Oversampling Techniques for Bankruptcy Prediction: Novel Features from a Transaction Dataset




Abstract
:1. Introduction
2. Related Works
3. Preliminaries
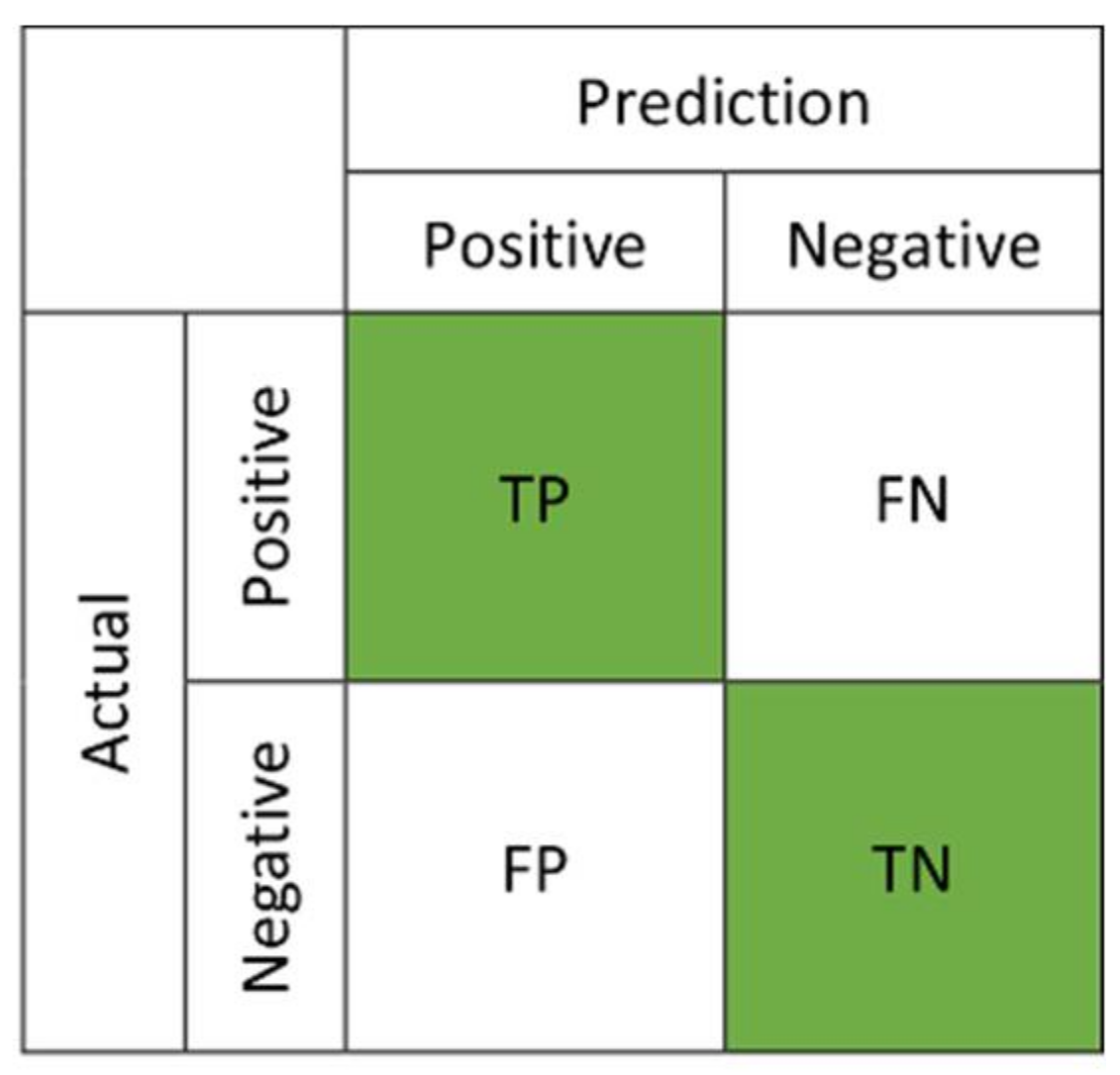
3.1. Imbalanced Data Problem in Binary Classification
3.2. Oversampling Techniques
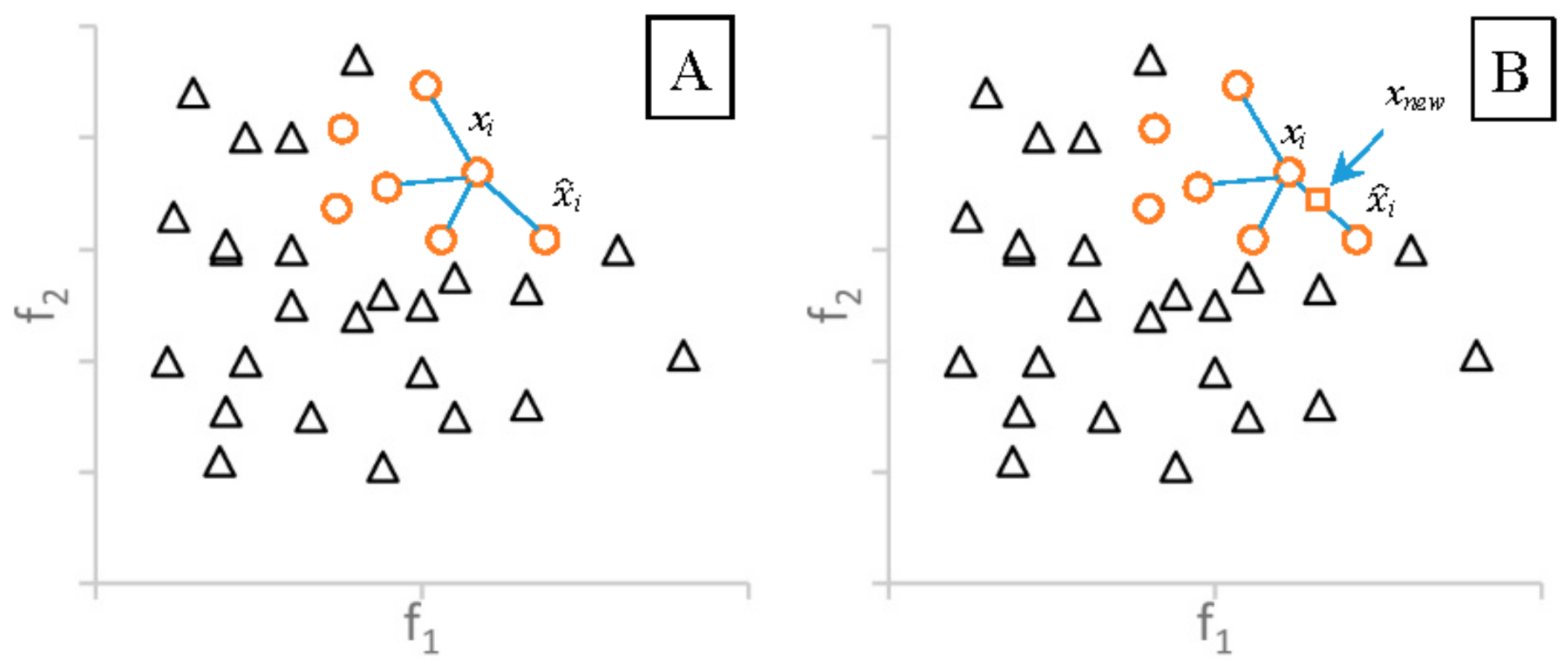
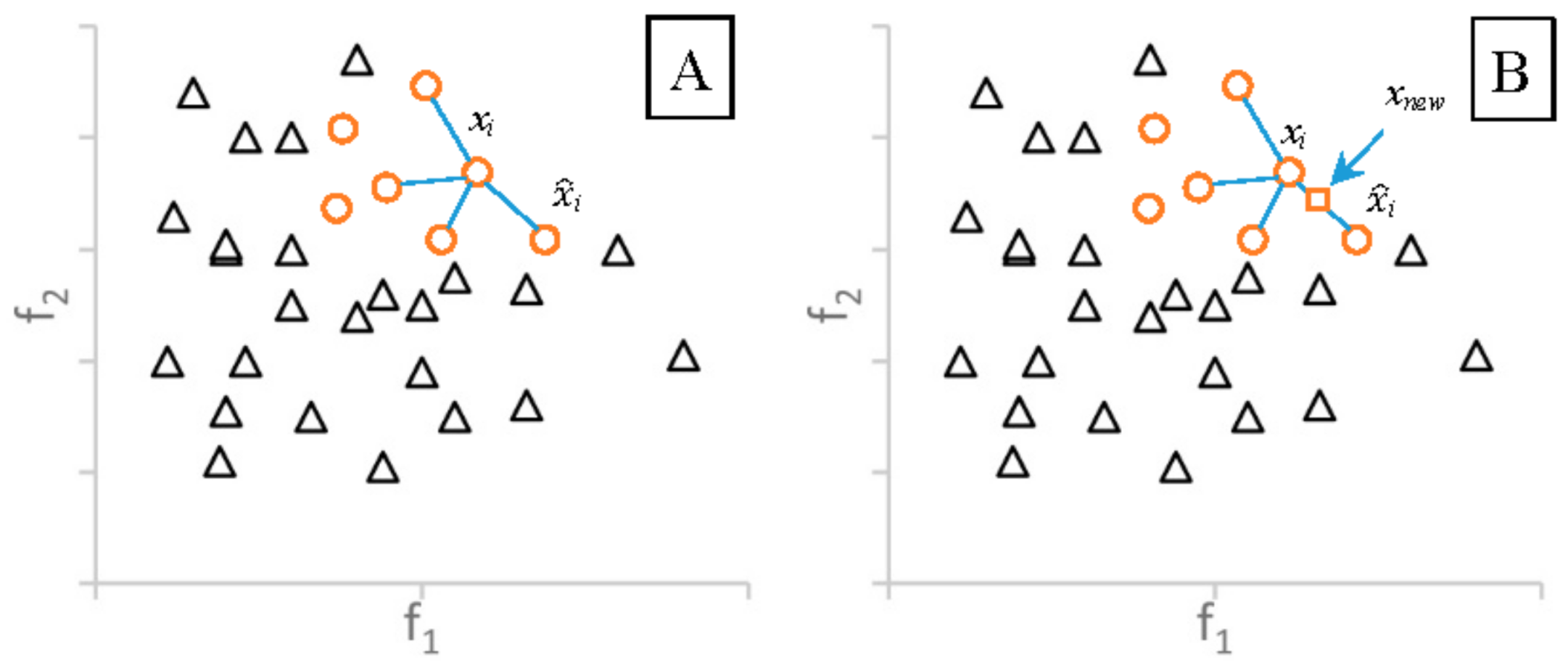
3.2.1. Synthetic Minority Oversampling Technique
3.2.2. Adaptive Synthetic Sampling
3.2.3. Borderline-SMOTE
3.2.4. Oversampling Followed by Data Cleaning Techniques
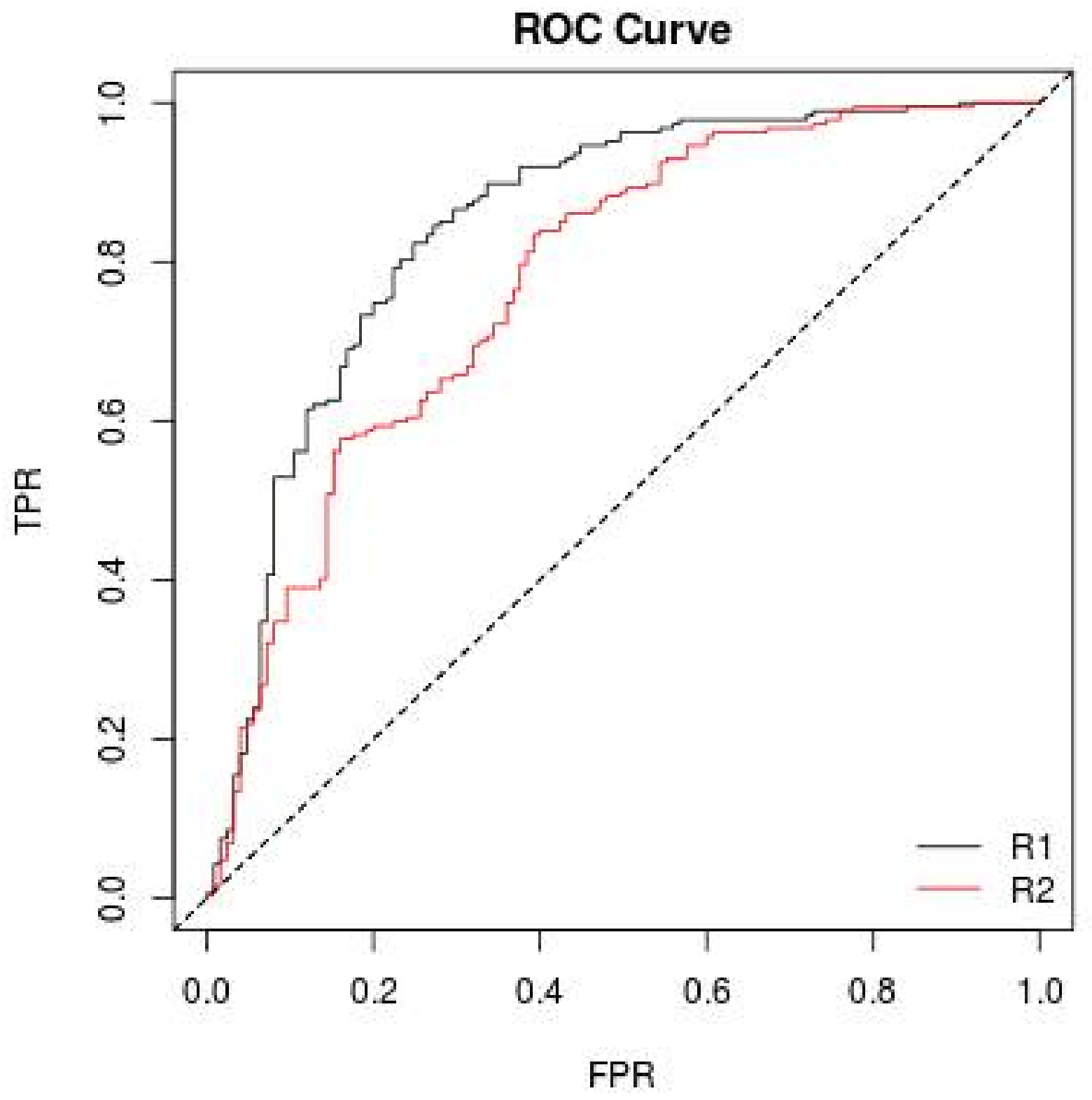
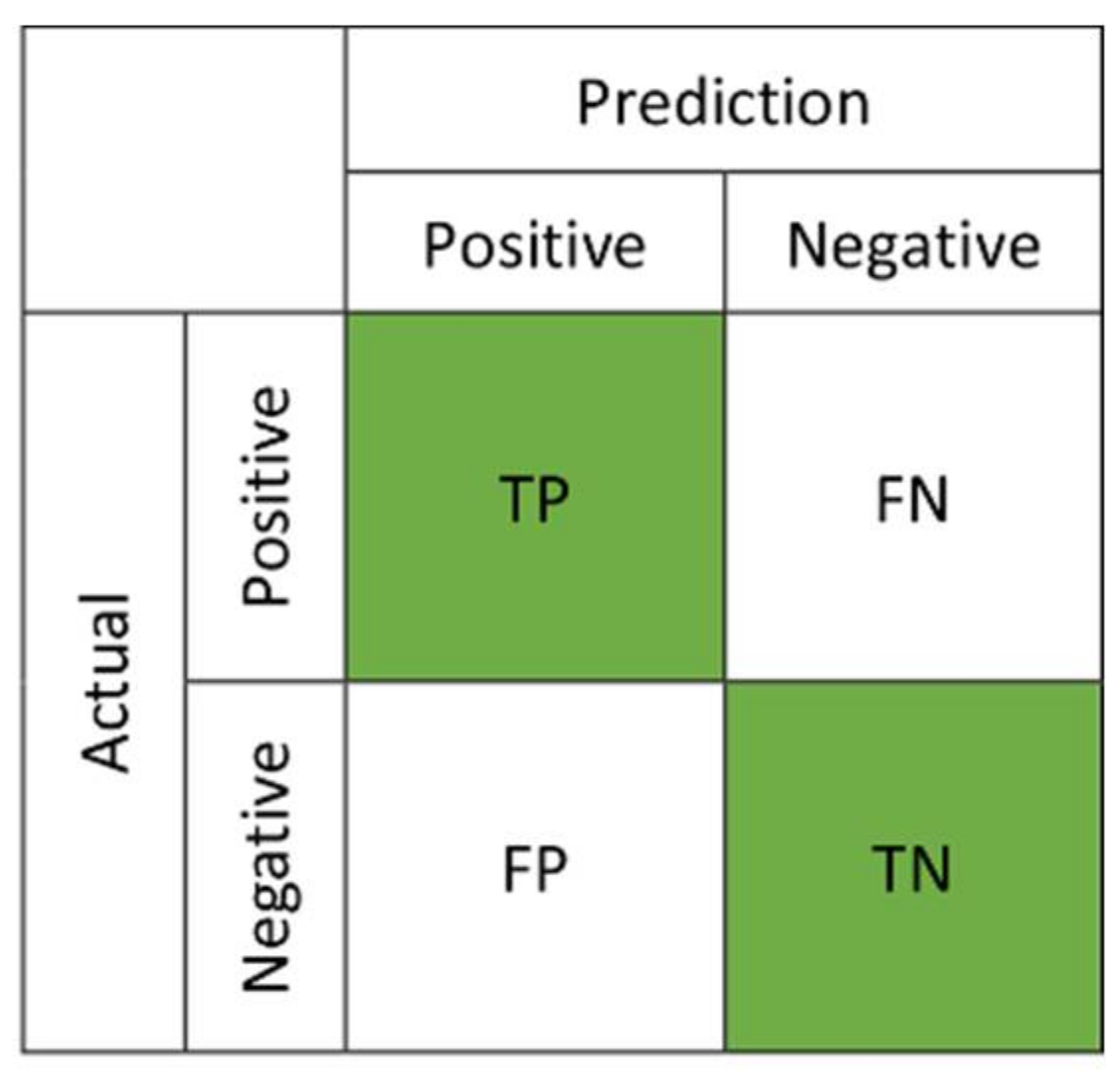
3.3. ROC Curve
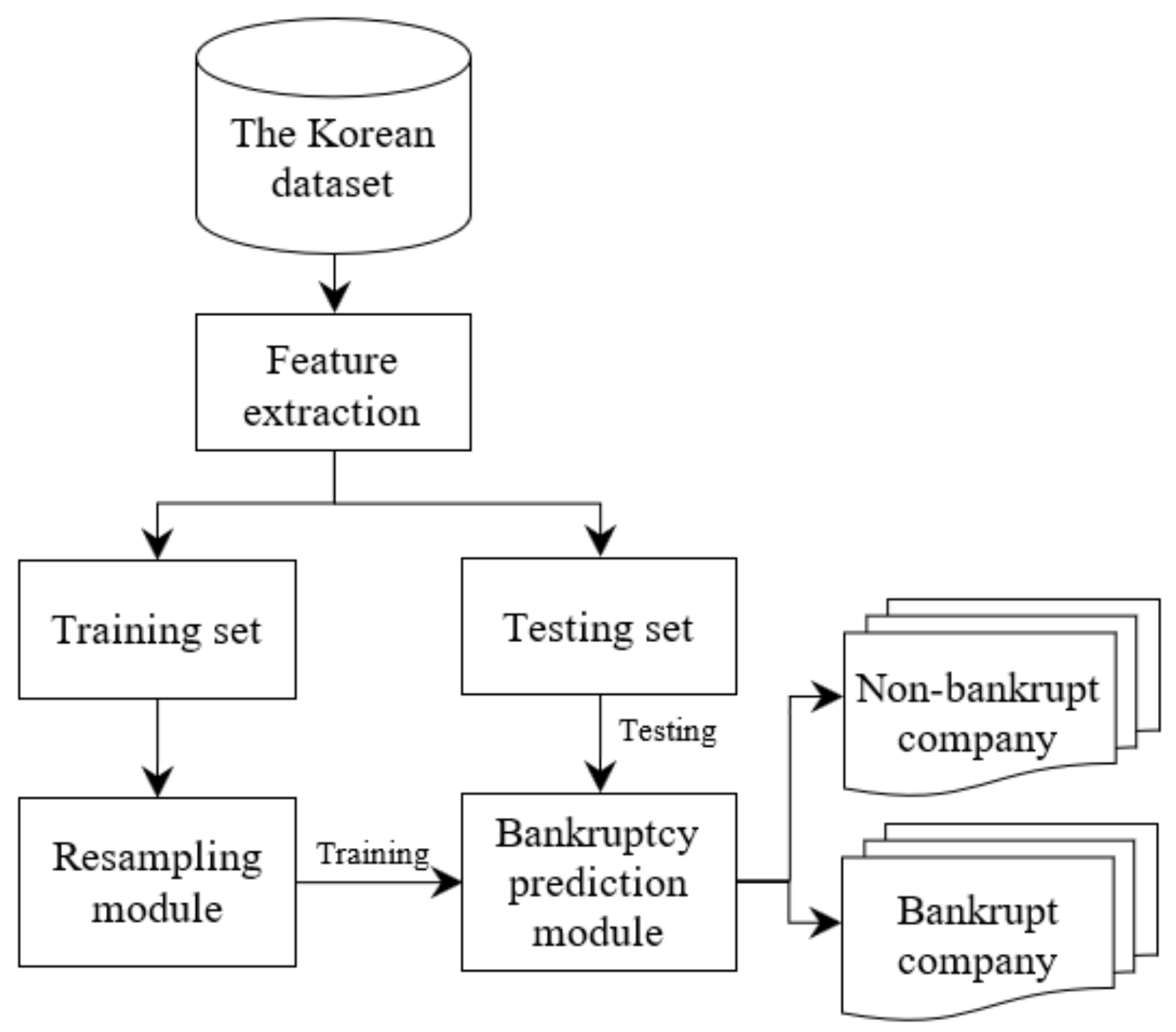
4. Research Design
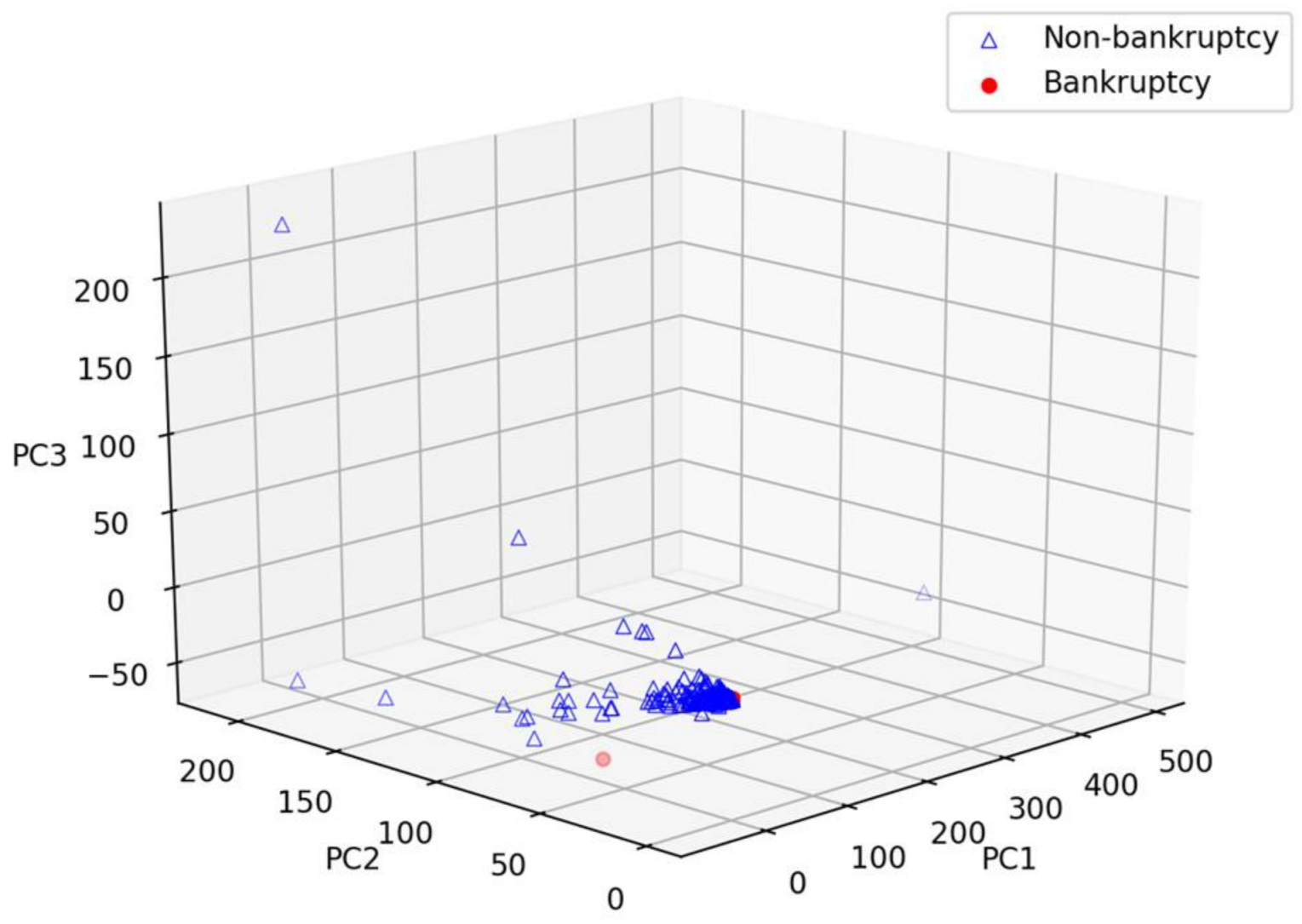
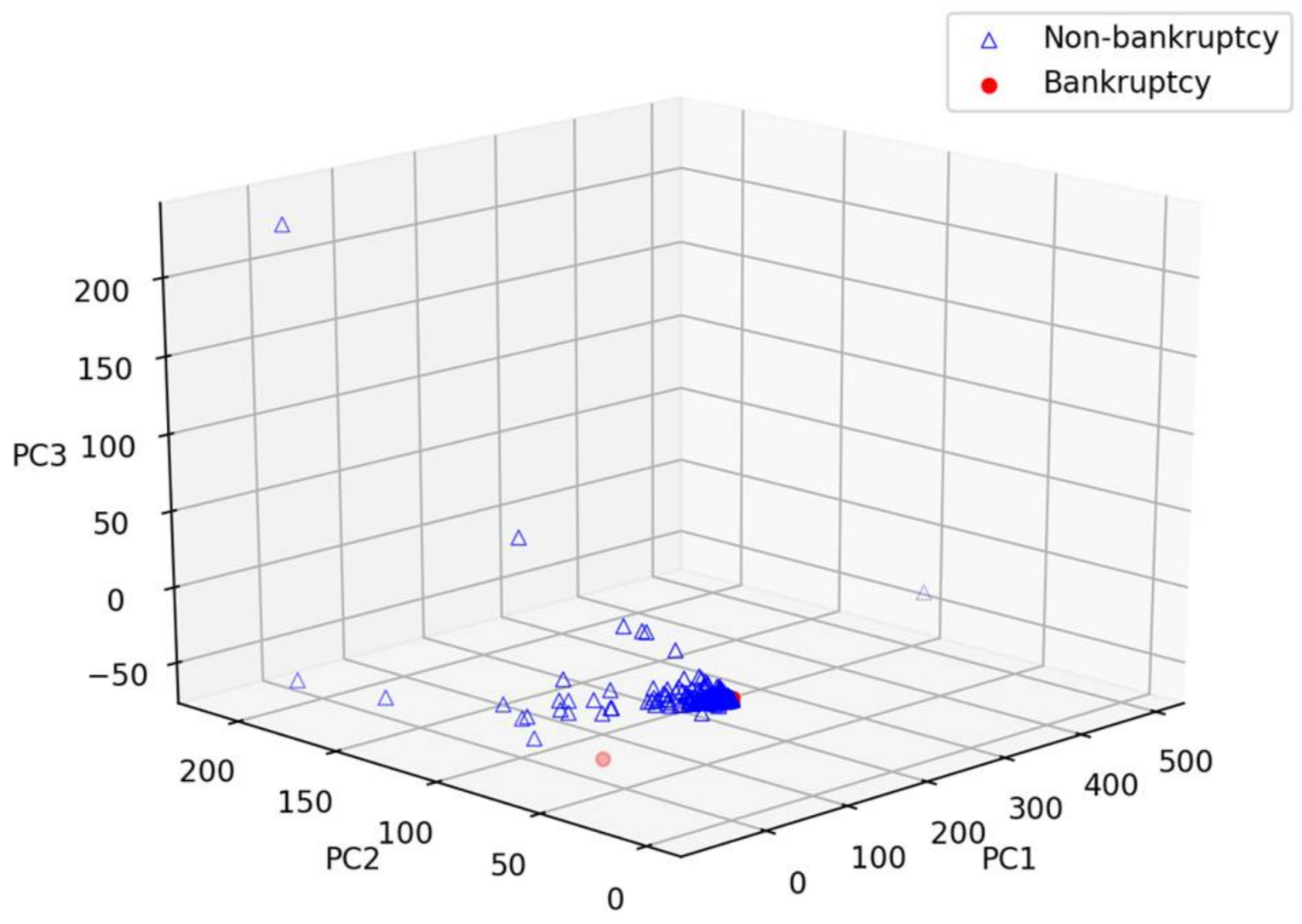
4.1. Dataset
4.2. Experiment Setup
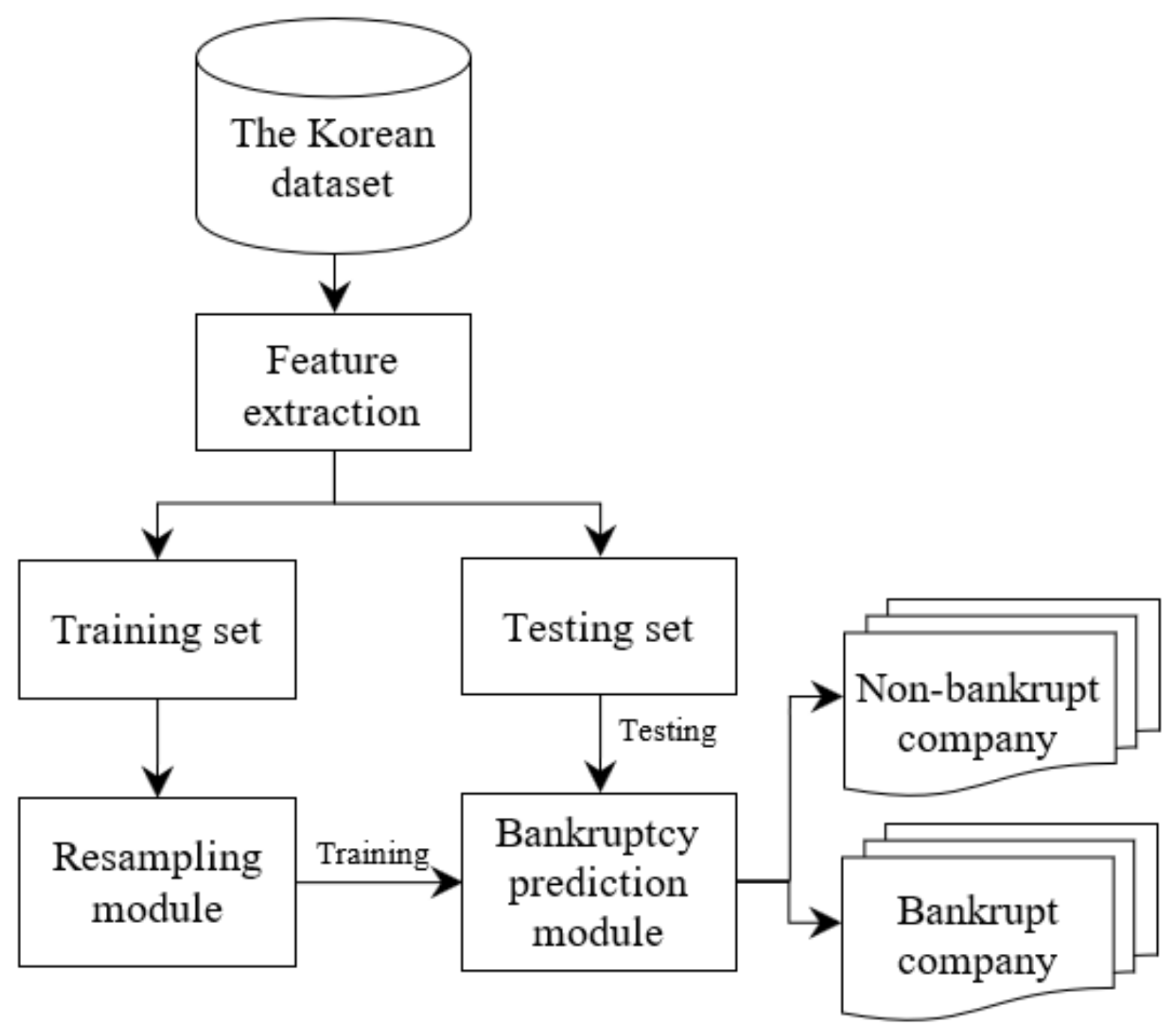
4.2.1. The Bankruptcy Prediction Framework
4.2.2. Novel Features from Transaction Dataset
| Algorithm 1. A novel algorithm for feature extraction. |
 |
5. Experimental Results
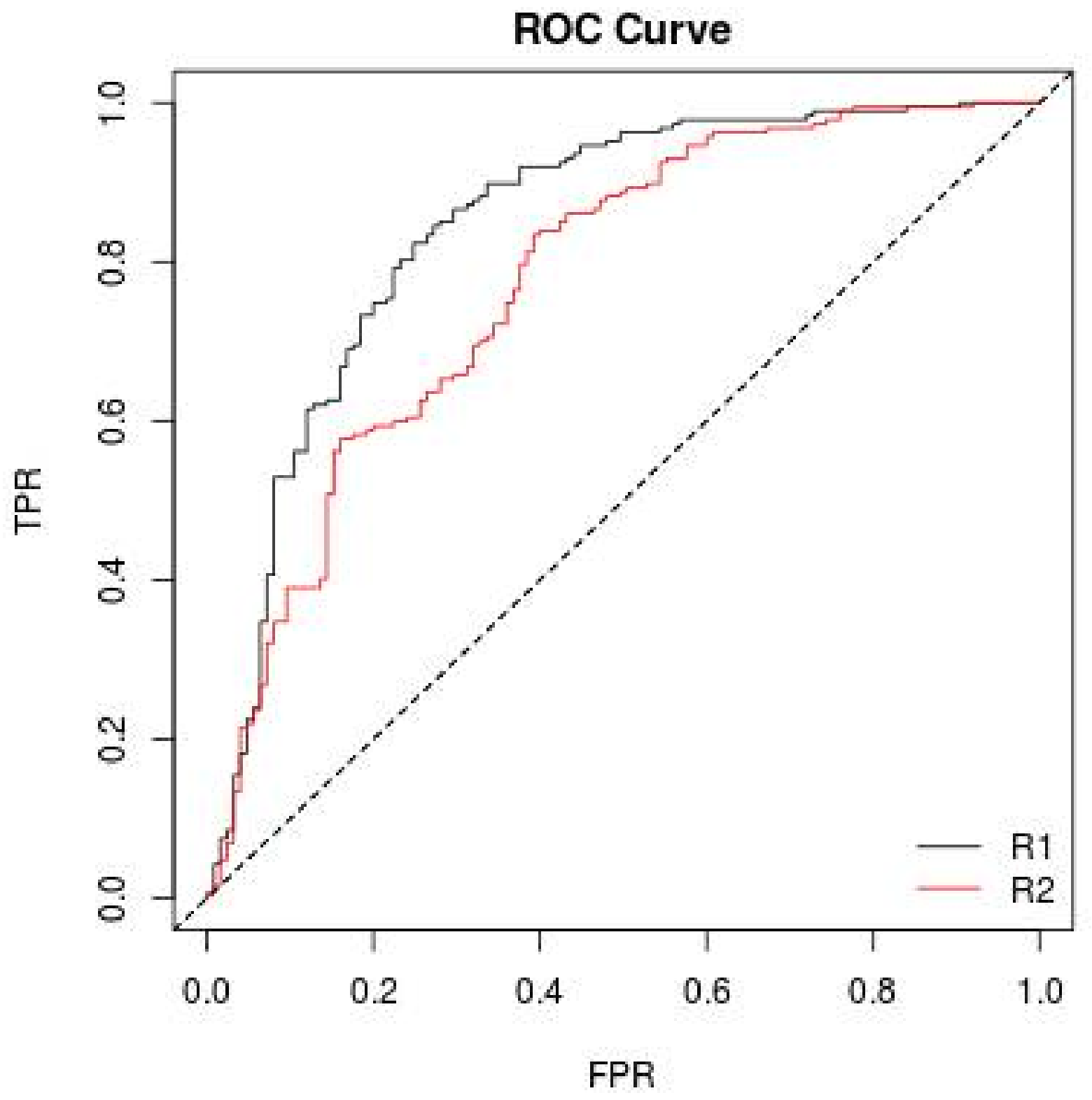
5.1. Results of Bankruptcy Prediction
5.2. Result of Bankruptcy Prediction with Mixed Dataset
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kieu, T.; Vo, B.; Le, T.; Deng, Z.H.; Le, B. Mining top-k co-occurrence items with sequential pattern. Expert Syst. Appl. 2017, 85, 123–133. [Google Scholar] [CrossRef]
- Le, T.; Vo, B.; Baik, S.W. Efficient algorithms for mining top-rank-k erasable patterns using pruning strategies and the subsume concept. Eng. Appl. Artif. Intell. 2018, 68, 1–9. [Google Scholar] [CrossRef]
- Le, T.; Vo, B. The lattice-based approaches for mining association rules: A review. WIREs Data Min. Knowl. Discov. 2016, 6, 140–151. [Google Scholar] [CrossRef]
- Vo, B.; Le, T.; Nguyen, G.; Hong, T.P. Efficient algorithms for mining erasable closed patterns from product datasets. IEEE Access 2017, 5, 3111–3120. [Google Scholar] [CrossRef]
- Vo, B.; Le, T.; Pedrycz, W.; Nguyen, G.; Baik, S.W. Mining erasable itemsets with subset and superset itemset constraints. Expert Syst. Appl. 2017, 69, 50–61. [Google Scholar] [CrossRef]
- Vo, B.; Pham, S.; Le, T.; Deng, Z.H. A novel approach for mining maximal frequent patterns. Expert Syst. Appl. 2017, 73, 178–186. [Google Scholar] [CrossRef]
- Pham, H.P.; Le, H.S. Linguistic Vector Similarity Measures and Applications to Linguistic Information Classification. Int. J. Intell. Syst. 2017, 32, 67–81. [Google Scholar]
- Nguyen, D.T.; Ali, M.; Le, H.S. A Novel Clustering Algorithm in a Neutrosophic Recommender System for Medical Diagnosis. Cogn. Comput. 2017, 9, 526–544. [Google Scholar]
- Le, H.S.; Pham, H.T. Some novel hybrid forecast methods based on picture fuzzy clustering for weather nowcasting from satellite image sequences. Appl. Intell. 2017, 46, 1–15. [Google Scholar]
- Dang, T.H.; Le, H.S.; Le, V.T. Novel fuzzy clustering scheme for 3D wireless sensor networks. Appl. Soft Comput. 2017, 54, 141–149. [Google Scholar]
- Abeysinghe, C.; Li, J.; He, J. A Classifier Hub for Imbalanced Financial Data. In Proceedings of the Australasian Database Conference, Sydney, Australia, 28–29 September 2016; pp. 476–479. [Google Scholar]
- Laurikkala, J. Improving Identification of Difficult Small Classes by Balancing Class Distribution. In Proceedings of the Conference on AI in Medicine in Europe: Artificial Intelligence Medicine, Cascais, Portugal, 1–4 July 2001; pp. 63–66. [Google Scholar]
- Li, Y.; Zhang, S.; Yin, Y.; Xiao, W.; Zhang, J. A Novel Online Sequential Extreme Learning Machine for Gas Utilization Ratio Prediction in Blast Furnaces. Sensors 2017, 17, 1847. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Siegel, J.; Bhattacharyya, R.; Kumar, S.; Sarma, S.E. Air filter particulate loading detection using smartphone audio and optimized ensemble classification. Eng. Appl. Artif. Intell. 2017, 66, 104–112. [Google Scholar] [CrossRef]
- Wei, L.; Xiong, X.; Zhang, W.; He, X.Z.; Zhang, Y. The effect of genetic algorithm learning with a classifier system in limit order markets. Eng. Appl. Artif. Intell. 2017, 65, 436–448. [Google Scholar] [CrossRef]
- Bao, F.; Deng, Y.; Dai, Q. ACID: Association correction for imbalanced data in GWAS. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 15, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Wilk, S.; Stefanowski, J.; Wojciechowski, S.; Farion, K.J.; Michalowski, W. Application of Preprocessing Methods to Imbalanced Clinical Data: An Experimental Study. Inf. Technol. Med. 2016, 471, 503–515. [Google Scholar]
- Barboza, F.; Kimura, H.; Altman, E. Machine learning models and bankruptcy prediction. Expert Syst. Appl. 2017, 83, 405–417. [Google Scholar] [CrossRef]
- Kim, M.J.; Kang, D.K.; Kim, H.B. Geometric mean based boosting algorithm with over-sampling to resolve data imbalance problem for bankruptcy prediction. Expert Syst. Appl. 2015, 42, 1074–1082. [Google Scholar] [CrossRef]
- Wang, M.; Chen, H.; Li, H.; Cai, Z.N.; Zhao, X.; Tong, C.; Li, J.; Xu, X. Grey wolf optimization evolving kernel extreme learning machine: Application to bankruptcy prediction. Eng. Appl. Artif. Intell. 2017, 63, 54–68. [Google Scholar] [CrossRef]
- Zelenkov, Y.; Fedorova, E.; Chekrizov, D. Two-step classification method based on genetic algorithm for bankruptcy forecasting. Expert Syst. Appl. 2017, 88, 393–401. [Google Scholar] [CrossRef]
- Zakaryazad, A.; Duman, E. A profit-driven Artificial Neural Network (ANN) with applications to fraud detection and direct marketing. Neurocomputing 2016, 175, 121–131. [Google Scholar] [CrossRef]
- Tan, M.; Tan, L.; Dara, S.; Mayeux, C. Online defect prediction for imbalanced data. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering (ICSE), Florence, Italy, 16–24 May 2015; pp. 99–108. [Google Scholar]
- Folino, G.; Pisani, F.S.; Sabatino, P. An Incremental Ensemble Evolved by using Genetic Programming to Efficiently Detect Drifts in Cyber Security Datasets. In Proceedings of the GECCO (Companion), Denver, CO, USA, 20–24 July 2016; pp. 1103–1110. [Google Scholar]
- Li, Y.; Guo, H.; Liu, X.; Li, Y.; Li, J. Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl.-Based Syst. 2016, 94, 88–104. [Google Scholar] [CrossRef]
- Kim, H.J.; Jo, N.O.; Shin, K.S. Optimization of cluster-based evolutionary undersampling for the artificial neural networks in corporate bankruptcy prediction. Expert Syst. Appl. 2016, 59, 226–234. [Google Scholar] [CrossRef]
- Batista, G.; Prati, R.C.; Monard, M.C. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN 2008), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Zieba, M.; Tomczak, S.K.; Tomczak, J.M. Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction. Expert Syst. Appl. 2016, 58, 93–101. [Google Scholar] [CrossRef]
- Pietruszkiewicz, W. Dynamical systems and nonlinear Kalman filtering applied in classification. In Proceedings of the 7th IEEE International Conference on Cybernetic Intelligent Systems (CIS 2008), London, UK, 9–10 September 2008. [Google Scholar]
- Zhao, D.; Huang, C.; Wei, Y.; Yu, F.; Wang, M.; Chen, H. An Effective Computational Model for Bankruptcy Prediction Using Kernel Extreme Learning Machine Approach. Comput. Econ. 2017, 49, 325–341. [Google Scholar] [CrossRef]
- Kang, P.; Cho, S. EUS SVMs: Ensemble of Under-Sampled SVMs for Data Imbalance Problems. In Proceedings of the International Conference on Neural Information Processing (ICONIP 2006), Hong Kong, China, 3–6 October 2006; pp. 837–846. [Google Scholar]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Lemaitre, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 17. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Description |
|---|---|
| F1 | Current assets |
| F2 | Non-current assets, fixed assets, or fixed capital property |
| F3 | Total assets |
| F4 | Current liabilities within one year |
| F5 | Non-current liabilities that are over one-year terms. |
| F6 | Total liabilities |
| F7 | Capital |
| F8 | Earned surplus |
| F9 | Total capital |
| F10 | Total capital after liabilities |
| F11 | Sales revenue |
| F12 | Cost of sales |
| F13 | Gross profit |
| F14 | Sales and administrative expenses |
| F15 | Operating profit that refers to the profits earned through business operations |
| F16 | Non-operating income |
| F17 | Non-operating expenses |
| F18 | Income and loss before income taxes |
| F19 | Net income |
| Oversampling Techniques | Bankruptcy Prediction Model | AUC (%) |
|---|---|---|
| None | Random Forest | 82.4 ± 0.5 |
| Decision Tree | 76.2 ± 0.6 | |
| Multi-Layer Perceptron | 51.8 ± 0.2 | |
| SVM | 52.4 ± 1.7 | |
| SMOTE | Random Forest | 84.1 ± 0.4 |
| Decision Tree | 81.9 ± 0.5 | |
| Multi-Layer Perceptron | 71.4 ± 0.8 | |
| SVM | 53.1 ± 1.5 | |
| Borderline-SMOTE | Random Forest | 83.1 ± 0.5 |
| Decision Tree | 75.6 ± 0.6 | |
| Multi-Layer Perceptron | 67.7 ± 0.6 | |
| SVM | 52.1 ± 2.5 | |
| ADASYN | Random Forest | 83.1 ± 0.4 |
| Decision Tree | 80.3 ± 0.5 | |
| Multi-Layer Perceptron | 68.9 ± 0.5 | |
| SVM | 51.2 ± 2.1 | |
| SMOTE + Tomek | Random Forest | 84.1 ± 0.4 |
| Decision Tree | 81.9 ± 0.5 | |
| Multi-Layer Perceptron | 69.8 ± 0.4 | |
| SVM | 53.5 ± 1.2 | |
| SMOTE + ENN | Random Forest | 84.2 ± 0.5 |
| Decision Tree | 81.2 ± 0.5 | |
| Multi-Layer Perceptron | 72.7 ± 0.5 | |
| SVM | 54.2 ± 1.4 |
| Times | AUC (%) | AUC (%) for Mixed Dataset |
|---|---|---|
| 1 | 83.9 | 84.3 |
| 2 | 84.4 | 84.3 |
| 3 | 84.2 | 84.4 |
| 4 | 84.2 | 84.9 |
| 5 | 84.3 | 84.3 |
| 6 | 84.5 | 84.1 |
| Average AUC | 84.2 | 84.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, T.; Lee, M.Y.; Park, J.R.; Baik, S.W. Oversampling Techniques for Bankruptcy Prediction: Novel Features from a Transaction Dataset. Symmetry 2018, 10, 79. https://doi.org/10.3390/sym10040079
Le T, Lee MY, Park JR, Baik SW. Oversampling Techniques for Bankruptcy Prediction: Novel Features from a Transaction Dataset. Symmetry. 2018; 10(4):79. https://doi.org/10.3390/sym10040079
Chicago/Turabian StyleLe, Tuong, Mi Young Lee, Jun Ryeol Park, and Sung Wook Baik. 2018. "Oversampling Techniques for Bankruptcy Prediction: Novel Features from a Transaction Dataset" Symmetry 10, no. 4: 79. https://doi.org/10.3390/sym10040079
APA StyleLe, T., Lee, M. Y., Park, J. R., & Baik, S. W. (2018). Oversampling Techniques for Bankruptcy Prediction: Novel Features from a Transaction Dataset. Symmetry, 10(4), 79. https://doi.org/10.3390/sym10040079