1. Introduction
The way a catchment releases and metabolizes a compound defines the export regime (or behavior) of the catchment regarding this compound. Export regimes can be classified as chemodynamic when concentration varies with discharge (positively or negatively), and as chemostatic when the concentration is not affected by discharge [
1,
2,
3,
4,
5,
6,
7]. Chemodynamic export regimes can be classified as dilution behavior and mobilization behavior. During rainfall, a catchment demonstrates dilution behavior if the compound concentration is diluted with high discharge. Contrarily, the catchment shows mobilization behavior if the compound concentration increases with discharge. This can occur for compounds mobilized by fast runoff components (e.g., nitrate by interflow, particle-bound pollutants by surface runoff) [
7]. On the other hand, a chemostatic export regime presents a washout of pollutants at a relatively constant concentration (the compound concentration varies only slightly with discharge).
One can characterize the export regime of an entire catchment by collecting water samples in the catchment river outlet together with river discharge measurements. However, budgetary restrictions usually limit field campaigns. For this reason, it is crucial to design sampling strategies effectively. Sampling strategies can follow either high- or low-frequency approaches. Low-frequency series (samples by week or month) have commonly been used to characterize the concentration–discharge (
C–
Q) relationship of a catchment [
4,
7,
8,
9]. For example, Godsey et al. [
4] used hydrochemical data of 59 sites, with more than 30 years of data, but with only five to seven water samples a year. Musolff et al. [
7] used 16-year time series of monthly and bi-monthly samples at gauging stations to predict export behavior. In comparison to low-frequency sampling, high-frequency sampling (e.g., hourly samples) decreases the uncertainty of export estimates [
10] and water quality parameters [
11]. Some examples of studies that use high-frequency sampling are Bowes et al. [
12], Evans and Davies [
13], Floury et al. [
14], Grimaldi et al. [
15], Jones et al. [
16], Liu et al. [
17], Ockenden et al. [
18], Rusjan et al. [
19], and Schwientek et al. [
20]. Nevertheless, both low- and high-frequency sampling approaches can provide insightful information on the catchment, e.g., [
3,
21].
Export regimes of a catchment are commonly described by a simple linear regression slope of log-concentrations (
) versus log-discharges (
) measured in the river at the catchment outlet. The slope value of this power-law relationship defines the export regime of the catchment. A slope of negative value corresponds to dilution-type catchments, and a slope of zero corresponds to the chemostatic type [
4], whereas the mobilization type shows a positive relationship between
and
[
3,
4,
5,
6,
7]. Therefore, linear regression can provide a beneficial water quality metric via the slope of
-
.
However, the catchment has memory of its past due to the involved time scales of runoff formation, contaminant release, and reactive catchment-scale transport [
13]. Many studies look at the effects of hysteresis on compound exports [
22,
23,
24,
25,
26]. Hysteresis means that concentrations depend not only on discharge but also on showing an apparent dependency on past concentration values. Several studies capture hysteresis metrics to explain hysteresis loops produced during storms [
27,
28,
29,
30]. Thus, many catchments show temporal hysteresis that defies linear regression assumptions [
31]. These hysteresis effects profoundly contradict the “residuals are independent errors” assumption that forms the basis of classical least squares regression. In simpler words, the remaining scatter of data points around the regression line should at least be uncorrelated with zero mean and a constant variance. Yet, temporal hysteresis means that the residuals are autocorrelated in time. With these assumptions violated, regression results can be suboptimal and biased, as well as foster incorrect conclusions.
To overcome the limitations of linear regression, different alternatives have been developed. For example, some methods are able to model
C–
Q relationships that vary with time, discharge, and season. One of these approaches is the WRTDS model [
32], which is extensively used by the United States Geological Survey (USGS). The WRTDS model can analyze long-term surface-water-quality datasets by using weighted regression of concentrations on time, discharge, and season. Thus, WRTDS aims at interpolating low-frequency concentration time series (often monthly) at the scale of discharge time series (often daily), but not the characterization of export regimes. Also, the sample collection period must be at least 20 years, and a minimum of 200 samples is needed. These conditions are seldom met in most water-quality time series.
A modified and improved version of WRTDS, which gets better predictions of riverine concentration and flux, was developed by Zhang et al. [
33] and Zhang & Ball [
34]. Another more recent alternative methodology is the two-sided affine power scaling relationship by Tunqui et al. [
35], which produced better results than the linear regression. Underwood et al. [
36] applied Bayesian inference to estimate segmented regression model parameters and identify the export regime. Qian et al. [
37] showed that a Bayesian approach could improve the predictions of nutrient loads.
Other recent studies have taken advantage of high-frequency time series to study the
C–
Q relationship. For example, Bieroza & Heathwaite [
22] studied the variability of the phosphorous
C–
Q relationship by applying fuzzy logic models, and looked into the hysteresis of the phosphorous export.
To provide information about the processes regulating the export, many recent studies have shown that sampling strategies based on events or seasonality are deeply advantageous [
5,
6,
22,
30,
34,
36,
38,
39,
40,
41,
42,
43]. These event studies were focused on discharge time series (e.g., recession time series) such as in Jachens et al. [
39], as well as combined with solute time series (e.g.,
C–
Q studies) such as in Knapp et al. [
5]. For example, Minaudo et al. [
40] introduced a new model to account for different temporal scales that correspond to fast and slow events (storms and seasonal, respectively). Their results showed that apparent
C–
Q relationships could not only be different, but even opposite depending on the scale considered. Other recent studies used autoregressive time-series models to fit high-frequency data to decipher the dynamics of compound exports [
16,
18].
Nevertheless, hysteresis effects can only be detected when high-frequency observations are taken, since they are overlooked with low-frequency strategies [
6,
13,
44]. Additionally, high-frequency measurements can be resource intensive (labor and economically) and challenging to apply at many field sites, especially during high-flood events [
5].
Therefore, in this manuscript, we propose a new method to model
C–
Q relationships beyond simple regression. Additionally, we determine which observation strategies produce better predictions with the least effort (i.e., with fewer samples) when the use of high-frequency in situ analyzers is not available or restricted. For this purpose, we introduce a simple stochastic time-series model (regime-and-memory model, RMM) for concentrations in the river that accounts for fluctuating release and transport with memory, using an autocorrelation over time. One explicit parameter of our model represents the export regime. This parameter can morph the model among chemostatic-type and chemodynamic-type catchment behaviors, and it resembles the regression slope in plots of
versus
. To search for the best sampling strategies, we applied retrospective optimal design of experiments (ODE), as in [
45]. In our specific case, retrospective means thinning out an exhaustive time series from high-frequency in situ analyzers to only a few samples.
Overall, the contributions of our work are fourfold: (i) We introduce a simple stochastic time-series model to characterize the export regime of a catchment subject to hysteresis; (ii) We demonstrate the robustness of our model even with only small data sets; (iii) We explore how many
C–
Q samples can be enough to characterize the export regime of a catchment sufficiently well; and (iv) We recommend sampling strategies that optimize the characterization of the export regime with the least sampling effort. For illustration purposes, we use a high-frequency data series of collected nitrate concentrations. They were collected with an in situ analyzer in the Ammer catchment in southwestern Germany. The available data [
20] span a total period of nine months, with hourly observations. They include nitrate concentrations and discharge rates with over 6500 measurements in total.
Accordingly, this paper is organized as follows: In
Section 2, we first explain our stochastic time-series model. Then, we explain how to infer the parameters of our model from the whole time series and how we thin out data to reduce them towards different sampling strategies. In
Section 3, we introduce the observed data and catchment used for this study. In
Section 4 and
Section 5, we present and discuss, respectively, our results. Finally, we disclose our conclusions in
Section 6.
2. Methodology
Throughout this study, we will consider
versus
in the following, instead of
for mathematical convenience in model building. The slope in corresponding plots is
α in Equation (1), the parameter that describes the export regime in our model. For this study, we disregard a negative relation
α (mobilization behavior) between
and
, since the Ammer catchment misses this component as seen in Schwientek et al. [
20] and
Section 3. However, both the model and methodology can cover the full range of
α (chemostatic, dilution, and mobilization behavior).
2.1. Regime and Memory Model (RMM)
To represent the evolution of concentration versus time, we use a simple stochastic time-series model for nitrate in the river. Our model has an explicit morphing parameter
α. This parameter allows a transition of the model between chemostatic-type and chemodynamic-type behavior of the headwater catchment:
In Equation (1) and throughout this manuscript, we refer to (=−α) as the export regime [-] ( [-]), C is concentration (), Q is the discharge rate (), and is the apparent release rate . The subscript t indicates that parameters/variables depend on the current time t.
When 0 ( 0), the catchment shows a chemostatic export regime, e.g., concentration only depends on the apparent release rate, which then has units of a (fixed) concentration . When is positive (γ < 0), the catchment shows a dilution behavior, presenting an anti-proportional dependence on the discharge rate. In the limit case of α = 1 ( −1), k assumes units of a mass flow rate [M/T].
To ensure that
k is never negative, we assume that
k follows a lognormal distribution with mean
mk and variance
. Furthermore, we assume that
kt follows (over time) an auto-regressive model of order one (AR(1), [
46]) in order to account for the dominant characteristic time scale of release and chemical turnover in the catchment. Thus, the AR(1) model is commensurate with the source strength and includes effects such as hysteresis or event-to-event variations of source availability.
Setting
=
, we can define an AR(1) for
Y as:
where
is a correlation parameter to account for the correlation between concentrations at the current time and previous times;
c is a constant that is responsible for the mean; and
ε is a white-noise time series, following a normal distribution with mean equal to 0 and a standard deviation of
,
. The AR(1) is a stochastic model with mean and variance given by:
As seen in Mehne and Nowak [
47], the characterization of an AR(1) in calibration/inferences is made more convenient and intuitive by defining a characteristic time
tch, and the mean and variance of
k, respectively,
mk and
. The characteristic time is defined as
and the relationships between
,
and
mk,
are the well-known moment relations for the lognormal distribution [
48]:
Equations (6) and (7) allow the adjustment of into more understandable units of k, i.e., [M/L3] or [M/T] rather than for . Therefore, with only four parameters (α, mk, vk, and tch), we can represent concentrations versus time.
2.2. Bayesian Parameter Inference of Full Time-Series Data
Equations (1)–(7) define a stochastic time-series model for concentration, i.e., a model that can generate many random time series. Its relevant properties can be controlled by the choice of values for α, tch, mk, vk, and by using a given time series for Qt. Thus, the next step is to fit the model to the observed data of concentration Ct. Due to the stochastic randomness implied for Ct by kt (explicit by the white noise εt in Equation (2)), this is achieved by choosing parameter values such that the resulting model is most likely to generate good-fitting random Ct time series. This parameter choice is subject to a list of plausibility arguments for admissible parameter values.
The framework most suitable for this task is Bayesian parameter inference, as in [
49]. In the heart of Bayesian inference lies Bayes’ theorem
where
denotes the parameters to be inferred (
α,
tch,
mk,
vk) and
y denotes the measurement data (
Q,
C). The prior
represents our belief (or knowledge) about the parameters before seeing any data and has to be chosen by us (
Table 1). The first term on the right-hand side,
, is the likelihood of observing the data for the given parameters. The term in the denominator,
p(
y), is independent of the parameters
, and therefore does not need to be computed. The result is the posterior distribution
, which expresses our updated (calibrated) belief about the parameters after seeing the data
y.
Following this, we choose a prior distribution for our parameters and derive an expression for the likelihood. After that, we explain how to obtain a sample from the posterior distribution via Markov Chain Monte Carlo (MCMC) sampling.
2.2.1. Prior Distributions
Bayesian parameter inference treats unknown parameter values as random variables and formulates plausibility arguments as prior probability distribution functions (PDF) (
Table 1). Then, it updates these distributions to posterior distributions based on the available observation data.
We assumed that we were clueless about the export regime
α and we only discarded mobilization behavior as justified in
Section 3. Thus, we adopted a uniform distribution between the two extreme values of chemostatic and pure dilution behavior (
[0,1]).
For the characteristic time tch, we assumed that concentrations in the river present roughly weekly cycles (e.g., due to weekly cycles in the release of wastewater treatment plants, which are in turn triggered by cycles in known activities) with a mean equal to four days (mtch = 95.7 h) and a standard deviation of three days (stch = 71.7 h). Thus, the 95% confidence interval was about [1 d, 14 d]. Because tch must be positive, we chose once again a lognormal distribution. The corresponding parameters of the lognormal distribution LN(μ, σ) followed from respective copies of Equations (6) and (7), resulting in μtch = 4.35 and stch = 0.65.
We also assumed little prior information for the mean
mk, and variance
vk of the apparent release rate
k, so we chose uniform distributions. We will discuss the mean
mk first. For
α = 0, it corresponds to the long-term mean of nitrate concentrations. For an average discharge rate of 0.87 m
3/s (
Section 3), if we rounded this to ≈1 m
3/s, then concentration
C =
k (Equation (1)) for both extreme values of
α. Therefore, we can interchange
C and
k in the following discussion.
We assumed that the expected values of
k (e.g.,
mk) within the river were between pristine water (≈1 mg/L) and the effective average of the undiluted, agriculturally shaped groundwater in the Ammer catchment (≈40 mg/L, as observed as integral catchment output during baseflow by Schwientek et al. [
20]). Finally, we will discuss the standard deviation
of
k. For
α = 0, it controls the amplitude of fluctuations in nitrate concentrations. We assumed a uniform distribution between 1 and 6.32, because we could expect both an almost constant
k and a dynamic
k.
2.2.2. Likelihood
To compute the likelihood, we used the following semi-analytical method. It calculates so-called depreciated increments between Yt and Yt−l, where l is the lag distance along time between two observations. For example, the data we used comprehended 6604 hourly samples. Between the third and the first samples, the lag time was 2. Therefore, if the whole time series is taken into account, then the lag time between two observations is l = 1. Thinning out to half the sampling rate corresponds to l = 2. Irregular sampling triggers individual lag values between consecutive data values.
We assumed that = (α, tch, mk, and vk) were currently proposed trial values. We then wanted to compute the likelihood for data from the time series y = (Q, C) for the trial values . Note that y can include the whole high-frequency series of data or only a short list of observations at various lag times.
Using Equation (1), we could transform these two time series of
Q and
C into a time series of
kt. Then, by applying the log, we obtained a time series of
Yt. Next, we calculated
(Equation (5)), and then
c and
from
mY and
vY. We did so by first solving Equations (6) and (7), and then Equations (3) and (4). Before computing the depreciated increment between two observations, we wanted to get a
Y0 zero-mean AR(1); therefore, we removed the mean
mY (Equation (3)) from
Y:
Then, the depreciated increments
Xl can be computed:
Equation (10) shows that the
Xl are mutually independent, as they are sums of non-overlapping segments from the white-noise series
εt. The variance and corresponding standard deviation of the depreciated increment are, respectively:
After the rearrangements, the likelihood
is now the probability density value of
Xl, which in turn is given by the multivariate normal distribution:
where
nt is the total number of samples of the considered series (here
nt = 6604 when using
l = 1). In Equation (13), we can use the simple product rule due to independence within the time series of
Xl. Finally, the likelihood term
in Equation (13) is given by
which is the normal distribution for
Xl implied by the chosen priors and the above equations.
2.2.3. Sampling from the Posterior
With the prior and likelihood in place, we could then sample from the posterior distribution via MCMC sampling. Here, we explicitly coded MCMC in Matlab [
50]. The scaling factor for the MCMC proposal was constructed as an adjustable fraction of the posterior standard deviation to get an acceptance rate of approximately 27% (the optimal acceptance ratio for four dimensions according to Gelman et al. [
51]). Since the posterior standard deviation is only known after the MCMC is run at least once, we used a burn-in run of the MCMC to obtain good scaling factors for the productive final part of the MCMC.
The posterior marginal PDF of
α,
is again given by Bayes’ Theorem [
49]:
where
is the likelihood of the observed data given
α, the remaining parameters
and
Xl, and
is the prior of the parameters and
Xl. For simpler discussion, we reduced the sample to a point-estimate by computing the posterior mean from the posterior samples:
where
N is the length of the MCMC. We used
N = 10,000 and
N = 100,000 for the burn-in and the productive part of the MCMC, respectively. Finally, we could compute an inferred truth value
αfull from the full data set, and values
for various sampling designs
d.
2.3. Retrospective Optimal Design of Experiments (ODE)
The objective of our optimal design was to minimize the error
in estimating the parameter
α:
where
D is a set of considered design strategies,
d is any considered design,
dopt is the best design among
D, and
is the squared error in estimating
α for design
d (as
) when compared to
αfull:
In summary, when we thinned out the time-series data, only including data as specified by design d, we inferred α and hoped that this would remain close to αfull (α inferred with full time-series data). We also assessed whether had little remaining uncertainty as expressed by intervals in its distribution according to Equation (15).
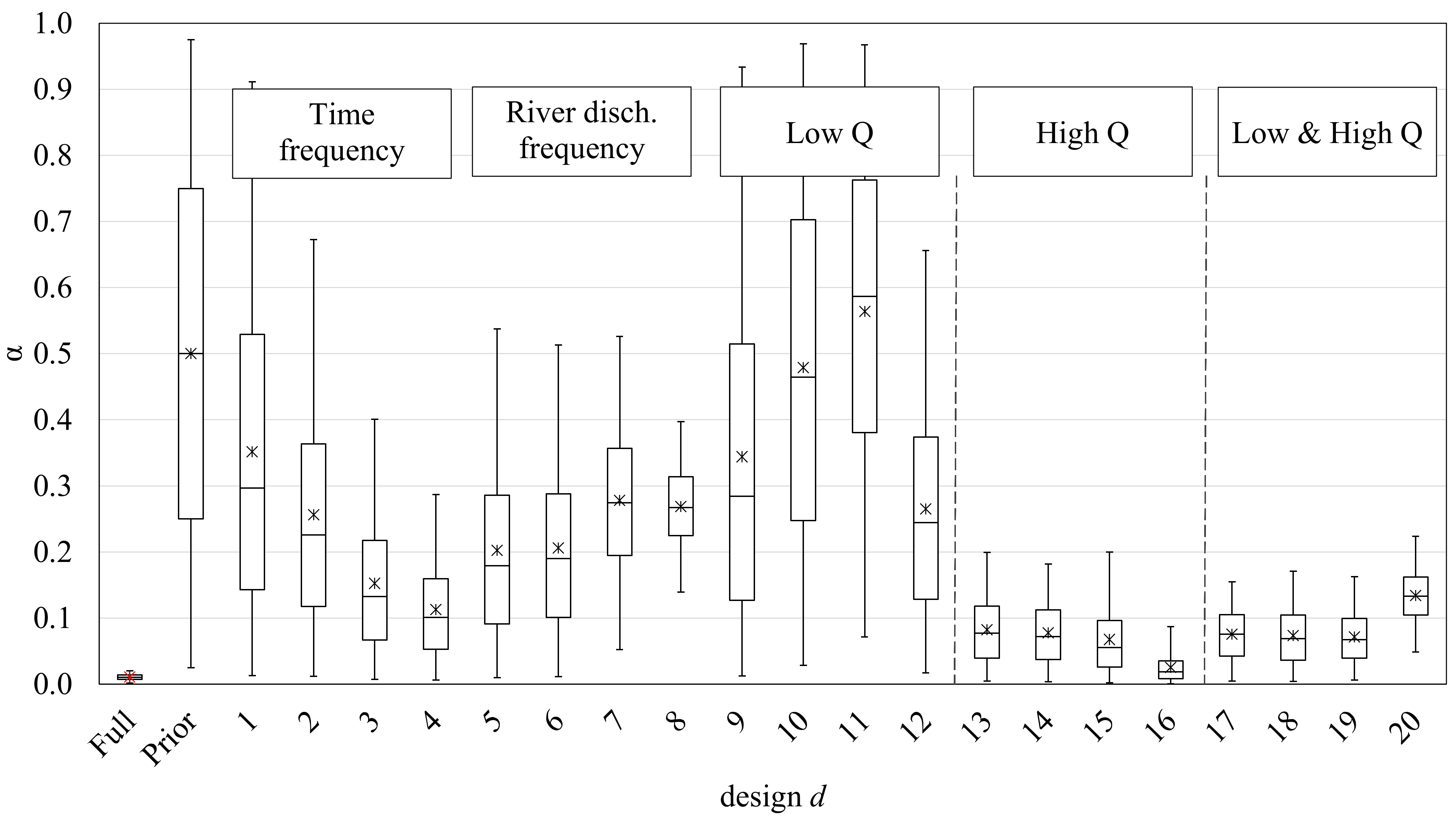
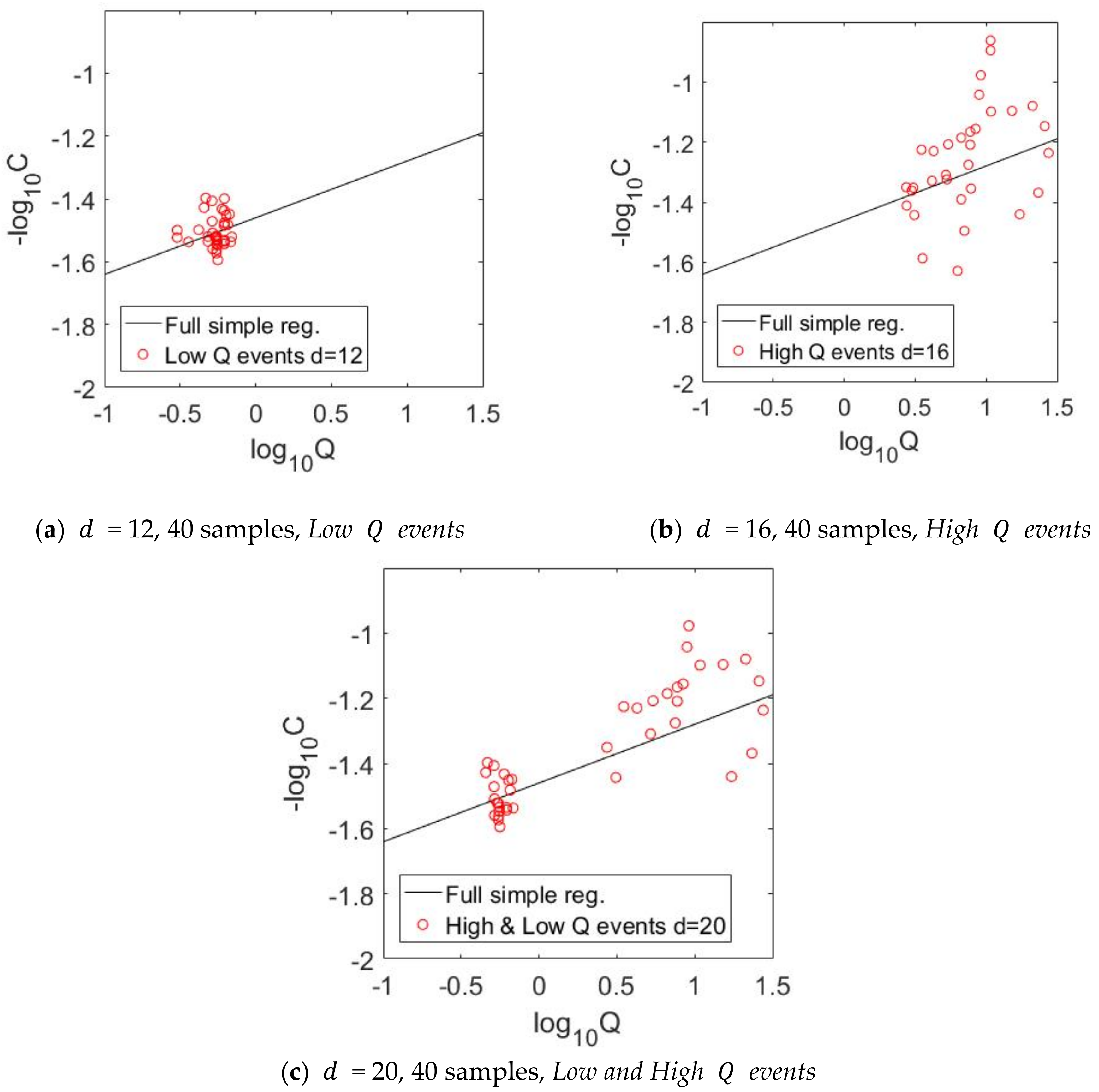
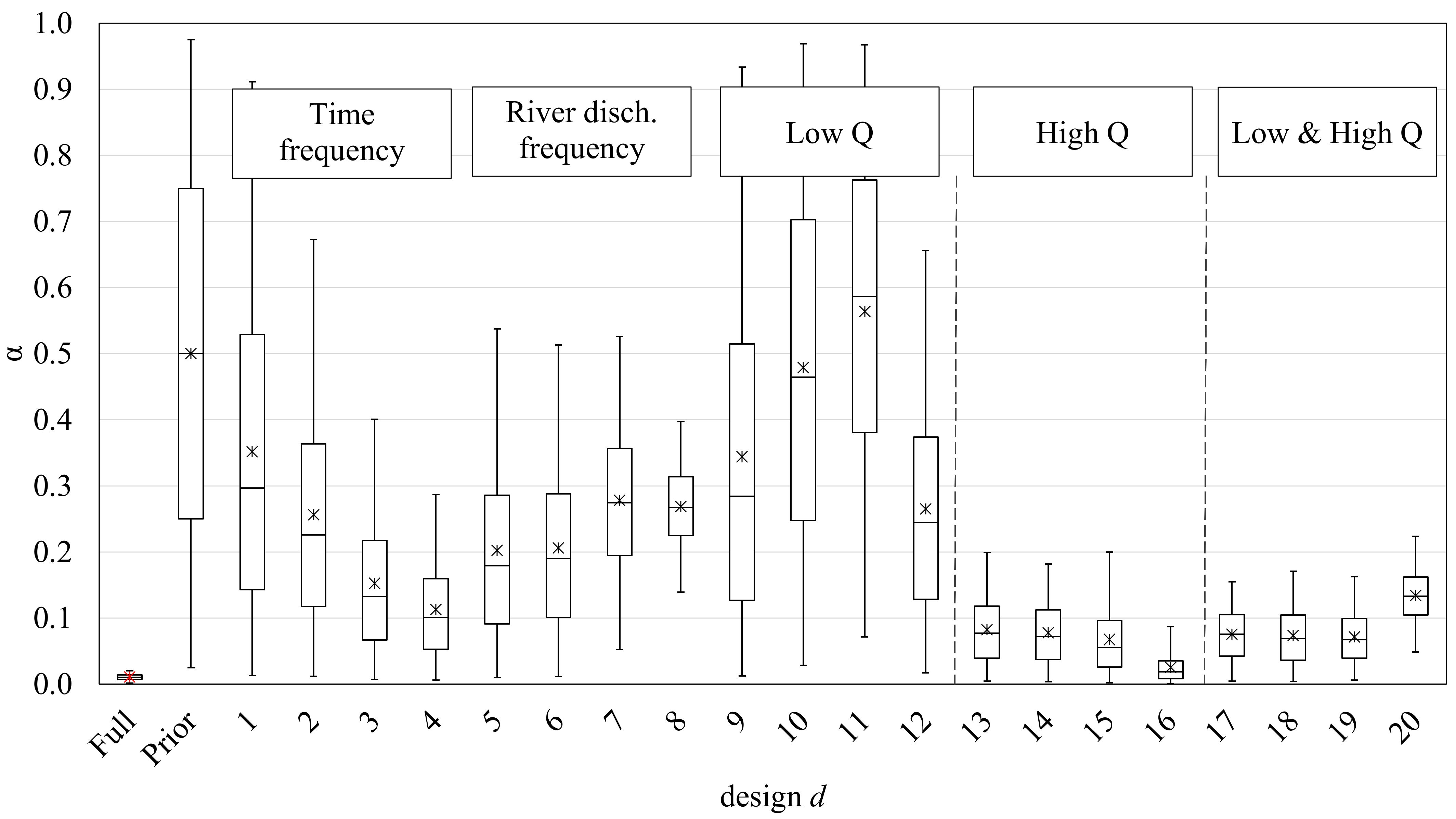
We propose 20 designs based on four sampling strategies (
Table 2). Firstly, we thinned out the observed data based on time-frequency strategies (
d = 1 to 4). Secondly, we thinned out based on discharged volume within the river (
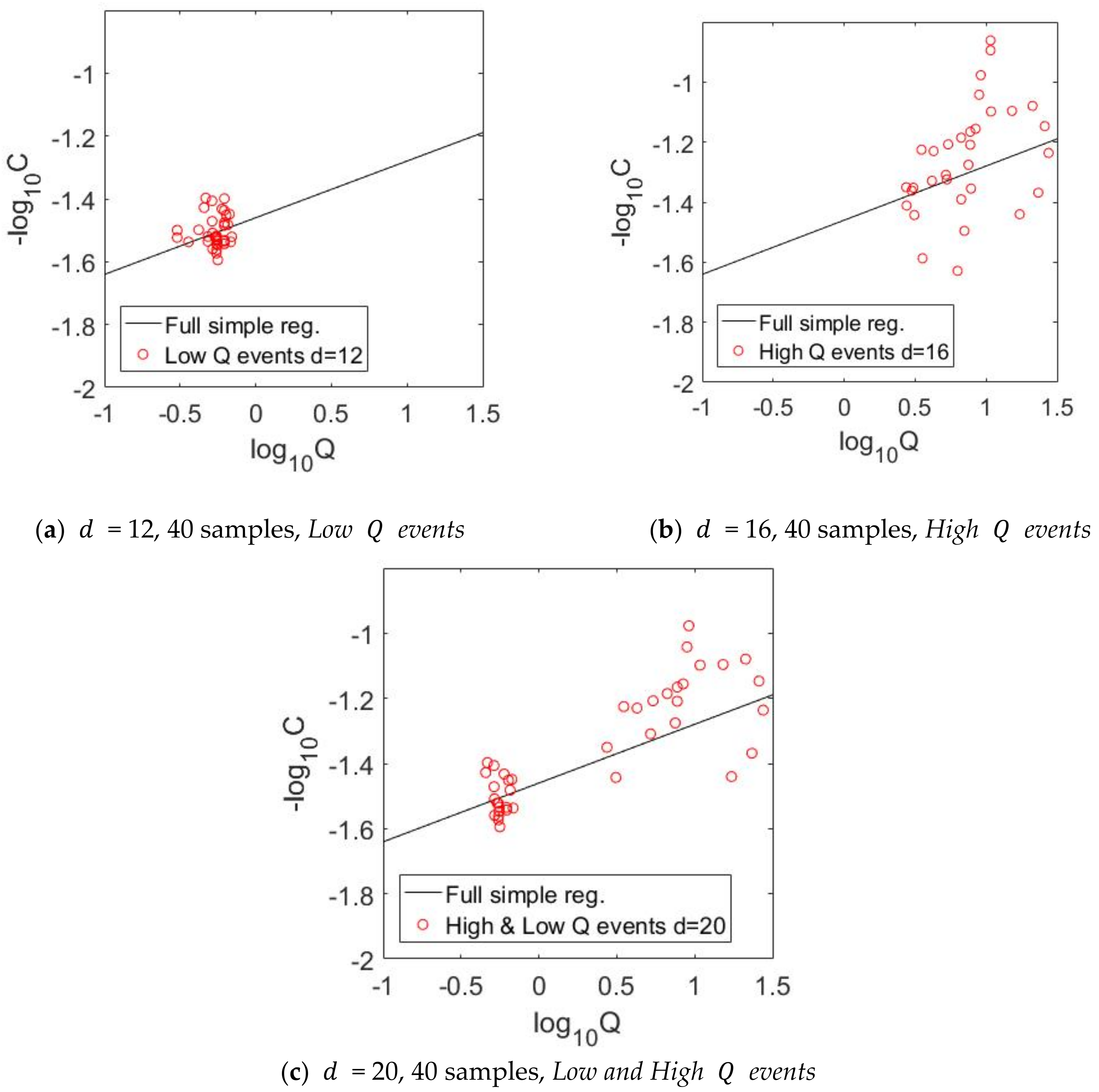
d = 5 to 8). In both strategies, sampling was uniform (in time or discharged water), and we varied the number of samples between 5 and 40. Thirdly, we applied event-based sampling strategies, in which we considered samples at low discharge rates (
d = 9 to 12) and high ones (
d = 13–16). The last strategy considered low and high discharge rates together (
d = 17 to 20). Here, we also considered between 5 and 40 samples. Designs should not be understood as random selections but manual selections as described in
Appendix B. In this same appendix, the reader can find the observation values and the exact time coordinates for each sampling strategy.
For this study, we considered a low discharge rate to be lower than 0.67 m3/s (which corresponds to a value 25% below the mean discharge of the whole time series) and a high discharge rate to be Q > 2.5 m3/s.
3. Catchment and Data
The data used in this study were already published in 2013 [
20]. The data were observed in the gauged catchment of the Ammer River located in the state of Baden-Württemberg in southwest Germany. The area of the catchment upstream of the gauging station Pfäffingen is 134 km
2. The geology is dominated by limestone of the Middle Triassic (“Oberer Muschelkalk”) and gypsum-bearing mudstone of the Upper Triassic (“Gipskeuper”). Both formations, particularly the limestone, are strongly karstified, and the Ammer River is primarily fed by karst springs, most of them being situated close to the main stem river [
52]. In line with the large storage capacity of the karst system, the permeable rocks of the catchment lead to a dampened hydrologic variability with a very strong and steady baseflow. Mean annual low flow (0.44 m
3/s) is as high as 50% of the long-term average flow (0.87 m
3/s) (retrievable from
https://www.hvz.baden-wuerttemberg.de/, accessed on 14 May 2020). Nevertheless, pronounced and sharp flood peaks typically occur during the summer season. They are caused by surface runoff generation on impervious urban areas in the upper catchment [
20,
53]. Usually, due to steep recessions, baseflow is attained within a few hours after the flood peaks. In total, 17% of the catchment area is urbanized and 71% is occupied by agriculture, 66% of which is used for arable land [
20].
In terms of hydrochemistry, the strong and steady contribution from the limestone karst system leads to stable concentrations of geogenic and agriculture-derived solutes such as nitrate and chloride. A short-term dilution of these compounds may occur during storm events. Then, large amounts of event water with low solute content are introduced into the river [
20]. Discharge data and chemical data were collected hourly with in situ analyzers from 07/1/2011 to 03/31/2012. This data set of observations includes over 6500 measurements of nitrate concentrations, electric conductivity, and discharge rates.
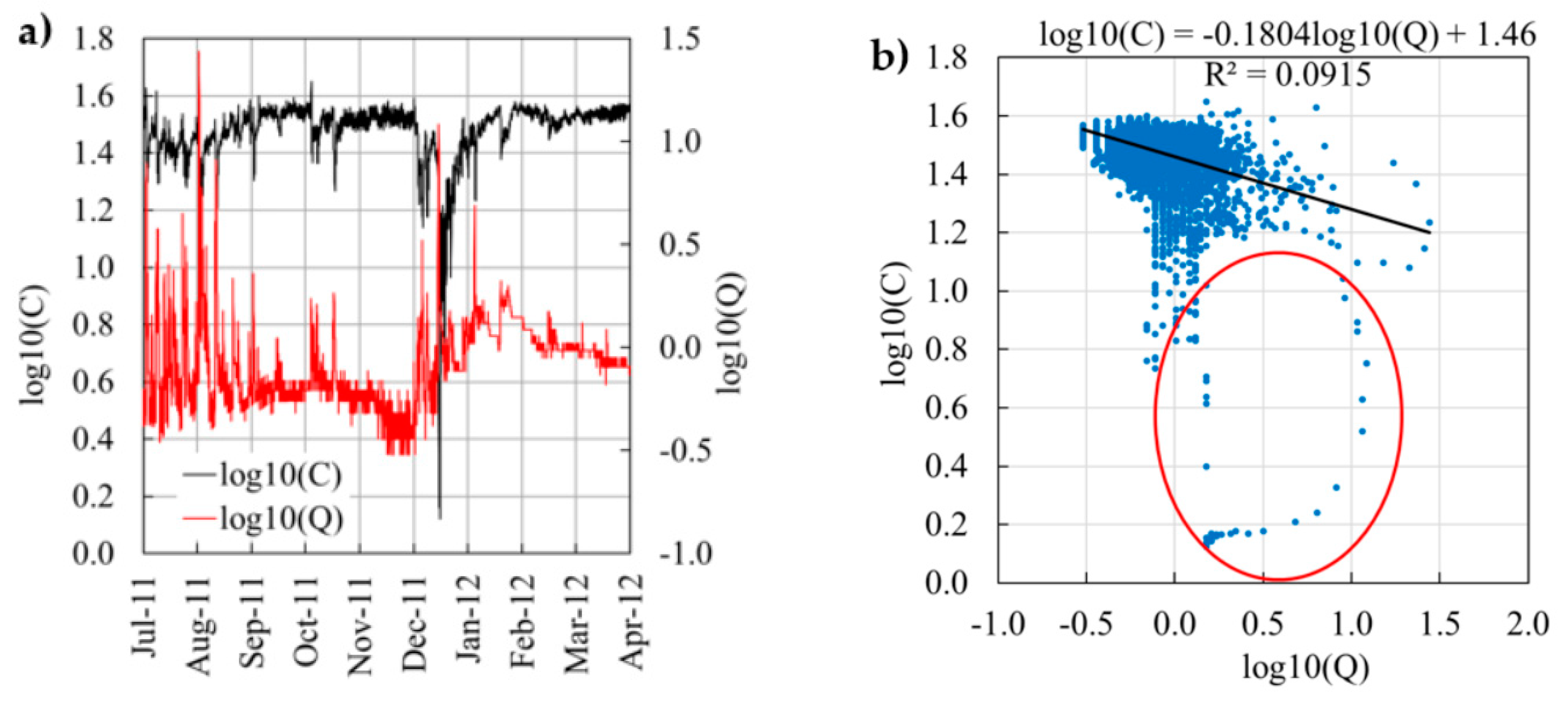
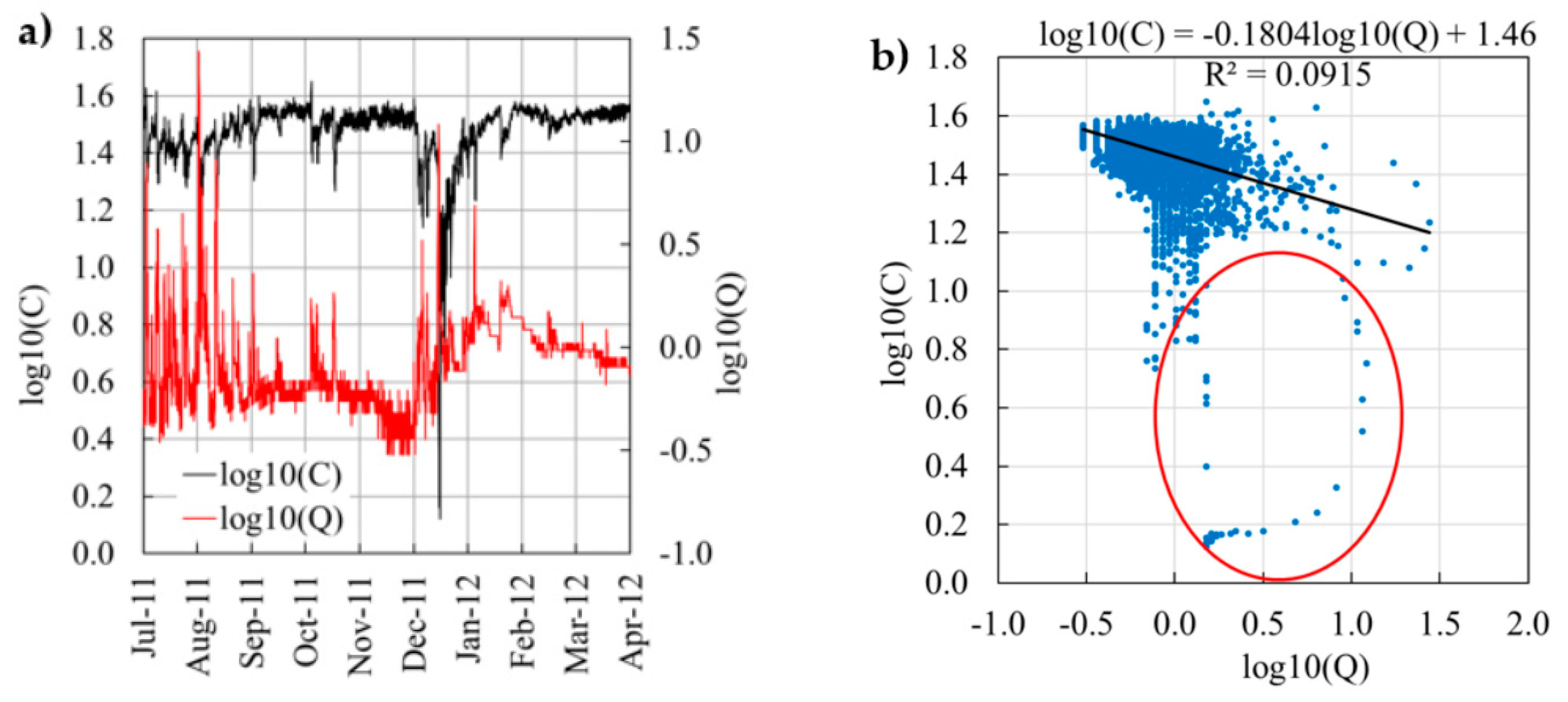
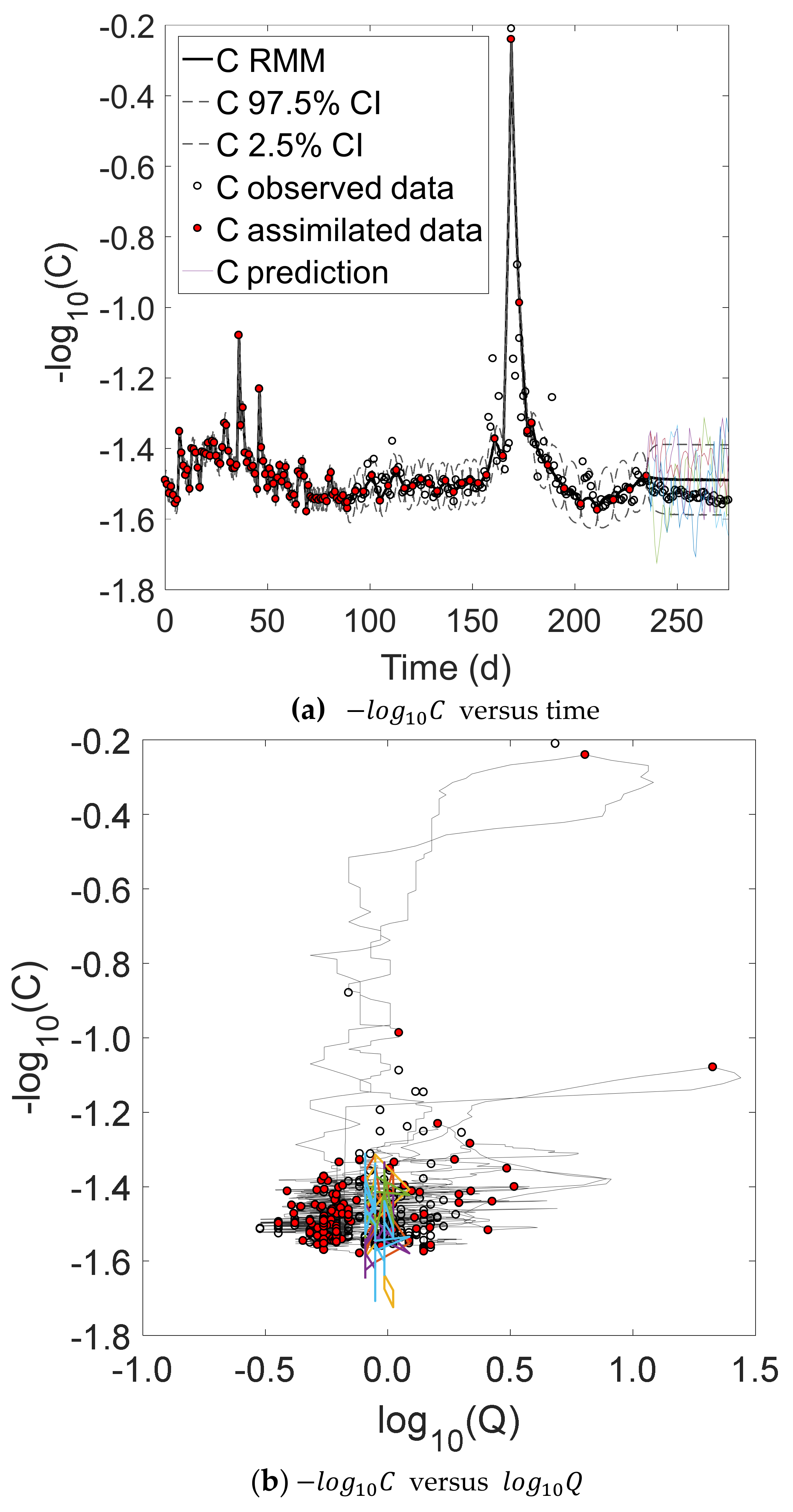
Here, we focus on discharge rate,
Q, and nitrate concentration,
C, (
Figure 1a) although our proposed procedure could likewise be applied to other compounds. Over the time series, the average
Q (0.93 m
3/s) was similar to the long-term average (0.87 m
3/s). The maximum
Q (27.5 m
3/s) represents an exceptional flood with a return period of about 20 years. The average
C was 31.5 mg/L, but a range between 9.5 and 44.7 mg/L was captured.
Figure 1a demonstrates the strong baseflow component of the Ammer system with a steady
Q and 60% of all measured values falling within the narrow range of 0.5–1.0 m
3/s (
= −0.30–0.00) during the recorded time series. During these baseflow periods, flow is predominantly fed from the large karst storage and, at rather constant rates, from wastewater treatment plant effluents, and thus exhibits stable nitrate concentrations around an average of 31.5 mg/L (
= 1.50). Most floods occur in the summer period and are the result of convective precipitation events. They typically have very short durations with steep recessions and cause a dilution of the nitrate concentrations. This may be explained by a fast runoff component dominated by a heavy precipitation event on sealed urban surfaces that carry low nitrate concentrations.
At the same time, flow supplied from the karst system with high C varies relatively little during flood events. There is no intermediate flow component that would connect agricultural soils with the stream network and mobilize additional nitrate fluxes. Such an interflow component would likely result in prolonged recessions of the hydrograph and, more importantly, positive relations between Q and C. In summary, the system is dominated by baseflow, which explains the clear tendency towards a chemostatic behavior.
Figure 1b shows the classic approach to determine the export regime of a catchment by computing a regression slope of
versus
. The effect of the short-term dilutions by event water inputs results in a slightly negative relation between
Q and
C, expressed by a small negative regression slope (−0.1804 in
Figure 1b). This means that the Ammer River shows a rather chemostatic export regime for nitrate. The red circle in
Figure 1b includes observations taken sequentially over time that belong to a hysteretic event. It depicts hysteresis in a highly visible fashion. Other hysteresis loops exist as well, e.g., the rightmost group of data points. Many more such loops are hidden in the bulk of the point cloud. With such unconventional residual statistics (i.e., loop patterns in the scatter around the regression line), the applied least-squares linear regression is not robust. Especially for smaller time series, almost any regression slope between 0 and −1 (and even outside these bounds) would be possible.
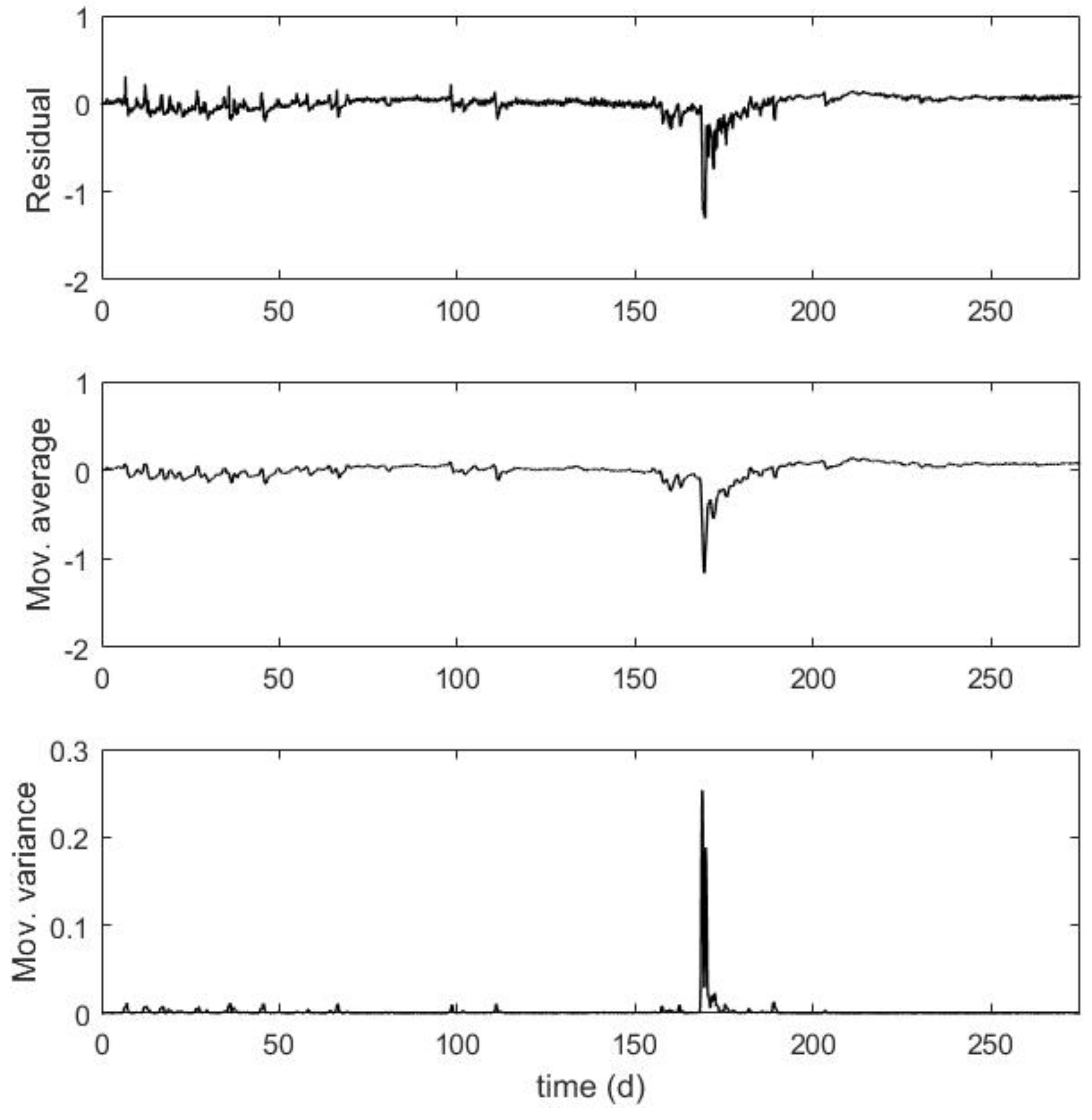
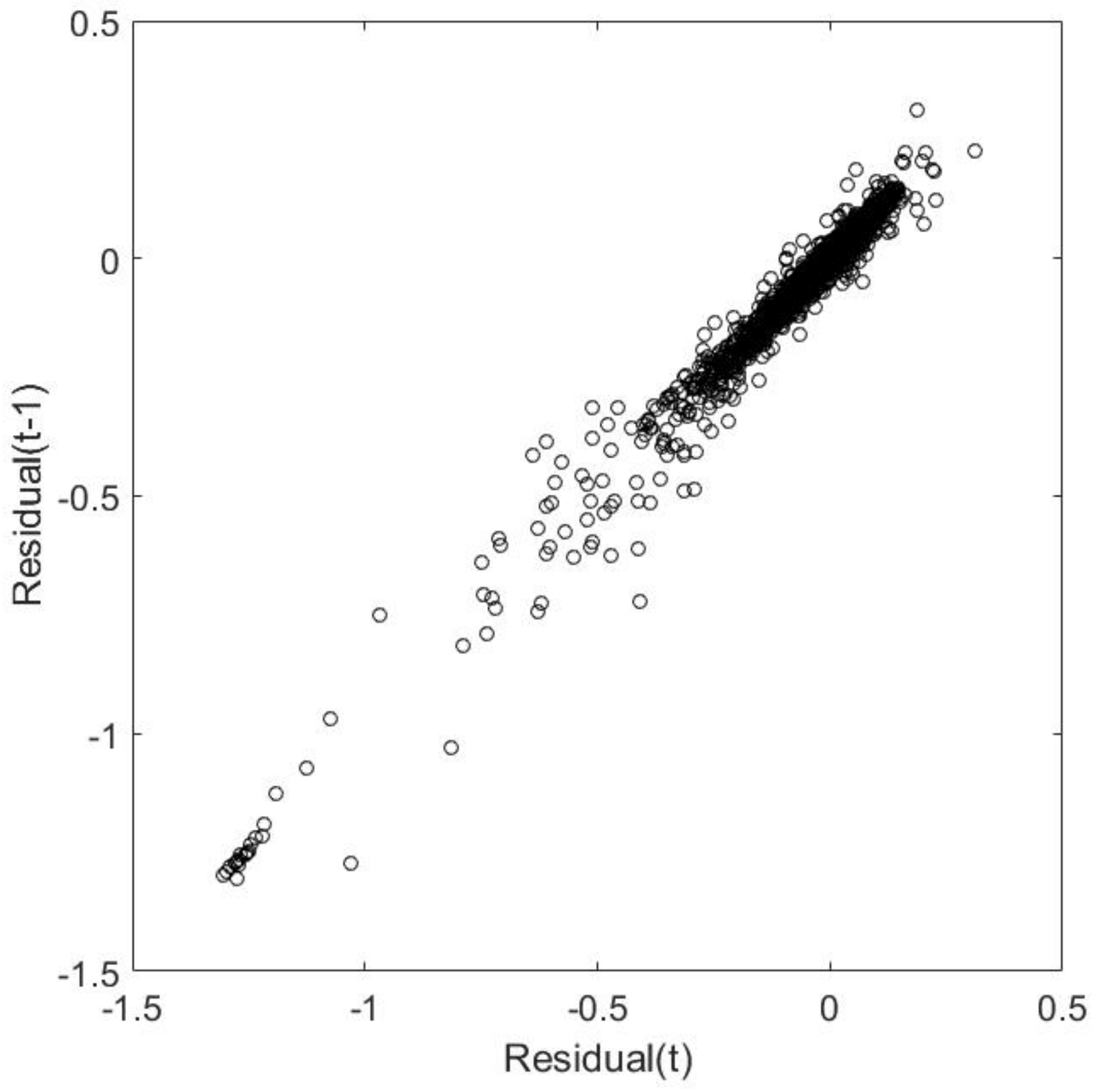
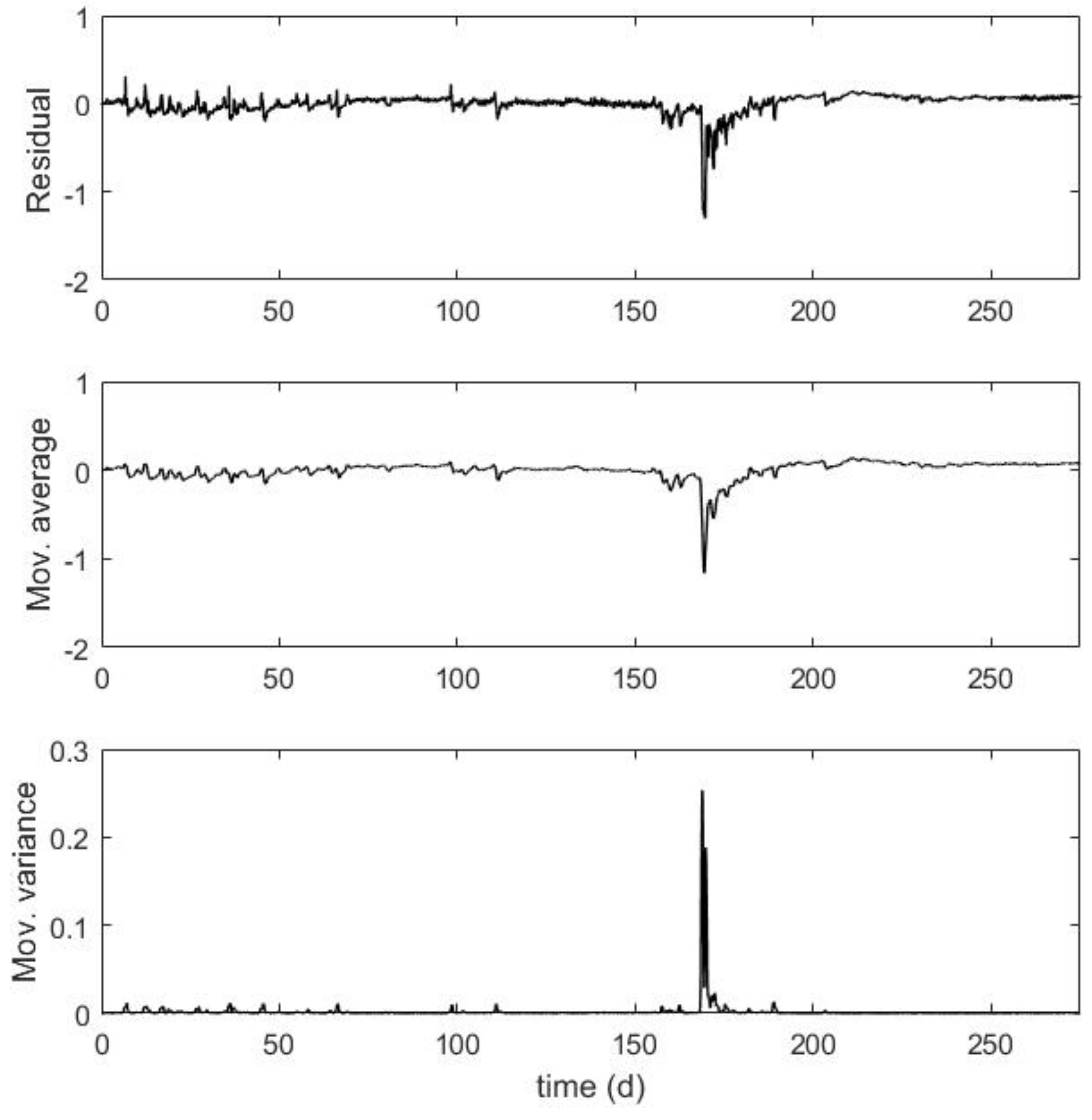
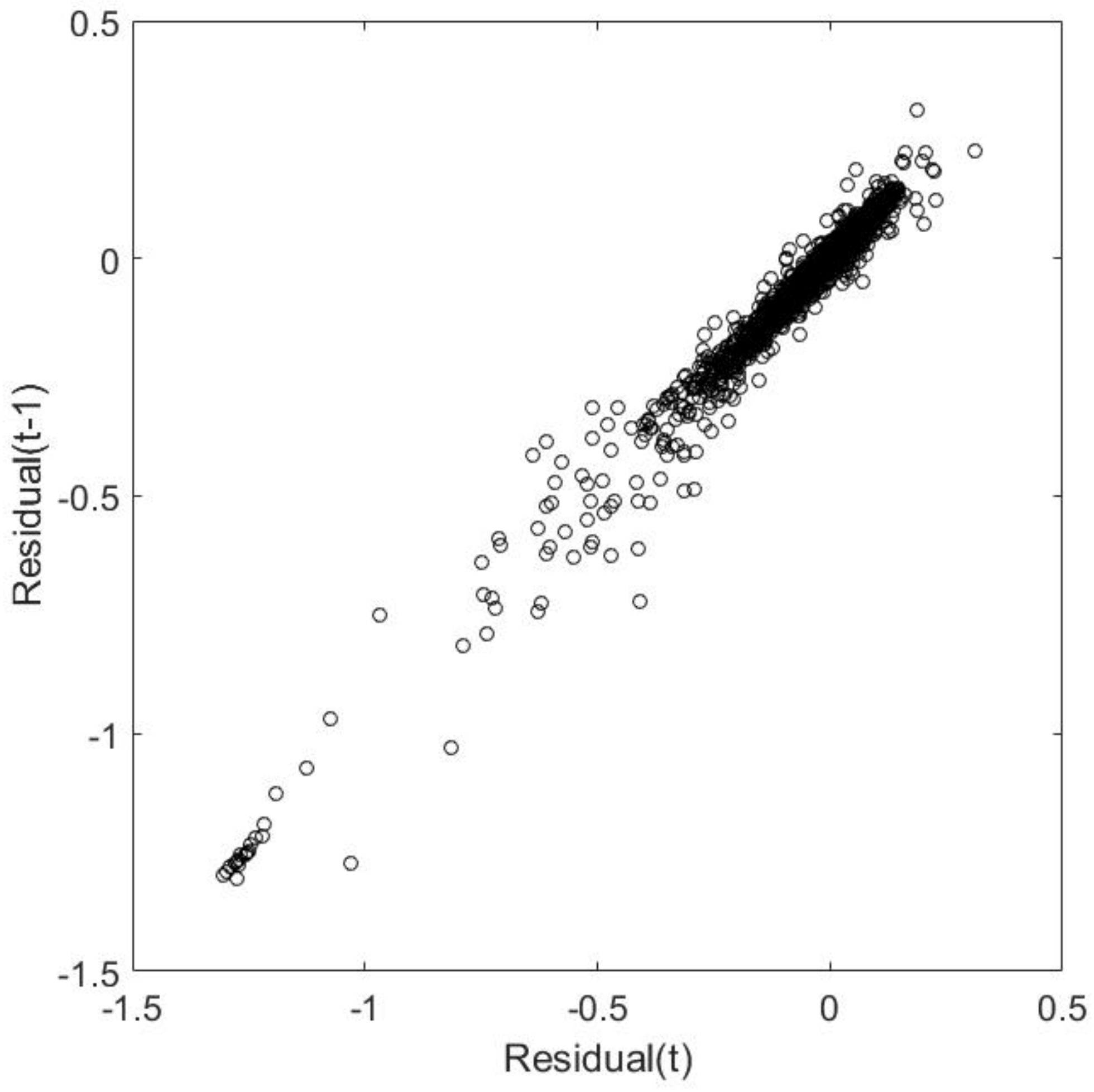
To show that these data do not comply with the regression assumptions (e.g., the mean is not constantly zero and the variance is not constant), we computed the residuals in the
C–
Q regression of the Ammer catchment. In
Appendix A, we present the plots of the residuals, moving window average, and moving window variance (
Figure A1), as well as the correlation of Residual(t) with Residual(t-1) (
Figure A2).
6. Summary and Conclusions
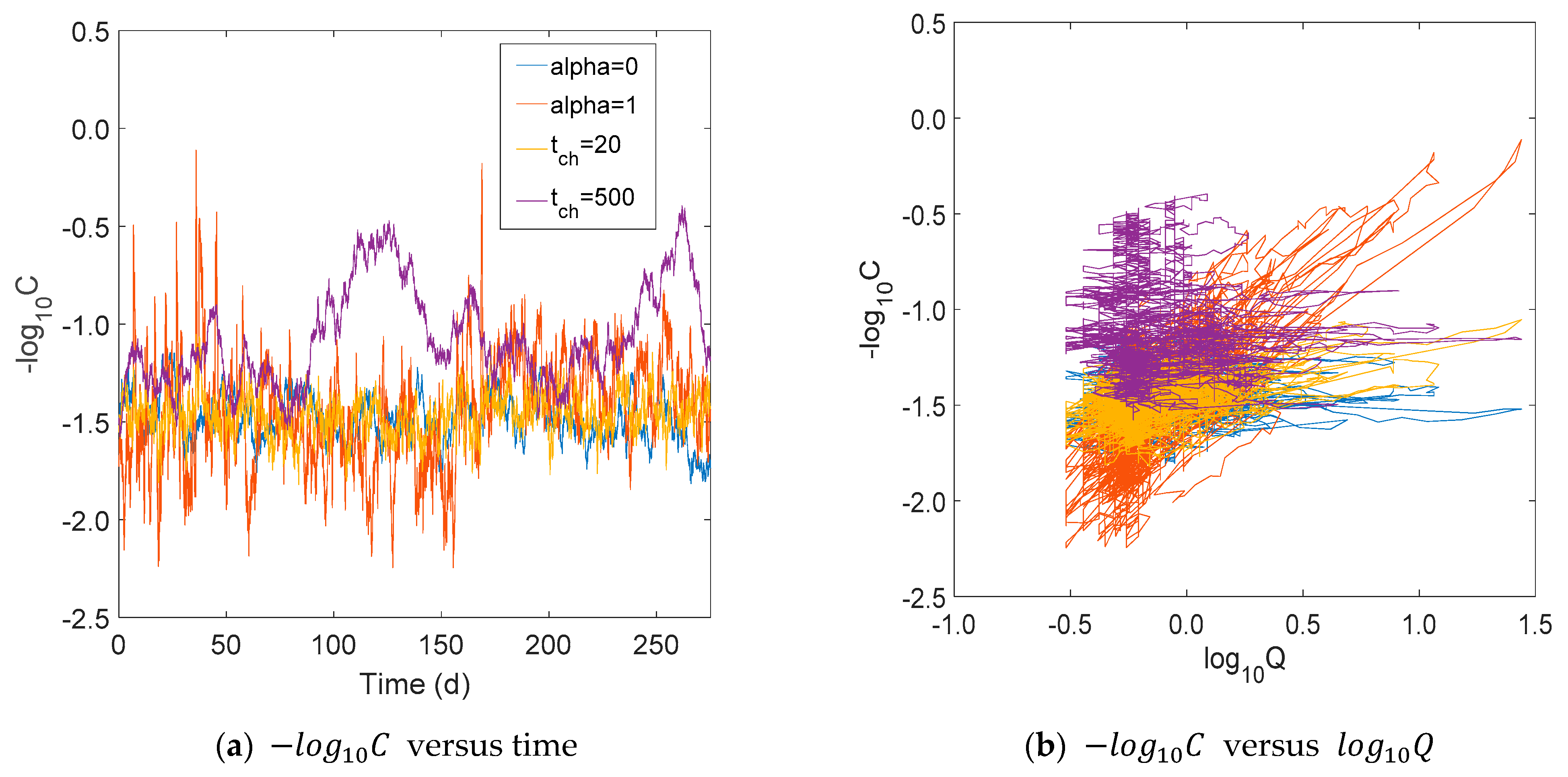
In this work, we proposed a better and more robust alternative to model the behavior of a catchment. Generally, the export regime of a catchment (chemostatic, dilution, or mobilization type) is characterized by the slope obtained by plotting versus measured in the river at the catchment outlet. However, we can usually observe in this representation that measurements show hysteresis effects of the system, defying the assumptions of linear regression. With these assumptions violated, linear regression results can be suboptimal, biased, and strongly misleading. In contrast, our regime-and-memory model (RMM) includes an explicit parameter to model the type of export regime and a parameter to account for the characteristic time scale of release and chemical turnover in the catchment. Thus, our model can mimic these memory effects of the catchment.
For demonstration, we used a high-frequency data series of nitrate concentrations collected with a high-frequency in situ analyzer in a catchment in Germany for nine months. We showed that our simple model is able to mimic the nitrate dynamics of the catchment, including the hysteresis effect. Also, our model showed robustness and consistency in inferring the export regime compared to the linear regression, even for much smaller data sets. Thus, our RMM has the potential to improve export regime predictions.
Regarding the sampling strategies, we found out that the strongest sampling strategies are based on High Q events for the Ammer catchment. These strategies cover a large range of discharge rates and accompanied C values. Representativeness of the collected data (in the face of short-term fluctuations in compound release and catchment memory effects) is ensured by stretching the sampling days across events. From our analyses, we observed that five samples/observations are necessary to produce a significant reduction of α bias (or better accuracy) if the right sampling strategy is implemented (High Q events strategy). However, to decrease the uncertainty (or increase the precision), one must increase the number of samples.
Thus, for catchments with similar characteristics to the Ammer catchment, we recommend collecting the samples when peak events occur since this provides a wide range of Q in a short time interval. However, it bears the risk that these large events are dependent on the season, so their observation would be restricted seasonally. To avoid this seasonal restriction, alternatively, we recommend measuring samples at uncorrelated events at low Q. However, the uncertainty of the export regime will be larger than when C is measured only at High Q events. Hence, sampling strategies based on extreme events, both at low and high Q, are key to reducing the prediction uncertainty of the catchment behavior, and event-based thinking can be reasonably generalized to catchments with C–Q behavior that can be represented by our RMM.
Future work with the RMM includes validating these statements with longer time series, more solutes, as well as data from different catchments. Also, further research will be needed to extend the presented statistical approach of the RMM to consider for the mobilization transport regime (for positive correlations of versus ), in which wet periods do not result in dilution but an additional mobilization of substances.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}