Study on Massive-Scale Slow-Hash Recovery Using Unified Probabilistic Context-Free Grammar and Symmetrical Collaborative Prioritization with Parallel Machines

Abstract
1. Introduction
- Recovering slow hashes by reusing passwords from a large source corpus. Our corpus is the largest ever studied in literature to our knowledge. Based on it, we find cross-site passwords account for a large proportion of the target sites, which can be exploited for hash recovery.
- Identifying a less-studied issue which degrades the efficiency of massive-scale slow-hash recovery: weak accounts are blocked by stronger accounts during expanding and guessing. We solve this by proposing concurrent global prioritization and overcome two key shortcomings of the usage of a huge global heap which the method brings in.
- Helping organizations to better protect their data. Our algorithm models the behavior of real-world attackers who would try the best to maximize the cracking profit before it is finally exceeded by the cost. Based on it, organizations can better balance the hashing costs with the sever load, and can proactively detect weak credentials before financial and reputational damages happen.
2. Related Work
2.1. Offline Password Guessing
2.2. Password Reuse
2.3. Bcrypt Recovery
2.4. Recovery Metric
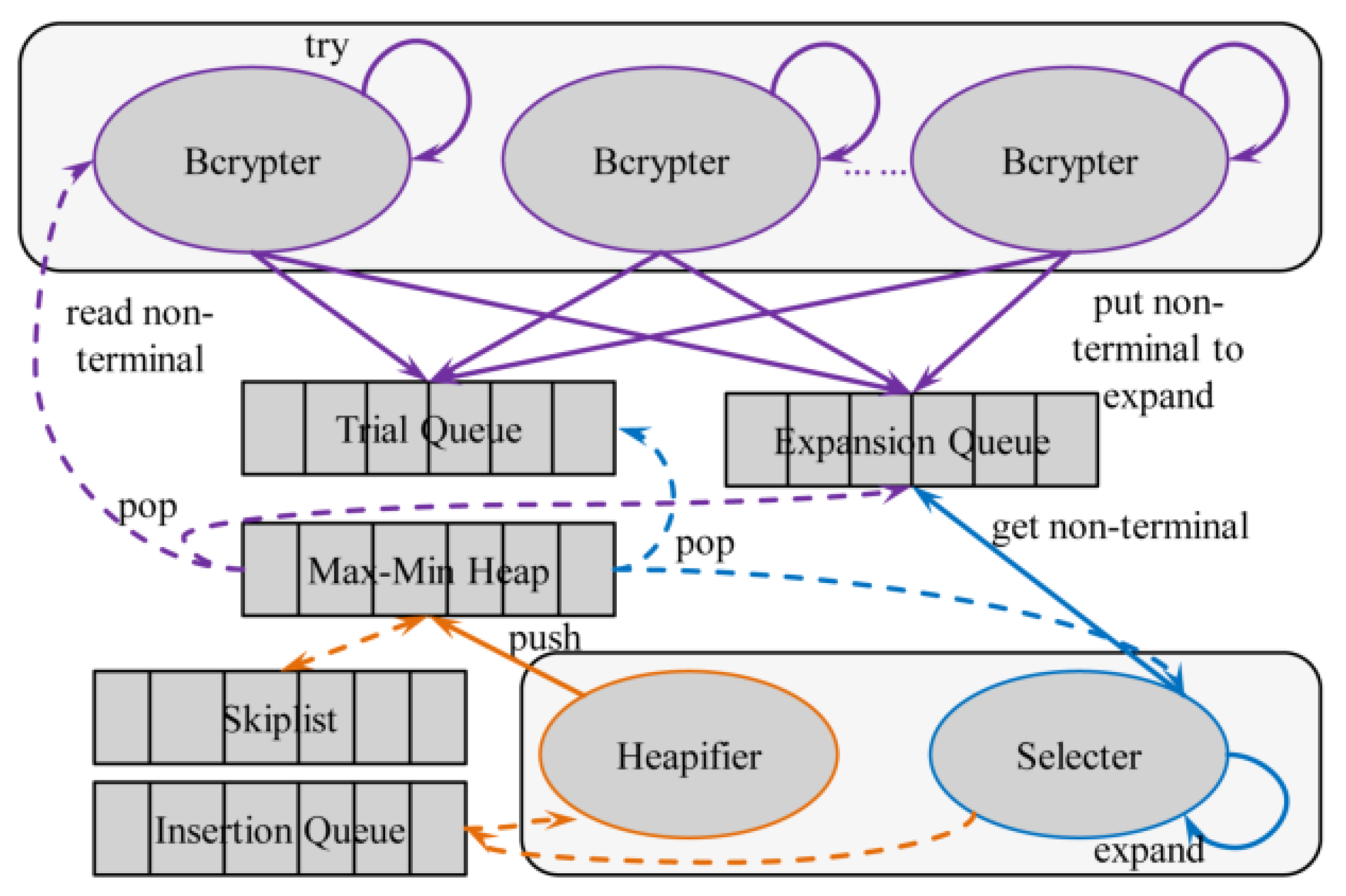
3. Our Solution
- Effective: Recover a substantial proportion of the target dataset.
- Efficient: Make the more promising (account, password) pairs to be attempted earlier.
- Parallelizable: Perform as many trials as possible per unit time.
- Scalable: Handle a large dataset with restricted memory resource.
3.1. PCFG Expansion
- Σ is the set of 95 printable ASCII codes.
- V = {s; Li, Di, Si} (i ∈ {1, 2, …, 16}), where Li, Di, Si each stands for an alphabetic/digital/symbolic string of length i (called segment).
- s ∈ V is the start symbol.
- E is a set of rules in the form of v → v’, where v ∈ V and v’ ∈ (V ∪ Σ)∗.
- λ:E → [0, 1] assigns each rule to a probability and it fulfills the constraint
3.2. Global Ranking
| Algorithm 1. GlobalSort. |
| Input:PQ:max-min heap, EQ:expansion queue, TQ:trial queue, IQ:insertion queue Output: 4 updated queues 1 while True do 2 if EQ!=0 then 3 cand<-EQ.Get() 4 else 5 with PQ.lock do 6 cand<-PQ.PopMax() 7 if isPseudTerminal(cand) or isTerminal(cand) then 8 TQ.Put(cand) 9 else 10 cands<-IncTranse(cand) 11 foreach e in cands do 12 IQ.Put(cands) |
| Algorithm 2. Materialization. |
| Input:PQ:max-min heap, SL:skiplist, IQ:insertion queue Output: 3 updated queues 1 while True do 2 if IQ!=0 then 3 cand<-IQ.Get() /* candidate to insert */ 4 if cand.prob>=SL.ReadMax() then 5 with PQ.lock do 6 if Len(PQ)>=MAX_LEN then 7 if cand.prob<=PQ.ReadMin() then 8 SL.Push(cand) 9 else 10 pq_min<-PQ.PopMin() 11 SL.Push(pq_min) 12 PQ.Push(cand) 13 else 14 SL.Push(cand) 15 with PQ.lock do 16 if Len(PQ)<MAX_LEN then 17 sl_max<-SL.PopMax() 18 PQ.Push(sl_max) |
3.3. Bcrypt Trial
| Algorithm 3. Bcrypt Trial. |
| Input:PQ:max-min heap, EQ:expansion queue, TQ:trial queue, sets of recovered accounts Output: Updated queues and sets 1 while True do 2 if TQ!=0 then 3 cand<-TQ.Get() 4 else 5 with PQ.lock do 6 cand<-PQ.PopMax() 7 if not(isPseudTerminal(cand) or isTerminal(cand)) then 8 EQ.Put(cand) 9 break 10 isCracked<-try(cand) 11 if isCracked then 12 Output: <cand.usr:cand.password> 13 if isTerminal(cand) and not isAllUsrTried(cand) then 14 TQ.Put(cand) 15 if not isCracked or not isTerminal(cand) then 16 EQ.Put(cand) |
4. Experimental Evaluation
4.1. Experimental Setting
- oclHashcat. We use the default configuration of oclHashcat and pipe the output of trawling PCFG [10] into it for guessing. In the default configuration, oclHashcat will not try the next account until all candidates are tried or a correct guess is made for the current account. The PCFG is trained on 1 million passwords randomly sampled from Linkedin.
- TarGuessII+Trawling PCFG. TarGuessII can be parallelized, naively but inefficiently, by segmenting the data and assigning each segment to a core. The password-reused model is trained on cross-site password pairs from the source site of Linkedin to the target site of 000webhost, though it would be better to train distinctly for different target sites. We vary the number of trials per account (k) by 100, 1000, and 10000. The trawling model is similarly trained as the one used for oclHashcat.
- BcryptRecover. This implements our method. The training configuration is the same with TarGuessII.
4.2. Comparison of Various Approaches
4.3. Impact of Global Ranking
- LocalFullTrans. This is exactly TarGuessII + Trawling PCFG, in which we consider a typical value 1000 for k. All the candidate passwords of a single round are generated and sorted at once before the bcrypt recovery begins, instead of being generated step by step according to the types of transformation rules.
- GlobalFullTrans. It replaces the incremental transformation strategy of BcryptRecover (alias GlobalIncTrans) with the expanding strategy of LocalFullTrans.
4.4. Impact of Parallelization
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Why You Shouldn’t Panic about Dropbox Leaking 68 Million Passwords. Available online: https://www.forbes.com/sites/thomasbrewster/2016/08/31/dropbox-hacked-but-its-not-thatbad/#675839355576 (accessed on 8 May 2017).
- Lessons Learned from Cracking 4000 Ashley Madison Passwords. Available online: https://arstechnica.com/informationtechnology/2015/08/cracking-all-hacked-ashleymadison-passwords-could-take-a-lifetime/ (accessed on 15 December 2017).
- Deep Dive into the Edmodo Data Breach. Available online: https://medium.com/4iqdelvedeep/deep-dive-into-theedmodo-data-breach-f1207c415ffb (accessed on 22 November 2017).
- Hashcat. Available online: https://hashcat.net/oclhashcat/ (accessed on 1 September 2017).
- John the Ripper. Available online: http://www.openwall.com/john/ (accessed on 1 December 2017).
- Das, A.; Bonneau, J.; Caesar, M.; Borisov, N.; Wang, X. The tangled web of password reuse. In Proceedings of the NDSS 2014, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Wang, D.; Zhang, Z.; Wang, P.; Yan, J.; Huang, X. Targeted online password guessing: An underestimated threat. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS 2016), Vienna, Austria, 24–28 October 2016; pp. 1242–1254. [Google Scholar]
- Han, W.; Li, Z.; Ni, M.; Gu, G.; Xu, W. Shadow attacks based on password reuses: A quantitative empirical view. IEEE Trans. Depend. Secur. Comput. 2016. [Google Scholar] [CrossRef]
- VeriClouds Whitepapers & Resources. Available online: https://www.vericlouds.com/resources/ (accessed on 3 March 2018).
- Weir, M.; Aggarwal, S.; de Medeiros, B.; Glodek, B. Password cracking using probabilistic context-free grammars. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 17–20 May 2009; pp. 391–405. [Google Scholar]
- Narayanan, A.; Shmatikov, V. Fast dictionary attacks on passwords using time-space tradeoff. In Proceedings of the 12th ACM Conference on Computer and Communications Security (CCS 2005), Alexandria, VA, USA, 7–11 November 2005; pp. 364–372. [Google Scholar]
- Castelluccia, C.; Durmuth, M.; Perito, D. Adaptive password-strength meters from Markov models. In Proceedings of the 2012 Network and Distributed Systems Security Symposium, San Diego, CA, USA, 5–8 February 2012; pp. 23–26. [Google Scholar]
- Ma, J.; Yang, W.; Luo, M.; Li, N. A study of probabilistic password models. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 689–704. [Google Scholar]
- Komanduri, S. Modeling the Adversary to Evaluate Password Strengh with Limited Samples. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 2016. [Google Scholar]
- Melicher, W.; Ur, B.; Segreti, S.; Komanduri, S.; Bauer, L.; Christin, N.; Cranor, L. Fast, lean and accurate: Modeling password guessability using neural networks. In Proceedings of the 25th USENIX Conference on Security Symposium, Austin, TX, USA, 10–12 August 2016; pp. 1–17. [Google Scholar]
- Ur, B.; Segreti, S.M.; Bauer, L.; Christin, N.; Cranor, L.F.; Komanduri, S.; Kurilova, D.; Mazurek, M.L.; Melicher, W.; Shay, R. Measuring real-world accuracies and biases in modeling password guessability. In Proceedings of the 24th USENIX Conference on Security Symposium (USENIX SEC 2015), Washington, DC, USA, 12–14 August 2015; pp. 463–481. [Google Scholar]
- Wang, D.; Wang, P. On the implications of Zipf’s law in passwords. In Proceedings of the European Symposium on Research in Computer Security, Heraklion, Greece, 26–30 September 2016; pp. 1–21. [Google Scholar]
- Zhang, Y.; Monrose, F.; Reiter, M. The security of modern password expiration: An algorithmic framework and empirical analysis. In Proceedings of the 17th ACM conference on Computer and Communications Security (CCS 2010), Chicago, IL, USA, 4–8 October 2010; pp. 176–186. [Google Scholar]
- Wang, C.; Jan, S.T.K.; Hu, H.; Wang, G. Empirical analysis of password reuse and modification across online service. arXiv, 2017; arXiv:1706.01939. [Google Scholar]
- Harsha, B.; Blocki, J. Just in Time Hashing. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 368–383. [Google Scholar]
- Li, Y.; Wang, H.; Sun, K. A study of personal information in human-chosen passwords and its security implications. In Proceedings of the 35th Annual IEEE International Conference on Computer Communications (INFOCOM 2016), San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Oechslin, P. Making a faster cryptanalytic time-memory trade-off. In Proceedings of the Annual International Cryptology Conference (CRYPTO 2003), Santa Barbara, CA, USA, 17–21 August 2003; pp. 617–630. [Google Scholar]
- Provos, N.; Mazières, D. A future-adaptable password scheme. In Proceedings of the USENIX Annual Technical Conference 1999 (FREENIX Track), Monterey, CA, USA, 6–11 June 1999; pp. 81–91. [Google Scholar]
- Percival, C. Stronger Key Derivation via Sequential Memory-Hard Functions. Presentation at BSDCan 2009. Available online: http://www.tarsnap.com/scrypt/scrypt.pdf (accessed on 10 May 2018).
- Kaliski, B. PKCS #5: Password-Based Cryptography Specification Version 2.0. RFC 2898. 2000. Available online: http://tools.ietf.org/html/rfc2898 (accessed on 6 April 2018).
- Biryukov, A.; Dinu, D.; Khovratovich, D. Argon2: New generation of memory-hard functions for password hashing and other applications. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 292–302. [Google Scholar]
- Steube, J. PRINCE: Modern Password Guessing Algorithm. Presentation at Passwords 2014. Available online: https://hashcat.net/events/p14-trondheim/prince-attack.pdf (accessed on 16 December 2017).
- Malvoni, K.; Designer, S.; Knezovic, J. Are your passwords safe: Energy-efficient bcrypt cracking with low-Cost parallel hardware. In Proceedings of the 8th USENIX Workshop on Offensive Technologies (WOOT 2014), San Diego, CA, USA, 19 August 2014. [Google Scholar]
- Blocki, J.; Harsha, B.; Zhou, S. On the economics of offline password cracking. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018. [Google Scholar]
- Blocki, J.; Harsha, B.; Kang, S.; Lee, S.; Xing, L.; Zhou, S. Data-Independent Memory Hard Functions: New Attacks and Stronger Constructions. 2018. Available online: https://eprint.iacr.org/2018/944 (accessed on 10 May 2018).
- Weir, M.; Aggarwal, S.; Collins, M.; Stern, H. Testing metrics for password creation policies by attacking large sets of revealed passwords. In Proceedings of the 17th ACM Conference on Computer and Communications Security (CCS 2010), Chicago, IL, USA, 4–8 October 2010; pp. 162–175. [Google Scholar]
- Min-Max Heap. Available online: https://en.wikipedia.org/wiki/Min-max_heap (accessed on 10 May 2018).
- Skip List. Available online: https://en.wikipedia.org/wiki/Skip_list (accessed on 3 April 2018).
- Levenshtein Distance. Available online: https://en.wikipedia.org/wiki/Levenshtein_distance (accessed on 10 May 2018).
- Heapsort. Available online: https://en.wikipedia.org/wiki/Heapsort (accessed on 3 April 2018).
- Once Seen as Bulletproof, 11 Million+ Ashley Madison Passwords Already Cracked. Available online: https://arstechnica.com/informationtechnology/2015/09/once-seen-as-bulletproof-11-million-ashley-madison-passwords-already-cracked/ (accessed on 11 December 2017).
- AWS EC2. Available online: https://aws.amazon.com/ec2/?ft=n (accessed on 22 August 2017).
- Amazon EC2 Instance Types. Available online: https://aws.amazon.com/ec2/instance-types/?nc1=h_ls (accessed on 10 May 2018).
- Ding, Z.; Jia, Y.; Zhou, B.; Han, Y. Mining topical influencers based on the multi-relational network in micro-blogging sites. China Commun. 2013. [Google Scholar] [CrossRef]
- Wang, P.; Lu, K.; Li, G.; Zhou, X. DFTracker: Detecting double-fetch bugs by multi-taint parallel tracking. Front. Comput. Sci. 2018, 1–17. [Google Scholar] [CrossRef]
- Wu, Z.; Lu, K.; Wang, X.; Zhou, X. Collaborative technique for concurrency bug detection. Int. J. Parallel Program. 2015, 43, 260–285. [Google Scholar] [CrossRef]
- Wu, T.; Yang, Y. Detecting android inter-app data leakage via compositional concolic walking. J. Autosoft. 2019. [Google Scholar] [CrossRef]
- Wu, Z.; Lu, K.; Wang, X.; Zhou, X.; Chen, C. Detecting harmful data races through parallel verification. J. Supercomput. 2015, 71, 2922–2943. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | #Accounts | Year |
|---|---|---|
| Exploit.in Combo List | 593,427,119 | 2016 |
| Anti Public Combo List | 457,962,538 | 2016 |
| MySpace | 359,420,698 | 2008 |
| NetEase | 234,842,089 | 2015 |
| 164,611,595 | 2012 | |
| Badoo | 112,005,531 | 2013 |
| Target | Cost | #Accounts | %Overlap | %Recovered |
|---|---|---|---|---|
| Dropbox-styled list | 8 | 31,862,436 | 59.1% | 20.1% |
| AshleyMadison (AM)-styled list | 12 | 30,653,460 | 46.7% | 19.4% |
| Edmodo-styled list | 12 | 43,488,310 | 21.4% | 8.1% |
| csdn.net (CSDN)-styled list (re-hashed) | 12 | 6,428,630 | 39.2% | 24.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Yang, Y.; Wang, C.; Wang, R. Study on Massive-Scale Slow-Hash Recovery Using Unified Probabilistic Context-Free Grammar and Symmetrical Collaborative Prioritization with Parallel Machines. Symmetry 2019, 11, 450. https://doi.org/10.3390/sym11040450
Wu T, Yang Y, Wang C, Wang R. Study on Massive-Scale Slow-Hash Recovery Using Unified Probabilistic Context-Free Grammar and Symmetrical Collaborative Prioritization with Parallel Machines. Symmetry. 2019; 11(4):450. https://doi.org/10.3390/sym11040450
Chicago/Turabian StyleWu, Tianjun, Yuexiang Yang, Chi Wang, and Rui Wang. 2019. "Study on Massive-Scale Slow-Hash Recovery Using Unified Probabilistic Context-Free Grammar and Symmetrical Collaborative Prioritization with Parallel Machines" Symmetry 11, no. 4: 450. https://doi.org/10.3390/sym11040450
APA StyleWu, T., Yang, Y., Wang, C., & Wang, R. (2019). Study on Massive-Scale Slow-Hash Recovery Using Unified Probabilistic Context-Free Grammar and Symmetrical Collaborative Prioritization with Parallel Machines. Symmetry, 11(4), 450. https://doi.org/10.3390/sym11040450