hills, CA, USA, 31 January–2 February 2018; Volume 2018, pp. 79–86. [Google Scholar]
- Ciaburro, G. Sound event detection in underground parking garage using convolutional neural network. Big Data Cogn. Comput. 2020, 4, 20. [Google Scholar] [CrossRef]
- Ciaburro, G.; Iannace, G. Improving Smart Cities Safety Using Sound Events Detection Based on Deep Neural Network Algorithms. Informatics 2020, 7, 23. [Google Scholar] [CrossRef]
- Sigtia, S.; Stark, A.M.; Krstulović, S.; Plumbley, M.D. Automatic Environmental Sound Recognition: Performance Versus Computational Cost. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2096–2107. [Google Scholar] [CrossRef]
- Sun, L.; Gu, T.; Xie, K.; Chen, J. Text-independent speaker identification based on deep Gaussian correlation supervector. Int. J. Speech Technol. 2019, 22, 449–457. [Google Scholar] [CrossRef]
- Costa, Y.M.G.; Oliveira, L.S.; Silla, C.N. An evaluation of Convolutional Neural Networks for music classification using spectrograms. Appl. Soft Comput. J. 2017, 52, 28–38. [Google Scholar] [CrossRef]
- Phan, H.; Hertel, L.; Maass, M.; Mazur, R.; Mertins, A. Learning representations for nonspeech audio events through their similarities to speech patterns. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 807–822. [Google Scholar] [CrossRef]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V. Audio surveillance: A systematic review. ACM Comput. Surv. 2016, 48. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Probabilistic novelty detection for acoustic surveillance under real-world conditions. IEEE Trans. Multimed. 2011, 13, 713–719. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Vuegen, L.; Karsmakers, P.; Vanrumste, B.; Van Hamme, H. An exemplar-based NMF approach to audio event detection. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 20–23 October 2013; pp. 1–4. [Google Scholar]
- Chachada, S.; Kuo, C.C.J. Environmental sound recognition: A survey. APSIPA Trans. Signal Inf. Process. 2014, 3, 1–15. [Google Scholar] [CrossRef]
- Muller, M.; Kurth, F.; Clausen, M. Chroma based statistical audio features for audio matching. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, Bonn, Germany, 16–19 October 2005; pp. 275–278. [Google Scholar]
- Harte, C.; Sandler, M.; Gasser, M. Detecting Harmonic Change in Musical Audio. In Proceedings of the AMCMM’06: The 14th ACM International Conference on Multimedia 2006, Santa Barbara, CA, USA, 23–27 October 2006; pp. 21–25. [Google Scholar]
- Lu, L.; Zhang, H.; Tao, J.; Cui, L.; Jiang, D. Music type classification by spectral contrast feature’. In Proceedings of the IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, 26–29 August 2002; pp. 113–116. [Google Scholar]
- Zhang, Z.; Xu, S.; Cao, S.; Zhang, S. Deep Convolutional Neural Network with mixup for Environmental Sound Classification. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV); Springer: Cham, Switzerland, 2018; Volume 2, pp. 356–367. [Google Scholar]
- Qu, L.; Weber, C.; Wermter, S. LipSound: Neural mel-spectrogram reconstruction for lip reading. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Graz, Austria, 15–19 September 2019; Volume 2019, pp. 2768–2772. [Google Scholar]
- Li, J.; Dai, W.; Metze, F.; Qu, S.; Das, S. A Comparison of Deep Learning methods for Environmental Sound Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 126–130. [Google Scholar]
- Holdsworth, J.; Nimmo-Smith, I. Implementing a gammatone filter bank. SVOS Final Rep. Part A Audit. Filter Bank 1988, 1, 1–5. [Google Scholar]
- Geiger, J.T.; Helwani, K. Improving event detection for audio surveillance using Gabor filterbank features. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 714–718. [Google Scholar]
- Su, Y.; Zhang, K.; Wang, J.; Zhou, D.; Madani, K. Performance analysis of multiple aggregated acoustic features for environment sound classification. Appl. Acoust. 2020, 158, 107050. [Google Scholar] [CrossRef]
- Yu, C.-Y.; Liu, H.; Qi, Z.-M. Sound Event Detection Using Deep Random Forest. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16–17 November 2017; pp. 1–3. [Google Scholar]
- Lavner, Y.; Ruinskiy, D. A decision-tree-based algorithm for speech/music classification and segmentation. Eurasip J. Audio Speech Music Process. 2009, 2009, 1–14. [Google Scholar] [CrossRef]
- Karbasi, M.; Ahadi, S.M.; Bahmanian, M. Environmental sound classification using spectral dynamic features. In Proceedings of the ICICS 2011–8th International Conference on Information, Communications and Signal Processing, Singapore, 13–16 December 2011; pp. 1–5. [Google Scholar]
- Aggarwal, S.; Aggarwal, N. Classification of Audio Data using Support Vector Machine. IJCST 2011, 2, 398–405. [Google Scholar]
- Wang, S.; Tang, Z.; Li, S. Design and implementation of an audio classification system based on SVM. Procedia Eng. 2011, 15, 4031–4035. [Google Scholar]
- Tokozume, Y.; Harada, T. Learning Environmental Sounds With End-to-End Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2721–2725. [Google Scholar]
- Pons, J.; Serra, X. Randomly Weighted CNNs for (music) audio classification. In Proceedings of the 44th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2019), Brighton, UK, 12–17 May 2019; pp. 336–340. [Google Scholar]
- Zhao, H.; Huang, X.; Liu, W.; Yang, L. Environmental sound classification based on feature fusion. In MATEC Web of Conferences; EDP Sciences: Ullis, France, 2018; Volume 173, pp. 1–5. [Google Scholar]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Fault diagnosis for UAV blades using artificial neural network. Robotics 2019, 8, 59. [Google Scholar] [CrossRef]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the MM 2015—Proceedings of the 2015 ACM Multimedia Conference, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Salamon, J.; Jacoby, C.; Bello, J.P. A Dataset and Taxonomy for Urban Sound Research. In Proceedings of the MM ’14 Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1041–1044. [Google Scholar]
- da Silva, B.; Happi, A.W.; Braeken, A.; Touhafi, A. Evaluation of classical Machine Learning techniques towards urban sound recognition on embedded systems. Appl. Sci. 2019, 9, 3885. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental Sound Classification With Convolutional Neural Networks. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015. [Google Scholar]
- Zhou, H.; Song, Y.; Shu, H. Using deep convolutional neural network to classify urban sounds. In Proceedings of the IEEE Region 10 Annual International Conference, Proceedings/TENCON, Penang, Malaysia, 5–8 November 2017; Volume 2017, pp. 3089–3092. [Google Scholar]
- Demir, F.; Abdullah, D.A.; Sengur, A. A New Deep CNN model for Environmental Sound Classification. IEEE Access 2020, 8, 66529–66537. [Google Scholar] [CrossRef]
- Chen, Y.; Guo, Q.; Liang, X.; Wang, J.; Qian, Y. Environmental sound classification with dilated convolutions. Appl. Acoust. 2019, 148, 123–132. [Google Scholar] [CrossRef]
- Hertel, L.; Phan, H.; Mertins, A. Comparing time and frequency domain for audio event recognition using deep learning. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3407–3411. [Google Scholar]
- Pillos, A.; Alghamidi, K.; Alzamel, N.; Pavlov, V.; Machanavajhala, S. A Real-Time Environmental Sound Recognition System for the Android Os. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016, Budapest, Hungary, 8 February–7 September 2016. [Google Scholar]
- Ahmad, S.; Agrawal, S.; Joshi, S.; Taran, S.; Bajaj, V.; Demir, F.; Sengur, A. Environmental sound classification using optimum allocation sampling based empirical mode decomposition. Phys. A Stat. Mech. Appl. 2020, 537, 122613. [Google Scholar] [CrossRef]
- Medhat, F.; Chesmore, D.; Robinson, J. Masked Conditional Neural Networks for sound classification. Appl. Soft Comput. J. 2020, 90, 106073. [Google Scholar] [CrossRef]
- Singh, A.; Rajan, P.; Bhavsar, A. SVD-based redundancy removal in 1-D CNNs for acoustic scene classification. Pattern Recognit. Lett. 2020, 131, 383–389. [Google Scholar] [CrossRef]
- Abdoli, S.; Cardinal, P.; Lameiras Koerich, A. End-to-end environmental sound classification using a 1D convolutional neural network. Expert Syst. Appl. 2019, 136, 252–263. [Google Scholar] [CrossRef]
- Li, X.; Chebiyyam, V.; Kirchhoff, K. Multi-stream network with temporal attention for environmental sound classification. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Graz, Austria, 15–19 September 2019; Volume 2019, pp. 3604–3608. [Google Scholar]
- Ye, J.; Kobayashi, T.; Murakawa, M. Urban sound event classification based on local and global features aggregation. Appl. Acoust. 2017, 117, 246–256. [Google Scholar] [CrossRef]
- Chong, D.; Zou, Y.; Wang, W. Multi-channel Convolutional Neural Networks with Multi-level Feature Fusion for Environmental Sound Classification. In International Conference on Multimedia Modeling; Springer: Cham, Switzerland, 2019; Volume 2, pp. 157–168. [Google Scholar]
- Yang, M.; Yu, L.; Herweg, A. Automated environmental sound recognition for soundscape measurement and assessment. In Proceedings of the INTER-NOISE 2019 MADRID—48th International Congress and Exhibition on Noise Control Engineering, Madrid, Spain, 16–19 June 2019. [Google Scholar]
- Sharma, J.; Granmo, O.-C.; Goodwin, M. Environment Sound Classification using Multiple Feature Channels and Deep Convolutional Neural Networks. J. Latex CL Files 2015, 14, 1–11. [Google Scholar]
- Mushtaq, Z.; Su, S.-F.; Tran, Q.-V. Spectral images based environmental sound classification using CNN with meaningful data augmentation. Appl. Acoust. 2020, 172, 107581. [Google Scholar] [CrossRef]
- Deng, J.D.; Simmermacher, C.; Cranefield, S. A Study on Feature Analysis for Musical Instrument Classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 38, 269–274. [Google Scholar] [CrossRef]
- Bachu, R.G.; Kopparthi, S.; Adapa, B.; Barkana, B.D. Separation of Voiced and Unvoiced using Zero crossing rate and Energy of the Speech Signal. In Proceedings of the American Society for Engineering Education, Tulsa, OK, USA, 17–19 September 2008; pp. 279–282. [Google Scholar]
- Bartsch, M.A.; Wakefield, G.H. Audio Thumbnailing of Popular Music Using Chroma-Based Representations. IEEE Trans. Multimed. 2005, 7, 96–104. [Google Scholar] [CrossRef]
- Nepal, A.; Shah, A.K.; Shrestha, D.C. Chroma Feature Extraction. In Encyclopedia of GIS; Springer: Berlin, Germany, 2019; pp. 1–9. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–24. [Google Scholar]
- J. and Others Howard, “vision.learner|fastai,” GitHub. 2018. Available online: https://docs.fast.ai/vision.learner.html (accessed on 26 February 2020).
- Audacity Team, “Audacity,” Audacity Version 2.3.3. 2008. Available online: https://www.audacityteam.org/ (accessed on 20 February 2020).
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding Transfer Learning for Medical Imaging. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurlPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 1–11. [Google Scholar]
- Arora, P.; Haeb-Umbach, R. A study on transfer learning for acoustic event detection in a real life scenario. In Proceedings of the 2017 IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), Luton, UK, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 2261–2269. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 4, 3320–3328. [Google Scholar]
- George, A.P.; Powell, W.B. Adaptive stepsizes for recursive estimation with applications in approximate dynamic programming. Mach. Learn. 2006, 65, 167–198. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision, WACV 2017, Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp? In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Wang, S.; Pan, B.; Chen, H.; Ji, Q. Thermal augmented expression recognition. IEEE Trans. Cybern. 2018, 48, 2203–2214. [Google Scholar] [CrossRef]
- Luo, J.; Boutell, M.; Gray, R.T.; Brown, C. Image Transform Bootstrapping and Its Applications to Semantic Scene Classification. IEEE Trans. Syst. Man Cybern. B Cybern. 2005, 35, 563–570. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef]
- Demir, F.; Turkoglu, M.; Aslan, M.; Sengur, A. A new pyramidal concatenated CNN approach for environmental sound classification. Appl. Acoust. 2020, 170, 107520. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.F. Environmental sound classification using a regularized deep convolutional neural network with data augmentation. Appl. Acoust. 2020, 167, 107389. [Google Scholar] [CrossRef]
- Boddapati, V.; Petef, A.; Rasmusson, J.; Lundberg, L. Classifying environmental sounds using image recognition networks. Procedia Comput. Sci. 2017, 112, 2048–2056. [Google Scholar] [CrossRef]
- Khamparia, A.; Gupta, D.; Nguyen, N.G.; Khanna, A.; Pandey, B.; Tiwari, P. Sound classification using convolutional neural network and tensor deep stacking network. IEEE Access 2019, 7, 7717–7727. [Google Scholar] [CrossRef]
- Su, Y.; Zhang, K.; Wang, J.; Madani, K. Environment sound classification using a two-stream CNN based on decision-level fusion. Sensors 2019, 19, 1733. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Learning Attentive Representations for Environmental Sound Classification. IEEE Access 2019, 7, 130327–130339. [Google Scholar] [CrossRef]
- Tokozume, Y.; Ushiku, Y.; Harada, T. Learning from Between-class Examples for Deep Sound Recognition. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resemblance Dataset | Total Recordings | Total Classes in Clips | Avg. Length of Audio Clips in Secs |
|---|---|---|---|
| ESC-10 | 80 | 10 | 5~8 |
| ESC-50 | 400 | 50 | 5~8 |
| Us8k | 500 | 10 | 4~9 |
| Aggregation Scheme | Mel | TSLM | WNLM | TSL2M | WNL2M | TSL3M | WNL3M |
|---|---|---|---|---|---|---|---|
| The Accumulated Features Which are Used in the Experiment | |||||||
| Fu1 = Mel ⊕ TSLM | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ |
| Fu2 = Mel ⊕ WNLM | ✓ | ✕ | ✓ | ✕ | ✕ | ✕ | ✕ |
| Fu3= Mel ⊕ TSL2M | ✓ | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ |
| Fu4 = Mel ⊕ WNL2M | ✓ | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ |
| Fu5 = Mel ⊕ TSL3M | ✓ | ✕ | ✕ | ✕ | ✕ | ✓ | ✕ |
| Fu6 = Mel ⊕ WNL3M | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Fu7 = TSLM ⊕ WNLM | ✕ | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ |
| Fu8 = TSL2M ⊕ WNL2M | ✕ | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ |
| Fu9 = TSL3M ⊕ WNL3M | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ | ✓ |
| The Accumulated Features which are not Used in the Experiment | |||||||
| Fnu10 = TSLM ⊕ WNL2M | ✕ | ✓ | ✕ | ✕ | ✓ | ✕ | ✕ |
| Fnu11 = TSLM ⊕ WNL3M | ✕ | ✓ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Fnu12 = TSLM ⊕ TSL2M | ✕ | ✓ | ✕ | ✓ | ✕ | ✕ | ✕ |
| Fnu13 = TSLM ⊕ TSL3M | ✕ | ✓ | ✕ | ✕ | ✕ | ✓ | ✕ |
| Fnu14 = WNLM ⊕ TSL2M | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ | ✕ |
| Fnu15 = WNLM ⊕ WNL2M | ✕ | ✕ | ✓ | ✕ | ✓ | ✕ | ✕ |
| Fnu16 = WNLM ⊕ TSL3M | ✕ | ✕ | ✓ | ✕ | ✕ | ✓ | ✕ |
| Fnu17 = WNLM ⊕ WNL3M | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ | ✓ |
| Fnu18 = TSL2M ⊕ TSL3M | ✕ | ✕ | ✕ | ✓ | ✕ | ✓ | ✕ |
| Fnu19 = TSL2M ⊕ WNL3M | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ | ✓ |
| Fnu20 = WNL2M ⊕ TSL3M | ✕ | ✕ | ✕ | ✕ | ✓ | ✓ | ✕ |
| Fnu21 = WNL2M ⊕ WNL3M | ✕ | ✕ | ✕ | ✕ | ✓ | ✕ | ✓ |
| Acoustic Features | Valid Loss | Error Rate % | ACC % | Kappa Score % | MCC % | PPV % | TPR % | F1 Score % | FNR % | FDR % | FM % | Train Time (m:s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Us8k | ||||||||||||
| Mel | 0.3511 | 11.47 | 88.52 | 84.17 | 87.15 | 89.32 | 89.13 | 89.17 | 10.86 | 10.67 | 89.23 | 84:21 |
| LM | 0.4716 | 15.25 | 84.74 | 79.41 | 82.94 | 85.91 | 85.36 | 85.47 | 14.63 | 14.08 | 85.64 | 84:00 |
| L2M | 0.4819 | 15.45 | 84.54 | 78.84 | 82.71 | 85.61 | 85.27 | 85.34 | 14.72 | 14.38 | 85.44 | 84:00 |
| L3M | 0.5767 | 18.96 | 81.03 | 74.61 | 78.85 | 83.42 | 81.80 | 82.12 | 18.20 | 16.57 | 82.61 | 84:05 |
| (S-C) | 1.439 | 52.63 | 44.77 | 33.10 | 40.90 | 48.47 | 47.11 | 48.25 | 52.88 | 51.52 | 47.78 | 82:45 |
| (Z-C) | 1.765 | 62.46 | 37.53 | 14.27 | 30.06 | 40.00 | 38.24 | 38.58 | 61.75 | 60.00 | 39.11 | 85:58 |
| Tonnetz | 1.850 | 64.24 | 35.75 | 25.95 | 28.15 | 39.01 | 36.24 | 36.76 | 63.75 | 60.98 | 37.87 | 85:32 |
| (C-S) | 1.139 | 38.78 | 61.21 | 54.01 | 56.68 | 62.42 | 62.78 | 62.70 | 37.21 | 37.57 | 62.60 | 85:51 |
| ESC-50 | ||||||||||||
| Mel | 0.5213 | 15.05 | 84.95 | 88.83 | 84.66 | 85.54 | 85.16 | 85.24 | 14.83 | 14.45 | 85.35 | 10:00 |
| LM | 0.8397 | 21.45 | 78.55 | 82.92 | 78.14 | 79.51 | 79.26 | 79.31 | 20.73 | 20.48 | 79.39 | 9:52 |
| L2M | 1.198 | 32.50 | 67.50 | 75.88 | 66.88 | 68.81 | 67.77 | 67.97 | 32.22 | 31.18 | 68.29 | 9:54 |
| L3M | 1.132 | 31.60 | 68.40 | 77.22 | 67.81 | 70.56 | 68.96 | 69.27 | 31.03 | 29.43 | 69.75 | 9:45 |
| (S-C) | 2.179 | 60.30 | 39.70 | 39.56 | 38.58 | 20.63 | 40.33 | 16.53 | 59.66 | 79.36 | 28.85 | 9:52 |
| (Z-C) | 3.167 | 81.40 | 18.60 | 22.55 | 17.07 | 20.34 | 19.35 | 0.000 | 80.64 | 79.65 | 21.11 | 9:55 |
| Tonnetz | 3.128 | 82.75 | 17.25 | 23.69 | 15.75 | 2.948 | 17.54 | 0.000 | 82.45 | 97.05 | 7.192 | 9:48 |
| (C-S) | 2.261 | 62.45 | 37.55 | 46.79 | 36.43 | 40.68 | 38.23 | 38.69 | 61.76 | 59.31 | 39.44 | 9:55 |
| ESC-10 | ||||||||||||
| Mel | 0.5169 | 18.75 | 81.25 | 88.43 | 79.23 | 80.31 | 79.46 | 79.62 | 20.53 | 19.68 | 79.88 | 2:20 |
| LM | 1.058 | 28.75 | 71.25 | 75.92 | 68.57 | 70.78 | 75.47 | 74.46 | 24.52 | 29.21 | 73.09 | 2:23 |
| L2M | 0.5670 | 20.00 | 80.00 | 77.94 | 77.92 | 80.07 | 79.49 | 79.59 | 20.51 | 19.92 | 79.83 | 2:20 |
| L3M | 0.6058 | 17.50 | 82.50 | 79.55 | 80.70 | 82.27 | 82.83 | 82.71 | 17.16 | 17.72 | 82.55 | 2:20 |
| (S-C) | 1.741 | 58.75 | 41.25 | 46.85 | 35.37 | 41.56 | 41.45 | 34.01 | 58.54 | 58.43 | 41.51 | 2:20 |
| (Z-C) | 2.031 | 67.75 | 32.25 | 37.48 | 25.54 | 32.62 | 34.34 | 26.33 | 65.65 | 67.37 | 33.47 | 2:20 |
| Tonnetz | 1.944 | 63.00 | 37.00 | 35.06 | 30.94 | 37.18 | 37.67 | 37.40 | 62.32 | 62.81 | 37.42 | 2:20 |
| (C-S) | 1.403 | 50.25 | 49.75 | 47.47 | 45.04 | 40.45 | 49.88 | 40.40 | 50.11 | 59.54 | 44.92 | 2:20 |
| Acoustic Features | Valid Loss | Error Rate % | ACC % | Kappa Score % | MCC % | PPV % | TPR % | F1 Score % | FNR % | FDR % | FM % | Train Time (m:s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Us8k | ||||||||||||
| Mel | 0.1118 | 3.705 | 96.29 | 94.74 | 95.85 | 96.58 | 96.49 | 96.51 | 3.507 | 3.420 | 96.53 | 241:09 |
| LM | 0.1173 | 3.854 | 96.14 | 94.51 | 95.68 | 96.40 | 96.33 | 96.34 | 3.666 | 3.595 | 96.36 | 241:30 |
| L2M | 0.1719 | 5.618 | 94.38 | 92.62 | 93.71 | 94.87 | 94.54 | 94.61 | 5.452 | 5.128 | 94.70 | 241:57 |
| L3M | 0.2104 | 6.672 | 93.32 | 91.91 | 92.53 | 93.81 | 93.64 | 93.67 | 6.357 | 6.187 | 93.72 | 239:03 |
| (S-C) | 0.7624 | 26.29 | 73.70 | 66.24 | 70.59 | 75.73 | 74.83 | 75.00 | 25.16 | 24.26 | 75.28 | 246:06 |
| (Z-C) | 1.440 | 53.05 | 46.94 | 27.36 | 40.60 | 50.31 | 47.14 | 47.74 | 52.85 | 49.68 | 48.70 | 243:11 |
| Tonnetz | 1.282 | 45.25 | 54.74 | 46.05 | 49.36 | 57.62 | 55.76 | 56.12 | 44.23 | 42.37 | 56.68 | 243:36 |
| (C-S) | 0.5843 | 19.52 | 80.47 | 75.22 | 78.17 | 81.66 | 81.43 | 81.47 | 18.56 | 18.33 | 81.54 | 242:02 |
| ESC-50 | ||||||||||||
| Mel | 0.4028 | 11.75 | 88.25 | 92.79 | 88.02 | 88.21 | 88.37 | 88.33 | 11.62 | 11.78 | 88.29 | 27:49 |
| LM | 0.5662 | 14.40 | 85.60 | 89.77 | 85.32 | 86.46 | 86.55 | 86.53 | 13.44 | 13.53 | 86.51 | 27:40 |
| L2M | 1.037 | 27.45 | 72.55 | 81.21 | 72.01 | 72.80 | 72.93 | 72.90 | 27.06 | 27.19 | 72.86 | 27:31 |
| L3M | 0.9979 | 26.80 | 73.20 | 80.94 | 72.68 | 74.14 | 73.82 | 73.88 | 26.17 | 25.85 | 74.01 | 27:34 |
| (S-C) | 1.999 | 53.20 | 46.80 | 50.90 | 45.78 | 48.34 | 47.58 | 47.72 | 52.41 | 51.65 | 47.96 | 28:03 |
| (Z-C) | 3.309 | 78.95 | 21.05 | 26.65 | 19.53 | 20.42 | 21.69 | 16.94 | 78.30 | 79.57 | 21.05 | 28:05 |
| Tonnetz | 3.225 | 78.70 | 21.30 | 35.05 | 19.76 | 23.37 | 21.46 | 21.80 | 78.53 | 76.62 | 22.40 | 27:46 |
| (C-S) | 2.186 | 57.00 | 43.00 | 53.15 | 41.91 | 44.73 | 44.22 | 44.32 | 55.77 | 55.26 | 44.48 | 28:00 |
| ESC-10 | ||||||||||||
| Mel | 0.3925 | 10.25 | 89.75 | 90.21 | 88.70 | 90.13 | 89.72 | 89.80 | 10.27 | 9.861 | 89.93 | 6:12 |
| LM | 0.7774 | 18.95 | 81.04 | 85.72 | 78.53 | 81.99 | 83.48 | 83.16 | 16.51 | 18.00 | 82.73 | 6:37 |
| L2M | 0.2814 | 9.750 | 90.25 | 90.38 | 89.20 | 90.79 | 90.14 | 90.26 | 9.858 | 9.206 | 90.46 | 6:30 |
| L3M | 0.3445 | 8.000 | 92.00 | 91.47 | 91.12 | 91.45 | 91.87 | 91.78 | 8.126 | 8.547 | 91.66 | 6:30 |
| (S-C) | 1.079 | 29.50 | 70.50 | 77.92 | 67.58 | 72.68 | 68.45 | 69.24 | 31.54 | 27.31 | 70.53 | 6:30 |
| (Z-C) | 1.809 | 51.75 | 48.25 | 41.39 | 42.88 | 50.54 | 49.29 | 49.53 | 50.70 | 49.45 | 49.91 | 6:28 |
| Tonnetz | 1.610 | 44.00 | 56.00 | 56.02 | 51.55 | 60.19 | 55.97 | 56.75 | 44.02 | 39.80 | 58.04 | 6:28 |
| (C-S) | 1.195 | 28.00 | 72.00 | 72.52 | 69.00 | 73.17 | 70.78 | 71.24 | 29.21 | 26.82 | 71.97 | 6:29 |
| Features Aggregation | Valid Loss | Error Rate % | ACC % | Kappa Score % | MCC % | PPV % | TPR % | F1 Score % | FNR % | FDR % | FM % | Train Time (m:s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Us8k | ||||||||||||
| M-NC | 0.1338 | 4.215 | 95.78 | 94.15 | 95.28 | 96.10 | 95.96 | 95.99 | 4.036 | 3.891 | 96.03 | 205:15 |
| LM-NC | 0.1382 | 4.473 | 95.52 | 93.93 | 94.99 | 95.82 | 95.66 | 95.69 | 4.333 | 4.177 | 95.74 | 203:54 |
| C-NC | 0.8229 | 33.23 | 71.80 | 67.20 | 68.73 | 73.71 | 72.72 | 72.91 | 27.27 | 26.28 | 73.21 | 201:44 |
| S-NC | 1.240 | 43.31 | 56.68 | 45.93 | 51.60 | 60.17 | 57.35 | 57.89 | 42.64 | 39.82 | 58.75 | 202:27 |
| M-LM-NC | 0.1873 | 6.002 | 93.99 | 91.38 | 93.28 | 94.30 | 94.23 | 94.24 | 5.770 | 5.691 | 94.27 | 204:50 |
| M-S-NC | 0.9629 | 34.06 | 65.93 | 56.23 | 61.95 | 67.78 | 67.89 | 67.86 | 32.10 | 32.21 | 67.83 | 207:01 |
| LM-C-NC | 0.6545 | 22.64 | 77.35 | 72.02 | 74.69 | 79.11 | 78.38 | 78.53 | 21.61 | 20.88 | 78.75 | 201:34 |
| ESC-50 | ||||||||||||
| M-NC | 0.6434 | 17.10 | 82.90 | 87.90 | 82.56 | 83.70 | 83.85 | 83.82 | 16.14 | 16.29 | 83.78 | 23:22 |
| LM-NC | 0.7150 | 19.30 | 80.70 | 86.91 | 80.33 | 81.81 | 81.35 | 81.44 | 18.64 | 18.18 | 81.58 | 23:22 |
| C-NC | 2.558 | 61.70 | 38.30 | 46.88 | 37.12 | 39.08 | 39.52 | 39.43 | 60.47 | 60.91 | 39.30 | 23:24 |
| S-NC | 2.444 | 61.65 | 38.35 | 46.01 | 37.18 | 39.62 | 38.85 | 38.99 | 61.14 | 60.37 | 39.24 | 23:21 |
| M-LM-NC | 1.043 | 29.25 | 70.75 | 78.65 | 70.18 | 71.71 | 71.88 | 71.84 | 28.11 | 28.29 | 71.79 | 23:18 |
| M-S-NC | 0.9807 | 26.75 | 73.25 | 82.51 | 72.72 | 74.13 | 73.37 | 73.52 | 26.62 | 25.86 | 73.75 | 23:13 |
| LM-C-NC | 1.121 | 30.50 | 69.50 | 77.57 | 68.92 | 69.88 | 69.00 | 69.17 | 30.99 | 30.11 | 69.44 | 23:18 |
| ESC-10 | ||||||||||||
| M-NC | 0.3537 | 7.75 | 92.25 | 92.60 | 91.45 | 93.47 | 91.95 | 92.24 | 8.048 | 6.523 | 92.71 | 5:47 |
| LM-NC | 0.2889 | 8.00 | 92.00 | 94.92 | 91.06 | 92.95 | 92.47 | 92.56 | 7.523 | 7.042 | 92.71 | 5:40 |
| C-NC | 0.3897 | 12.75 | 87.25 | 87.91 | 86.00 | 88.04 | 87.87 | 87.90 | 12.12 | 11.95 | 87.96 | 5:42 |
| S-NC | 0.7294 | 19.00 | 81.00 | 82.63 | 79.01 | 84.00 | 81.51 | 81.98 | 18.48 | 15.99 | 82.74 | 5:46 |
| M-LM-NC | 0.2146 | 5.50 | 94.50 | 96.54 | 93.93 | 94.64 | 94.43 | 94.47 | 5.564 | 5.358 | 94.53 | 4:22 |
| M-S-NC | 0.5476 | 15.50 | 84.50 | 84.87 | 83.02 | 85.86 | 84.82 | 85.02 | 15.17 | 14.13 | 85.34 | 4:15 |
| LM-C-NC | 0.5617 | 15.00 | 85.00 | 84.01 | 83.34 | 85.15 | 84.41 | 84.55 | 15.58 | 14.84 | 84.78 | 4:30 |
| Acoustic Features Augment | Valid Loss | Error Rate % | ACC % | Kappa Score % | MCC % | PPV % | TPR % | F1 Score % | FNR % | FDR % | FM % | Train Time (m:s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Us8k | ||||||||||||
| NA-1 | 0.0591 | 2.018 | 97.98 | 97.09 | 97.73 | 98.14 | 98.13 | 98.13 | 1.863 | 1.854 | 98.14 | 967:51 |
| NA-2 | 0.0820 | 2.814 | 97.18 | 96.19 | 96.84 | 97.40 | 97.32 | 97.34 | 2.674 | 2.597 | 97.36 | 2228:5 |
| ESC-50 | ||||||||||||
| NA-1 | 0.1005 | 2.950 | 97.05 | 97.46 | 96.99 | 97.09 | 97.15 | 97.14 | 2.842 | 2.901 | 97.12 | 110:00 |
| NA-2 | 0.0470 | 1.476 | 98.52 | 98.95 | 98.49 | 98.57 | 98.53 | 98.53 | 1.469 | 1.469 | 98.55 | 134:18 |
| ESC-10 | ||||||||||||
| NA-1 | 0.0444 | 1.285 | 98.71 | 98.23 | 98.57 | 98.74 | 98.75 | 98.75 | 1.243 | 1.250 | 98.75 | 37:41 |
| NA-2 | 0.0281 | 0.777 | 99.22 | 98.93 | 99.13 | 99.24 | 99.25 | 99.25 | 0.744 | 0.758 | 99.24 | 50:00 |
| Acoustic Features Approach | Valid Loss | Error Rate % | ACC % | Kappa Score % | MCC % | PPV % | TPR % | F1 Score % | FNR % | FDR % | FM % | Train Time (m:s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Us8k(NA-1) | ||||||||||||
| MEL | 0.1456 | 5.083 | 94.91 | 92.86 | 94.31 | 95.42 | 95.03 | 95.11 | 4.966 | 4.579 | 95.22 | 133:17 |
| LM | 0.1407 | 4.931 | 95.06 | 93.22 | 94.48 | 95.48 | 95.41 | 95.42 | 4.587 | 4.519 | 95.44 | 132:53 |
| L2M | 0.1499 | 5.433 | 94.63 | 92.23 | 93.92 | 95.03 | 94.91 | 94.94 | 5.080 | 4.965 | 94.97 | 132:08 |
| L3M | 0.1491 | 5.361 | 94.63 | 93.08 | 94.00 | 95.10 | 94.92 | 94.95 | 5.077 | 4.895 | 95.01 | 132:59 |
| Us8k(NA-2) | ||||||||||||
| MEL | 0.0817 | 2.676 | 97.32 | 96.44 | 97.00 | 97.50 | 97.49 | 97.49 | 2.504 | 2.490 | 97.52 | 200:20 |
| LM | 0.0796 | 2.823 | 97.17 | 96.22 | 96.83 | 97.39 | 97.31 | 97.33 | 2.688 | 2.607 | 97.35 | 201:55 |
| L2M | 9.294 | 3.046 | 96.95 | 96.16 | 96.58 | 97.00 | 97.08 | 97.07 | 2.911 | 2.998 | 97.04 | 173:19 |
| L3M | 9.031 | 2.913 | 97.08 | 96.13 | 96.73 | 97.29 | 97.14 | 97.18 | 2.851 | 2.708 | 97.22 | 172:38 |
| ESC-50(NA-1) | ||||||||||||
| MEL | 0.2481 | 6.544 | 93.45 | 94.60 | 93.32 | 93.62 | 93.56 | 93.58 | 6.436 | 6.376 | 93.59 | 16:30 |
| LM | 15.57 | 4.041 | 95.95 | 95.73 | 95.87 | 96.01 | 95.75 | 95.80 | 4.240 | 3.989 | 95.88 | 16:29 |
| L2M | 0.1906 | 4.705 | 95.29 | 96.72 | 95.20 | 95.30 | 95.31 | 95.31 | 4.696 | 4.691 | 95.32 | 16:39 |
| L3M | 0.2046 | 5.955 | 94.04 | 94.33 | 93.92 | 94.12 | 93.95 | 93.98 | 6.049 | 5.873 | 94.04 | 16:46 |
| ESC-50(NA-2) | ||||||||||||
| MEL | 0.1123 | 3.000 | 97.00 | 97.06 | 96.94 | 97.17 | 97.01 | 97.04 | 2.986 | 2.827 | 97.09 | 19:38 |
| LM | 0.1124 | 3.000 | 97.00 | 97.47 | 96.94 | 97.11 | 97.03 | 97.05 | 2.964 | 2.886 | 97.07 | 19:46 |
| L2M | 0.1560 | 3.937 | 96.06 | 97.15 | 95.98 | 96.28 | 96.13 | 96.17 | 3.863 | 3.710 | 96.21 | 19:28 |
| L3M | 0.1411 | 3.625 | 96.37 | 96.84 | 96.30 | 96.27 | 96.37 | 96.35 | 3.628 | 3.725 | 96.32 | 19:23 |
| ESC-10(NA-1) | ||||||||||||
| MEL | 0.0540 | 1.508 | 98.49 | 98.19 | 98.32 | 98.70 | 98.56 | 98.58 | 1.439 | 1.299 | 98.63 | 5:26 |
| LM | 0.0310 | 1.077 | 98.92 | 97.66 | 98.80 | 98.98 | 98.87 | 98.90 | 1.121 | 1.012 | 98.93 | 5:25 |
| L2M | 0.0366 | 0.646 | 99.35 | 99.86 | 99.28 | 99.34 | 99.37 | 99.36 | 0.630 | 0.658 | 99.35 | 8:25 |
| L3M | 0.0863 | 2.370 | 97.62 | 96.69 | 97.36 | 97.65 | 97.74 | 97.72 | 2.253 | 2.340 | 97.69 | 6:38 |
| ESC-10(NA-2) | ||||||||||||
| MEL | 0.0472 | 1.858 | 98.14 | 97.22 | 97.93 | 98.13 | 98.20 | 98.19 | 1.793 | 1.860 | 98.17 | 8:15 |
| LM | 0.0271 | 0.675 | 99.32 | 99.36 | 99.24 | 99.31 | 99.35 | 99.34 | 0.650 | 0.684 | 99.33 | 8:15 |
| L2M | 0.0528 | 2.030 | 97.97 | 98.36 | 97.75 | 98.06 | 97.96 | 97.98 | 2.050 | 1.932 | 98.01 | 8:15 |
| L3M | 0.0655 | 2.702 | 97.29 | 96.02 | 97.00 | 97.27 | 97.30 | 97.29 | 2.703 | 2.726 | 97.28 | 8:15 |
| Methodologies/Models | [References] Year | ACC on ESC-10 in % | ACC on ESC-50 in % | ACC on Us8k in % |
|---|---|---|---|---|
| Results of human accuracy on used datasets | ||||
| Human Accuracy | [41] 2015 | 95.7 | 81.3 | |
| Results of Baseline models on used datasets | ||||
| CNN | [44] 2015 | 80.5 | 64.9 | 73.7 |
| Ensemble (Random forest) | [41] 2015 | 72.7 | 44.3 | |
| Results of other’s methodologies related to spectrogram images | ||||
| Spectrogram Images (combined features + GoogleNet) | [83] 2017 | 91.0 | 73.0 | 93.0 |
| Spectrogram Images (CNN + TDSN) | [84] 2019 | 56.0 | 49.0 | |
| Results of other’s methodologies related features accumulation | ||||
| M-LM-C | [31] 2020 | 85.6 | 93.4 | |
| TSCNN-DS | [85] 2019 | 97.2 | ||
| Results of this study single features best results | ||||
| DenseNet-161 (Strategy-2) Mel spectrogram | This study 2020 | 88.25 | 96.29 | |
| DenseNet-161 (Strategy-2) L3M | This study 2020 | 92.00 | ||
| Results of this study aggregated features best results | ||||
| M-NC (Strategy-2) | This study 2020 | 82.90 | 95.78 | |
| M-LM-NC (Strategy-2) | This study 2020 | 94.50 | ||
| Results of this study proposed augmentation approach best results | ||||
| Proposed NA-1 (DenseNet-161) Strategy-2 | This study 2020 | 98.71 | 97.05 | 97.98 |
| Proposed NA-2 (DenseNet-161) Strategy-2 | This study 2020 | 99.22 | 98.52 | 97.18 |
| Methodologies/Models | [References] Year | ACC on ESC-10 in % | ACC on ESC-50 in % | ACC on Us8k in % |
|---|---|---|---|---|
| Audio-Based Data Augmentation Methodologies | ||||
| DCNN + Augmentation | [86] 2017 | 79.0 | ||
| CNN + Augmentation + Mix-up | [26] 2018 | 91.7 | 94.9 | 78.3 |
| EnvNet-V2 + Augmentation | [88] 2018 | 91.7 | 94.9 | 78.3 |
| CNN + Augmentation | [87] 2019 | 94.2 | 86.5 | |
| DCNN (no max-pool) + Log-Mel + Augmentation | [82] 2020 | 94.9 | 86.5 | 86.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mushtaq, Z.; Su, S.-F. Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry 2020, 12, 1822. https://doi.org/10.3390/sym12111822
Mushtaq Z, Su S-F. Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry. 2020; 12(11):1822. https://doi.org/10.3390/sym12111822
Chicago/Turabian StyleMushtaq, Zohaib, and Shun-Feng Su. 2020. "Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images" Symmetry 12, no. 11: 1822. https://doi.org/10.3390/sym12111822
APA StyleMushtaq, Z., & Su, S.-F. (2020). Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry, 12(11), 1822. https://doi.org/10.3390/sym12111822