Data Source Selection Based on an Improved Greedy Genetic Algorithm

Abstract
:1. Introduction
- We first summarize several dimensional indicators that affect the quality of data and establish a linear model to estimate the quality score. A gain-cost model driven by integration scores was proposed, which provides the basis for assessing the value of data sources.
- We propose an improved novel greedy genetic algorithm(IGGA). Not only improved genetic operators, but also a novel greedy strategy are proposed, which makes the source selection problem more efficient.
- We have conducted extensive experiments on real and synthetic datasets. A large number of experimental results show that our algorithm is very competitive against the other state-of-the-art intelligent algorithms in terms of performance and problem solving quality.
2. Related Works
2.1. The Sources Selection Approaches in a Distributed Environment
2.2. Application of a Genetic Algorithm in Combinatorial Optimization
3. Data Source Selection Driven by the Gain-Cost Model
3.1. Problem Definition
3.2. Data Quality and Coverage
3.3. Gain-Cost Models
- Linear gain assumes that the gain grows linearly with a certain composite score metric and sets =
- Step gain assumes that reaching a milestone of quality will significantly increase the gain and set:
- Linear costassumes the cost grows lineraly with the and applies ;
- Step cost assumes reaching some milestone of will significantly increase cost and so applies:
4. Improved Greedy Genetic Algorithm (IGGA)
4.1. Change the Way of Selection
| Algorithm 1 Selection. |
| input: All members of population output: New Selected population 1 Sort all data sources in descending order of fitness; 2 The individual in the top 1/4 is copied twice, the middle 2/4 is kept, the last 1/4 is abandoned and generate a transition population; 3 Generate a random number [0,1]; 4 repeat 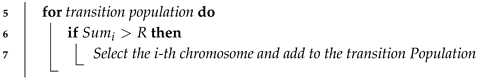 8 until create offspring; |
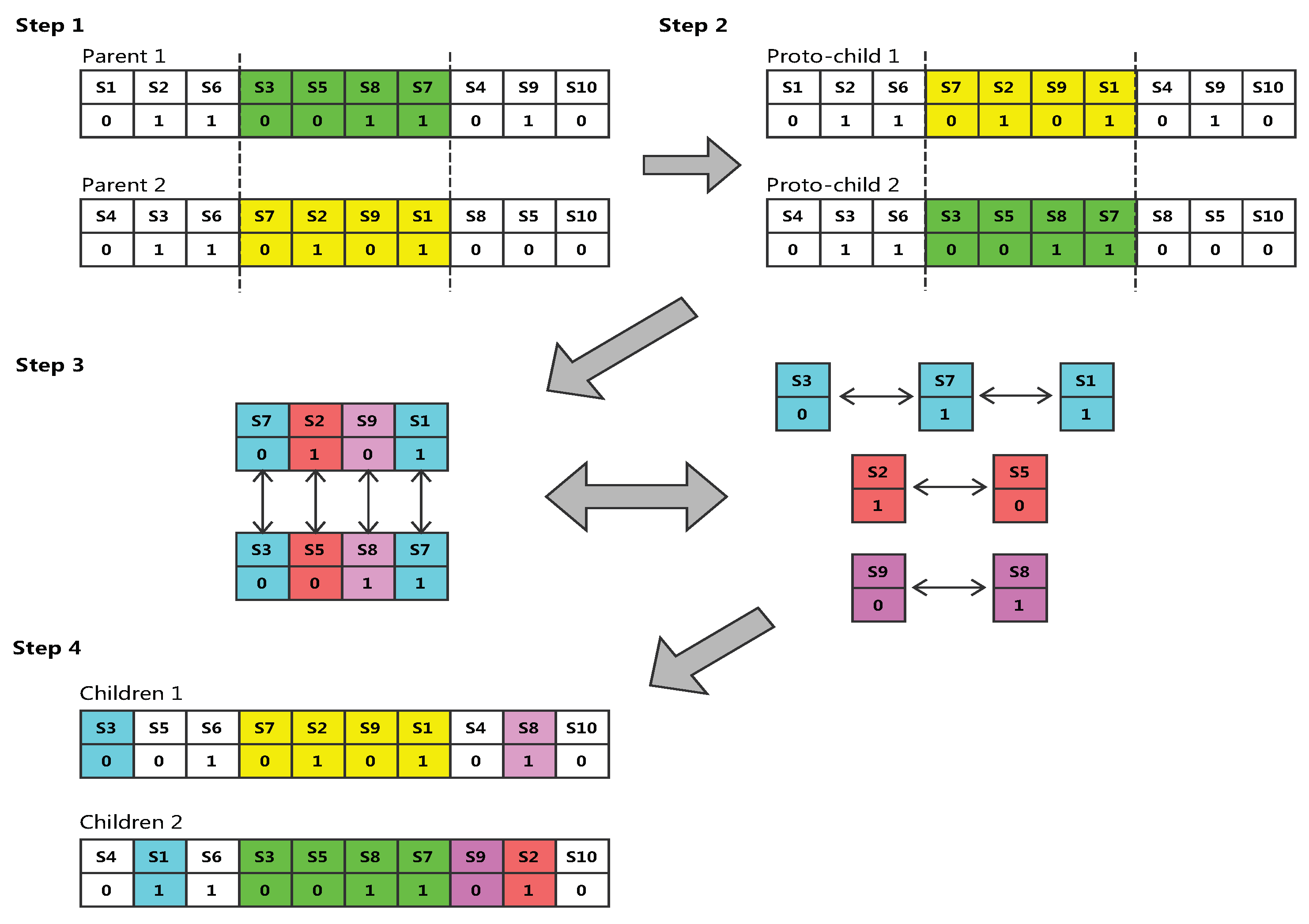
4.2. Crossover
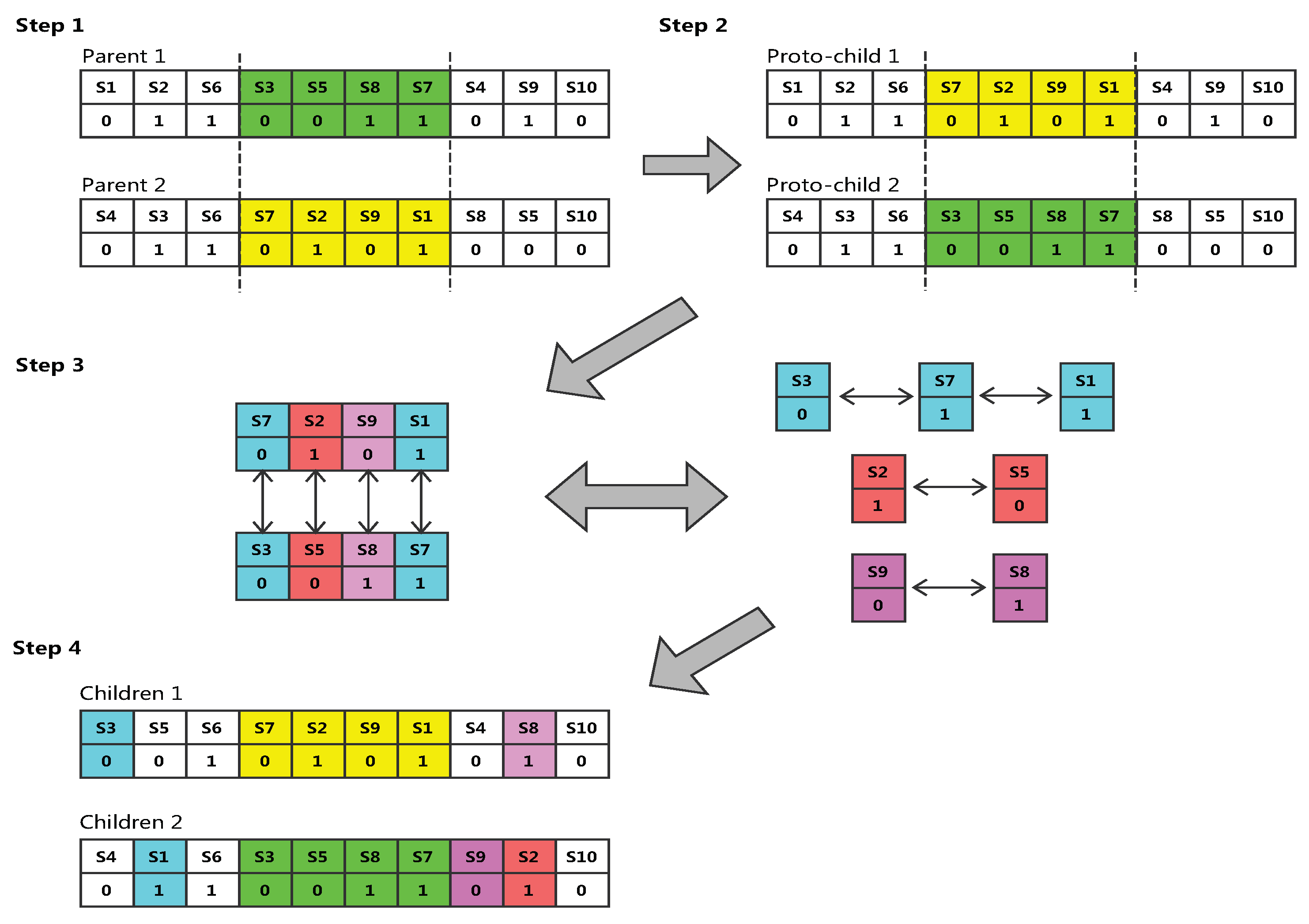
| Algorithm 2 Crossover. |
| input: Parents from the current population. output: Two new children. 1 Let M = () and N = () two parents to crossed; 2 Choose two random number(a,b∣ a<b) on the set {1,2, …k}, two new children and are created according to the following rules: 4 Remove, before the cutting point(a) and after the cutting point(b), the data source which are already placed segment (a,b); 5 Put the corresponding data source on the delete location according to the mapping. |
- Step 1. Randomly select the starting and ending positions of several genes in a pair of chromosomes (the two chromosomes are selected for the same position).
- Step 2. Exchange the location of these two sets of genes.
- Step 3. Detect conflict, according to the exchange of two sets of genes to establish a mapping relationship. Taking as an example, we can see that there are two genes in proto-child two in the second step, when it is transformed into the gene by the mapping relationship, and so on. Finally, all the conflicting genes are eliminated to ensure that the formation of a new pair of offspring genes without conflict.
- Step 4. Finally get the result.
4.3. Novel Greedy Repair Strategy
| Algorithm 3 Greedy repair strategy (GRS). |
| input: Chromosome S = [,,…,], A[0…n], : cost budget output: A new chromosome Y = [,,…,], 1 0, 0; 2 0, 0, 0; 3 Arrange data sources in descending order of gain-cost ratio; 4 for ( 1 to n) do 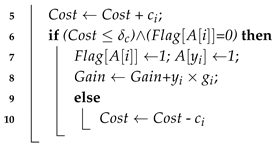 11 return (Y, ) |
4.4. Integrate Greedy Strategy into GAs
| Algorithm 4 Improved greedy genetic algorithm (IGGA). |
| input: , G = {(,,, …, )|( 0≤ i ≤ n)}, C = {(,,, …, )| (0≤ i ≤ n)}, Z, , , output: Optimal solution , Objective gain value 1 A[0…n]←Descending{ / | ∈ G, ∈ C, (0 ≤ i ≤ n)}; 2 Generate randomly an initial population of P = {(0) | 1 ≤ i ≤ Z}; 3 for i← 1 to Z do 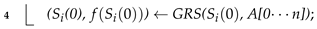 5 Set the number of inner loops r ← 0; 6 while (r ≤ ) do  14 return , ; |
- Step 1. According to the greedy repair strategy, all the selected data sources are non-incrementally sorted according to the ratio of gain and cost.
- Step 2. Use the binary coding method, randomly generate the initial population P, and use the greedy strategy to obtain the initial current optimal solution.
- Step 3. The fitness is calculated for each chromosome in the population P, and if the value corresponding to the chromosome is greater than the current optimal solution, the current solution is replaced.
- Step 4. If the maximum number of iterations is reached, then stop. Otherwise, a crossover operation is performed, and a temporary population is obtained according to the crossover probability.
- Step 5. With a small probability , a certain gene of each chromosome is mutated, and then a temporary population is generated. Use greedy strategies to repair chromosomes that do not meet the constraints.
- Step 6. Select some chromosomes according to Equation (5) to form a new population , and turn to Step 3.
5. Experimental Design and Result
5.1. Experimental Design
- To make the comparison as fair as possible, we discussed the trend of IGGA parameter values under the four gain-cost models and set reasonable values for them.
- We compared the performance of IGGA and DGGA in the synthetic data set. In addition, we made comparisons with other state-of-the-art intelligent algorithms to verify the efficiency of IGGA.
5.1.1. Dataset
5.1.2. Parameter Settings
5.2. Experimental Results
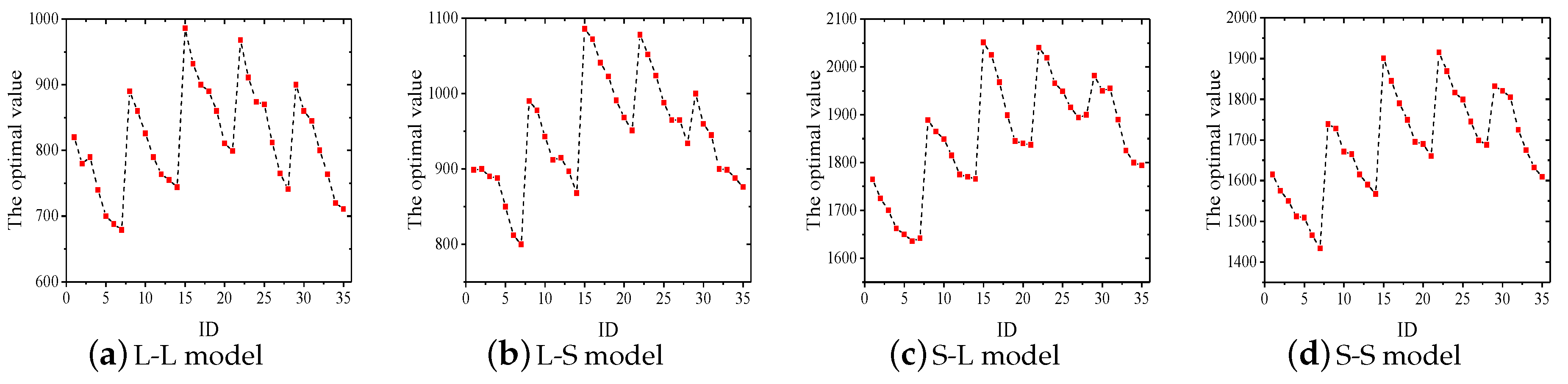
5.2.1. Performance Comparison of Four Algorithms under Different Gain-Cost Models Using Real Datasets
5.2.2. Performance Comparison of Algorithms under Different Source Scales Using Synthetic Datasets
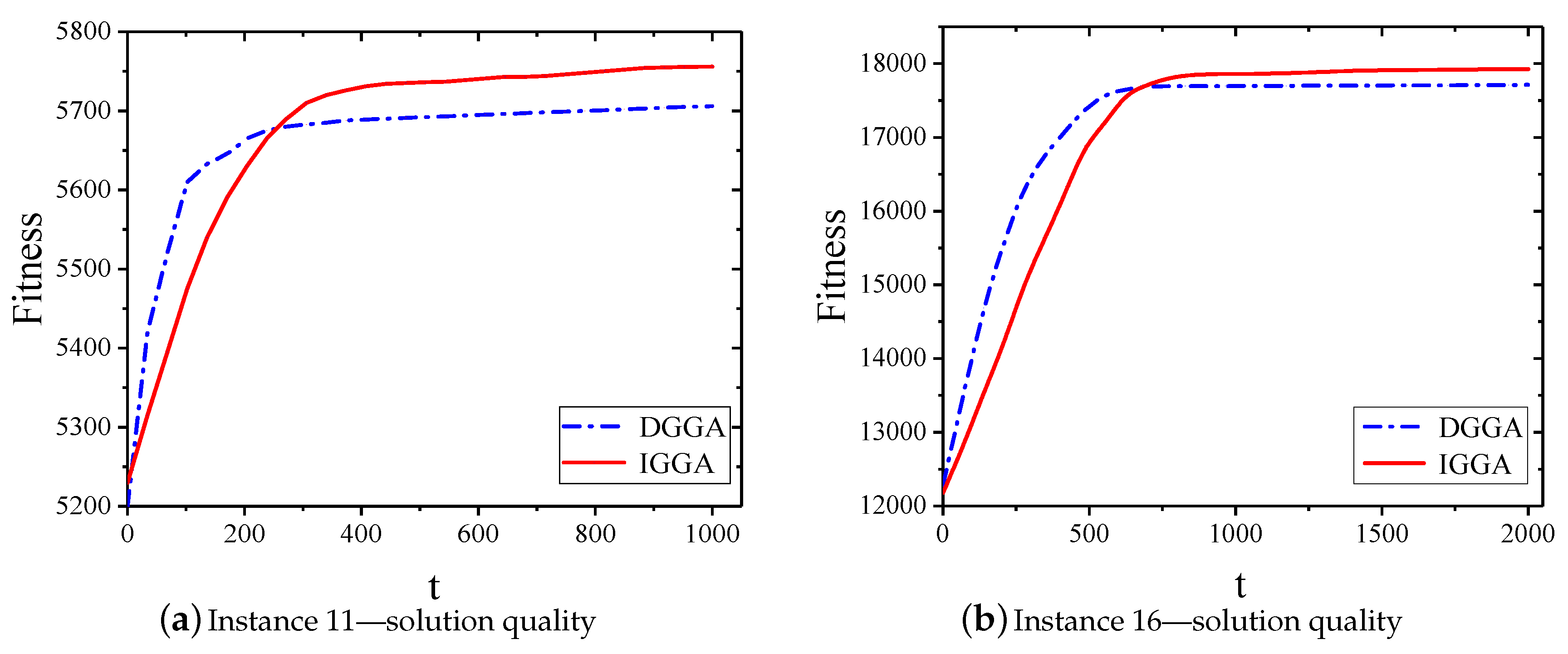
5.2.3. Convergence Analysis
5.2.4. Comparison with Other State-of-the-Art Models
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Factual. Available online: https://www.factual.com/ (accessed on 5 January 2019).
- Infochimps. Available online: http://www.infochimps.com/ (accessed on 5 January 2019).
- Xignite. Available online: http://www.xignite.com/ (accessed on 27 December 2018).
- Microsoft Windows Azure Marketplace. Available online: https://azuremarketplace.microsoft.com/en-us/ (accessed on 8 January 2019).
- Dong, X.L.; Saha, B.; Srivastava, D. Less is More: Selecting Sources Wisely for Integration. Proc. VLDB Endow. 2012, 6, 37–48. [Google Scholar] [CrossRef]
- Rekatsinas, T.; Dong, X.L.; Srivastava, D. Characterizing and Selecting Fresh Data Sources. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD ’14), Snowbird, UT, USA, 22–27 June 2014; pp. 919–930. [Google Scholar]
- Lin, Y.; Wang, H.; Zhang, S.; Li, J.; Gao, H. Efficient Quality-Driven Source Selection from Massive Data Sources. J. Syst. Softw. 2016, 118, 221–233. [Google Scholar] [CrossRef]
- Martello, S.; Pisinger, D.; Toth, P. Dynamic Programming and Strong Bounds for the 0–1 Knapsack Problem. Manag. Sci. 1999, 45, 414–424. [Google Scholar] [CrossRef]
- Martello, S.; Pisinger, D.; Toth, P. New Trends in Exact Algorithms for the 0-1 Knapsack Problem. Eur. J. Oper. Res. 2000, 123, 325–332. [Google Scholar] [CrossRef]
- Chand, J.; Deep, K. A Modified Binary Particle Swarm Optimization for Knapsack Problems. Appl. Math. Comput. 2012, 218, 11042–11061. [Google Scholar]
- He, L.; Huang, Y. Research of ant colony algorithm and the application of 0-1 knapsack. In Proceedings of the 2011 6th International Conference on Computer Science & Education (ICCSE), Singapore, 3–5 August 2011; pp. 464–467. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley: Hoboken, NJ, USA, 1989. [Google Scholar]
- Zhao, J.; Huang, T.; Pang, F.; Liu, Y. Genetic Algorithm Based on Greedy Strategy in the 0-1 Knapsack Problem. In Proceedings of the 2009 Third International Conference on Genetic and Evolutionary Computing, Guilin, China, 14–17 October 2009; pp. 105–107. [Google Scholar]
- Kallel, L.; Naudts, B.; Rogers, A. Theoretical Aspects of Evolutionary Computing; Springer-Verlag: Berlin, Germany, 2013. [Google Scholar]
- Drias, H.; Khennak, I.; Boukhedra, A. A hybrid genetic algorithm for large scale information retrieval. In Proceedings of the 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai, China, 20–22 November 2009; pp. 842–846. [Google Scholar]
- Salomon, R. Improving the Performance of Genetic Algorithms through Derandomization. Softw. Concepts Tools 1997, 18, 175–199. [Google Scholar]
- Balakrishnan, R.; Kambhampati, S. Factal: Integrating Deep Web Based on Trust And relevance. In Proceedings of the 20th International Conference on World Wide Web, WWW 2011, Hyderabad, India, 28 March–1 April 2011; pp. 181–184. [Google Scholar]
- Calì, A.; Straccia, U. Integration of Deepweb Sources: A Distributed Information Retrieval Approach. In Proceedings of the 7th International Conference on Web Intelligence, Mining and Semantics, Amantea, Italy, 19–22 June 2017; pp. 1–4. [Google Scholar]
- Nuray, R.; Can, F. Automatic Ranking of Information Retrieval Systems Using Data Fusion. Inf. Process. Manag. 2006, 42, 595–614. [Google Scholar] [CrossRef]
- Xu, J.; Pottinger, R. Integrating Domain Heterogeneous Data Sources Using Decomposition Aggregation Queries. Inf. Syst. 2014, 39, 80–107. [Google Scholar] [CrossRef]
- Moreno-Schneider, J.; Martínez, P.; Martínez-Fernández, J.L. Combining heterogeneous sources in an interactive multimedia content retrieval model. Expert Syst. Appl. 2017, 69, 201–213. [Google Scholar] [CrossRef]
- Abel, E.; Keane, J.; Paton, N.W.; Fernandes, A.A.A.; Koehler, M.; Konstantinou, N.; Cesar, J.; Rios, C.; Azuan, N.A.; Embury, S.M. User Driven Multi-Criteria Source Selection. Inf. Sci. 2018, 431, 179–199. [Google Scholar] [CrossRef]
- Al Mashagba, E.; Al Mashagba, F.; Nassar, M.O. Query Optimization Using Genetic Algorithms in the Vector Space Model. arXiv, 2011; arXiv:1112.0052. [Google Scholar]
- Araujo, L.; Pérez-Iglesias, J. Training a Classifier for the Selection of Good Query Expansion Terms with a Genetic Algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Sun, M.; Dou, H.; Li, Q.; Yan, Z. Quality Estimation of Deep Web Data Sources for Data Fusion. Procedia Eng. 2012, 29, 2347–2354. [Google Scholar] [CrossRef]
- Nguyen, H.Q.; Taniar, D.; Rahayu, J.W.; Nguyen, K. Double-Layered Schema Integration of Heterogeneous XML Sources. J. Syst. Softw. 2011, 84, 63–76. [Google Scholar] [CrossRef]
- Lebib, F.Z.; Mellah, H.; Drias, H. Enhancing Information Source Selection Using a Genetic Algorithm and Social Tagging. Int. J. Inf. Manag. 2017, 37, 741–749. [Google Scholar] [CrossRef]
- Kumar, R.; Singh, S.K.; Kumar, V. A Heuristic Approach for Search Engine Selection in Meta-Search Engine. In Proceedings of the International Conference on Computing, Communication & Automation, Noida, India, 15–16 May 2015; pp. 865–869. [Google Scholar]
- Abououf, M.; Mizouni, R.; Singh, S.; Otrok, H.; Ouali, A. Multi-worker multitask selection framework in mobile crowd sourcing. J. Netw. Comput. Appl. 2019. [Google Scholar] [CrossRef]
- Larr Naga, P.; Kuijpers, C.M.H.; Murga, R.H.; Inza, I.; Dizdarevic, S. Genetic Algorithms for the Travelling Salesman Problem: A Review of Representations and Operators. Artif. Intell. Rev. 1999, 13, 129–170. [Google Scholar] [CrossRef]
- Lim, T.Y.; Al-Betar, M.A.; Khader, A.T. Taming the 0/1 Knapsack Problem with Monogamous Pairs Genetic Algorithm. Expert Syst. Appl. 2016, 54, 241–250. [Google Scholar] [CrossRef]
- Quiroz-Castellanos, M.; Cruz-Reyes, L.; Torres-Jimenez, J.; Claudia Gómez, S.; Huacuja, H.J.F.; Alvim, A.C.F. A Grouping Genetic Algorithm with Controlled Gene Transmission for the Bin Packing Problem. Comput. Oper. Res. 2015, 55, 52–64. [Google Scholar] [CrossRef]
- Sarma, A.D.; Dong, X.L.; Halevy, A. Data Integration with Dependent Sources. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–24 March 2011. [Google Scholar]
- Vetrò, A.; Canova, L.; Torchiano, M.; Minotas, C.O.; Iemma, R.; Morando, F. Open Data Quality Measurement Framework: Definition and Application to Open Government Data. Gov. Inf. Q. 2016, 33, 325–337. [Google Scholar] [CrossRef]
- Liu, W.; Liu, G. Genetic Algorithm with Directional Mutation Based on Greedy Strategy for Large-Scale 0–1 Knapsack Problems. Int. J. Adv. Comput. Technol 2012, 4, 66–74. [Google Scholar] [CrossRef]
- The Book and Flight datasets. Available online: http://lunadong.com/fusionDataSets.htm (accessed on 13 October 2018).
- Zou, D.; Gao, L.; Li, S.; Wu, J. Solving 0-1 Knapsack Problem by a Novel Global Harmony Search Algorithm. Appl. Soft Comput. J. 2011, 11, 1556–1564. [Google Scholar] [CrossRef]
- Pospichal, P.; Schwarz, J.; Jaros, J. Parallel Genetic Algorithm Solving 0/1 Knapsack Problem Running on the GPU. Mendel 2010, 1, 64–70. [Google Scholar]
- Srinivas, M.; Patnaik, L.M. Adaptive Probabilities of Crossover and Mutation in Genetic Algorithms. IEEE Trans. Syst. Man Cybern. 1994, 24, 656–667. [Google Scholar] [CrossRef]
- He, Y.; Wang, X. Group theory-based optimization algorithm for solving knapsack problems. Knowl.-Based Syst. 2018. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, S.; Hu, Y.; Zhang, Y.; Mahadevan, S.; Deng, Y. Solving 0-1 Knapsack Problems Based on Amoeboid Organism Algorithm. Appl. Math. Comput 2013, 219, 9959–9970. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Metric | Description | Variables | Formula |
|---|---|---|---|---|
| Completeness | Proportion of complete cells | Indicates the proportion of complete cells in a dataset. It means the cells that are not empty and have a meaningful value assigned. | : Number of rows : Number of columns : Number of incomplete cells : Number of cells | = = 1− |
| Redundancy | Proportion of duplicate records | Redundancy expresses the proportion of duplicate records in the data source. Since this factor is the cost-indicator, we convert it to the benefit-indicator. | : Number of rows : Number of duplicate records | = 1− |
| Accuracy | Proportion of accurate cells | Indicate the proportion cells in a data source that has correct values according to the domain and the type of information of the data source. | : Number of cells with errors : Number of cells | = 1− |
| Cost | Linear | Step | |
|---|---|---|---|
| Gain | |||
| Linear | L-L | L-S | |
| Step | S-L | S-S | |
| ID | Name | Age | Sex | Status | Entry_Time | Salary | City | Area Code |
|---|---|---|---|---|---|---|---|---|
| 1 | Renata | 23 | F | married | 2013/5 | 50k | Shanghai | 021 |
| 3 | Jeremy | 36 | — | married | 2010/7 | 95k | Beijing | 020 |
| 4 | Armand | — | F | single | 2011/6 | — | Beijing | 010 |
| 6 | Leona | 46 | M | married | — | 120k | Guangzhou | 021 |
| 9 | Renata | 34 | F | married | 2013/5 | 50k | Shanghai | 021 |
| Source | ||||||
|---|---|---|---|---|---|---|
| Flag | 1 | 1 | 1 | 0 | 1 | 1 |
| The ratio of gain-cost | 6 | 4 | 3 | 2 | 1.5 | 1 |
| Gain | 90 | 80 | 75 | 100 | 45 | 10 |
| Cost | 15 | 20 | 25 | 50 | 30 | 10 |
| ID | ID | ID | ID | ID | |||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 8 | 15 | 22 | 29 | |||||
| 2 | 9 | 16 | 23 | 30 | |||||
| 3 | 10 | 17 | 24 | 31 | |||||
| 4 | 11 | 18 | 25 | 32 | |||||
| 5 | 12 | 19 | 26 | 33 | |||||
| 6 | 13 | 20 | 27 | 34 | |||||
| 7 | 14 | 21 | 28 | 35 |
| Datasets | Index | Gain | Cost | Algorithm | Best | Mean | Worst | S.D | Time |
|---|---|---|---|---|---|---|---|---|---|
| Book | 1 | Linear | Linear | IGGA | 986.32 | 963.16 | 921.41 | 6.84 | 2.423 |
| DGGA | 953.16 | 921.84 | 886.62 | 13.89 | 2.218 | ||||
| BPSO | 911.64 | 863.71 | 838.50 | 14.22 | 3.135 | ||||
| ACA | 935.55 | 896.39 | 865.04 | 16.49 | 3.352 | ||||
| 2 | Step | IGGA | 1092.21 | 1041.62 | 989.58 | 9.58 | 1.883 | ||
| DGGA | 967.08 | 894.21 | 847.33 | 11.98 | 1.684 | ||||
| BPSO | 988.36 | 918.48 | 843.24 | 16.69 | 2.418 | ||||
| ACA | 1013.14 | 968.74 | 921.37 | 12.99 | 2.350 | ||||
| 3 | Step | Linear | IGGA | 2052.45 | 1988.17 | 1923.62 | 8.73 | 2.045 | |
| DGGA | 2037.22 | 1942.46 | 1890.54 | 8.94 | 1.976 | ||||
| BPSO | 2055.86 | 1968.04 | 1904.88 | 15.83 | 2.724 | ||||
| ACA | 2011.37 | 1904.32 | 1852.56 | 18.48 | 2.831 | ||||
| 4 | Step | IGGA | 1926.05 | 1868.74 | 1831.81 | 7.17 | 1.928 | ||
| DGGA | 1902.28 | 1828.79 | 1787.03 | 9.89 | 1.882 | ||||
| BPSO | 1908.45 | 1803.86 | 1762.26 | 13.92 | 2.281 | ||||
| ACA | 1895.32 | 1789.92 | 1723.04 | 17.34 | 2.292 | ||||
| Flight | 1 | Linear | Linear | IGGA | 436.77 | 417.62 | 394.17 | 6.35 | 0.116 |
| DGGA | 421.21 | 396.45 | 376.35 | 8.06 | 0.102 | ||||
| BPSO | 413.58 | 388.39 | 369.67 | 11.20 | 0.185 | ||||
| ACA | 405.18 | 384.35 | 374.58 | 7.47 | 0.206 | ||||
| 2 | Step | IGGA | 465.26 | 437.72 | 421.28 | 5.58 | 0.108 | ||
| DGGA | 472.16 | 431.31 | 415.84 | 7.92 | 0.112 | ||||
| BPSO | 442.04 | 406.46 | 381.26 | 10.52 | 0.168 | ||||
| ACA | 416.37 | 390.61 | 373.92 | 8.96 | 0.179 | ||||
| 3 | Step | Linear | IGGA | 1105.54 | 1062.48 | 970.14 | 11.64 | 0.227 | |
| DGGA | 1045.34 | 991.67 | 966.38 | 8.95 | 0.198 | ||||
| BPSO | 992.32 | 936.72 | 893.15 | 10.40 | 0.294 | ||||
| ACA | 1019.93 | 958.61 | 902.94 | 13.94 | 0.315 | ||||
| 4 | Step | IGGA | 964.15 | 908.23 | 870.66 | 7.88 | 0.206 | ||
| DGGA | 972.37 | 902.52 | 862.17 | 10.95 | 0.192 | ||||
| BPSO | 911.63 | 858.35 | 810.81 | 14.75 | 0.308 | ||||
| ACA | 902.46 | 852.58 | 803.96 | 15.56 | 0.336 |
| Algorithm | IGGA | DGGA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ID | Scale | Best | Worst | Mean | S.D | Best | Worst | Mean | S.D |
| 1 | 10 | 295 | 295 | 295 | 0 | 295 | 288 | 292.32 | 1.24 |
| 2 | 20 | 1024 | 1024 | 1024 | 0 | 1024 | 1024 | 1024 | 0 |
| 3 | 4 | 35 | 35 | 35 | 0 | 35 | 28 | 34.58 | 1.56 |
| 4 | 4 | 23 | 23 | 23 | 0 | 23 | 23 | 23 | 0 |
| 5 | 15 | 481.07 | 481.07 | 481.07 | 0 | 481.07 | 438.24 | 478.57 | 9.38 |
| 6 | 10 | 50 | 50 | 50 | 0 | 50 | 40 | 46.8 | 1.96 |
| 7 | 7 | 107 | 107 | 107 | 0 | 107 | 93 | 106.2 | 1.38 |
| 8 | 23 | 9776 | 9776 | 9776 | 0 | 9767 | 9754 | 9766.32 | 0.76 |
| 9 | 5 | 130 | 130 | 130 | 0 | 130 | 130 | 130 | 0 |
| 10 | 20 | 1025 | 1025 | 1025 | 0 | 1025 | 1025 | 1025 | 0 |
| 11 | 30 | 5786 | 5380 | 5765 | 32.63 | 5716 | 5245 | 5560 | 54.47 |
| 12 | 40 | 4994 | 3857 | 4903 | 18.25 | 4994 | 3548 | 3742 | 35.82 |
| 13 | 100 | 6983 | 6854 | 6938.23 | 16.92 | 6879 | 6781 | 6857.34 | 20.57 |
| 14 | 200 | 10,799 | 10,677 | 10,731.22 | 23.42 | 10,522 | 10,282 | 10,358.73 | 36.45 |
| 15 | 300 | 13,368 | 13,104 | 13,271.94 | 54.04 | 12,566 | 12,362 | 12,472.45 | 75.54 |
| 16 | 500 | 18,111 | 17,684 | 17,878.74 | 92.34 | 17,921 | 17,450 | 17,743.37 | 146.08 |
| 17 | 800 | 37,338 | 36,892 | 37,172.17 | 114.16 | 35,147 | 34,741 | 34,914.81 | 189.47 |
| 18 | 1000 | 64,847 | 64,315 | 64,533.04 | 136.37 | 60,132 | 58,994 | 59,628.06 | 285.26 |
| 19 | 1200 | 86,399 | 85,847 | 86,142.41 | 88.17 | 86,003 | 85,224 | 85,647.24 | 352.06 |
| 20 | 1500 | 101,556 | 101,214 | 101,427.26 | 64.34 | 98,862 | 97,938 | 98,575.67 | 465.23 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Xing, C. Data Source Selection Based on an Improved Greedy Genetic Algorithm. Symmetry 2019, 11, 273. https://doi.org/10.3390/sym11020273
Yang J, Xing C. Data Source Selection Based on an Improved Greedy Genetic Algorithm. Symmetry. 2019; 11(2):273. https://doi.org/10.3390/sym11020273
Chicago/Turabian StyleYang, Jian, and Chunxiao Xing. 2019. "Data Source Selection Based on an Improved Greedy Genetic Algorithm" Symmetry 11, no. 2: 273. https://doi.org/10.3390/sym11020273
APA StyleYang, J., & Xing, C. (2019). Data Source Selection Based on an Improved Greedy Genetic Algorithm. Symmetry, 11(2), 273. https://doi.org/10.3390/sym11020273