2.1. Optic Disc and Cup Segmentation
The optic disc (OD) is a clinical intense fundus feature and is considered as a preliminary indicator of retinal vessel, optic cup (OC), macula, and fovea detection in fundus photographs. Localization and segmentation of the OD boundary indicates a disc contour and center. Most OD extraction approaches in the literature are based on morphological and geometrical-based methods, as explained in the subsequent paragraphs.
Considering the significance of optic disc segmentation for reliable glaucoma and DR screening, the author in [
23] considered morphological features to segment the OD boundary. The finite impulse response (FIR) filter was applied to remove retinal vessels and to extract morphological features for disc extraction. The author reported an average accuracy of 98.95% using a small set of images. However, the algorithm was unsuccessful on low bright disc color images. Similarly, Alshayeji et al. in [
24] applied an edge detection algorithm based on a gravitational law followed by pre- and post-processing steps for OD segmentation. They showed an accuracy of 95.91% with a cost of high running time. A real-time approach was developed in [
25] for OD segmentation, in which the disc boundary was extracted after the removal of vessels using a region growing adaptive threshold and ellipse fitting methods. They obtained an accuracy of 91%.
The authors in [
26] used the green plane of a fundus image for OD detection because it provides much higher information. They determined an accuracy of 94.7%. Abed et al. in [
27] presented a hybrid nature-inspired model named swarm intelligence with a pre-processing stage for OD segmentation. The authors obtained an average accuracy of 98.45% with less running time than other published methods. However, this model is highly dependent on preprocessing steps and algorithm parameters. Some other CAD algorithms have been developed based on the geometrical principle for OD segmentation with higher accuracy, such as the Hough circle cloud [
28], ensemble of probability models [
29], sliding band filter [
30], and active contour models [
31,
32]. In a previous study [
28], a fully automated software called Hough circle cloud was developed for OD localization. This yielded an average accuracy of 99.6%. However, the software was tested on a small dataset and was implemented on powerful graphical processing units (GPUs) instead of local computers. The system proposed in [
29] addressed the strengths of different object detection methods for OD segmentation. The authors achieved an accuracy of 98.91%. Nevertheless, the application was computationally expensive, i.e., based on pre-/post-processing steps and dependencies of each algorithm member existed.
A multi-resolution sliding band filter (SBF) was employed by [
30] to locate the OD area. After the elimination of the vessel structure, a low resolution SBF was used on the cropped images and achieved an initial estimation of the disc. High resolution SBF was then applied on the initial disc points to obtain a final approximation of the OD. The final disc area was selected by obtaining the maximum number of responses from a high resolution SBF and smoothing method, and obtained an average overlapping area of 85.66%. However, this scheme was noticeably less competitive on a complex pattern of a few retinal samples. The studies reported in [
31,
32] presented a performance comparison of 10 region-based active contour models (ACMs) for OD localization. Among these methods, the gradient vector flow (GVF)-ACM was found to be superior regarding the OD segmentation with a 97% accuracy. However, both these methods were evaluated on small datasets followed by pre-/post-processing steps. To detect the disc area, the authors of [
33] used the vessel direction, intensity, and bright area of the disc. These features were extracted using geometric methods and then combined through the confidence score method. The highest confidence value indicates accurate OD segmentation. The algorithm was tested on a small number of images and was reported as being robust in the presence of other bright lesions, with, on average, a 98.2% accuracy.
Optic cup boundary extraction is also a tedious task because of the interweavement of blood vessels around the cup region. In addition, OC is a brightest yellowish feature of fundus images that resides within the disc region and is a preliminary sign of glaucoma retinopathy [
34,
35]. OC segmentation methods in the literature can be categorized into machine learning and pixel-based classification schemes, as covered in the following subsection.
Tan et al. in [
36] developed a fully automated OC detection algorithm based on a multiscale super-pixel classification model. They employed different ranges of multi-scale pixel approaches for retinal vessel removal and image normalization. Finally, the cup area was localized using a combination of sparsity-based multiscale super-pixel models. The authors obtained significant results (7.12% higher rate than other methods) for OC localization. However, the scheme was computationally expensive and was tested on a small number of images. The authors in [
37] suggested entropy sampling and a convolutional neural network (CNN) for cup segmentation using a small amount of images. The authors yielded a classification accuracy of 94.1%. Although, the method was unsuccessful in translating the sampling points to obtain more reliable results. Chakravarty and Sivaswamy in [
38] proposed a joint segmentation model for disc and cup boundary extraction. Textural features of the disc and cup were extracted using the coupled and sparse dictionary approaches. These selected features were finally applied for cup detection. Their system achieved 0.85 of the area under the receiving operating curve (AUC) in the optic cup boundary extraction. Nevertheless, their proposed application was less impressive in estimating the cup-to-disc (CDR). In a previous study [
39], an ant colony optimization (ACO) algorithm was considered for OC segmentation. Their software reported an AUC of 0.79. However, the method was unsuccessful on few samples to characterize the cup boundary. Complementary features of both the disc and cup from the fundus and spectral domain optical coherence tomography (SD-OCT) modalities have shown great potential for OC extraction [
40]. An adaptive threshold approach was applied by Issac et al. in [
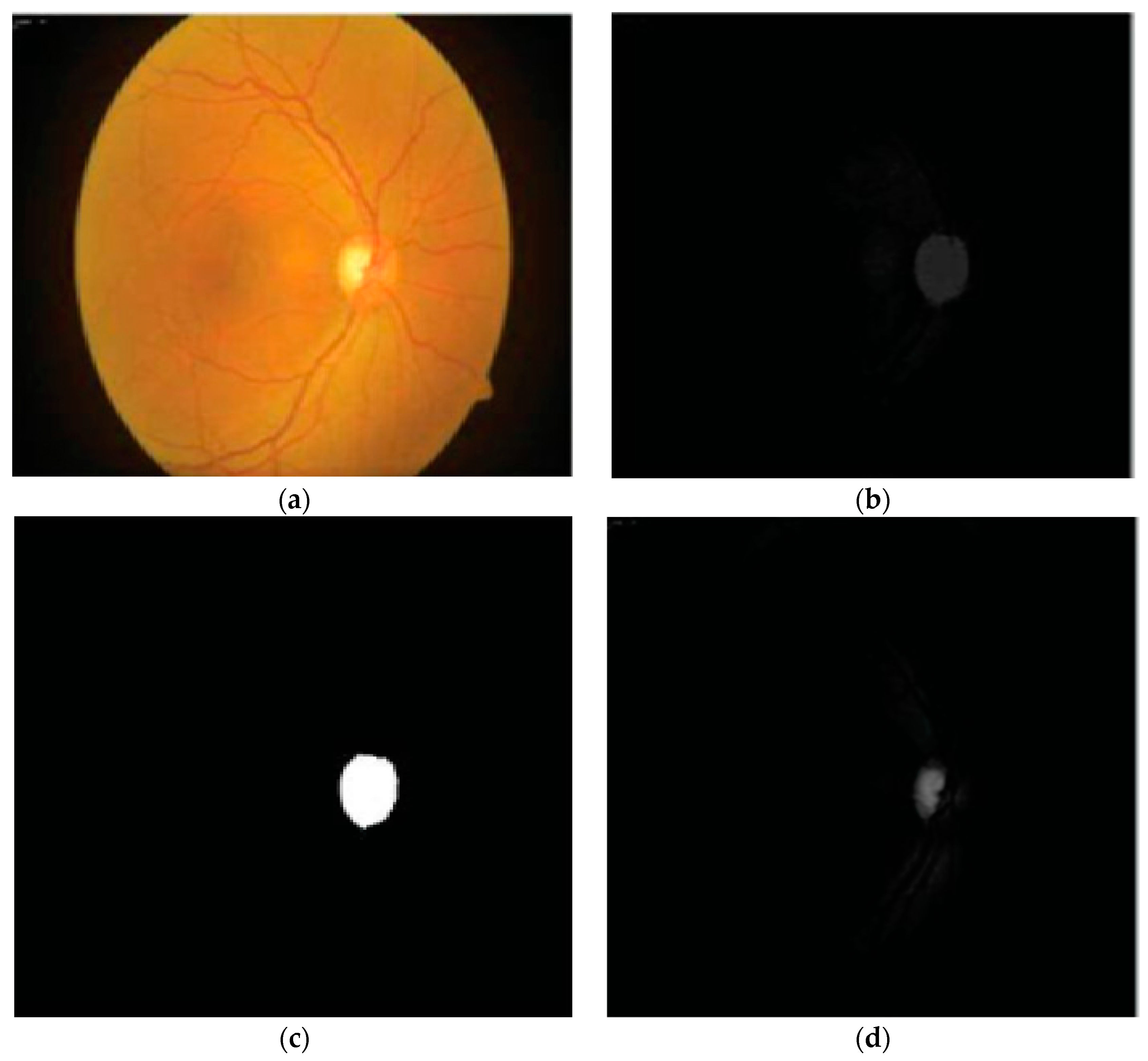
41] for disc and cup segmentation. Color features, e.g., mean and standard deviation, were computed from the fundus image and then applied for the subtraction of background parts of the OD and OC. Finally, OD and OC boundaries were extracted from the red and green channels, as shown in
Figure 3. The authors reported an accuracy of 92%. However, their scheme was tested on a small dataset and failed on low contrast images. A summary of the aforementioned disc and cup extraction approaches is given in
Table 2, illustrating the particular method, datasets used, and the number of images.
2.2. Blood Vessel Extraction
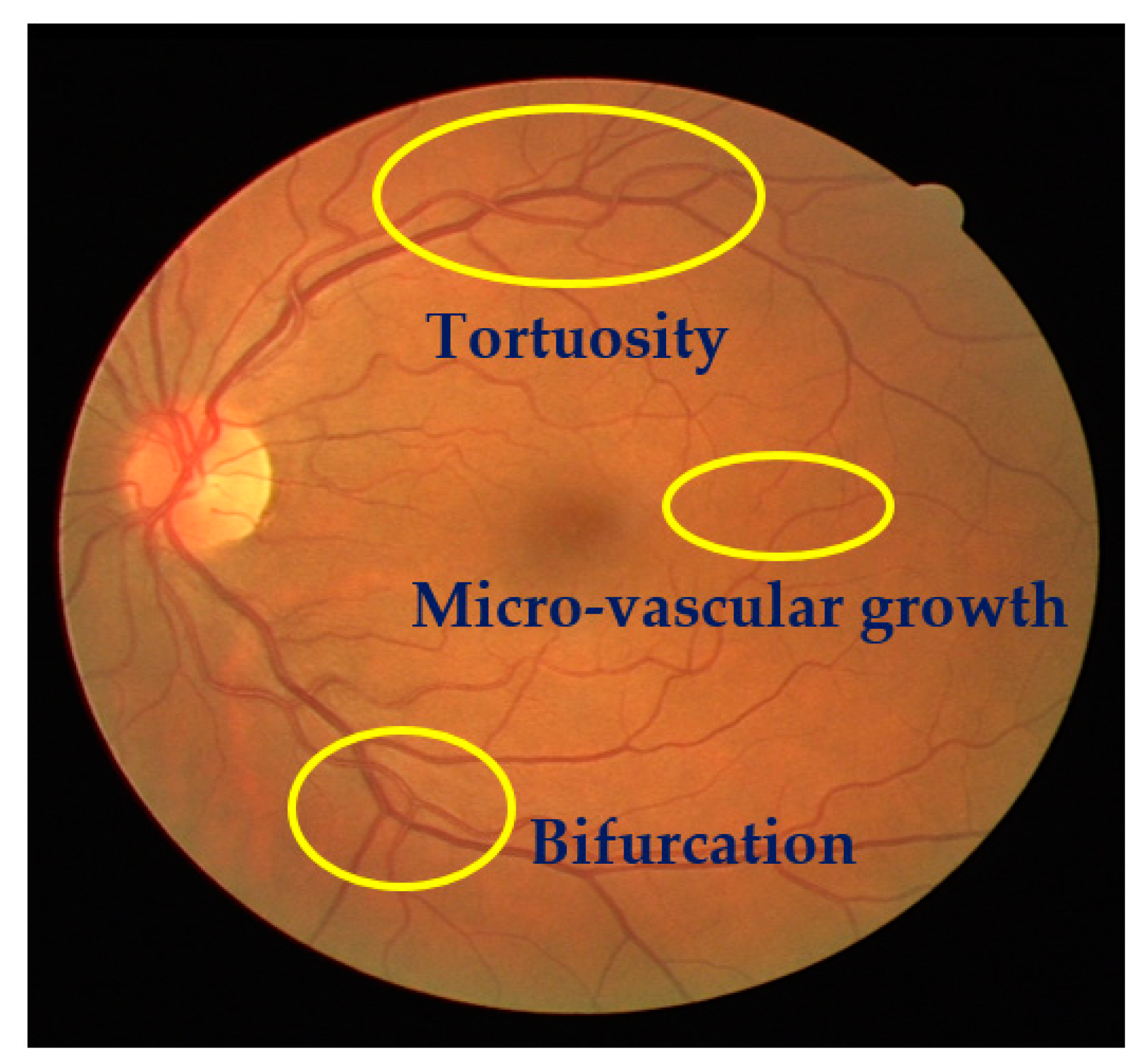
The detection of structural changes of the retinal vascularization system in color fundus angiography is a critical and repetitive task for clinical personnel. Accurate vessel segmentation leads to fast and reliable assessment by the DR-CAD system. Additionally, the detection of geometrical-based vessel features and secular changes of vessels, as shown in
Figure 4, assists less experienced doctors in the accurate diagnosis of DR. Retinal vessel segmentation methods in the literature can be divided into three groups: Supervised-based, unsupervised-based, and mathematical morphology-based methods.
Kaur and Mittal in [
42] developed a vascular detection system using fundus images. Preprocessing was initially done to normalize the images from low contrast and non-uniform illumination. They extracted the pixel intensity and geometric features using a matched filter and then fed these to a neural network classifier to classify vessels from a non-vascular region. The authors obtained an accuracy of 95.45%. Their intermediate results are shown in
Figure 5. However, the approach had less significance in the detection of lesions that contribute to an incorrect vascular structure. Neto et al. in [
43] presented an unsupervised coarse segmentation approach for vessel detection with an average accuracy of 87%. They incorporated multiple concepts, i.e., mathematical morphology, curvature, and spatial dependency, with the coarse-to-fine method to accurately define thin and elongated vessels from vessel pixels. However, the algorithm was unsuccessful in the determination of the vessel diameter and was also found to be less satisfactory at segmenting vessel structures on low contrast images. To detect changes in the structural and micro-pattern of vessels, several textural descriptors were applied to extract vascular features. These features were fed into a forest classifier to classify true vessel points from non-vessel patterns [
44]. A sensitivity (SE) of 96.1% and specificity (SP) of 92.2% in the classification of true vessel points was reported. A comprehensive review of supervised-related, unsupervised-related, image processing-related, and data mining-related algorithms is presented in [
45,
46,
47] with high vessel segmentation results.
The study in [
46] combined normal and abnormal retinal features with the patient’s contextual information at adaptive granularity levels through data mining methods to segment retinal vessels. The authors obtained more significant results than existing methods on larger datasets for the detection of vessels and other retinal pathologies. However, the system running time was highly expensive. Another study in [
47] used the sequential application of image pre-/post-processing and data mining methods for vessel segmentation. Their framework reported an accuracy of 95.36% at the cost of a long processing time and low specificity (SP) for vessel segmentation. Zhang et al. [
48] proposed an unsupervised vessel segmentation approach in which labelling inconsistencies from ground truth labels were optimized. Key point descriptors were furnished to generate a texton dictionary to distinguish vessel pixels from on-vessel intensities. The approach yielded an accuracy of 95.05%. However, this method suffers from false positive results around the disc and the left part of the peripheral region. These limitations can be overcome by utilizing some pre-processing steps in the future. Tan et al. [
49] implemented a seven-layer-based convolutional neural network (CNN) for the segmentation of retinal vessels and reported a classification accuracy of 94.54%. Wang et al. [
50] also used a CNN model with ensemble learning for vessel segmentation. They employed two classifiers, including CNN and random forest classifier, after image normalization to classify vessel parts from non-vessel structures. They obtained a classification accuracy of 97.5% at the cost of a long training time. Few machine learning techniques have been shown to have an excellent performance in vessel detection using retinal angiography, e.g., hybrid feature vector and random forest classifier [
51], gumbel probability distribution (GPD) [
52], and direction map [
53]. The tool in [
51] incorporated robust features from various algorithms into a 17-dimensional feature vector for vessel pixel characterization. This feature vector was then processed by the random forest classifier to distinguish vessel pixels from non-vessel pixels, and yielded an accuracy of 96%. Their proposed method was found to be computationally expensive because it followed 13 gabor filters to extract vessel features.
In a previous study [
52], a novel matched filter named GPD was implemented after image contrast enhancement using PCA greyscale conversion and adaptive local contrast enhancement methods. A sequence of experiments was executed to select an optimal parameter that was then used to design a GDP filter. Finally, clearer vessel structures were extracted after post-processing followed by thresholding and length filtering with a 0.91 AUC. The authors in [
53] recommended a direction map strategy called SEVERE (segmenting vessels in retina images) for vessel segmentation. They considered a green channel image from the color RGB image without following any preprocessing steps, and then direction maps were utilized for the segmentation of vessel patterns within images. Their method achieved an accuracy of 97%. Hassan et al. [
54] used mathematical morphology for the accurate segmentation of retinal vessels. A smoothing operation was applied to enhance the vessel structure, and then vessel classification was performed using the K-means algorithm, with a 96.25% accuracy. Eysteinn et al. [
55] applied an unsupervised model followed by a morphological approach and fuzzy classification for retinal vessel classification. The model achieved a classification accuracy of 94%. However, their method was computationally expensive and depended on human labeled data.
Differentiation among thin and thick retinal vessels has become a challenging task due to the existence of low contrast, the illumination of images, and the existence of bright lesions. For this reason, hybrid methods, like the phase-preserving denoising method, fuzzy conditional entropy (FCE) techniques, and saliency with active contour models, were exploited in [
56,
57,
58] to detect thin and thick vessels. The authors in [
56] recommended a multimodal mechanism for thin and thick vessel segmentation. Thin vessels were identified by using a phase-preserving line detection method after the subtraction of poor image quality, while the approximate level of thick vessels was identified using a maximum entropy thresholding method. Their application was noticeably powerful in the discrimination of thin and thick vessel structures in retinal images, with a 0.95 AUC. In a previous study [
57], an integrated system was designed for the automatic extraction of diverse structures of blood vessels from fundus images. Original images were normalized using curvelet denoising and a band pass filter (BPF) to remove noise and enhance the contrast of thin vessels. A matched filter response was considered as a dataset by the FCE algorithm to identify the best thresholds. The differential evolution method was utilized on the best thresholds for the extraction of different vessel outlines, like thin, thick, and medium vessels, with an average accuracy of 96.22%. The multiplication of reflection and illumination components, called retinex theory, was applied to stable thin vessel contrast and global image quality. Afterwards, an image was divided into super-pixels and given to the saliency method to find interesting vessel regions. To refine the vessel detection results, an infinite ACM was considered to distinguish the complex patterns of vessels, yielding a 0.8 AUC [
58].
Line detection and pixel-based techniques were applied in [
59] for the segmentation of small vessels. After preprocessing, the line detection method was implemented for image segmentation. Long and medium size vessels were then localized using the adaptive thresholding method. Finally, the pixel-based tensor voting procedure was applied by for small vessel extraction. Farokhian et al. in [
60] considered a bank of 180 Gabor filters followed by the optimization method, called an imperialism competitive algorithm, for vessel segmentation and reported a 93% precision. A Gabor filter is designed on the rotation degree of 1 scale to detect image and vessel edges. Next, an optimization method was then employed for accurate vessel segmentation. Similarly, a template matching approach using a Gabor function for the detection of the center of vessel lines after specification of the region of interest was considered in [
61] for low contrast thin vessel structure extraction and presented a 96% accuracy. The template matching method was used to produce a binary segmented image and then binary image contours were reconstructed to match the image characteristics with the manually annotated contours in the training dataset. Eventually, low contrast thin vessels were extracted using a large dataset. All these mathematical morphology-based methods are reported as being less satisfactory based on the following reasons: (i) A large number of pre-/post-processing steps were utilized to extract the vessel tree; (ii) methods were tested on a small set of retinal images and had limited cover of the varied-sized locations of an image; and (iii) reported a much higher running time during the detection of vessel patterns, which, in practice, are less reliable in screening programs.
Kar and Maity [
62] proposed a vessel extraction system based on the matched filter followed by curvelet and fuzzy c-mean algorithms. Initially, a curvelet transformation was applied to detect an object’s edges and lines. Further, a fuzzy c-mean algorithm was incorporated for vessel tree extraction, yielding an accuracy of 96.75%. Their method was unable to achieve a higher true positive rate. Zhao et al. [
63] suggested a level set and region growing method for the segmentation of retinal vessels. They achieved an accuracy of 94.93%. A hardware-based portable application was proposed by Koukounis et al.
In [
64], for the accurate segmentation of blood vessels., a proposed tool was used to segment vessels in three steps: First, a green channel of an RGB image was selected in the preprocessing step to improve the image quality; second, a matched filter was utilized on the normalized image to highlight the vessel points; and finally, different thresholds were applied for accurate vessel segmentation. However, the scheme was expensive regarding the capturing and loading of images. Imani et al. [
65] presented a morphological component analysis (MCA) model for vessel segmentation, which showed a 95% accuracy. Contrast improvement of vessels was first completed and then MCA was employed for vessel and lesion segmentation. However, the approach was limited to the detection of complex components of an image, like large lesions and vessel tortuosity. A summary of the blood vessel detection algorithms is shown in
Table 3, highlighting the utilized methods and databases and their size.
2.3. DR-Related Lesion Detection Methods
MA and HM localization and extraction is a challenging job due to varied size, color, and textural features on the fundus angiography. Therefore, the development of fast and reliable automated DR lesion detection tools is still a hot research area. Few recent studies regarding accurate MA and HM detection were encountered in the literature. MA assessment methods are divided into mathematical morphology, supervised-, and unsupervised-based methods, while HM segmentation methods are based on mathematical morphology, image processing, and machine learning-based methods, as described in the following subsections.
Habib et al. in [
66] developed an intelligent MA detection application using color fundus images. They extracted MA features using the Gaussian matched filter and fed these to a tree ensemble classifier to classify true MA points from false MA pixels. The authors achieved a receiver operating curve score (ROC) of 0.415. The disadvantage of their proposed method is that it does not avoid the overfitting problem and is unable to define a standard feature selection principle. Kumar et al. in [
67] also considered a Gaussian filter to extract MA features from images. A green channel was selected for further processing, i.e., the removal of vessels and the optic disc using a watershed transformation method to localize the MA region. Finally, microaneurysms were segmented using a Gaussian matched filter with an accuracy of 93.41%. Similarly, canny edge and maximum entropy-based methods were utilized by Sreng et al. in [
68] to detect MAs in fundus images. After the removal of vessels and the disc area in the image normalization step, MA patterns were segmented using canny edge and entropy methods. To obtain prominent MA marks within the image, a morphological operation followed by erosion was employed to identify MA patterns, obtaining an accuracy of 90%. Both these methods [
67,
68] were unsuccessful in overcoming spurious signals during micro-aneurysm detection. The authors in [
69] applied Gaussian, median, and kirsch filters to the green component of an RGB image to extract MA features. Those MA features were then fed to a multi-agent model to discriminate true MA pixels from non-MA pixels, yielding an ROC of 0.24. They did not evaluate all possible image locations for optimum MA detection.
In a previous study [
70], a series of image processing techniques, such as contrast enhancement and feature extraction, were used to present some novel hypotheses for improved MA detection software. Wu et al. in [
71] considered some local and profile features for MA detection. First, images were processed to reduce noise and other image artifacts to enhance the MA region. Further, a K-mean-based neural network classifier was utilized on the image features to classify MA pixels from non-MA pixels. The authors obtained an ROC of 0.202. Nevertheless, use of the approach on the very noisy images failed to localize MA pixels. Romero et al. in [
72] recommended bottom-hat and hit-or-miss transform methods for MA extraction after normalization of the gray contents of an image. To obtain an intact reddish region with a brighter part, a bottom-hat transformation was applied on the gray scale image. Blood vessel elimination was done using a hit/miss transformation application and finally, principal component analysis (PCA) and radon transform (RT) were applied to detect true MA points. They achieved a classification accuracy of 95.93%. Similarly, a top-hat transformation and an average-based filter was applied in [
73] for the elimination of retinal anatomic components with a 100% specificity. Afterwards, a Radon transform (RT) and multi-overlapping window were utilized for the cleavage of an optic nerve head (ONH) and MAs. The authors achieved an SE of 94%. However, the methods in [
72,
73] were computationally expensive and could not locate MA points in the low contrast MA pixels. For the segmentation of tiny and poor contrast MA features, a naïve Bayes classifier and location-based contrast enhancement were implemented in [
74,
75], with significant MA results.
The authors in [
74] considered a coarse segmentation method to initially localize the MA candidate region. Further, a naïve Bayes classifier was applied to extracted MA pixels and discriminated true MA points from non-MA points, yielding a classification accuracy of 99.99% and an SE of 82.64%. However, their classifier, i.e., naïve Bayes, was computationally expensive during training and was also limited on faint and blur MA pixels. To solve this problem, a contrast limited adaptive histogram equalization (CLAHE) technique was implemented in [
75] to detect poor contrast and blurry MA pixels. They divided input images into small and contextual tiles in order to detect tiny and low contrast MA pixels. They obtained an SE of 85.68%. However, their approach was only tested on 47 images, which limits its generalizability to other medical ailments. A sparse representation classifier (SRC) was applied in [
76] followed by dictionary learning (DL) to detect MA pixels. Initially, a Gaussian correlation filter was incorporated to localize the MA region. Further, those MA features were given to the SRC to classify true MA points from non-MA pixels. The authors achieved an SE of a 0.8% increase rate. However, their proposed dictionaries were generated artificially, thus lacking discriminative power in MA detection. Akram et al. in [
77] implemented a system to grade whether retina images belong to MA or non-MA regions. The authors obtained an accuracy of 99.40%. However, the method was computationally expensive, but presented better features for improving the discriminative performance of the classifier. In that line, sparse principal component analysis (SPCA) and ensemble-based adaptive over-sampling approaches also reduced false positives in MA detection and eliminated the class imbalance problem in color fundus images with an average 0.90 AUC score [
78,
79]. Javidi et al. in [
80] considered morphological analysis and two dictionaries for MA detection using fundus images. The MA candidate region was initially localized using the morelet-based wavelet algorithm. The MA extracted features were then evaluated by binary dictionaries to classify the true MA region from non-MA pixels. The authors obtained an ROC of 0.267. Their proposed MA detection results are shown in
Figure 6.
Nevertheless, the method was expensive in terms of the execution time and was unable to detect MA pixels on faint and poor contrast images. A deep learning strategy called stacked sparse auto encoder (SSAE) was applied by Shan et al. in [
81] for MA detection. Initially, images were cropped into small patches. These patches were then processed by the SSAE model to learn high-level features from patches. Finally, a soft max classifier was used in the output layer to give a patch probability of being a true MA or false MA. They reported an AUC of 96.2%. Another study in [
82] proposed a two-layer approach called multiple kernel filtering for MA and HM segmentation. Small patches were used instead of the whole image to deal with the varied size of lesions, and finally, a support vector machine (SVM) was applied on selected candidates to distinguish true MA and HM patterns from other parts of an image. They achieved an AUC of 0.97. Adal et al. in [
83] presented a machine learning algorithm for MA detection. Input image was first normalized and then different scale-based descriptors were applied for feature extraction. Finally, a semi-supervised algorithm was trained on the extracted candidate features to classify MA points from non-MA intensities, obtaining an AUC of 0.36. The methods in [
81,
82,
83] were found to be unable to address the over fitting problem for much larger datasets and contained low discriminative power. A summary of MA detection methods is given in
Table 4. It describes the respective methods with their utilized dataset and size.
Kaur et al. in [
84] implemented a supervised model for hemorrhage detection using 50 retinal images. A morphological closing operation was initially applied for the removal of anatomic components, such as fovea and vessels. HM points were then extracted using an adaption of Otsu’s thresholding-based method. These features were fed to a random forest classifier to distinguish HM and non-HM candidates with an SE of 90.40% and an SP of 93.53%. Their visual HM detection results are shown in
Figure 7. Another study in [
85] also used Otsu’s approach to suppress the vascular structure before hemorrhage extraction. The authors achieved an SE of 92.6% and an SP of 94% using 219 fundus images. However, hemorrhages near the border of the image aperture were not detected in [
84,
85], with some bifurcation of vessels present after vascular tree extraction. The detection of HM patterns that are very close to the vascular structure is observed to be a time consuming and difficult task for clinical practitioners. To deal with this issue, rule-based mask detection [
86], splat-based segmentation algorithms [
87,
88,
89], and basic knowledge of inter-/intra-retinal structures [
90] have produced impressive quantitative results.
In a previous study [
86], an image normalization step was applied to remove the normal features, i.e., blood vessels, disc, and fovea, and to improve the contrast of an input image. To localize the HM region, three Gaussian templates were employed, yielding an SE of 93.3% and an SP of 88%. The authors in [
87,
88,
89] considered splat-based HM segmentation methods with different configurations. Despite the better visual HM detection results, they did not present numerical measures when using a large number of tested images. The authors in [
90] utilized mathematical morphology and template matching methods to detect HMs in images, obtaining an accuracy of 97.70%. Some machine learning and pixel-based approaches for the detection of HMs were highlighted in [
91,
92,
93,
94]. In a previous study [
91], a number of the automated DR screening and monitoring methods for HM detection were discussed regarding their basic framework, problems, datasets, and solutions. This review facilitated the authors’ understanding of the role of automated screening tools in DR grading. The automated HM detection tools in [
92,
93] utilized an illumination equalization method on the green channel to localize white and HM pixels. Support vector machine (SVM) was then applied onto the localized region and HM features were classified from normal pixels. Another image processing based software for HM detection using 89 retinal images was reported in [
94], where dynamic thresholding with morphological operations were employed to estimate the HM region in the retinal image. Their application obtained an accuracy of 90%. Nevertheless, the methods [
92,
93,
94] are computationally expensive and are limited to covering all possible locations of an image. Similarly, in a previous study [
95], a three steps-based HM detection system using 108 images was proposed. Brightest features were initially localized based on the varied intensities of fundus components. Four texture forms were then extracted from the bright pixels and eventually, a classifier was trained using the textural descriptors to separate HM pixels from non-HM pixels. The authors achieved an accuracy of 100%.
2.4. Exudate Detection Methods
Exudate is a prime sign of DR, appearing as a bright white/yellowish blob shape on the retinal surface. In the literature, EX extraction techniques are categorized into three parts: Pixel-based, mathematical morphology, and machine learning. The following section discusses these EX detection methods.
Anatomic retinal landmarks, such as an elongated vascular system and optic disc, lead to the production of false positives in the automated detection of exudates. Therefore, a morphological matched filter and saliency methods were employed by Liu et al. in [
96] to eliminate vessels and the optic disc before EX detection. Initially, an input RGB image was preprocessed to visualize retinal anatomic features and to enhance image contrast. Next, vessel and disc components were removed using a matched filter and saliency techniques to localize the EX area in the image. Finally, the random forest classifier was applied on the extracted features, i.e., size, color, and contrast of exudates, and an SE of 83% and an accuracy of 79% was reported using 136 fundus images. Imani et al. [
97] considered a morphological component analysis (MCA) model to separate retinal vessels from the exudate region using 340 images. Afterwards, mathematical morphology and dynamic thresholding methods were incorporated for the distinguishing of EXs from normal features, yielding AUC of 0.961 score.
In a previous study [
98], a multiprocessing scheme was introduced for EX detection using 83 retinal images. First, an exudate candidate region was extracted by applying grey morphology and then the boundaries of these candidates were segmented using an ACM model. Lastly, the features computed by the ACM were fed to the naïve Bayes classifier, and classified exudate features with an SE of 86% and an accuracy of 85%. Zhang et al. in [
99] developed an EX segmentation method based on mathematical morphology using 47 images. After image normalization, classical and textural features were employed using mathematical morphology and then EX features were segmented with an AUC score of 0.95. The authors in [
100] also applied mathematical morphology for EX extraction using 149 images. The final EX classification was performed using the SVM classifier, obtaining an accuracy of 90.54%. Akram et al. in [
101] recommended a mean-variance approach for vessel and disc removal using 1410 images. Bank filters were utilized for the selection of EX points and finally, images were classified into EX and non-EX pixels by utilizing a Gaussian mixture with an integration of the m-mediods model, achieving a 0.97 AUC score. Region-based local binary pattern features were suggested by Omar et al.
In [
102], using 130 images, the image quality was enhanced for EX detection, with a 96.73% accuracy. Morphological operations, like mean shift, normalized cut, and cannys, have presented better performance in EX extraction [
103]. Several machine learning principles have shown better sensitivity results for EX segmentation [
104,
105,
106,
107,
108,
109,
110,
111]. Fraz et al. in [
104] applied morphological reconstruction and a Gabor filter for EX candidate extraction using 498 images. Initially, false positives were reduced in selected candidates using contextual cues. Region-based features, computed from the candidate area, were then fed to an ensemble classifier for the detection of true and false EXs, yielding a 0.99 ROC score. Prentasic et al. in [
105] proposed a deep CNN for exudate segmentation using 50 images. The optic disc was segmented based on the probability maps of different algorithms. The Frangi filter was then implemented for vessel segmentation. Finally, the performance of the DCNN was combined with the disc and vessel results to segment true EX pixels, obtaining a 0.78 F-score. Similarly, SVM classifiers with sparse coded features, K-means, scale invariant feature transform, and visual dictionaries were exploited in [
22,
106,
107] to distinguish non-EX from EX points. Logistic regression followed by multilayer perceptron and radial basis function classifiers successfully classified hard exudates using 130 images with a 96% sensitivity [
108]. Ground truth data usually have an inaccuracy problem that directly affects the final classification output of an algorithm. Therefore, in a previous study [
109], image features were evaluated for the elimination of inaccuracy in clinical data and the segmentation of exudates. Pereira et al. in [
110] utilized an ant colony optimization (ACO) technique to extract EX edges using 169 low contrast images. The green channel was selected because of its higher intensity of EX lesions compared to the background part of an image. Next, a median filter with kernel size of 50 x 50 was utilized to normalize and balance the intensity space. A double threshold was applied to extract EX points and then ACO was employed to detect the borders of bright lesions, yielding a 97% accuracy. Figueiredo et al. in [
111] applied wavelet band analysis on the green channel to learn the whole image’s features. Hybrid approaches, like Hessian multiscale analysis, variation, and cartoon with texture decomposition, were then applied on the learned features to discriminate EXs from other bright lesions. They achieved an SE of 90% and an SP of 97% using 45,770 fundus images. Their EX segmentation results are shown in
Figure 8.
Despite the highly significant results of the EX detection methods in [
96,
97,
98,
99,
100,
101,
102,
103,
104,
105,
106,
107,
108,
109,
110,
111], some weaknesses exist that need to be addressed in the future to provide the best possible EX detection systems: (I) Most methods were evaluated on small datasets, which limit theirs performance ability to detect other pathological features, e.g., dark lesions; (II) only bright lesions, i.e., EXs were detected followed by preprocessing steps, which is expensive in terms of processing; (III) high accuracy was achieved at the cost of a low SE rate; and (IV) it is difficult to detect EXs in low contrast areas.
2.5. Diabetic Retinopathy Detection Systems
CAD tools have been successfully applied to identify the five stages of DR and produce similar results to human experts. The fundamental goal of CAD systems in DR is to distinguish retinal anatomic components from DR-related lesions. To address this, some recent DR-based CAD studies are highlighted in the subsequent paragraph with their results and challenges.
Kaur et al. [
112] proposed a DR screening tool to detect exudates using 1307 images. Their algorithm segmented exudates with a mean accuracy of 93.46%. Bander et al. [
113] developed a computer-aided diagnosis (CAD) system to segment OD and fovea using 11,200 retinal images acquired from the MESSIDOR and Kaggle datasets. The OD and fovea were detected by employing a multiscale deep learning model with an accuracy of 97% and 96.7% on the MESSIDOR and 96.6% and 95.6% on the kaggle databases, respectively. Gargeya et al. [
114] also proposed a deep learning model for the grading of DR and no-DR cases. Their model evaluated the color features of 75,137 images obtained from the MESSIDOR2 and e-OPTHA datasets and achieved an AUC of 0.94 and 0.95, respectively. Silva et al. [
115] evaluated 126 images from 69 patients for the early screening of DR. Their application detected MA and HM features with a kappa value of a 0.10 ratio. Dash et al. [
116] developed a DR screening tool based on the segmentation of vascular structures. Their software used 58 images obtained from the DRIVE and CHASE_DB1 datasets and achieved a 0.955 and 0.954 accuracy, respectively.
Leontidis [
117] presented a DR-CAD system to detect vessels. Vessels were classified based on geometric vessel features with a classification accuracy of 0.821 and 0.968, respectively. Koh et al. [
118] presented an automated DR tool to identify normal and pathological images based on energy and entropies with a sensitivity and specificity of 89.37% and 95.58%, respectively. A comprehensive study about the causes and automated screening of different retinal pathologies, like DR, cataract, and glaucoma, in a younger and adult population were discussed in [
119]. Their review may be useful in finding a novel hypothesis for the screening of retinopathies. Barua et al. [
120] developed a DR screening tool to extract retinal vessels using 45 images acquired from the HRF database. Image features were classified by applying ANN with classification accuracy of 97%. R et al. [
121] presented a machine learning algorithm for DR screening to locate EXs and HMs using 767 patches with an accuracy of 96% and 85%, respectively. Several deep learning, machine learning, and data mining approaches were discussed in [
122,
123] for the the segmentation and classification of anatomic and DR lesions, image quality assessment, and registration. Devarakonda et al. [
124] also applied ANN and SVM classifiers to extracted features for the identification of normal and DR parts. Their system achieved an accuracy of 99% using 338 images acquired from a local dataset.
Vo et al. [
125] developed a deep learning model for DR screening using 91,402 images obtained from the EyePACS and MESSIDOR datasets. Their software utilized two deep networks and hybrid color space features and achieved ROC values of 0.891 and 0.887, respectively. Lahiri et al. [
126] also proposed deep neural networks for DR screening to detect blood vessels using 40 images obtained from the DRIVE dataset. Their model achieved an average accuracy of 95.33%. In [
127], a two-step deep convolutional neural network was presented for lesion detection and DR grading using 23,595 images from the Kaggle dataset. Their proposed architecture obtained an AUC of 0.9687. Wang et al. [
128] utilized a deep convolutional neural network to detect lesions and screen DR severity stages using 90,200 images from the EyePACS and MESSIDOR data sources with specialists’ labels. Their system identified the severity levels of DR with AUC values of 0.865 and 0.957, respectively. Another deep learning-based study, termed the AlexNet deep convolutional neural network, was employed by [
129] to classify the five classes of DR using 35,126 images selected from the Kaggle dataset. Their method achieved a diabetic retinopathy classification accuracy of 97.93%. Lachure et al. [
130] utilized morphological operations and SVM classifiers to detect MA and EX lesions using color fundus angiographies. Their application successfully detected MA and EX regions with a specificity of 100% and a sensitivity of 90%.
Nijalingappa et al. [
131] applied a machine learning model to detect EX features using 85 images from the MESSIDOR and DIARETDB0 datasets. Initially, image preprocessing followed by RGB to green plane conversion and contrast enhancement were performed. The K-nn classifier was used on extracted features to classify EX regions with an accuracy of 95% on MESSIDOR and 87% on DIARETDB0. Kunwar et al. [
132] proposed a CAD tool for the recognition of the severity level of DR using 60 subjects acquired from the MESSIDOR dataset. Textural features of MAs and EXs with the SVM classifier were applied to classify DR and normal lesions with a sensitivity of 91%. A real time, web-based platform was introduced by [
133] for the recognition of DR levels. Their system achieved a sensitivity and specificity of 91.9% and 65.2% in the detection of NPDR lesions. However, the DR-based CAD methods in [
112,
113,
114,
115,
116,
117,
118,
119,
120,
121,
122,
123,
124,
125,
126,
127,
128,
129,
130,
131,
132,
133] mainly focused on the detection of DR-related lesions and were limited by the severity category of DR. The DR severity level, i.e., PDR, has been addressed rarely by the CAD systems. They only produced a contribution to differentiate between NPDR and PDR. Moreover, these CAD studies were found to be less applicable to the classification of the five stages of DR.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}