

Identification of Urban Clusters Based on Multisource Data—An Example of Three Major Urban Agglomerations in China

Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Study Data
2.2.1. Population Data
2.2.2. GDP Data
2.2.3. Land Use Data
2.2.4. Nighttime Light Data
2.2.5. Road Network and POI Data
2.3. Methods
2.3.1. Social Economic Method (SEM)
2.3.2. Remote Sensing Method (RSM)
2.3.3. Traffic Network Method (TNM)
2.3.4. Multi-Source Data Fusion
2.3.5. Accuracy Evaluation
3. Results
3.1. Boundaries of Urban Clusters Identified by Different Methods
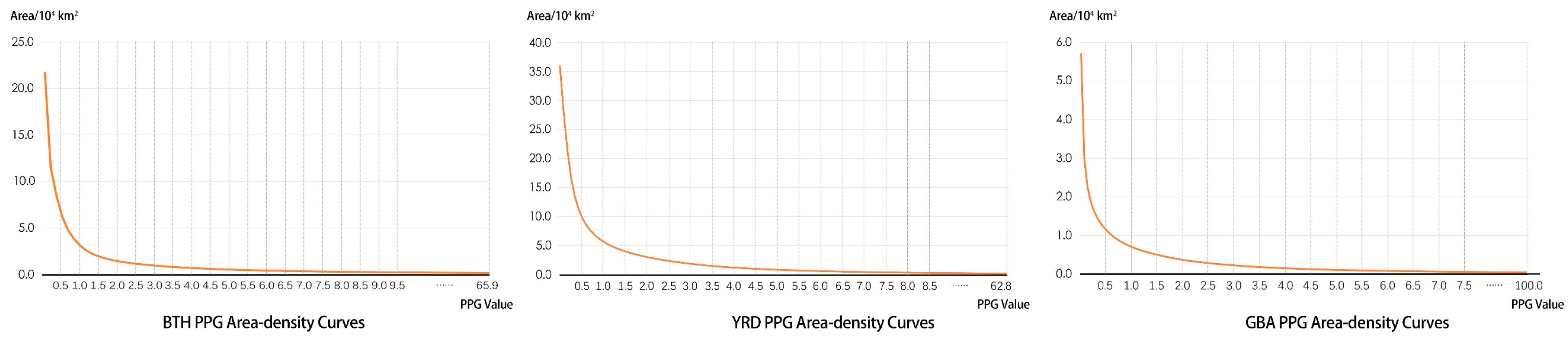
3.1.1. Boundary of Urban Clusters Identified by SEM
3.1.2. Boundary of Urban Clusters Identified Using RSM
3.1.3. Boundary of Urban Clusters Identified by TNM
3.2. Comparison and Fusion of Identified Urban Clusters
3.3. Verification of Urban Cluster Identifications
4. Discussion
4.1. Method Comparison
4.2. Limitations and Potential Solutions
4.3. How Urban Clusters Contribute
5. Conclusions and Prospects
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Ma, S.; Zheng, Y.; Xiao, X. Integrated Regional Development: Comparison of Urban Agglomeration Policies in China. Land Use Policy 2022, 114, 105939. [Google Scholar] [CrossRef]
- He, X.; Cao, Y.; Zhou, C. Evaluation of Polycentric Spatial Structure in the Urban Agglomeration of the Pearl River Delta (Prd) Based on Multi-Source Big Data Fusion. Remote Sens. 2021, 13, 3639. [Google Scholar] [CrossRef]
- Veneri, P. City Size Distribution across the OECD: Does the Definition of Cities Matter? Comput. Environ. Urban Syst. 2016, 59, 86–94. [Google Scholar] [CrossRef]
- Yu, Q.; Li, M.; Li, Q.; Wang, Y.; Chen, W. Economic Agglomeration and Emissions Reduction: Does High Agglomeration in China’s Urban Clusters Lead to Higher Carbon Intensity? Urban Clim. 2022, 43, 101174. [Google Scholar] [CrossRef]
- Ascher, C.S.; Geddes, P.; The Outlook Tower Association, E. Cities in Evolution. Land Econ. 1951, 27, 83. [Google Scholar] [CrossRef]
- Gottmann, J. The Evolution of the Concept of Territory. Soc. Sci. Inf. 1975, 14, 29–47. [Google Scholar] [CrossRef]
- Thacher, P.S. Ecumenopolis, The Inevitable City of the Future, by C. A. Doxiadis & J. G. Papaioannou. Athens Center of Ekistics, 24 Stratiotikou Syndesmou Street, Athens 136, Greece: Xxviii + 469 Pp., 153 Figs Incl. Numerous Maps, 23.5 × 15.6 × 2.5 Cm, Thick Paper Cove. Environ. Conserv. 1975, 2, 315–317. [Google Scholar] [CrossRef]
- Gottmann, J. Megalopolis or the Urbanization of the Northeastern Seaboard. Econ. Geogr. 1957, 33, 189. [Google Scholar] [CrossRef]
- Denis, P.-Y. Hall, Peter (1984) The World Cities. London, Weidenfeld and Nicolson, Third Edition, 276 P. Cah. Geogr. Que. 2012, 29, 441. [Google Scholar] [CrossRef]
- Friedmann, J.; Miller, J. THE URBAN FIELD. J. Am. Plan. Assoc. 1965, 31, 312–320. [Google Scholar] [CrossRef]
- O’Neill, P. Global City-Regions: Trends, Theory, Policy. Area 2003, 35, 326–327. [Google Scholar] [CrossRef]
- Fang, C. The Basic Law of the Formation and Expansion in Urban Agglomerations. J. Geogr. Sci. 2019, 29, 1699–1712. [Google Scholar] [CrossRef]
- Lv, Q.; Dou, Y.; Niu, X.; Xu, J.; Xu, J.; Xia, F. Urban Land Use and Land Cover Classification Using Remotely Sensed Sar Data through Deep Belief Networks. J. Sens. 2015, 2015, 538063. [Google Scholar] [CrossRef]
- Fragkias, M.; Seto, K.C. Evolving Rank-Size Distributions of Intra-Metropolitan Urban Clusters in South China. Comput. Environ. Urban Syst. 2009, 33, 189–199. [Google Scholar] [CrossRef]
- Wheeler, J.O.; Mitchelson, R.L. Information Flows among Major Metropolitan Areas in the United States. Ann. Assoc. Am. Geogr. 1989, 79, 523–543. [Google Scholar] [CrossRef]
- Wang, H.; Deng, Y.; Tian, E.; Wang, K. A Comparative Study of Methods for Delineating Sphere of Urban Influence: A Case Study on Central China. Chin. Geogr. Sci. 2014, 24, 751–762. [Google Scholar] [CrossRef]
- Huff, D.L.; Lutz, J.M. Ireland’s Urban System. Econ. Geogr. 1979, 55, 196. [Google Scholar] [CrossRef]
- Van Arjen Klink, H.; Van Den Berg, G.C. Gateways and Intermodalism. J. Transp. Geogr. 1998, 6, 1–9. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, G.; Li, P.; Li, F.; Guo, X. Analysis on the Driving Factors of Urban Expansion Policy Based on DMSP/OLS Remote Sensing Image. Cehui Xuebao/Acta Geod. Cartogr. Sin. 2018, 47, 1466. [Google Scholar] [CrossRef]
- Tannier, C.; Thomas, I. Defining and Characterizing Urban Boundaries: A Fractal Analysis of Theoretical Cities and Belgian Cities. Comput. Environ. Urban Syst. 2013, 41, 234–248. [Google Scholar] [CrossRef]
- Liu, X.; Derudder, B.; Wang, M. Polycentric Urban Development in China: A Multi-Scale Analysis. Environ. Plan. B Urban Anal. City Sci. 2018, 45, 953–972. [Google Scholar] [CrossRef]
- Li, F.; Yan, Q.; Bian, Z.; Liu, B.; Wu, Z. A Poi and Lst Adjusted Ntl Urban Index for Urban Built-up Area Extraction. Sensors 2020, 20, 2918. [Google Scholar] [CrossRef]
- Adolphson, M. Estimating a Polycentric Urban Structure. Case Study: Urban Changes in the Stockholm Region 1991–2004. J. Urban Plan. Dev. 2009, 135, 19–30. [Google Scholar] [CrossRef]
- Cao, W.; Dong, L.; Cheng, Y.; Wu, L.; Guo, Q.; Liu, Y. Constructing Multi-Level Urban Clusters Based on Population Distributions and Interactions. Comput. Environ. Urban Syst. 2023, 99, 101897. [Google Scholar] [CrossRef]
- Georg, I.; Blaschke, T.; Taubenböck, H. Spatial Delineation of Urban Corridors in North America: An Approach Incorporating Fuzziness Based on Multi-Source Geospatial Data. Cities 2023, 133, 104129. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Dietz, J.B.; Bland, T.; Sutton, P.C.; Kroehl, H.W. Radiance Calibration of DMSP-OLS Low-Light Imaging Data of Human Settlements. Remote Sens. Environ. 1999, 68, 77–88. [Google Scholar] [CrossRef]
- Dai, X.; Jin, J.; Chen, Q.; Fang, X. On Physical Urban Boundaries, Urban Sprawl, and Compactness Measurement: A Case Study of the Wen-Tai Region, China. Land 2022, 11, 1637. [Google Scholar] [CrossRef]
- Hu, S.; Tong, L.; Frazier, A.E.; Liu, Y. Urban Boundary Extraction and Sprawl Analysis Using Landsat Images: A Case Study in Wuhan, China. Habitat Int. 2015, 47, 183–195. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Zhou, Y.; Xu, Y. Extracting Physical Urban Areas of 81 Major Chinese Cities from High-Resolution Land Uses. Cities 2022, 131, 104061. [Google Scholar] [CrossRef]
- Van de Voorde, T.; Jacquet, W.; Canters, F. Mapping Form and Function in Urban Areas: An Approach Based on Urban Metrics and Continuous Impervious Surface Data. Landsc. Urban Plan. 2011, 102, 143–155. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Y.; Zhu, Z.; Liang, L.; Yu, B.; Cao, W. Mapping Annual Urban Dynamics (1985–2015) Using Time Series of Landsat Data. Remote Sens. Environ. 2018, 216, 674–683. [Google Scholar] [CrossRef]
- Luqman, M.; Rayner, P.J.; Gurney, K.R. Combining Measurements of Built-up Area, Nighttime Light, and Travel Time Distance for Detecting Changes in Urban Boundaries: Introducing the BUNTUS Algorithm. Remote Sens. 2019, 11, 2969. [Google Scholar] [CrossRef]
- Lou, G.; Chen, Q.; He, K.; Zhou, Y.; Shi, Z. Using Nighttime Light Data and POI Big Data to Detect the Urban Centers of Hangzhou. Remote Sens. 2019, 11, 1821. [Google Scholar] [CrossRef]
- He, X.; Zhu, Y.; Chang, P.; Zhou, C. Using Tencent User Location Data to Modify Night-Time Light Data for Delineating Urban Agglomeration Boundaries. Front. Environ. Sci. 2022, 10, 860365. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H.; Ning, X.; Zhang, X.; Liu, R.; Wang, H. Identification of Metropolitan Area Boundaries Based on Comprehensive Spatial Linkages of Cities: A Case Study of the Beijing–Tianjin–Hebei Region. ISPRS Int. J. Geo-Inf. 2022, 11, 396. [Google Scholar] [CrossRef]
- Fang, C.; Yu, D. Urban Agglomeration: An Evolving Concept of an Emerging Phenomenon. Landsc. Urban Plan. 2017, 162, 126–136. [Google Scholar] [CrossRef]
- Takahashi, K.I.; Terakado, R.; Nakamura, J.; Adachi, Y.; Elvidge, C.D.; Matsuno, Y. In-Use Stock Analysis Using Satellite Nighttime Light Observation Data. Resour. Conserv. Recycl. 2010, 55, 196–200. [Google Scholar] [CrossRef]
- Stokes, E.C.; Seto, K.C. Characterizing Urban Infrastructural Transitions for the Sustainable Development Goals Using Multi-Temporal Land, Population, and Nighttime Light Data. Remote Sens. Environ. 2019, 234, 111430. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, H. Identification of Urban Agglomeration Spatial Range Based on Social and Remote-Sensing Data—For Evaluating Development Level of Urban Agglomeration. ISPRS Int. J. Geo-Inf. 2022, 11, 456. [Google Scholar] [CrossRef]
- Fang, C. New Structure and New Trend of Formation and Development. Sci. Geogr. Sin. 2019, 31, 1025–1034. [Google Scholar] [CrossRef]
- Zhang, Y.; Mao, W.; Zhang, B. Distortion of Government Behaviour under Target Constraints: Economic Growth Target and Urban Sprawl in China. Cities 2022, 131, 104009. [Google Scholar] [CrossRef]
- Hosseinpour, H.; Samadzadegan, F.; Javan, F.D. CMGFNet: A Deep Cross-Modal Gated Fusion Network for Building Extraction from Very High-Resolution Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2022, 184, 96–115. [Google Scholar] [CrossRef]
- Wang, M.; Song, Y.; Wang, F.; Meng, Z. Boundary Extraction of Urban Built-Up Area Based on Luminance Value Correction of NTL Image. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7466–7477. [Google Scholar] [CrossRef]
- Wang, S.; Huang, L.; Xu, X.; Li, J. Spatio-Temporal Variation Characteristics of Ecological Space and Its Ecological Carrying Status in Mega-Urban Agglomerations. Dili Xuebao/Acta Geogr. Sin. 2022, 77, 164–181. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. The 30m Annual Land Cover Dataset and Its Dynamics in China from 1990 to 2019. Earth Syst. Sci. Data 2021, 13, 3907–3925. [Google Scholar] [CrossRef]
- Yu, M.; Guo, S.; Guan, Y.; Cai, D.; Zhang, C.; Fraedrich, K.; Liao, Z.; Zhang, X.; Tian, Z. Spatiotemporal Heterogeneity Analysis of Yangtze River Delta Urban Agglomeration: Evidence from Nighttime Light Data (2001–2019). Remote Sens. 2021, 13, 1235. [Google Scholar] [CrossRef]
- Zheng, Y.; He, Y.; Zhou, Q.; Wang, H. Quantitative Evaluation of Urban Expansion Using NPP-VIIRS Nighttime Light and Landsat Spectral Data. Sustain. Cities Soc. 2022, 76, 103338. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, C.; Zheng, W.; Rong, Y.; Liu, W. Identification of Urban Shrinkage Using NPP-VIIRS Nighttime Light Data at the County Level in China. Cities 2021, 118, 103373. [Google Scholar] [CrossRef]
- Zhao, P.; Jia, T.; Qin, K.; Shan, J.; Jiao, C. Statistical Analysis on the Evolution of OpenStreetMap Road Networks in Beijing. Phys. A Stat. Mech. Its Appl. 2015, 420, 59–72. [Google Scholar] [CrossRef]
- Huang, W.; Zhang, D.; Mai, G.; Guo, X.; Cui, L. ISPRS Journal of Photogrammetry and Remote Sensing Learning Urban Region Representations with POIs and Hierarchical Graph Infomax. ISPRS J. Photogramm. Remote Sens. 2023, 196, 134–145. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Q.; Yang, F. Identification of Urban Agglomeration Boundary Based on POI and NPP/VIIRS Night Light Data. Prog. Geogr. 2019, 38, 840–850. [Google Scholar] [CrossRef]
- Peng, J.; Hu, Y.; Liu, Y.; Ma, J.; Zhao, S. A New Approach for Urban-Rural Fringe Identification: Integrating Impervious Surface Area and Spatial Continuous Wavelet Transform. Landsc. Urban Plan. 2018, 175, 72–79. [Google Scholar] [CrossRef]
- Shahtahmassebi, A.R.; Song, J.; Zheng, Q.; Blackburn, G.A.; Wang, K.; Huang, L.Y.; Pan, Y.; Moore, N.; Shahtahmassebi, G.; Sadrabadi Haghighi, R.; et al. Remote Sensing of Impervious Surface Growth: A Framework for Quantifying Urban Expansion and Re-Densification Mechanisms. Int. J. Appl. Earth Obs. Geoinf. 2016, 46, 94–112. [Google Scholar] [CrossRef]
- Li, G.; CAO, Y.; He, Z.; He, J.; Cao, Y.; Wang, J.; Fang, X. Understanding the Diversity of Urban–Rural Fringe Development in a Fast Urbanizing Region of China. Remote Sens. 2021, 13, 2373. [Google Scholar] [CrossRef]
- Clark, C. Urban Population Pensities. J. R. Stat. Soc. Ser. A (Gen.) 1898, 114, 490–496. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, J. Study on the Model of Regional Differentiation of Land Use Degree in China. J. Nat. Resour. 1997, 12, 105–111. [Google Scholar]
- Qin, H.; Zhang, F.; Du, Z.; Renyi, L. The Evaluate of Urban Development in Zhejiang Province Based on DMSP/OLS Nighttime Light Data. J. Zhejiang Univ. Ed. 2017, 44, 640–648. [Google Scholar] [CrossRef]
- Weiss, D.J.; Nelson, A.; Gibson, H.S.; Temperley, W.; Peedell, S.; Lieber, A.; Hancher, M.; Poyart, E.; Belchior, S.; Fullman, N.; et al. A Global Map of Travel Time to Cities to Assess Inequalities in Accessibility in 2015. Nat. Publ. Gr. 2018, 553, 333–336. [Google Scholar] [CrossRef]
- Chen, W. Identifying the Spatial Scope of Megaregions in China from the Perspective of Accessibility. Geogr. Res. 2020, 39, 2808–2820. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The Analysis of Spatial Association by Use of Distance Statistics. Perspect. Spat. Data Anal. 1992, 24, 127–145. [Google Scholar] [CrossRef]
- Yang, Y.; Xiao, P.; Feng, X.; Li, H. ISPRS Journal of Photogrammetry and Remote Sensing Accuracy Assessment of Seven Global Land Cover Datasets over China. ISPRS J. Photogramm. Remote Sens. 2017, 125, 156–173. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and Interpreting Measures of Thematic Classification Accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Schindler, N.H.A. Bandwidth Selection for Kernel Density Estimation: A Review of Fully Automatic Selectors. AStA Adv. Stat. Anal. 2013, 97, 403–433. [Google Scholar] [CrossRef]
- Schucany, W.R. Locally Optimal Window Widths for Kernel Density Estimation with Large Samples. Stat. Probab. Lett. 1989, 7, 401–405. [Google Scholar] [CrossRef]
- Yao, Z.; Ye, K.; Xiao, L.; Wang, X. Radiation Effect of Urban Agglomeration’s Transportation Network: Evidence from Chengdu–Chongqing Urban Agglomeration, China. Land 2021, 10, 520. [Google Scholar] [CrossRef]
- Liu, X.; Ning, X.; Wang, H.; Wang, C.; Zhang, H.; Meng, J. A Rapid and Automated Urban Boundary Extraction Method Based on Nighttime Light Data in China. Remote Sens. 2019, 11, 1126. [Google Scholar] [CrossRef]
- Li, X.; Levin, N.; Xie, J.; Li, D. Monitoring Hourly Night-Time Light by an Unmanned Aerial Vehicle and Its Implications to Satellite Remote Sensing. Remote Sens. Environ. 2020, 247, 111942. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Level | Second Level | Description | Contribution | Weight |
|---|---|---|---|---|
| Denseness | Impervious surface ratio | The percentage of impervious surface within the 1 km2 cell grid was calculated and divided into 5 classes in the range of 20%: high (>80%), medium-high (60–80%), medium (40–60%), medium-low (20–40%), and low (<20%) density impervious surface areas (unitless). | + | 0.314 |
| Continuity | PLADJ | The percentage of adjacent landscape types in the total adjacent landscape (%). | + | 0.043 |
| COHENSION | The physical connectedness of patches at fractional land cover thresholds; it is computed from the patch area and the perimeter (unitless). | + | 0.016 | |
| Aggregation index | The degree of aggregation in urban class based on like cell adjacencies. High values of AI indicate urban patches are highly clustered (%). | + | 0.036 | |
| CONTAG | The extent to which patch types are aggregated or clumped (%) | + | 0.031 | |
| Shannon’s diversity index | The negative sum, across all patch types, of the proportional abundance of each patch type multiplied by that proportion (unitless). | - | 0.017 | |
| Edge density | The sum of the lengths (m) of all edge segments in the landscape, divided by the total landscape area (m2), multiplied by 10,000 (to convert to hectares) (m/hectare). | - | 0.005 | |
| Gradient | Urban influence gradient | Calculate the distance from each pixel to the impervious surface site, quantify the spatial pattern of town influence by using the Clark model, and perform mean statistics with a sampling grid (unitless). | + | 0.198 |
| Development intensity gradient | The spatial distribution of land development intensity was calculated using the integrated land use degree index model (unitless). | + | 0.227 | |
| Development | Potential of construction | The sum of the product of the nighttime light intensity of the pixel and the distance function of the source point of the town from the pixel. The source points are the centers of each town (DN/m2). | + | 0.113 |
| Road Network Type | Speed (km/h) | Speed Cost (min) | Barrier |
|---|---|---|---|
| High-speed railway | 300 | 0.2 | Station |
| Ordinary railway | 120 | 0.5 | Station |
| Highway | 120 | 0.5 | Entrance and exit |
| National road | 80 | 0.75 | / |
| Provincial road | 60 | 1 | |
| Other road | 30 | 2 |
| Case | BTH | YRD | GBA | ||||
|---|---|---|---|---|---|---|---|
| Methods | OA | Kappa Efficient | OA | Kappa Efficient | OA | Kappa Efficient | |
| SEM | 55.97% | 0.4435 | 52.91% | 0.4203 | 63.58% | 0.5748 | |
| RSM | 44.45% | 0.3524 | 20.34% | 0.1830 | 27.84% | 0.2473 | |
| TNM | 33.72% | 0.3141 | 28.35% | 0.2212 | 31.17% | 0.2958 | |
| Data fusion | 90.11% | 0.8115 | 81.40% | 0.6807 | 84.52% | 0.7260 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Wang, Y.; Li, Y.; Chen, T. Identification of Urban Clusters Based on Multisource Data—An Example of Three Major Urban Agglomerations in China. Land 2023, 12, 1058. https://doi.org/10.3390/land12051058
Wang G, Wang Y, Li Y, Chen T. Identification of Urban Clusters Based on Multisource Data—An Example of Three Major Urban Agglomerations in China. Land. 2023; 12(5):1058. https://doi.org/10.3390/land12051058
Chicago/Turabian StyleWang, Gaoyuan, Yixuan Wang, Yangli Li, and Tian Chen. 2023. "Identification of Urban Clusters Based on Multisource Data—An Example of Three Major Urban Agglomerations in China" Land 12, no. 5: 1058. https://doi.org/10.3390/land12051058
APA StyleWang, G., Wang, Y., Li, Y., & Chen, T. (2023). Identification of Urban Clusters Based on Multisource Data—An Example of Three Major Urban Agglomerations in China. Land, 12(5), 1058. https://doi.org/10.3390/land12051058