An Efficient MapReduce-Based Parallel Processing Framework for User-Based Collaborative Filtering


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminaries
2.1. User-Based Collaborative Filtering
2.2. MapReduce
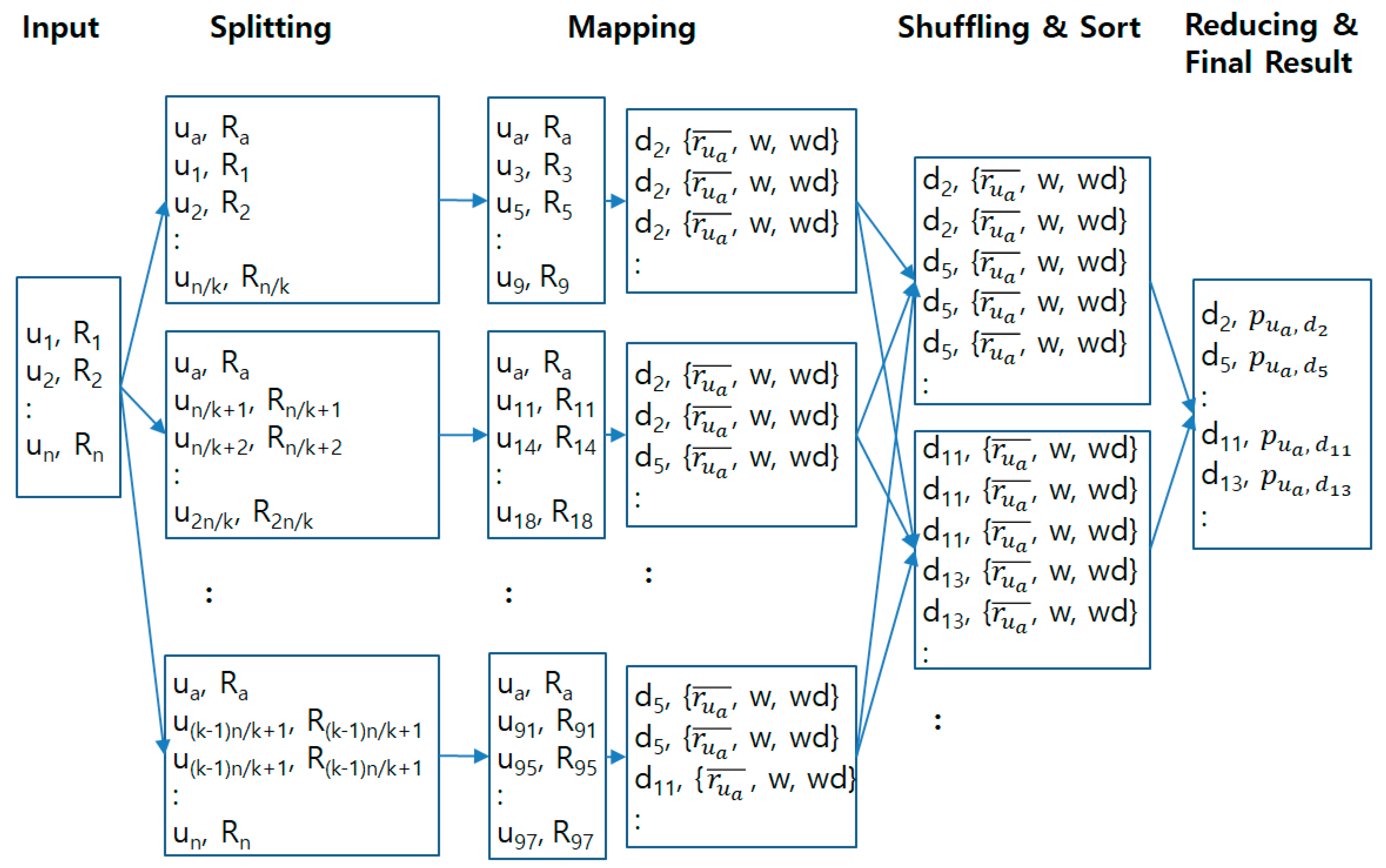
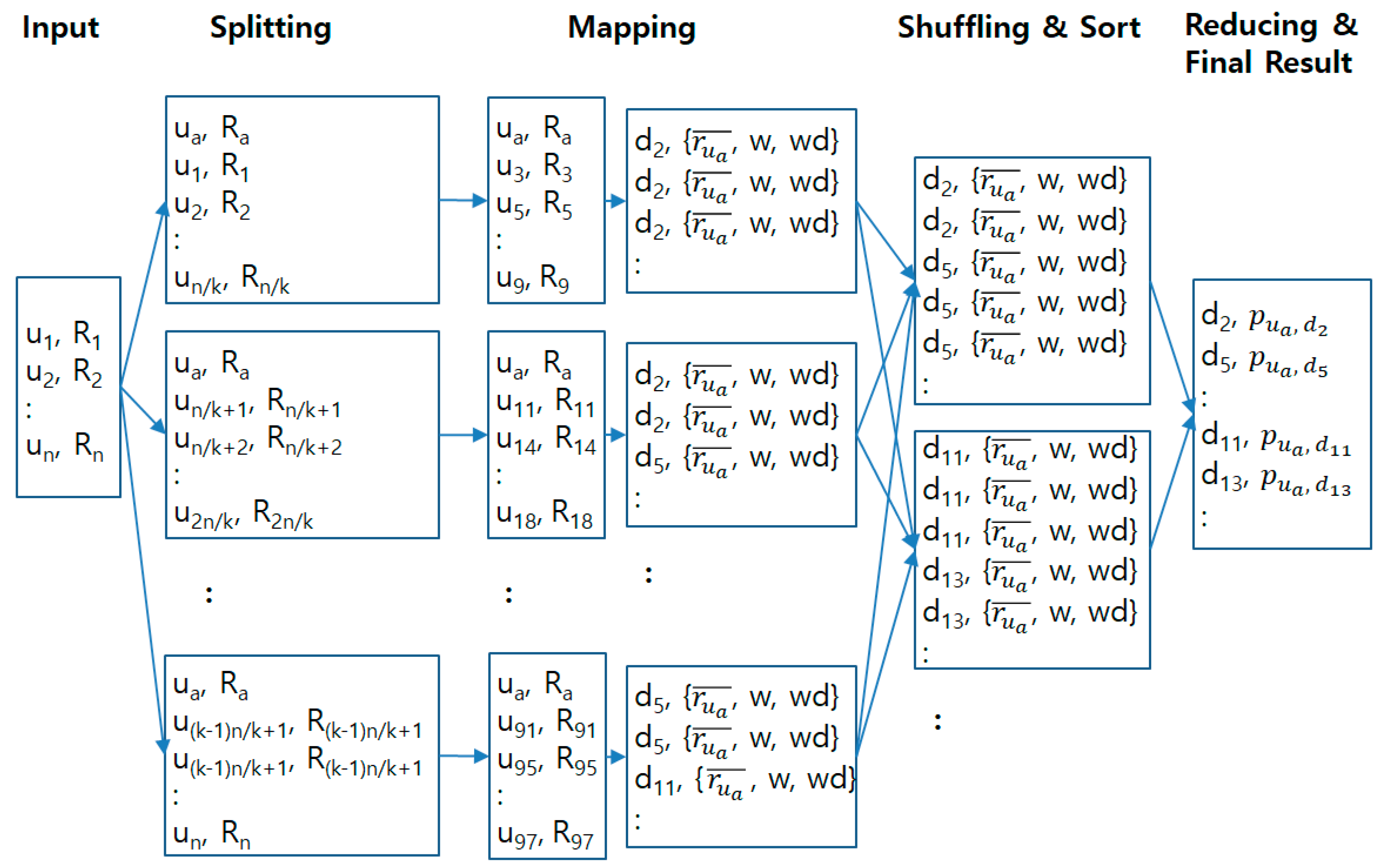
3. MapReduce-Based Parallel Processing Method for Collaborative Filtering
3.1. Mapping Phase
3.2. Reducing Phase
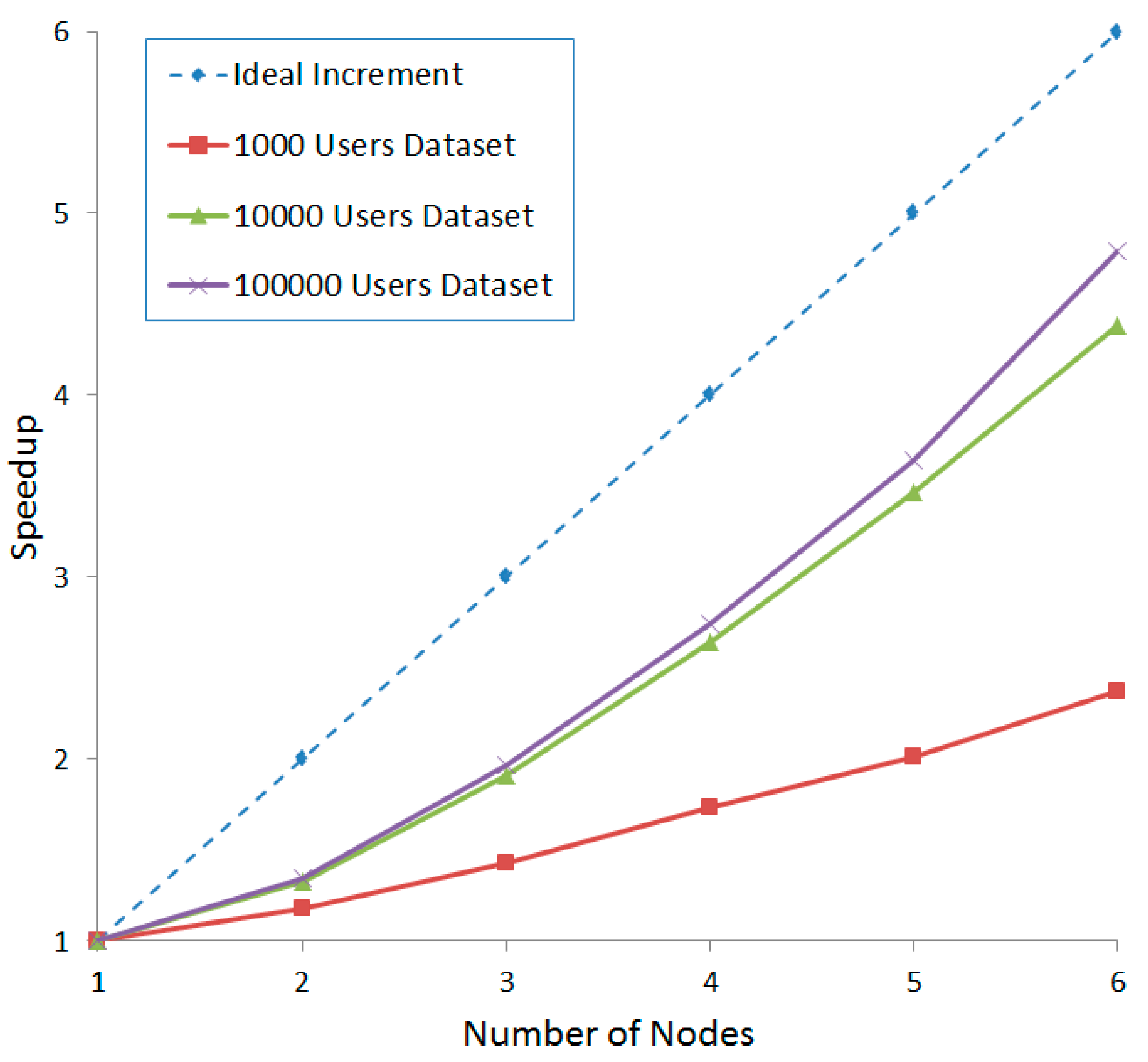
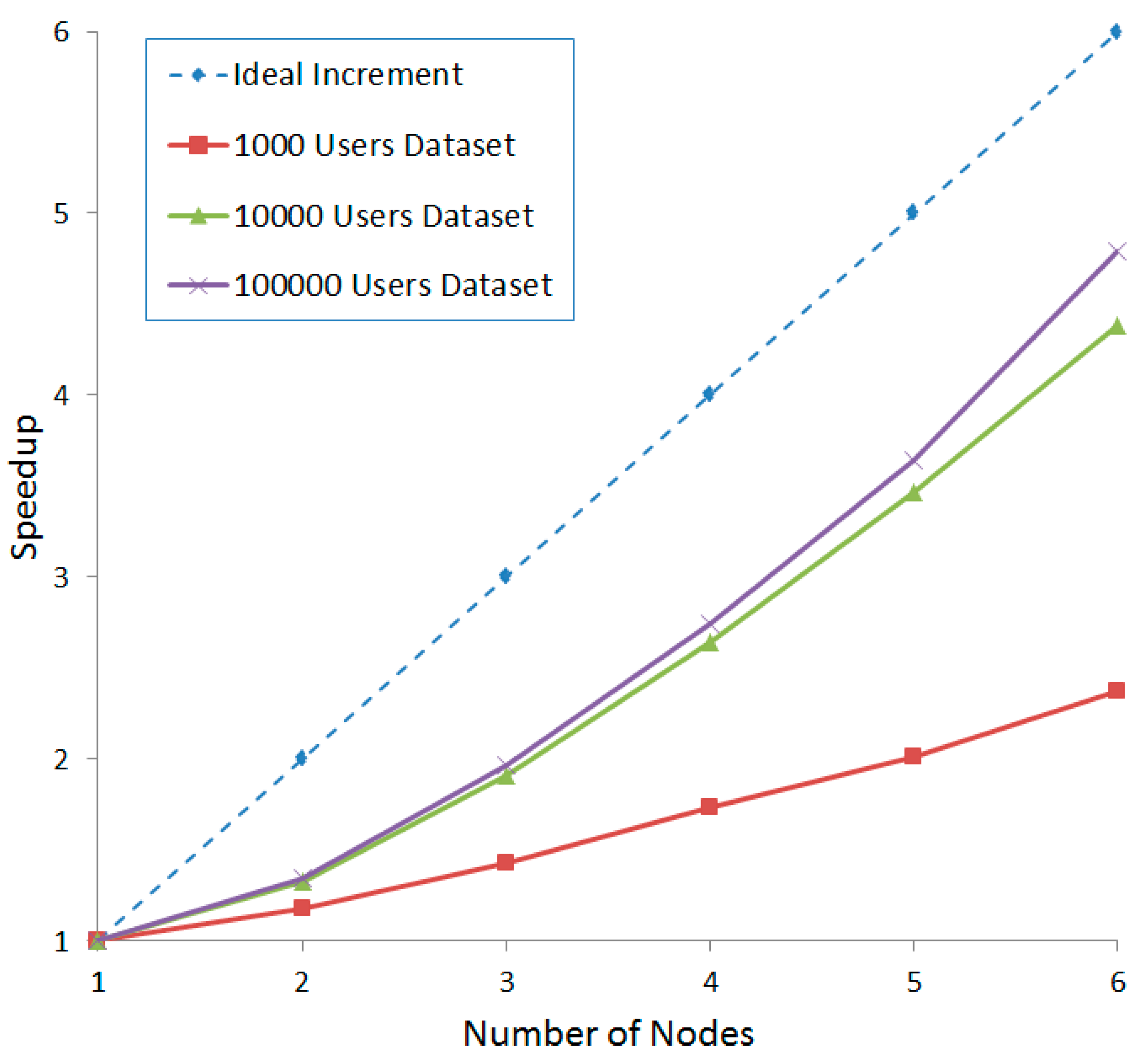
4. Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Bell, R.M.; Koren, Y. Improved neighborhood-based collaborative filtering. In Proceedings of the KDD cup and workshop at the 13th ACM SIGKDD international conference on knowledge discovery and data mining, San Jose, CA, USA, 12 August 2007; pp. 7–14. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 1, 76–80. [Google Scholar] [CrossRef]
- Hadoop. Available online: http://hadoop.apache.org/ (accessed on 15 May 2019).
- Borthakur, D. The hadoop distributed file system: Architecture and design. Hadoop Proj. Website 2007, 11, 1–21. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Verma, J.P.; Patel, B.; Patel, A. Big data analysis: Recommendation system with Hadoop framework. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence & Communication Technology, Ghaziabad, India, 13 February 2015; pp. 92–97. [Google Scholar]
- Sharma, S.; Sethi, M. Implementing Collaborative Filtering on Large Scale Data Using Hadoop And Mahout. Int. Res. J. Eng. Technol. (IRJET) 2015, 2, 102–106. [Google Scholar]
- Shen, F.; Jiamthapthaksin, R. Dimension independent cosine similarity for collaborative filtering using MapReduce. In Proceedings of the 2016 8th International Conference on Knowledge and Smart Technology (KST), Chiangmai, Thailand, 3 February 2016; pp. 72–76. [Google Scholar]
- Cai, R.; Li, C. Research on collaborative filtering algorithm based on MapReduce. In Proceedings of the 2016 9th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 10 December 2016; pp. 370–374. [Google Scholar]
- Tang, H.; Cheng, X. Personalized E-commerce recommendation system based on collaborative filtering under Hadoop. World 2017, 1, 146–148. [Google Scholar]
- Konstan, J.A.; Miller, B.N.; Maltz, D.; Herlocker, J.L.; Gordon, L.R.; Riedl, J. Grouplens: Applying collaborative filtering to usenet news. Commun. ACM 1997, 40, 77–87. [Google Scholar] [CrossRef]
- White, T. Hadoop: The Definitive Guide, 4th ed.; O’Reilly Media: Cambridge, UK, 2015. [Google Scholar]
- MovieLens Dataset. Available online: https://grouplens.org/datasets/movielens/ (accessed on 15 May 2019).
- Karydi, E.; Margaritis, K. Parallel and distributed collaborative filtering: A survey. ACM Comput. Surv. (CSUR) 2016, 49, 1–37. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X. A New Parallel Item-Based Collaborative Filtering Algorithm Based on Hadoop. JSW 2015, 10, 416–426. [Google Scholar] [CrossRef]
- Gupta, A.K.; Varshney, P.; Kumar, A.; Prasad, B.R.; Agarwal, S. Evaluation of MapReduce-Based Distributed Parallel Machine Learning Algorithms. In Advances in Big Data and Cloud Computing; Rajsingh, E.B., Veerasamy, J., Alavi, A.H., Peter, J.D., Eds.; Springer: New York, NY, USA, 2018; pp. 101–111. [Google Scholar]
- Diedhiou, C.; Carpenter, B.; Shafi, A.; Sarkar, S.; Esmeli, R.; Gadsdon, R. Performance Comparison of a Parallel Recommender Algorithm Across Three Hadoop-Based Frameworks. In Proceedings of the 30th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Lyon, France, 24–27 September 2018; pp. 380–387. [Google Scholar]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, H.; CHA, K.J. An Efficient MapReduce-Based Parallel Processing Framework for User-Based Collaborative Filtering. Symmetry 2019, 11, 748. https://doi.org/10.3390/sym11060748
Jeong H, CHA KJ. An Efficient MapReduce-Based Parallel Processing Framework for User-Based Collaborative Filtering. Symmetry. 2019; 11(6):748. https://doi.org/10.3390/sym11060748
Chicago/Turabian StyleJeong, Hanjo, and Kyung Jin CHA. 2019. "An Efficient MapReduce-Based Parallel Processing Framework for User-Based Collaborative Filtering" Symmetry 11, no. 6: 748. https://doi.org/10.3390/sym11060748
APA StyleJeong, H., & CHA, K. J. (2019). An Efficient MapReduce-Based Parallel Processing Framework for User-Based Collaborative Filtering. Symmetry, 11(6), 748. https://doi.org/10.3390/sym11060748