K-Hyperline Clustering-Based Color Image Segmentation Robust to Illumination Changes


Abstract
1. Introduction
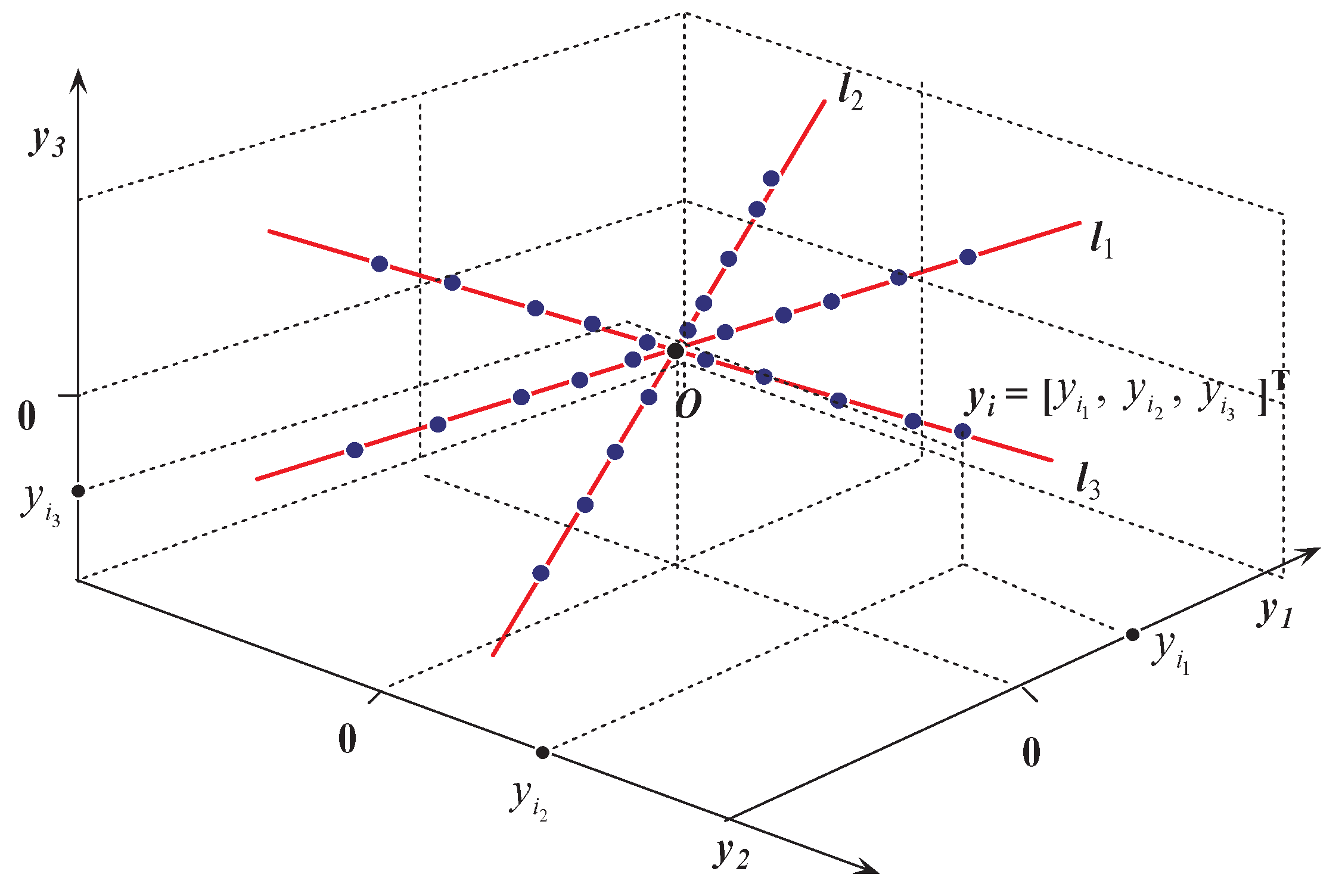
2. K-Hyperline Clustering
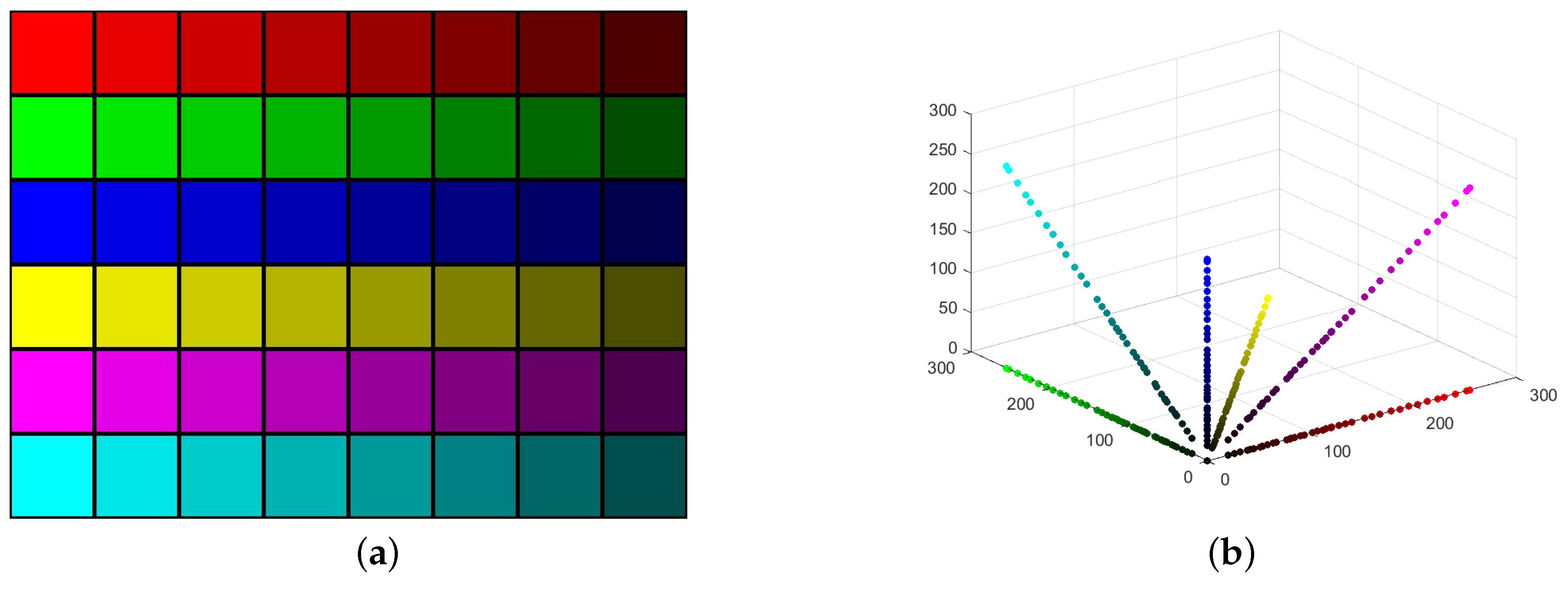
3. Color Image Segmentation Based on K-Hyperline Clustering
| Algorithm 1: Color image segmentation based on K-HLC. |
| Input: Observed data and cluster number K. |
|
| Output: Clustering data , . |
| * Usually, we can set and . |
4. Experimental Results and Discussion
4.1. Results of Different Color Spaces
4.2. Results of Synthetic Color Images
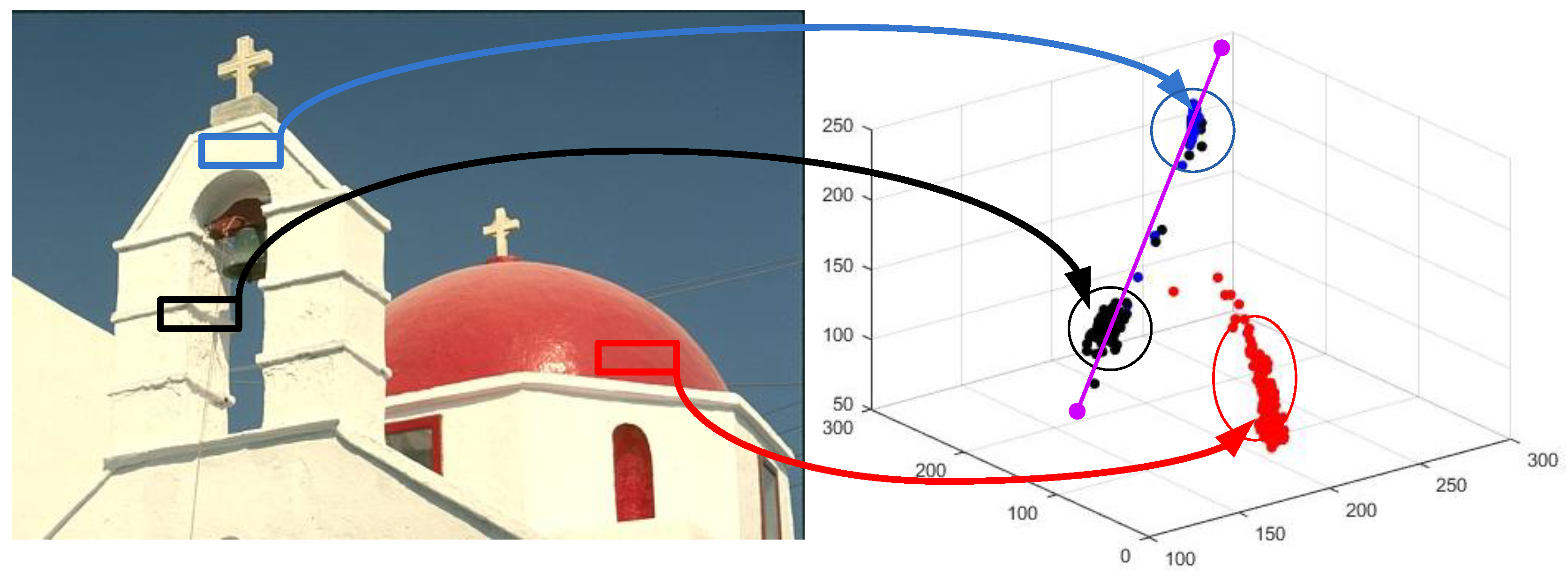
4.3. Results of Real- World Color Images
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Zheng, H.; Lin, X.; Wu, Y.; Su, M. A novel image segmentation method based on fast density clustering algorithm. Eng. Appl. Artif. Intell. 2018, 73, 92–110. [Google Scholar] [CrossRef]
- Gong, M.; Qian, Y.; Cheng, L. Integrated Foreground Segmentation and Boundary Matting for Live Videos. IEEE Trans. Image Process. 2015, 24, 1356–1370. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Čehovin, L.; Leonardis, A.; Kristan, M. Robust visual tracking using template anchors. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Mazzon, R.; Cavallaro, A. Multi-camera tracking using a Multi-Goal Social Force Model. Neurocomputing 2013, 100, 41–50. [Google Scholar] [CrossRef]
- Jeong, J.; Won, I.; Yang, H.; Lee, B.; Jeong, D. Deformable Object Matching Algorithm Using Fast Agglomerative Binary Search Tree Clustering. Symmetry 2017, 9, 25. [Google Scholar] [CrossRef]
- Li, F.; Qin, J. Robust fuzzy local information and LpLp-norm distance-based image segmentation method. IET Image Process. 2017, 11, 217–226. [Google Scholar] [CrossRef]
- Yin, S.; Qian, Y.; Gong, M. Unsupervised Hierarchical Image Segmentation through Fuzzy Entropy Maximization. Pattern Recognit. 2017, 68, 245–259. [Google Scholar] [CrossRef]
- He, L.; Li, Y.; Zhang, X.; Chen, C.; Zhu, L.; Leng, C. Incremental Spectral Clustering via Fastfood Features and Its Application to Stream Image Segmentation. Symmetry 2018, 10, 272. [Google Scholar] [CrossRef]
- Moreno, R.; GranA, M.; Ramik, D.M.; Madani, K. Image segmentation on spherical coordinate representation of RGB colour space. Image Process. IET 2012, 6, 1275–1283. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An Efficient k-Means Clustering Algorithm: Analysis and Implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Nongmeikapam, K.; Kumar, W.K.; Singh, A.D. Fast and Automatically Adjustable GRBF Kernel Based Fuzzy C-Means for Cluster-wise Coloured Feature Extraction and Segmentation of MR Images. IET Image Process. 2018, 12, 513–524. [Google Scholar] [CrossRef]
- Ahmed, M.N.; Yamany, S.M.; Mohamed, N.; Farag, A.A.; Moriarty, T. A modified fuzzy C-means algorithm for bias field estimation and segmentation of MRI data. IEEE Trans. Med. Imag. 2002, 21, 193–199. [Google Scholar] [CrossRef] [PubMed]
- Krinidis, S.; Chatzis, V. A Robust Fuzzy Local Information C-Means Clustering Algorithm. IEEE Trans. Image Process. 2010, 19, 1328–1337. [Google Scholar] [CrossRef] [PubMed]
- Lei, T.; Jia, X.; Zhang, Y.; He, L.; Meng, H.; Nandi, A.K. Significantly Fast and Robust Fuzzy C-Means Clustering Algorithm Based on Morphological Reconstruction and Membership Filtering. IEEE Trans. Fuzzy Syst. 2018, 26, 3027–3041. [Google Scholar] [CrossRef]
- Li, J.; Miao, Z. Foreground segmentation for dynamic scenes with sudden illumination changes. Image Process. IET 2012, 6, 606–615. [Google Scholar] [CrossRef]
- Delibasis, K.K.; Goudas, T.; Maglogiannis, I. A novel robust approach for handling illumination changes in video segmentation. Eng. Appl. Artif. Intell. 2016, 49, 43–60. [Google Scholar] [CrossRef]
- Xie, K.; He, Z.; Cichocki, A.; Fang, X. Rate of Convergence of the FOCUSS Algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1276–1289. [Google Scholar] [CrossRef] [PubMed]
- Xie, K.; He, Z.; Cichocki, A. Convergence analysis of the FOCUSS algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2017, 26, 601–613. [Google Scholar] [CrossRef] [PubMed]
- Bofill, P.; Zibulevsky, M. Underdetermined blind source separation using sparse representations. Signal Process. 2001, 81, 2353–2362. [Google Scholar] [CrossRef]
- He, Z.; Cichocki, A.; Li, Y.; Xie, S.; Sanei, S. K-hyperline clustering learning for sparse component analysis. Signal Process. 2009, 89, 1011–1022. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vision 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Finlayson, G.D.; Drew, M.S.; Funt, B.V. Diagonal transforms suffice for color constancy. In Proceedings of the International Conference on Computer Vision, Berlin, Germany, 11–14 May 1993; pp. 164–171. [Google Scholar]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Smith, A.R. Color gamut transform pairs. ACM Siggraph Comput. Graph. 1978, 12, 12–19. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Illumination Levels (%) | 10 | 20 | 30 | 40 | 50 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| K-means | 0.18 | 0.31 | 0.50 | 0.62 | 0.81 | 0.81 | 0.62 | 0.50 | 0.31 | 0.18 |
| K-means (norm) | 0.25 | 0.37 | 0.56 | 0.68 | 0.81 | 0.81 | 0.81 | 0.50 | 0.31 | 0.25 |
| FCM | 0.25 | 0.37 | 0.56 | 0.81 | 0.87 | 0.93 | 0.81 | 0.56 | 0.31 | 0.25 |
| FCM (norm) | 0.06 | 0.06 | 0.12 | 0.12 | 0.18 | 0.18 | 0.12 | 0.12 | 0.12 | 0.06 |
| FLICM | 0.32 | 0.42 | 0.56 | 0.65 | 0.81 | 0.81 | 0.68 | 0.62 | 0.48 | 0.35 |
| FRFCM | 0.58 | 0.61 | 0.78 | 0.89 | 0.96 | 0.96 | 0.89 | 0.77 | 0.63 | 0.61 |
| Our method |
| Images (Name) | K-Means | FCM | FLICM | FRFCM | Ours |
|---|---|---|---|---|---|
| Church | 0.9216 | 0.9246 | 0.8211 | 0.9730 | |
| Flower | 0.8349 | 0.8457 | 0.7414 | 0.9387 | |
| Rhinoceros | 0.5536 | 0.6105 | 0.6290 | 0.7266 | |
| Tiger | 0.4180 | 0.6597 | 0.6461 | 0.8472 | |
| Horses | 0.7425 | 0.7922 | 0.6643 | 0.8321 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Li, P.; Wen, H.; Xie, Y.; He, Z. K-Hyperline Clustering-Based Color Image Segmentation Robust to Illumination Changes. Symmetry 2018, 10, 610. https://doi.org/10.3390/sym10110610
Yang S, Li P, Wen H, Xie Y, He Z. K-Hyperline Clustering-Based Color Image Segmentation Robust to Illumination Changes. Symmetry. 2018; 10(11):610. https://doi.org/10.3390/sym10110610
Chicago/Turabian StyleYang, Senquan, Pu Li, HaoXiang Wen, Yuan Xie, and Zhaoshui He. 2018. "K-Hyperline Clustering-Based Color Image Segmentation Robust to Illumination Changes" Symmetry 10, no. 11: 610. https://doi.org/10.3390/sym10110610
APA StyleYang, S., Li, P., Wen, H., Xie, Y., & He, Z. (2018). K-Hyperline Clustering-Based Color Image Segmentation Robust to Illumination Changes. Symmetry, 10(11), 610. https://doi.org/10.3390/sym10110610