Improvement of Speech/Music Classification for 3GPP EVS Based on LSTM


Abstract
1. Introduction
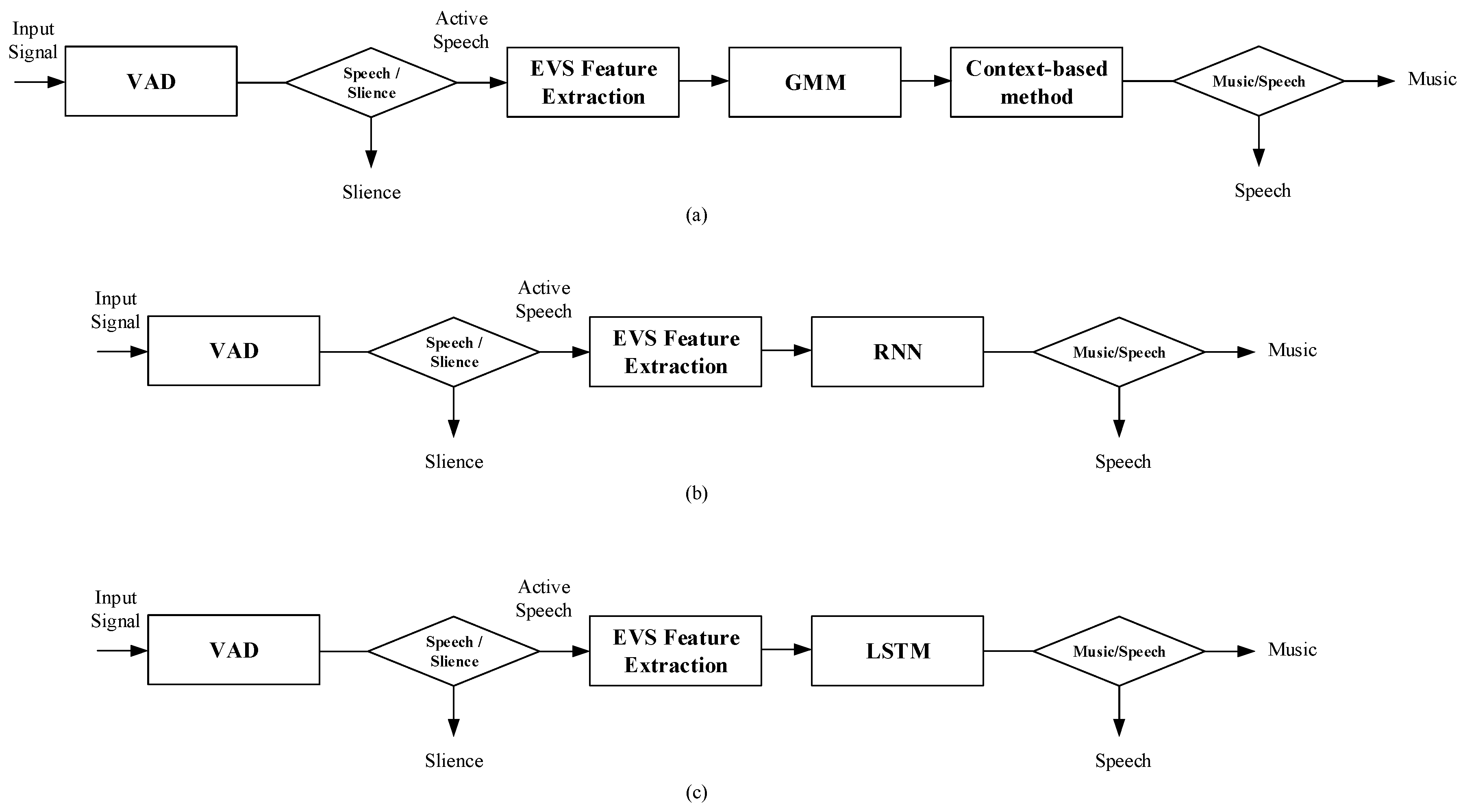
2. Conventional 3GPP Enhanced Voice Services
2.1. Feature Selection
2.2. GMM-Based Method
2.3. Context-Based Method
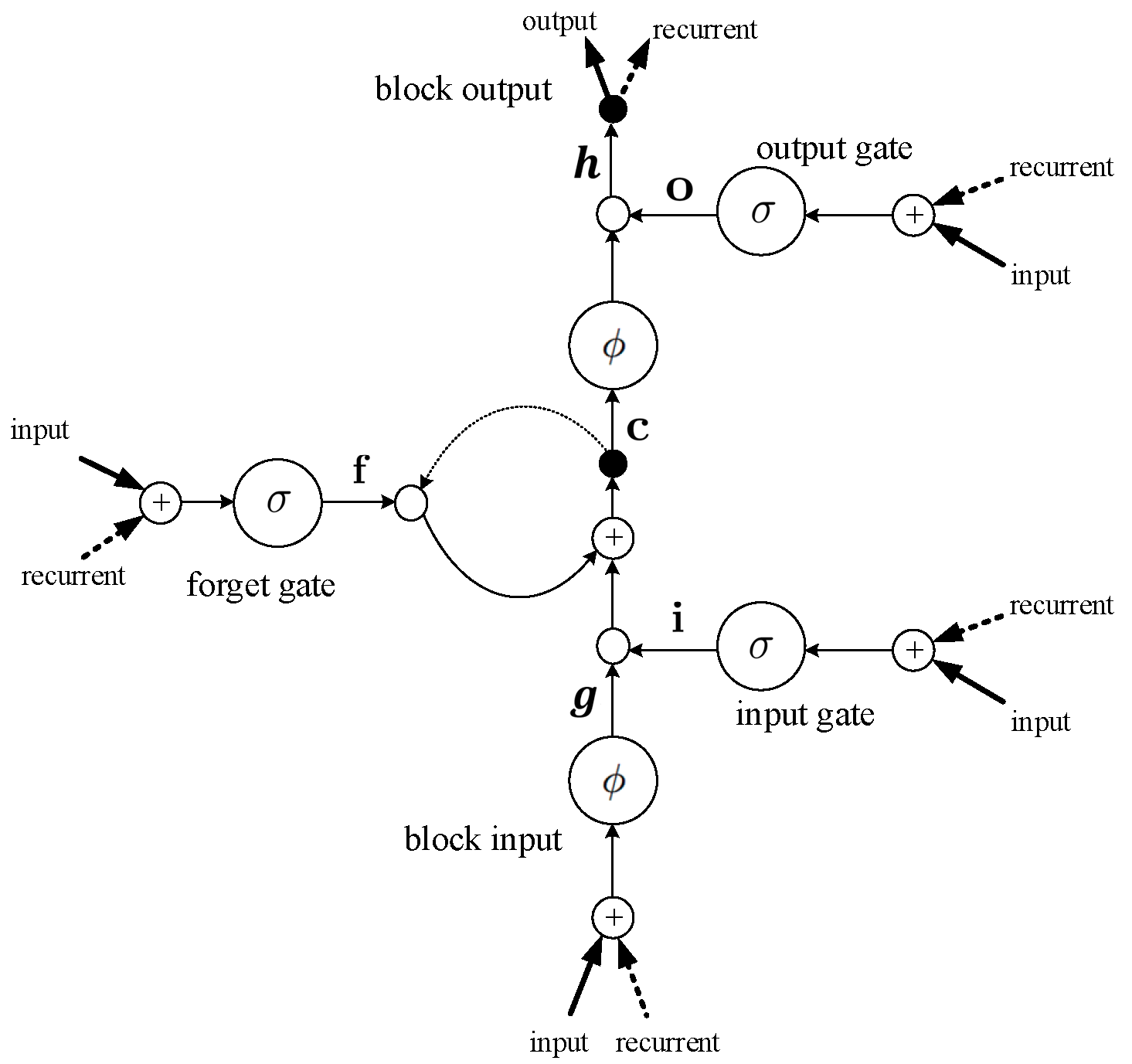
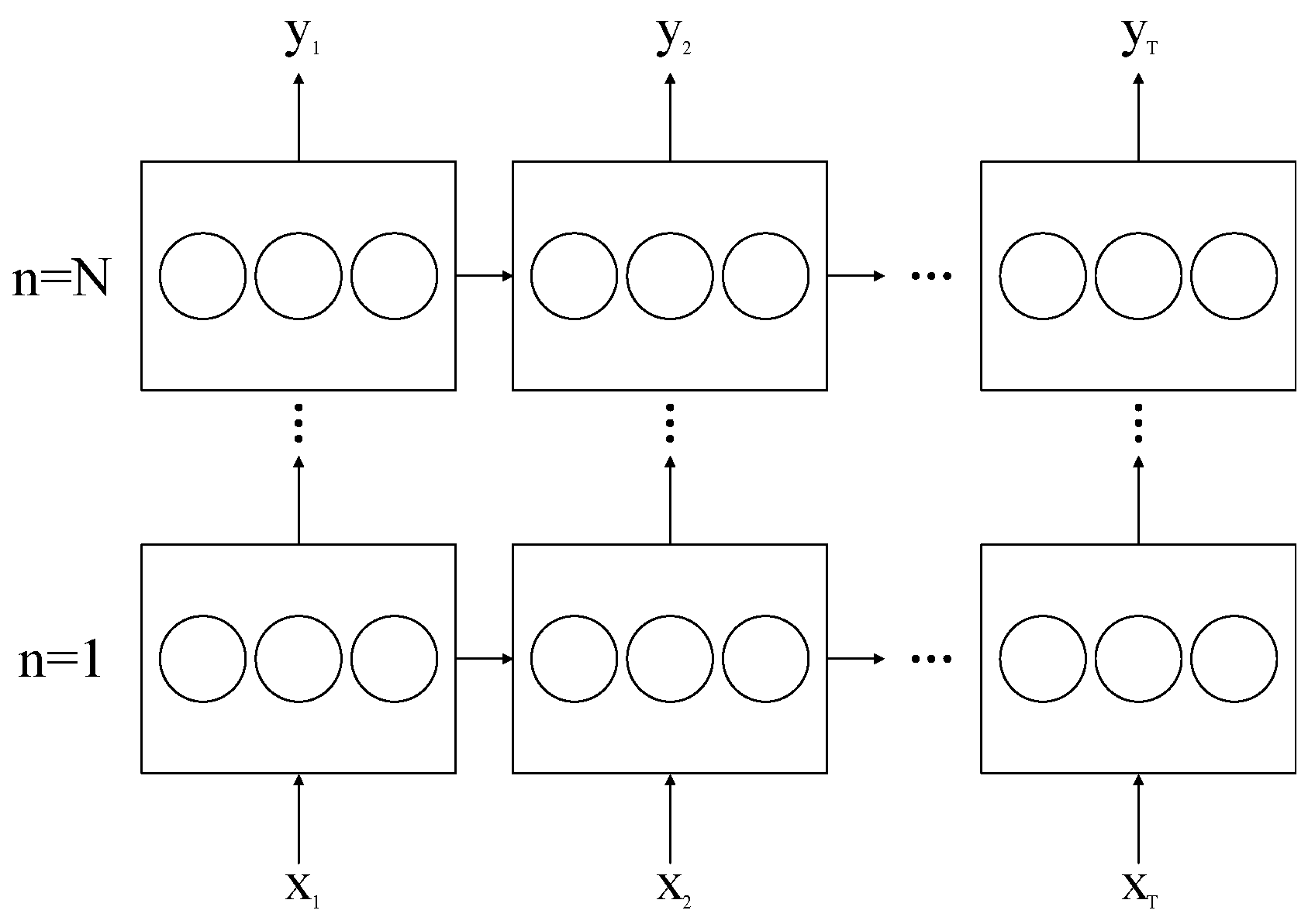
3. Proposed LSTM-Based Speech/Music Classification
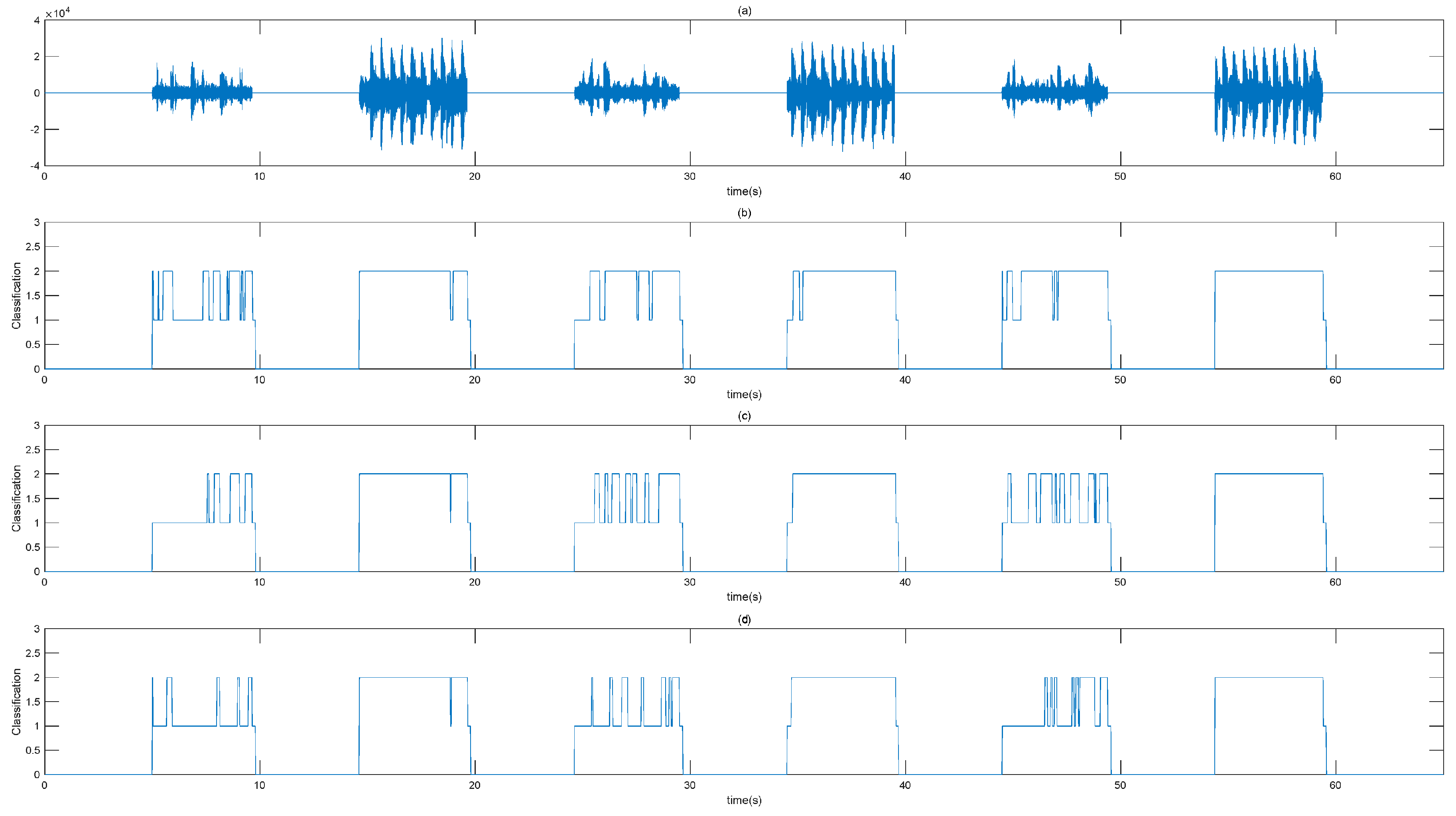
4. Experiments and Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gao, Y.; Shlomot, E.; Benyassine, A.; Thyssen, J.; Su, H.-Y.; Murgia, C. The SMV algorithm selected by TIA and 3GPP2 for CDMA application. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 709–712. [Google Scholar]
- 3GPP2 Spec. Source-Controlled Variable-Rate Multimedia Wideband Speech Codec (VMR-WB), Service Option 62 and 63 for Spread Spectrum Systems, 3GPP2-C.S0052-A, v.1.0. April 2005. Available online: https://www.3gpp2.org/Public_html/Specs/C.S0052-0_v1.0_040617.pdf (accessed on 6 November 2018).
- 3GPP Spec. Codec for Enhanced Voice Services (EVS), Detailed Algorithm Description, TS 26.445, v.12.0.0. September 2014. Available online: https://www.etsi.org/deliver/etsi_ts/126400_126499/126445/12.00.00_60/ts_126445v120000p.pdf (accessed on 6 November 2018).
- Saunders, J. Real-time discrimination of broadcast speech/music. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Atlanta, GA, USA, 7–10 May 1996; pp. 993–996. [Google Scholar]
- Fuchs, G. A robust speech/music discriminator for switched audio coding. In Proceedings of the Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 569–573. [Google Scholar]
- Lim, C.; Chang, J.-H. Improvement of SVM-Based Speech/Music Classification Using Adaptive Kernel Technique. IEICE Trans. Inf. Syst. 2012, 9, 888–891. [Google Scholar] [CrossRef]
- Lim, C.; Chang, J.-H. Efficient implementation techniques of an svm-based speech/music classifier in smv. Multimed. Tools Appl. 2015, 74, 5375–5400. [Google Scholar] [CrossRef]
- Song, J.H.; Lee, K.H.; Chang, J.H.; Kim, J.K.; Kim, N.S. Analysis and Improvement of Speech/Music Classification for 3GPP2 SMV Based on GMM. IEEE Signal Process. Lett. 2008, 15, 103–106. [Google Scholar] [CrossRef]
- Song, J.-H.; An, H.-S.; Lee, S.M. Speech/music classification enhancement for 3gpp2 smv codec based on deep belief networks. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2014, 97, 661–664. [Google Scholar] [CrossRef]
- Malenovsky, V.; Vaillancourt, T.; Zhe, W.; Choo, K.; Atti, V. Two-stage speech/music classifier with decision smoothing and sharpening in the EVS codec. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 5718–5722. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2342–2350. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Karnebäck, S. Discrimination between speech and music based on a low frequency modulation feature. In Proceedings of the Eurospeech, Aalborg, Denmark, 3–7 September 2001; pp. 1891–1984. [Google Scholar]
- Dempster, A.P.; Lairdand, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–38. [Google Scholar]
- Fisher, W.M.; Doddington, G.R.; Goudie-Marshall, K.M. The DARPA speech recognition research database: Specification and status. In Proceedings of the DARPA Workshop Speech Recognition, Palo Alto, CA, USA, 19–20 February 1986; pp. 93–99. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of first hidden layer units | 200 |
| Number of second hidden layer units | 600 |
| Number of third hidden layer units | 200 |
| Learning rate | 0.00006 |
| Dropout rate | 0.2 |
| dB | EVS | RNN | Proposed | ||
|---|---|---|---|---|---|
| speech | clean | - | 0.9980 | 0.9981 | 0.9985 |
| car | 5 dB | 0.8830 | 0.8911 | 0.9135 | |
| 10 dB | 0.9131 | 0.9414 | 0.9517 | ||
| 15 dB | 0.9933 | 0.9940 | 0.9951 | ||
| 20 dB | 0.9927 | 0.9941 | 0.9943 | ||
| babble | 5 dB | 0.5757 | 0.6157 | 0.6524 | |
| 10 dB | 0.7214 | 0.7561 | 0.7752 | ||
| 15 dB | 0.9649 | 0.9710 | 0.9760 | ||
| 20 dB | 0.9905 | 0.9914 | 0.9920 | ||
| white | 5 dB | 0.6633 | 0.6917 | 0.7017 | |
| 10 dB | 0.8362 | 0.8581 | 0.8710 | ||
| 15 dB | 0.8792 | 0.9012 | 0.9104 | ||
| 20 dB | 0.9642 | 0.9775 | 0.9867 | ||
| pink | 5 dB | 0.3752 | 0.6016 | 0.6312 | |
| 10 dB | 0.6900 | 0.6925 | 0.8110 | ||
| 15 dB | 0.9312 | 0.9450 | 0.9757 | ||
| 20 dB | 0.9853 | 0.9937 | 0.9948 | ||
| factory1 | 5 dB | 0.3289 | 0.5948 | 0.6391 | |
| 10 dB | 0.6702 | 0.7491 | 0.8471 | ||
| 15 dB | 0.9265 | 0.9481 | 0.9513 | ||
| 20 dB | 0.9850 | 0.9871 | 0.9906 | ||
| factory2 | 5 dB | 0.7251 | 0.8362 | 0.8974 | |
| 10 dB | 0.9119 | 0.9341 | 0.9591 | ||
| 15 dB | 0.9711 | 0.9721 | 0.9812 | ||
| 20 dB | 0.9855 | 0.9856 | 0.9878 | ||
| music | classical | - | 0.9868 | 0.9912 | 0.9931 |
| others | - | 0.9311 | 0.9435 | 0.9514 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, S.-I.; Lee, S. Improvement of Speech/Music Classification for 3GPP EVS Based on LSTM. Symmetry 2018, 10, 605. https://doi.org/10.3390/sym10110605
Kang S-I, Lee S. Improvement of Speech/Music Classification for 3GPP EVS Based on LSTM. Symmetry. 2018; 10(11):605. https://doi.org/10.3390/sym10110605
Chicago/Turabian StyleKang, Sang-Ick, and Sangmin Lee. 2018. "Improvement of Speech/Music Classification for 3GPP EVS Based on LSTM" Symmetry 10, no. 11: 605. https://doi.org/10.3390/sym10110605
APA StyleKang, S.-I., & Lee, S. (2018). Improvement of Speech/Music Classification for 3GPP EVS Based on LSTM. Symmetry, 10(11), 605. https://doi.org/10.3390/sym10110605