An Ensemble Machine Learning Technique for Functional Requirement Classification



Abstract
1. Introduction
- Solution requirements: This type describes the actions that must be carried out by the system or the action that is carried out by the system or the user.
- Enablement requirements: This class determines the capabilities offered to the user by the system. It may determine the subsystem that offers the capability, or it may not determine the subsystem that offers this capability.
- Action Constraint requirements: This class describes the allowable actions for the system or subsystem or the actions that are not allowed. This class also may determine business rules that control some actions in the system.
- Attribute Constraint requirements: This class is related to constraints on attributes or entity attributes.
- Definition requirements: This class is used to define entities.
- Policy requirements: This class is to specify the policies that the system must follow.
2. Related Work
2.1. Traditional Techniques of Classification
2.2. ML Techniques of Classification
3. Materials and Methods
3.1. Data Collection Description
- Collecting a reasonable number of FR statements in a spreadsheet with two columns: requirements and class. We used a total of 600 FR statements that include the same number of each desired class to ensure that the dataset is balanced.
- Labeling each FR according to the syntax of each chosen class as solution, enablement, action constraint, attribute constraint, definition, or policy requirements.
3.2. Methodology
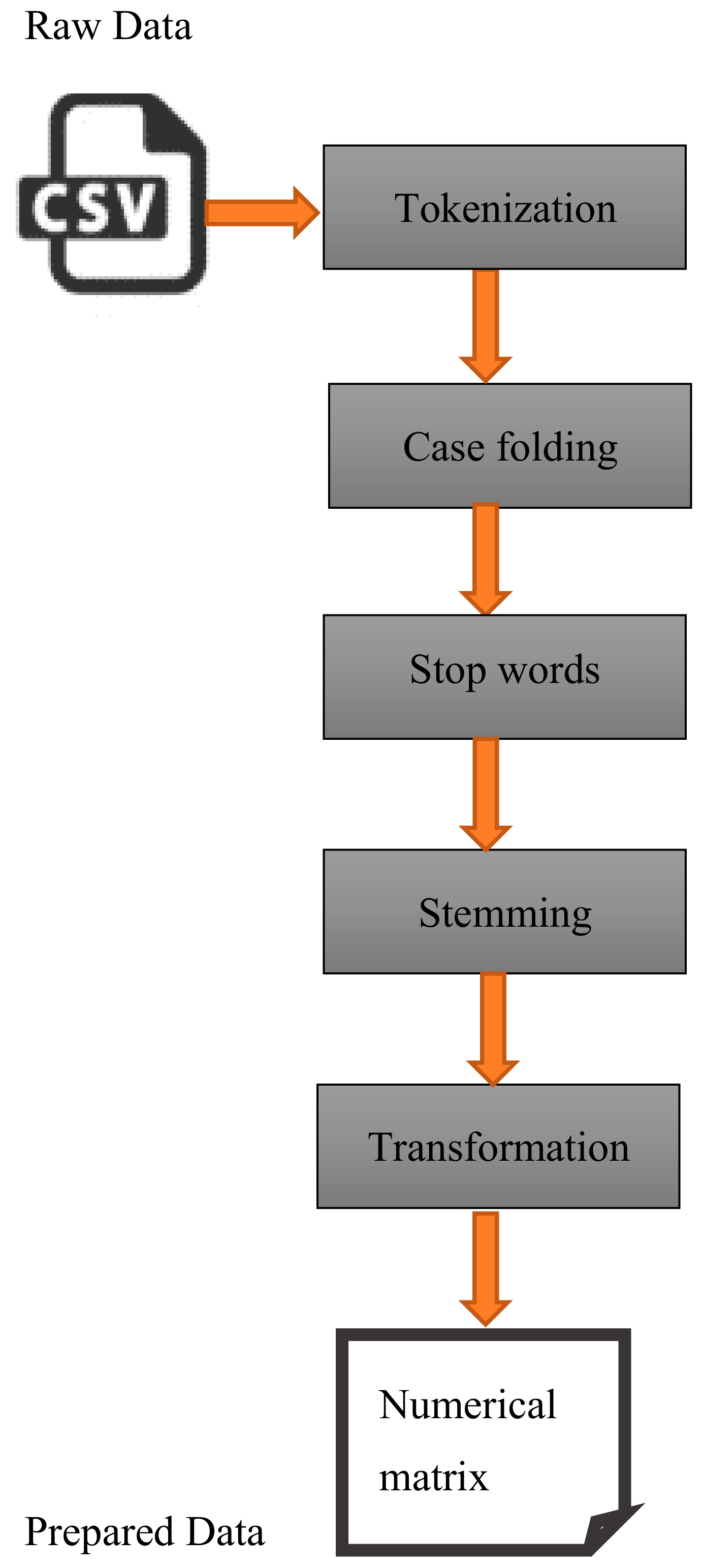
- Data Pre-processing.
- Classification using ML base classifiers (SVM, Naïve Bayes, SVC, Decision Tree, and Logistic Regression).
- Building a confusion matrix for each base classifier.
- Calculating the accuracy for each base classifier.
- Generating a numerical array.
- Ensemble classifier (the accuracy per class as a weight in weighted ensemble voting).
3.2.1. Data Pre-Processing
- Tokenization is defined as separating the input data into tokens. A token is a group of letters joined with a semantic meaning with no need for further processing. Different tokenization methods can be applied to a text, so it is important to use the same technique for all texts used in an experiment [31]
- Case folding is the process of unifying the cases of the letters in the entire text, but there can be some ambiguity if uppercase letters are used to distinguish different abbreviations [31].
- Stop words are the parts of sentences with negative effects on multiclassification problems. Stop words include prepositions, pronouns, adverbs, and conjunctions [31]
- Stemming refers to extracting the morphological root of a word. Several different techniques are used for this process, including lemmatization, the use of semi-automatic lookup tables, and suffix stripping [31].
- The last step is transformation, which involves using word frequency to provide a score or identification (ID).
3.2.2. ML Classifiers
- Support Vector Machine (SVM) model
- Naïve Bayes Model
- Logistic Regression
- Decision Tree
- Support Vector Classification (SVC)
3.2.3. Building a Confusion Matrix for Each Classifier
3.2.4. Calculating the Accuracy for Each Base Classifier
3.2.5. Generating the Numerical Matrix
3.2.6. Ensemble Classifier
- Mean Ensemble Voting
- Weighted Ensemble Voting
- Accuracy in Weight Ensemble Voting
- Proposed Ensemble voting
| Algorithm 1: Calculating weight for base ML classifiers |
| Input: X: A data stream of sentences inserted from a file. Y: a label of the sentences Clf(i): Number of algorithms used [SVM, SCV, Naïve Bayes, Decision Tree, Logistic Regression]. Output: W: An array of weights assigned for each Clf(i) Voting_ Accuracy: Represents the proposed ensemble voting model. // Data preprocessing stage X<Tokenize sentences in X X<Remove spaces and stop words. X<Convector(X) // convert sentences into numbers Y< Convector (Y) // convert labels (classes) into numbers // split data into training and testing portions train_data (x, y), test_data(x,y) < Split (X, Y) For each model in CLF(i): Clf(i) < fit (train_data (X, Y)) P(y’) < Predict (test data(X)) Result< Compare(p(y’), Y) Conf(i)< Calculate (Confusion matrix) Accuracy(i) < Result / Y*100 End // Give a weight for each model // combine the diagonals of all confusion matrices into one matrix Conf_matrix < [[Conf (i:). diagonal]] // find the maximum of each column that will represent the algorithm weight W < max_coloumn (Conf_matrix(i)) V_result< Voting_algorithm (Clf(i), W(i)) Voting_ Accuracy < V_Result / Y*100 |
4. Experiment Details
4.1. Dataset
4.2. Tools and Instruments
4.2.1. Software
4.2.2. Hardware
5. Results
5.1. Training
5.2. Testing
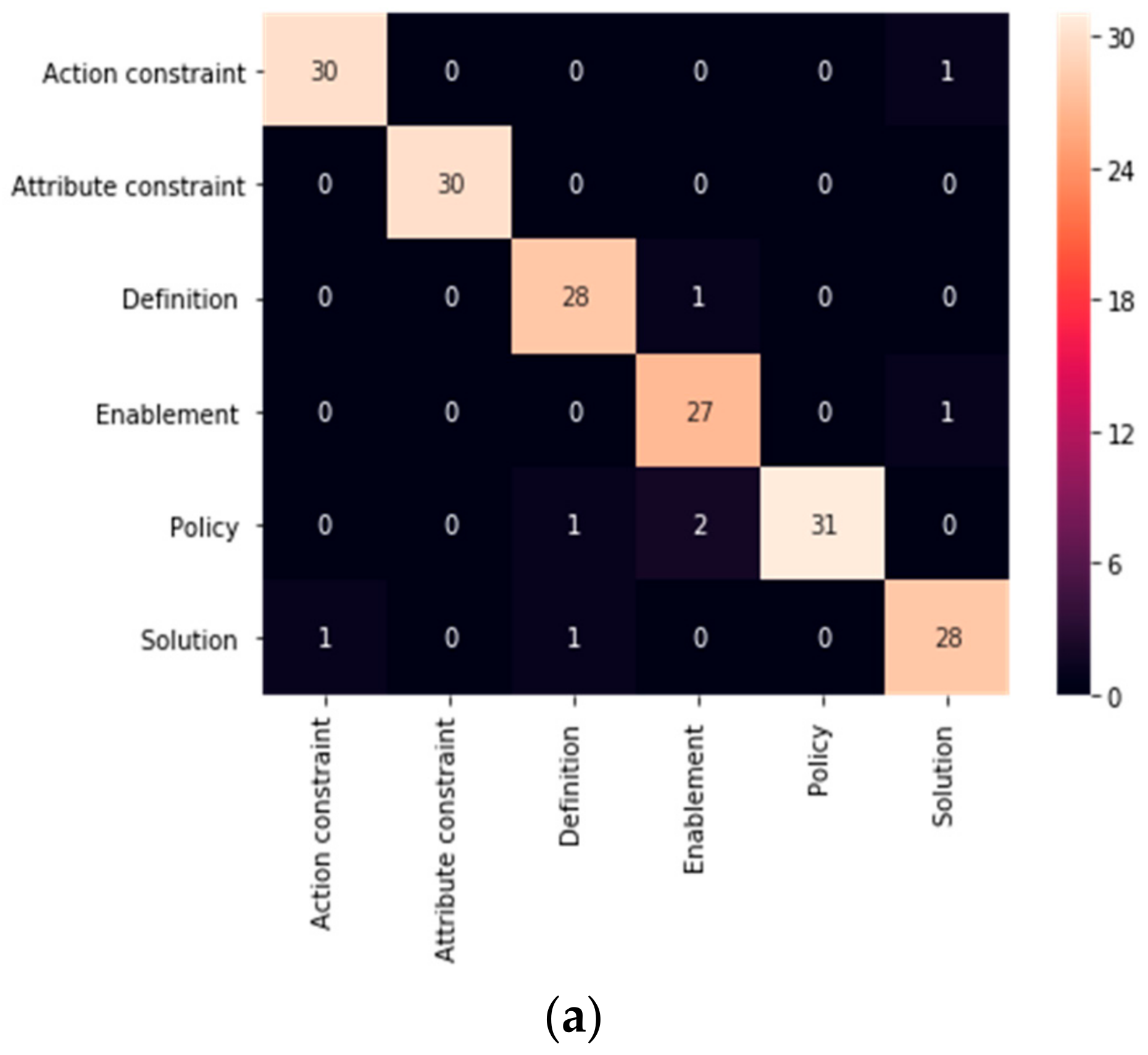
- First, the base ML classifier performance was tested using preprocessing with TF-IDF and Countvectorizer. The results are shown in Figure 4 and Figure 5, which illustrate the confusion matrices for the base classifiers, and Table 1, which summarizes the accuracy and required time for each base classifier in the proposed enhanced ensemble approach.
- Second, different data split percentages of training and testing data have been tested (50:50, 40:60, 30:70, 20:80, 10:90) to find the idle split for the ML classifiers. The results are shown in Table 2, which summarizes the accuracy and required time for each base classifier in the proposed enhanced ensemble approach.
5.3. Comparative Analysis
5.3.1. Experimental Section
- Based on time and accuracy
- Based on Receiver Operating Characteristic (ROC) metric
5.3.2. Theoretical Section
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sharma, R.; Biswas, K.K. Functional requirements categorization: Grounded theory approach. In Proceedings of the 2015 International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE), Barcelona, Spain, 29–30 April 2015; pp. 301–307. [Google Scholar] [CrossRef]
- Abad, Z.S.H.; Karras, O.; Ghazi, P.; Glinz, M.; Ruhe, G.; Schneider, K. What Works Better? A Study of Classifying Requirements. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; pp. 496–501. [Google Scholar]
- Ghazarian, A. Characterization of functional software requirements space: The law of requirements taxonomic growth. In Proceedings of the 2012 20th IEEE International Requirements Engineering Conference (RE), Chicago, IL, USA, 24–28 September 2012; pp. 241–250. [Google Scholar] [CrossRef]
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Ponta, L.; Puliga, G.; Oneto, L.; Manzini, R. Identifying the determinants of Innovation Capability With Machine Learning and Patents. IEEE Trans. Eng. Manag. 2020, 1–11. [Google Scholar] [CrossRef]
- Casamayor, A.; Godoy, D.; Campo, M. Identification of non-functional requirements in textual specifications: A semi-supervised learning approach. Inf. Softw. Technol. 2010, 52, 436–445. [Google Scholar]
- Slankas, J.; Williams, L. Automated extraction of non-functional requirements in available documentation. In Proceedings of the 1st International Workshop on Natural Language Analysis in Software Engineering (NaturaLiSE), San Francisco, CA, USA, 25 May 2013; pp. 9–16. [Google Scholar]
- Kurtanovic, Z.; Maalej, W. Automatically Classifying Functional and Non-functional Requirements Using Supervised Machine Learning. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; pp. 490–495. [Google Scholar]
- Mahmoud, M. Software Requirements Classification using Natural Language Processing and SVD. Int. J. Comput. Appl. 2017, 164, 7–12. [Google Scholar] [CrossRef]
- Singh, P.; Singh, D.; Sharma, A. Rule-based system for automated classification of non-functional requirements from requirement specifications. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics, ICACCI 2016, Jaipur, India, 21–24 September 2016; pp. 620–626. [Google Scholar]
- Navarro-Almanza, R.; Juurez-Ramirez, R.; Licea, G. Towards Supporting Software Engineering Using Deep Learning: A Case of Software Requirements Classification. In Proceedings of the 5th International Conference on Software Engineering Research and Innovation (CONISOFT’17), Yucatán, Mexico, 25–27 October 2017; pp. 116–120. [Google Scholar]
- Taj, S.; Arain, Q.; Memon, I.; Zubedi, A. To apply data mining for classification of crowd sourced software requirements. In Proceedings of the ACM International Conference Proceedings Series, Phoenix, AZ, USA, 26–28 June 2019; pp. 42–46. [Google Scholar]
- Dalpiaz, F.; Dell’Anna, D.; Aydemir, F.B.; Çevikol, S. Requirements classification with interpretable machine learning and dependency parsing. In Proceedings of the International Conference on Industrial Engineering and Applications (ICIEA), Jeju Island, Korea, 23–27 September 2019; pp. 142–152. [Google Scholar]
- Baker, C.; Deng, L.; Chakraborty, S.; Dehlinger, J. Automatic multi-class non-functional software requirements classification using neural networks. In Proceedings of the IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, USA, 15–19 July 2019; Volume 2, pp. 610–615. [Google Scholar]
- Halim, F.; Siahaan, D. Detecting Non-Atomic Requirements in Software Requirements Specifications Using Classification Methods. In Proceedings of the 1st International Conference on Cybernetics and Intelligent System (ICORIS), Denpasar, Indonesia, 22–23 August 2019; pp. 269–273. [Google Scholar]
- Parra, E.; Dimou, C.; Llorens, J.; Moreno, V.; Fraga, A. A methodology for the classification of quality of requirements using machine learning techniques. Inf. Softw. Technol. 2015, 67, 180–195. [Google Scholar] [CrossRef]
- Knauss, E.; Houmb, S.; Schneider, K.; Islam, S.; Jürjens, J. Supporting Requirements Engineers in Recognising Security Issues. Lect. Notes Comput. Sci. 2011, 6606 LNCS, 4–18. [Google Scholar]
- Tamai, T.; Anzai, T. Quality requirements analysis with machine learning. In Proceedings of the 13th International Conference Evaluation Novel Approaches to Software Engineering (ENASE 2018), Funchal, Madeira, Portugal, 23–24 March 2018; pp. 241–248. [Google Scholar] [CrossRef]
- Jain, P.; Verma, K.; Kass, A.; Vasquez, R.G. Automated review of natural language requirements documents: Generating useful warnings with user-extensible glossaries driving a simple state machine. In Proceedings of the 2nd India Software Engineering Conference, Pune, India, 23–26 February 2009; pp. 37–45. [Google Scholar] [CrossRef]
- Alomari, R.; Elazhary, H. Implementation of a formal software requirements ambiguity prevention tool. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 424–432. [Google Scholar] [CrossRef]
- Elazhary, H. Translation of Software Requirements. Int. J. Sci. Eng. Res. 2011, 2, 1–7. [Google Scholar]
- Maw, M.; Balakrishman, V.; Rana, O.; Ravana, S. Trends and Patterns of Text Classification Techniques: A Systematic Mapping Study. Malays. J. Comput. Sci. 2020, 33, 102–117. [Google Scholar] [CrossRef]
- Martinez, A.; Jenkins, M.; Quesada-Lopez, C. Identifying implied security requirements from functional requirements. In Proceedings of the 2019 14th Iberian Conference on Information Systems and Technologies (CISTI), Coimbra, Portugal, 19–22 June 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Anish, P.R.; Balasubramaniam, B.; Cleland-Huang, J.; Wieringa, R.; Daneva, M.; Ghaisas, S. Identifying Architecturally Significant Functional Requirements. In Proceedings of the 2015 IEEE/ACM 5th International Workshop on the Twin Peaks of Requirements and Architecture, Florence, Italy, 17 May 2015; pp. 3–8. [Google Scholar] [CrossRef]
- Tseng, M.M.; Jiao, J. A variant approach to product definition by recognizing functional requirement patterns. J. Eng. Des. 1997, 8, 329–340. [Google Scholar] [CrossRef]
- Formal Methods & Tools GroupNatural Language Requirements Dataset. Available online: http://fmt.isti.cnr.it/nlreqdataset/ (accessed on 20 April 2019).
- INSPIRE Helpdesk “MIWP 2014–2016” MIWP-16: Monitoring. Available online: https://ies-svn.jrc.ec.europa.eu/documents/33 (accessed on 20 April 2019).
- What Is a Functional Requirement? Specification, Types, EXAMPLES. Available online: https://www.guru99.com/functional-requirement-specification-example.html (accessed on 20 April 2019).
- Week 3: Requirement Analysis & Specification-ppt Video Online Download. Available online: https://slideplayer.com/slide/8979379/ (accessed on 20 April 2019).
- Keezhatta, M. Understanding EFL Linguistic Models through Relationship between Natural Language Processing and Artificial Intelligence Applications. Arab World Engl. J. 2019, 10, 251–262. [Google Scholar] [CrossRef]
- Petrović, D.; Stanković, M. The Influence of Text Preprocessing Methods and Tools on Calculating Text Similarity. Ser. Math. Inform. 2019, 34, 973–994. [Google Scholar]
- Brownlee, J. How to Prepare Text Data for Machine Learning with Scikit-Learn. Available online: https://machinelearningmastery.com/prepare-text-data-machine-learning-scikit-learn/ (accessed on 20 June 2020).
- Chauhan, V.K.; Dahiya, K.; Sharma, A. Problem formulations and solvers in linear SVM: A review. Artif. Intell. Rev. 2019, 52, 803–855. [Google Scholar] [CrossRef]
- Mukherjee, S.; Sharma, N. Intrusion Detection using Naive Bayes Classifier with Feature Reduction. Procedia Technol. 2012, 4, 119–128. [Google Scholar] [CrossRef]
- Lee, E.P.F.; Lee, E.P.F.; Lozeille, J.; Soldán, P.; Daire, S.E.; Dyke, J.M.; Wright, T.G. An ab initio study of RbO, CsO and FrO (X2∑+; A2∏) and their cations (X3∑-; A3∏). Phys. Chem. Chem. Phys. 2001, 3, 4863–4869. [Google Scholar] [CrossRef]
- Navlani, A. Understanding Logistic Regression in Python. Available online: https://www.datacamp.com/community/tutorials/understanding-logistic-regression-python (accessed on 15 June 2020).
- Arivoli, P.V. Empirical Evaluation of Machine Learning Algorithms for Automatic Document Classification. Int. J. Adv. Res. Comput. Sci. 2017, 8, 299–302. [Google Scholar] [CrossRef]
- Pham, B.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Du, T.; Yen, H.; Phong, T.; Nguyen, D.; Le, H.; Gholam, D.; et al. Performance Evaluation of Machine Learning Methods for Forest Fire Modeling and Prediction. Symmetry (Basel) 2020, 12, 1022. [Google Scholar] [CrossRef]
- Steinhaeuser, K.; Chawla, N.V.; Ganguly, A.R. Improving Inference of Gaussian Mixtures using Auxiliary Variables. Stat. Anal. Data Min. 2015, 8, 497–511. [Google Scholar] [CrossRef]
- Mohtadi, F. In Depth: Parameter Tuning for SVC. Available online: https://medium.com/all-things-ai/in-depth-parameter-tuning-for-svc-758215394769 (accessed on 20 June 2020).
- Fenner, M. Machine Learning with Python for Everyone Addison-Wesley Data & Analytics Series; Addison-Wesley Professional: Boston, MA, USA, 2019; ISBN1 0134845641. ISBN2 9780134845647. [Google Scholar]
- Qu, Y.; Qian, X.; Song, H.; Xing, Y.; Li, Z.; Tan, J. Soil moisture investigation utilizing machine learning approach based experimental data and Landsat5-TM images: A case study in the Mega City Beijing. Water (Switz.) 2018, 10, 423. [Google Scholar] [CrossRef]
- Rhys, H.I. Machine Learning with R, the Tidyverse, and mlr; Manning Publications: New York, NY, USA, 2020; p. 311. [Google Scholar]
- Hamed, T.; Dara, R.; Kremer, S.C. Intrusion Detection in Contemporary Environments. Comput. Inf. Secur. Handb. 2017, 109–130. [Google Scholar] [CrossRef]
- Raschka, S. EnsembleVoteClassifier-mlxtend. Available online: http://rasbt.github.io/mlxtend/user_guide/classifier/EnsembleVoteClassifier/ (accessed on 10 July 2020).
- Maheswari, J. Breaking the Curse of Small Datasets in Machine Learning: Part 1. Available online: https://towardsdatascience.com/breaking-the-curse-of-small-datasets-in-machine-learning-part-1-36f28b0c044d (accessed on 15 September 2020).
- Alencar, R. Dealing with Very Small Datasets. Available online: https://www.kaggle.com/rafjaa/dealing-with-very-small-datasets (accessed on 10 June 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Pupale, R. Support Vector Machines(SVM)—An Overview. Available online: https://towardsdatascience.com/https-medium-com-pupalerushikesh-svm-f4b42800e989 (accessed on 18 September 2020).
- Scikit-learn Sklearn.Naive_Bayes.Multinomialnb—Scikit-Learn 0.23.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html (accessed on 18 September 2020).
- Scikit-learn.org sklearn.svm.LinearSVC—Scikit-Learn 0.23.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html (accessed on 18 September 2020).
- Fraj, M. Ben InDepth: Parameter Tuning for Decision Tree. Available online: https://medium.com/@mohtedibf/indepth-parameter-tuning-for-decision-tree-6753118a03c3 (accessed on 18 September 2020).
- Kaggle Tuning Parameters for Logistic Regression. Available online: https://www.kaggle.com/joparga3/2-tuning-parameters-for-logistic-regression (accessed on 19 September 2020).
- Scikit-Learn Receiver Operating Characteristic (ROC). Available online: https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html (accessed on 18 September 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Accuracy (%) | Time (Seconds) | ||
|---|---|---|---|---|
| TF-IDF | Countvectorizer | TF-IDF | Countvectorizer | |
| Decision Tree(DT) | 73.0 | 96.0 | 0.123668 | 0.017952 |
| Support Vector Machine (SVM) | 79.0 | 99.0 | 0.097742 | 0.104719 |
| Support Vector Classification (SVC) | 75.0 | 97.0 | 1.979704 | 0.621348 |
| Logistic Regression(LR) | 79.0 | 99.0 | 0.016955 | 0.013964 |
| Naïve Bayes(NB) | 70.0 | 95.0 | 0.008976 | 0.007967 |
| Proposed Ensemble | 79.12 | 99.45 | 2.175181 | 0.750992 |
| Data Split (Testing: Training) Classifier | 50:50 | 40:60 | 30:70 | 20:80 | 10:90 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | Time (Seconds) | Accuracy (%) | Time (Seconds) | Accuracy (%) | Time (Seconds) | Accuracy (%) | Time (Seconds) | Accuracy (%) | Time (Seconds) | |
| DT | 96.0 | 0.040 | 95.0 | 0.032 | 96.0 | 0.018 | 97.0 | 0.080 | 97.0 | 0.064 |
| SVM | 99.0 | 0.288 | 99.0 | 0.216 | 99.0 | 0.105 | 99.0 | 0.256 | 100 | 0.280 |
| SVC | 97.0 | 1.280 | 97.0 | 1.549 | 97.0 | 0.621 | 97.0 | 2.175 | 97.0 | 2.435 |
| LR | 99.0 | 0.032 | 98.0 | 0.032 | 99.0 | 0.014 | 99.0 | 0.040 | 100 | 0.040 |
| NB | 94.0 | 0.024 | 95.0 | 0.016 | 95.0 | 0.008 | 96.0 | 0.024 | 93.0 | 0.016 |
| Proposed Ensemble | 99.3 | 1.567 | 99.1 | 1.855 | 99.45 | 0.751 | 99.1 | 2.614 | 100 | 2.866 |
| Classifier | Accuracy (%) | Time (Seconds) |
|---|---|---|
| SVM | 99.0 | 0.084772 |
| SVC | 97.0 | 0.612361 |
| Logistic Regression | 99.0 | 0.017953 |
| Proposed Ensemble | 99.45 | 0.740020 |
| Classifier | Accuracy (%) | Time (Seconds) |
|---|---|---|
| Decision Tree | 96.0 | 0.013962 |
| Logistic Regression | 99.0 | 0.012965 |
| Naïve Bayes | 95.0 | 0.006983 |
| Proposed Ensemble | 95.05 | 0.037898 |
| Ensemble | Accuracy (%) | Time (Seconds) |
|---|---|---|
| Mean Ensemble Voting | 97.80 | 0.001001 |
| Weighted Ensemble Voting (classifier Importance as weight) | 98.35 | 0.001001 |
| Accuracy as Weight Ensemble | 97.25 | 0.749387 |
| Proposed Ensemble | 99.45 | 0.740020 |
| Reference# (Year) | Classes | Methodology | Dataset | Results | |
|---|---|---|---|---|---|
| Traditional Classification Technique | [19] (2009) | Solution Enablement Action Constraint Attribute Constraint Definition Policy | Lexical Analyzer Syntactic Analyzer | Not specified | 30–50% reduction in time needed to review requirements |
| [20] (2011) | Solution Enablement Action Constraint Attribute Constraint Definition Policy | Lexical Analyzer Syntactic Analyzer | Not specified | Many ambiguities were resolved while translating software requirements between English and Arabic. | |
| [3] (2012) | Data input Data output Data validation Business logic Data Persistence Communication Event Trigger User Interface User Interface Navigation User Interface Logic Event Trigger External Call External Behavior | Use of frequency distributions as a means to characterize the phenomena of interest in a particular domain. | 15 software projects with 1236 FR statements. | The highest percentage was for the output data class with a percentage of 26.37% | |
| [22] (2018) | Solution Enablement Action Constraint Attribute Constraint Definition Policy |
| 40 requirements | Classification and transformation processes are not straightforward | |
| [23] (2019) | Security Requirement Templates such as Authorized access Confidentiality during storage Confidentiality during transmission Unique accounts Logging authentication Events |
| Not specified | Time: ranged from 20 min to 193 min Quality: from 2.66 to 4.57 (scale from 1 to 5) | |
| ML Classification Technique | [18] (2018) | Requirements for user interfaces Requirements for databases Requirements for system functions Requirements for external interfaces | Convolutional Neural Networks (CNN) | Software Requirement Specification (SRS) in the Japanese language including 13 systems 11,538 FR-QR- Non-Requirements (Unbalanced data) | Precision: 0.89 Recall: 0.94 F-score: 0.91 |
| [1] (2015) | External Communication Business Constraints Business Workflow User Interactions User Privileges User Interfaces Entity Modelling | Naïve Bayes Bayes net K-Nearest Neighborhood Random Forest | Eight documents with different numbers of FR statements ranging from 208 to 6187. | Precision: from 0.39 to 0.60 Recall: from 0.40 to 0.71 F-measure: from 0.47 to 0.60 | |
| [24] (2015) | Audit trail Batch processing localization Communication Payments Printing Reporting Searching Third party interactions Workflow | Multinomial Naïve Bayes | 450 FR statements selected from the insurance domain | Recall ranged from 28% to 90% Precision ranged from 50% to 100%. | |
| [25] (97) | Safety requirements Electrical specifications General specifications Power failure detection Federal Communications Commission (FCC) Mechanical specification regulations Ripple | Conceptual Clustering | Case study of power supply product designs | This approach opens the opportunity to utilize historical knowledge through experts on FR patterns. | |
| Proposed Approach | Solution Enablement Action Constraints Attribute Constraints Definitions Policy | Naïve Bayes, Support Vector Machine (SVM), Decision Tree, Logistic Regression, and Support Vector Classification (SVC). | 600 FR statements, as there were 100 FR statements from each class. | Accuracy: 99.45% Time: 0.7 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahimi, N.; Eassa, F.; Elrefaei, L. An Ensemble Machine Learning Technique for Functional Requirement Classification. Symmetry 2020, 12, 1601. https://doi.org/10.3390/sym12101601
Rahimi N, Eassa F, Elrefaei L. An Ensemble Machine Learning Technique for Functional Requirement Classification. Symmetry. 2020; 12(10):1601. https://doi.org/10.3390/sym12101601
Chicago/Turabian StyleRahimi, Nouf, Fathy Eassa, and Lamiaa Elrefaei. 2020. "An Ensemble Machine Learning Technique for Functional Requirement Classification" Symmetry 12, no. 10: 1601. https://doi.org/10.3390/sym12101601
APA StyleRahimi, N., Eassa, F., & Elrefaei, L. (2020). An Ensemble Machine Learning Technique for Functional Requirement Classification. Symmetry, 12(10), 1601. https://doi.org/10.3390/sym12101601