1. Introduction
The rapid development of computer technology and the Internet, has resulted in most information to now be stored electronically as digital data. Computer networks have replaced conventional communication methods, such as written letters, for information transmission between people. However, the Internet is an open platform. Without proper protection, anyone can steal, destroy, or modify transmitted data. Therefore, how to effectively claim copyrights and protect the integrity of digital data is a popular topic amongst researchers. One of the solutions to the aforementioned problems is copyright marking techniques.
According to various levels of application, copyright marking techniques [
1,
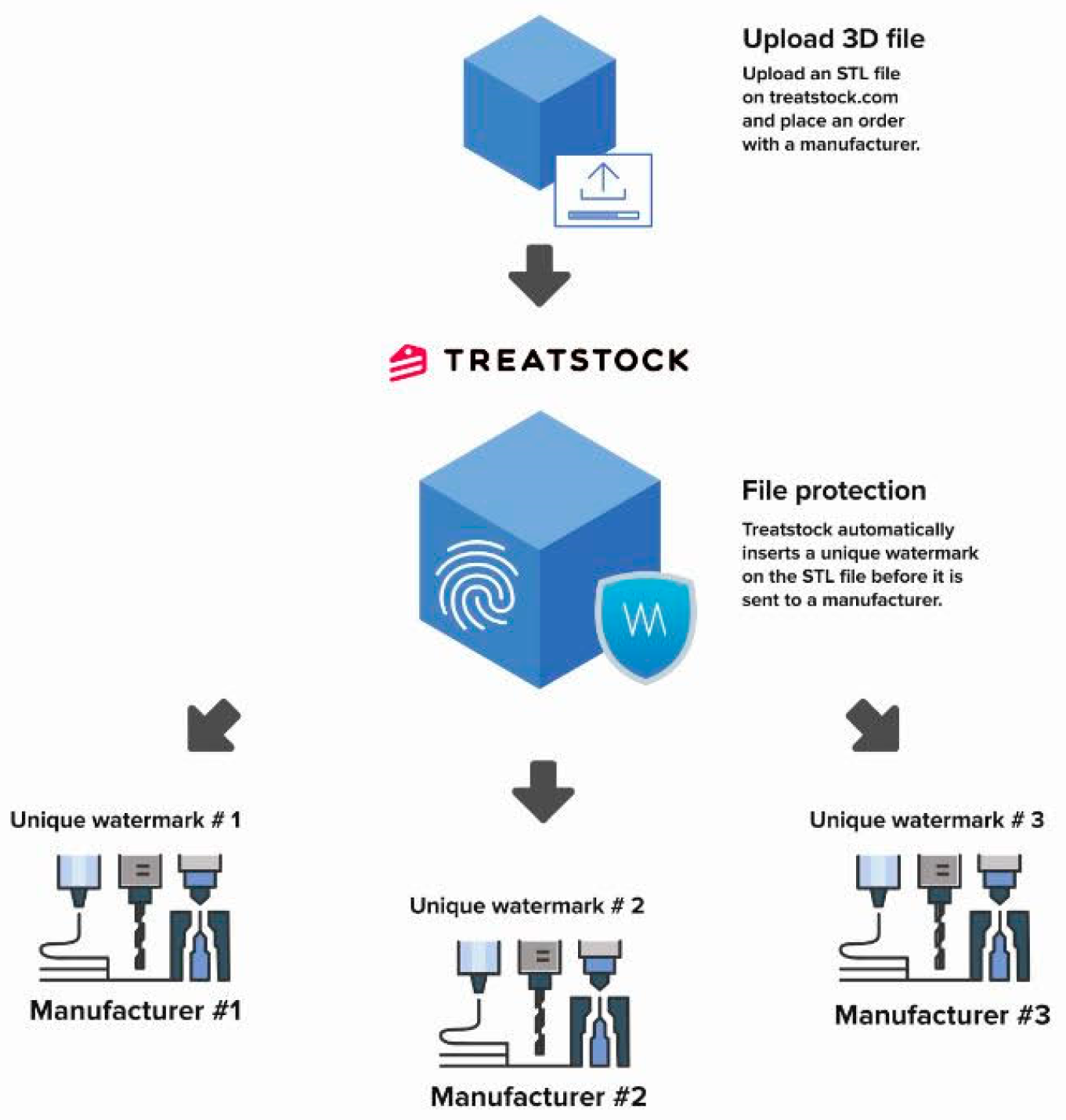
2] can be categorized into fragile watermarking and robust watermarking, according to the robustness of the embedded watermark. Fragile watermarking technique aims to protect the integrity of multimedia data through tamper detection; this technique can verify the integrity of multimedia content, even if the data have been only slightly modified. Robust watermarking technique is used to protect the copyright of multimedia content. It detects the copyright information embedded in multimedia data, when the data have been maliciously or non-maliciously attacked. The difference in practical scenarios between the above two techniques can be illustrated as follows. A 3D model designer creates a fantastic work and wants to share and disperse it all over the world. Before this, the designer should adopt ‘robust’ watermarking algorithms to embed their confidential personal information into the 3D model. Thus, the designer can claim rightful ownership when an adversary steals or plagiarizes the work. In another scenario, a designer completes a 3D model with all the functionality requested by the customer and then sends it out for their approval. The functionality of the 3D model may be compromised, even after inadvertent modification by a third party during transmission. Therefore, the designer can adopt ‘fragile’ watermarking algorithms to embed the authentication code into the 3D model in advance, for integrity checking and tamper detection. Relating to industrial applications for 3D copyright protection, Treatstock introduced the ‘Watermark3D’ software solution [
3] for 3D printable files. This software can allow creators to adopt different watermarks to files given to different users. Thus, the illegal user can be detected by extracted watermark.
Figure 1 shows its system flowchart.
Widely used in digital images and videos [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15], fragile watermarking technique has been a popular research topic, and numerous studies have obtained favorable results. The research and development of 3D model protection mechanisms, which have numerous applications, have gradually received scholarly attention. Based on the size of the tampered area, fragile watermarking technique can be categorized into two types: Region-based and Vertex-based. Region-based fragile watermarking technique detects tampered areas relatively loosely, and the detected area may contain vertices that have not been tampered with; however, this technique effectively detects the tampered topology. In contrast, vertex-based fragile watermarking technique accurately detects the tampered vertices but cannot detect changes in topology because of the limitation of the algorithm used.
According to the latest survey [
16] and our understanding about the 3D authentication algorithm, there are currently eight vertex-based 3D model authentication algorithms [
17,
18,
19,
20,
21,
22,
23,
24], which are implemented in the spatial domain. Despite these algorithms obtaining favorable experimental results, there is still room for improvement. Some techniques ignore geometric operations, such as translation, rotation, and uniform scaling, which are common for 3D models, and this prevents the authentication code from being correctly extracted. Furthermore, the length of the authentication code used in some approaches is insufficient, resulting in a high rate of false alarms after a vertex has been tampered with. Finally, some technologies do not support blind extraction schemes, limiting their practicality.
Therefore, this paper proposes a vertex-based 3D model authentication algorithm based on spatial subdivision and provides solutions to the aforementioned deficiencies. First, we use a binary space partitioning tree (BSP tree) and an embedding threshold to decompose the bounding volume of the 3D model into numerous subspaces, and then we employ a tree structure to encode each vertex into a series of binary data, denoted as its authentication code. Subsequently, we use the secret key to determine the reference vertex corresponding to each processing vertex. Finally, the position of the reference vertices in the subspace is altered, and the encoding result of the processing vertex is embedded to complete authentication code embedding, enabling self-recovery. Compared with previously developed algorithms, the proposed technique has high embedding capacity and ensures highly robust authentication codes. In addition, this technique effectively and accurately detects tampered areas, executing self-recovery to restore vertex values. The proposed technique can also be applied to polygonal models and point-cloud models, to implement new concepts in the field of 3D model authentication.
The remainder of the paper is organized as follows:
Section 2 introduces eight vertex-based 3D model authentication algorithms implemented in the spatial domain. This section also illustrates Tsai et al.’s tree-based information hiding algorithm [
25] for 3D models.
Section 3 details the method proposed by this study.
Section 4 presents the experimental results and discussion; and
Section 5 presents the conclusions and future research directions.
3. The Proposed Algorithm
This paper extends the information hiding algorithm of the 3D model based on a BSP tree proposed by Tsai et al., to an authentication algorithm. In the original algorithm, the visiting process of the tree structure exactly represents the encoding result of each vertex. Given a bounding volume equivalent to the original model in size, the vertex positions can be located using the aforementioned encoding results. When the threshold value in the subdivision process is lower, the vertex can be accurately located. However, the threshold value, which is limited by the number of decimal places represented by the vertex coordinate value in the file, should not be too low; otherwise, the accurate secret message cannot be extracted.
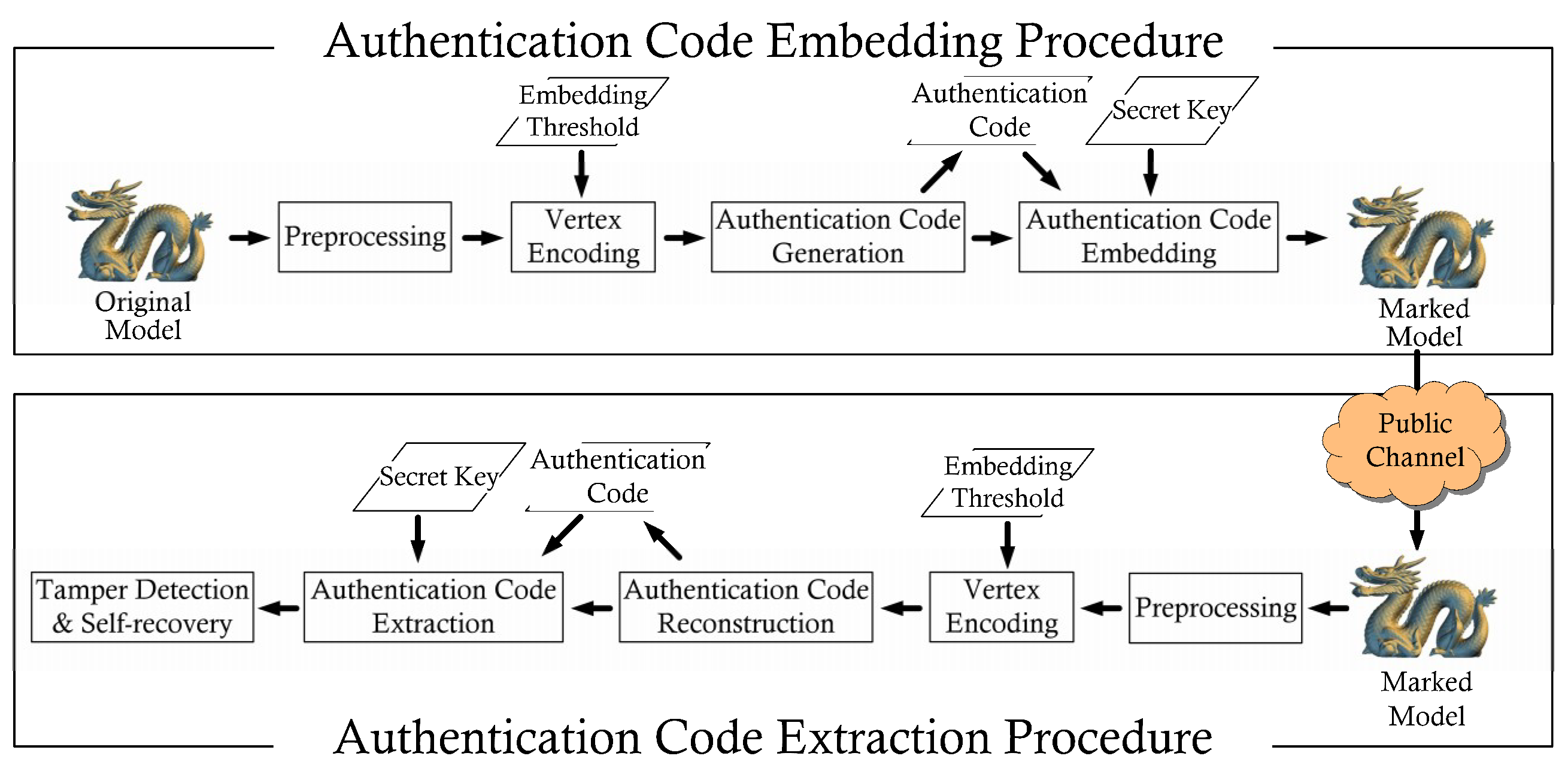
The proposed approach is divided into two procedures: Authentication code embedding and extraction (
Figure 3). The authentication code embedding procedure comprises four processes: Preprocessing, vertex encoding, authentication code generation, and authentication code embedding. The authentication code extraction procedure is composed of five processes: Preprocessing, vertex encoding, authentication code reconstruction, authentication code extraction, and tamper detection and self-recovery.
3.1. Preprocessing Process
In this process, the 3D model is first read to obtain the related information of the original model. Let the number of vertices be
VN and the number of polygons be
. After reading the information of vertex
and polygon
, a bounding volume of the 3D model is established on the basis of Cartesian coordinates. The magnitude of the bounding volume,
, is determined using the distance between the boundary points
and
as follows:
3.2. Vertex Encoding Process
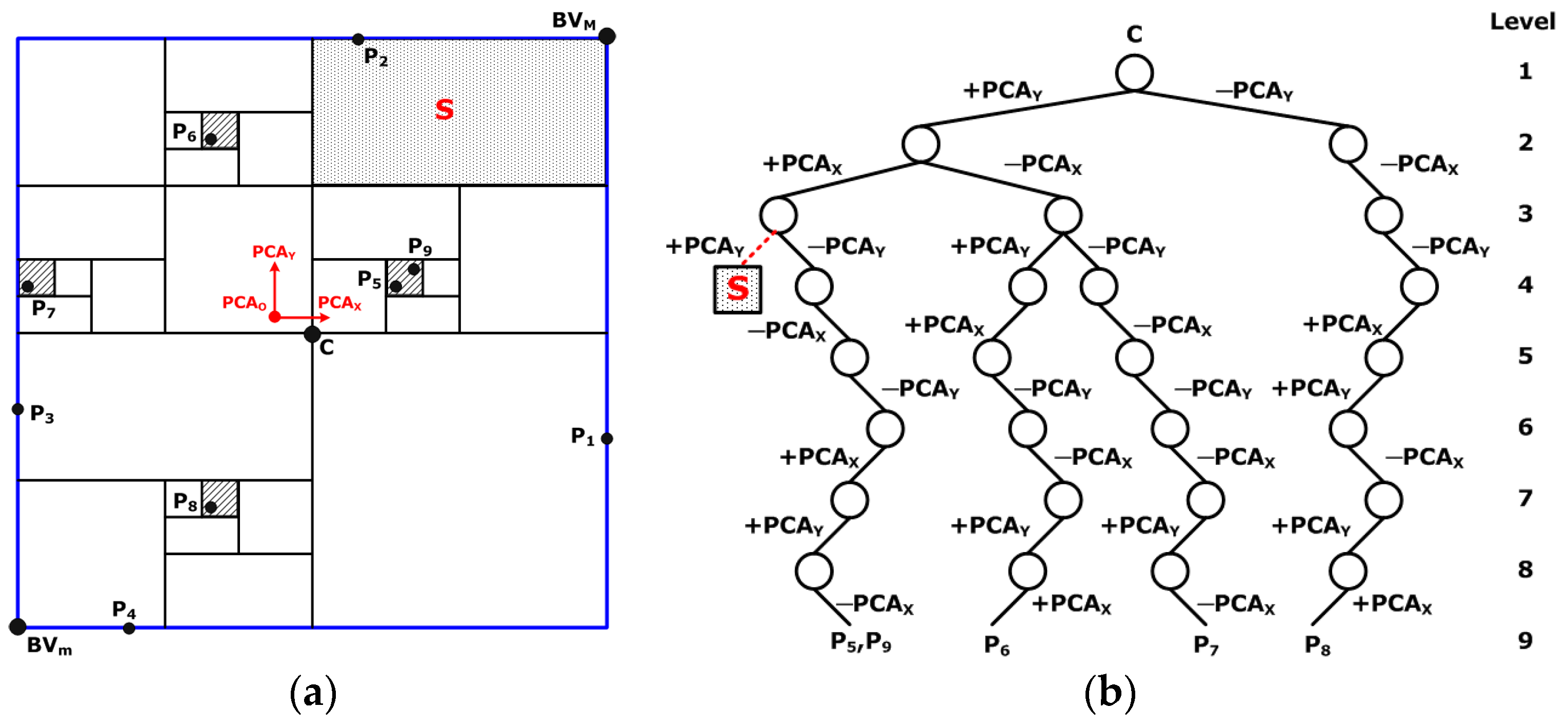
We use a BSP tree with an embedding threshold to decompose the bounding volume into numerous subspaces according to the distribution of vertices, and each vertex must fall within a certain subspace. Using the tree structure’s visiting process, each vertex can be encoded. Assuming the leftward visit is 0 and the rightward visit is 1, taking vertices
and
in
Figure 2 as examples,
is encoded as 00111001 and
is encoded as 11100100.
3.3. Authentication Code Generation Process
This process converts the aforementioned encoding result into three weights , and , between 0 and 1. Each weight will be used for each corresponding coordinate axis in the authentication code embedding process. First, three-bit data is grabbed each time from the encoding result to generate a decimal digit. Thus, a string of decimal digits is generated. Second, we break the above number into three groups, working from left to right, and insufficient places are filled with 0. Finally, three weights are obtained by converting the number of each group into decimals between 0 and 1. Taking the encoding results of vertices and from the previous process as examples, the encoding result of becomes (00101)2 = (11)10, generating the decimals 0.1, 0.6, and 0.1; and the encoding result of is converted to (11100)2 = (70)10, producing the decimals 0.7, 0.1, and 0.0.
3.4. Authentication Code Embedding Process
To be able to execute self-recovery in the authentication process, a secret key is used to obtain the reference vertex corresponding to each embedded vertex; in addition to increasing the security and privacy of the authentication code, this enables the technique to support self-recovery. For each embedding vertex
, its authentication code is obtained in the previous process, and the boundary vertex
of the subspace in which the corresponding reference vertex
is located can be found. The authentication code is embedded into the reference vertex, as indicated in the following:
where
is the generated data-embedded reference vertex which carries the authentication code information, and
is the length, width, and height of the subspace in which
is located.
The procedure presented in the flowchart (
Figure 3) should be followed when the integrity of a model must be verified. First, the information related to the marked model is obtained in the preprocessing process, and the encoding result of each vertex is extracted during the vertex encoding process. Then, in the authentication code reconstruction process, the authentication code of a vertex is reconstructed using the scheme illustrated in
Section 3.3. Whether the vertex has been tampered with can be determined by comparing the three weights derived from the subspace where the reference vertex is located. If a vertex is confirmed to have been tampered with, its authentication code is extracted from its corresponding reference vertex, and the BSP tree is used to locate the vertex in a certain subspace to complete self-recovery.
4. Experimental Evaluations
This section presents the results of experiments using the proposed method to demonstrate its feasibility. The information related to the 3D models used in this experiment and the visual effects of the models are shown in
Figure 4. Experiments were performed using the C programming language, on a personal computer equipped with an Intel Core i7 3.40 GHz processor and 32 GB of memory. The normalized root-mean-square error was used to calculate the level of distortion between the original model and the model with authentication codes, and it was calculated as follows:
where
and
represent the
i-th vertex in the original model and embedded model, respectively.
First, the experimental results were presented, consisting of the embedding capacity and the quality of the models with the authentication code embedded. The visual effects of the data-embedded models under various embedding thresholds were then detailed. We also presented the experimental results for tamper detection, to demonstrate the feasibility of our proposed algorithm. Finally, the feasibility of the proposed technique was confirmed through comparison between currently available methods and the proposed method.
Table 1 and
Table 2 list the encoding lengths for each model under various embedding thresholds, and the model distortion after authentication code embedding, respectively.
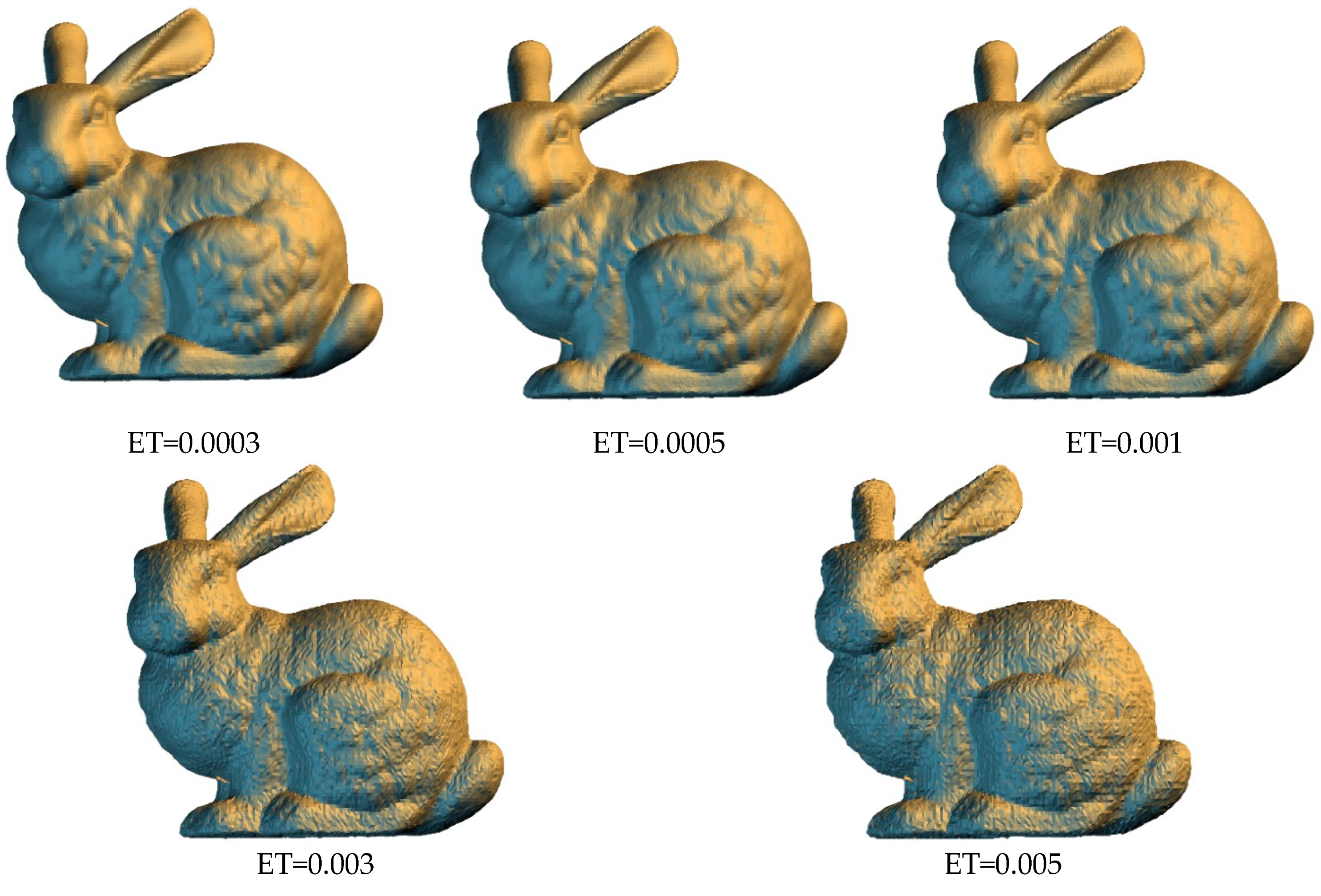
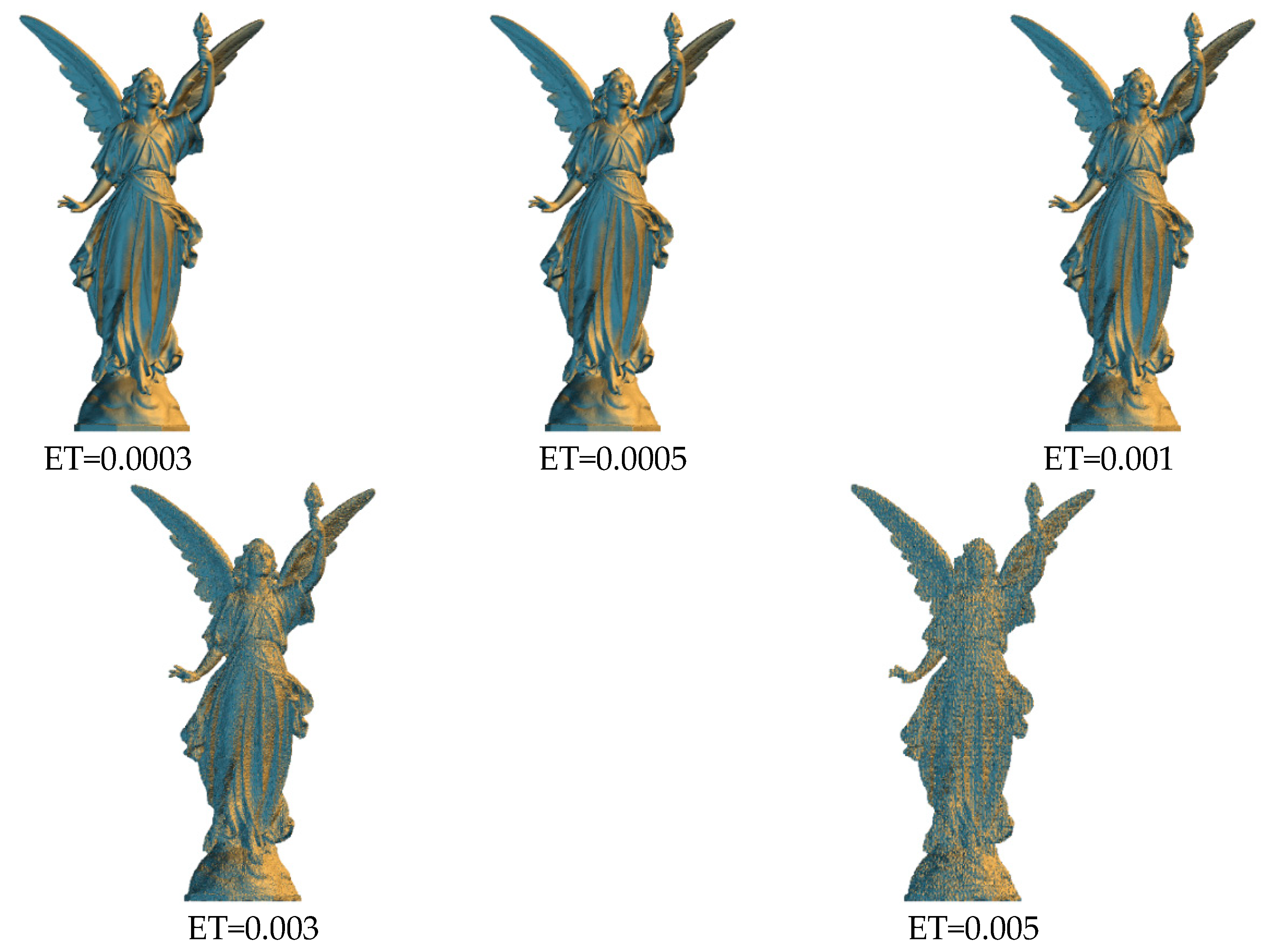
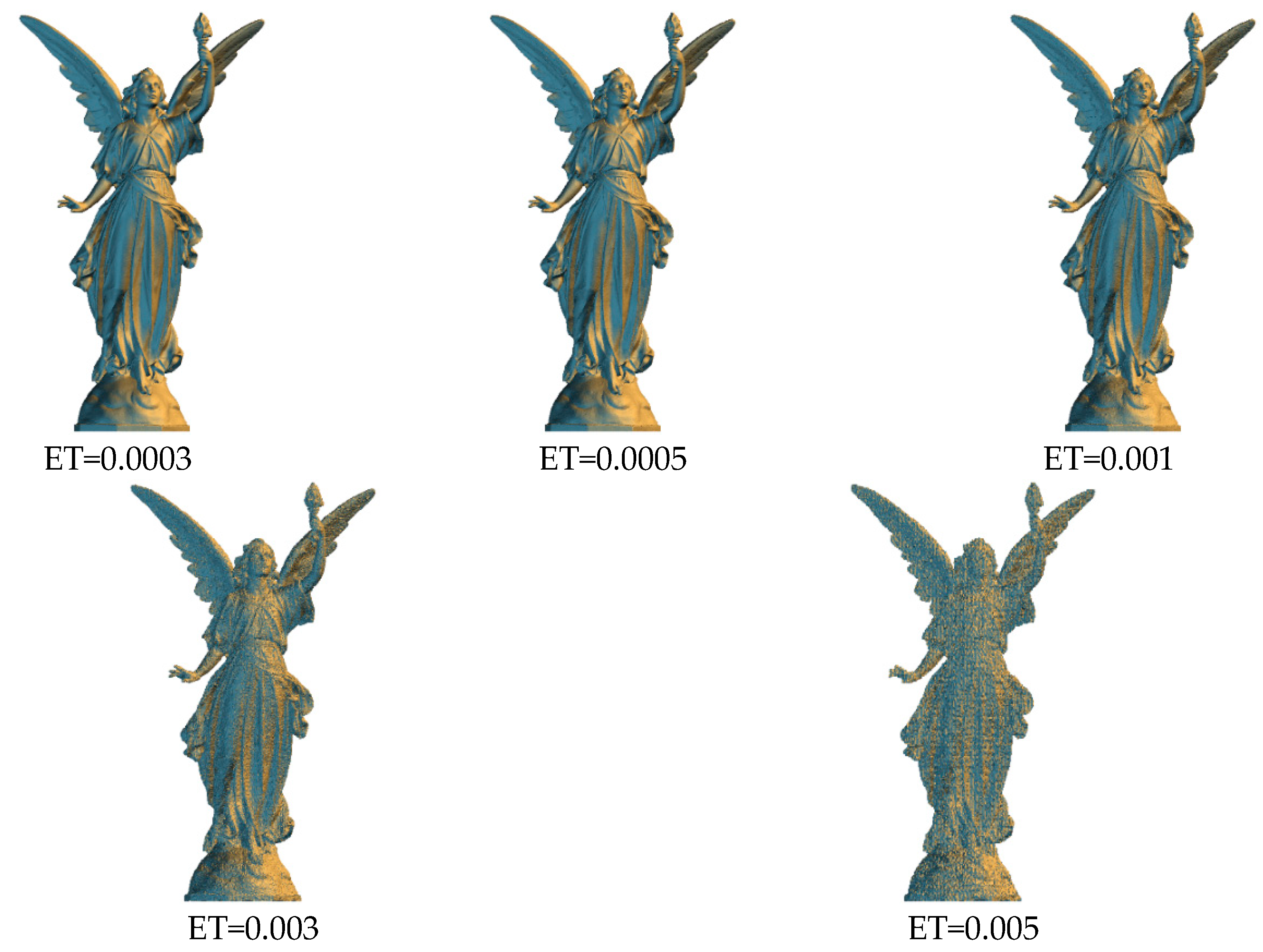
Figure 5,
Figure 6,
Figure 7 and
Figure 8 shows the visual effects for each model with the authentication code embedded under various thresholds. When a lower embedding threshold was employed, the subspaces were smaller, the tree structure was larger, the encoding length of each vertex was higher, and the small subspace size limited the modification of vertex coordinates, resulting in a lower level of distortion. Given the space subdivision operation was related to the diagonal length ratio of the bounding volume, the encoding length of the vertices for each model was similar. The code length of each vertex was 24 bits when the threshold was 0.005, and 36 bits when the threshold was 0.0003. The model distortion decreased from 0.166% to 0.009% as the threshold value decreased.
Table 3 shows the average number of detected suspicious vertices, for each model, under different embedding thresholds, for 100 iterations. In each iteration, we randomly added or subtracted 0.01% of the diagonal length of the bounding volume of the test model from x, y, and z coordinate value of 50 vertices separately. The proposed algorithm was then used to perform tamper detection and self-recovery operation. The experimental results showed that all modified vertices could be detected. However, the modified vertex may affect the construction results of the BSP tree, resulting in unaltered vertices with different encoding results. Fortunately, the entire tree structure can be entirely recovered after moving each tampered vertex to its original located subspace. With the increasing value of the embedding threshold, the varied range of the modified vertex may be limited within the same subspace, and the tree structure is not affected. Thus, the number of suspicious vertices is decreased. The only problem is that the boundary vertices are the key to successfully construct the same tree structure and cannot be modified. Otherwise, the algorithm fails to perform the following processes.
Finally,
Table 4 is a comparison of the proposed method in this study, with currently available methods. The embedding methods for current algorithms can be categorized into four groups, including quantization index modification (QIM), coefficient modification (CM), hamming code (HC), and least-significant-bit substitution (LSBs). Our proposed algorithm was based on message-digit conversion (MC). LSBs-based algorithms directly replace the coordinate value by authentication code. Therefore, except Reference [
23] proposed in the spherical coordinate system, common similarity transformation attacks can terminate the algorithm execution. From the aspect of embedding capacity, although the technique proposed by Wang et al. [
18] had the highest embedding capacity, this technique stored vertex coordinates values using the IEEE single-precision floating-point format, whereas our technique presented the numerical values in a 3D model to six decimal places and had an embedding capacity of 36 bits. Wang et al.’s algorithm [
24] was also performed on the 3D model with binary representation; their embedding capacity may be similar to ours. In addition, the proposed approach controlled the encoding length of vertices by setting the threshold, resulting in an adaptive embedding capacity, and the model distortion could also be controlled by the threshold. QIM-based algorithms [
17,
18,
20] can also have the capability of controllable distortion with settable quantization steps. Finally, the bounding volume used by the BSP tree was produced by the boundary vertices. To maintain the same bounding volume, six or fewer vertices cannot be embedded with messages.
5. Conclusions and Future Studies
This study extended Tsai et al.’s tree-based 3D information hiding algorithm to a 3D model authentication algorithm. In the framework of the BSP tree, the tree traversal result of each vertex can be the encoding result of the vertex. With the absence of vertex coordinate values, the encoding result can be used to locate the vertex in a certain subspace in the 3D space; where the vertex can be accurately located when the encoding result is sufficiently long. Since this technique does not require the connection attributes between vertices, it can be applied to polygonal models and point-cloud models. In addition to using the BSP tree technique, we employed the message-digit conversion mechanism to embed the encoding result into vertices and use a secret key to determine the reference vertex corresponding to each embedded vertex, for effectively performing self-recovery. The experimental results indicated that the proposed method had high embedding capacity and a relatively low false alarm rate. The 3D models with authentication codes embedded presented a decent visual effect, proving that the proposed algorithm was feasible.
In the future, we will continue to explore and enhance the robustness of authentication coding, so that it can resist both non-malicious attacks (e.g., rotation, translation, and scaling) and malicious attacks, such as vertex deletion. In addition, we will discuss variations of the vertex encoding and authentication code embedding procedure to embed more authentication code. Finally, it is worth investigating how to determine the threshold value and the embedding order of multiple vertices in the same subspace.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}