Intersection Traffic Prediction Using Decision Tree Models


Abstract
1. Introduction
2. Related Works
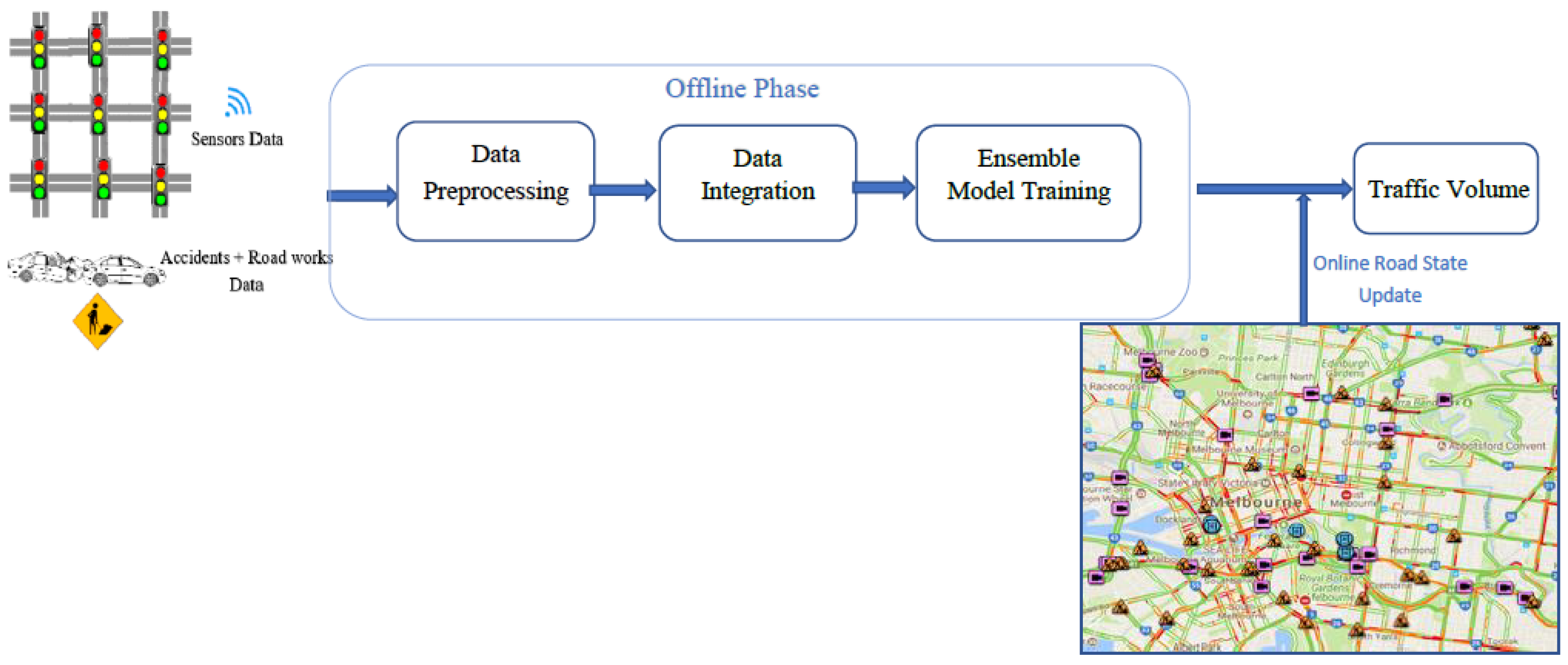
3. Data Integration and Preprocessing
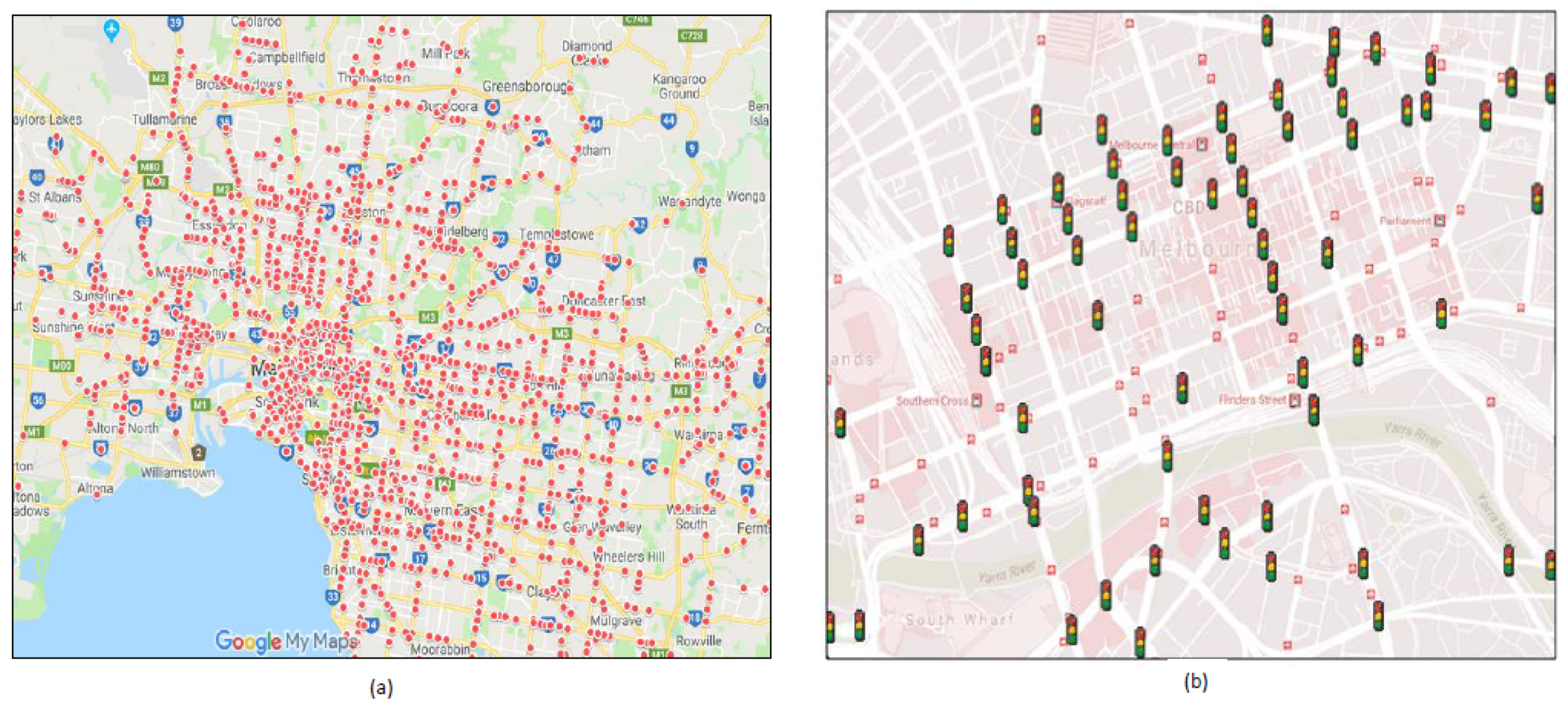
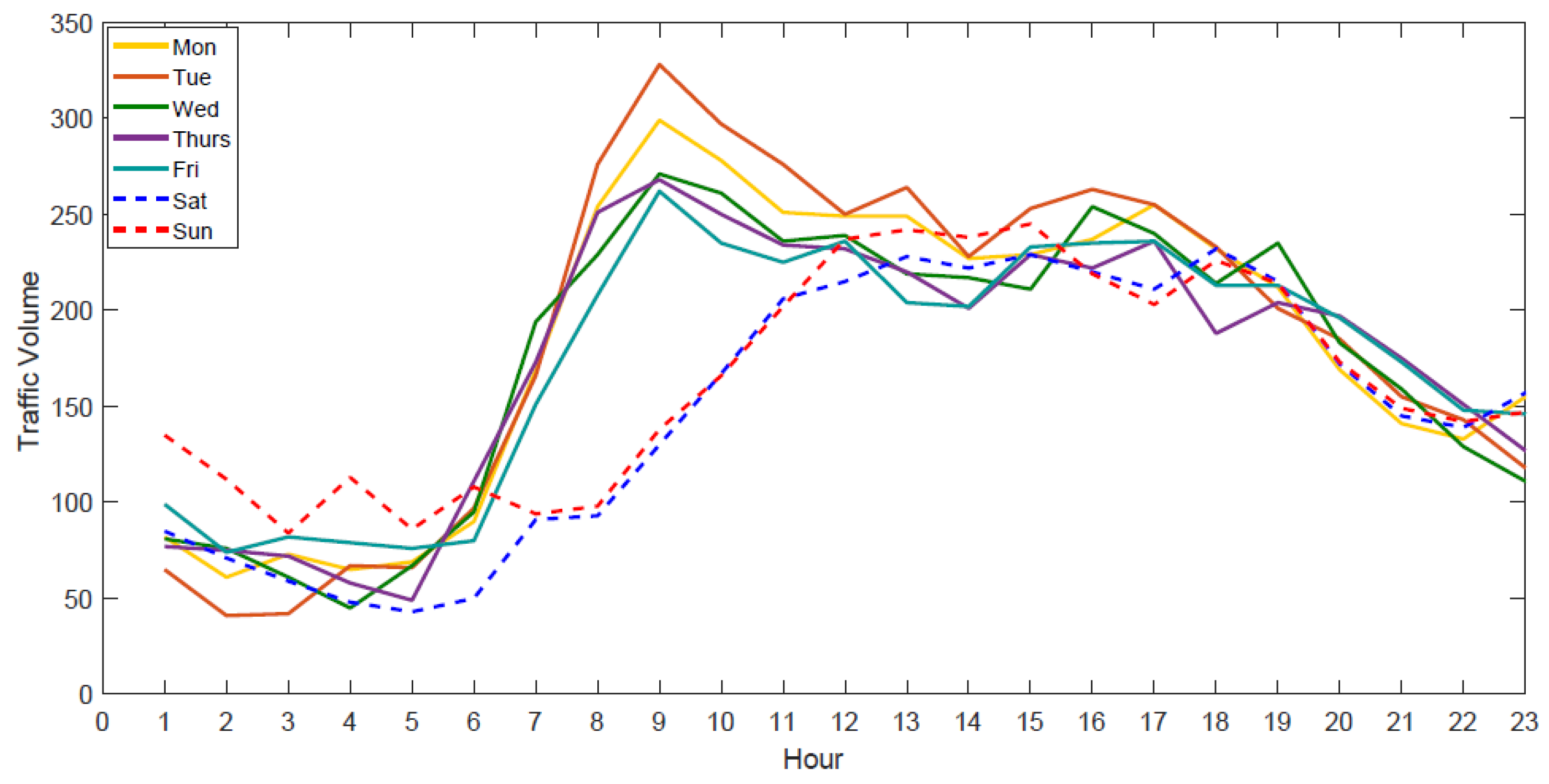
3.1. Data Sets
3.2. Features Selection
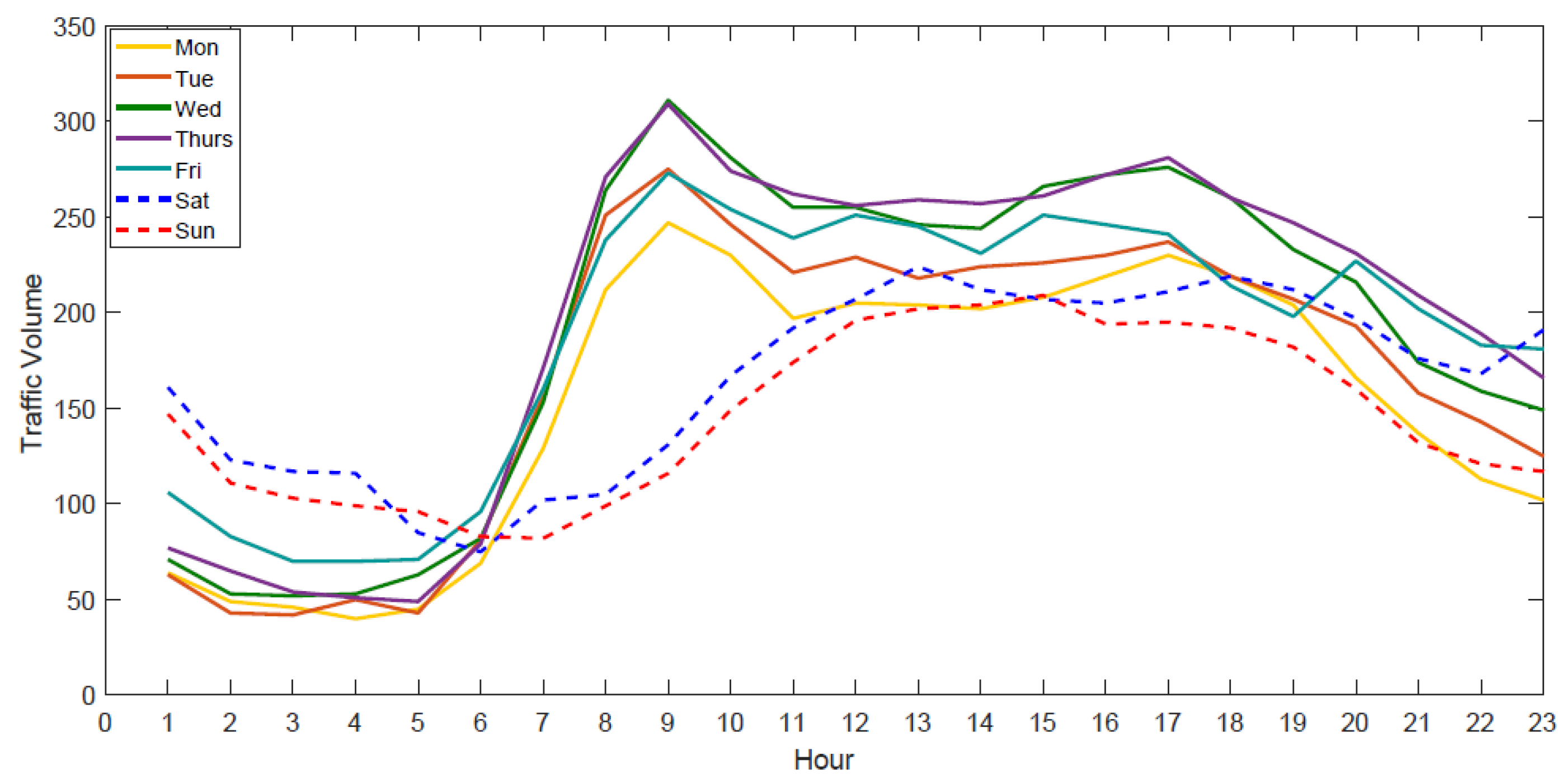
- The day of the week: The feature was selected because lots of existing studies have shown that traffic patterns differ on different days of the week.
- Weekend/weekday: Set to 1 if the day is on the weekend; set to 0 otherwise. The feature was selected because the traffic patterns during weekends are usually different from those during weekdays.
- Peak/Off-Peak: Set to 1 if the time is between 6:00 and 13:00 h; set to 0 otherwise. The feature was selected because the traffic patterns during peak hours are usually different from those during off-peak hours.
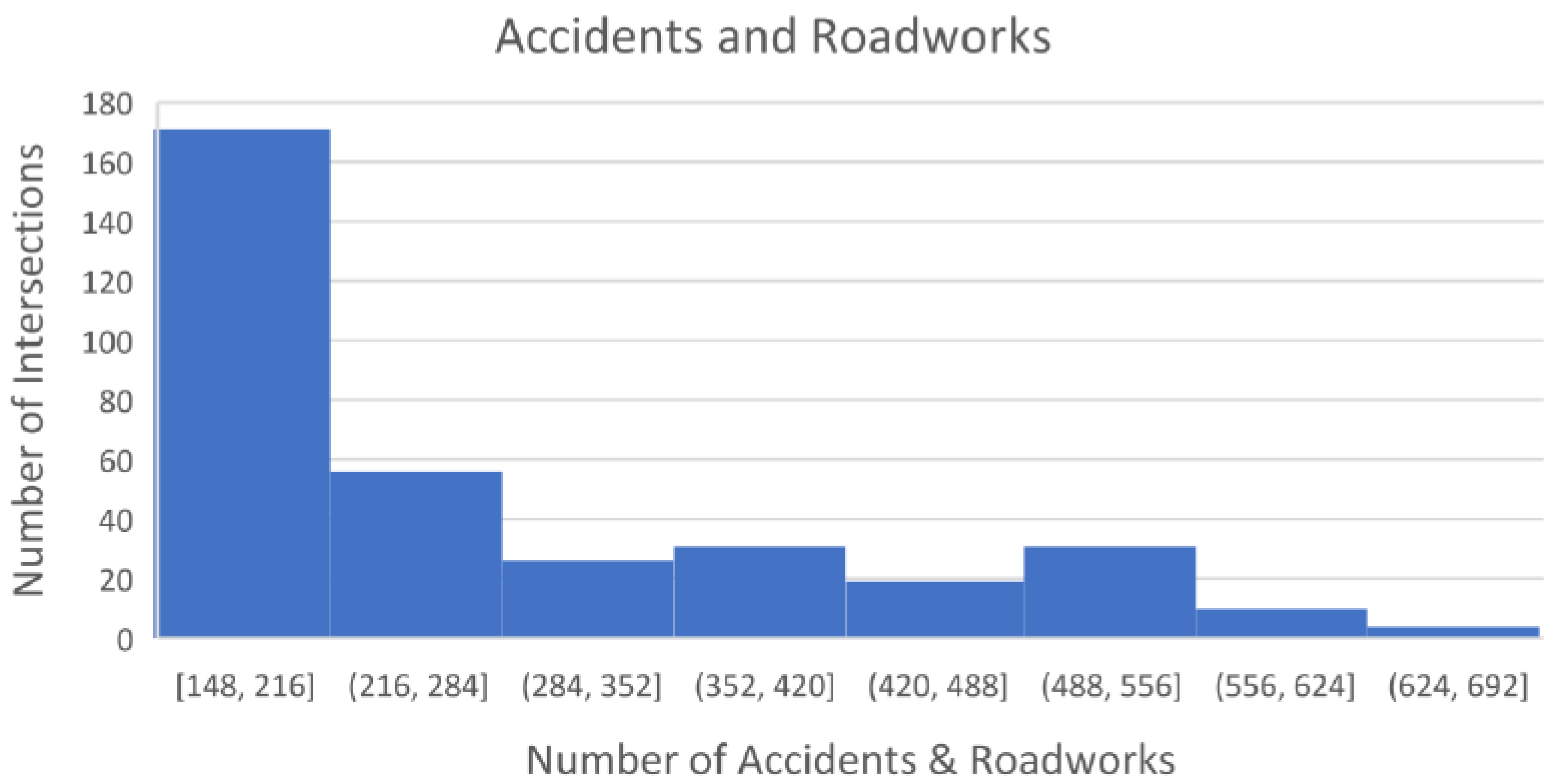
- Event Distance: As discussed above, traffic patterns change if a nonrecurring event, such as an accident or roadwork, occurs. One of the key contributions of this study is introducing this feature into the process of traffic prediction at intersections. The distance was calculated using the Haversine distance function in Python to find the distance between two coordinates. The value of this feature was 0 if there was no event within 500 m, 1 if the distance was 0–199 m, 2 if the distance was 200–299 m and 3 if the distance was 400–500 m. Figure 2 shows the number of events within 500 m in a subset of intersections in our data set.
- Time: Clock time was used as a feature after converting it into float:
- Day/night: This feature distinguishes whether the time is day time or night time.
4. Proposed Methods
4.1. Batch Learning
4.1.1. Gradient Boosting Regression Trees
4.1.2. Random Forest
- Input: An n-dimensional vector ().
- Output: A predictor (y).
- Step 1: Bootstrap sampling. In this step, the RF selects a random number of data points with replacement to generate a new training set. Unselected examples are marked as out-of-bag (OOB).
- Step 2: Decision tree generation. A fully grown decision tree is constructed in this step using the training set without pruning. At each node split, the best feature set from a random number of features subsets is selected until there are no more splits.
- Repetition: Step 1 and step 2 are repeated until C number of trees is reached.
- Step 3: C output values are aggregated to obtain the final output (y) by taking the mean of the output values of all the generated trees, as described in Equation (11):where is the set of input samples, and is the output of the jth tree.
4.2. XGBoost
4.3. Online Learning
5. Results
5.1. Features Importance
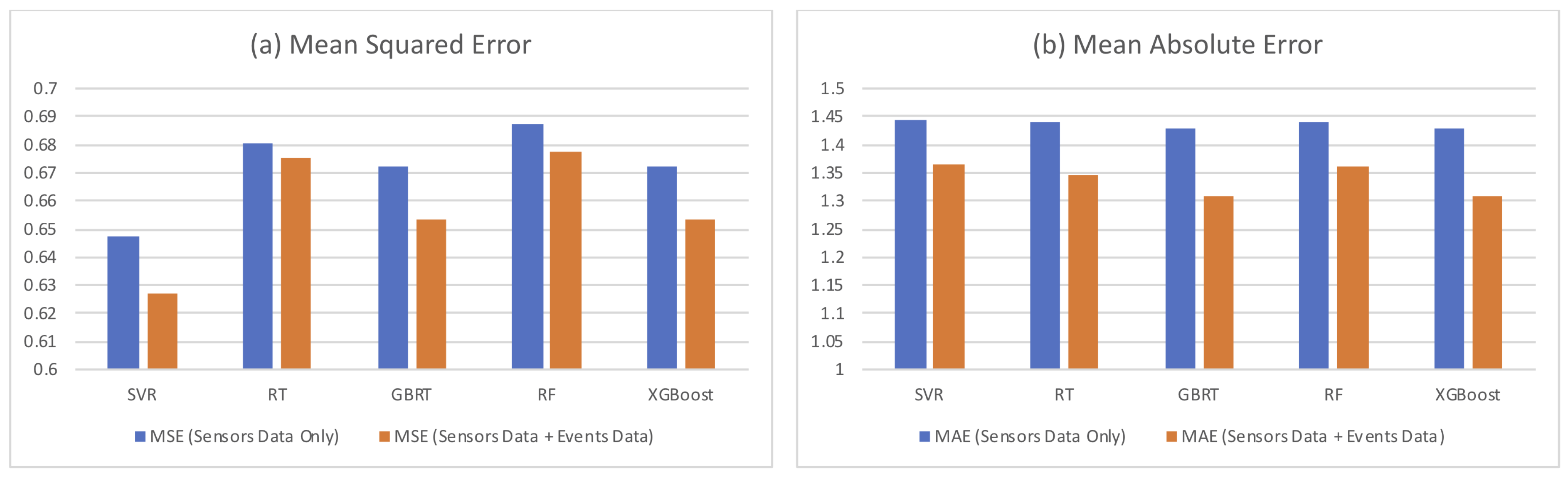
5.2. Model Comparison
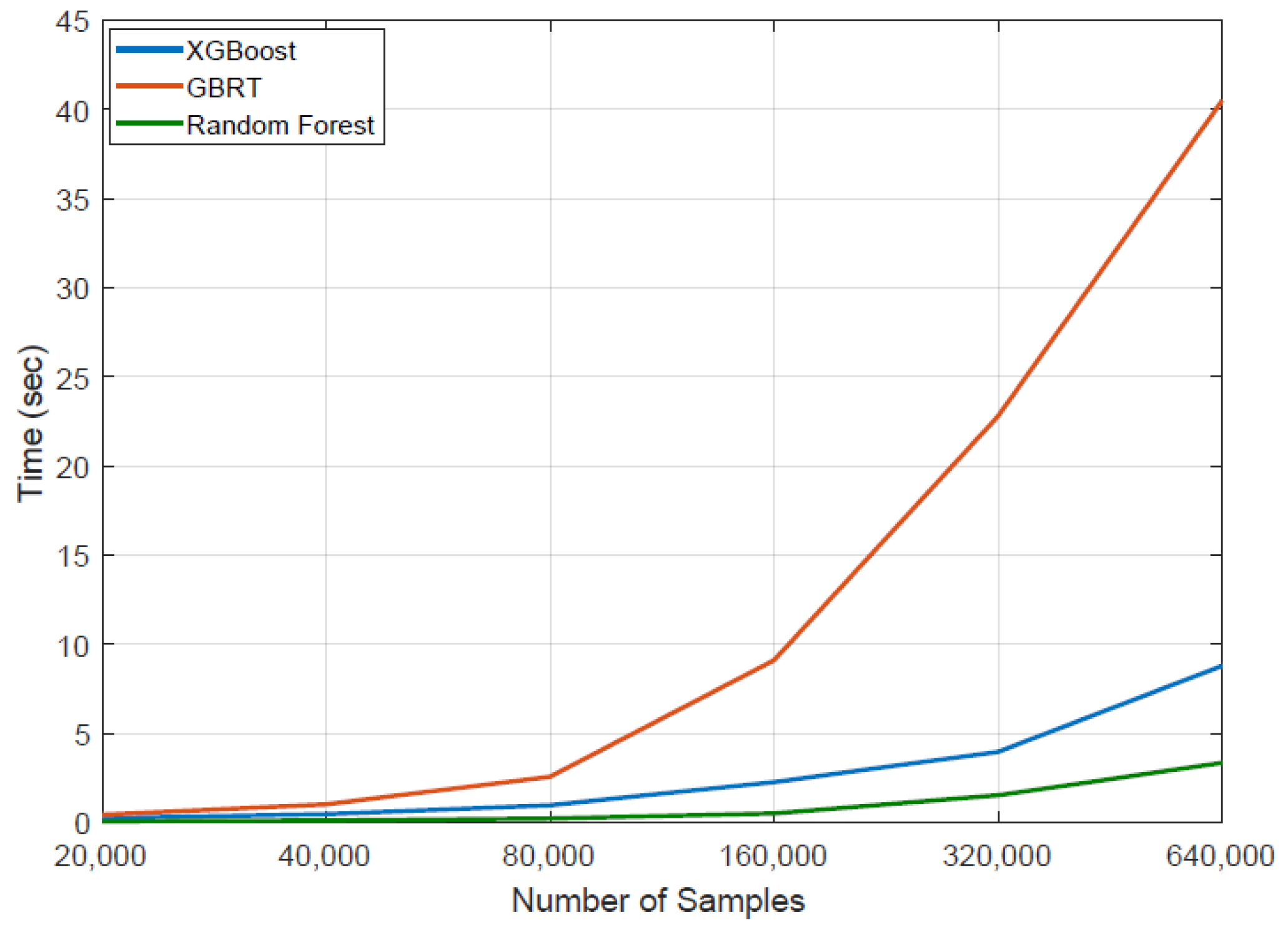
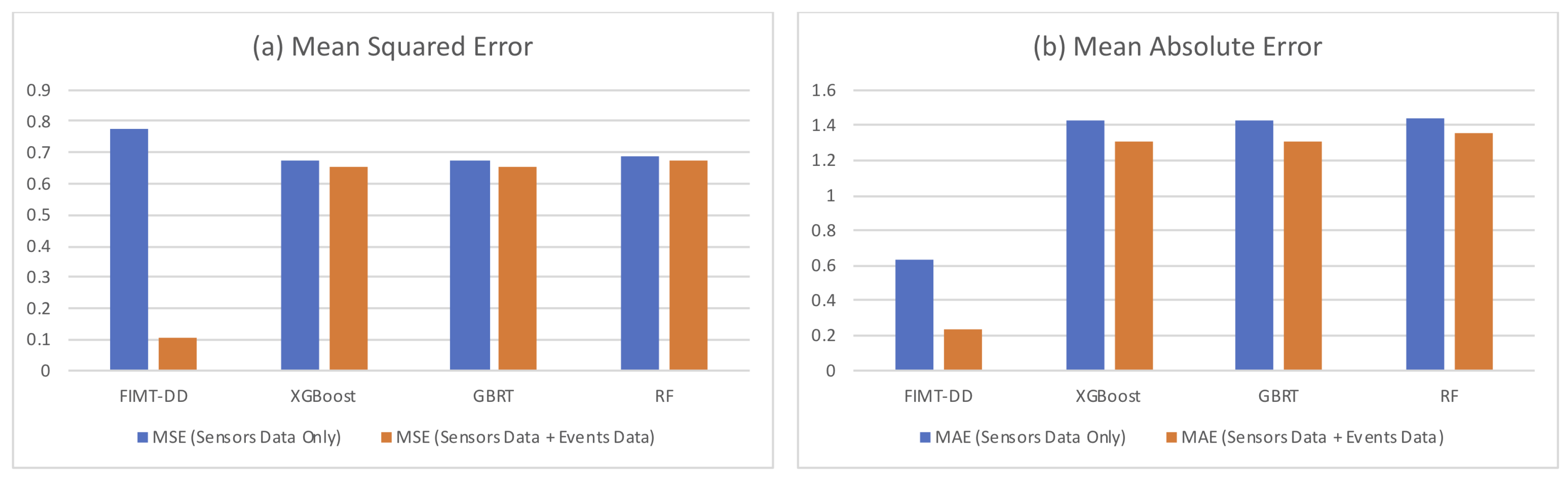
5.3. Results of Batch Learning Methods
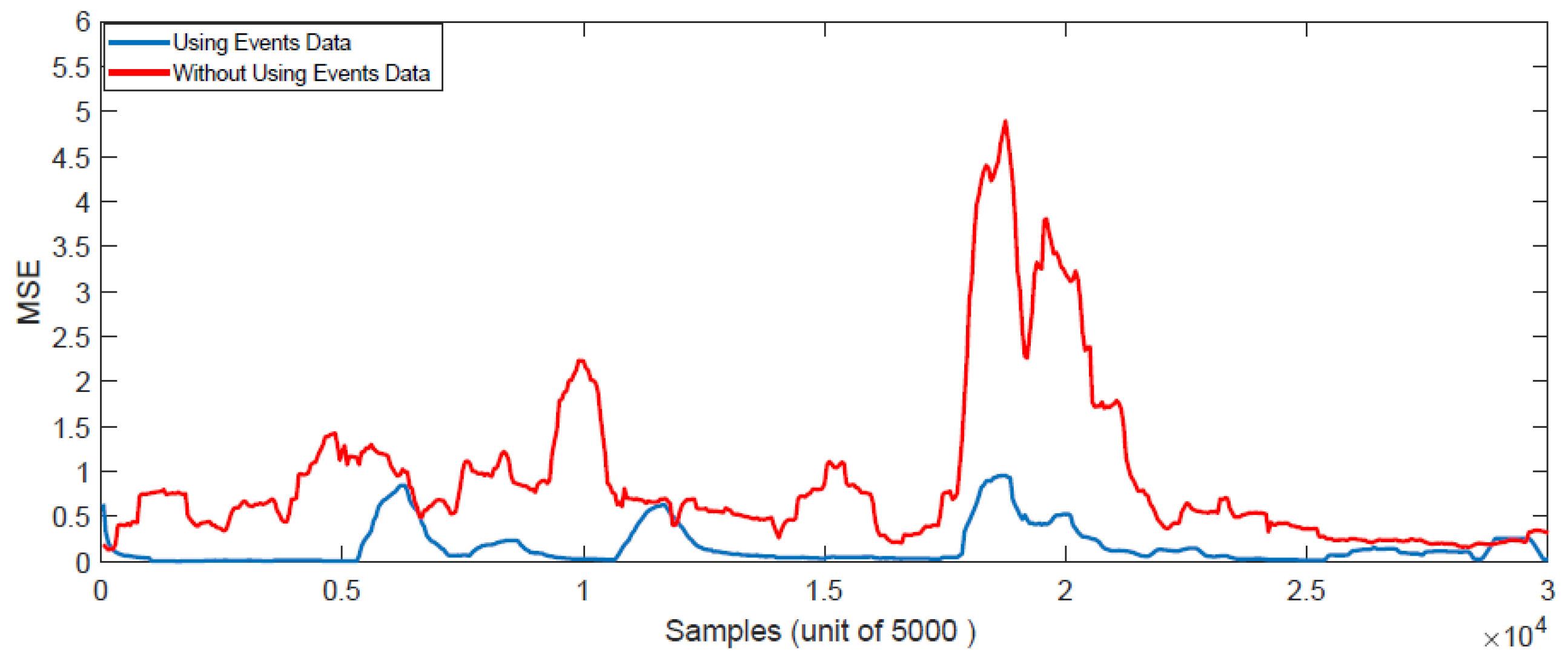
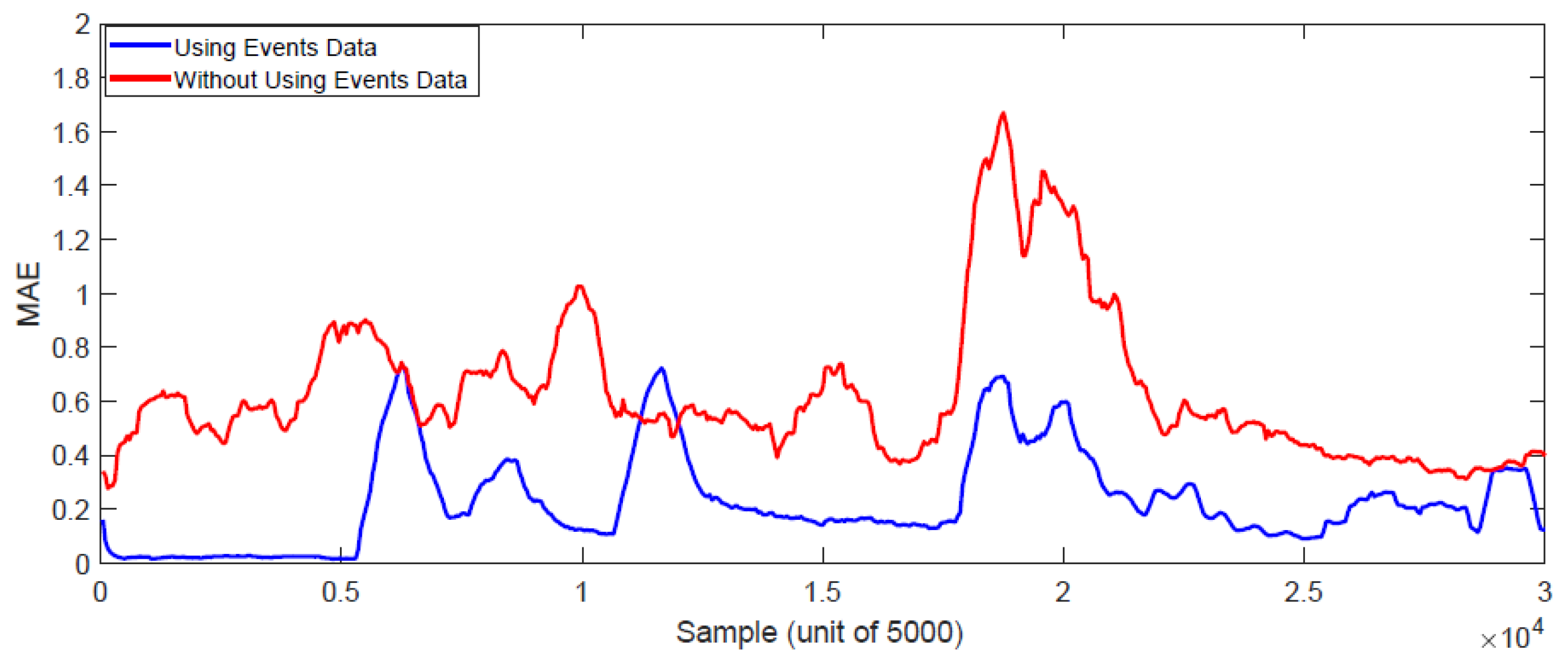
5.4. Results of Online Learning Methods
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mitrovic, N.; Asif, M.T.; Dauwels, J.; Jaillet, P. Low-dimensional models for compressed sensing and prediction of large-scale traffic data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2949–2954. [Google Scholar] [CrossRef]
- Cai, J.; Wang, Y.; Liu, Y.; Luo, J.Z.; Wei, W.; Xu, X. Enhancing network capacity by weakening community structure in scale-free network. Future Gener. Comput. Syst. 2017, 87, 765–771. [Google Scholar] [CrossRef]
- Peng, S.; Wang, G.; Xie, D. Social influence analysis in social networking Big Data: Opportunities and challenges. IEEE Netw. 2017, 31, 11–17. [Google Scholar] [CrossRef]
- Peng, S.; Yang, A.; Cao, L.; Yu, S.; Xie, D. Social influence modeling using information theory in mobile social networks. Inf. Sci. 2017, 379, 146–159. [Google Scholar] [CrossRef]
- Chen, S.; Wang, G.; Yan, G.; Xie, D. Multi-dimensional fuzzy trust evaluation for mobile social networks based on dynamic community structures. Concurr. Comput.-Pract. Exp. 2017, 29, e3901. [Google Scholar] [CrossRef]
- Zheng, J.; Bhuiyan, M.Z.A.; Liang, S.; Xing, X.; Wang, G. Auction-based adaptive sensor activation algorithm for target tracking in wireless sensor networks. Future Gener. Comput. Syst. 2014, 39, 88–99. [Google Scholar] [CrossRef]
- Xing, X.; Guojun, W.; Jie, L. Collaborative Target Tracking in Wireless Sensor Networks. Ad Hoc Sens. Wirel. Netw. 2014, 23, 117–135. [Google Scholar]
- Liu, Q.; Wang, G.; Liu, X.; Peng, T.; Wu, J. Achieving reliable and secure services in cloud computing environments. Comput. Electr. Eng. 2017, 59, 153–164. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Shirazi, M.S.; Morris, B.T. Looking at intersections: A survey of intersection monitoring, behavior and safety analysis of recent studies. IEEE Trans. Intell. Transp. Syst. 2017, 18, 4–24. [Google Scholar] [CrossRef]
- National Highway Traffic Safety Administration. Crash Factors in Intersection-Related Crashes: An On-Scene Perspective. 2018. Available online: http://www-nrd.nhtsa.dot.gov/Pubs/811366.pdf (accessed on 15 January 2018).
- Anantharam, P.; Thirunarayan, K.; Marupudi, S.; Sheth, A.P.; Banerjee, T. Understanding city traffic dynamics utilizing sensor and textual observations. In Proceedings of the 30th Conference on Artificial Intelligence (AAAI-2016), Phoenix, AZ, USA, 12–17 February 2016; pp. 3793–3799. [Google Scholar]
- Polson, N.G.; Sokolov, V.O. Deep learning for short-term traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2017, 79, 1–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part C Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs. Neurons: Comparison between random forest and ANN for high-resolution prediction of building energy consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Wibisono, A.; Jatmiko, W.; Wisesa, H.A.; Hardjono, B.; Mursanto, P. Traffic big data prediction and visualization using fast incremental model trees-drift detection (FIMT-DD). Knowl.-Based Syst. 2016, 93, 33–46. [Google Scholar] [CrossRef]
- Hamed, M.M.; Al-Masaeid, H.R.; Said, Z.M.B. Short-term prediction of traffic volume in urban arterials. J. Transp. Eng. 1995, 121, 249–254. [Google Scholar] [CrossRef]
- Lee, S.; Fambro, D. Application of subset autoregressive integrated moving average model for short-term freeway traffic volume forecasting. Transp. Res. Rec. 1999, 1678, 179–188. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Min, X.; Hu, J.; Zhang, Z. Urban traffic network modeling and short-term traffic flow forecasting based on GSTARIMA model. In Proceedings of the 13th International IEEE Annual Conference on Intelligent Transportation Systems, Madelra Island, Portugal, 19–22 September 2010; pp. 1535–1540. [Google Scholar]
- Asif, M.T.; Dauwels, J.; Goh, C.Y.; Oran, A.; Fathi, E.; Xu, M.; Dhanya, M.M.; Mitrovic, N.; Jaillet, P. Spatiotemporal patterns in large-scale traffic speed prediction. IEEE Trans. Intell. Transp. Syst. 2014, 15, 794–804. [Google Scholar] [CrossRef]
- Kim, Y.J.; Hong, J.S.; Oh, S. Urban traffic flow prediction system using a multifactor pattern recognition model. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2744–2755. [Google Scholar]
- Zhan, H.; Gomes, G.; Li, X.S.; Madduri, K.; Sim, A.; Wu, K. Consensus Ensemble System for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2018, 1–12. [Google Scholar] [CrossRef]
- Clark, S. Traffic prediction using multivariate nonparametric regression. J. Transp. Eng. 2003, 129, 161–168. [Google Scholar] [CrossRef]
- Zhao, J.; Sun, S. High-order Gaussian process dynamical models for traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2014–2019. [Google Scholar] [CrossRef]
- Dell’Acqua, P.; Bellotti, F.; Berta, R.; De Gloria, A. Time-aware multivariate nearest neighbor regression methods for traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3393–3402. [Google Scholar] [CrossRef]
- Chen, D. Research on traffic flow prediction in the big data environment based on the improved RBF neural network. IEEE Trans. Ind. Inf. 2017, 13, 2000–2008. [Google Scholar] [CrossRef]
- Xu, Y.; Kong, Q.J.; Klette, R.; Liu, Y. Accurate and interpretable Bayesian MARS for traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2457–2469. [Google Scholar] [CrossRef]
- Lei, Y.; Qiu, G.; Zheng, L.; Huang, J. Fast Near-Duplicate Image Detection Using Uniform Randomized Trees. ACM Trans. Multimed. Comput. Commun. Appl. 2014, 10. [Google Scholar] [CrossRef]
- Chen, Z.; Peng, L.; Gao, C.; Yang, B.; Chen, Y.; Li, J. Flexible neural trees based early stage identification for IP traffic. Soft Comput. 2017, 21, 2035–2046. [Google Scholar] [CrossRef]
- Alajali, W.; Zhou, W.; Wen, S. Traffic Flow Prediction for Road Intersections Safety. In Proceedings of the 2nd IEEE International Conference on Smart City Innovations (IEEE SCI 2018), Guangzhou, China, 8–12 October 2018. [Google Scholar]
- Castro-Neto, M.; Jeong, Y.S.; Jeong, M.K.; Han, L.D. Online-SVR for short-term traffic flow prediction under typical and atypical traffic conditions. Expert Syst. Appl. 2009, 36, 6164–6173. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Byon, Y.J.; Castro-Neto, M.M.; Easa, S.M. Supervised weighting-online learning algorithm for short-term traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1700–1707. [Google Scholar] [CrossRef]
- Li, J.; Sun, L.; Yan, Q.; Li, Z.; Srisa-an, W.; Ye, H. Significant permission identification for machine learning based android malware detection. IEEE Trans. Ind. Inf. 2018, 14, 3216–3225. [Google Scholar] [CrossRef]
- Meng, W.; Jiang, L.; Wang, Y.; Li, J.; Zhang, J.; Xiang, Y. JFCGuard: Detecting juice filming charging attack via processor usage analysis on smartphones. Comput. Secur. 2017, 76, 252–264. [Google Scholar] [CrossRef]
- Wu, T.; Wen, S.; Xiang, Y.; Zhou, W. Twitter spam detection: Survey of new approaches and comparative Study. Comput. Secur. 2018, 76, 265–284. [Google Scholar] [CrossRef]
- Liu, Y.; Ling, J.; Liu, Z.; Shen, J.; Gao, C. Finger vein secure biometric template generation based on deep learning. Soft Comput. 2018, 22, 2257–2265. [Google Scholar] [CrossRef]
- Yuan, C.; Li, X.; Wu, Q.; Li, J.; Sun, X. Fingerprint liveness detection from different fingerprint materials using convolutional neural network and principal component analysis. CMC-Comput. Mater. Contin. 2017, 53, 357–371. [Google Scholar]
- Meng, W.; Wang, Y.; Wong, D.S.; Wen, S.; Xiang, Y. TouchWB: Touch behavioral user authentication based on web browsing on smartphones. J. Netw. Comput. Appl. 2018, 117, 1–9. [Google Scholar] [CrossRef]
- Jiang, J.; Wen, S.; Yu, S.; Xiang, Y.; Zhou, W. Identifying propagation sources in networks: State-of-the-art and comparative studies. IEEE Commun. Surv. Tutor. 2017, 19, 465–481. [Google Scholar] [CrossRef]
- Wen, S.; Haghighi, M.S.; Chen, C.; Xiang, Y.; Zhou, W.; Jia, W. A sword with two edges: Propagation studies on both positive and negative information in online social networks. IEEE Trans. Comput. 2015, 64, 640–653. [Google Scholar] [CrossRef]
- Wang, Y.; Wen, S.; Xiang, Y.; Zhou, W. Modeling the propagation of worms in networks: A survey. IEEE Commun. Surv. Tutor. 2014, 16, 942–960. [Google Scholar] [CrossRef]
- Li, P.; Li, J.; Huang, Z.; Gao, C.Z.; Chen, W.B.; Chen, K. Privacy-preserving outsourced classification in cloud computing. Clust. Comput. 2017. [Google Scholar] [CrossRef]
- Li, P.; Li, J.; Huang, Z.; Li, T.; Gao, C.Z.; Yiu, S.M.; Chen, K. Multi-key privacy-preserving deep learning in cloud computing. Future Gener. Comput. Syst. 2017, 74, 76–85. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Chen, X.; Xiang, Y. Secure attribute-based data sharing for resource-limited users in cloud computing. Comput. Secur. 2018, 72, 1–12. [Google Scholar] [CrossRef]
- Gao, C.Z.; Cheng, Q.; Li, X.; Xia, S.B. Cloud-assisted privacy-preserving profile-matching scheme under multiple keys in mobile social network. Clust. Comput. 2018. [Google Scholar] [CrossRef]
- Luo, E.; Liu, Q.; Abawajy, J.H.; Wang, G. Privacy-preserving multi-hop profile-matching protocol for proximity mobile social networks. Future Gener. Comput. Syst. 2017, 68, 222–233. [Google Scholar] [CrossRef]
- Gao, C.; Cheng, Q.; He, P.; Susilo, W.; Li, J. Privacy-preserving Naive Bayes classifiers secure against the substitution-then-comparison attack. Inf. Sci. 2018, 444, 72–88. [Google Scholar] [CrossRef]
- VicTraffic. Available online: https://traffic.vicroads.vic.gov.au/ (accessed on 15 January 2018).
- Victorian Government Data Directory. Available online: https://www.data.vic.gov.au/ (accessed on 15 January 2018).
- Scikit-learn. Available online: http://scikit-learn.org/stable/ (accessed on 15 January 2018).
- XGBoost. Available online: https://github.com/dmlc/xgboost (accessed on 15 January 2018).
- Moa: Massive Online Analysis. Available online: https://moa.cms.waikato.ac.nz/ (accessed on 15 January 2018).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Duration | # of Records | Type | # of Sensors | Time Interval |
|---|---|---|---|---|---|
| Traffic Volume | 1 January 2014–31 December 2014 | 28,992 per intersection | Public | 4598 | 15 min |
| Car Accidents | 1 January 2014–31 December 2014 | 14,247 | Public | - | - |
| Roadworks | 1 January 2014–31 December 2014 | 5637 | Public | - | - |
| Prediction Model | Time | Day | Weekend | Peak | Day Night | Event Distance |
|---|---|---|---|---|---|---|
| GBRT | 0.3836 | 0.244 | 0.4030 | 0.0107 | 0.0903 | 0.2409 |
| RF | 0.1510 | 0.0263 | 0.0422 | 0.0001 | 0.6172 | 0.1633 |
| XGBoost | 0.4692 | 0.2678 | 0.001 | 0.0217 | 0.0176 | 0.2237 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alajali, W.; Zhou, W.; Wen, S.; Wang, Y. Intersection Traffic Prediction Using Decision Tree Models. Symmetry 2018, 10, 386. https://doi.org/10.3390/sym10090386
Alajali W, Zhou W, Wen S, Wang Y. Intersection Traffic Prediction Using Decision Tree Models. Symmetry. 2018; 10(9):386. https://doi.org/10.3390/sym10090386
Chicago/Turabian StyleAlajali, Walaa, Wei Zhou, Sheng Wen, and Yu Wang. 2018. "Intersection Traffic Prediction Using Decision Tree Models" Symmetry 10, no. 9: 386. https://doi.org/10.3390/sym10090386
APA StyleAlajali, W., Zhou, W., Wen, S., & Wang, Y. (2018). Intersection Traffic Prediction Using Decision Tree Models. Symmetry, 10(9), 386. https://doi.org/10.3390/sym10090386