A Multi-Level Privacy-Preserving Approach to Hierarchical Data Based on Fuzzy Set Theory


Abstract
1. Introduction
- We utilize the fuzzy set theory to obtain the sensitivity levels for sensitive numerical and categorical attribute values, and present the privacy model (, k)-anonymity for hierarchical data with multi-level sensitivity. This model can solve the similarity attack, and provide reasonable privacy protection for sensitive value in different sensitivity level.
- We improve the privacy-preserving approach in hierarchical data to obtain the anonymous data that satisfies (, k)-anonymity.
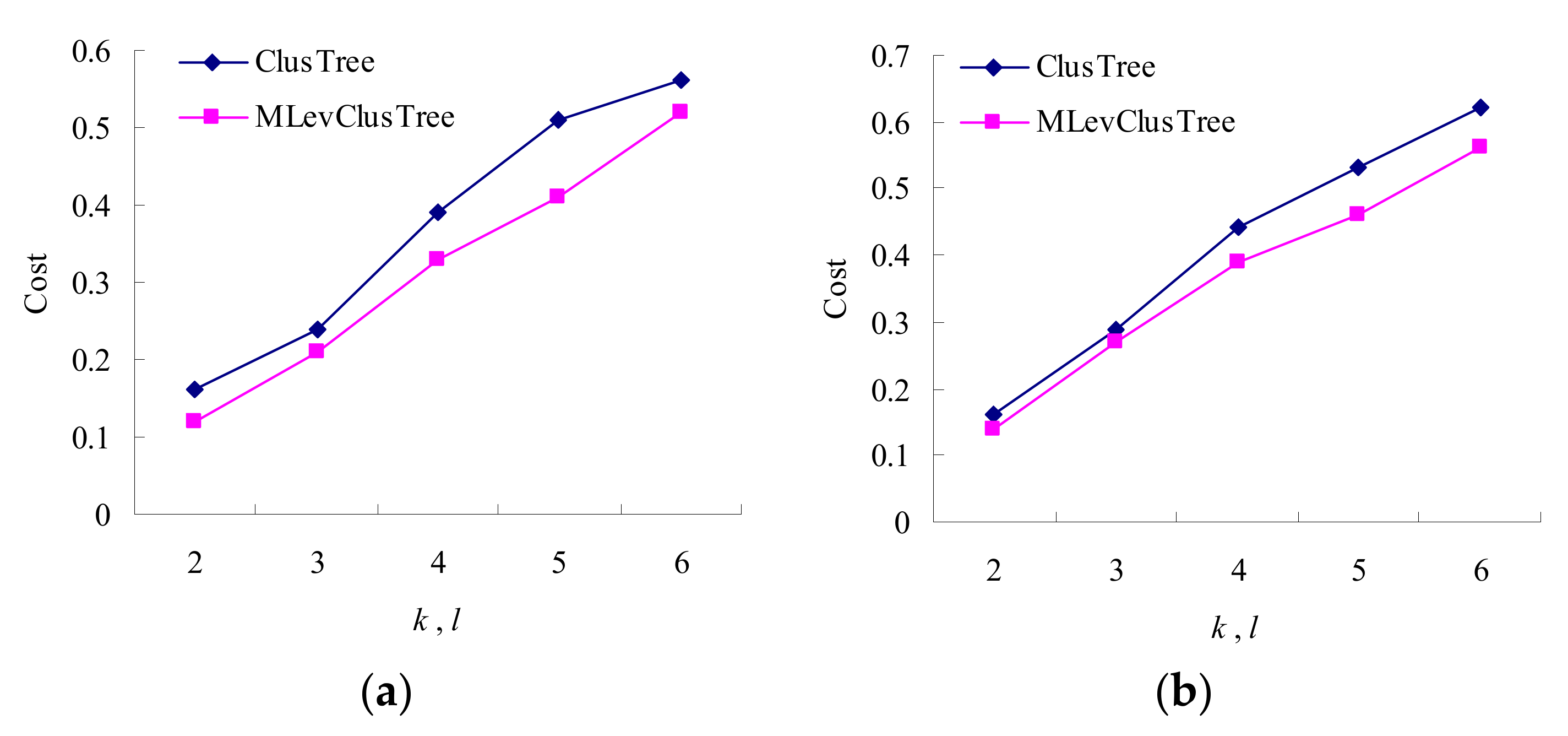
- We do experiments to compare our approach with the existing anonymous method ClusTree proposed in [16]. Experiment results demonstrate that our approach is superior to ClusTree in terms of utility and security.
2. Related Work
2.1. Preserving Privacy for Publishing Relational Data
2.2. Preserving Privacy for Publishing Hierarchical Data
3. Problem Descriptions
3.1. Attack Model
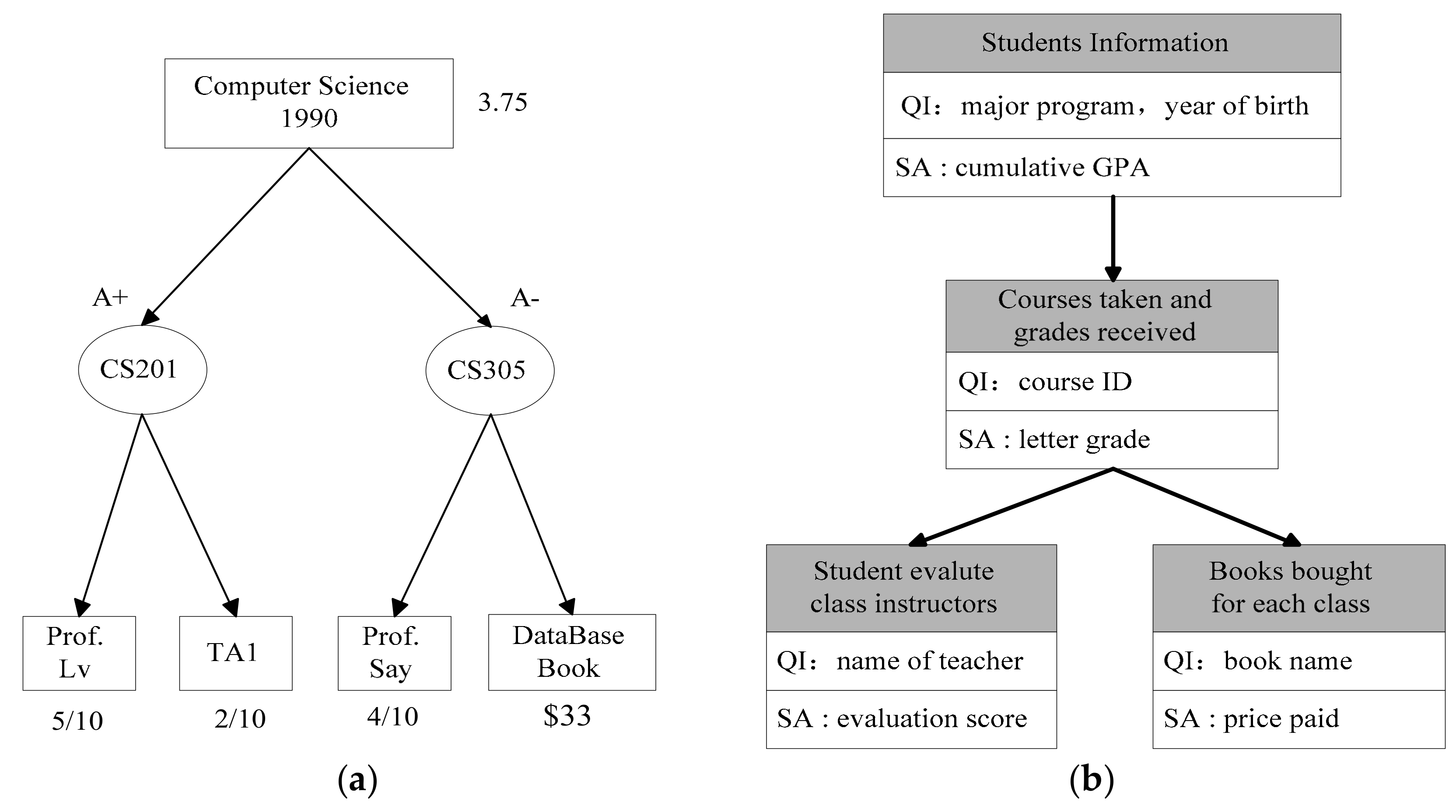
3.2. Basic Definitions in Hierarchical Data
- (1)
- For x, y ∈ V1, there exists an edge ei ∈ E2 from f(x) to f(y) if and only if there exists an edge ej ∈ E1 from x to y.
- (2)
- f(r1) = r2, where r1 ∈ V1 and r2 ∈ V2 be the roots of T1(V1, E1) and T2(V2, E2), respectively.
- (3)
- For all pairs (x, x′), where x ∈ V1 and x′ = f(x), x and x′ are union-compatible and xQI = x′QI.
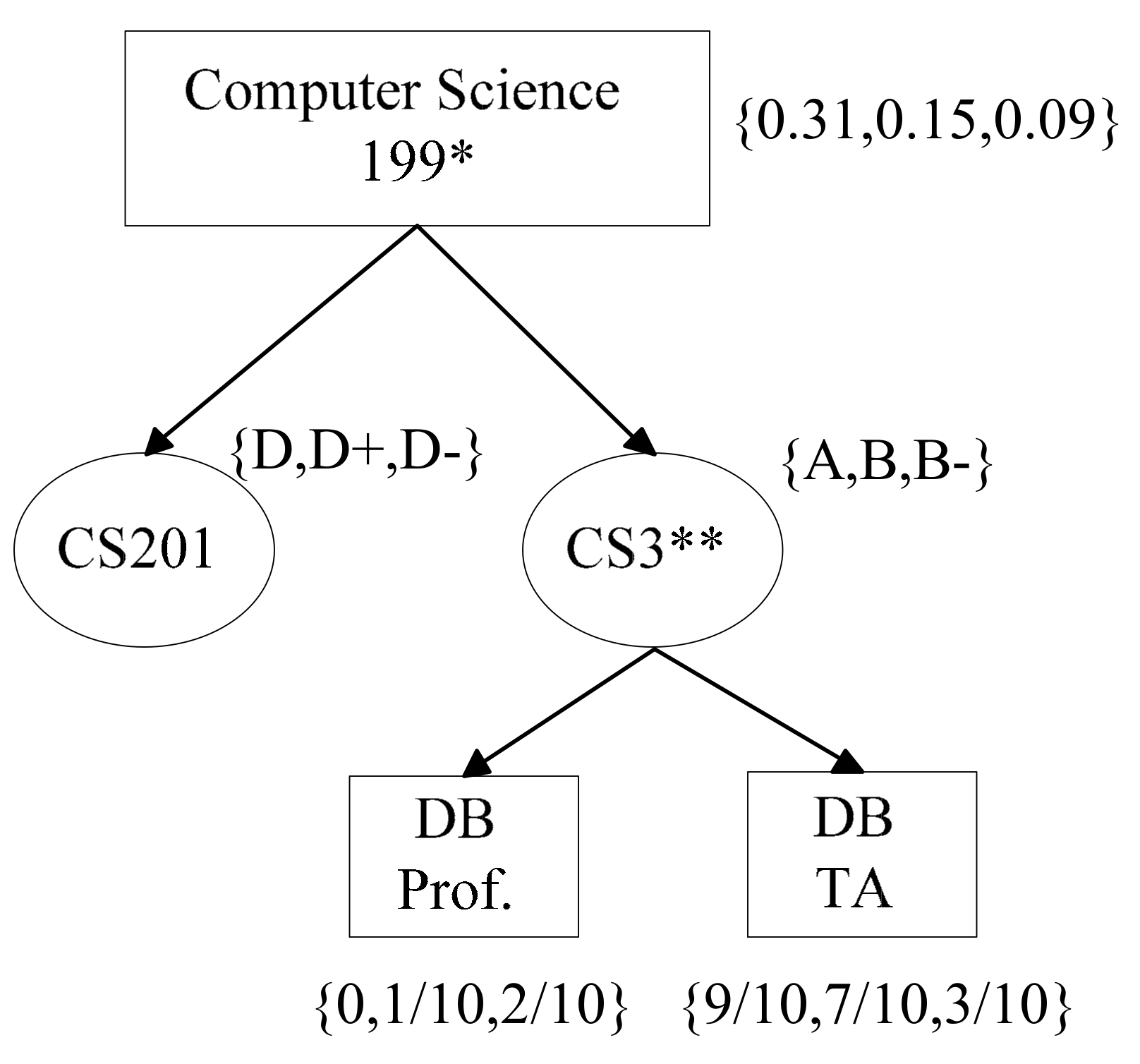
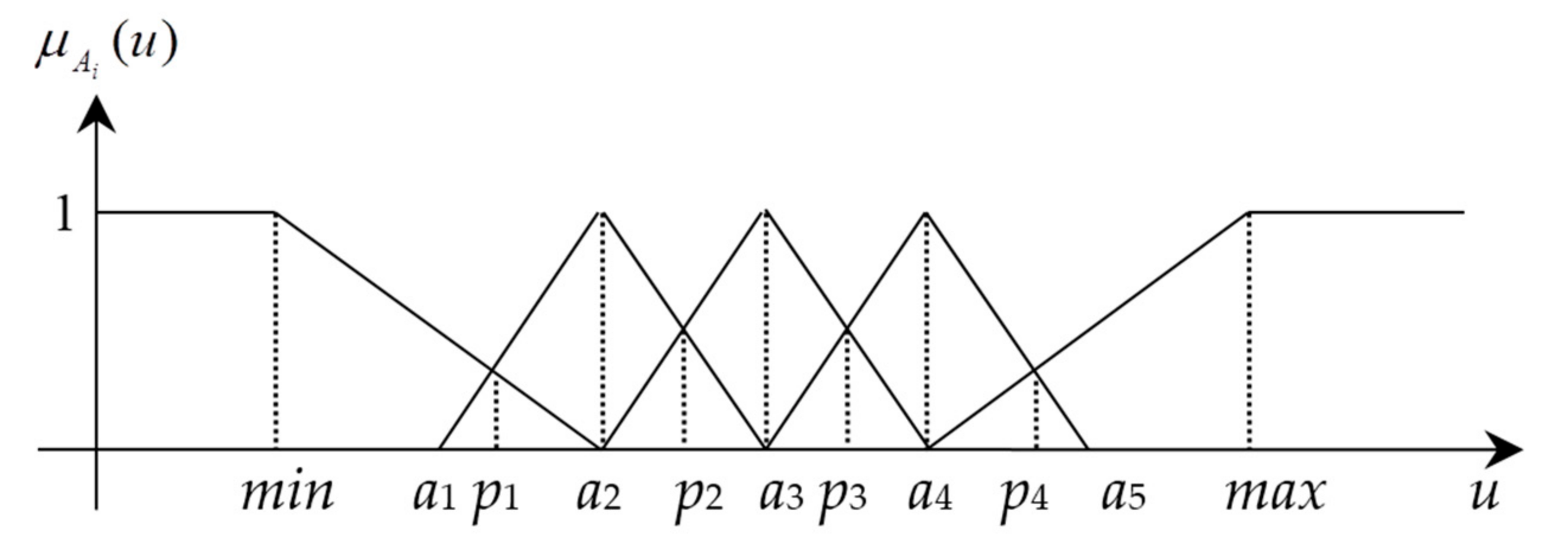
3.3. Privacy Model
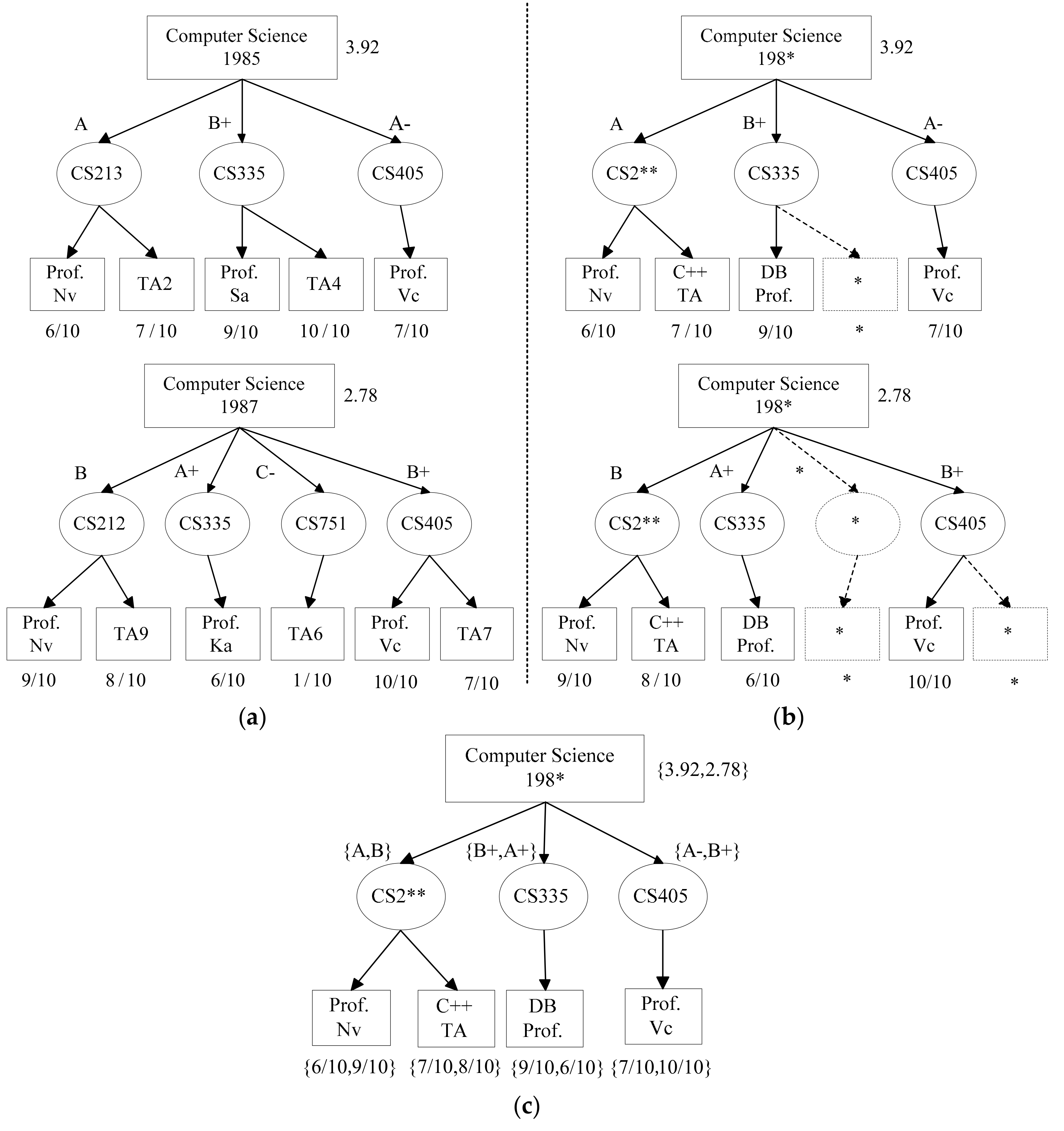
4. The Anonymization Method
| Algorithm 1. MLevAnonytree(T1, T2) |
| Input: Two hierarchical data records T1 and T2 Output: Anonymous information loss 1 a ← root(T1); b ← root(T2); 2 if check_condition(a, b) then 3 suppress tree(a) and tree(b); 4 return cost(tree(a)) + cost(tree(b)); 5 for i = 1 to |aQI| do 6 replace aQI[i] and bQI[i] with their generalized value; 7 if subtrees(a) = ∅ and subtrees(b) = ∅ then 8 return cost(tree(a)) + cost(tree(b)); 9 if subtrees(a) = ∅ and subtrees(b) ≠ ∅ then 10 suppress all vertices under b; 11 return cost(tree(a)) + cost(tree(b)); 12 pairs ← ∅; 13 for i = 1 to m do 14 min_cost ← ∞; 15 paired_index ← ∅; 16 for j = 1 to n do 17 if j ∈ pairs then 18 continue; 19 x ← Ui; y ← Vj; 20 loss ← MLevAnonytree(x, y); 21 if loss < min_cost then 22 min_cost ← loss; paired_index ← j; 23 pairs.append(i, paired_index); 24 for (i, j) ∈ pairs do 25 MLevAnonytree (Ui, Vj); 26 if there are unpaired subtrees in b then suppress them; 27 return cost(tree(a)) + cost(tree(b)); |
| Algorithm 2. MLevCluTree(H, , k) |
| Input: A hierarchical data H = {T1, T2, ..., Tn}, and privacy parameters , k; Output: anonymous dataset H′ which satisfies (, k)-anonymity 1 H′ ← ∅; 2 while H ≥ k do 3 pick randomly a record x from H; H ← H-x; 4 initialize Q with x and Crep ← x; 5 Q_cost ← ∅; 6 for i = 1 to |H| do 7 loss ← MLevAnonytree(copy(x), copy(Ti)); 8 Q_cost.append(loss); 9 use Q_cost to sort H in ascending order; 10 cand_set ← H[1:50]; 11 for j = 2 to k do 12 y′ ← argminy ∈ cand_set(MLevAnonytree(copy(Crep), copy(y))); 13 H ← H- y′; cand_set ← cand_set- y′; Q ← Q ∪ y′; 14 update Crep; 15 H′←H′∪Q; 16 if H ≠ ∅ then 17 suppress all records in H; 18 return H′; |
5. Experimental Results
5.1. Evaluation Metrics
5.2. Experimental Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zavadskas, E.K.; Mardani, A.; Turskis, Z.; Jusoh, A.; Nor, K. Development of TOPSIS method to solve complicated decision-making problems—An overview on developments from 2000 to 2015. Int. J. Inf. Technol. Decis. Mak. 2016, 15, 645–682. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Turskis, Z.; Kildienė, S. State of art surveys of overviews on MCDM/MADM methods. Technol. Econ. Dev. Econ. 2014, 20, 165–179. [Google Scholar] [CrossRef]
- Li, Z.; Sun, D.; Zeng, H. Intuitionistic Fuzzy Multiple Attribute Decision-Making Model Based on Weighted Induced Distance Measure and Its Application to Investment Selection. Symmetry 2018, 10, 261. [Google Scholar] [CrossRef]
- Li, D.; He, J.; Cheng, P.; Wang, J.; Zhang, H. A Novel Selection Model of Surgical Treatments for Early Gastric Cancer Patients Based on Heterogeneous Multicriteria Group Decision-Making. Symmetry 2018, 10, 223. [Google Scholar] [CrossRef]
- Ma, X.; Zhan, J.; Ali, M.I.; Mehmood, N. A survey of decision making methods based on two classes of hybrid soft set models. Artif. Intell. Rev. 2018, 49, 511–529. [Google Scholar] [CrossRef]
- Zhan, J.; Xu, W. Two types of coverings based multigranulation rough fuzzy sets and applications to decision making. Artif. Intell. Rev. 2018. [Google Scholar] [CrossRef]
- Zhan, J.; Liu, Q.; Herawan, T. A novel soft rough set: Soft rough hemirings and its multicriteria group decision making. Appl. Soft Comput. 2017, 54, 393–402. [Google Scholar] [CrossRef]
- Hu, C.K.; Liu, F.B.; Hu, C.F. A Hybrid Fuzzy DEA/AHP Methodology for Ranking Units in a Fuzzy Environment. Symmetry 2017, 9, 273. [Google Scholar] [CrossRef]
- Kang, J.; Han, J.; Park, J.H. Design of IP Camera Access Control Protocol by Utilizing Hierarchical Group Key. Symmetry 2015, 7, 1567–1586. [Google Scholar] [CrossRef]
- Lee, G. Hierarchical Clustering Using One-Class Support Vector Machines. Symmetry 2015, 7, 1164–1175. [Google Scholar] [CrossRef]
- Samarati, P.; Sweeney, L. Generalizing data to provide anonymity when disclosing information. In Proceedings of the ACM Symposium on Principles of Database Systems, Seattle, WA, USA, 1–3 June 1998; p. 188. [Google Scholar]
- Fung, B.C.M.; Wang, K.; Chen, R.; Yu, P.S. Privacy-preserving data publishing: A survey of recent development. ACM Comput. Surv. 2010, 42, 14. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Wong, C.R.; Li, J.; Fu, A.; Wang, K. (α, k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 754–759. [Google Scholar]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- Ozalp, I.; Gursoy, M.E.; Nergiz, M.E.; Saygin, Y. Privacy-preserving publishing of hierarchical data. ACM Trans. Priv. Secur. 2016, 19, 7. [Google Scholar] [CrossRef]
- Lefevre, K.; Dewitt, D.J.; Ramakrishnan, R. Incognito: Efficient full-domain k-anonymity. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 49–60. [Google Scholar]
- Fung, B.C.M.; Wang, K.; Yu, P.S. Top-down specialization for information and privacy preservation. In Proceedings of the 21st International Conference on Data Engineering, Tokoyo, Japan, 5–8 April 2005; pp. 205–216. [Google Scholar]
- Aggarwal, G.; Feder, T.; Kenthapadi, K.; Khuller, S.; Panigrahy, R.; Thomas, D.; Zhu, A. Achieving anonymity via clustering. ACM Trans. Algorithms 2010, 6, 49. [Google Scholar] [CrossRef]
- Ghinita, G.; Karras, P.; Kalnis, P.; Mamoulis, N. A framework for efficient data anonymization under privacy and accuracy constraints. ACM Trans. Database Syst. 2009, 32, 9. [Google Scholar] [CrossRef]
- Wang, J.; Du, K.; Luo, X.; Li, X. Two privacy-preserving approaches for data publishing with identity reservation. Knowl. Inf. Syst. 2018. [Google Scholar] [CrossRef]
- Han, J.; Yu, J.; Yu, H.; Jia, J. A multi-level l-diversity model for numerical sensitive attributes. J. Comput. Res. Dev. 2011, 48, 147–158. [Google Scholar]
- Jin, H.; Zhang, Z.; Liu, S.; Ju, S. (αi, k)-anonymity Privacy Preservation Based on Sensitivity Grading. Comput. Eng. 2011, 37, 12–17. [Google Scholar]
- Wang, Q.; Yang, C.; Liu, H. Fuzzy based methods for privacy preserving. Appl. Res. Comput. 2013, 30, 518–520. [Google Scholar]
- Kumari, V.V.; Rao, S.S.; Raju, K.; Ramana, K.V.; Avadhani, B.V.S. Fuzzy based approach for privacy preserving publication of data. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 115–121. [Google Scholar]
- Yang, X.; Li, C. Secure XML publishing without information leakage in the presence of data inference. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 96–107. [Google Scholar]
- Landberg, A.H.; Nguyen, K.; Pardede, E.; Rahayu, J.W. δ-dependency for privacy-preserving XML data publishing. J. Biomed. Inform. 2014, 50, 77–94. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Nergiz, M.E.; Clifton, C.; Nergiz, A.E. Multirelational k-anonymity. IEEE Trans. Knowl. Data Eng. 2009, 21, 1104–1117. [Google Scholar] [CrossRef]
- Gkountouna, O.; Terrovitis, M. Anonymizing collections of tree-structured data. IEEE Trans. Knowl. Data Eng. 2015, 27, 2034–2048. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Jorba, L.; Adillon, R. Interval Fuzzy Segments. Symmetry 2018, 10, 309. [Google Scholar] [CrossRef]
- Bi, L.; Dai, S.; Hu, B. Complex Fuzzy Geometric Aggregation Operators. Symmetry 2018, 10, 251. [Google Scholar] [CrossRef]
- Klir, G.J.; Clair, U.S.; Yuan, B. Fuzzy Set Theory: Foundations and Applications; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1997. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GPA | 0.8 | 1.6 | 2.3 | 2.7 | 3.5 | 3.9 | |
|---|---|---|---|---|---|---|---|
| Value Level | |||||||
| Low | 0.40 | 0 | 0 | 0 | 0 | 0 | |
| Very low | 0.20 | 0.60 | 0 | 0 | 0 | 0 | |
| Middle | 0 | 0.40 | 0.55 | 0 | 0 | 0 | |
| Very high | 0 | 0 | 0.45 | 0.95 | 0 | 0 | |
| High | 0 | 0 | 0 | 0.025 | 0.625 | 0.925 | |
| Value Level | GPA | Letter Grade | Evaluation Score | Sensitivity Level | |
|---|---|---|---|---|---|
| Low | [0, 0.89) | E | [0, 0.25) | 5 | 0.1 |
| Very low | [0.89, 1.67) | D−, D, D+ | [0.25, 0.42) | 4 | 0.2 |
| Middle | [1.67, 2.33) | C−, C, C+ | [0.42, 0.58) | 3 | 0.4 |
| Very high | [2.33, 3.11) | B−, B, B+ | [0.58, 0.78) | 2 | 0.6 |
| High | [3.11, 4] | A−, A, A+ | [0.78, 1] | 1 | 0.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Cai, G.; Liu, C.; Wu, J.; Li, X. A Multi-Level Privacy-Preserving Approach to Hierarchical Data Based on Fuzzy Set Theory. Symmetry 2018, 10, 333. https://doi.org/10.3390/sym10080333
Wang J, Cai G, Liu C, Wu J, Li X. A Multi-Level Privacy-Preserving Approach to Hierarchical Data Based on Fuzzy Set Theory. Symmetry. 2018; 10(8):333. https://doi.org/10.3390/sym10080333
Chicago/Turabian StyleWang, Jinyan, Guoqing Cai, Chen Liu, Jingli Wu, and Xianxian Li. 2018. "A Multi-Level Privacy-Preserving Approach to Hierarchical Data Based on Fuzzy Set Theory" Symmetry 10, no. 8: 333. https://doi.org/10.3390/sym10080333
APA StyleWang, J., Cai, G., Liu, C., Wu, J., & Li, X. (2018). A Multi-Level Privacy-Preserving Approach to Hierarchical Data Based on Fuzzy Set Theory. Symmetry, 10(8), 333. https://doi.org/10.3390/sym10080333