A Change Recommendation Approach Using Change Patterns of a Corresponding Test File


Abstract
:1. Introduction
2. Related Work
2.1. Association Rule Discovery and Change Recommendation
2.2. Coevolution of Source and Test Files
- Typically, it is thought that file-level change patterns are more appropriate for assisting software project developers’ tasks than module-level change patterns because a file is a basic task unit of developers in software project development.
- In a software project that has very few modules, file-level change patterns are more applicable than module-level change patterns.
3. Our Approach
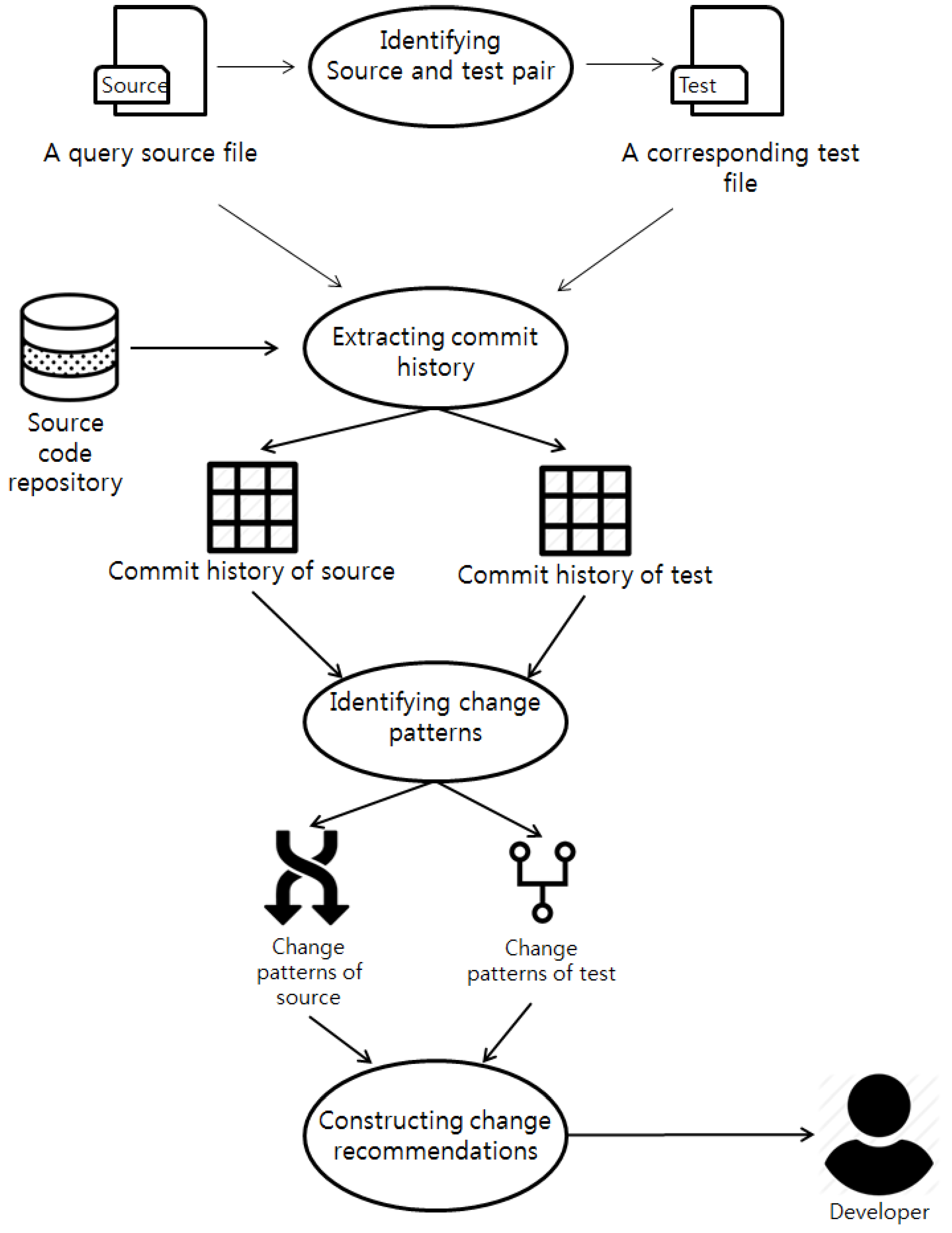
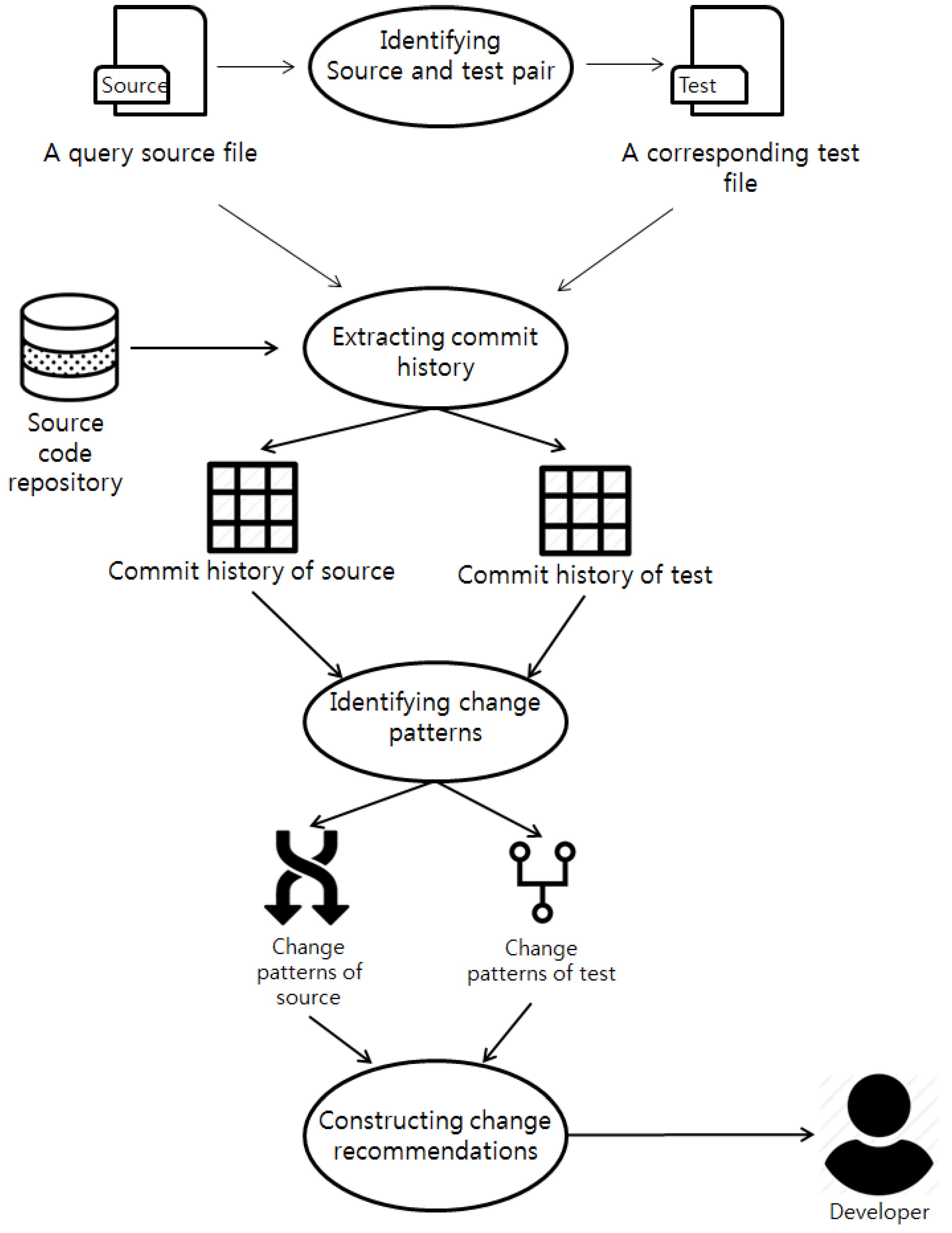
3.1. Overview of Proposed Change-Recommendation Method
3.2. Identifying Corresponding Test File
3.3. Extracting Commit Histories
3.4. Identifying Change Patterns
3.5. Constructing Change-Recommendation Set
4. Experiment
4.1. Experimental Data
4.2. Experimental Setting
4.3. Evaluation Metric
4.4. Result
5. Discussion, Implications, Limitations, and Conclusion
5.1. Discussion and Implications
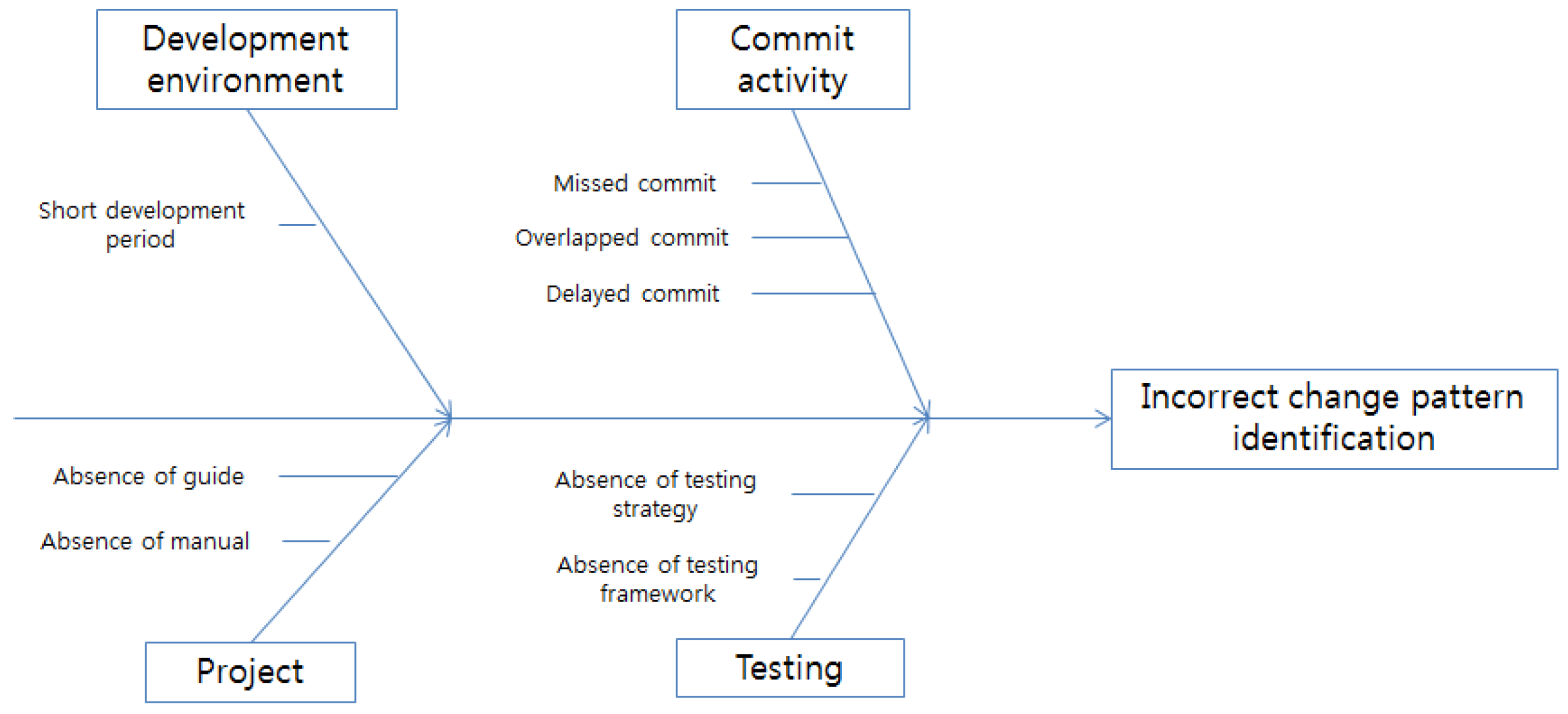
5.2. Limitation
5.3. Conclusion
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Lehman, M.M. On understanding laws, evolution, and conservation in the large-program life cycle. J. Syst. Softw. 1979, 1, 213–221. [Google Scholar] [CrossRef]
- Gall, H.; Hajek, K.; Jazayeri, M. Detection of Logical Coupling Based on Product Release History. In Proceedings of the International Conference on Software Maintenance, Bethesda, MD, USA, 16–19 March 1998; pp. 190–198. [Google Scholar]
- Fluri, B.; Gall, C.H.; Pinzger, M. Fine-Grained Analysis of Change Couplings. In Proceedings of the 5th IEEE International Workshop on Source Code Analysis and Manipulation, Budapest, Hungary, 30 September–1 October 2005; pp. 66–74. [Google Scholar]
- Poshyvanyk, D.; Marcus, A. The Conceptual Coupling Metrics for Object-Oriented Systems. In Proceedings of the 22nd IEEE International Conference on Software Maintenance, Philadelphia, PA, USA, 24–27 September 2006; pp. 469–478. [Google Scholar]
- Poshyvanyk, D.; Marcus, A.; Ferenc, R.; Gyimothy, T. Using information retrieval based coupling measures for impact analysis. Empir. Softw. Eng. 2009, 14, 5–32. [Google Scholar] [CrossRef]
- D’Ambros, M.; Lanza, M.; Robbes, R. On the Relationship Between Change Coupling and Software Defects. In Proceedings of the 16th Working Conference on Reverse Engineering, Lille, France, 13–16 October 2009; pp. 135–144. [Google Scholar]
- Mondal, M.; Roy, K.C.; Schneider, A.K. Insight into a Method Co-change Pattern to Identify Highly Coupled Methods: An Empirical Study. In Proceedings of the 21st IEEE International Conference on Program Comprehension, San Francisco, CA, USA, 20–21 May 2013; pp. 103–112. [Google Scholar]
- Rahman, S.M.; Roy, K.C.A. Change-Type Based Empirical Study on the Stability of Cloned Code. In Proceedings of the IEEE 14th International Working Conference on Source Code Analysis and Manipulation, Victoria, BC, Canada, 28–29 September 2014; pp. 31–40. [Google Scholar]
- Canfora, G.; Cerulo, L. Impact Analysis by Mining Software and Change Request Repositories. In Proceedings of the 11th IEEE International Software Metrics Symposium, Washington, DC, USA, 19–22 September 2005; pp. 29–37. [Google Scholar]
- Zanjani, M.B.; Swartzendruber, G.; Kagdi, H. Impact analysis of change requests on source code based on interaction and commit histories. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; pp. 162–171. [Google Scholar]
- Ying, T.T.A.; Murphy, C.G.; Ng, R.; Chu-Carroll, C.M. Predicting Source Code Changes by Mining Change History. IEEE Trans. Softw. Eng. 2004, 30, 574–586. [Google Scholar] [CrossRef]
- Zimmermann, T.; Weißgerber, P.; Diehl, S.; Zeller, A. Mining Version Histories to Guide Software Changes. IEEE Trans. Softw. Eng. 2005, 31, 429–445. [Google Scholar] [CrossRef]
- Dondero, M.R. Predicting Software Change Coupling. Ph.D. Thesis, The Faculty of Drexel University, Philadelphia, PA, USA, 2008. [Google Scholar]
- Robbes, R.; Pollet, D.; Lanza, M. Logical Coupling Based on Fine-Grained Change Information. In Proceedings of the 15th Working Conference on Reverse Engineering, Antwerp, Belgium, 15–18 October 2008; pp. 42–46. [Google Scholar]
- Canfora, G.; Ceccarelli, M.; Cerulo, L.; Penta, D.M. Using Multivariate Time Series and Association Rules to Detect Logical Change Coupling: An Empirical Study. In Proceedings of the IEEE International Conference on Software Maintenance, Timisoara, Romania, 12–18 September 2010; pp. 1–10. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; pp. 207–216. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Education: Boston, MA, USA, 2006. [Google Scholar]
- Siddiqui, T.; Ahmad, A. Data Mining Tools and Techniques for Mining Software Repositories: A Systematic Review. In Big Data Analytics; Aggarwal, V., Bhatnagar, V., Mishra, D., Eds.; Springer: Singapore, 2018; Volume 654, pp. 717–726. [Google Scholar]
- Rolfsnes, T.; Alesio, D.S.; Behjati, R.; Moonen, L.; Binkley, W.D. Generalizing the Analysis of Evolutionary Coupling for Software Change Impact Analysis. In Proceedings of the IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering, Suita, Japan, 14–18 March 2016; pp. 201–212. [Google Scholar]
- Rolfsnes, T.; Moonen, L.; Alesio, D.S.; Behjati, R.; Binkley, D. Improving Change Recommendation using Aggregated Association Rules. In Proceedings of the IEEE/ACM 13th Working Conference on Mining Software Repositories, Austin, TX, USA, 14–15 May 2016; pp. 73–84. [Google Scholar]
- Rolfsnes, T.; Moonen, L.; Di Alesio, S.; Behjati, R.; Binkley, D. Aggregating Association Rules to Improve Change Recommendation. Empir. Softw. Eng. 2018, 23, 987–1035. [Google Scholar] [CrossRef]
- Herzig, K.; Zeller, A. The impact of tangled code changes. In Proceedings of the 10th Working Conference on Mining Software Repositories, San Francisco, CA, USA, 18–19 May 2013; pp. 121–130. [Google Scholar]
- Kirinuki, H.; Higo, Y.; Hotta, K.; Kusumoto, S. Hey! are you committing tangled changes? In Proceedings of the 22nd International Conference on Program Comprehension, Hyderabad, India, 2–3 June 2014; pp. 262–265. [Google Scholar]
- Zaidman, A.; van Rompaey, B.; Demeyer, S.; van Deursen, A. Mining Software Repositories to Study Co-Evolution of Production & Test Code. In Proceedings of the 1st International Conference on Software Testing, Verification, and Validation, Lillehammer, Norway, 9–11 April 2008; pp. 220–229. [Google Scholar]
- van Rompaey, B.; Zaidman, A.; van Deursen, A.; Demeyer, S. Comparing the Co-Evolution of Production and Test Code in Open Source and Industrial Developer Test Processes through Repository Mining; Technical Report TUD-SERG-2008-034; Delft University of Technology, Software Engineering Research Group: Delft, The Netherlands, 2008. [Google Scholar]
- Lubsen, Z.; Zaidman, A.; Pinzger, M. Using Association Rules to Study the Co-evolution of Production & Test Code. In Proceedings of the 6th IEEE International Working Conference on Mining Software Repositories, Vancouver, BC, Canada, 16–17 May 2009; pp. 151–154. [Google Scholar]
- Zaidman, A.; van Rompaey, B.; van Deursen, A.; Demeyer, S. Studying the co-evolution of production and test code in open source and industrial developer test processes through repository mining. Empir. Softw. Eng. 2011, 16, 325–364. [Google Scholar] [CrossRef]
- Marsavina, C. Studying Fine-Grained Co-Evolution Patterns of Production and Test Code. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2014. [Google Scholar]
- van Rompaey, B.; Demeyer, S. Establishing Traceability Links between Unit Test Cases and Units under Test. In Proceedings of the 13th European Conference on Software Maintenance and Reengineering, Kaiserslautern, Germany, 24–27 March 2009; pp. 209–218. [Google Scholar]
- Qusef, A.; Bavota1, G.; Oliveto, R.; De Lucia1, A.; Binkley, D. SCOTCH: Test-to-Code Traceability using Slicing and Conceptual Coupling. In Proceedings of the 27th IEEE International Conference on Software Maintenance, Williamsburg, VI, USA, 25–30 September 2011; pp. 63–72. [Google Scholar]
- Nguyen, L.; Vo, B.; Nguyen, L.; Fournier-Viger, P.; Selamat, A. ETARM: An efficient top-k association rule mining algorithm. Appl. Intell. 2018, 48, 1148–1160. [Google Scholar] [CrossRef]
- Peng, M.; Sundararajan, V.; Williamson, T.; Minty, P.E.; Smith, C.T.; Doktorchik, T.A.C.; Quan, H. Exploration of association rule mining for coding consistency and completeness assessment in inpatient administrative health data. J. Biomed. Inform. 2018, 79, 41–47. [Google Scholar] [CrossRef] [PubMed]
- Fluri, B.; Gall, C.H. Classifying Change Types for Qualifying Change Couplings. In Proceedings of the International Conference on Program Comprehension, Athens, Greece, 14–16 June 2006; pp. 35–45. [Google Scholar]
- JGit—The Eclipse Foundation. Available online: https://www.eclipse.org/jgit/ (accessed on 19 October 2018).
- Lang—Home. Available online: https://commons.apache.org/proper/commons-lang/ (accessed on 19 October 2018).
- Math—Commons Math: The Apache Commons Mathematics Library. Available online: http://commons.apache.org/proper/commons-math/ (accessed on 19 October 2018).
- Maven—Welcome to Apache Maven. Available online: https://maven.apache.org/ (accessed on 19 October 2018).
- Apache Flink: Stateful Computations over Data Streams. Available online: https://flink.apache.org/ (accessed on 19 October 2018).
- Apache Wicket. Available online: https://wicket.apache.org/ (accessed on 19 October 2018).
- JUnit 5. Available online: https://junit.org/junit5/ (accessed on 19 October 2018).
- The World’s Leading Software Development Platform—GitHub. Available online: https://www.github.com (accessed on 19 October 2018).
- Kim, J.; Lee, E. Understanding Review Expertise of Developers: A Reviewer Recommendation Approach Based on Latent Dirichlet Allocation. Symmetry 2018, 10, 114. [Google Scholar] [CrossRef]
- Xia, X.; Loy, D.; Wang, X.; Zhou, B. Tag recommendation in software information sites. In Proceedings of the 10th Working Conference on Mining Software Repositories, San Francisco, CA, USA, 18–19 May 2013; pp. 287–296. [Google Scholar]
- Marung, U.; Theera-Umpon, N.; Auephanwiriyakul, S. Top-N Recommender Systems Using Genetic Algorithm-Based Visual-Clustering Methods. Symmetry 2016, 8, 54. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, M.; Li, X. An Interactive Personalized Recommendation System Using the Hybrid Algorithm Model. Symmetry 2017, 9, 216. [Google Scholar] [CrossRef]
- Zheg, J.; Li, D.; Arun Kumar, S. Group User Profile Modeling Based on Neural Word Embeddings in Social Networks. Symmetry 2018, 10, 435. [Google Scholar] [CrossRef]
- Lamkanfi, A.; Demeyer, S. Studying the Co-evolution of Application Code and Test Cases. In Proceedings of the 9th Belgian-Netherlands Software Evolution Seminar (BENEVOL 2010), Lille, France, 16 December 2010. [Google Scholar]

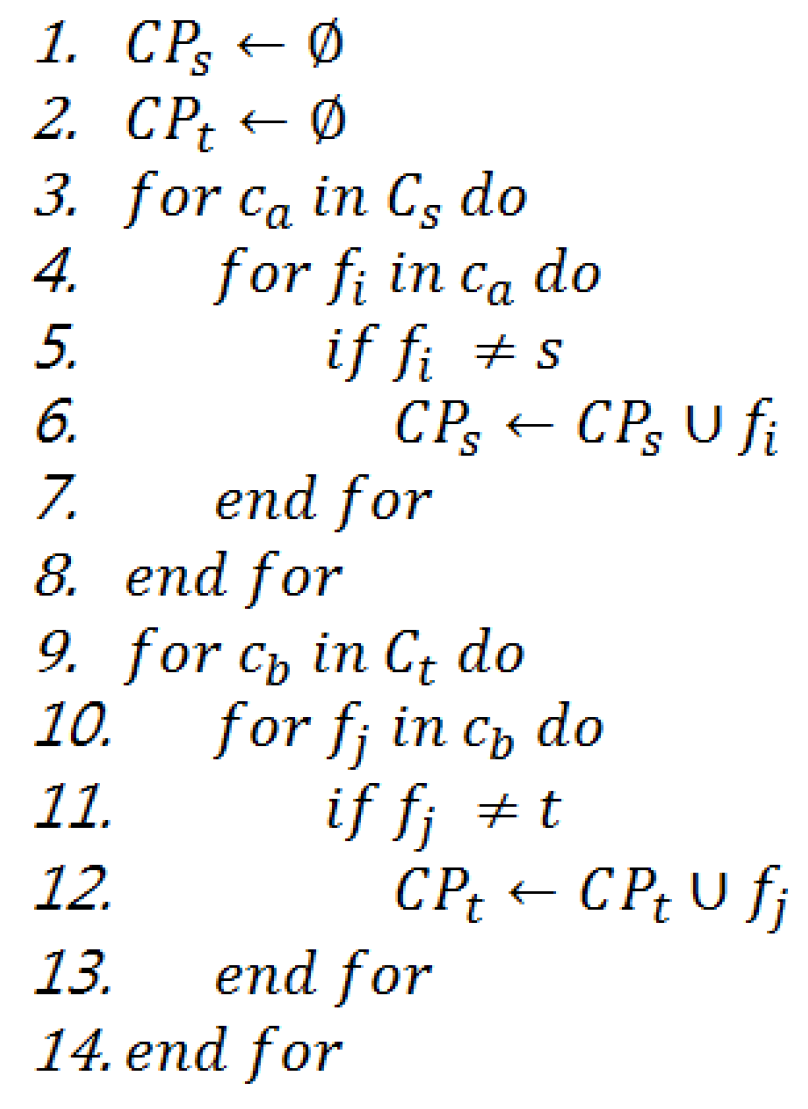

{kind=link}
{kind=link}
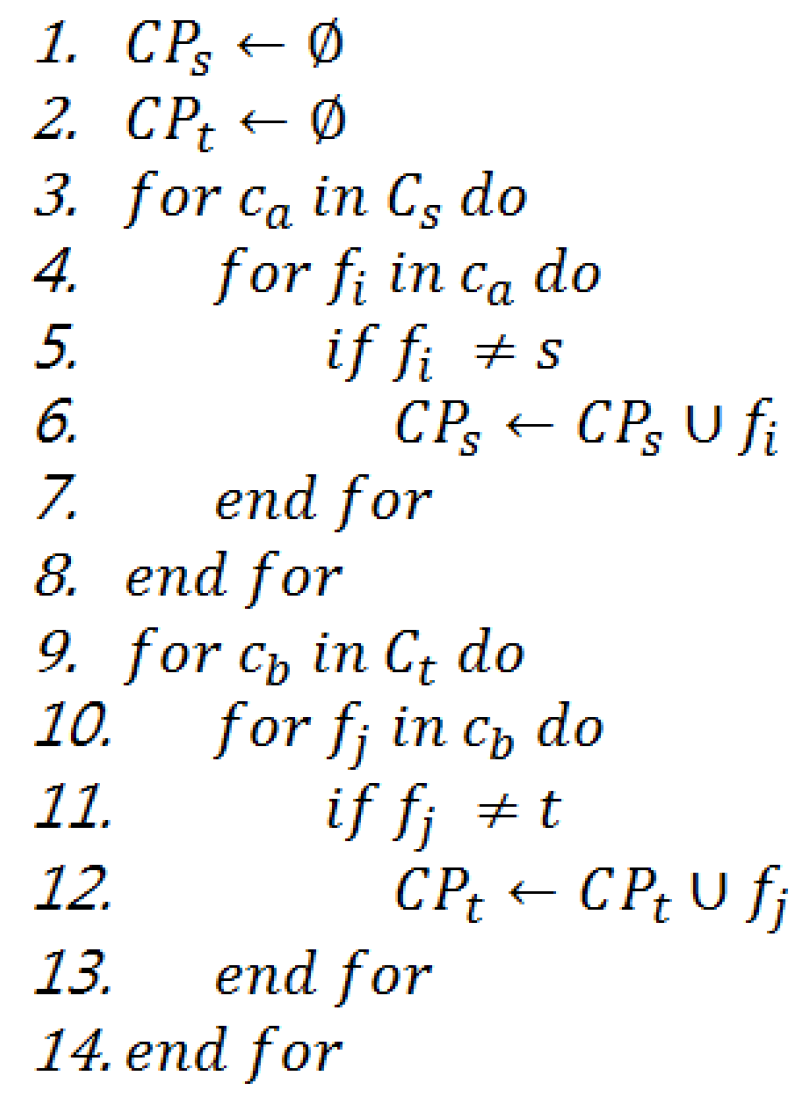{kind=link}
{kind=link}
| Project | Commit Period | #. Commits | #. Changed Source Files | #. Changed Test Files | #. Pairs of Source and Test | #. Related Commits |
|---|---|---|---|---|---|---|
| commons-lang | 2002-07-19 ~ 2018-03-11 | 5632 | 320 | 452 | 101 | 234 |
| commons-math | 2003-05-13 ~ 2018-03-18 | 7231 | 2954 | 1735 | 510 | 501 |
| Jgit | 2009-09-30 ~ 2018-03-28 | 5836 | 1037 | 437 | 192 | 1490 |
| Maven | 2003-09-02 ~ 2018-03-21 | 12,218 | 767 | 925 | 49 | 442 |
| Flink | 2010-12-16 ~ 2018-07-25 | 17,289 | 754 | 396 | 78 | 173 |
| Wicket | 2004-09-22 ~ 2018-07-25 | 32,366 | 1401 | 2455 | 167 | 659 |
| Project | Accuracy | ||
|---|---|---|---|
| Existing | Proposed | Improvement | |
| commons-lang | 20% | 82% | 62% |
| commons-math | 13% | 70% | 56% |
| JGit | 11% | 58% | 47% |
| Maven | 27% | 48% | 21% |
| Flink | 16% | 56% | 40% |
| Wicket | 16% | 50% | 34% |
| Avg. | 17% | 61% | 43% |
| Project | p-Value | |
|---|---|---|
| commons-lang | < | Reject |
| commons-math | < | Reject |
| JGit | < | Reject |
| Maven | < | Reject |
| Flink | < | Reject |
| Wicket | < | Reject |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Lee, E. A Change Recommendation Approach Using Change Patterns of a Corresponding Test File. Symmetry 2018, 10, 534. https://doi.org/10.3390/sym10110534
Kim J, Lee E. A Change Recommendation Approach Using Change Patterns of a Corresponding Test File. Symmetry. 2018; 10(11):534. https://doi.org/10.3390/sym10110534
Chicago/Turabian StyleKim, Jungil, and Eunjoo Lee. 2018. "A Change Recommendation Approach Using Change Patterns of a Corresponding Test File" Symmetry 10, no. 11: 534. https://doi.org/10.3390/sym10110534
APA StyleKim, J., & Lee, E. (2018). A Change Recommendation Approach Using Change Patterns of a Corresponding Test File. Symmetry, 10(11), 534. https://doi.org/10.3390/sym10110534