In this section, we first propose the definition of a new score function of HFLTSs based on a linguistic scale function, then the new similarity measure and its properties are given. Furthermore, we construct a corresponding distance measure based on the relationship between the similarity measure and the distance measure.
3.2. The Similarity Measure Between HFLTSs Based on the Linguistic Scale Function
It is already known the regular similarity measure satisfies the following Lemma 2:
Lemma 2. Letbe a LTS,andbe any two HFLTSs; if the similarity measuresatisfies the following properties [9]: - (1)
,
- (2)
if and only if,
- (3)
.
then the similarity measureis a regular similarity measure, and the corresponding distance measure.
The cosine similarity measure proposed by Liao et al. [
31] is sometimes different from human intuition in practical decision-making problems, and we can determine this from the following Example 4.
Example 4. When two experts evaluate the performance of a company, they provide their opinions with hesitant fuzzy linguistic information; for the given LTS,, and two experts’ evaluations are represented as HFLTSsand, respectively.
It is already known
, but from using Formula (3) to calculate the similarity measure between
and
, we have
. That is to say, the property (2) in Lemma 2 is not satisfied. So, the similarity measure
proposed by Liao et al. [
31] is not a regular similarity measure. On the other hand, the similarity measure
as defined by Liao et al. [
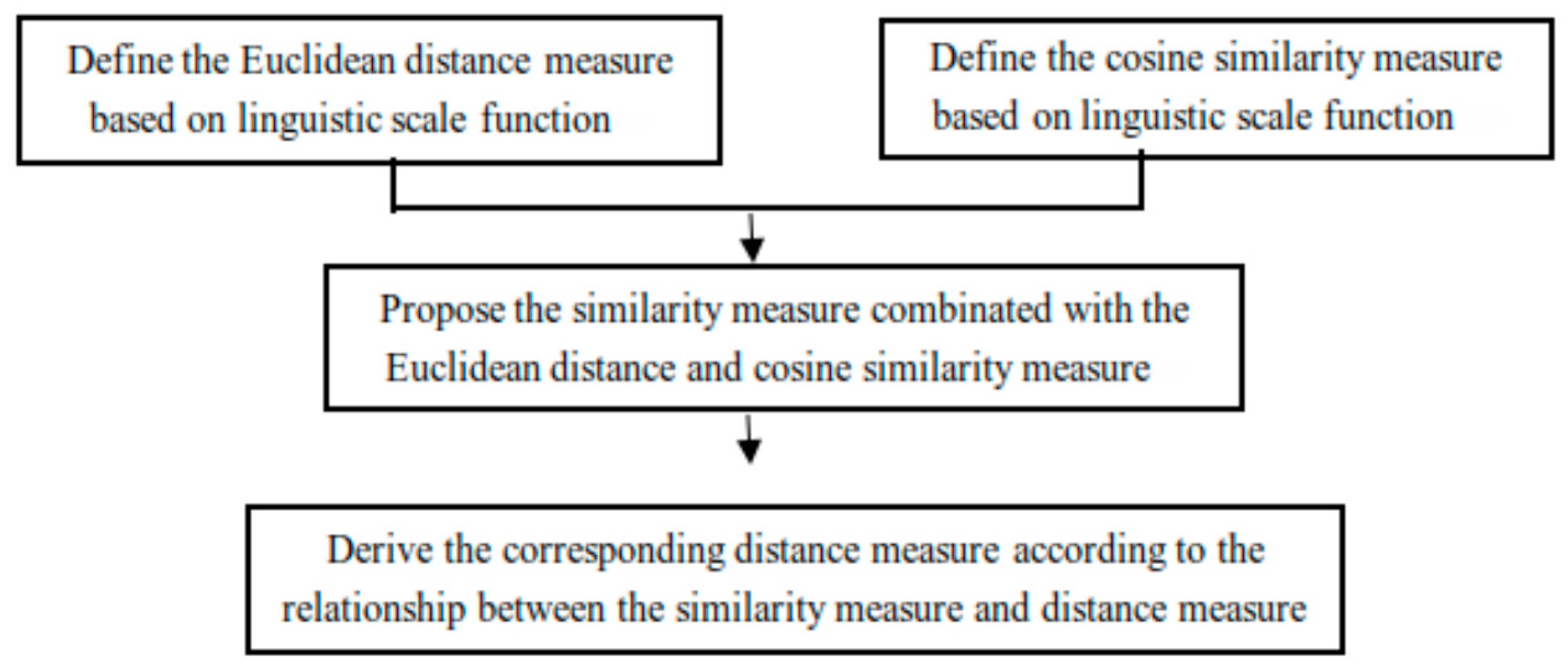
31] used the subscript of linguistic terms directly in the process of operations; they did not consider the semantic environment, which may cause the loss of information in the decision process. In order to overcome its disadvantages, next we will construct a new similarity measure and derive a corresponding distance measure. A scheme of this process is shown in
Figure 2.
At first, we improve the existing distance measure (1) and similarity measure (2) based on a linguistic scale function, which can be defined as follows:
Definition 8. Given a fixed set, letbe a LTS, and letbe a linguistic scale function,, where,represents the number of elements in. For any two HFLTSsand, if the weight of the different elementis, then the improved weighted distance measure between HFLTSsandcan be defined as follows: Theorem 2. Letandbe any two HFLTSs, and letbe a linguistic scale function; the distance measurebetween HFLTSs satisfies the following properties:
- (1)
;
- (2)
if and only if;
- (3)
.
Proof. Properties (1), (2), and (3) are obvious, and we omit the proof here. ☐
Remark 4. For all, if the weight, then the improved weighted distance measureis reduced to the improved Euclidean distance measure:
Definition 9. Given a fixed set, letbe a LTS, and letbe a linguistic scale function,, where,represents the number of elements in. For any two HFLTSsand, if the weight of different elementis, then the improved weighted cosine similarity measure betweenandcan be defined as: Remark 5. For all, if the weight, then the improved weighted cosine similarity measureis reduced to the similarity measure:
In the following, we go on to propose a similarity measure between the HFLTSs, which combine the distance measure and the cosine similarity measure .
Definition 10. Given a fixed set, letbe a LTS, and letbe a linguistic scale function,, where,,represents the number of elements in. For any two HFLTSsand, then the new similarity measurecan be defined as follows:where,
.
Theorem 3. The similarity measureis a regular similarity measure.
Proof. According to Lemma 2, we will prove it by three steps as follows:
- (1)
Since can be considered as the extension of cosine function, then . According to Theorem 2, we know that is a distance measure, then . Thus, we get , so is obvious.
- (2)
If , we have , , , then . On the other hand, when , we have ; that is, . Because , hold simultaneously, then we have , . When , we know that and is a constant; while , we know that . That is to say, when , .
Thus, if and only if .
- (3)
According to Remark 5, is obvious. From Theorem 2, it is already known that when , then are proven. ☐
From Theorem 3, we know that the proposed similarity measure
is a regular similarity measure, which overcomes the disadvantages of the similarity measure as defined by Liao et al. [
31].
Remark 6. According to the relation between the distance measure and the regular similarity measure, we can obtain a new distance measure, which is based on the proposed similarity measure: Theorem 4. The new distance measuresatisfies the following properties:
- (1)
;
- (2)
if and only if;
- (3)
.
Proof. Properties (1) and (3) are obvious, here we only present the proof of property (2).
If , we have , then . On the other hand, when , we have . Because is a regular similarity measure, according to Lemma 2, we have .
Thus, we obtain if and only if . ☐
Definition 11. Given a fixed set, letbe a LTS, and letbe a linguistic scale function., where,,represents the number of elements in. For any two HFLTSsand, the associated weighting vectorsatisfying with, then the weighted similarity measure betweenandcan be defined as: Theorem 5. The weighted similarity measureis also a regular similarity measure.
Proof. The proof is similar to Theorem 3; we omit it here. ☐
Remark 7. If the weight of the different elementis, satisfying, then the weighted distance measure betweenandcan be obtained by: Remark 8. If we take the weightinand, thenandare reduced toand, respectively.
Next, we utilize the medical diagnosis example to illustrate the application of the proposed similarity measure.
Example 5. In traditional Chinese medical diagnosis, doctors diagnose patients by watching, smelling, asking and touching, so the doctor always get some imprecise information about patients’ symptoms. Let us consider a set of diagnosesand a set of symptoms}. Assume that a patient, with respect to all symptoms, can be depicted as the following LTS, respectively:low,. Furthermore, letbe the weight vector of symptoms.
Suppose that the patient
has all of the symptoms, which are represented by a HFLTS and are given in
Table 1.
According to experience, each patient’s symptoms diagnosis can be viewed as a HFLTS, and these are shown in
Table 2.
In order to diagnose what kind of symptoms that the patients belong to, we can calculate the similarity measure between each patient’s symptoms and the diagnosis. If the linguistic scale function
, we apply the proposed similarity measure
to calculate the degree of similarity between each patient’s symptoms and the diagnosis; the results are shown in
Table 3.
It is already known that the larger value of similarity measure, the higher the possibility of diagnosis for the patient. From the above results of
Table 3, the symptoms of Richard, Catherine, Nicole, and Kevin indicate that they are suffering from typhoid, stomach problems, viral fever, and pneumonia, respectively.





{kind=link}
{kind=link}
{kind=link}