The Use of a Hidden Mixture Transition Distribution Model in Clustering Few but Long Continuous Sequences: An Illustration with Cognitive Skills Data



Abstract
1. Introduction
2. Data
2.1. Participants
2.2. Perceptual-Motor Skills
2.3. Other Covariates
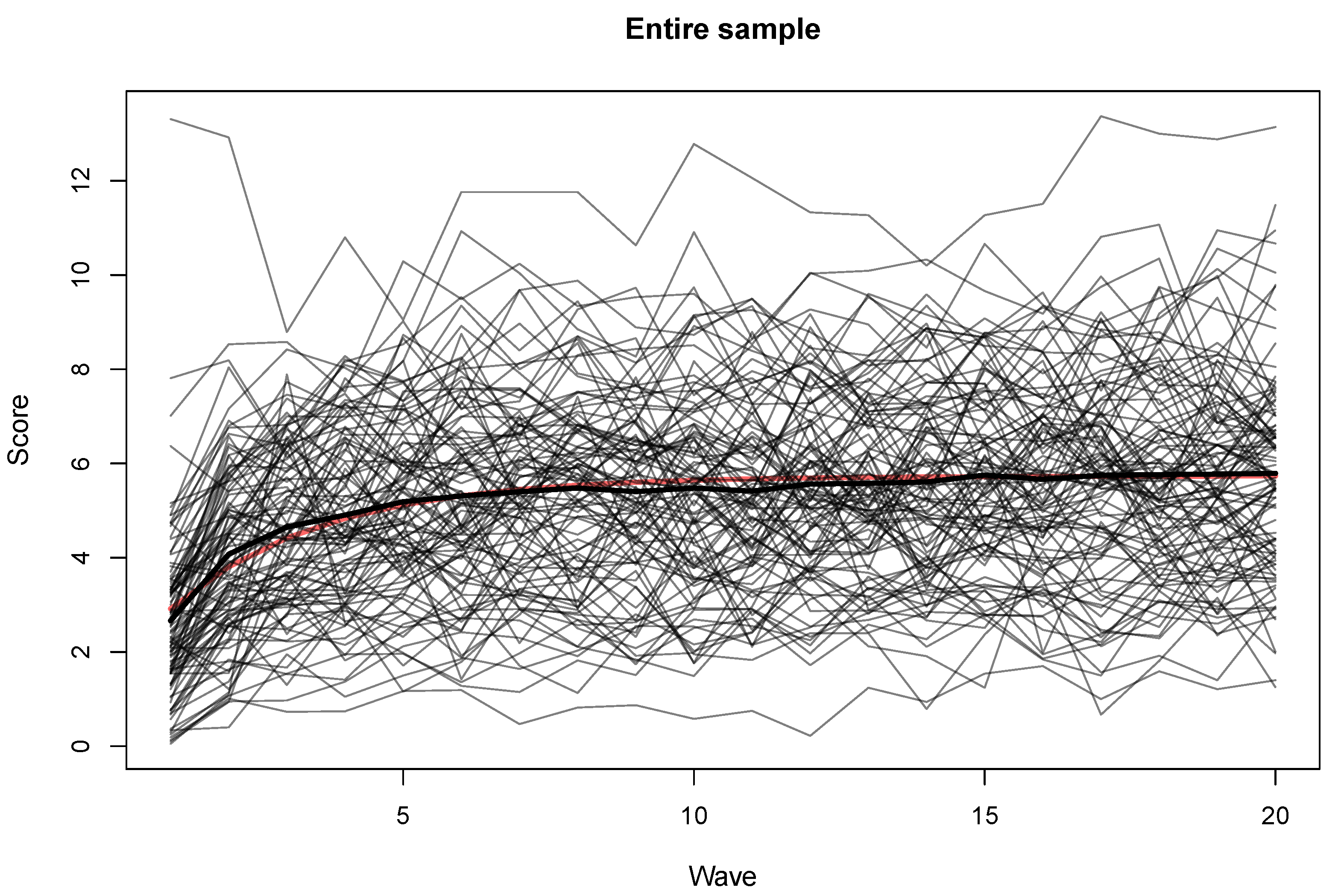
2.4. Data Characteristics and Change Functions
3. Clustering Models
3.1. Growth Models and the Growth Mixture Model (Gmm)
3.2. Residual-Based Approach (Marcoulides and Trinchera)
- a common growth model is fitted to the entire sample;
- individual case residuals from the common growth model are calculated;
- these residuals are clustered using a hierarchical algorithm;
- the user determines the number k of latent classes based on the hierarchical clustering dendrogram and related output;
- the individuals are assigned to one of the k latent classes;
- the k latent classes are treated separately and a common growth model is fitted to each;
- the distances between each individual sequence and each of the k local growth models are computed and compared;
- each individual is assigned to its closest local growth model (cluster);Steps 6 to 8 are iterated until convergence criterion is met (i.e., no more cluster switching or a maximal number of iterations); and,
- an average growth trajectory (and its parameters) for each cluster is computed.
3.3. HMTD
3.4. Underlying Assumptions and Distinction between the 3 Models
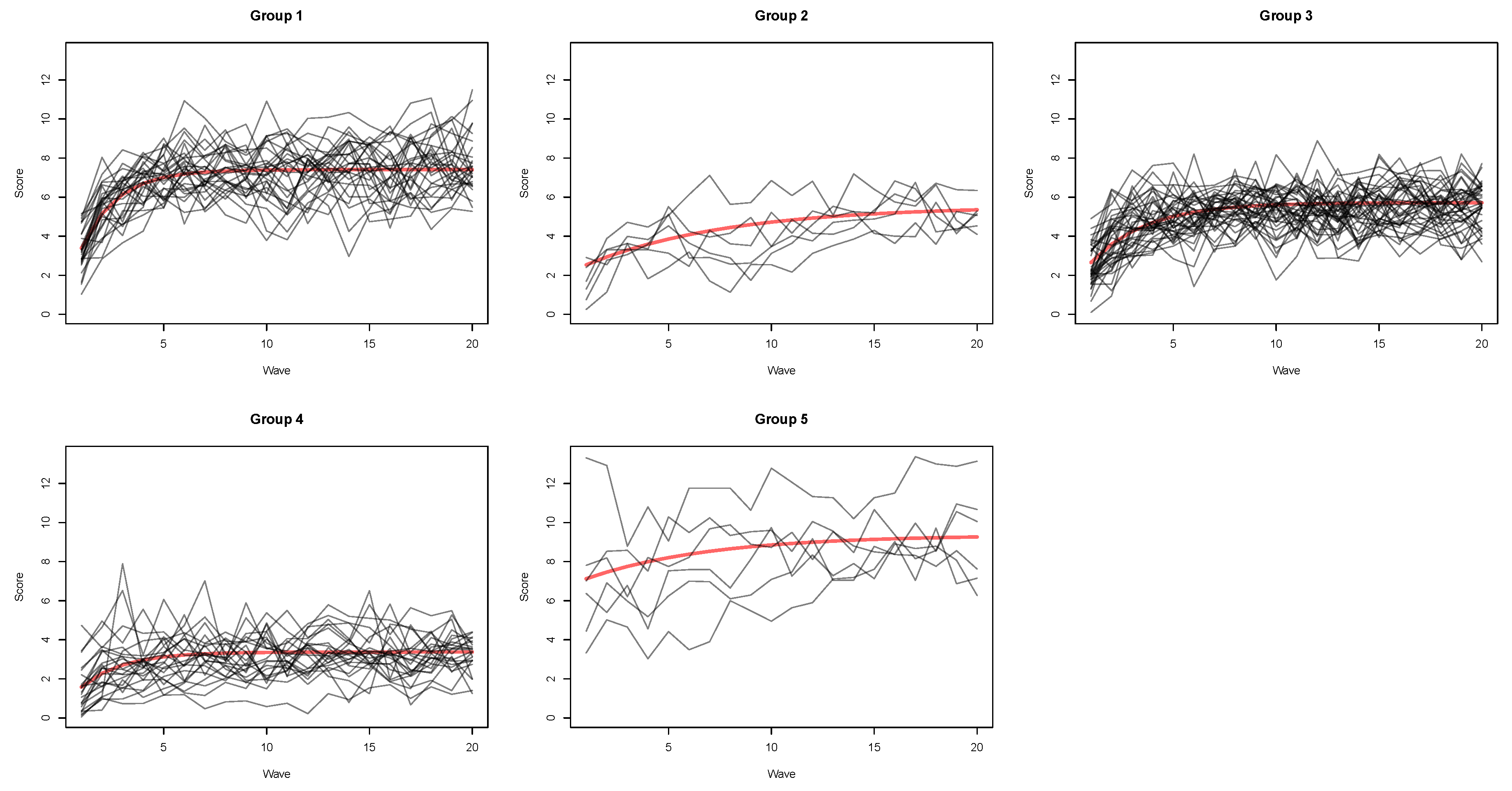
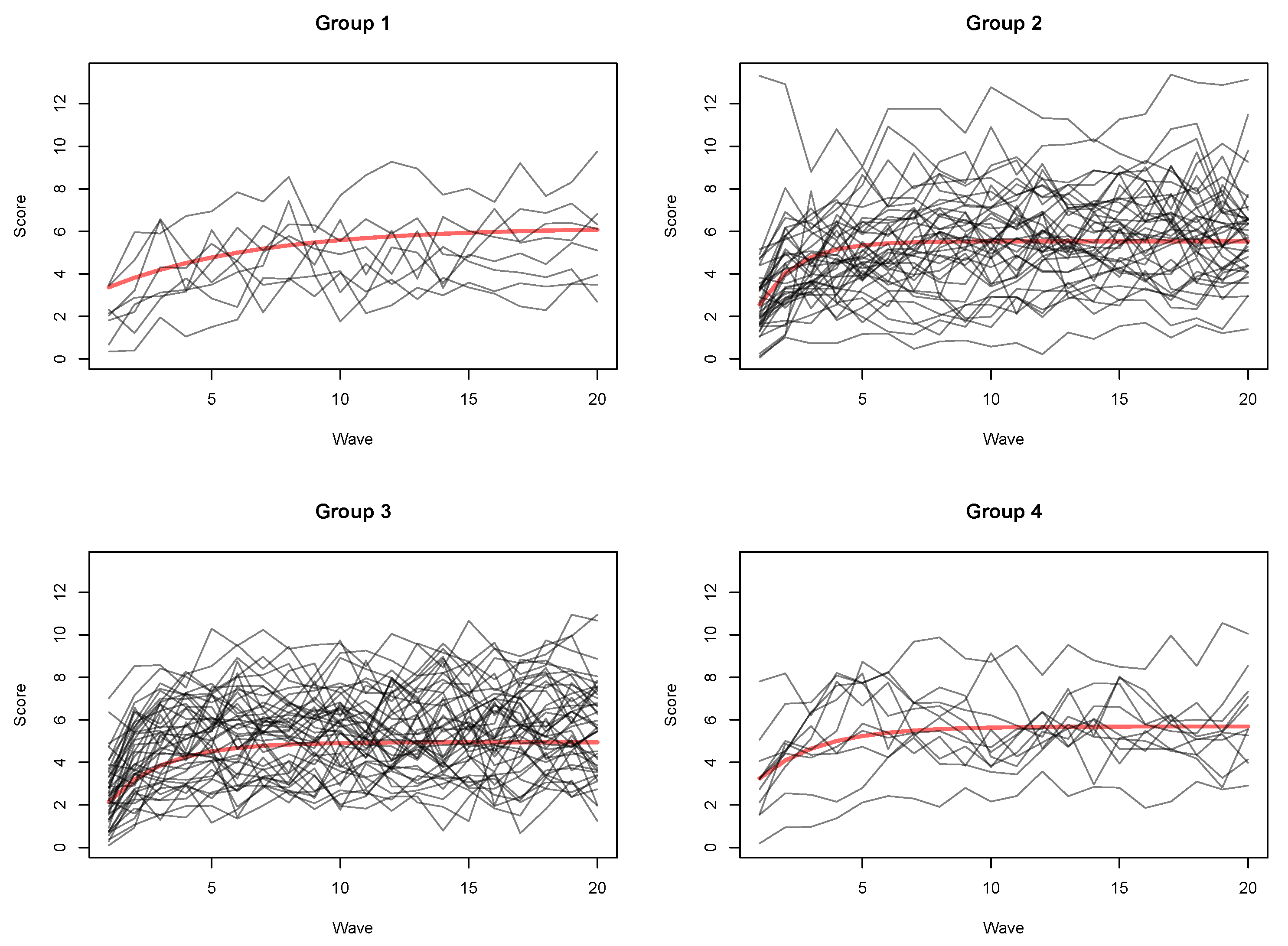
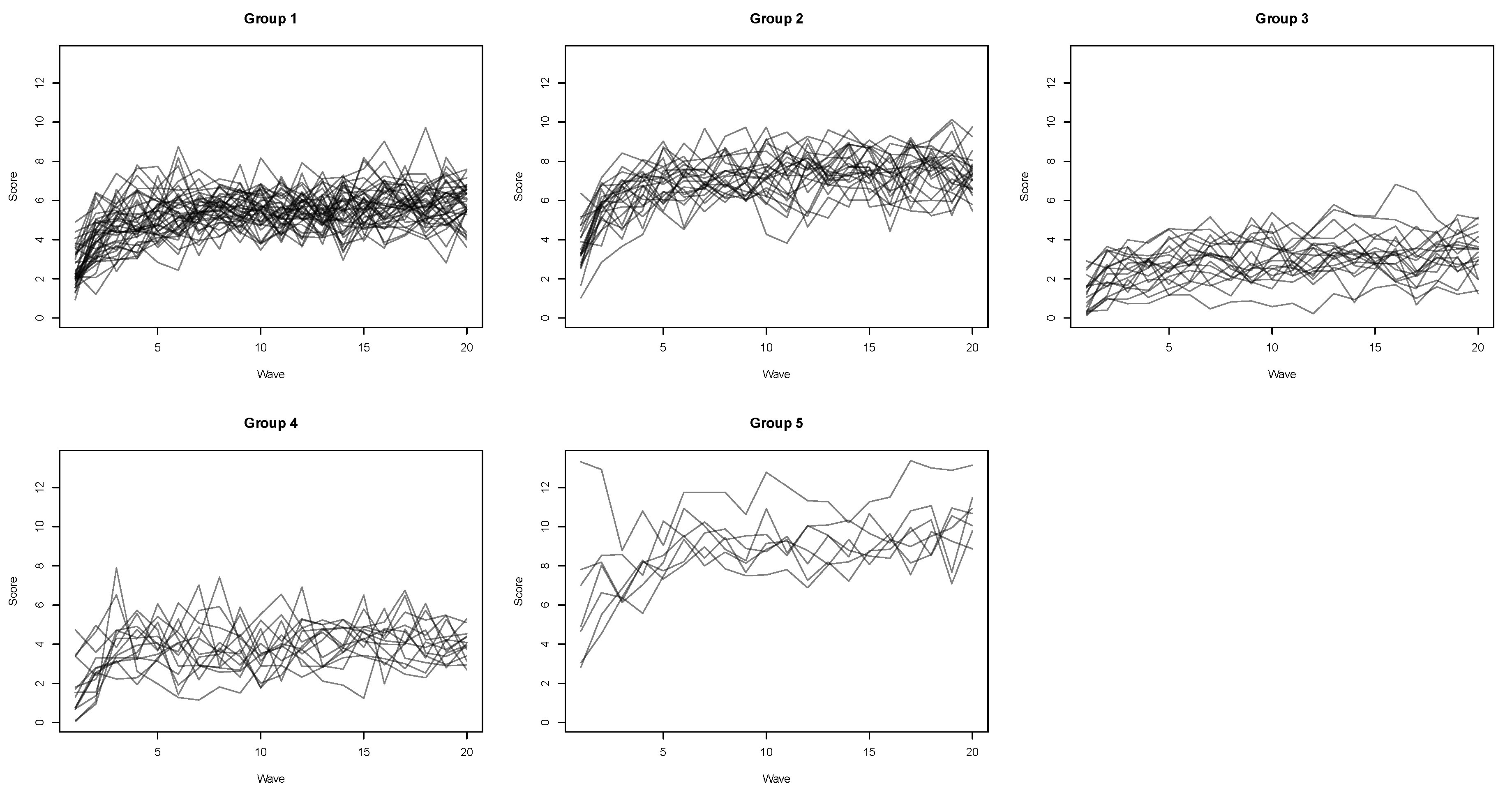
4. Results
4.1. Gmm Clustering with Exponential Trajectory
4.2. Icr-Gmm Clustering with Exponential Trajectory
4.3. HMTD Clustering
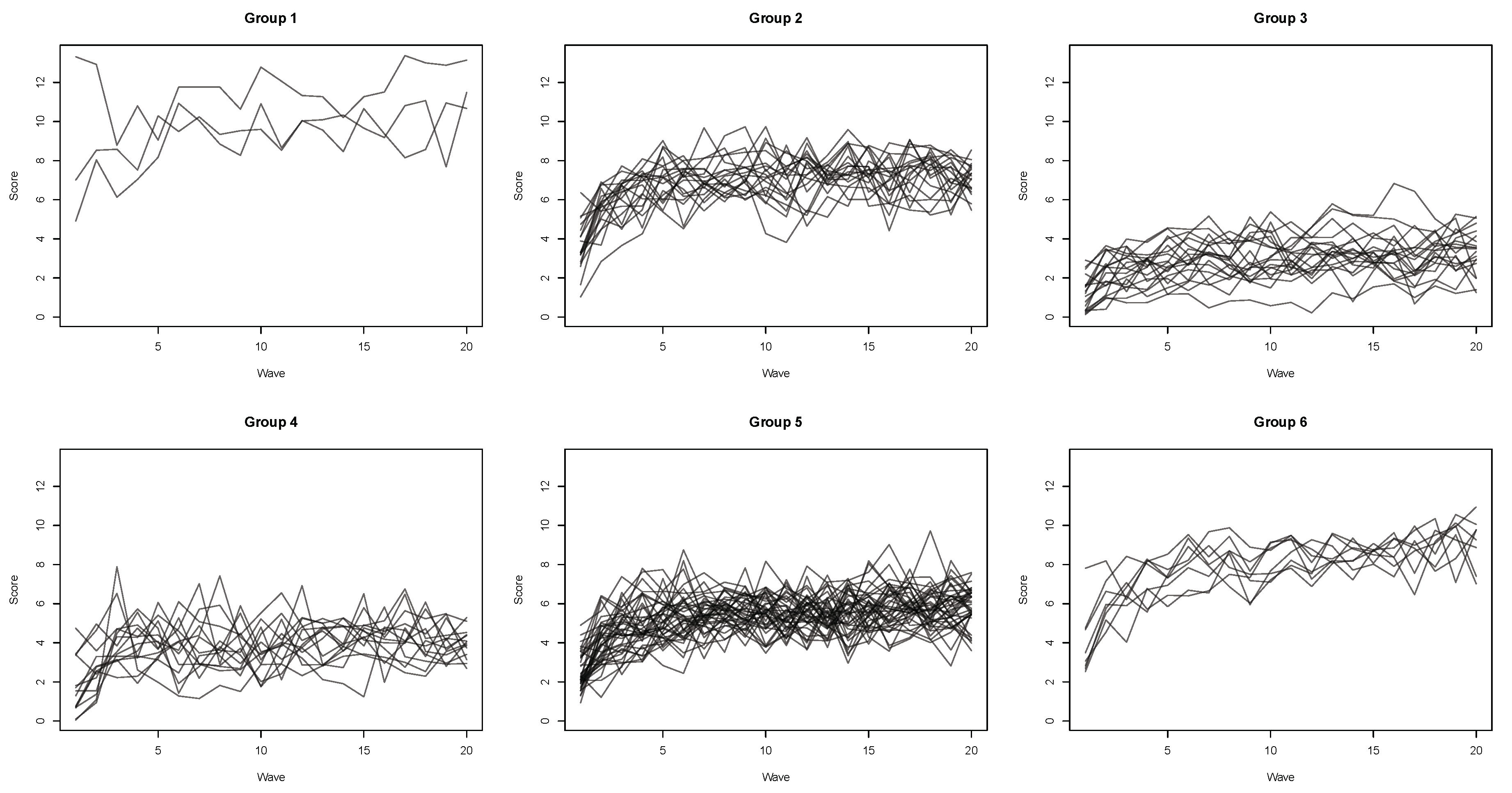
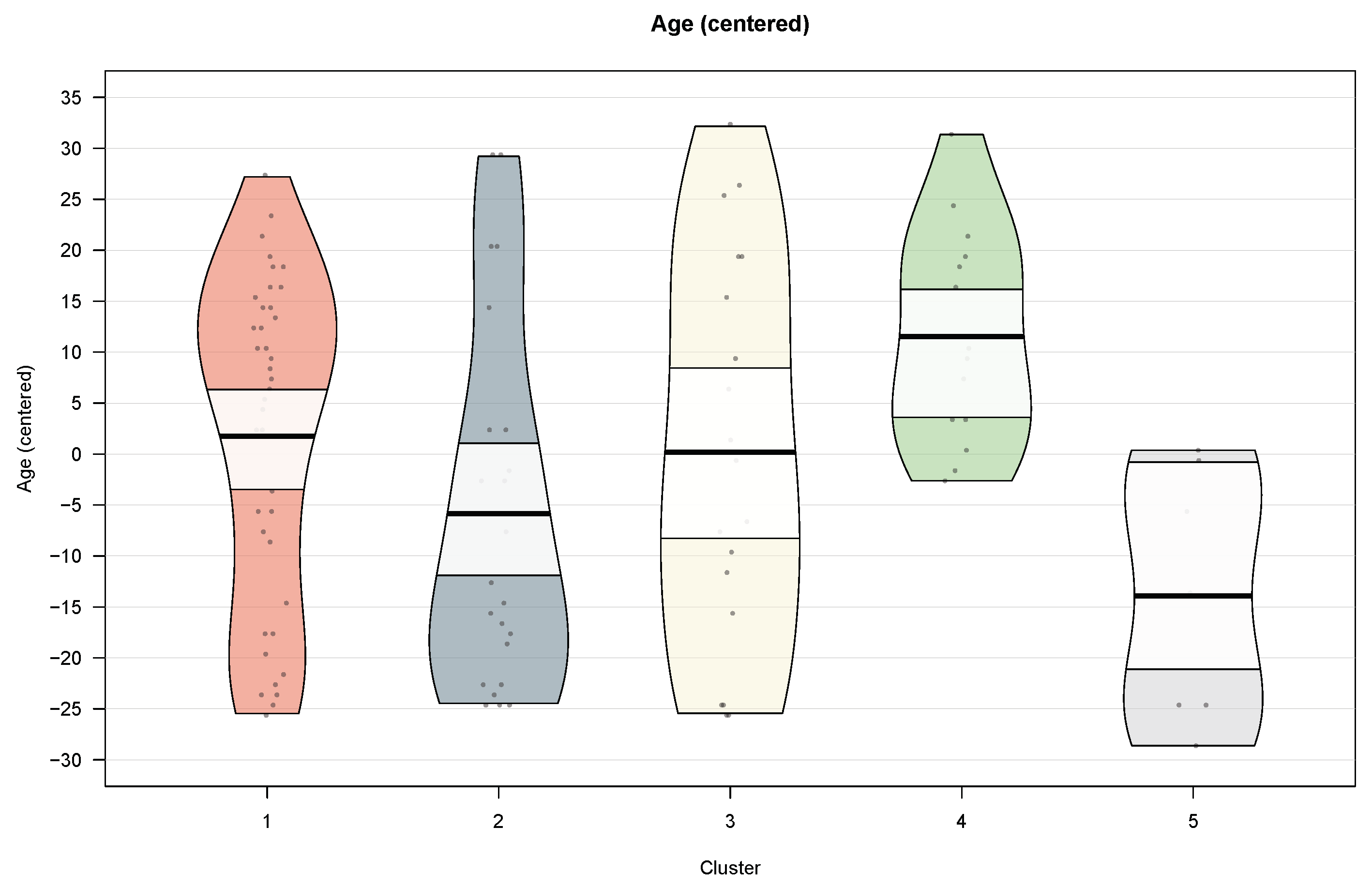
4.3.1. Five-Group Solution
4.3.2. Six-Group Solution
4.4. Correspondence between the Model Solutions
5. Discussion
5.1. Data Particularities and Number of Parameters
5.2. Linearity and Trajectory Assumptions
5.3. Summary of the Results
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HMTD | Hidden Mixture Transition Distribution Model |
| GMM | Growth Mixture Model |
| ICR-GMM | Individual Case Residual Growth Mixture Model of Marcoulides and Trinchera |
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GMM | 2 cl. | 3 Clusters | 4 Clusters | 5 Clusters | ||||||||||||||||
| (Linear) | 2-1 | 2-1 | 3-1 | 3-2 | 2-1 | 3-1 | 4-1 | 3-2 | 4-2 | 4-3 | 2-1 | 3-1 | 4-1 | 5-1 | 3-2 | 4-2 | 5-2 | 4-3 | 5-3 | 5-4 |
| Age | −5.831 | 2.883 | −17.658 | −20.541 | −1.481 | −2.106 | −21.473 | −0.625 | −19.992 | −19.367 | 0.582 | −2.484 | −10.740 | −20.502 | −3.067 | −11.322 | −21.085 | −8.256 | −18.018 | −9.763 |
| p-value | 0.086 | 0.683 | 0.002 | 0.000 | 0.974 | 0.990 | 0.000 | 1.000 | 0.000 | 0.055 | 1.000 | 0.997 | 0.129 | 0.002 | 0.994 | 0.121 | 0.002 | 0.835 | 0.218 | 0.485 |
| LS | 2.979 | −2.438 | 5.176 | 7.614 | 4.146 | 0.375 | 8.732 | −3.771 | 4.586 | 8.357 | −3.263 | −3.513 | 1.292 | 4.837 | −0.250 | 4.556 | 8.100 | 4.806 | 8.350 | 3.544 |
| p-value | 0.285 | 0.697 | 0.461 | 0.227 | 0.531 | 1.000 | 0.186 | 0.932 | 0.674 | 0.631 | 0.865 | 0.988 | 0.997 | 0.853 | 1.000 | 0.796 | 0.485 | 0.968 | 0.836 | 0.964 |
| CS | 1.367 | −0.440 | 12.358 | 12.798 | 1.407 | −5.284 | 10.901 | −6.691 | 9.493 | 16.185 | −2.544 | −9.472 | −1.806 | 14.750 | −6.929 | 0.738 | 17.294 | 7.667 | 24.222 | 16.556 |
| p-value | 0.697 | 0.992 | 0.069 | 0.075 | 0.983 | 0.909 | 0.197 | 0.823 | 0.266 | 0.252 | 0.971 | 0.801 | 0.995 | 0.117 | 0.930 | 1.000 | 0.052 | 0.912 | 0.106 | 0.102 |
| SJS | 0.350 | −0.156 | 1.065 | 1.221 | 0.323 | −0.469 | 1.174 | −0.792 | 0.851 | 1.643 | 0.053 | −0.747 | 1.164 | 1.253 | −0.800 | 1.111 | 1.200 | 1.911 | 2.000 | 0.089 |
| p-value | 0.336 | 0.915 | 0.149 | 0.106 | 0.851 | 0.931 | 0.167 | 0.725 | 0.386 | 0.229 | 1.000 | 0.890 | 0.136 | 0.252 | 0.871 | 0.208 | 0.324 | 0.191 | 0.220 | 1.000 |
| SR | 1.163 | −0.693 | 1.796 | 2.490 | 0.925 | −3.387 | 2.541 | −4.312 | 1.616 | 5.929 | −0.632 | −4.632 | 0.480 | 1.768 | −4.000 | 1.111 | 2.400 | 5.111 | 6.400 | 1.289 |
| p-value | 0.128 | 0.679 | 0.286 | 0.122 | 0.670 | 0.205 | 0.127 | 0.056 | 0.442 | 0.011 | 0.954 | 0.114 | 0.990 | 0.639 | 0.239 | 0.843 | 0.374 | 0.087 | 0.029 | 0.892 |
| WCST | −9.469 | 8.597 | −6.962 | −15.559 | −8.163 | −9.010 | −16.690 | −0.848 | −8.527 | −7.679 | 7.389 | −0.984 | −4.062 | −11.006 | −8.372 | −11.450 | −18.395 | −3.078 | −10.022 | −6.944 |
| p-value | 0.022 | 0.129 | 0.545 | 0.070 | 0.284 | 0.737 | 0.060 | 1.000 | 0.520 | 0.861 | 0.569 | 1.000 | 0.954 | 0.574 | 0.908 | 0.319 | 0.122 | 0.998 | 0.895 | 0.912 |
References
- Baltes, P.B.; Nesselroade, J.R. History and rationale of longitudinal research. In Longitudinal Research in the Study of Behavior and Development; Nesselroade, J., Baltes, P., Eds.; Academic Press: New York, NY, USA, 1979; pp. 1–39. [Google Scholar]
- McArdle, J.J.; Nesselroade, J.R. Growth curve analysis in contemporary psychological research. In Comprehensive Handbook of Psychology, Vol. 2: Research Methods in Psychology; Schinka, J., Velicer, W., Eds.; Wiley: New York, NY, USA, 2003; pp. 447–480. [Google Scholar] [CrossRef]
- Bauer, D.J. Observations on the Use of Growth Mixture Models in Psychological Research. Multivar. Behav. Res. 2007, 42, 757–786. [Google Scholar] [CrossRef]
- Bolano, D.; Berchtold, A. General framework and model building in the class of Hidden Mixture Transition Distribution models. Comput. Stat. Data Anal. 2016, 93, 131–145. [Google Scholar] [CrossRef]
- Taushanov, Z. Latent Markovian Modelling and Clustering for Continuous Data Sequences. Ph.D. Thesis, Université de Lausanne, Faculté des Sciences Sociales et Politiques, Lausanne, Switzerland, 2018. [Google Scholar]
- Kennedy, K.M.; Partridge, T.; Raz, N. Age-related differences in acquisition of perceptual-motor skills: Working memory as a mediator. Aging Neuropsychol. Cogn. 2008, 15, 165–183. [Google Scholar] [CrossRef]
- Ghisletta, P.; Kennedy, K.M.; Rodrigue, K.M.; Lindenberger, U.; Raz, N. Adult age differences and the role of cognitive resources in perceptual–motor skill acquisition: Application of a multilevel negative exponential model. J. Gerontol. Ser. B Psychol. Sci. Soc. Sci. 2010, 65, 163–173. [Google Scholar] [CrossRef] [PubMed]
- Ghisletta, P.; Cantoni, E.; Jacot, N. Nonlinear growth curve models. In Dependent Data in Social Sciences Research; Springer: Berlin/Heidelberg, Germany, 2015; pp. 47–66. [Google Scholar]
- Ghisletta, P.; McArdle, J.J. Latent growth curve analyses of the development of height. Struct. Equ. Model. 2001, 8, 531–555. [Google Scholar] [CrossRef]
- Marcoulides, K.M.; Trinchera, L. Detecting Unobserved Heterogeneity in Latent Growth Curve Models. Struct. Equ. Model. A Multidiscip. J. 2019, 26, 390–401. [Google Scholar] [CrossRef]
- Berchtold, A.; Raftery, A.E. The mixture transition distribution model for high-order Markov chains and non-Gaussian time series. Stat. Sci. 2002, 17, 328–356. [Google Scholar] [CrossRef]
- Nagin, D.S. Analyzing developmental trajectories: A semiparametric, group-based approach. Psychol. Methods 1999, 4, 139. [Google Scholar] [CrossRef]
- Francis, B.; Liu, J. Modelling escalation in crime seriousness: A latent variable approach. Metron 2015, 73, 277–297. [Google Scholar] [CrossRef]
- Muthén, B.; Shedden, K. Finite mixture modeling with mixture outcomes using the EM algorithm. Biometrics 1999, 55, 463–469. [Google Scholar] [CrossRef] [PubMed]
- Ram, N.; Grimm, K.J. Methods and measures: Growth mixture modeling: A method for identifying differences in longitudinal change among unobserved groups. Int. J. Behav. Dev. 2009, 33, 565–576. [Google Scholar] [CrossRef] [PubMed]
- Grimm, K.J.; Helm, J.L. Latent Class Analysis and Growth Mixture Models. In The Encyclopedia of Adulthood and Aging; Whitbourne, S.K., Ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Grimm, K.J.; Ram, N.; Estabrook, R. Nonlinear Structured Growth Mixture Models in Mplus and OpenMx. Multivar. Behav. Res. 2010, 45, 887–909. [Google Scholar] [CrossRef] [PubMed]
- Muthén, B.O. Latent variable mixture modeling. In New Developments and Techniques in Structural Equation Modeling; Psychology Press: London, UK, 2001; pp. 21–54. [Google Scholar]
- Taushanov, Z.; Berchtold, A. Markovian-based clustering of internet addiction trajectories. In Sequence Analysis and Related Approaches; Springer: Berlin/Heidelberg, Germany, 2018; pp. 203–222. [Google Scholar]
- Bauer, D.J.; Curran, P.J. Distributional assumptions of growth mixture models: Implications for overextraction of latent trajectory classes. Psychol. Methods 2003, 8, 338. [Google Scholar] [CrossRef] [PubMed]
- Proust-Lima, C.; Philipps, V.; Liquet, B. Estimation of extended mixed models using latent classes and latent processes: The R package lcmm. arXiv 2015, arXiv:1503.00890. [Google Scholar] [CrossRef]
- Muthén, L.K.; Muthén, B.O. Mplus Users’s Guide, 8th ed.; Muthén & Muthén: Los Angeles, CA, USA, 1998. [Google Scholar]
- Berchtold, A.; Surís, J.C.; Meyer, T.; Taushanov, Z. Development of somatic complaints among adolescents and young adults in Switzerland. Swiss J. Sociol. 2018, 44, 239–258. [Google Scholar] [CrossRef]
- Raftery, A.E. A model for high-order Markov chains. J. R. Stat. Soc. Ser. B (Methodol.) 1985, 47, 528–539. [Google Scholar] [CrossRef]
- Berchtold, A. Estimation in the mixture transition distribution model. J. Time Ser. Anal. 2001, 22, 379–397. [Google Scholar] [CrossRef]
- Berchtold, A. Mixture transition distribution (MTD) modeling of heteroscedastic time series. Comput. Stat. Data Anal. 2003, 41, 399–411. [Google Scholar] [CrossRef]
- Taushanov, Z.; Berchtold, A. Bootstrap Validation of the Estimated Parameters in Mixture Models Used for Clustering. J. Soc. Fr. Stat. 2019, 160, 114–129. [Google Scholar]
- Rosseel, Y. lavaan: An R Package for Structural Equation Modeling. J. Stat. Softw. 2012, 48, 1–36. [Google Scholar] [CrossRef]





| 2 cl | 3cl | 4cl | 5cl | 6cl. | |
|---|---|---|---|---|---|
| HMTD | |||||
| AIC | 6052.044 | 5921.18 | 5889.645 | 5822.483 | 5822.184 |
| BIC | 6073.044 | 5952.679 | 5931.644 | 5874.983 | 5885.184 |
| nb. estimted parameters | 6 | 9 | 12 | 15 | 18 |
| GMM (exp.) | |||||
| AIC | 6058.933 | 6063.217 | 6053.86 | 6048.243 | - |
| BIC | 6095.683 | 6110.467 | 6111.616 | 6116.492 | - |
| adjusted BIC | 6051.462 | 6053.611 | 6042.126 | 6034.367 | - |
| nb. estimted parameters | 14 | 18 | 22 | 26 | - |
| ICR-GMM (exp.) | |||||
| AIC | 6084.298 | 6071.239 | 6037.246 | - | - |
| BIC | 6136.797 | 6149.988 | 6142.245 | - | - |
| BIC2 | 6073.625 | 6055.229 | 6015.9 | - | - |
| nb. estimted parameters | 20 | 30 | 40 | - | - |
| GMM | cl.1 | cl.2 | cl.3 | cl.4 | cl.5 |
|---|---|---|---|---|---|
| cluster size | 28 | 6 | 39 | 23 | 6 |
| 3.39 | 2.53 | 2.65 | 1.58 | 7.12 | |
| 7.41 | 5.55 | 5.72 | 3.37 | 9.36 | |
| 0.58 | 0.14 | 0.37 | 0.50 | 0.17 | |
| ICR-GMM | cl.1 | cl.2 | cl.3 | cl.4 | |
| cluster size | 8 | 39 | 44 | 11 | |
| 3.37 | 2.56 | 2.14 | 3.25 | ||
| 6.18 | 5.53 | 4.95 | 5.69 | ||
| 0.17 | 0.69 | 0.47 | 0.42 |
| GMM | 2 cl. | 3 Clusters | 4 Clusters | 5 Clusters | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exponential | 2-1 | 2-1 | 3-1 | 3-2 | 2-1 | 3-1 | 4-1 | 3-2 | 4-2 | 4-3 | 2-1 | 3-1 | 4-1 | 5-1 | 3-2 | 4-2 | 5-2 | 4-3 | 5-3 | 5-4 |
| Age | −8.040 | 4.200 | 8.783 | 4.583 | 9.003 | 6.755 | −8.969 | −2.248 | −17.972 | −15.724 | 16.060 | 9.649 | 6.654 | −1.940 | −6.410 | −9.406 | −18.000 | −2.996 | −11.590 | −8.594 |
| p-value | 0.143 | 0.741 | 0.452 | 0.659 | 0.117 | 0.380 | 0.667 | 0.946 | 0.108 | 0.204 | 0.202 | 0.135 | 0.604 | 0.999 | 0.899 | 0.722 | 0.328 | 0.957 | 0.496 | 0.784 |
| LS | 4.216 | 0.105 | −2.645 | −2.751 | −6.304 | −8.683 | 3.213 | −2.380 | 9.517 | 11.896 | −15.778 | −7.778 | −9.778 | −2.111 | 8.000 | 6.000 | 13.667 | −2.000 | 5.667 | 7.667 |
| p-value | 0.342 | 1.000 | 0.898 | 0.808 | 0.216 | 0.068 | 0.957 | 0.893 | 0.435 | 0.257 | 0.067 | 0.132 | 0.085 | 0.996 | 0.629 | 0.856 | 0.372 | 0.979 | 0.858 | 0.709 |
| CS | 6.729 | −1.415 | −3.589 | −2.174 | −5.269 | −4.787 | 15.065 | 0.481 | 20.333 | 19.852 | −16.481 | −7.037 | −6.434 | 6.852 | 9.444 | 10.048 | 23.333 | 0.603 | 13.889 | 13.286 |
| p-value | 0.238 | 0.969 | 0.889 | 0.923 | 0.572 | 0.682 | 0.313 | 0.999 | 0.097 | 0.116 | 0.176 | 0.441 | 0.655 | 0.908 | 0.681 | 0.670 | 0.136 | 1.000 | 0.388 | 0.476 |
| SJS | 0.321 | 0.291 | 0.273 | −0.018 | −0.616 | −1.267 | −0.039 | −0.651 | 0.578 | 1.229 | −2.000 | −0.744 | −1.364 | −0.500 | 1.256 | 0.636 | 1.500 | −0.620 | 0.244 | 0.864 |
| p-value | 0.581 | 0.880 | 0.936 | 0.999 | 0.470 | 0.032 | 1.000 | 0.447 | 0.897 | 0.465 | 0.084 | 0.420 | 0.054 | 0.967 | 0.457 | 0.928 | 0.555 | 0.656 | 0.998 | 0.808 |
| SR | 0.189 | −1.035 | −2.411 | −1.376 | −1.764 | −3.740 | 1.125 | −1.976 | 2.889 | 4.865 | −3.583 | −1.776 | −4.100 | 0.850 | 1.808 | −0.517 | 4.433 | −2.324 | 2.626 | 4.950 |
| p-value | 0.882 | 0.709 | 0.340 | 0.515 | 0.156 | 0.000 | 0.925 | 0.121 | 0.384 | 0.048 | 0.147 | 0.231 | 0.001 | 0.986 | 0.746 | 0.998 | 0.213 | 0.108 | 0.489 | 0.039 |
| WCST | 1.823 | −5.444 | 0.465 | 5.909 | 11.649 | 10.501 | 2.760 | −1.148 | −8.889 | −7.741 | 8.900 | 13.141 | 14.455 | 18.000 | 4.241 | 5.555 | 9.100 | 1.314 | 4.859 | 3.545 |
| p-value | 0.793 | 0.729 | 0.999 | 0.642 | 0.081 | 0.185 | 0.996 | 0.996 | 0.876 | 0.917 | 0.881 | 0.063 | 0.083 | 0.427 | 0.991 | 0.978 | 0.957 | 0.999 | 0.989 | 0.997 |
| ICR-GMM | 2 cl. | 3 Clusters | 4 Clusters | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Exponential | 2-1 | 2-1 | 3-1 | 3-2 | 2-1 | 3-1 | 4-1 | 3-2 | 4-2 | 4-3 |
| Age | −3.333 | −4.254 | −4.976 | −0.723 | 1.240 | 1.648 | 0.625 | 0.407 | −0.615 | −1.023 |
| p-value | 0.329 | 0.648 | 0.418 | 0.985 | 0.998 | 0.994 | 1.000 | 1.000 | 1.000 | 0.998 |
| LS | 6.564 | 0.877 | 0.969 | 0.093 | 5.083 | 4.068 | 8.841 | −1.015 | 3.758 | 4.773 |
| p-value | 0.017 | 0.973 | 0.953 | 1.000 | 0.776 | 0.865 | 0.506 | 0.987 | 0.854 | 0.727 |
| CS | 6.298 | 3.614 | −0.844 | −4.459 | −0.868 | 0.655 | 5.614 | 1.522 | 6.481 | 4.959 |
| p-value | 0.071 | 0.749 | 0.977 | 0.591 | 0.999 | 1.000 | 0.891 | 0.980 | 0.687 | 0.822 |
| SJS | 0.040 | 0.234 | −0.489 | −0.723 | 0.385 | 0.636 | 0.795 | 0.251 | 0.410 | 0.159 |
| p-value | 0.913 | 0.890 | 0.478 | 0.264 | 0.946 | 0.792 | 0.775 | 0.922 | 0.909 | 0.994 |
| SR | 0.795 | 1.412 | 1.064 | −0.348 | 1.014 | 1.195 | 2.307 | 0.181 | 1.293 | 1.112 |
| p-value | 0.299 | 0.392 | 0.454 | 0.933 | 0.899 | 0.839 | 0.547 | 0.996 | 0.746 | 0.814 |
| WCST | −4.531 | −7.583 | −12.908 | −5.325 | 10.139 | 9.919 | 5.227 | −0.220 | −4.912 | −4.691 |
| p-value | 0.279 | 0.390 | 0.018 | 0.577 | 0.583 | 0.588 | 0.946 | 1.000 | 0.897 | 0.904 |
| 6cl. sol. | corresp. | |||
|---|---|---|---|---|
| 5cl. sol. | ||||
| 1 | 1.81 | 4.81 | 0.53 | |
| 2 | 1.07 | 4.47 | 0.37 | |
| 3 | 3 | 0.65 | 1.07 | 0.67 |
| 4 | 4 | 1.32 | 2.76 | 0.29 |
| 5 | 1 | 1.00 | 3.18 | 0.43 |
| 6 | 0.98 | 4.13 | 0.51 | |
| 5cl. sol. | ||||
| 1 | 0.99 | 3.25 | 0.41 | |
| 2 | 1.08 | 4.08 | 0.44 | |
| 3 | 0.64 | 1.07 | 0.66 | |
| 4 | 1.30 | 2.76 | 0.29 | |
| 5 | 1.40 | 3.70 | 0.61 | |
| HMTD | 2 Cl. | 3 Clusters | 4 Clusters | 5 Clusters | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-1 | 2-1 | 3-1 | 3-2 | 2-1 | 3-1 | 4-1 | 3-2 | 4-2 | 4-3 | 2-1 | 3-1 | 4-1 | 5-1 | 3-2 | 4-2 | 5-2 | 4-3 | 5-3 | 5-4 | |
| Age | −7.882 | 10.581 | 13.187 | 2.606 | 9.756 | 7.267 | −8.068 | −2.488 | −17.824 | −15.336 | −7.576 | −1.570 | 9.784 | −15.645 | 6.007 | 17.360 | −8.068 | 11.353 | −14.075 | −25.429 |
| p-value | 0.028 | 0.024 | 0.005 | 0.783 | 0.087 | 0.467 | 0.661 | 0.937 | 0.040 | 0.149 | 0.385 | 0.997 | 0.298 | 0.134 | 0.748 | 0.017 | 0.772 | 0.273 | 0.285 | 0.009 |
| LS | 7.824 | −3.828 | −9.820 | −5.992 | −5.698 | −8.596 | 3.487 | −2.898 | 9.185 | 12.083 | 3.997 | −3.620 | −8.385 | 7.484 | −7.616 | −12.381 | 3.487 | −4.765 | 11.103 | 15.868 |
| p-value | 0.008 | 0.472 | 0.014 | 0.158 | 0.343 | 0.176 | 0.931 | 0.850 | 0.326 | 0.179 | 0.787 | 0.871 | 0.284 | 0.641 | 0.372 | 0.066 | 0.973 | 0.858 | 0.332 | 0.087 |
| CS | 4.633 | −9.217 | −9.673 | −0.456 | −6.545 | −4.809 | 14.026 | 1.737 | 20.571 | 18.835 | 5.831 | 2.175 | −4.099 | 19.857 | −3.657 | −9.930 | 14.026 | −6.274 | 17.683 | 23.956 |
| p-value | 0.215 | 0.074 | 0.067 | 0.993 | 0.400 | 0.776 | 0.195 | 0.979 | 0.012 | 0.048 | 0.676 | 0.990 | 0.935 | 0.032 | 0.953 | 0.407 | 0.276 | 0.823 | 0.112 | 0.019 |
| SJS | 1.202 | −0.453 | −1.462 | −1.010 | −0.570 | −1.277 | 1.130 | −0.707 | 1.700 | 2.407 | 0.343 | −0.911 | −1.000 | 1.473 | −1.254 | −1.343 | 1.130 | −0.089 | 2.383 | 2.473 |
| p-value | 0.001 | 0.531 | 0.003 | 0.043 | 0.558 | 0.081 | 0.426 | 0.400 | 0.072 | 0.010 | 0.941 | 0.313 | 0.356 | 0.222 | 0.136 | 0.167 | 0.541 | 1.000 | 0.017 | 0.021 |
| SR | 2.970 | −1.391 | −3.800 | −2.409 | −1.931 | −3.807 | 0.638 | −1.876 | 2.569 | 4.444 | 1.388 | −2.719 | −1.923 | 2.026 | −4.107 | −3.311 | 0.638 | 0.796 | 4.745 | 3.949 |
| p-value | 0.000 | 0.237 | 0.000 | 0.016 | 0.136 | 0.005 | 0.979 | 0.217 | 0.333 | 0.044 | 0.549 | 0.063 | 0.419 | 0.671 | 0.003 | 0.055 | 0.994 | 0.971 | 0.039 | 0.153 |
| WCST | −8.481 | 8.967 | 14.378 | 5.411 | 8.308 | 14.946 | −5.638 | 6.638 | −13.946 | −20.583 | −7.801 | 7.895 | 1.478 | −13.439 | 15.696 | 9.279 | −5.638 | −6.417 | −21.333 | −14.917 |
| p-value | 0.056 | 0.169 | 0.018 | 0.506 | 0.349 | 0.072 | 0.924 | 0.586 | 0.366 | 0.122 | 0.573 | 0.619 | 0.999 | 0.539 | 0.090 | 0.684 | 0.971 | 0.904 | 0.158 | 0.563 |
| HMTD | 6 Clusters | |||||||||||||||||||
| 2-1 | 3-1 | 4-1 | 5-1 | 6-1 | 3-2 | 4-2 | 5-2 | 6-2 | 4-3 | 5-3 | 6-3 | 5-4 | 6-4 | 6-5 | ||||||
| Age | 7.386 | 10.123 | 21.476 | 11.692 | −9.167 | 2.737 | 14.090 | 4.306 | −16.553 | 11.353 | 1.570 | −19.289 | −9.784 | −30.643 | −20.859 | |||||
| p-value | 0.973 | 0.902 | 0.269 | 0.811 | 0.953 | 0.994 | 0.121 | 0.921 | 0.134 | 0.319 | 0.999 | 0.050 | 0.347 | 0.000 | 0.012 | |||||
| LS | −1.982 | −9.056 | −13.821 | −5.436 | 2.905 | −7.073 | −11.838 | −3.453 | 4.887 | −4.765 | 3.620 | 11.960 | 8.385 | 16.725 | 8.341 | |||||
| p-value | 1.000 | 0.877 | 0.573 | 0.982 | 1.000 | 0.576 | 0.137 | 0.934 | 0.958 | 0.917 | 0.926 | 0.328 | 0.356 | 0.085 | 0.634 | |||||
| CS | −9.368 | −13.111 | −19.385 | −15.286 | 0.286 | −3.743 | −10.016 | −5.917 | 9.654 | −6.274 | −2.175 | 13.397 | 4.099 | 19.670 | 15.571 | |||||
| p-value | 0.938 | 0.787 | 0.434 | 0.625 | 1.000 | 0.981 | 0.528 | 0.796 | 0.759 | 0.895 | 0.997 | 0.441 | 0.971 | 0.116 | 0.203 | |||||
| SJS | −0.368 | −1.526 | −1.615 | −0.615 | 1.000 | −1.158 | −1.247 | −0.247 | 1.368 | −0.089 | 0.911 | 2.526 | 1.000 | 2.615 | 1.615 | |||||
| p-value | 0.999 | 0.687 | 0.662 | 0.990 | 0.954 | 0.285 | 0.317 | 0.995 | 0.443 | 1.000 | 0.386 | 0.013 | 0.433 | 0.017 | 0.190 | |||||
| SR | −0.368 | −4.412 | −3.615 | −1.692 | 0.250 | −4.043 | −3.247 | −1.324 | 0.618 | 0.796 | 2.719 | 4.662 | 1.923 | 3.865 | 1.942 | |||||
| p-value | 1.000 | 0.527 | 0.737 | 0.984 | 1.000 | 0.010 | 0.106 | 0.741 | 0.998 | 0.989 | 0.085 | 0.028 | 0.508 | 0.139 | 0.694 | |||||
| WCST | 9.763 | 24.500 | 18.083 | 16.605 | 4.500 | 14.737 | 8.320 | 6.842 | −5.263 | −6.417 | −7.895 | −20.000 | −1.478 | −13.583 | −12.105 | |||||
| p-value | 0.985 | 0.554 | 0.834 | 0.853 | 1.000 | 0.207 | 0.860 | 0.817 | 0.988 | 0.949 | 0.711 | 0.168 | 1.000 | 0.658 | 0.614 | |||||
| Cluster | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 39 | 0 |
| 2 | 0 | 19 | 0 | 0 | 0 | 4 |
| 3 | 0 | 0 | 19 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 14 | 0 | 0 |
| 5 | 3 | 0 | 0 | 0 | 0 | 4 |
| (a) | (b) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| HMTD | 4 cl. exp. ICR-GMM | HMTD | 5 cl. exponential GMM | |||||||
| 5 clusters | 1 | 2 | 3 | 4 | 5 clusters | 1 | 2 | 3 | 4 | 5 |
| 1 | 3 | 14 | 17 | 5 | 1 | 4 | 2 | 32 | 0 | 1 |
| 2 | 1 | 9 | 10 | 3 | 2 | 20 | 0 | 1 | 0 | 2 |
| 3 | 1 | 7 | 9 | 2 | 3 | 0 | 2 | 1 | 16 | 0 |
| 4 | 3 | 6 | 5 | 0 | 4 | 0 | 2 | 5 | 7 | 0 |
| 5 | 0 | 3 | 3 | 1 | 5 | 4 | 0 | 0 | 0 | 3 |
| 6 clusters | 1 | 2 | 3 | 4 | 6 clusters | 1 | 2 | 3 | 4 | 5 |
| 1 | 0 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 2 |
| 2 | 0 | 7 | 9 | 3 | 2 | 16 | 0 | 1 | 0 | 2 |
| 3 | 1 | 7 | 9 | 2 | 3 | 0 | 2 | 1 | 16 | 0 |
| 4 | 3 | 6 | 5 | 0 | 4 | 0 | 2 | 5 | 7 | 0 |
| 5 | 3 | 14 | 17 | 5 | 5 | 4 | 2 | 32 | 0 | 1 |
| 6 | 1 | 3 | 3 | 1 | 6 | 7 | 0 | 0 | 0 | 1 |
| Exp.GMM | 4 cl. exp. ICR-GMM | |||
|---|---|---|---|---|
| Clusters | 1 | 2 | 3 | 4 |
| 1 | 1 | 9 | 14 | 4 |
| 2 | 0 | 5 | 1 | 0 |
| 3 | 5 | 15 | 15 | 4 |
| 4 | 2 | 7 | 12 | 2 |
| 5 | 0 | 3 | 2 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taushanov, Z.; Ghisletta, P. The Use of a Hidden Mixture Transition Distribution Model in Clustering Few but Long Continuous Sequences: An Illustration with Cognitive Skills Data. Symmetry 2020, 12, 1618. https://doi.org/10.3390/sym12101618
Taushanov Z, Ghisletta P. The Use of a Hidden Mixture Transition Distribution Model in Clustering Few but Long Continuous Sequences: An Illustration with Cognitive Skills Data. Symmetry. 2020; 12(10):1618. https://doi.org/10.3390/sym12101618
Chicago/Turabian StyleTaushanov, Zhivko, and Paolo Ghisletta. 2020. "The Use of a Hidden Mixture Transition Distribution Model in Clustering Few but Long Continuous Sequences: An Illustration with Cognitive Skills Data" Symmetry 12, no. 10: 1618. https://doi.org/10.3390/sym12101618
APA StyleTaushanov, Z., & Ghisletta, P. (2020). The Use of a Hidden Mixture Transition Distribution Model in Clustering Few but Long Continuous Sequences: An Illustration with Cognitive Skills Data. Symmetry, 12(10), 1618. https://doi.org/10.3390/sym12101618