
Forest Fire Risk Prediction in South Korea Using Google Earth Engine: Comparison of Machine Learning Models


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. GEE
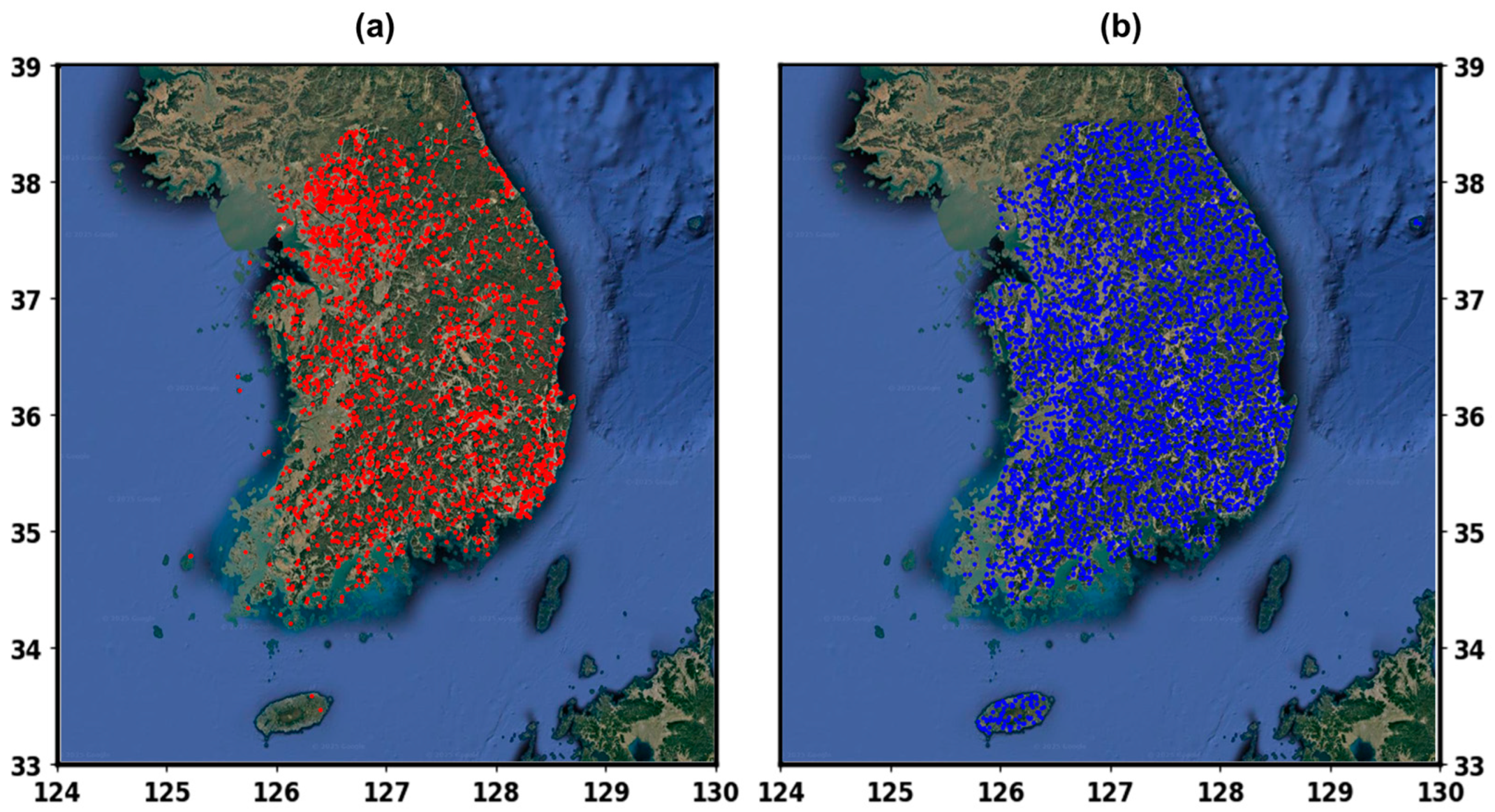
2.3. Forest Fire Dataset
2.4. Environmental Variables
2.5. Methods
- TP (true positive): actual fire events correctly predicted as fire
- TN (true negative): actual non-fire events correctly predicted as non-fire events
- FP (false positive): actual non-fire events mistakenly predicted as fire
- FN (false negative): actual fire events mistakenly predicted as non-fire
3. Results
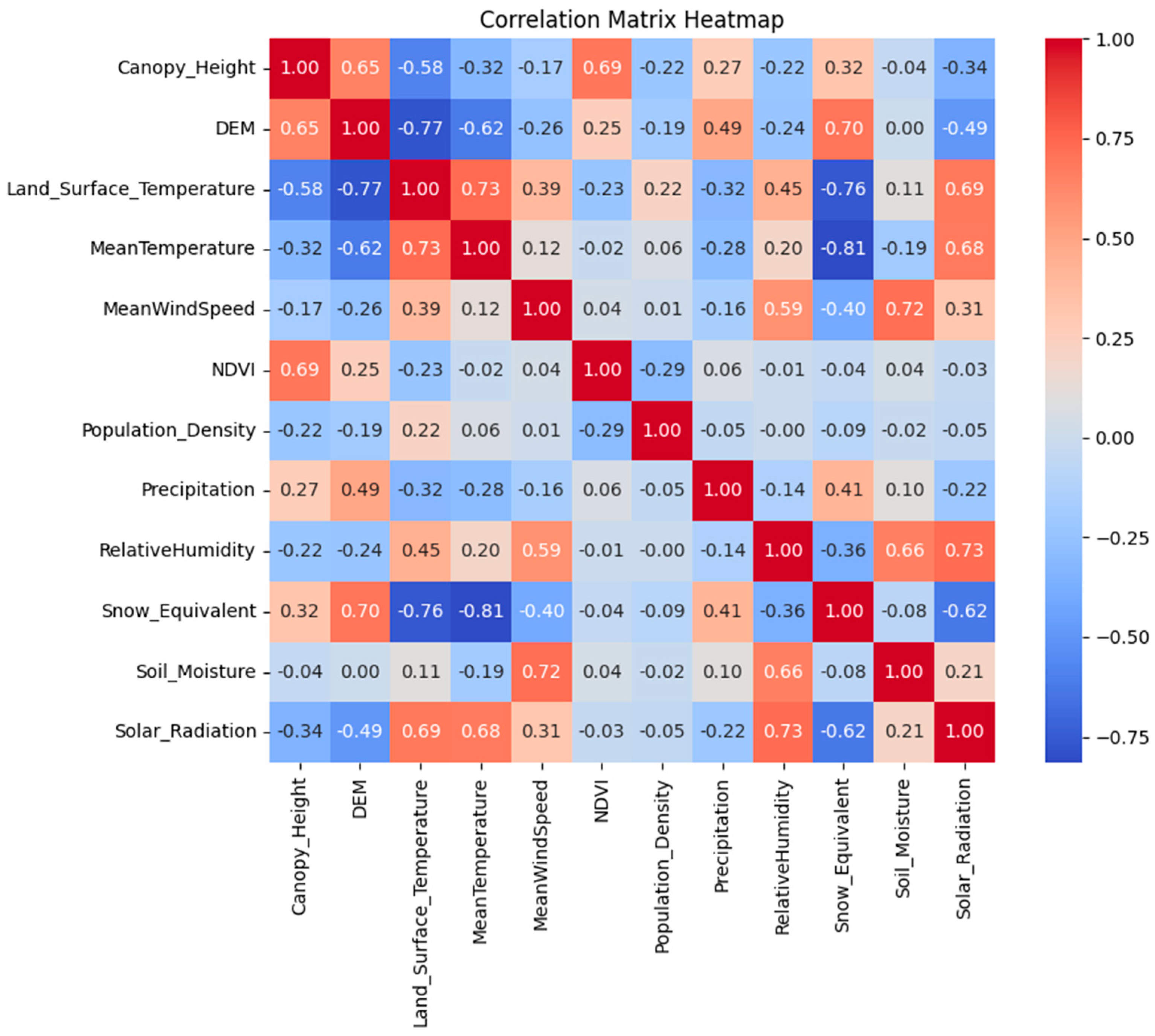
3.1. Removal of Highly Collinear Features
3.2. Model Prediction Performance Visualization
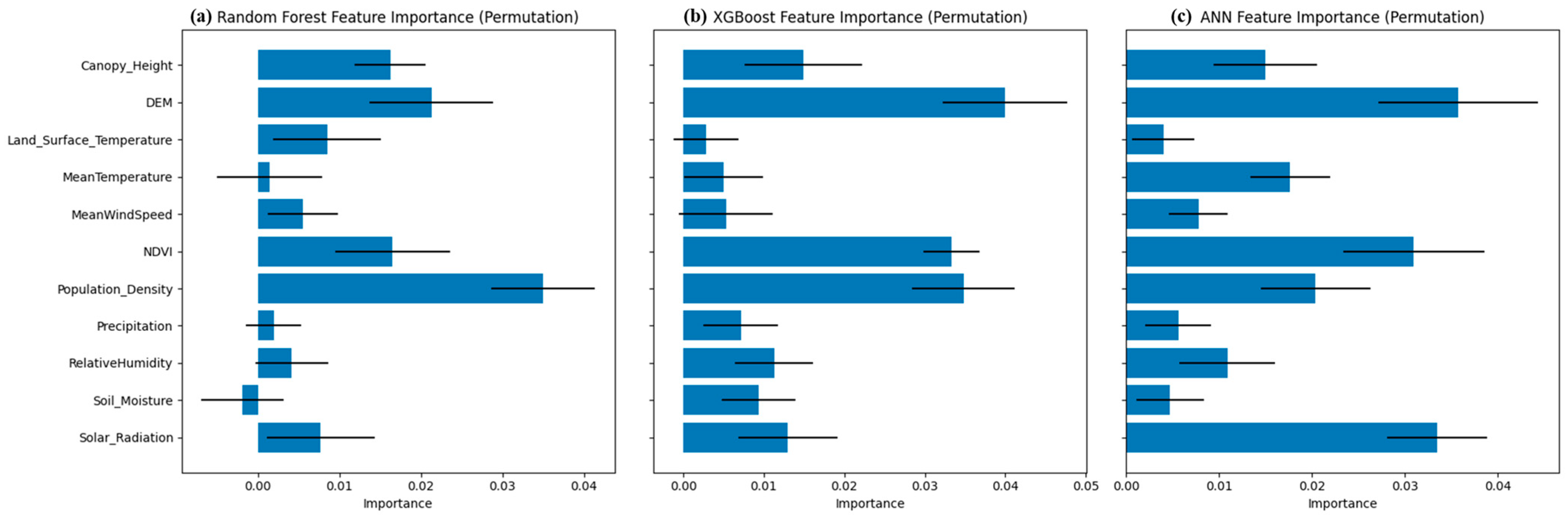
3.3. Permutation Feature Importance
3.4. Confusion Matrix and F1 Score Evaluation
3.5. ROC Curve and AUC Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Baccini, A.; Walker, W.; Carvalho, L.; Farina, M.; Sulla-Menashe, D.; Houghton, R.A. Tropical forests are a net carbon source based on aboveground measurements of gain and loss. Science 2017, 358, 230–234. [Google Scholar] [CrossRef]
- Scholes, R.J.; Archer, S.R. Tree-Grass Interactions in Savannas. Annu. Rev. Ecol. Syst. 1997, 28, 517–544. [Google Scholar] [CrossRef]
- Bowman, D.M.J.S.; Balch, J.K.; Artaxo, P.; Bond, W.J.; Carlson, J.M.; Cochrane, M.A.; D’Antonio, C.M.; DeFries, R.S.; Doyle, J.C.; Harrison, S.P.; et al. Fire in the Earth System. Science 2009, 324, 481–484. [Google Scholar] [CrossRef]
- Liu, Y.; Stanturf, J.; Goodrick, S. Trends in global wildfire potential in a changing climate. For. Ecol. Manag. 2010, 259, 685–697. [Google Scholar] [CrossRef]
- Calkin, D.E.; Cohen, J.D.; Finney, M.A.; Thompson, M.P. How risk management can prevent future wildfire disasters in the wildland-urban interface. Proc. Natl. Acad. Sci. USA 2013, 111, 746–751. [Google Scholar] [CrossRef]
- Ager, A.A.; Vaillant, N.M.; Finney, M.A. A comparison of landscape fuel treatment strategies to mitigate wildland fire risk in the urban interface and preserve old forest structure. For. Ecol. Manag. 2010, 259, 1556–1570. [Google Scholar] [CrossRef]
- Jones, M.W.; Smith, A.; Betts, R.; Canadell, J.G.; Prentice, I.C.; Le Quéré, C. Climate Change Increases the Risk of Wildfires. Science-Brief.org, 14 January 2020. Available online: https://sciencebrief.org/briefs/wildfires (accessed on 15 April 2025).
- Jolly, W.M.; Cochrane, M.A.; Freeborn, P.H.; Holden, Z.A.; Brown, T.J.; Williamson, G.J.; Bowman, D.M.J.S. Climate-induced variations in global wildfire danger from 1979 to 2013. Nat. Commun. 2015, 6, 7537. [Google Scholar] [CrossRef] [PubMed]
- Godfree, R.C.; Knerr, N.; Encinas-Viso, F.; Albrecht, D.; Bush, D.; Cargill, D.C.; Clements, M.; Gueidan, C.; Guja, L.K.; Harwood, T.; et al. Implications of the 2019–2020 megafires for the biogeography and conservation of Australian vegetation. Nat. Commun. 2021, 12, 1023. [Google Scholar] [CrossRef]
- Boulanger, Y.; Arseneault, D.; Bélisle, A.C.; Bergeron, Y.; Boucher, J.; Boucher, Y.; Danneyrolles, V.; Erni, S.; Gachon, P.; Girardin, M.P.; et al. The 2023 wildfire season in Québec: An overview of extreme conditions, impacts, lessons learned, and considerations for the future. Can. J. For. Res. 2024, 55, 1–21. [Google Scholar] [CrossRef]
- Sarris, D.; Christopoulou, A.; Angelonidi, E.; Koutsias, N.; Fulé, P.Z.; Arianoutsou, M. Increasing extremes of heat and drought associated with recent severe wildfires in southern Greece. Reg. Environ. Change 2014, 14, 1257–1268. [Google Scholar] [CrossRef]
- Abatzoglou, J.T.; Williams, A.P. Impact of anthropogenic climate change on wildfire across western US forests. Proc. Natl. Acad. Sci. USA 2016, 113, 11770–11775. [Google Scholar] [CrossRef] [PubMed]
- Dennison, P.E.; Brewer, S.C.; Arnold, J.D.; Moritz, M.A. Large wildfire trends in the western United States, 1984–2011. Geophys. Res. Lett. 2014, 41, 2928–2933. [Google Scholar] [CrossRef]
- Flannigan, M.D.; Stocks, B.J.; Wotton, B.M. Climate change and forest fires. Sci. Total Environ. 2000, 262, 221–229. [Google Scholar] [CrossRef] [PubMed]
- Kouassi, J.-L.; Wandan, N.; Mbow, C. Predictive modeling of wildfire occurrence and damage in a tropical savanna ecosystem of West Africa. Fire 2020, 3, 42. [Google Scholar] [CrossRef]
- Syphard, A.D.; Radeloff, V.C.; Keeley, J.E.; Hawbaker, T.J.; Clayton, M.K.; Stewart, S.I.; Hammer, R.B. Human influence on California fire regimes. Ecol. Appl. 2007, 17, 1388–1402. [Google Scholar] [CrossRef]
- Modugno, S.; Balzter, H.; Cole, B.; Borrelli, P. Mapping regional patterns of large forest fires in Wildland–Urban Interface areas in Europe. J. Environ. Manag. 2016, 172, 112–126. [Google Scholar] [CrossRef] [PubMed]
- Martell, D.L. A review of operational research studies in forest fire management. Can. J. For. Res. 1982, 12, 119–140. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Van Wagner, C.E. Development and Structure of the Canadian Forest Fire Weather Index System; Canadian Forestry Service: Ottawa, ON, Canada, 1987. [Google Scholar]
- Taylor, S.W.; Alexander, M.E. Science, technology, and human factors in fire danger rating: The Canadian experience. Int. J. Wildland Fire 2006, 15, 121–135. [Google Scholar] [CrossRef]
- Chuvieco, E.; Congalton, R.G. Application of remote sensing and geographic information systems to forest fire hazard mapping. Remote Sens. Environ. 1989, 29, 147–159. [Google Scholar] [CrossRef]
- Suryabhagavan, K.V.; Alemu, M.; Balakrishnan, M. GIS-based multi-criteria decision analysis for forest fire susceptibility mapping: A case study in Harenna forest, southwestern Ethiopia. Trop. Ecol. 2016, 57, 33–43. [Google Scholar]
- Guo, F.; Zhang, L.; Jin, S.; Tigabu, M.; Su, Z.; Wang, W. Modeling anthropogenic fire occurrence in the boreal forest of China using logistic regression and random forests. Forests 2016, 7, 250. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Guo, H.; Li, Y.; Shang, J.; Gu, M.; Huang, Y.; Gong, B. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Kanwal, R.; Rafaqat, W.; Iqbal, M.; Weiguo, S. Data-driven approaches for wildfire mapping and prediction assessment using a convolutional neural network (CNN). Remote Sens. 2023, 15, 5099. [Google Scholar] [CrossRef]
- Chuvieco, E.; Aguado, I.; Salas, J.; García, M.; Yebra, M.; Oliva, P. Satellite remote sensing contributions to wildland fire science and management. Curr. For. Rep. 2020, 6, 81–96. [Google Scholar] [CrossRef]
- Tian, L.; Wu, X.; Tao, Y.; Li, M.; Qian, C.; Liao, L.; Fu, W. Review of remote sensing-based methods for forest aboveground biomass estimation: Progress, challenges, and prospects. Forests 2023, 14, 1086. [Google Scholar] [CrossRef]
- Sivrikaya, F.; Günlü, A.; Küçük, Ö.; Ürker, O. Forest fire risk mapping with Landsat 8 OLI images: Evaluation of the potential use of vegetation indices. Ecol. Inform. 2024, 79, 102461. [Google Scholar] [CrossRef]
- Peña-Molina, E.; Moya, D.; Marino, E.; Tomé, J.L.; Fajardo-Cantos, Á.; González-Romero, J.; Lucas-Borja, M.E.; de las Heras, J. Fire vulnerability, resilience, and recovery rates of mediterranean pine forests using a 33-year time series of satellite imagery. Remote Sens. 2024, 16, 1718. [Google Scholar] [CrossRef]
- Hu, X.; Ban, Y.; Nascetti, A. Sentinel-2 MSI data for active fire detection in major fire-prone biomes: A multi-criteria approach. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102347. [Google Scholar] [CrossRef]
- Kurbanov, E.; Vorobev, O.; Lezhnin, S.; Sha, J.; Wang, J.; Li, X.; Cole, J.; Dergunov, D.; Wang, Y. Remote sensing of forest burnt area, burn severity, and post-fire recovery: A review. Remote. Sens. 2022, 14, 4714. [Google Scholar] [CrossRef]
- Ghosh, S.; Kumar, D.; Kumari, R. Cloud-based large-scale data retrieval, mapping, and analysis for land monitoring applications with Google Earth Engine (GEE). Environ. Chall. 2022, 9, 100605. [Google Scholar] [CrossRef]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Gemitzi, A.; Kopsidas, O.; Stefani, F.; Polymeros, A.; Bellos, V. A Constantly updated flood hazard assessment tool using satellite-based high-resolution land cover dataset within Google Earth Engine. Land 2024, 13, 1929. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Quintero, N.; Viedma, O.; Urbieta, I.R.; Moreno, J.M. Assessing landscape fire hazard by multitemporal automatic classification of Landsat time series using the Google Earth Engine in west-central spain. Forests 2019, 10, 518. [Google Scholar] [CrossRef]
- Khan, S.M.; Shafi, I.; Haider Butt, W.; de la Torre Diez, I.; López Flores, M.A.; Castanedo Galán, J.; Ashraf, I. A systematic review of disaster management systems: Approaches, challenges, and future directions. Land 2023, 12, 1514. [Google Scholar] [CrossRef]
- Limber, R.; Hargrove, W.W.; Hoffman, F.M.; Kumar, J. Forecast of wildfire potential across California USA using a transformer. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2024; pp. 4342–4350. [Google Scholar] [CrossRef]
- Xia, Z.; Liao, K.; Guo, L.; Wang, B.; Huang, H.; Chen, X.; Fang, X.; Zu, K.; Luo, Z.; Shen, F.; et al. Determining dominant factors of vegetation change with machine learning and multisource data in the Ganjiang River Basin, China. Land 2025, 14, 76. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, W.; He, Z.; Zhang, Y.; Wu, W.; Chen, T. Quantifying nonlinear responses of vegetation to hydro-climatic changes in mountainous Southwest China. Front. For. Glob. Change 2024, 7, 1417737. [Google Scholar] [CrossRef]
- Shahzad, F.; Mehmood, K.; Hussain, K.; Haidar, I.; Anees, S.A.; Muhammad, S.; Ali, J.; Adnan, M.; Wang, Z.; Feng, Z. Comparing machine learning algorithms to predict vegetation fire detections in Pakistan. Fire Ecol. 2024, 20, 57. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, C.; Zhang, F. Predicting forest fire area growth rate using an ensemble algorithm. Forests 2024, 15, 1493. [Google Scholar] [CrossRef]
- Wang, C.; Liu, H.; Xu, Y.; Zhang, F. A forest fire prediction framework based on multiple machine learning models. Forests 2025, 16, 329. [Google Scholar] [CrossRef]
- Sarkar, M.S.; Majhi, B.K.; Pathak, B.; Biswas, T.; Mahapatra, S.; Kumar, D.; Bhatt, I.D.; Kuniyal, J.C.; Nautiyal, S. Ensembling machine learning models to identify forest fire-susceptible zones in Northeast India. Ecol. Inform. 2024, 81, 102598. [Google Scholar] [CrossRef]
- Joshi, J.; Sukumar, R. Improving prediction and assessment of global fires using multilayer neural networks. Sci. Rep. 2021, 11, 3295. [Google Scholar] [CrossRef]
- Kucuk, O.; Sevinc, V. Fire behavior prediction with artificial intelligence in thinned black pine (Pinus nigra Arnold) stand. For. Ecol. Manag. 2023, 529, 120707. [Google Scholar] [CrossRef]
- Akinci, H.A.; Akinci, H.; Zeybek, M. Comparison of diverse machine learning algorithms for forest fire susceptibility mapping in Antalya, Türkiye. Adv. Space Res. 2024, 74, 647–667. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Y.; Wang, S.; Zhao, Z.; Liu, C.; Wen, J. Comparative study of machine learning methods for mapping forest fire areas using Sentinel-1B and 2A imagery. Front. Remote Sens. 2024, 5, 1446641. [Google Scholar] [CrossRef]
- Gholamnia, K.; Nachappa, T.G.; Ghorbanzadeh, O.; Blaschke, T. Comparisons of diverse machine learning approaches for wildfire susceptibility mapping. Symmetry 2020, 12, 604. [Google Scholar] [CrossRef]
- Kalantar, B.; Ueda, N.; Idrees, M.O.; Janizadeh, S.; Ahmadi, K.; Shabani, F. Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data. Remote Sens. 2020, 12, 3682. [Google Scholar] [CrossRef]
- Choi, J.; Chae, H. Assessing wildfire risk in South Korea under climate change using the Maximum Entropy model and Shared Socioeconomic Pathway scenarios. Atmosphere 2025, 16, 5. [Google Scholar] [CrossRef]
- Kil, S.-H.; Lee, D.K.; Kim, H.G.; Kim, N.-C.; Im, S.; Park, G.-S. Comparing potential unstable sites and stable sites on revegetated cut-slopes of mountainous terrain in Korea. Sustainability 2015, 7, 15319–15341. [Google Scholar] [CrossRef]
- Choe, H.; Thorne, J.H.; Lee, D. Comparing climate projections for Asia, East Asia and South Korea. J. Environ. Impact Assess. 2017, 26, 114–126. [Google Scholar] [CrossRef]
- Hur, T.C.; Joo, S.H. Comparison of soil physical and chemical properties between coniferous and deciduous forests in Mt. Palgong. Curr. Res. Agric. Life Sci. 2002, 20, 39–47. [Google Scholar]
- Estanqueiro, M.; Šalamon, A.; Lewis, H.; Molloy, B.; Jovanović, D. Sentinel-2 imagery analyses for archaeological site detection: An application to Late Bronze Age settlements in Serbian Banat, southern Carpathian Basin. J. Archaeol. Sci. Rep. 2023, 51, 104188. [Google Scholar] [CrossRef]
- He, P.; Shi, Y.; Ding, H.; Yang, F. Classification and transition of grassland in Qinghai, China, from 1986 to 2020 with Landsat archives on Google Earth Engine. Land 2023, 12, 1686. [Google Scholar] [CrossRef]
- Vanama, V.S.K.; Mandal, D.; Rao, Y.S. GEE4FLOOD: Rapid mapping of flood areas using temporal Sentinel-1 SAR images with Google Earth Engine cloud platform. J. Appl. Remote Sens. 2020, 14, 034505. [Google Scholar] [CrossRef]
- Wang, S.; Feng, W.; Quan, Y.; Li, Q.; Dauphin, G.; Huang, W.; Li, J.; Xing, M. A heterogeneous double ensemble algorithm for soybean planting area extraction in Google Earth Engine. Comput. Electron. Agric. 2022, 197, 106955. [Google Scholar] [CrossRef]
- Quan, X.; Jiao, M.; He, Z.; Jaafari, A.; Xie, Q.; Lai, X. Effects of different sampling strategies for unburned label selection in machine learning modelling of wildfire occurrence probability. Int. J. Wildland Fire 2023, 32, 561–575. [Google Scholar] [CrossRef]
- Tavakoli, F. Dataset Creation and Imbalance Mitigation in Big Data: Enhancing Machine Learning Models for Forest Fire Prediction. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 10 October 2023. [Google Scholar]
- Senay, G.B.; Friedrichs, M.; Morton, C.; Parrish, G.E.; Schauer, M.; Khand, K.; Kagone, S.; Boiko, O.; Huntington, J. Mapping actual evapotranspiration using Landsat for the conterminous United States: Google Earth Engine implementation and assessment of the SSEBop model. Remote Sens. Environ. 2022, 275, 113011. [Google Scholar] [CrossRef]
- Wiethase, J.H.; Critchlow, R.; Foley, C.; Foley, L.; Kinsey, E.J.; Bergman, B.G.; Osujaki, B.; Mbwambo, Z.; Kirway, P.B.; Redeker, K.R.; et al. Pathways of degradation in rangelands in Northern Tanzania show their loss of resistance, but potential for recovery. Sci. Rep. 2023, 13, 2417. [Google Scholar] [CrossRef]
- Balch, J.K.; Denis, L.A.S.; Mahood, A.L.; Mietkiewicz, N.P.; Williams, T.M.; McGlinchy, J.; Cook, M.C. FIRED (Fire Events Delineation): An open, flexible algorithm and database of US fire events derived from the MODIS burned area product (2001–2019). Remote Sens. 2020, 12, 3498. [Google Scholar] [CrossRef]
- Sharma, S.; Khanal, P. Forest fire prediction: A spatial machine learning and neural network approach. Fire 2024, 7, 205. [Google Scholar] [CrossRef]
- Carmo, M.; Moreira, F.; Casimiro, P.; Vaz, P. Land use and topography influences on wildfire occurrence in northern Portugal. Landsc. Urban Plan. 2011, 100, 169–176. [Google Scholar] [CrossRef]
- Piao, Y.; Lee, D.; Park, S.; Kim, H.G.; Jin, Y. Forest fire susceptibility assessment using Google Earth Engine in Gangwon-do, Republic of Korea. Geomat. Nat. Hazards Risk 2022, 13, 432–450. [Google Scholar] [CrossRef]
- Xu, H.; Chen, J.; He, G.; Lin, Z.; Bai, Y.; Ren, M.; Zhang, H.; Yin, H.; Liu, F. Immediate assessment of forest fire using a novel vegetation index and machine learning based on multi-platform, high temporal resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2024, 134, 104210. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Data Source | Spatial Resolution | Unit | Time Period | Temporal Resolution |
|---|---|---|---|---|---|---|
| Land surface temperature | Surface temperature measured from satellite data | MODIS/006/MOD11A1 | 1 km | °C (converted) | 2020–2023 | Daily average |
| Temperature (2 m) | Mean air temperature 2 m above the ground | ECMWF/ERA5_LAND/DAILY_AGGR | ~9 km | °C (converted) | 2020–2023 | Daily average |
| Relative humidity | Atmospheric relative humidity | ECMWF/ERA5_LAND/DAILY_AGGR (dewpoint + temperature) | ~9 km | percentage (%) | 2020–2023 | Daily average |
| Soil moisture | Volumetric soil moisture content | NASA_USDA/HSL/SMAP10KM_soil_moisture | 10 km | mm | 2020–2023 | Three-day average |
| Solar radiation | Solar radiation received at the surface | IDAHO_EPSCOR/TERRACLIMATE (srad) | ~4.6 km | W/m2 | 2020–2023 | Monthly average |
| Precipitation | Total precipitation | IDAHO_EPSCOR/TERRACLIMATE (pr) | ~4.6 km | mm | 2020–2023 | Monthly total |
| Snow equivalent | Equivalent snow water content | IDAHO_EPSCOR/TERRACLIMATE (swe) | ~4.6 km | mm | 2020–2023 | Monthly average |
| Elevation (DEM) | Digital elevation model | USGS/SRTMGL1_003 (SRTM DEM) | 30 m | m | 2000 | Static |
| NDVI | Normalized difference vegetation index | COPERNICUS/S2_SR_HARMONIZED | 10 m | index (−1 to 1) | 2020–2023 | Monthly composite |
| Canopy height | Height of forest canopy | users/potapovpeter/GEDI_V27 (UMD GEDI) | 30 m | m | 2019–2020 | Static |
| Population density | Population density in the area | WorldPop/GP/100m/pop/KOR_2020 | 100 m | persons per km2 | 2020 | Static |
| Wind speed | Average wind speed | ECMWF/ERA5_LAND/DAILY_AGGR (u10, v10) | ~9 km | m/s | 2020–2023 | Daily average |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Yun, Y.; Chae, H. Forest Fire Risk Prediction in South Korea Using Google Earth Engine: Comparison of Machine Learning Models. Land 2025, 14, 1155. https://doi.org/10.3390/land14061155
Choi J, Yun Y, Chae H. Forest Fire Risk Prediction in South Korea Using Google Earth Engine: Comparison of Machine Learning Models. Land. 2025; 14(6):1155. https://doi.org/10.3390/land14061155
Chicago/Turabian StyleChoi, Jukyeong, Youngjo Yun, and Heemun Chae. 2025. "Forest Fire Risk Prediction in South Korea Using Google Earth Engine: Comparison of Machine Learning Models" Land 14, no. 6: 1155. https://doi.org/10.3390/land14061155
APA StyleChoi, J., Yun, Y., & Chae, H. (2025). Forest Fire Risk Prediction in South Korea Using Google Earth Engine: Comparison of Machine Learning Models. Land, 14(6), 1155. https://doi.org/10.3390/land14061155