Gender Classification Based on the Non-Lexical Cues of Emergency Calls with Recurrent Neural Networks (RNN)


Abstract
:1. Introduction
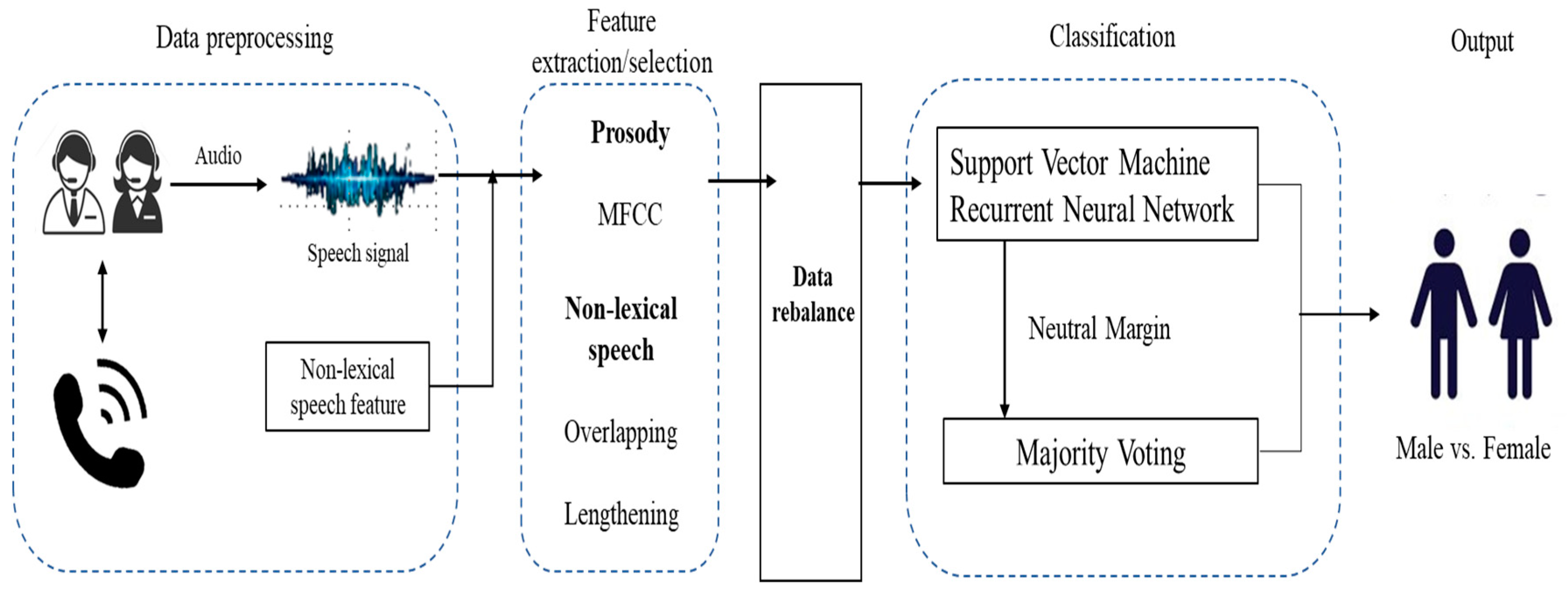
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Non-Lexical Speech Utterances for Gender Classification
2.2.2. Statistical Analysis
2.2.3. Machine-Learning-Based Gender Classification
3. Results
3.1. Descriptive Analysis: Non-Lexical Speech Utterances
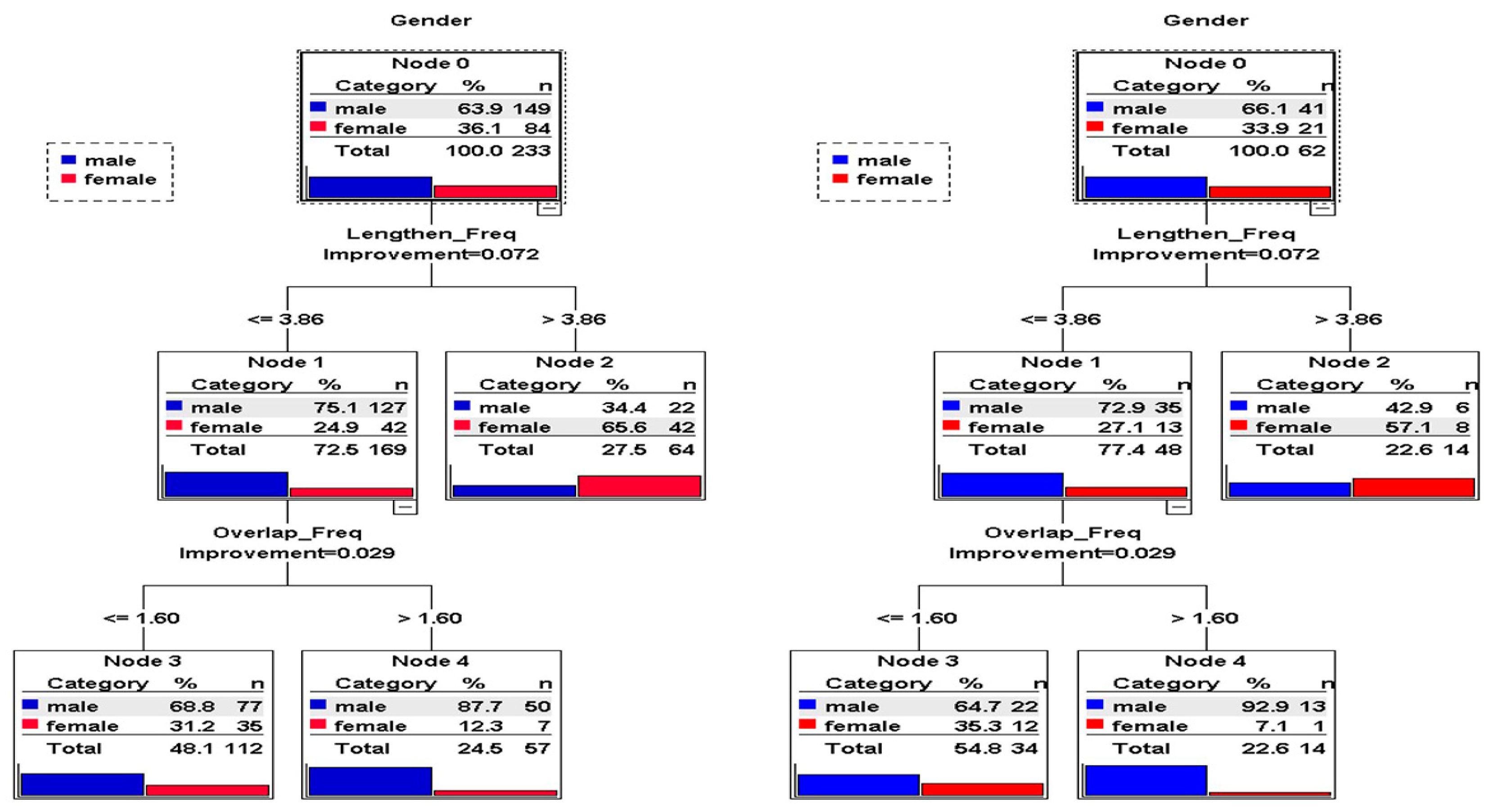
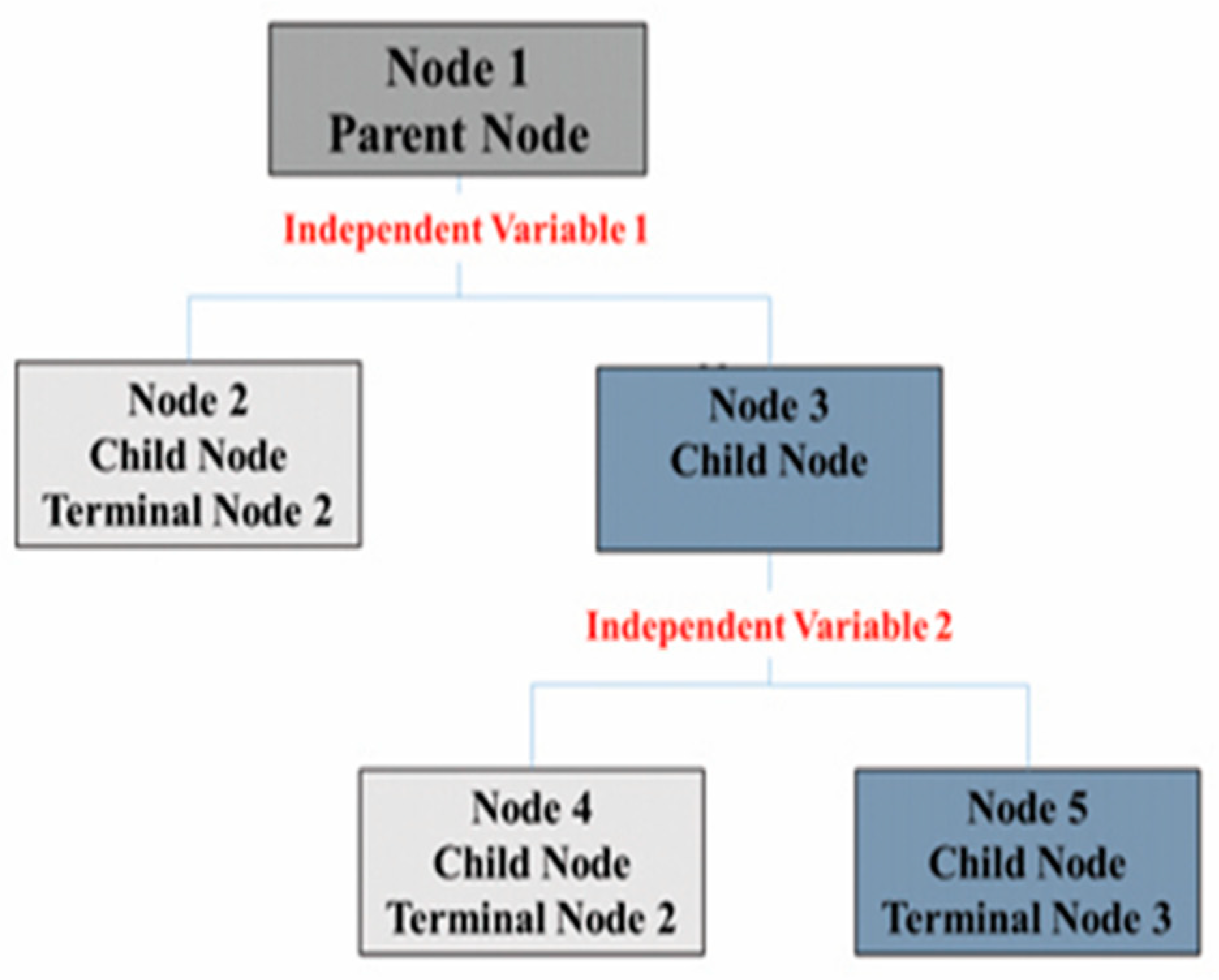
3.2. Decision-Making Tree: CRT Analysis
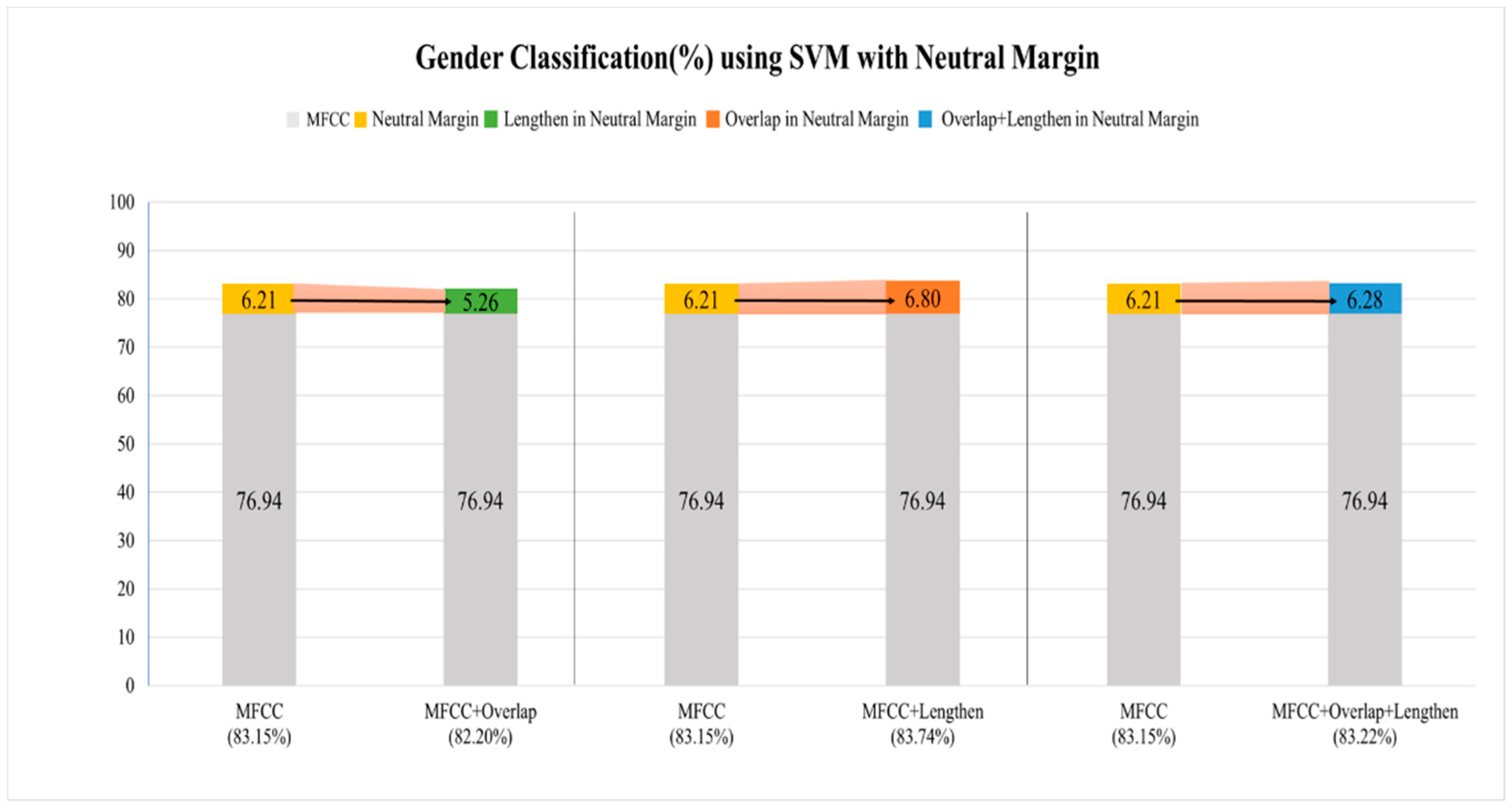
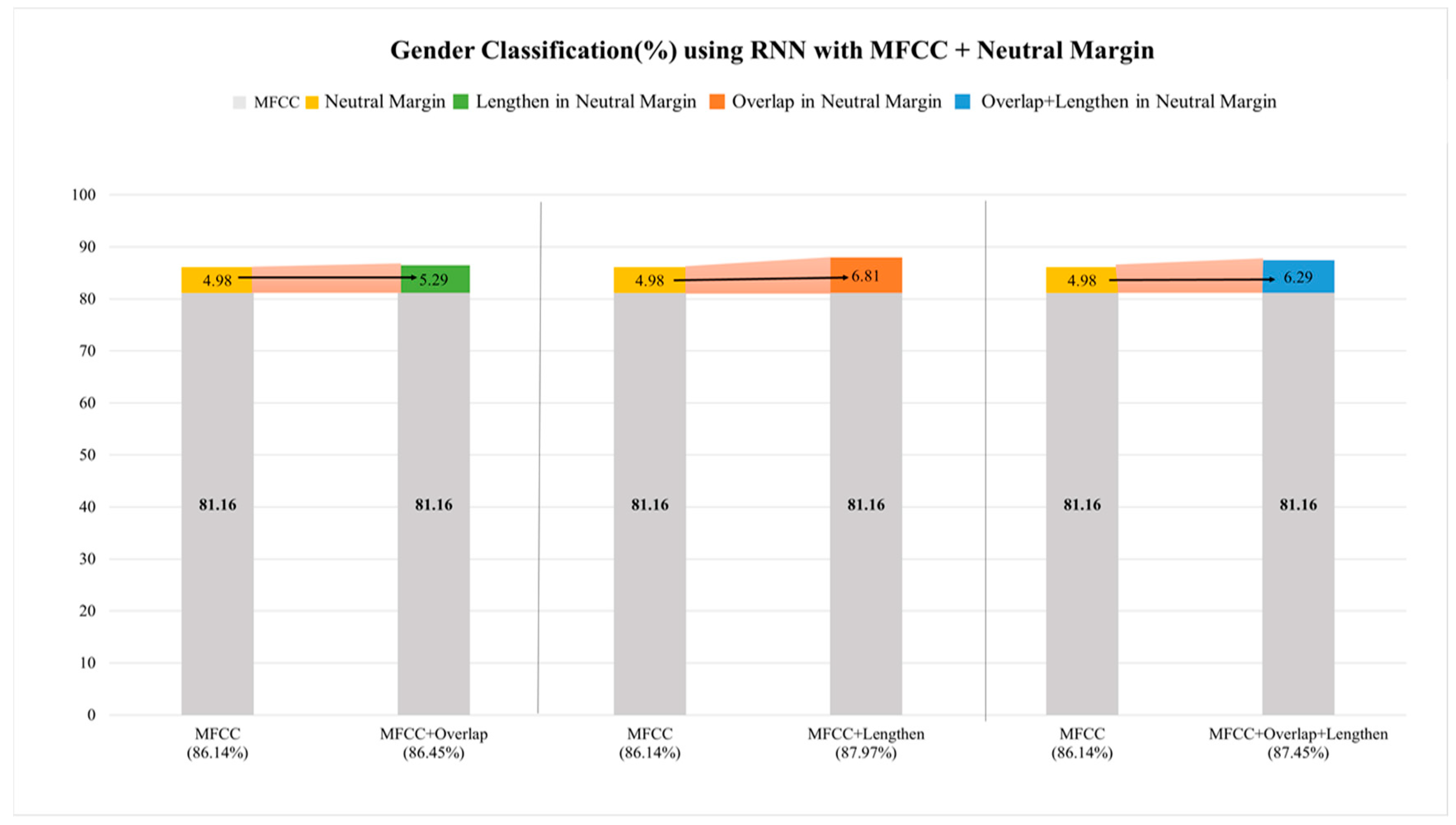
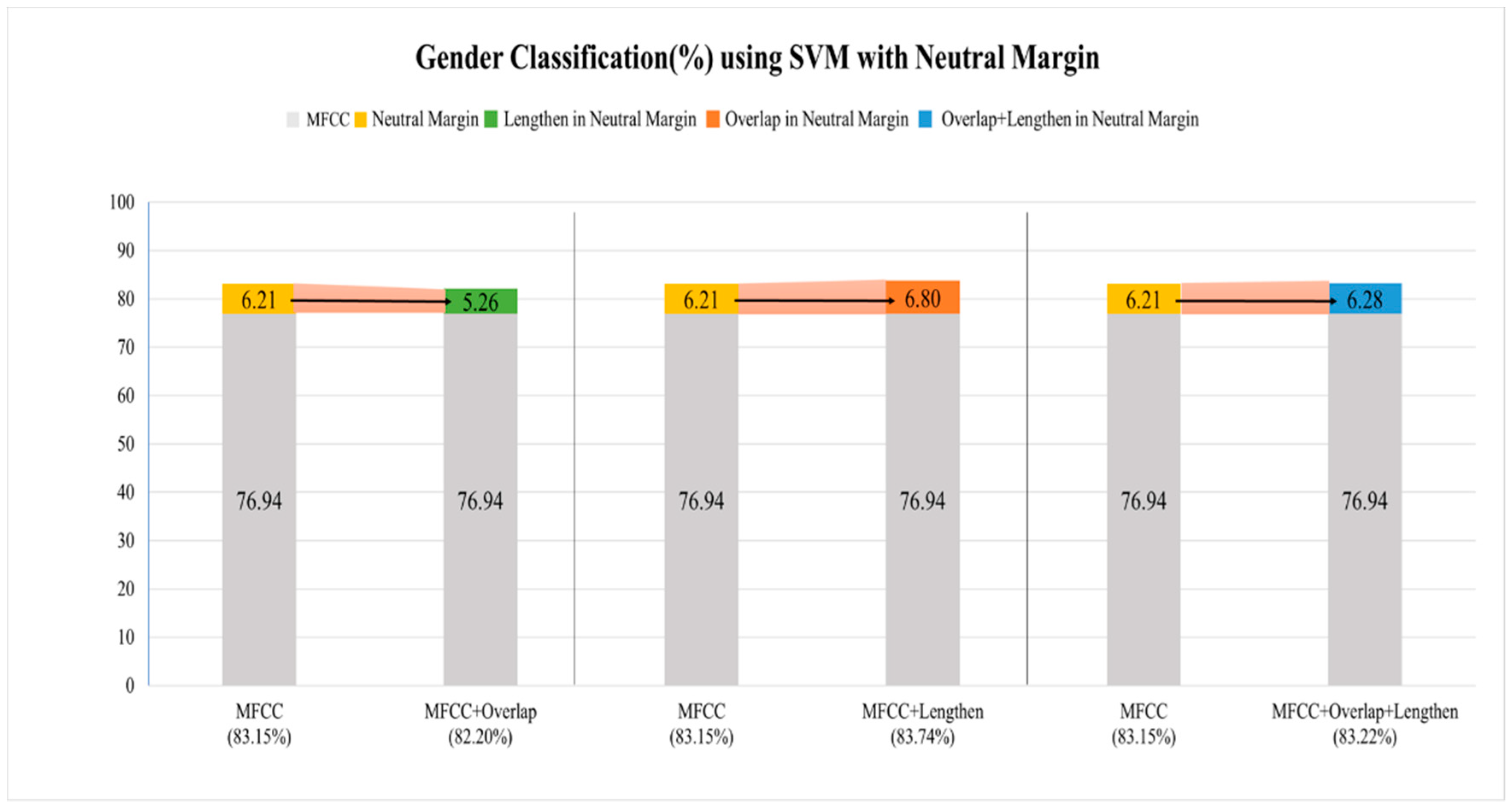
3.3. Gender Classification: SVM and RNN
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Groves, R.M.; O’Hare, B.C.; Gould-Smith, D.; Benki, J.; Maher, P. Telephone interviewer voice characteristics and the survey participation decision. Adv. Teleph. Surv. Methodol. 2008, 385–400. [Google Scholar]
- Li, M.; Han, K.J.; Narayanan, S. Automatic speaker age and gender recognition using acoustic and prosodic level information fusion. Comput. Speech Lang. 2013, 27, 151–167. [Google Scholar] [CrossRef]
- Siniscalchi, S.M.; Salerno, V.M. Adaptation to new microphones using artificial neural networks with trainable activation functions. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1959–1965. [Google Scholar] [CrossRef] [PubMed]
- Naini, A.S.; Homayounpour, M. Speaker age interval and sex identification based on jitters, shimmers and mean mfcc using supervised and unsupervised discriminative classification methods. In Proceedings of the 2006 8th international Conference on Signal Processing, Beijing, China, 16–20 November 2006. [Google Scholar]
- Zeng, Y.-M.; Wu, Z.-Y.; Falk, T.; Chan, W.-Y. Robust GMM based gender classification using pitch and RASTA-PLP parameters of speech. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 3376–3379. [Google Scholar]
- Metze, F.; Ajmera, J.; Englert, R.; Bub, U.; Burkhardt, F.; Stegmann, J.; Muller, C.; Huber, R.; Andrassy, B.; Bauer, J.G. Comparison of four approaches to age and gender recognition for telephone applications. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; pp. 1089–1092. [Google Scholar]
- Vergin, R.; Farhat, A.; O’Shaughnessy, D. Robust gender-dependent acoustic-phonetic modelling in continuous speech recognition based on a new automatic male/female classification. In Proceedings of the Fourth International Conference on Spoken Language Processing, Philadelphia, PA, USA, 3–6 October 1996; pp. 1081–1084. [Google Scholar]
- Ververidis, D.; Kotropoulos, C. Automatic speech classification to five emotional states based on gender information. In Proceedings of the EUSIPCO, Vienna, Austria, 6–10 September 2004; pp. 341–344. [Google Scholar]
- Hu, Y.; Wu, D.; Nucci, A. Pitch-based gender identification with two-stage classification. Secur. Commun. Netw. 2012, 5, 211–225. [Google Scholar] [CrossRef]
- Ting, H.; Yingchun, Y.; Zhaohui, W. Combining MFCC and pitch to enhance the performance of the gender recognition. In Proceedings of the 2006 8th international Conference on Signal Processing, Beijing, China, 16–20 November 2006. [Google Scholar]
- Kabil, S.H.; Muckenhirn, H.; Doss, M.M. On Learning to Identify Genders from Raw Speech Signal using CNNs. 2018. Available online: http://publications.idiap.ch/downloads/papers/2018/Kabil_INTERSPEECH_2018.pdf (accessed on 1 March 2019).
- Barkana, B.D.; Zhou, J. A new pitch-range based feature set for a speaker’s age and gender classification. Appl. Acoust. 2015, 98, 52–61. [Google Scholar] [CrossRef]
- Sapienza, C.M. Aerodynamic and acoustic characteristics of the adult AfricanAmerican voice. J. Voice 1997, 11, 410–416. [Google Scholar] [CrossRef]
- Morris, R.J.; Brown, W.; Hicks, D.M.; Howell, E. Phonational profiles of male trained singers and nonsingers. J. Voice 1995, 9, 142–148. [Google Scholar] [CrossRef]
- Hanson, H.M.; Chuang, E.S. Glottal characteristics of male speakers: Acoustic correlates and comparison with female data. J. Acoust. Soc. Am. 1999, 106, 1064–1077. [Google Scholar] [CrossRef] [PubMed]
- Jun, J.; Kim, S. Gender Differences in Powerful/Powerless Language Use in Adult and Higher Education Settings: A Meta-Analysis. Asian J. Educ. 2005, 6, 53–73. [Google Scholar]
- Corley, M.; Stewart, O.W. Hesitation disfluencies in spontaneous speech: The meaning of um. Lang. Linguist. Compass 2008, 2, 589–602. [Google Scholar] [CrossRef]
- Stouten, F.; Duchateau, J.; Martens, J.-P.; Wambacq, P. Coping with disfluencies in spontaneous speech recognition: Acoustic detection and linguistic context manipulation. Speech Commun. 2006, 48, 1590–1606. [Google Scholar] [CrossRef]
- Hye-Young, K. A Corpus-analysis of Gender Effects in Private Speech: The Function of Discourse Markers in Spoken Korean. Lang. Linguist. 2011, 53, 89–108. [Google Scholar]
- Gyu-hong, L. A Study on the Use of Korean Discourse Markers according to Gender. Korean Lang. Lit. 2004, 1, 93–113. [Google Scholar]
- Soon-ja, K. Special Feature-Korean Speech and Conversation Analysis: Characteristics found among Men and Women engaging in Interrupting the Turn of the Next Speaker. Speech Res. 2000, 2, 61–92. [Google Scholar]
- Cheon, E.S. The Difference between Men’s and Women’s Speeches: From the Aspect of Discourse Strategy and Discourse Context. Korean J. Russ. Lang. Lit. 2007, 19, 41–73. [Google Scholar]
- Won-Pyo, L. Interventions in Talk Shows: Discourse Functions and Social Variables. Discourse Cogn. 1999, 6, 23–59. [Google Scholar]
- Kim, S.-H. Intonation Patterns of Korean Spontaneous Speech. J. Korean Soc. Speech Sci. 2009, 1, 85–94. [Google Scholar]
- Min-Ha, J. Politeness Strategy in Intonation Based on Age: Through Analysis of Spontaneous Speech of Those in 10s, 20s, and 30s Women. Korean Semant. 2014, 45, 99–127. [Google Scholar]
- Hagerer, G.; Pandit, V.; Eyben, F.; Schuller, B. Enhancing lstm rnn-based speech overlap detection by artificially mixed data. In Proceedings of the Audio Engineering Society Conference: 2017 AES International Conference on Semantic Audio, Erlangen, Germany, 22–24 June 2017; p. 1. [Google Scholar]
- Wang, Z.-Q.; Tashev, I. Learning utterance-level representations for speech emotion and age/gender recognition using deep neural networks. In Proceedings of the 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5150–5154. [Google Scholar]
- Buyukyilmaz, M.; Cibikdiken, A.O. Voice gender recognition using deep learning. In Proceedings of the 2016 International Conference on Modeling, Simulation and Optimization Technologies and Applications (MSOTA2016), Xiamen, China, 18–19 December 2016. [Google Scholar]
- Bisio, I.; Delfino, A.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Gender-driven emotion recognition through speech signals for ambient intelligence applications. IEEE Emerg. Top Com. 2013, 1, 244–257. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, L.; Dang, J.; Guo, L.; Yu, Q. Gender-Aware CNN-BLSTM for Speech Emotion Recognition. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 782–790. [Google Scholar]
- Zazo, R.; Nidadavolu, P.S.; Chen, N.; Gonzalez-Rodriguez, J.; Dehak, N. Age estimation in short speech utterances based on LSTM recurrent neural networks. IEEE Access 2018, 6, 22524–22530. [Google Scholar] [CrossRef]
- Siniscalchi, S.M.; Yu, D.; Deng, L.; Lee, C.-H. Exploiting deep neural networks for detection-based speech recognition. Neurocomputing 2013, 106, 148–157. [Google Scholar] [CrossRef]
- Katerenchuk, D. Age group classification with speech and metadata multimodality fusion. arXiv 2018, arXiv:1803.00721. [Google Scholar]
- Abouelenien, M.; Pérez-Rosas, V.; Mihalcea, R.; Burzo, M. Multimodal gender detection. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 302–311. [Google Scholar]
- McCowan, I.; Carletta, J.; Kraaij, W.; Ashby, S.; Bourban, S.; Flynn, M.; Guillemot, M.; Hain, T.; Kadlec, J.; Karaiskos, V. The AMI meeting corpus. In Proceedings of the 5th International Conference on Methods and Techniques in Behavioral Research, Edinburgh, UK, 11–13 July 2005; p. 100. [Google Scholar]
- Batliner, A.; Steidl, S.; Nöth, E. Releasing a thoroughly annotated and processed spontaneous emotional database: the FAU Aibo Emotion Corpus. In Proceedings of the Satellite Workshop of LREC, Marrakech, Morocco, 26 May–1 June 2008; pp. 28–31. [Google Scholar]
- Burkhardt, F.; Eckert, M.; Johannsen, W.; Stegmann, J. A Database of Age and Gender Annotated Telephone Speech. In Proceedings of the LREC, Valletta, Malta, 17–23 May 2010; pp. 1562–1565. [Google Scholar]
- IBM SPSS Decision Trees 21. 2012. Available online: http://www.sussex.ac.uk/its/pdfs/SPSS_Decision_Trees_21.pdf (accessed on 1 March 2019).
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Eyben, F.; Weninger, F.; Squartini, S.; Schuller, B. Real-life voice activity detection with lstm recurrent neural networks and an application to hollywood movies. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 483–487. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filler | Examlple |
|---|---|
| 아 (ah) | 아 아니 (ah A Ni) = ah No |
| 어 (uh) | 어 어 있잖아 (uh uh I chana) = uh uh you know |
| 음 (um) | 내가 음 많이 아파요. (Neyga um Mani Appayo.) = I am um very sick. |
| 저 (ceo) | 저 여기 00 식당인데요. (Ceo Yeogi 00 Siktangindeyo.) = ceo this is 00 restaurant. |
| 그 (ku) | 그 여기가 그 (ku Yeogiga ku) = ku here is ku |
| Speech Utterance | Occurrence | Gender (N = 340) | x2 | df | p | |
|---|---|---|---|---|---|---|
| Male (N = 223) | Female (N = 117) | |||||
| Fillers | Occurrence | 197 (88.3) | 75 (64.1) | 28.177 | 1 | 0.001 |
| Non-occurrence | 26 (11.7) | 42 (35.9) | ||||
| Overlapping | Occurrence | 146 (65.5) | 45 (38.5) | 22.739 | 1 | 0.001 |
| Non-occurrence | 77 (34.5) | 72 (61.5) | ||||
| Lengthening | Occurrence | 145 (63.7) | 93 (79.5) | 8.986 | 1 | 0.003 |
| Non-occurrence | 81 (36.3) | 24 (20.5) | ||||
| Speech Utterance | Male | Female | t | df | p-Value |
|---|---|---|---|---|---|
| Mean (SD) | Mean (SD) | ||||
| Fillers | 3.004 (2.542) | 2.586 (1.807) | 1.319 | 274 | 0.188 |
| Overlapping | 1.851 (1.407) | 1.482 (1.421) | 2.294 | 193 | 0.023 |
| Lengthening | 2.493 (2.080) | 4.479 (2.901) | −5.711 | 153.07 | 0.001 |
| Target Variable: Gender | ||||||||
|---|---|---|---|---|---|---|---|---|
| Node | Node by Node | |||||||
| Node | Response | Gain | Gain Index | |||||
| N | % | N | % | |||||
| Male | Training | 4 | 104 | 44.7% | 85 | 56.9% | 82.8% | 128.8% |
| 3 | 69 | 29.6% | 45 | 29.7% | 64.2% | 99.9% | ||
| 2 | 60 | 25.6% | 20 | 13.2% | 33.1% | 51.6% | ||
| Test | 4 | 28 | 45.0% | 22 | 54.9% | 78.3% | 121.9% | |
| 3 | 20 | 32.1% | 13 | 30.9% | 61.3% | 94.9% | ||
| 2 | 14 | 22.8% | 6 | 14.1% | 38.7% | 60.3% | ||
| Female | Training | 2 | 60 | 25.6% | 40 | 47.8% | 66.8% | 187.5% |
| 3 | 69 | 29.6% | 25 | 29.3% | 35.7% | 100.1% | ||
| 4 | 104 | 44.7% | 19 | 22.7% | 17.1% | 48.4% | ||
| Test | 2 | 14 | 22.8% | 9 | 38.8% | 61.2% | 175.5% | |
| 3 | 20 | 32.1% | 7 | 33.5% | 38.6% | 107.5% | ||
| 4 | 28 | 45.0% | 6 | 27.5% | 21.6% | 61.0% | ||
| Variable | Total (N = 340) | Male (N = 223) | Female (N = 117) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F | O | L | F | O | L | F | O | L | ||
| F | r | 1 | 1 | 1 | ||||||
| p | ||||||||||
| n | 276 | 199 | 77 | |||||||
| O | r | 292 ** | 1 | .249 ** | 1 | 483 ** | 1 | |||
| p | .000 | .003 | .006 | |||||||
| n | 168 | 195 | 137 | 149 | 31 | 46 | ||||
| L | r | .098 | .454 ** | 1 | .109 | .433 ** | 1 | .241 | .555 ** | 1 |
| p | .173 | .000 | .217 | .000 | .053 | .001 | ||||
| n | 194 | 135 | 235 | 129 | 101 | 142 | 65 | 34 | 93 | |
| Category | Predicted | |||
|---|---|---|---|---|
| Male | Female | Accuracy | ||
| Training | Male | 130 (6) | 20 (3) | 86.9% |
| Female | 40 (1) | 44 (2) | 47.7% | |
| Overall percentage | 79.7% | 20.3% | 72.9% | |
| Risk Estimate | .271 | |||
| Risk Std. Error | .029 | |||
| Test | Male | 35 (5) | 6 (2) | 86.9% |
| Female | 13 (1) | 9 (2) | 38.3% | |
| Overall percentage | 82.5% | 17.5% | 69.8% | |
| Risk Estimate | .308 | |||
| Risk Std. Error | .058 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, G.; Kwon, S.; Park, N. Gender Classification Based on the Non-Lexical Cues of Emergency Calls with Recurrent Neural Networks (RNN). Symmetry 2019, 11, 525. https://doi.org/10.3390/sym11040525
Son G, Kwon S, Park N. Gender Classification Based on the Non-Lexical Cues of Emergency Calls with Recurrent Neural Networks (RNN). Symmetry. 2019; 11(4):525. https://doi.org/10.3390/sym11040525
Chicago/Turabian StyleSon, Guiyoung, Soonil Kwon, and Neungsoo Park. 2019. "Gender Classification Based on the Non-Lexical Cues of Emergency Calls with Recurrent Neural Networks (RNN)" Symmetry 11, no. 4: 525. https://doi.org/10.3390/sym11040525
APA StyleSon, G., Kwon, S., & Park, N. (2019). Gender Classification Based on the Non-Lexical Cues of Emergency Calls with Recurrent Neural Networks (RNN). Symmetry, 11(4), 525. https://doi.org/10.3390/sym11040525