






Customer Complaints-Based Water Quality Analysis


Abstract
:1. Introduction
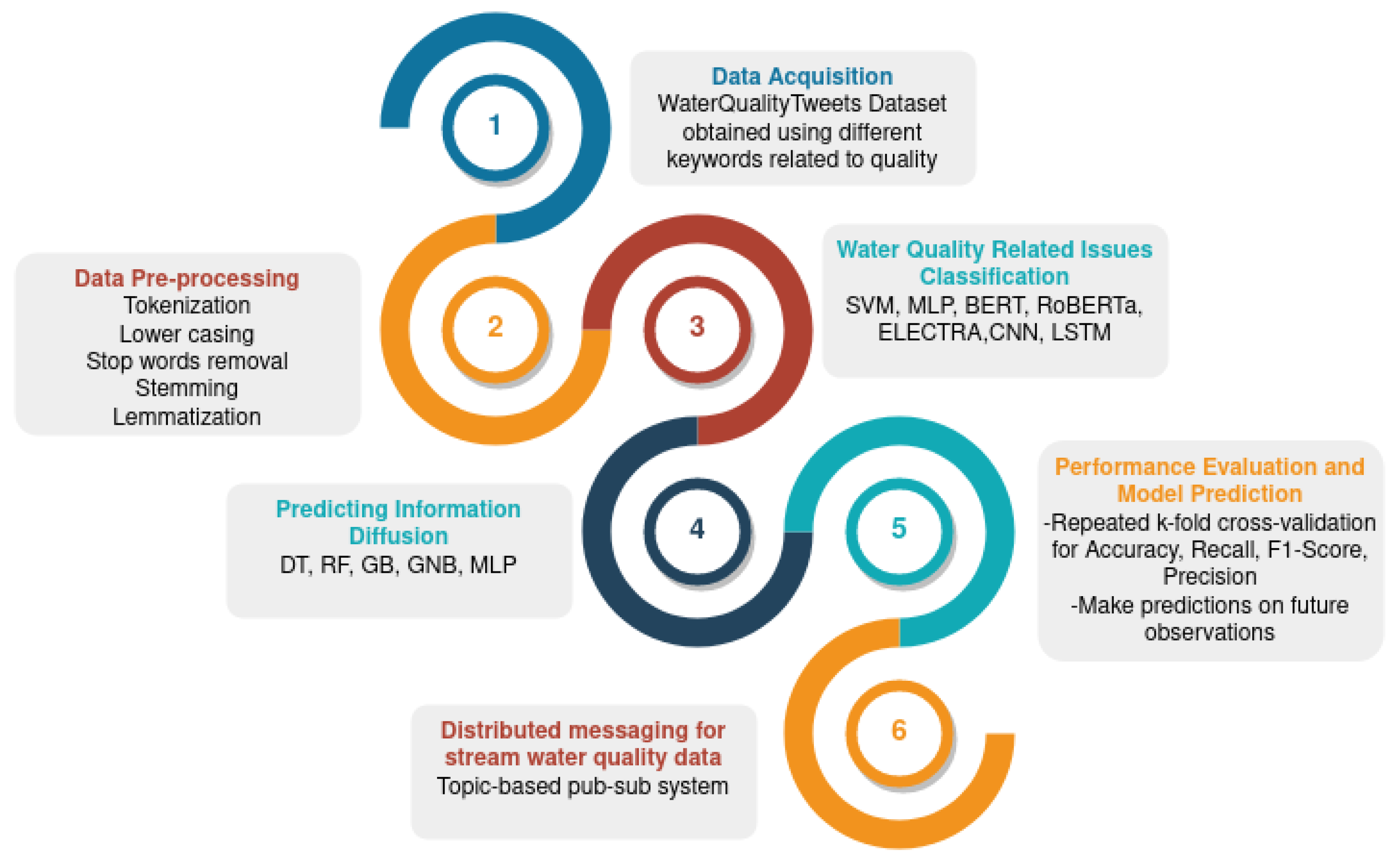
- We collect a new dataset, WaterQualityTweets, to include different water quality issues specified by the EPA.
- We proceed with two stages of classification for these issues.
- Predicting information diffusion on customer complaints is proposed.
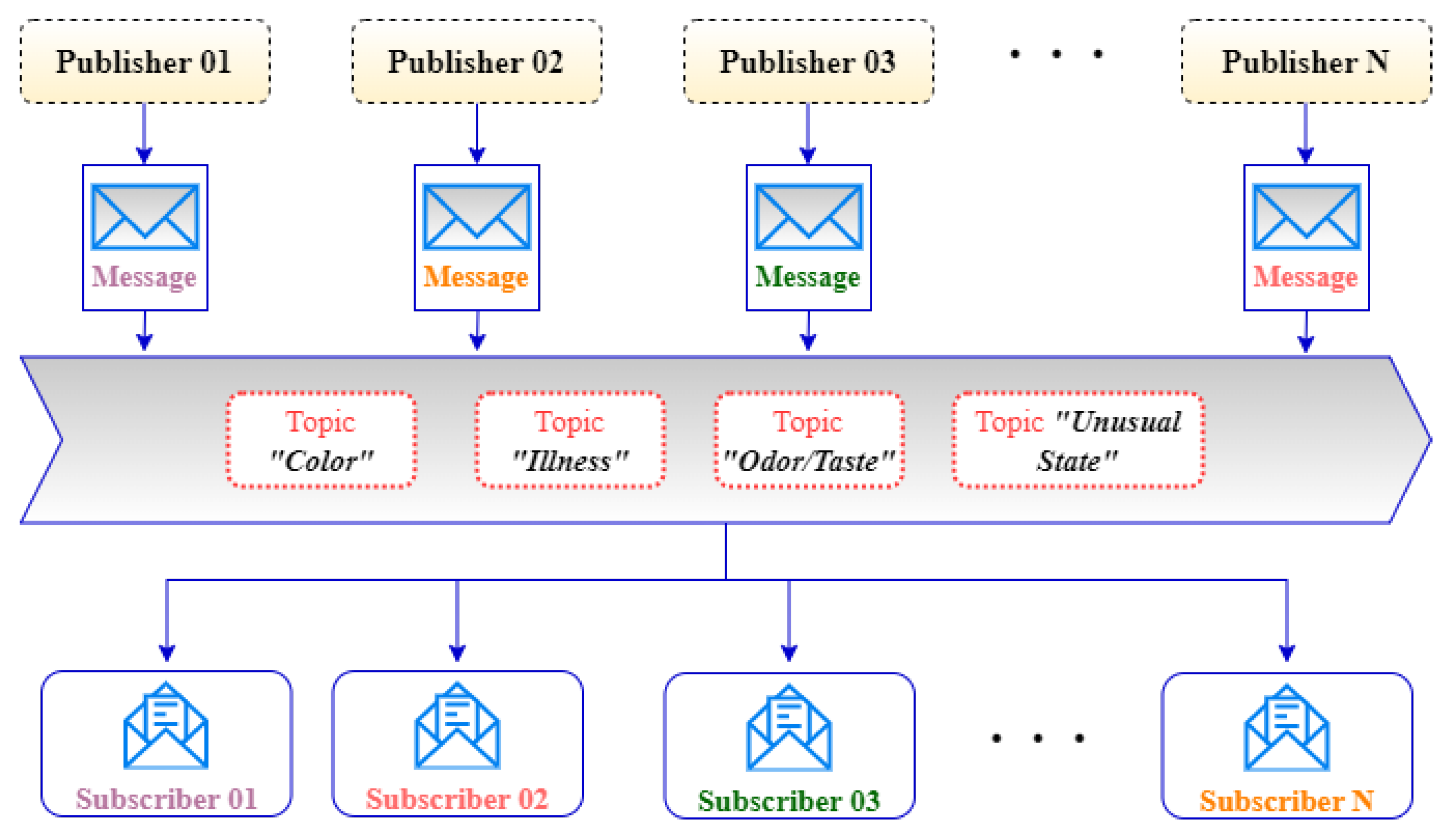
- A scalable messaging system enables different water quality-related issues to be sent to different subscribers.
2. Related Work
2.1. The Importance of Social Media in Water Quality
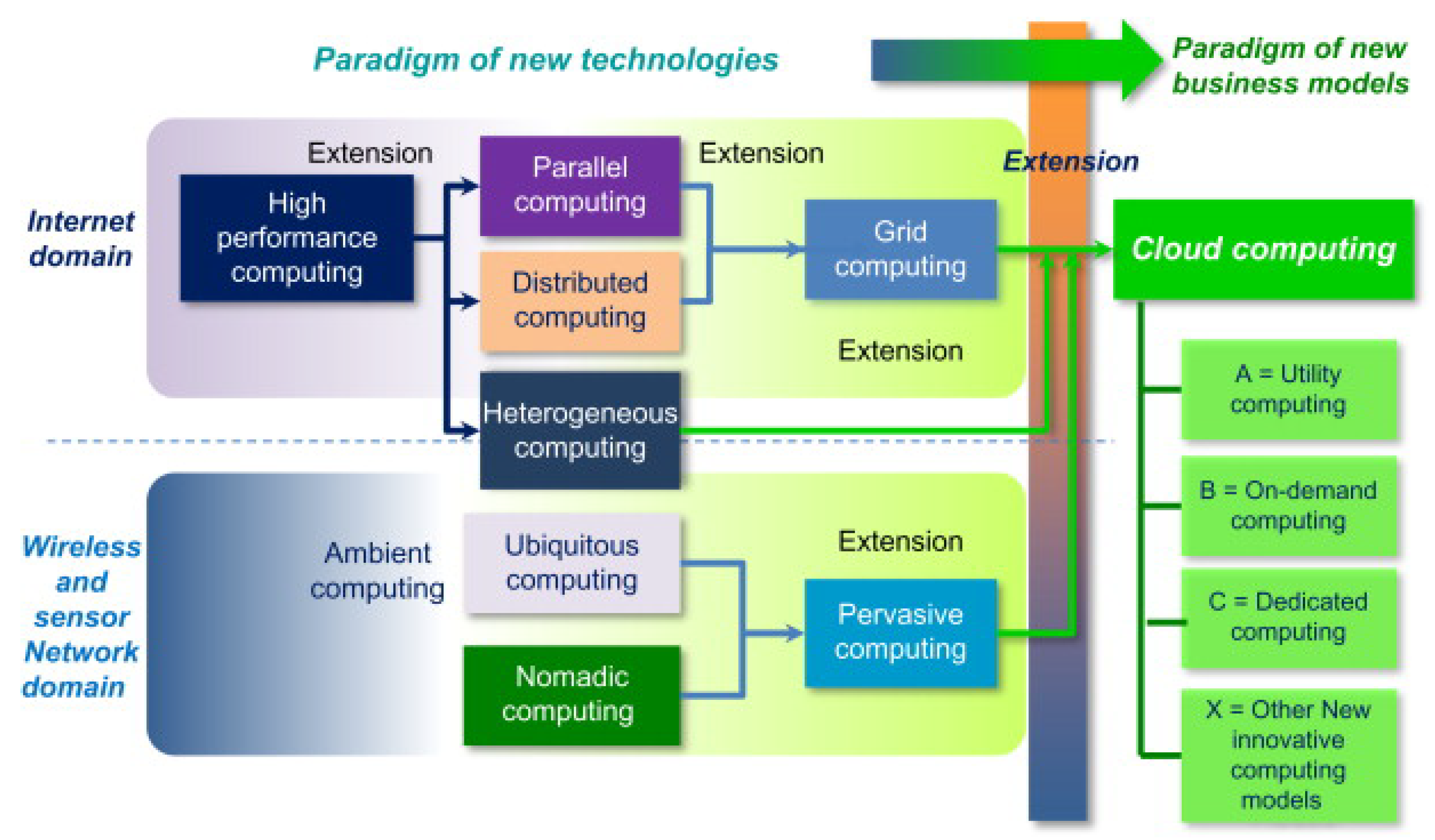
2.2. Distributed Systems in Water Quality
2.3. Predicting Information Diffusion
3. Materials and Methods
3.1. Data Acquisition
3.2. Data Pre-Processing
3.3. Text Classification
3.3.1. BERT
3.3.2. RoBERTa
3.3.3. ELECTRA
3.3.4. SVM
3.3.5. CNN
3.3.6. MLP
3.3.7. LSTM
3.4. Distributed Messaging for Stream Water Quality Data
4. Experimental Results and Discussion
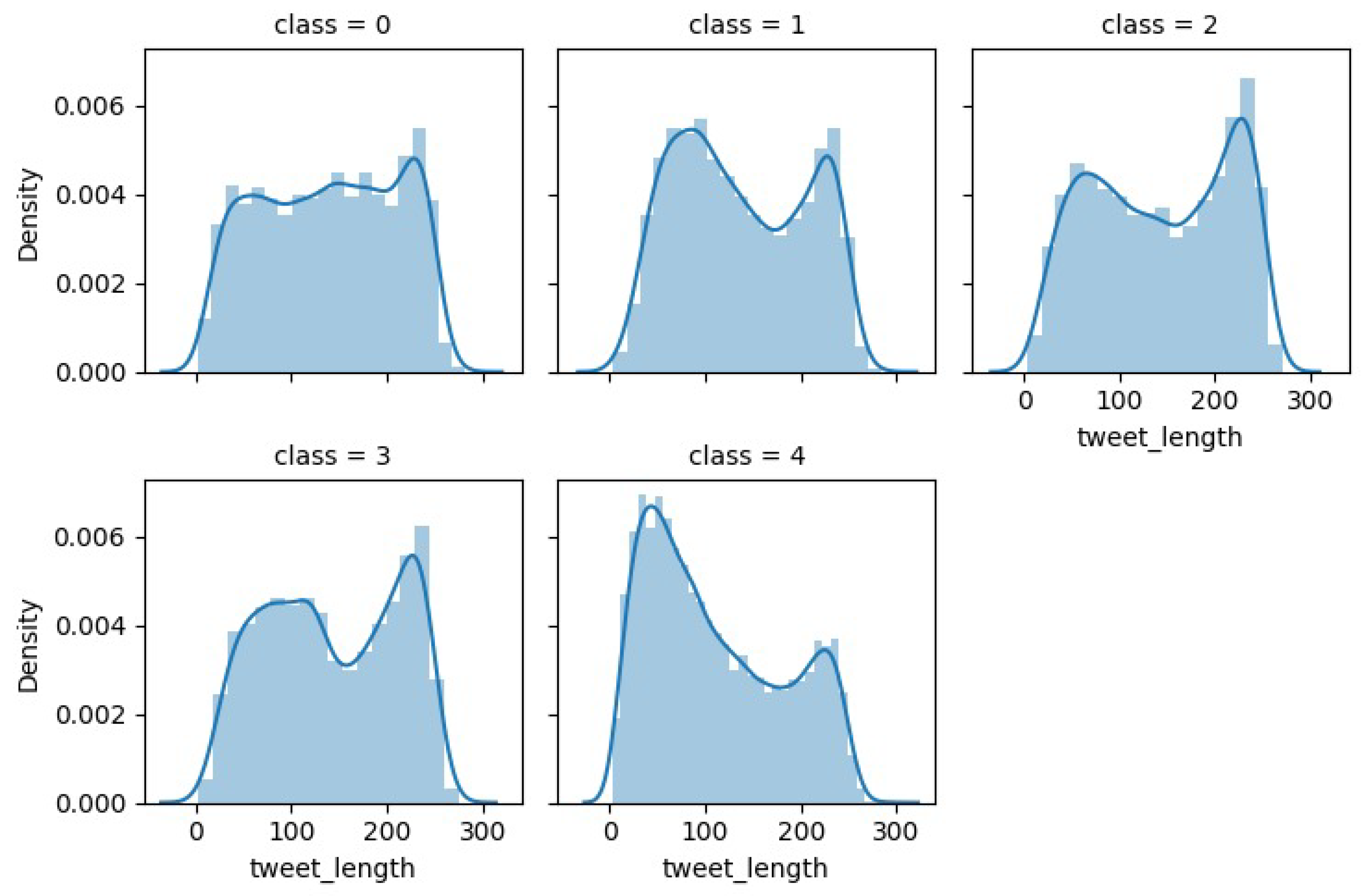
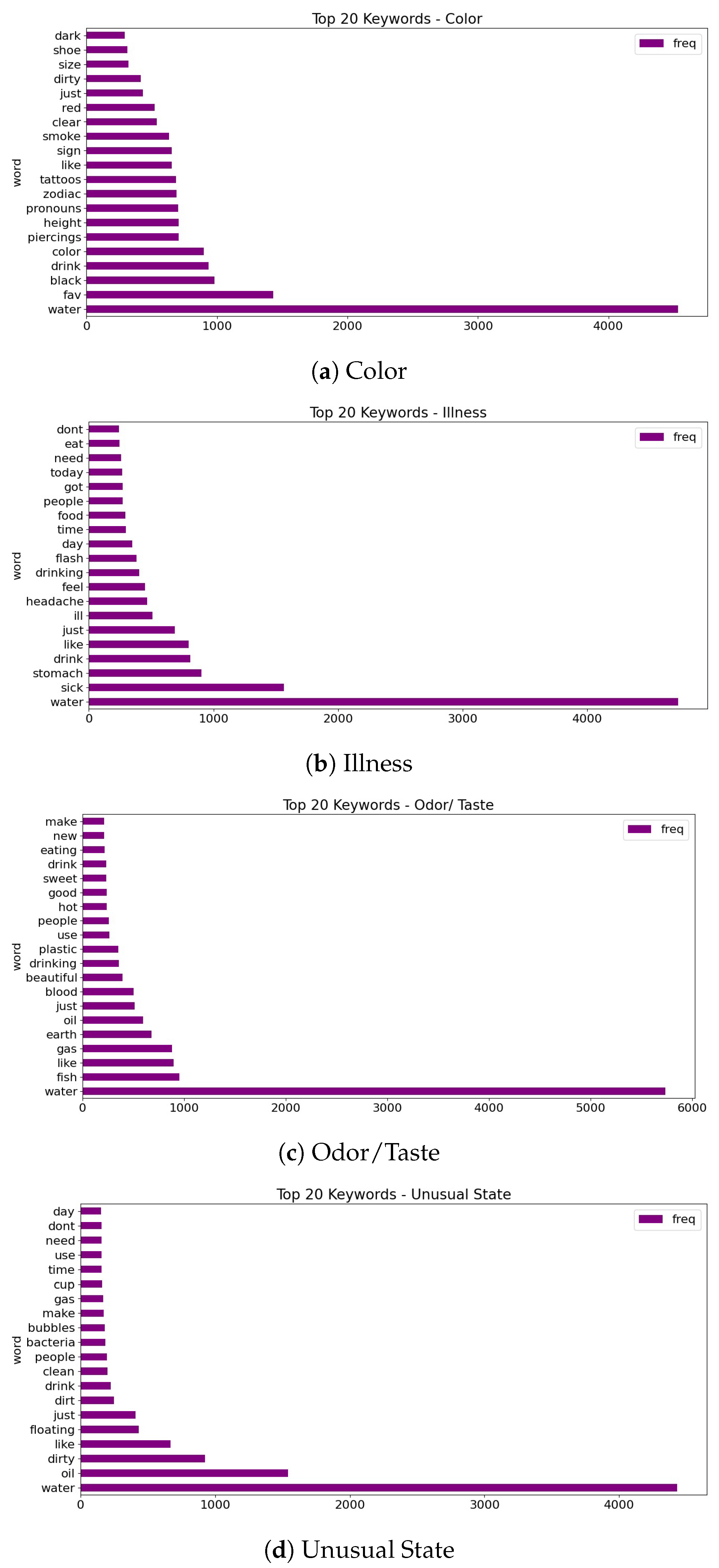
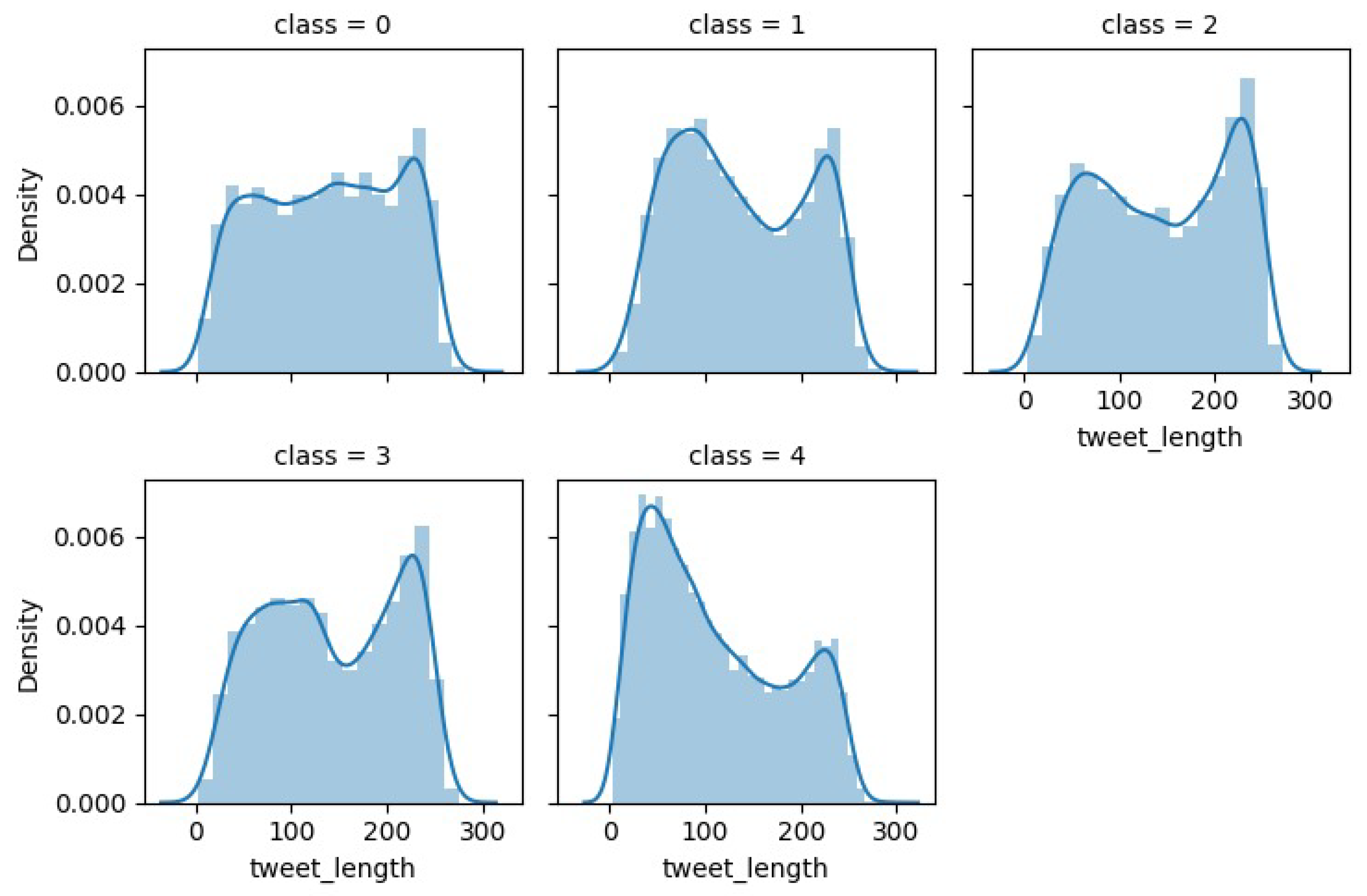
4.1. Exploratory Data Analysis on WaterQualityTweets Dataset
4.2. Performance Metrics
4.3. Binary Classification
4.4. Multi-Class Classification
4.5. Predicting Information Diffusion on WaterQualityTweets
4.6. Comparison with the State-of-the-Art Work
5. Conclusions
- Explainability in water-management systems refers to the ability to explain the decisions and predictions that have been made by an AI-based system. Explainability can provide insight into why and how an AI-based system has arrived at a certain decision, enabling users to evaluate the accuracy and reliability of the system. This can be used by water-management teams to better identify areas of concern and inform decisions about how best to allocate resources and solve issues related to water quality, safety, and sustainability. Recent initiatives to increase black-box models’ explainability lie under the purview of XAI research.
- Data visualization is the use of visual components to effectively communicate the relevance of large datasets and to find undiscovered data trends. Charts, graphs, maps, tables, and other visual representations of data are all examples of data visualization. Interactive data visualization, on the other hand, allows users to directly alter plot elements and create connections between several plots. Decision-makers can more easily and swiftly understand analytical data with the help of data visualization, especially those without a background in computer science or statistical analysis. In most cases, the graphical user interface (GUI) is furnished by the user interface layer of water-management systems, allowing users to export, view, and summarize data, along with editing the data quality.
- The size of datasets is expanding quickly at a rate of millions per second. To extract knowledge or make an accurate prediction, integrating, analyzing, and mining enormous amounts of data requires an effective and efficient framework and an algorithm. Due to the continuous evolution of data streams, predicting water quality issues and monitoring water quality at high speed are crucial challenges. Most current and traditional techniques rely significantly on stationary data, and it can take a centralized algorithm hours or even days to compute and identify accurate results. Thus, parallel and distributed computing is critical in reducing the execution time, which can fit the need for real-time or near-real-time detection and monitoring.
- Utilizing the additional data offered in the form of images and meta-data to improve the framework’s efficiency.
- Implementing advanced fusion schemes through the assignment of merit-based weights to the contributing models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Del Vecchio, P.; Mele, G.; Passiante, G.; Vrontis, D.; Fanuli, C. Detecting customers knowledge from social media big data: Toward an integrated methodological framework based on netnography and business analytics. J. Knowl. Manag. 2020, 24, 799–821. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. Acm Sigkdd Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Quijano-Sánchez, L.; Cantador, I.; Cortés-Cediel, M.E.; Gil, O. Recommender systems for smart cities. Inf. Syst. 2020, 92, 101545. [Google Scholar] [CrossRef]
- Aguilera, U.; Peña, O.; Belmonte, O.; López-de Ipiña, D. Citizen-centric data services for smarter cities. Future Gener. Comput. Syst. 2017, 76, 234–247. [Google Scholar] [CrossRef]
- Komninos, N.; Bratsas, C.; Kakderi, C.; Tsarchopoulos, P. Smart city ontologies: Improving the effectiveness of smart city applications. J. Smart Cities 2016, 1, 1–16. [Google Scholar] [CrossRef]
- Eken, S. An exploratory teaching program in big data analysis for undergraduate students. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4285–4304. [Google Scholar] [CrossRef]
- Premkumar, M.; Jangir, P.; Sowmya, R.; Elavarasan, R.M. Many-objective gradient-based optimizer to solve optimal power flow problems: Analysis and validations. Eng. Appl. Artif. Intell. 2021, 106, 104479. [Google Scholar] [CrossRef]
- Pandya, S.B.; Ravichandran, S.; Manoharan, P.; Jangir, P.; Alhelou, H.H. Multi-objective optimization framework for optimal power flow problem of hybrid power systems considering security constraints. IEEE Access 2022, 10, 103509–103528. [Google Scholar] [CrossRef]
- Mirjalili, S.; Jangir, P.; Mirjalili, S.Z.; Saremi, S.; Trivedi, I.N. Optimization of problems with multiple objectives using the multi-verse optimization algorithm. Knowl.-Based Syst. 2017, 134, 50–71. [Google Scholar] [CrossRef]
- Quadar, N.; Chehri, A.; Jeon, G.; Ahmad, A. Smart water distribution system based on IoT networks, a critical review. In Proceedings of the Human Centred Intelligent Systems: KES-HCIS 2020 Conference, Split, Croatia, 17–19 June 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 293–303. [Google Scholar]
- Nakhaei, M.; Akrami, M.; Gheibi, M.; Coronado, P.D.U.; Hajiaghaei-Keshteli, M.; Mahlknecht, J. A novel framework for technical performance evaluation of water distribution networks based on the water-energy nexus concept. Energy Convers. Manag. 2022, 273, 116422. [Google Scholar] [CrossRef]
- Daulat, S.; Rokstad, M.M.; Klein-Paste, A.; Langeveld, J.; Tscheikner-Gratl, F. Challenges of integrated multi-infrastructure asset management: A review of pavement, sewer, and water distribution networks. Struct. Infrastruct. Eng. 2022, 1–20. [Google Scholar] [CrossRef]
- Uddin, M.G.; Nash, S.; Olbert, A.I. A review of water quality index models and their use for assessing surface water quality. Ecol. Indic. 2021, 122, 107218. [Google Scholar] [CrossRef]
- Chen, Y.; Song, L.; Liu, Y.; Yang, L.; Li, D. A review of the artificial neural network models for water quality prediction. Appl. Sci. 2020, 10, 5776. [Google Scholar] [CrossRef]
- ÖzçelIk, I.; Iskefiyeli, M.; Balta, M.; Akpinar, K.O.; Toker, F.S. Center water: A secure testbed infrastructure proposal for waste and potable water management. In Proceedings of the 2021 9th International Symposium on Digital Forensics and Security (ISDFS), Elazig, Turkey, 8–29 June 2021; IEEE: Piscataway, NY, USA, 2021; pp. 1–7. [Google Scholar]
- Wade, T.J.; Pai, N.; Eisenberg, J.N.; Colford, J.M., Jr. Do US Environmental Protection Agency water quality guidelines for recreational waters prevent gastrointestinal illness? A systematic review and meta-analysis. Environ. Health Perspect. 2003, 111, 1102–1109. [Google Scholar] [CrossRef]
- WHO. Guidelines for Drinking-Water Quality; World Health Organization: Geneva, Switzerland, 2004; Volume 1. [Google Scholar]
- Yurtsever, M.M.E.; Shiraz, M.; Ekinci, E.; Eken, S. Comparing COVID-19 vaccine passports attitudes across countries by analysing Reddit comments. J. Inf. Sci. 2023, 01655515221148356. [Google Scholar] [CrossRef]
- Yavuz, A.; Eken, S. Gold Returns Prediction: Assessment based on Major Events. Eai Endorsed Trans. Scalable Inf. Syst. 2023. [CrossRef]
- Özgüven, Y.M.; Eken, S. Distributed messaging and light streaming system for combating pandemics. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 773–787. [Google Scholar] [CrossRef]
- Shao, Z.; Sumari, N.S.; Portnov, A.; Ujoh, F.; Musakwa, W.; Mandela, P.J. Urban sprawl and its impact on sustainable urban development: A combination of remote sensing and social media data. Geo-Spat. Inf. Sci. 2021, 24, 241–255. [Google Scholar] [CrossRef]
- Andreadis, S.; Gialampoukidis, I.; Bozas, A.; Moumtzidou, A.; Fiorin, R.; Lombardo, F.; Karakostas, A.; Norbiato, D.; Vrochidis, S.; Ferri, M.; et al. Watermm: Water quality in social multimedia task at mediaeval 2021. In Proceedings of the MediaEval 2021 Workshop, Online, 13–15 December 2021. [Google Scholar]
- Ahmad, K.; Ayub, M.; Khan, J.; Ahmad, N.; Al-Fuqaha, A. Social Media as an Instant Source of Feedback on Water Quality. IEEE Trans. Technol. Soc. 2022. [Google Scholar] [CrossRef]
- Hanif, M.; Khawar, A.; Tahir, M.A.; Rafi, M. Deep Learning Based Framework for Classification of Water Quality in Social Media Data. In Proceedings of the MediaEval 2021 Workshop, Online, 13–15 December 2021. [Google Scholar]
- Zheng, H.; Hong, Y.; Long, D.; Jing, H. Monitoring surface water quality using social media in the context of citizen science. Hydrol. Earth Syst. Sci. 2017, 21, 949–961. [Google Scholar] [CrossRef]
- Mallick, R.; Bajpai, S.P. Impact of social media on environmental awareness. In Environmental Awareness and the Role of Social Media; IGI Global: Hershey, PA, USA, 2019; pp. 140–149. [Google Scholar]
- Dewinta, A.; Irawan, M.I. Customer complaints clusterization of government drinking water company on social media twitter using text mining. In Proceedings of the 2021 3rd East Indonesia Conference on Computer and Information Technology (EIConCIT), Surabaya, Indonesia, 9–11 April 2021; IEEE: Piscataway, NY, USA, 2021; pp. 338–342. [Google Scholar]
- Shan, S.; Peng, J.; Wei, Y. Environmental Sustainability assessment 2.0: The value of social media data for determining the emotional responses of people to river pollution—A case study of Weibo (Chinese Twitter). Socio-Econ. Plan. Sci. 2021, 75, 100868. [Google Scholar] [CrossRef]
- Li, L.; Liu, X.; Zhang, X. Public attention and sentiment of recycled water: Evidence from social media text mining in China. J. Clean. Prod. 2021, 303, 126814. [Google Scholar] [CrossRef]
- Xiong, J.; Hswen, Y.; Naslund, J.A. Digital surveillance for monitoring environmental health threats: A case study capturing public opinion from Twitter about the 2019 Chennai water crisis. Int. J. Environ. Res. Public Health 2020, 17, 5077. [Google Scholar] [CrossRef]
- Sun, A.Y.; Scanlon, B.R. How can Big Data and machine learning benefit environment and water management: A survey of methods, applications, and future directions. Environ. Res. Lett. 2019, 14, 073001. [Google Scholar] [CrossRef]
- Balta, S.; Zavrak, S.; Eken, S. Real-Time Monitoring and Scalable Messaging of SCADA Networks Data: A Case Study on Cyber-Physical Attack Detection in Water Distribution System. In Proceedings of the International Congress of Electrical and Computer Engineering, Virtual, 9–12 February 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 203–215. [Google Scholar]
- Difallah, D.E.; Cudre-Mauroux, P.; McKenna, S.A. Scalable anomaly detection for smart city infrastructure networks. IEEE Internet Comput. 2013, 17, 39–47. [Google Scholar] [CrossRef]
- Wu, C.; Buyya, R. Cloud Data Centers and Cost Modeling: A Complete Guide to Planning, Designing and Building a Cloud Data Center; Morgan Kaufmann: Burlington, MA, USA, 2015. [Google Scholar]
- Ahmed, A.A.; Al Omari, S.; Awal, R.; Fares, A.; Chouikha, M. A distributed system for supporting smart irrigation using Internet of Things technology. Eng. Rep. 2021, 3, e12352. [Google Scholar] [CrossRef]
- Hoskins, A.; Stoianov, I. Infrasense: A distributed system for the continuous analysis of hydraulic transients. Procedia Eng. 2014, 70, 823–832. [Google Scholar] [CrossRef]
- Amoretti, M.; Rizzini, D.L.; Penzotti, G.; Caselli, S. A scalable distributed system for precision irrigation. In Proceedings of the 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; IEEE: Piscataway, NY, USA, 2020; pp. 338–343. [Google Scholar]
- Zoss, B.M.; Mateo, D.; Kuan, Y.K.; Tokić, G.; Chamanbaz, M.; Goh, L.; Vallegra, F.; Bouffanais, R.; Yue, D.K. Distributed system of autonomous buoys for scalable deployment and monitoring of large waterbodies. Auton. Robot. 2018, 42, 1669–1689. [Google Scholar] [CrossRef]
- Encinas, C.; Ruiz, E.; Cortez, J.; Espinoza, A. Design and implementation of a distributed IoT system for the monitoring of water quality in aquaculture. In Proceedings of the 2017 Wireless Telecommunications Symposium (WTS), Chicago, IL, USA, 26–28 April 2017; IEEE: Piscataway, NY, USA, 2017; pp. 1–7. [Google Scholar]
- Tuna, G.; Arkoc, O.; Gulez, K. Continuous monitoring of water quality using portable and low-cost approaches. Int. J. Distrib. Sens. Netw. 2013, 9, 249598. [Google Scholar] [CrossRef]
- Hong, L.; Dan, O.; Davison, B.D. Predicting popular messages in twitter. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 57–58. [Google Scholar]
- Naveed, N.; Gottron, T.; Kunegis, J.; Alhadi, A.C. Bad news travel fast: A content-based analysis of interestingness on twitter. In Proceedings of the 3rd International Web Science Conference, Koblenz, Germany, 14–17 June 2011; pp. 1–7. [Google Scholar]
- Shafiq, Z.; Liu, A. Cascade size prediction in online social networks. In Proceedings of the 2017 IFIP Networking Conference (IFIP Networking) and Workshops, Stockholm, Sweden, 12–16 June 2017; IEEE: Piscataway, NY, USA, 2017; pp. 1–9. [Google Scholar]
- Kupavskii, A.; Ostroumova, L.; Umnov, A.; Usachev, S.; Serdyukov, P.; Gusev, G.; Kustarev, A. Prediction of retweet cascade size over time. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 2335–2338. [Google Scholar]
- Mix, N.; George, A.; Haas, A. Social media monitoring for water quality surveillance and response systems. AWWA Water Sci. 2020, 112, 44. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Choi, H.; Kim, J.; Joe, S.; Gwon, Y. Evaluation of bert and albert sentence embedding performance on downstream nlp tasks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NY, USA, 2021; pp. 5482–5487. [Google Scholar]
- Gargiulo, F.; Minutolo, A.; Guarasci, R.; Damiano, E.; De Pietro, G.; Fujita, H.; Esposito, M. An ELECTRA-Based Model for Neural Coreference Resolution. IEEE Access 2022, 10, 75144–75157. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Chen, X.; Beaver, I.; Freeman, C. Fine-Tuning Language Models For Semi-Supervised Text Mining. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NY, USA, 2020; pp. 3608–3617. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Perera, N.; Nguyen, T.T.L.; Dehmer, M.; Emmert-Streib, F. Comparison of text mining models for food and dietary constituent named-entity recognition. Mach. Learn. Knowl. Extr. 2022, 4, 254–275. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27-29 July 1992; pp. 144–152. [Google Scholar]
- Vapnik, V.N. Adaptive and learning systems for signal processing communications, and control. Stat. Learn. Theory 1998, 244–245. [Google Scholar] [CrossRef]
- Smola, A.; Schölkopf, B. From regularization operators to support vector kernels. Adv. Neural Inf. Process. Syst. 1997, 10. [Google Scholar]
- Azimi-Pour, M.; Eskandari-Naddaf, H.; Pakzad, A. Linear and non-linear SVM prediction for fresh properties and compressive strength of high volume fly ash self-compacting concrete. Constr. Build. Mater. 2020, 230, 117021. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Hui, D.S.; Azhar, E.I.; Madani, T.A.; Ntoumi, F.; Kock, R.; Dar, O.; Ippolito, G.; Mchugh, T.D.; Memish, Z.A.; Drosten, C.; et al. The continuing 2019-nCoV epidemic threat of novel coronaviruses to global health—The latest 2019 novel coronavirus outbreak in Wuhan, China. Int. J. Infect. Dis. 2020, 91, 264–266. [Google Scholar] [CrossRef]
- Car, Z.; Baressi Šegota, S.; Andjelić, N.; Lorencin, I.; Mrzljak, V. Modeling the spread of COVID-19 infection using a multilayer perceptron. Comput. Math. Methods Med. 2020, 2020, 5714714. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. Adv. Neural Inf. Process. Syst. 1996, 9, 473–479. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Kreps, J.; Narkhede, N.; Rao, J. Kafka: A distributed messaging system for log processing. In Proceedings of the NetDB, Athens, Greece, 12–16 June 2011; Volume 11, pp. 1–7. [Google Scholar]
- Fabret, F.; Jacobsen, H.A.; Llirbat, F.; Pereira, J.; Ross, K.A.; Shasha, D. Filtering algorithms and implementation for very fast publish/subscribe systems. In Proceedings of the 2001 ACM SIGMOD International Conference on Management of Data, Santa Barbara, CA, USA, 21–24 May 2001; pp. 115–126. [Google Scholar]
- Eugster, P.T.; Guerraoui, R.; Sventek, J. Type-Based Publish/Subscribe. Ph.D. Thesis, Università della Svizzera Italiana (USI), Lugano, Switzerland, 2000. [Google Scholar]
- Said, N.; Ahmad, K.; Gul, A.; Ahmad, N.; Al-Fuqaha, A. Floods detection in twitter text and images. arXiv 2020, arXiv:2011.14943. [Google Scholar]
- Ayub, M.A.; Ahmad, K.; Ahmad, K.; Ahmad, N.; Al-Fuqaha, A. Nlp techniques for water quality analysis in social media content. arXiv 2021, arXiv:2112.11441. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Words to Search For—e.g., using ‘OR’, ‘AND’ | |||||
|---|---|---|---|---|---|
| General Terms (to be called G.T.) | |||||
| Drink water Water | Bad Wrong | Undrinkable | Problem Issue | ||
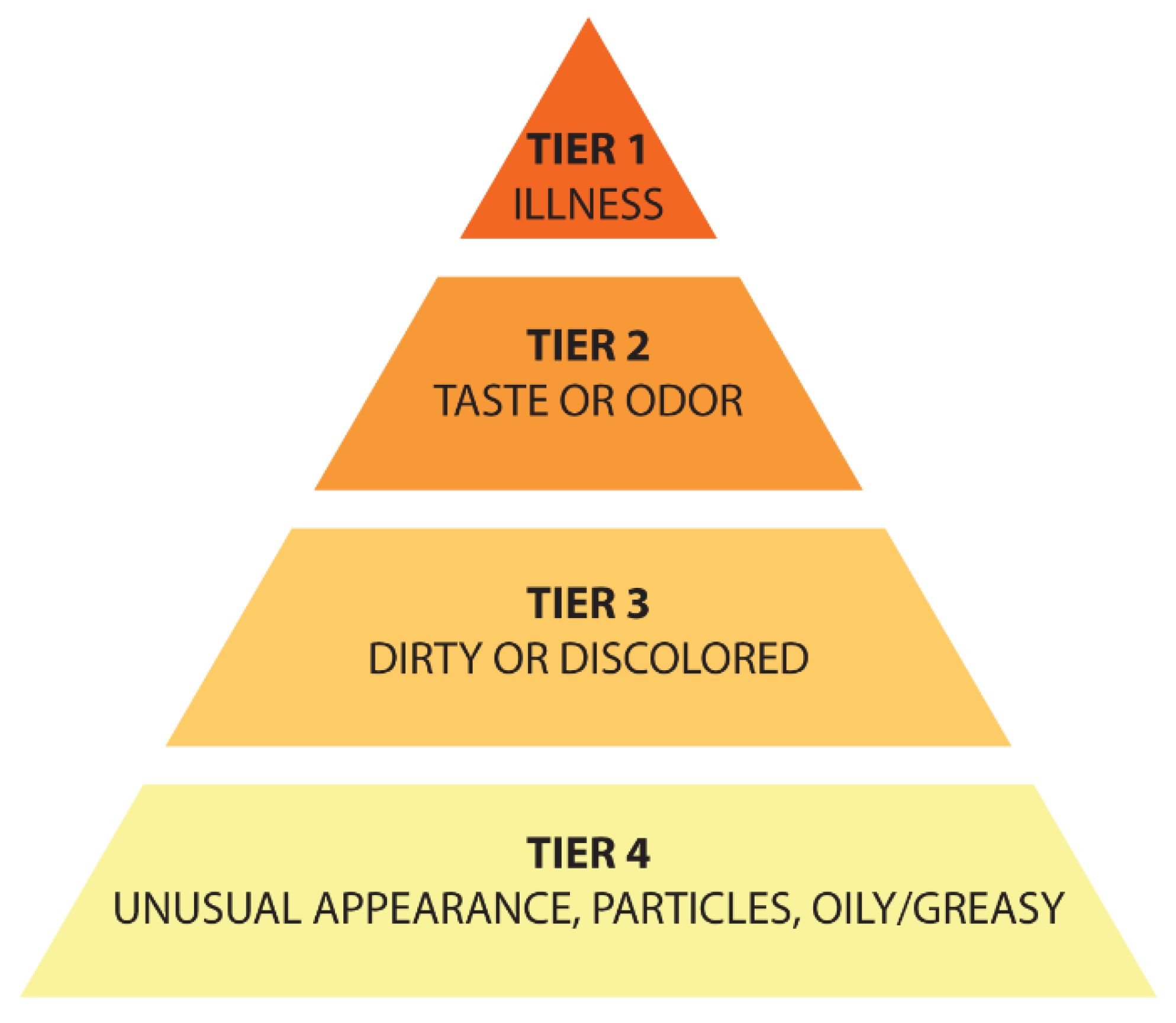
| Class 0—Color | |||||
| Color Colored Discolored | Dirty/dirt Unclear Muddy Chalky Blurry | Sludgy Slimy Lime Limy Gray/grey | Dark Red Black Brown Yellow | ||
| Class 1—Illness | |||||
| Illness Sick Ill Made me | Vomit Fire Stomach Megrim | Puke Spew Headache | Diarrhea Influenza Nausea | ||
| Class 2—Odor/Taste | |||||
| Smells like Tastes like Taste Odor Smell | Mold Mildy Rotten Ether Oil | Metal Petroleum Plastic Rust/rusty Chlorine | Rubber Sulfur Gas Chemical Septic | ||
| Class 3—Unusual State | |||||
| Looks Appears Unusual | Particles Stain Rust/rusty Oil/oily | Grease/Greasily Bacteria Bacterium | Aluvyon Specks Cloudy Floaters | ||
| Words to Exclude—e.g., using AND NOT | |||||
| Excellent Perfect Wonderful | Fabulous Fantastic Beautiful | Flower Good Fine | Sweet Pretty Clear Bright | ||
| Text | Class |
|---|---|
| My fear of flying has me checking the age of the plane and I saw it was 20 and now I feel worse. | unrelated |
| Reporter muddies the waters and complains about muddy water you are a big part of the problem. | related (color) |
| Yes, the healthy colon absorbs water but diarrhea indicates ill health. | related (illness) |
| I am washing my hands in this building and the water smells like rotten eggs. | related (odor/taste) |
| I feel like they should test that water now they have got a chance. It is probably full of bacteria. | related (unusual state) |
| Class | Number of Raw Data | After Pre-Processing |
|---|---|---|
| unrelated | 54,991 | 18,981 |
| color | 19,788 | 5032 |
| illness | 10,708 | 4825 |
| odor/taste | 22,038 | 5572 |
| unusual state | 20,415 | 4395 |
| Model | Parameters | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| SVM | LinearSVC | 0.9501 | 0.9501 | 0.9506 | 0.9504 |
| CNN | lr = 5 × 10−4, 1 × 10−3 Softmax+reLu | 0.85 | 0.8525 | 0.85 | 0.8475 |
| MLP | lr = 5 × 10−4 Softmax+reLu | 0.76 | 0.7625 | 0.7625 | 0.7575 |
| LSTM | lr = 5 × 10−4 Softmax+reLu | 0.95 | 0.945 | 0.945 | 0.95 |
| BERT | lr = 1 × 10−5 Batch size = 6 | 0.96 | 0.955 | 0.955 | 0.955 |
| RoBERTa | lr = 1 × 10−5 Batch size = 6 | 0.95 | 0.955 | 0.955 | 0.955 |
| ELECTRA | lr = 1 × 10−4 Batch size = 6 | 0.95 | 0.955 | 0.955 | 0.95 |
| Model | Parameters | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| SVM | LinearSVC | 0.80 | 0.80 | 0.80 | 0.80 |
| CNN | lr = 5 × 10−4 Softmax+reLu | 0.85 | 0.8525 | 0.85 | 0.8475 |
| MLP | lr = 5 × 10−4 Softmax + reLu | 0.76 | 0.7625 | 0.7625 | 0.7575 |
| BERT | lr = 1 × 10−5 Batch size = 32 | 0.83 | 0.835 | 0.84 | 0.8325 |
| RoBERTa | lr = 1 × 10−5 Batch size = 32 | 0.83 | 0.835 | 0.8375 | 0.83 |
| ELECTRA | lr = 1 × 10−4 Batch size = 6 | 0.83 | 0.835 | 0.83 | 0.8275 |
| Model | Parameters | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| DT | max_depth = 22 | 0.87 | 0.86 | 0.87 | 0.86 |
| RF | n_estimators = 200, n_jobs = −1, bootstrap = True | 0.87 | 0.87 | 0.87 | 0.86 |
| GB | learning_rate = 0.01, n_estimators = 80, max_depth = 10 | 0.87 | 0.87 | 0.87 | 0.86 |
| GNB | var_smoothing = 1 × 10−4 | 0.69 | 0.71 | 0.69 | 0.70 |
| MLP | random_state = 1, max_iter = 500, learning_rate = ïnvscaling | 0.75 | 0.73 | 0.75 | 0.74 |
| Ref | Models | Techniques and Methods | Data Type | Data Languages | Best Model Performance (F1 Score) |
|---|---|---|---|---|---|
| [23] | BERT | Particle Swarm Optimization (PSO) Genetic Algorithm (GA), Brute Force (BF) Nelder–Mead and Powell’s optimization | Text | Italian English | BERT: 0.81 BERT + BF: 0.85 |
| XLM-RoBERTa | |||||
| LSTM | |||||
| [24] | BERT | 1. task: text data + translation + binary classification 2. task: image + text | Text Visual | Italian English | BERT: 0.31 BERT + VGG16: 0.24 |
| VGG16 | |||||
| [73] | BOW | Text classification | Text Visual | Italian English | BOW: 0.77 |
| BERT | |||||
| ImageNet | Image classification | ImageNet: 0.75 | |||
| [74] | BERT | Binary cross entropy Adaptive Moments (Adam) optimizer | Text | × | BERT: 0.79 |
| XLM-RoBERTa | |||||
| LSTM | 3 layers: input, lstm, output | ||||
| Fusion Model | Late Fusion: 0.79 | ||||
| Our Study | SVM | The first stage: binary classification Learning rate: 1 × 10−5, batch size: 6 Max length: 128 | Text | English | BERT: 0.96 |
| CNN | |||||
| MLP | |||||
| LSTM | The second stage: multi-class classification Learning rate: 5 × 10−4, Softmax + relu activation function Categorical cross-entropy, Nadam optimizer | CNN: 0.8475 | |||
| BERT | |||||
| RoBERTA | |||||
| ELECTRA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balta Kaç, S.; Eken, S. Customer Complaints-Based Water Quality Analysis. Water 2023, 15, 3171. https://doi.org/10.3390/w15183171
Balta Kaç S, Eken S. Customer Complaints-Based Water Quality Analysis. Water. 2023; 15(18):3171. https://doi.org/10.3390/w15183171
Chicago/Turabian StyleBalta Kaç, Seda, and Süleyman Eken. 2023. "Customer Complaints-Based Water Quality Analysis" Water 15, no. 18: 3171. https://doi.org/10.3390/w15183171
APA StyleBalta Kaç, S., & Eken, S. (2023). Customer Complaints-Based Water Quality Analysis. Water, 15(18), 3171. https://doi.org/10.3390/w15183171