
Transforming Hydrology Python Packages into Web Application Programming Interfaces: A Comprehensive Workflow Using Modern Web Technologies


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Study Objective
1.2. Overview of Existing Web-Based Hydrology Frameworks
1.2.1. Tethys Platform
1.2.2. HydroShare
1.2.3. HydroServer
1.2.4. HydroLang
1.2.5. HydroDS
1.2.6. HydroCompute
1.2.7. PyWPS
2. Materials and Methods
2.1. Web Technologies and Frameworks
2.1.1. FastAPI
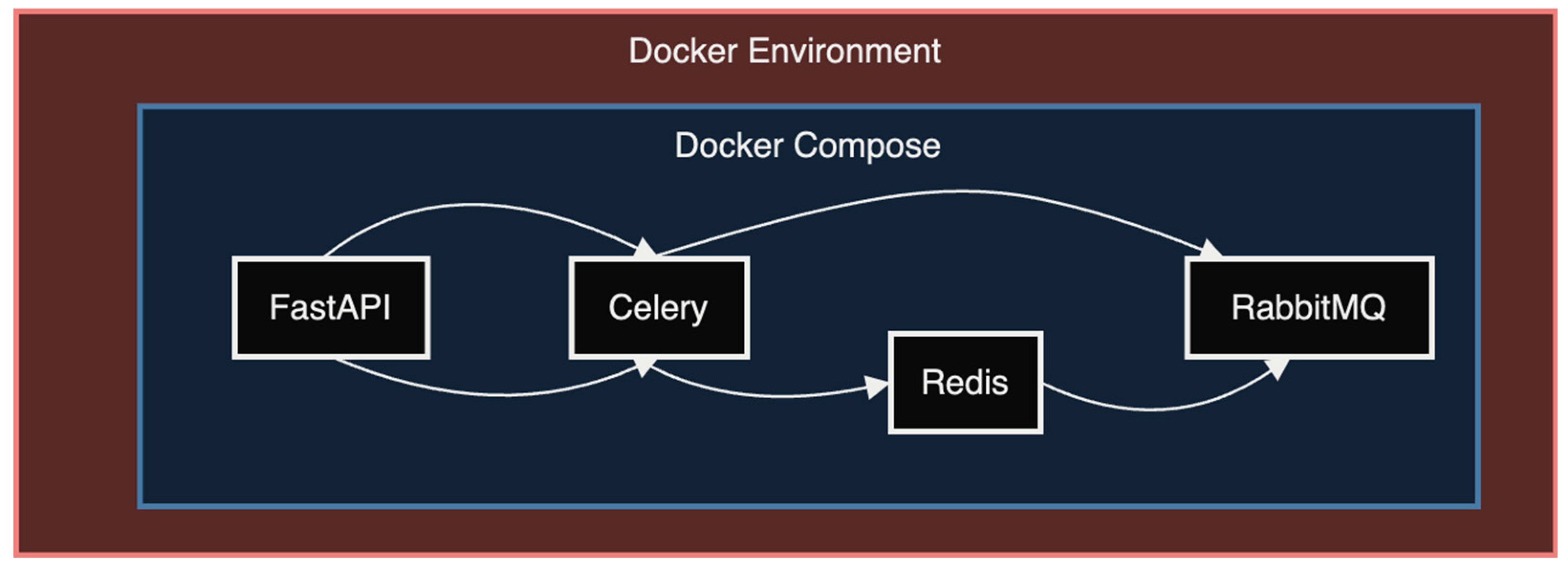
2.1.2. Docker and Docker Compose
2.1.3. Celery and RabbitMQ
2.1.4. Redis
2.2. Workflow Implementation
- Analysis of package structure and dependencies.
- API design and endpoint mapping.
- Implementation of the FastAPI application.
- Integration of asynchronous task processing.
- Containerization and deployment configuration.
- Comprehensive testing and validation.
- Documentation generation.
2.2.1. Analysis of Package Structure and Dependencies
- Package Structure Analysis. The analysis begins with an in-depth examination of the overall structure of the Python package:
- Module Organization: The package is mapped out into its modules and submodules to understand the logical separation of functionalities within the package.
- Class and Function Hierarchy: The main classes and functions are identified, along with their relationships and dependencies, which informs the API design and helps decide which elements should be exposed as endpoints.
- Data Flow: The flow of data from input to output is traced, which is crucial for designing efficient API endpoints and determining where asynchronous processing might be beneficial.
- Configuration and Settings: Any configuration files or environment-specific settings the package relies on are identified, as these may need to be translated into API parameters or environment variables in the containerized setup.
- Dependency Analysis. A thorough analysis of the package’s dependencies is conducted as follows:
- Direct Dependencies: The requirements.txt or setup.py file is examined to list all direct dependencies. Each dependency is evaluated for the following:
- o
- Compatibility with the target Python version.
- o
- Potential conflicts with other required libraries.
- o
- Availability of recent updates or known security issues.
- Indirect Dependencies: Tools like pipdeptree are used to visualize the full dependency tree, including indirect dependencies, to identify potential conflicts or redundancies in the dependency chain.
- System-Level Dependencies: Any system-level libraries or tools the package relies on are identified, and plans are made for their inclusion in the containerized environment.
- Dependency Licensing: The licenses of all dependencies are reviewed to ensure compliance with the project’s licensing requirements and to avoid any potential legal issues.
- Computational Resource Assessment. The computational requirements of the package are assessed as follows:
- CPU Usage: The package is profiled to understand its CPU intensity, identifying functions that may benefit from asynchronous processing or parallelization in the API.
- Memory Usage: The memory footprint of typical operations is analyzed to inform server specifications and potential memory optimization in the API.
- I/O Operations: The package’s file I/O and database interactions are examined to design efficient data handling strategies in the API.
- Identifying API Conversion Challenges. Based on the analysis, the following potential challenges in the API conversion process are identified:
- Stateful Operations: Operations that maintain state between calls are noted, as these may require special handling in a stateless API environment.
- Long-Running Processes: Processes that may exceed typical web request timeouts are identified, with plans for asynchronous processing solutions.
- Data Volume: The typical volume of input and output data is assessed to inform choices for data transfer methods and storage solutions.
- Package-Specific Quirks: Any unique behaviors or requirements of the package that may need special consideration in the API design are documented.
- Documentation Review. A thorough review of the existing package documentation is conducted as follows:
- User Guides: User guides are examined to understand the intended use cases and typical workflows of the package.
- Examples and Tutorials: Examples and tutorials are collected, which will be valuable for creating sample API calls and usage guidelines.
2.2.2. API Design and Endpoint Mapping
- Statelessness: Each client request to the server must contain all the necessary information to understand and process the request. The server does not store any client state between requests.
- Client–Server: The client and server are independent, allowing each to evolve separately.
- Uniform Interface: Standard HTTP methods (GET, POST, PUT, DELETE) are used for different operations:
- o
- GET: Retrieve data (e.g., obtain simulation results).
- o
- POST: Create new resources (e.g., start a new simulation).
- o
- PUT: Update existing resources (e.g., modify simulation parameters).
- o
- DELETE: Remove resources (e.g., cancel a running simulation).
- Resource-Based: The API is structured around resources such as models, simulations, datasets, and results.
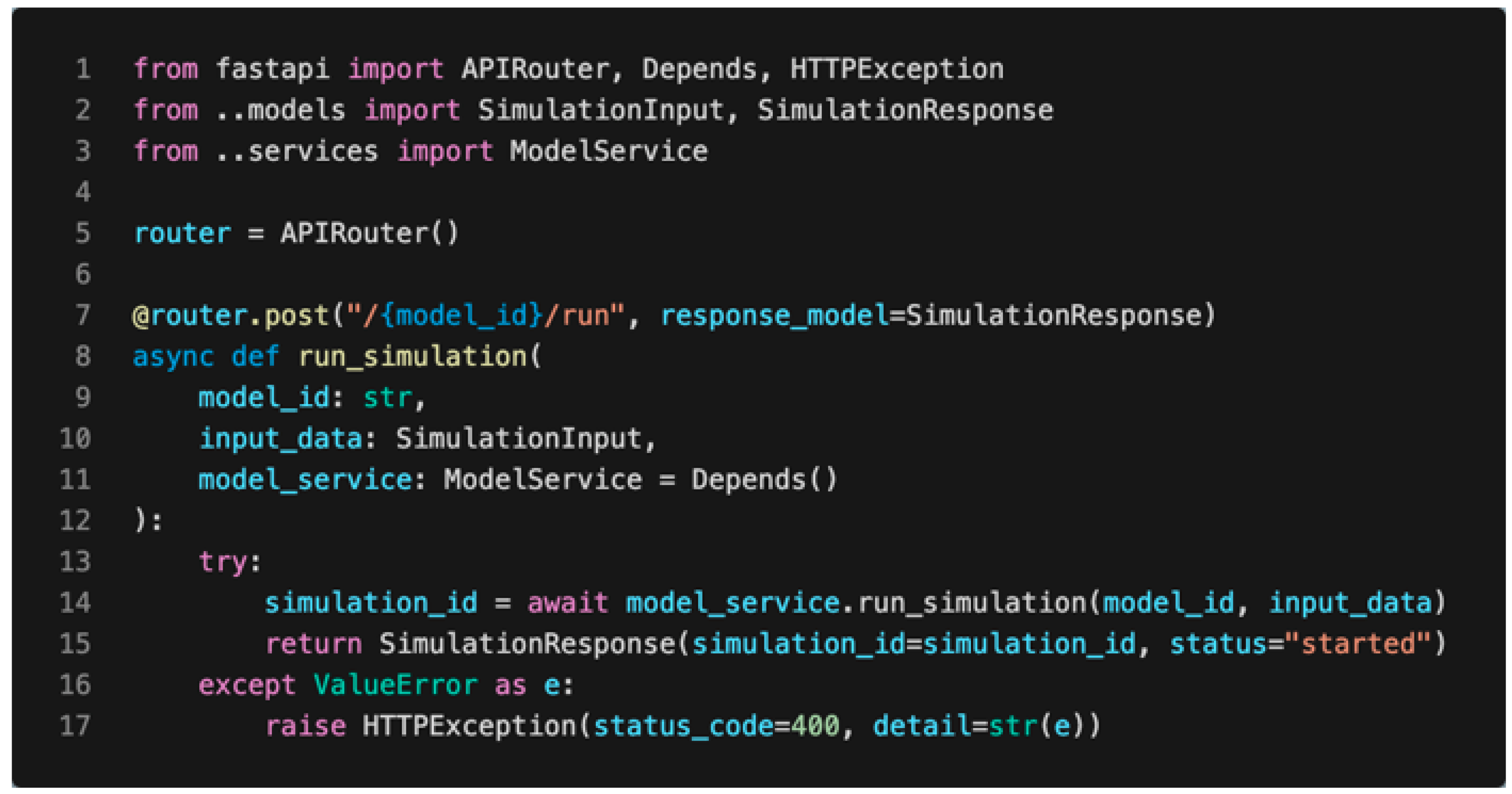
- Core Model Functionalities: These are exposed as primary endpoints, such as the following:
- o
- /models/{model_id}/run: Initiates a model simulation.
- o
- /models/{model_id}/calibrate: Starts the model calibration process.
- Auxiliary Functions: These are mapped to secondary endpoints or incorporated as query parameters as follows:
- o
- /models/{model_id}/parameters: Retrieves or updates model parameters.
- o
- /simulations/{simulation_id}?include_metadata=true: Retrieves simulation results with an option to include metadata.
- Complex Workflows: These are decomposed into sequences of API calls. For instance, a complete modeling process might involve the following:
- o
- Uploading input data: POST/datasets.
- o
- Setting model parameters: PUT/models/{model_id}/parameters.
- o
- Running the simulation: POST/models/{model_id}/run.
- o
- Retrieving results: GET/simulations/{simulation_id}.
- Input Parameters: These are handled through a combination of the following:
- o
- Path variables: For identifying specific resources (e.g., {model_id} in/models/{model_id}/run).
- o
- Query parameters: For optional or filter-like parameters (e.g., ?start_date=2023-01-01).
- o
- Request bodies: For complex or large inputs, typically sent as JSON.
- Output Formats: JSON is standardized format for structured data due to its widespread use and ease of parsing. For large datasets, binary formats may be used, and content negotiation is implemented to support multiple response formats.
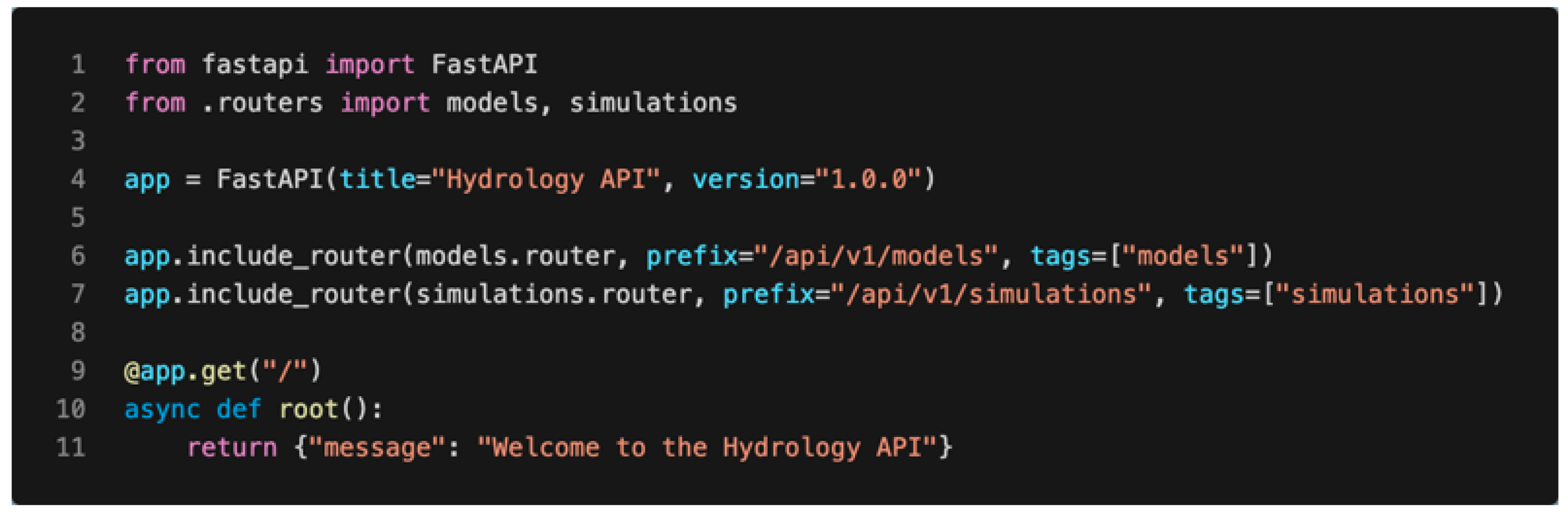
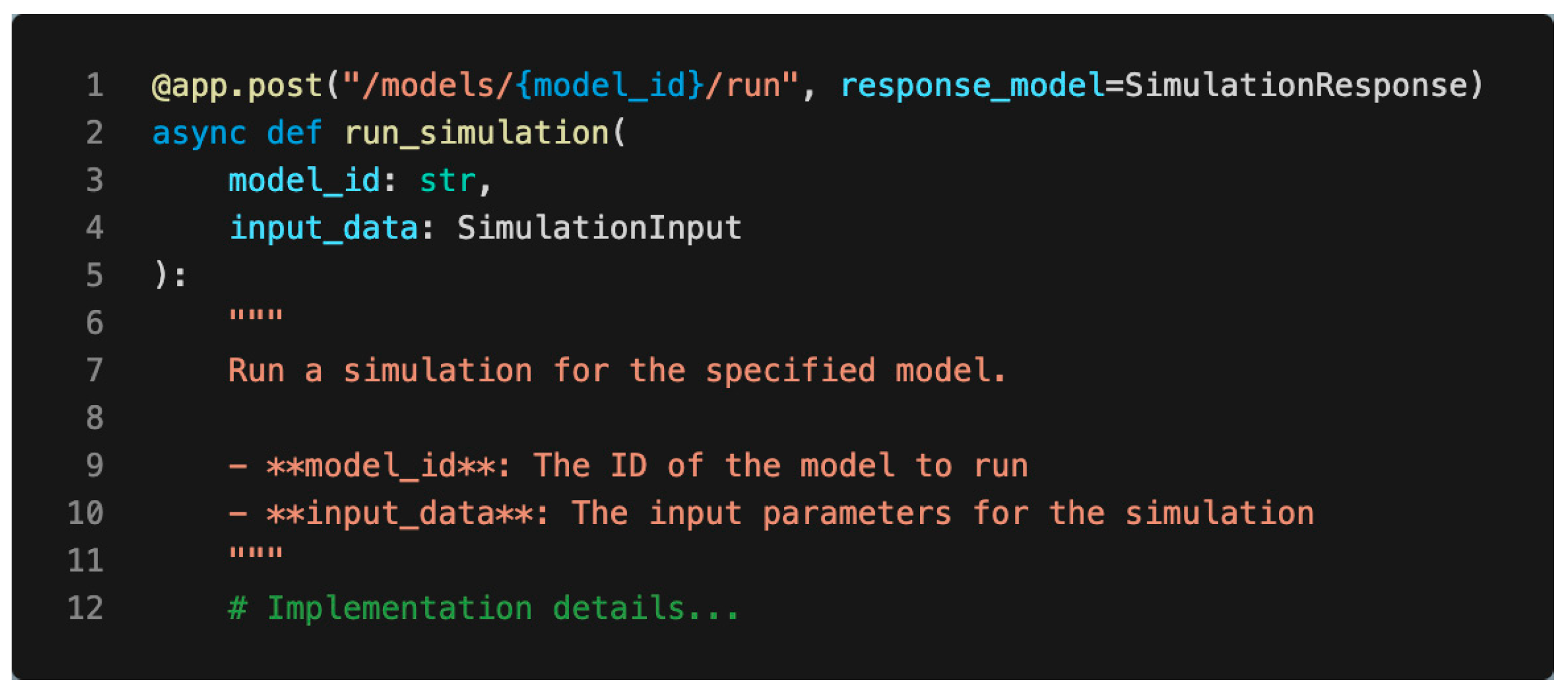
2.2.3. FastAPI Implementation
- main.py: The entry point of the application, where the FastAPI instance is created and routers are included.
- routers/: A directory containing route handlers for different parts of the API (e.g., models.py, simulations.py).
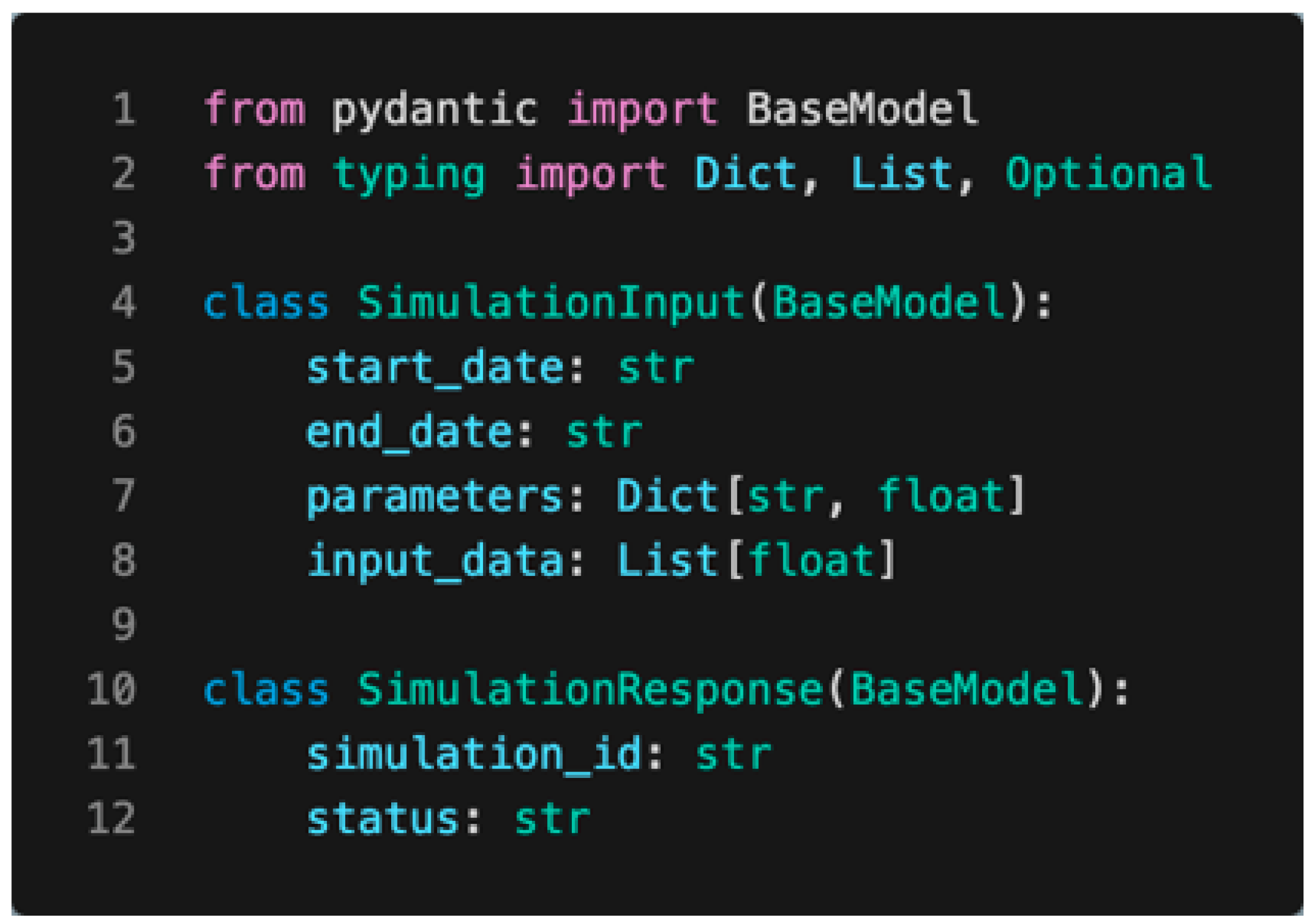
- models/: Pydantic models defining the structure of request and response data.
- services/: Business logic and interactions with the underlying hydrological models.
- utils/: Utility functions and helpers.
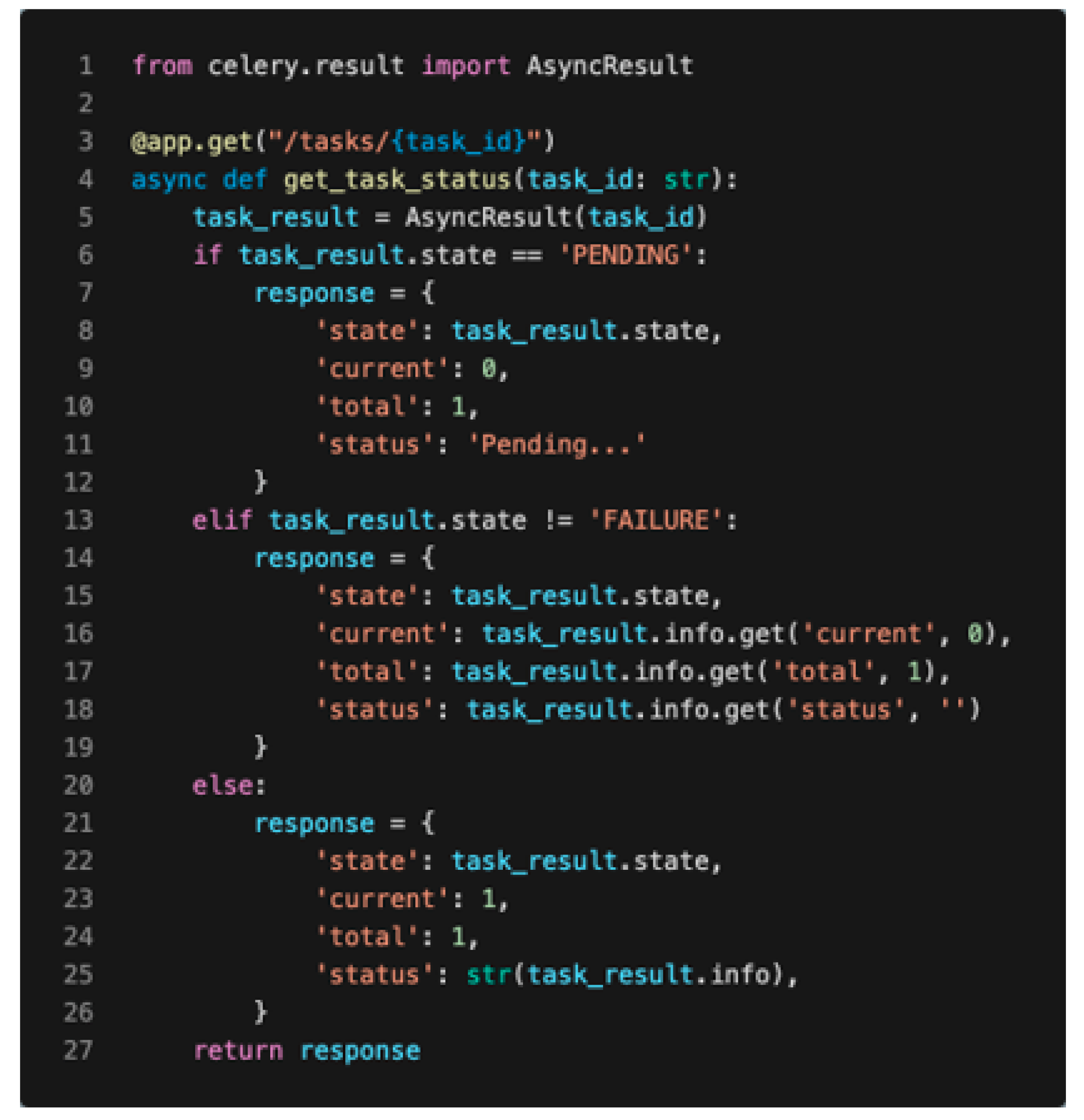
2.2.4. Asynchronous Task Processing
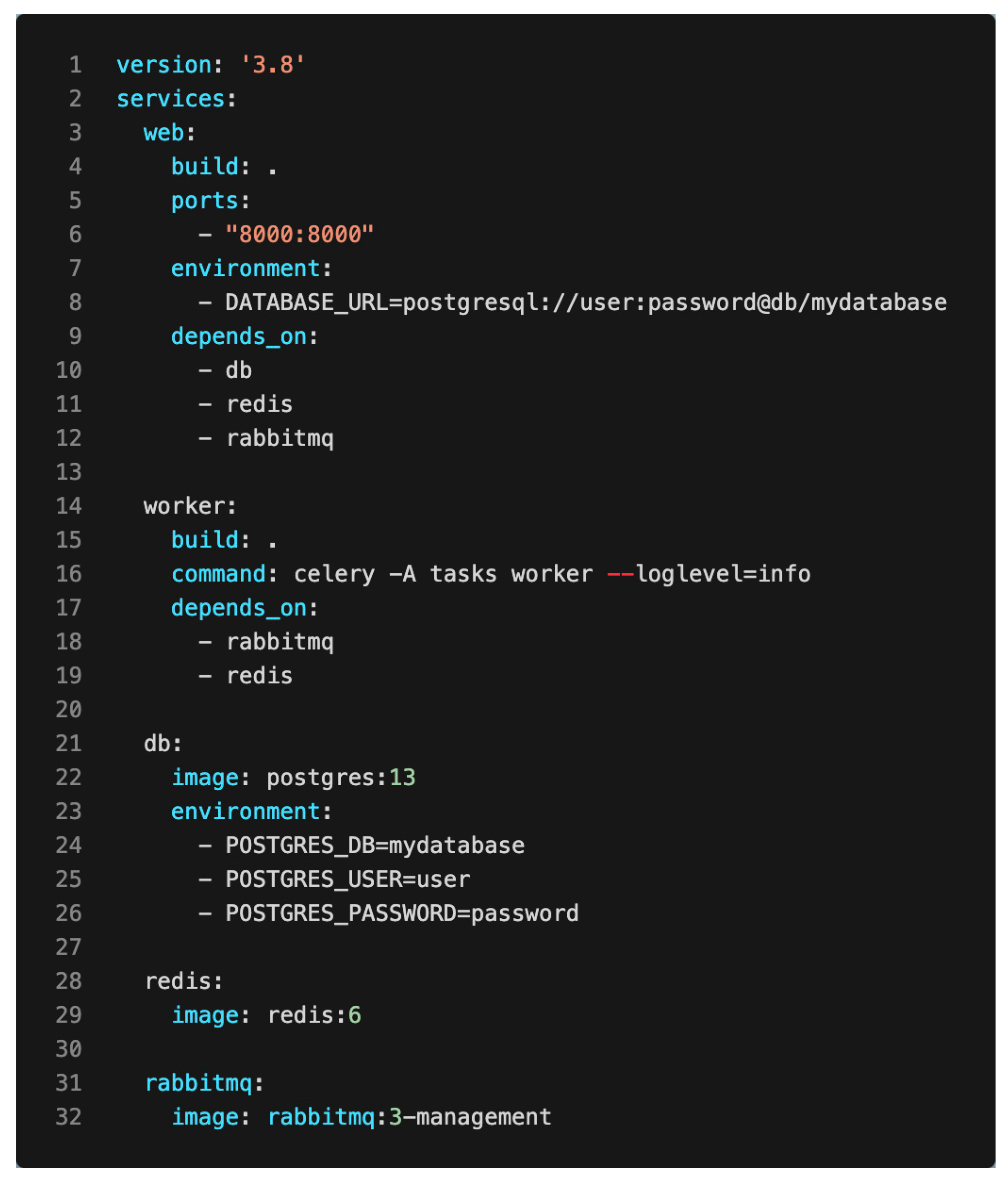
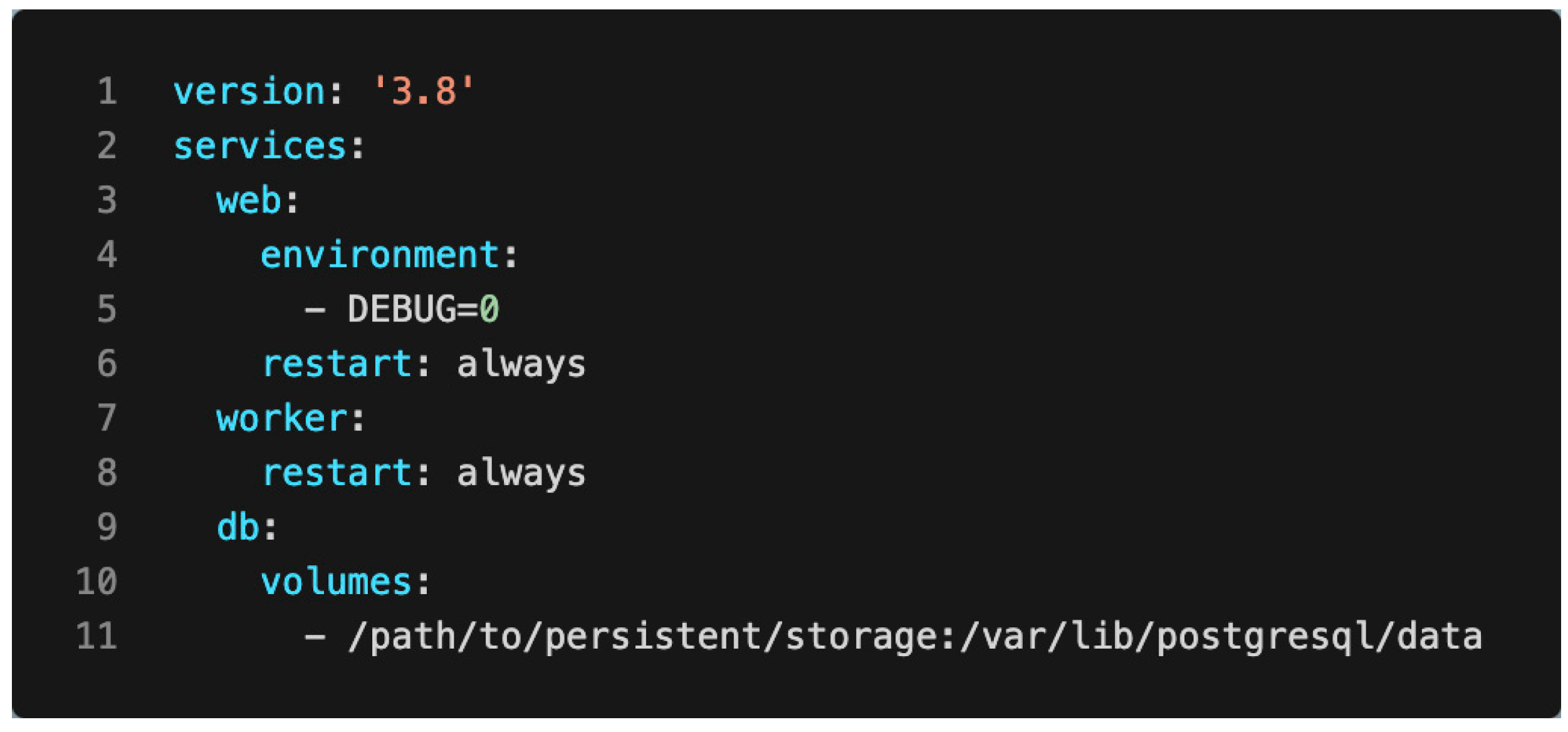
2.2.5. Containerization and Deployment
- Web Service: Builds the FastAPI application, exposes port 8000, and sets environment variables for the database connection. It depends on the database, Redis, and RabbitMQ services.
- Worker Service: Builds the application, runs the Celery worker with appropriate logging, and depends on RabbitMQ and Redis.
- Database Service: Uses a PostgreSQL image with specified environmental variables for the database name, user, and password.
- Redis Service: Utilizes a Redis image for caching.
- RabbitMQ Service: Uses a RabbitMQ management image for message brokering.
- docker-compose build.
- docker-compose up-d.
- Using official base images to reduce the risk of vulnerabilities.
- Minimizing the attack surface by only installing necessary packages.
- Implementing proper secret management for sensitive data like database passwords.
- Regularly updating all images and dependencies to patch known vulnerabilities.
- Utilizing Docker’s network features to isolate services that do not need to communicate with each other.
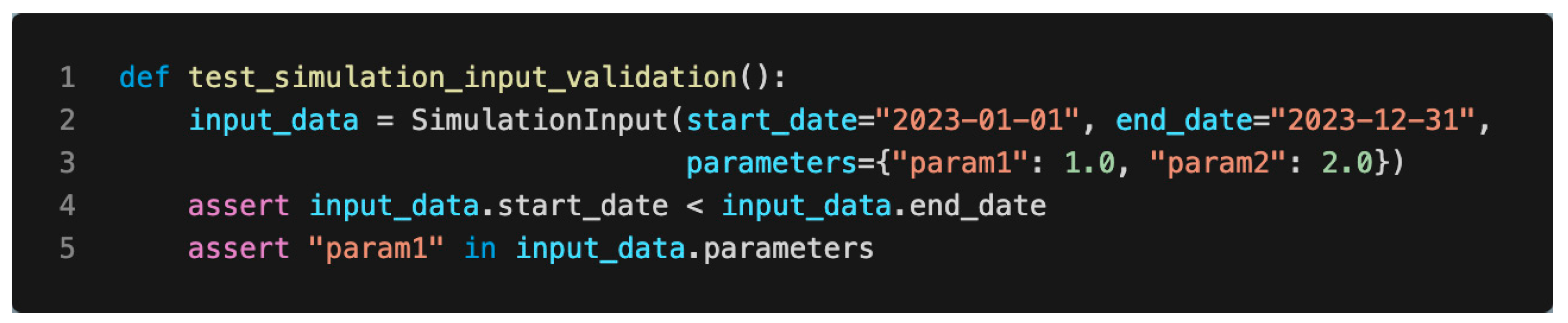
2.2.6. Testing and Validation
2.2.7. Documentation Generation
3. Results
3.1. Case Study 1: Web APIs for GRACE Downscaling and Synthetic Time Series Models
3.1.1. Implementation and Deployment
- Both machine learning models were containerized using a single Dockerfile, simplifying the deployment process.
- With a reliable internet connection, the entire process of provisioning an instance and deploying the models was accomplished in less than 15 min.
- The rapid deployment showcases the workflow’s efficiency in making complex machine learning-based hydrological models accessible as web services.
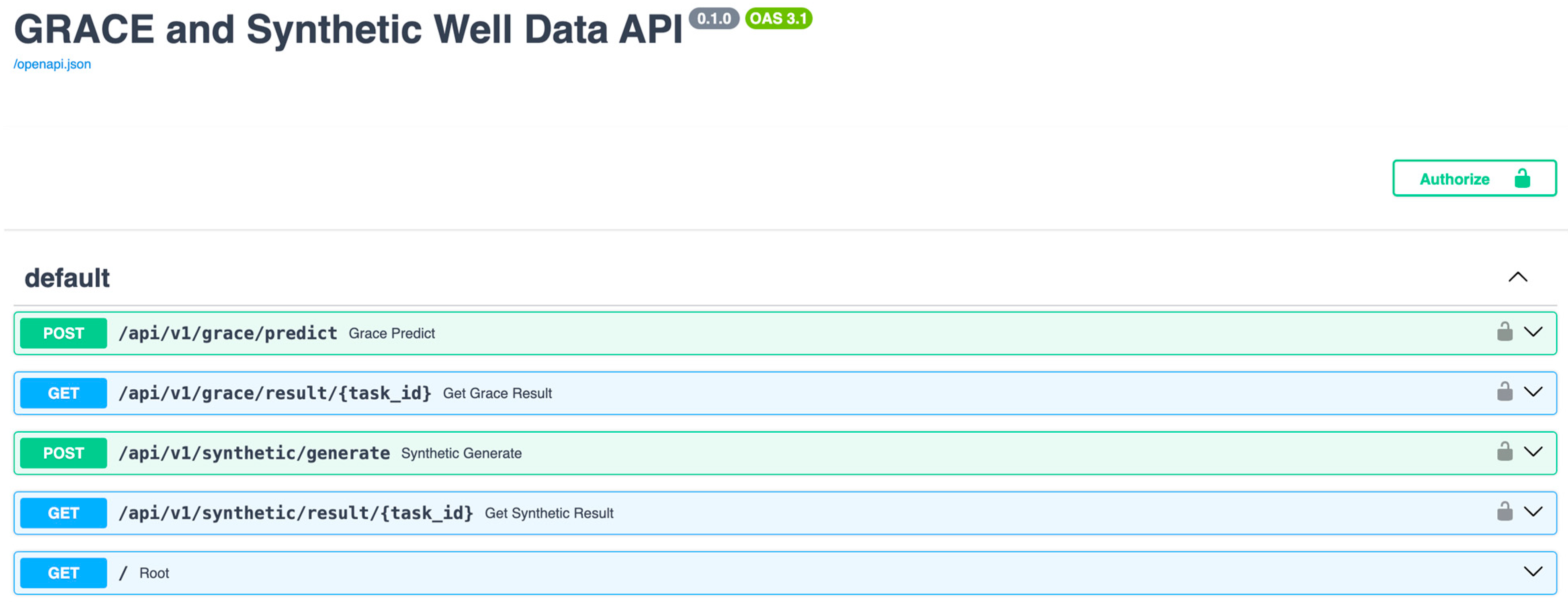
3.1.2. User Interface and Functionality
- Interactive API documentation with OpenAPI (Swagger) UI.
- Clear separation of endpoints for each model.
- User-friendly forms for input parameter submission.
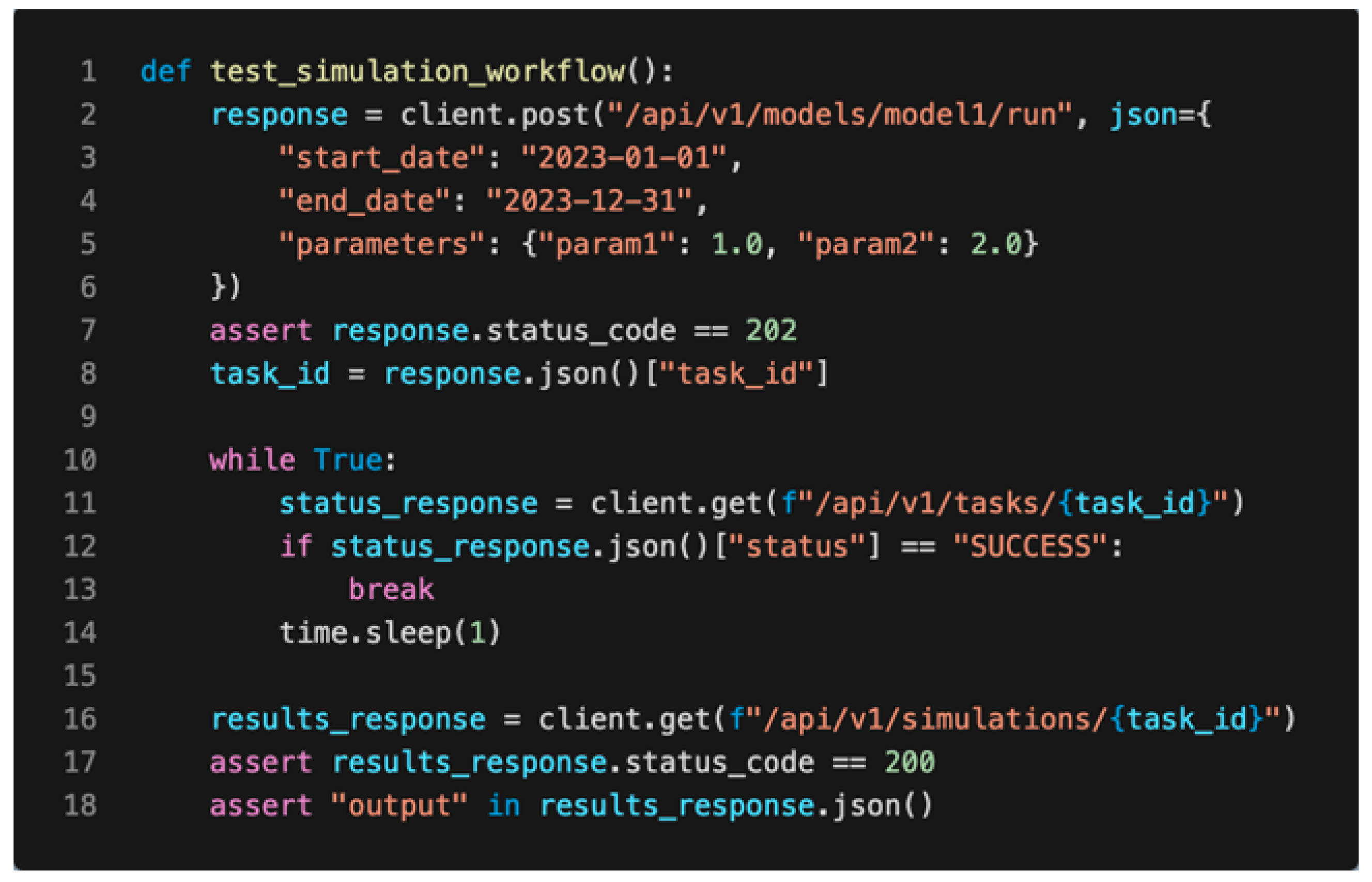
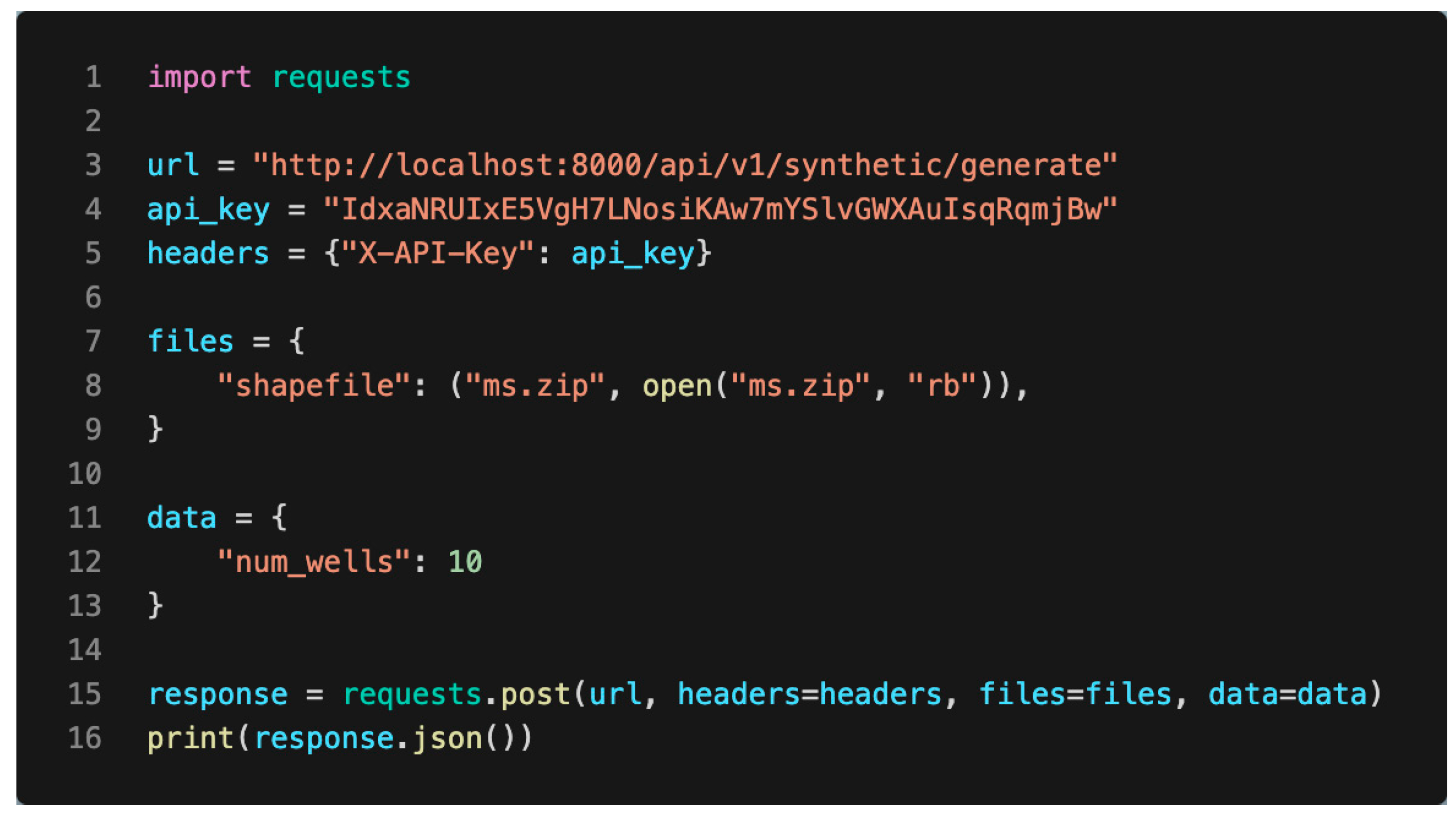
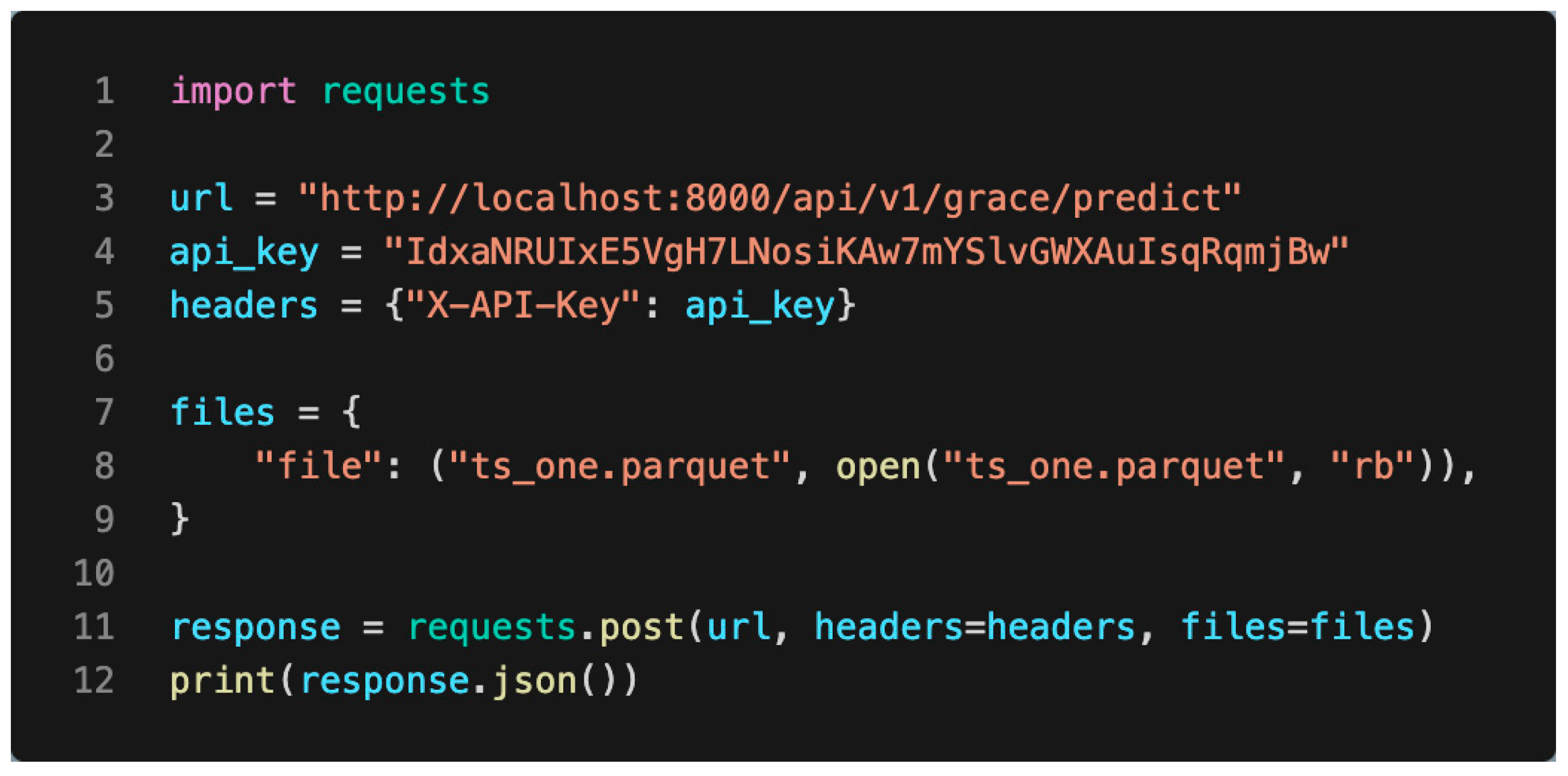
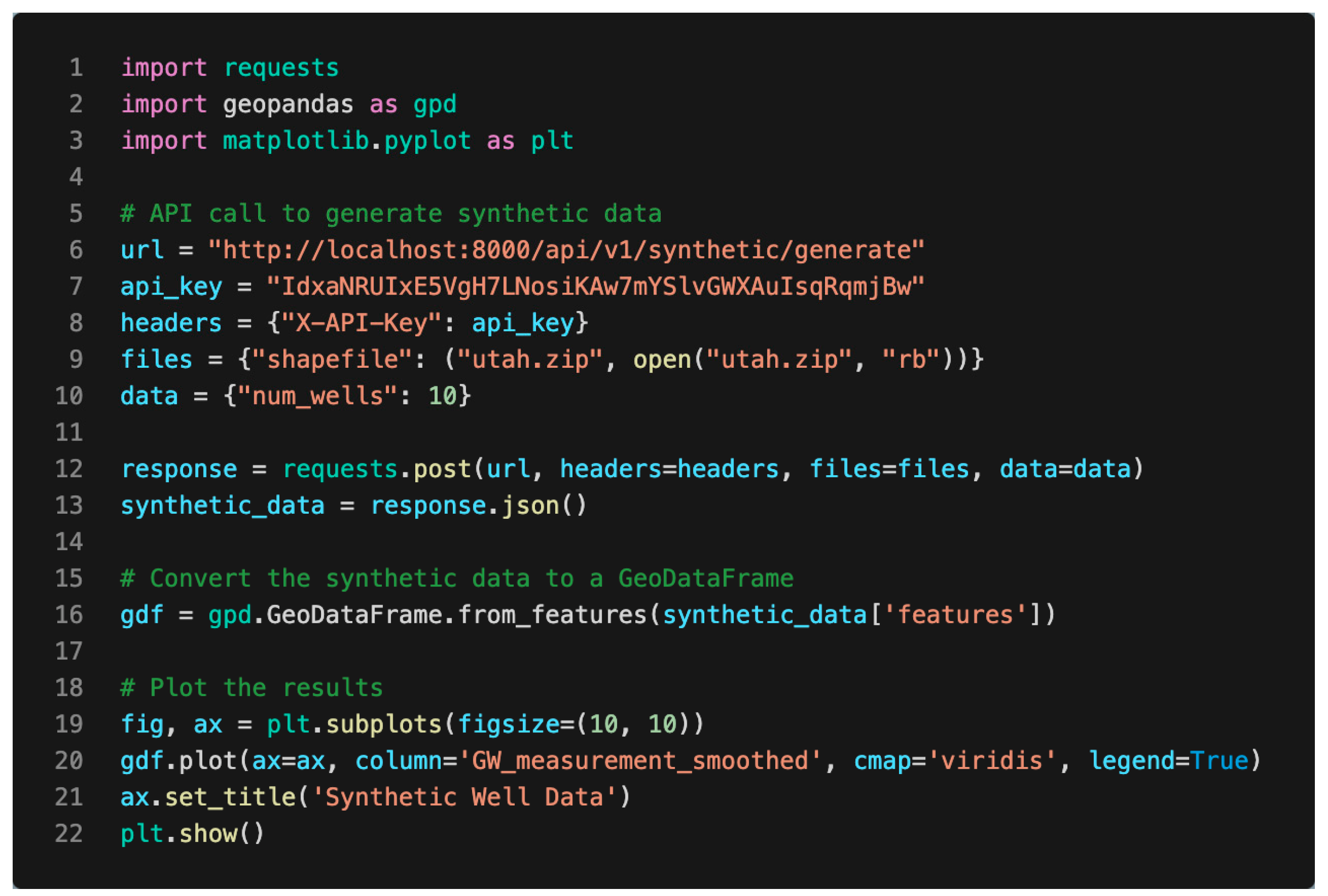
3.1.3. API Integration Examples
3.1.4. Integration with Developer Applications
3.2. Case Study 2: Web API for MODFLOW Groundwater Model
3.2.1. Implementation and Deployment
- Deployment time was comparable to the machine learning models in Case Study 1, taking approximately 15 min.
- This rapid deployment showcases the workflow’s effectiveness in making complex numerical hydrological models accessible as web services.
3.2.2. API Structure and Functionality
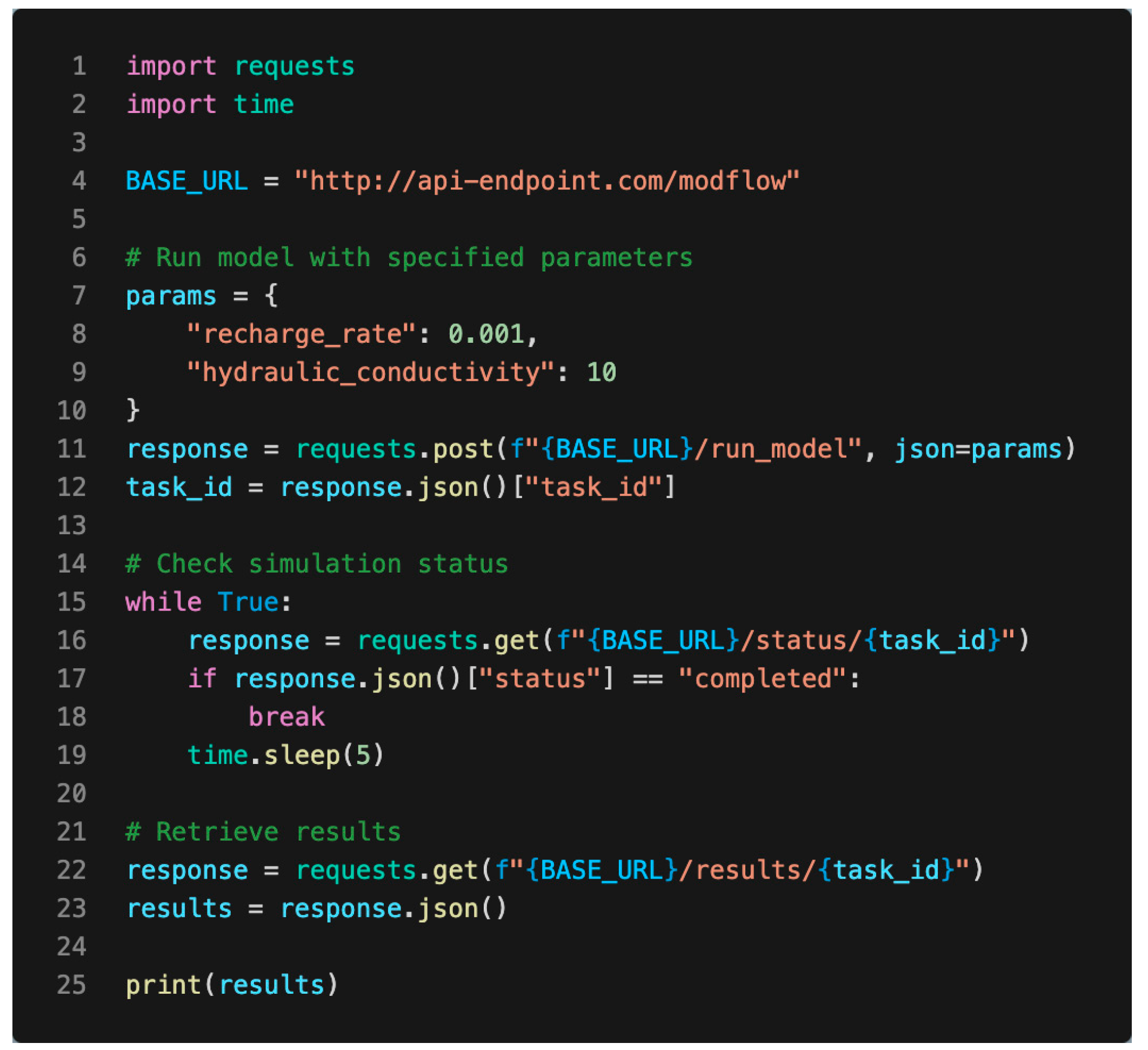
- A run_model endpoint that accepts parameters such as recharge rate and hydraulic conductivity.
- An endpoint to track the progress of model runs.
- A results retrieval endpoint for accessing simulation outputs.
3.2.3. Integration with Developer Applications
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zehe, E.; Sivapalan, M. Towards a New Generation of Hydrological Process Models for the Meso-Scale: An Introduction. Hydrol. Earth Syst. Sci. 2007, 10, 981–996. [Google Scholar] [CrossRef]
- Asgari, M.; Yang, W.; Lindsay, J.; Tolson, B.; Dehnavi, M.M. A Review of Parallel Computing Applications in Calibrating Watershed Hydrologic Models. Environ. Model. Softw. 2022, 151, 105370. [Google Scholar] [CrossRef]
- Singh, V.P. Hydrologic Modeling: Progress and Future Directions. Geosci. Lett. 2018, 5, 15. [Google Scholar] [CrossRef]
- SWAT: Model Use, Calibration, and Validation. Available online: https://digitalcommons.unl.edu/biosysengfacpub/406/ (accessed on 8 July 2024).
- Singh, J.; Knapp, H.V.; Arnold, J.G.; Demissie, M. Hydrological Modeling of the Iroquois River Watershed Using Hspf and Swat1. JAWRA J. Am. Water Resour. Assoc. 2005, 41, 343–360. [Google Scholar] [CrossRef]
- Harbaugh, A.W.; McDonald, M.G. User’s Documentation for MODFLOW-96, an Update to the U.S. Geological Survey Modular Finite-Difference Ground-Water Flow Model; U.S. Geological Survey; Branch of Information Services: Reston, VA, USA, 1996.
- Thakur, J.K.; Singh, S.K.; Ekanthalu, V.S. Integrating Remote Sensing, Geographic Information Systems and Global Positioning System Techniques with Hydrological Modeling. Appl. Water Sci. 2017, 7, 1595–1608. [Google Scholar] [CrossRef]
- Lee, S.; Hyun, Y.; Lee, S.; Lee, M.-J. Groundwater Potential Mapping Using Remote Sensing and GIS-Based Machine Learning Techniques. Remote Sens. 2020, 12, 1200. [Google Scholar] [CrossRef]
- Ashraf, A.; Ahmad, Z.; Ashraf, A.; Ahmad, Z. Integration of Groundwater Flow Modeling and GIS. In Water Resources Management and Modeling; IntechOpen: London, UK, 2012; ISBN 978-953-51-0246-5. [Google Scholar]
- Xu, X.; Li, J.; Tolson, B.A. Progress in Integrating Remote Sensing Data and Hydrologic Modeling. Prog. Phys. Geogr. Earth Environ. 2014, 38, 464–498. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Waller, S.T. Remote Sensing Methods for Flood Prediction: A Review. Sensors 2022, 22, 960. [Google Scholar] [CrossRef]
- Choi, M.; Jacobs, J.M.; Anderson, M.C.; Bosch, D.D. Evaluation of Drought Indices via Remotely Sensed Data with Hydrological Variables. J. Hydrol. 2013, 476, 265–273. [Google Scholar] [CrossRef]
- Nobre, R.C.M.; Rotunno Filho, O.C.; Mansur, W.J.; Nobre, M.M.M.; Cosenza, C.A.N. Groundwater Vulnerability and Risk Mapping Using GIS, Modeling and a Fuzzy Logic Tool. J. Contam. Hydrol. 2007, 94, 277–292. [Google Scholar] [CrossRef]
- Hussein, E.A.; Thron, C.; Ghaziasgar, M.; Bagula, A.; Vaccari, M. Groundwater Prediction Using Machine-Learning Tools. Algorithms 2020, 13, 300. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Anaraki, M.V.; Farzin, S.; Mousavi, S.-F.; Karami, H. Uncertainty Analysis of Climate Change Impacts on Flood Frequency by Using Hybrid Machine Learning Methods. Water Resour. Manag. 2021, 35, 199–223. [Google Scholar] [CrossRef]
- Alizamir, M.; Kisi, O.; Zounemat-Kermani, M. Modelling Long-Term Groundwater Fluctuations by Extreme Learning Machine Using Hydro-Climatic Data. Hydrol. Sci. J. 2018, 63, 63–73. [Google Scholar] [CrossRef]
- Swain, N.R.; Christensen, S.D.; Snow, A.D.; Dolder, H.; Espinoza-Dávalos, G.; Goharian, E.; Jones, N.L.; Nelson, E.J.; Ames, D.P.; Burian, S.J. A New Open Source Platform for Lowering the Barrier for Environmental Web App Development. Environ. Model. Softw. 2016, 85, 11–26. [Google Scholar] [CrossRef]
- Rocklin, M. Dask: Parallel Computation with Blocked Algorithms and Task Scheduling. In Proceedings of the Python in Science Conferences (SciPy 2015), Austin, TX, USA, 6–12 July 2015; pp. 126–132. [Google Scholar]
- Erickson, R.A.; Fienen, M.N.; McCalla, S.G.; Weiser, E.L.; Bower, M.L.; Knudson, J.M.; Thain, G. Wrangling Distributed Computing for High-Throughput Environmental Science: An Introduction to HTCondor. PLoS Comput. Biol. 2018, 14, e1006468. [Google Scholar] [CrossRef]
- Christensen, S.D.; Swain, N.R.; Jones, N.L.; Nelson, E.J.; Snow, A.D.; Dolder, H.G. A Comprehensive Python Toolkit for Accessing High-Throughput Computing to Support Large Hydrologic Modeling Tasks. JAWRA J. Am. Water Resour. Assoc. 2017, 53, 333–343. [Google Scholar] [CrossRef]
- Horsburgh, J.S.; Morsy, M.M.; Castronova, A.M.; Goodall, J.L.; Gan, T.; Yi, H.; Stealey, M.J.; Tarboton, D.G. HydroShare: Sharing Diverse Environmental Data Types and Models as Social Objects with Application to the Hydrology Domain. JAWRA J. Am. Water Resour. Assoc. 2016, 52, 873–889. [Google Scholar] [CrossRef]
- Horsburgh, J.; Tarboton, D.; Schreuders, K.; Maidment, D.; Zaslavsky, I.; Valentine, D. Hydroserver: A Platform for Publishing Space-Time Hydrologic Datasets. In Proceedings of the AWRA 2010 Spring Specialty Conference: GIS and Water Resources VI, Orlando, FL, USA, 29–31 March 2010; pp. 1–6. [Google Scholar]
- Erazo Ramirez, C.; Sermet, Y.; Molkenthin, F.; Demir, I. HydroLang: An Open-Source Web-Based Programming Framework for Hydrological Sciences. Environ. Model. Softw. 2022, 157, 105525. [Google Scholar] [CrossRef]
- Gichamo, T.Z.; Sazib, N.S.; Tarboton, D.G.; Dash, P. HydroDS: Data Services in Support of Physically Based, Distributed Hydrological Models. Environ. Model. Softw. 2020, 125, 104623. [Google Scholar] [CrossRef]
- Ramirez, C.E.; Sermet, Y.; Demir, I. HydroCompute: An Open-Source Web-Based Computational Library for Hydrology and Environmental Sciences. Environ. Model. Softw. 2024, 175, 106005. [Google Scholar] [CrossRef]
- de Sousa, L.M.; de Jesus, J.M.; Čepicky, J.; Kralidis, A.T.; Huard, D.; Ehbrecht, C.; Barreto, S.; Eberle, J. PyWPS: Overview, New Features in Version 4 and Existing Implementations. Open Geospat. Data Softw. Stand. 2019, 4, 13. [Google Scholar] [CrossRef]
- FastAPI. Available online: https://fastapi.tiangolo.com/ (accessed on 21 June 2024).
- Boettiger, C. An Introduction to Docker for Reproducible Research. SIGOPS Oper. Syst. Rev. 2015, 49, 71–79. [Google Scholar] [CrossRef]
- Ibrahim, M.H.; Sayagh, M.; Hassan, A.E. A Study of How Docker Compose Is Used to Compose Multi-Component Systems. Empir. Softw. Eng. 2021, 26, 128. [Google Scholar] [CrossRef]
- Skorpil, V.; Oujezsky, V. Parallel Genetic Algorithms’ Implementation Using a Scalable Concurrent Operation in Python. Sensors 2022, 22, 2389. [Google Scholar] [CrossRef]
- Williams, J. RabbitMQ in Action: Distributed Messaging for Everyone; Simon and Schuster: New York City, NY, USA, 2012; ISBN 978-1-63835-384-3. [Google Scholar]
- Silva, M.D.D.; Tavares, H.L. Redis Essentials; Packt Publishing Ltd.: Birmingham, UK, 2015; ISBN 978-1-78439-608-4. [Google Scholar]
- Principled Design of the Modern Web Architecture|ACM Transactions on Internet Technology. Available online: https://dl.acm.org/doi/abs/10.1145/514183.514185 (accessed on 9 July 2024).
- Pulla, S.T.; Yasarer, H.; Yarbrough, L.D. GRACE Downscaler: A Framework to Develop and Evaluate Downscaling Models for GRACE. Remote Sens. 2023, 15, 2247. [Google Scholar] [CrossRef]
- Pulla, S.T.; Yasarer, H.; Yarbrough, L.D. Synthetic Time Series Data in Groundwater Analytics: Challenges, Insights, and Applications. Water 2024, 16, 949. [Google Scholar] [CrossRef]
- FloPy Workflows for Creating Structured and Unstructured MODFLOW Models—Hughes—2024—Groundwater—Wiley Online Library. Available online: https://ngwa.onlinelibrary.wiley.com/doi/10.1111/gwat.13327 (accessed on 9 July 2024).
- Bakker, M.; Post, V.; Langevin, C.D.; Hughes, J.D.; White, J.T.; Starn, J.J.; Fienen, M.N. Scripting MODFLOW Model Development Using Python and FloPy. Groundwater 2016, 54, 733–739. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pulla, S.T.; Yasarer, H.; Yarbrough, L.D. Transforming Hydrology Python Packages into Web Application Programming Interfaces: A Comprehensive Workflow Using Modern Web Technologies. Water 2024, 16, 2609. https://doi.org/10.3390/w16182609
Pulla ST, Yasarer H, Yarbrough LD. Transforming Hydrology Python Packages into Web Application Programming Interfaces: A Comprehensive Workflow Using Modern Web Technologies. Water. 2024; 16(18):2609. https://doi.org/10.3390/w16182609
Chicago/Turabian StylePulla, Sarva T., Hakan Yasarer, and Lance D. Yarbrough. 2024. "Transforming Hydrology Python Packages into Web Application Programming Interfaces: A Comprehensive Workflow Using Modern Web Technologies" Water 16, no. 18: 2609. https://doi.org/10.3390/w16182609
APA StylePulla, S. T., Yasarer, H., & Yarbrough, L. D. (2024). Transforming Hydrology Python Packages into Web Application Programming Interfaces: A Comprehensive Workflow Using Modern Web Technologies. Water, 16(18), 2609. https://doi.org/10.3390/w16182609