1. Introduction
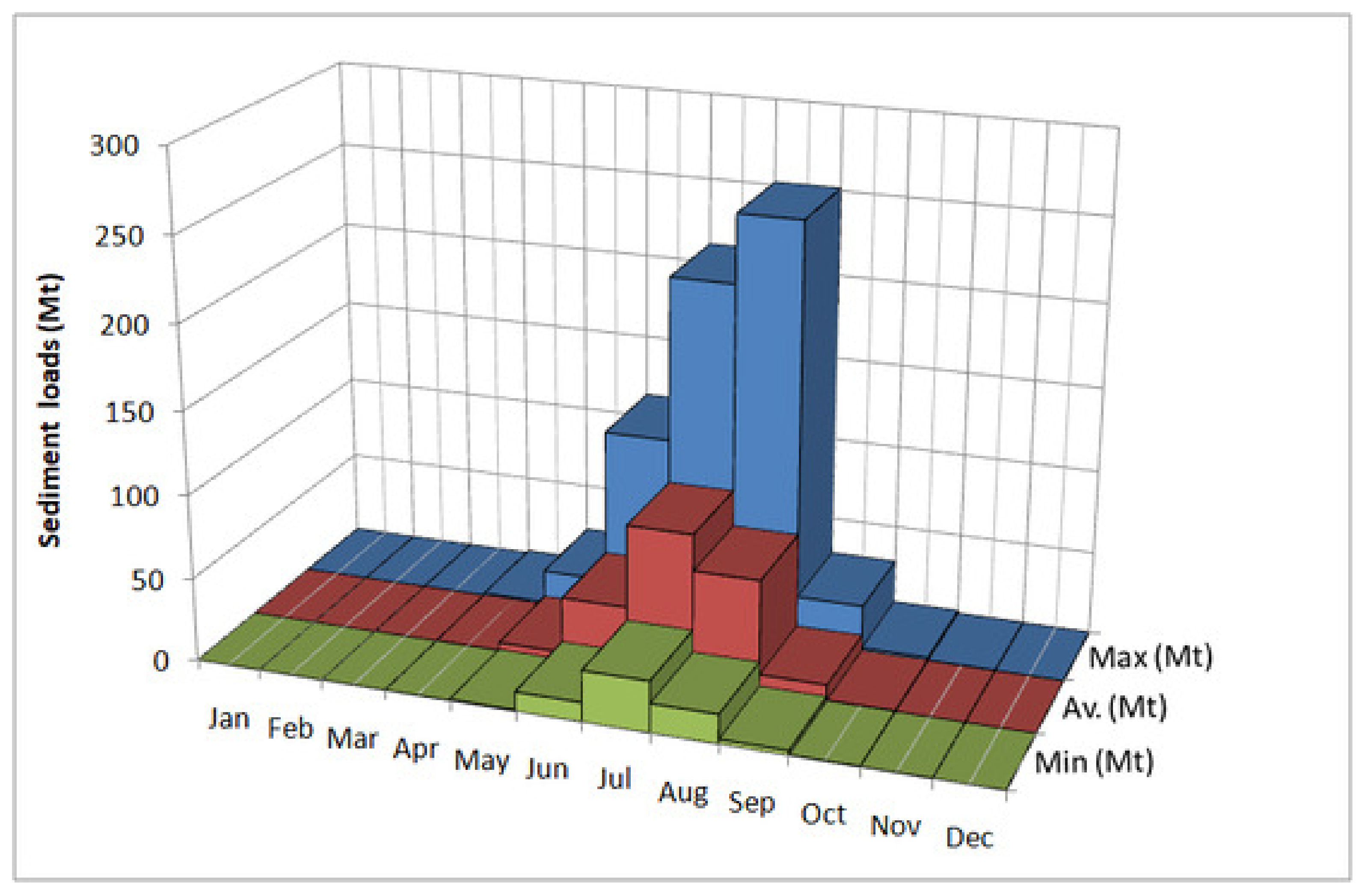
The uncertainties in modeling reservoir sedimentation are due to: (a) both flow and sediment; (b) the distribution of sediment particle size; (c) the specific weights of sediment deposits; (d) reservoir geometry; and (e) the operational rules of reservoirs [
1]. These uncertainties are propagated, particularly, due to the varying input of sediment loads as boundary conditions. Normally, sediment series, as input to the model, are estimated by utilizing sediment rating curves (SRCs), prepared by developing relationships through simple regression techniques, between flow and sediment, observed over a considerable period, adequately representing the complete hydrological cycle over decades [
2,
3]. It has been observed in various sediment studies of reservoirs around the world that SRCs, though a simple and convenient way to estimate missing values of sediment inflow, often overestimate and overshoot the sediment entry into the reservoirs against the actual conditions, up to 50% [
4,
5]. Tarbela Reservoir hydrographical/bathymetric surveys have been conducted since 1979 to observe the sediment entry and position/advancement of the delta in the reservoir. Each year, the reservoir authorities issue Sedimentation Reports based on the above conducted surveys. As per the Sedimentation Report of Tarbela Reservoir [
6], the actual observed sediment deposits in the reservoir are about 171.3 Mt/year, which are about 53% of the average of the below-mentioned studies, i.e., 47% overestimation. Hence, precise hydro-morphodynamic boundary conditions play a principal role in modeling the transport processes in rivers and reservoirs.
The Tarbela Dam Project (TDP) was completed in the mid-1970s and is the backbone of the hydropower and water resources of Pakistan, with its 3478 MW of existing installed and 6298 MW of near future capacity. It is the world’s largest earth-filled dam and also by structural volume [
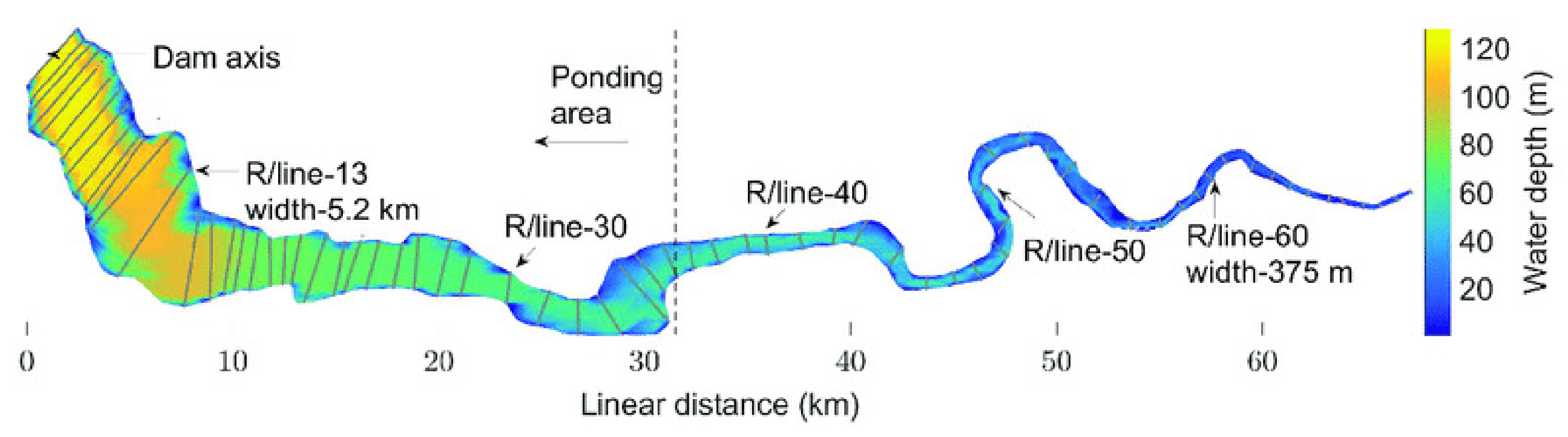
7]. The Tarbela Reservoir drains UIB and lies at its lowest point. The drainage area up to the dam is about 170,000 km
2, as shown and demarcated in
Figure 1. The huge body of water created behind the dam, originally 11.620 million acre feet (MAF), has been reduced by sedimentation to 6.856 MAF in 2019 [
8], meaning that it is only 59% of its original storage volume, and the rest has been consumed by sedimentation. The feasibility and engineering studies of Tarbela Dam that were conducted in the mid-1960s and 1970s took serious note of the potential sedimentation problems that were likely to arise after some years of dam construction. Various studies at the time and afterwards estimated sediment entering the reservoir to be substantially overestimated, based primarily on techniques in vogue and with less data. The Tarbela Dam Consultants (Tippets, Abbett, McCarthy, Stratton (TAMS)) used 235 million tons (Mt) annually as the sediments entering the reservoir [
9]. The Kalabagh Dam Consultants estimated the annual sediment load entering Tarbela as 295.7 Mt using sediment rating curves. The same figure of 295.7 Mt was adopted for sediment studies of Tarbela by the Consultants of the Ghazi Barotha Hydropower Project located just 8 km downstream of Tarbela Dam. The Consultants for the Mega Diamer-Basha Dam, making use of additional data from 1962–2003 in sediment rating curves, calculated the load for Tarbela Reservoir as 233 Mt annually [
10]. Future sedimentation scenarios fir Tarbela Reservoir hold a pivotal position for authorities and water managers alike, as a reduction in the storage capacity of Pakistan’s largest water body and its implications for all related disciplines would be sensitive enough to provoke studies into alternative or preventive measures.
A list of studies also cited by [
11], in addition to the ones mentioned above, calculating sediment entering Tarbela Reservoir/main Upper Indus Basin (UIB), is tabulated in
Table 1:
All above estimates were based on sediment rating curve (SRC) method and varied in a wide range from around 200 Mt y
−1 – 675 Mt y
−1 over the last 50 years. Unfortunately, the accuracy of SRCs is limited, as they map all scattered data points of discharge and sediment loads using a single fitting line, which is more likely to be affected by data outliers [
22,
23,
24]. Therefore, the single fitting line cannot handle sediment transport processes connected to the phenomenon of hysteresis and noticeable hydrological variations, such as: (a) fluvial erosion and transport processes, interacting with other sediment-production processes; (b) sediment temporary storage in the main channel of the river [
25]; (c) landslide phases related to aggradation and degradation [
26]; (d) on average, 5–10 waves of high flow of an average of 10–12 days’ duration during the monsoon period; (e) different discharge and sediment conveyance times and their differing lag-times from sources to the gauge recording stations. Basically, all these processes cause different sediment concentrations on same magnitude of discharge during rising and falling limbs of flood events, which is referred to as the hysteresis phenomenon. As SRCs are mostly employed in the estimation process of sediment load boundary conditions due to their construction simplicity, a marked compromise could arise in the numerical or physical modeling outcomes.
Since the variations in sediment load boundary conditions affect the calculations of the morphodynamics, it is essential to model time-related changes in sediment supply more accurately, influenced by the above-mentioned phenomenon of hysteresis and noticeable hydrological changes. During recent years, artificial neural networks (ANNs) have gained increased reception as new analytical techniques due to their robustness and ability to model non-stationary data series. Therefore, ANNs have a clear advantage over other conceptual models as they do not need previous knowledge of the process because they build a relationship between data inputs and targets using non-linear activation functions. The ANNs have multiple inputs with dissimilar characteristics, making ANNs be able to represent time-space variation [
1]. In spite of the adequate flexibility of ANNs in modeling time series, sometimes, ANNs have a weakness when signal alterations are highly non-stationary and physical hydrological processes operate under scales of large ranges, with variations of one day to several years. In such a situation, different methods have been proposed, among which are wavelet transforms. They have become a capable method for analyzing such changes and trends in hydrological time series [
27,
28,
29,
30,
31]. A wavelet has been defined as a small wave whose energy is limited in a short period of time and is a logical method for signals that are non-stationary, having short-lived transient components, featuring at different scales, or singularities. A non-stationary signal can be broken up into a certain number of unvarying signals by wavelet transform. ANN is then combined with wavelet transform (WA-ANN). It is considered that WA-ANN models are more precise than the conventional methods since wavelet transforms provide effective break-ups of the original time series, and the wavelet transformation data improves the performance of conventional ANN models by catching effective information for various resolution levels [
4,
5,
11].
In the present study, effort has been made to model the sediment delta of Tarbela Reservoir using the 1D HEC-RAS numerical model with the objective to reduce variations in its future prediction by employing first the conventionally-estimated sediment inflow based on SRC and then by the above elaborated innovative WA-ANN technique. The sediment series based on WA-ANN, as developed by [
4,
11], was further updated, calibrated, and validated by inclusion of sediment data up to 2014 and used as input to the model.
3. Results and Discussion
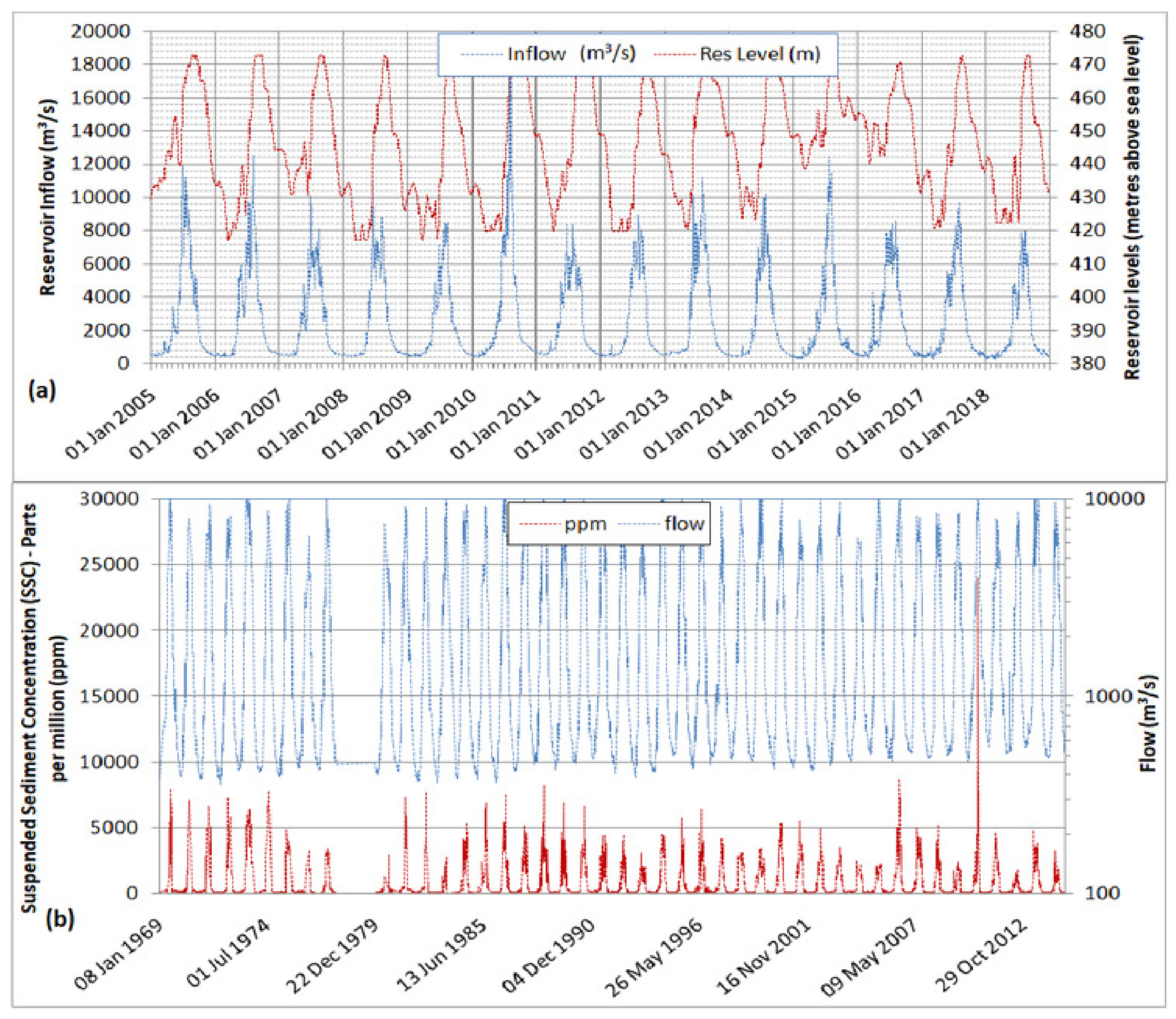
In the numerical model, daily reservoir water levels (RWLs) of the Tarbela Reservoir were applied for the downstream boundary condition. At the upstream boundary, we specified daily inflows with corresponding sediment load. Modeled results were compared to observations and evaluated based on the statistical performance parameters like the coefficient of determination (R2), the observations standard deviations ratio (RSR), and the Nash–Sutcliffe Efficiency (NSE).
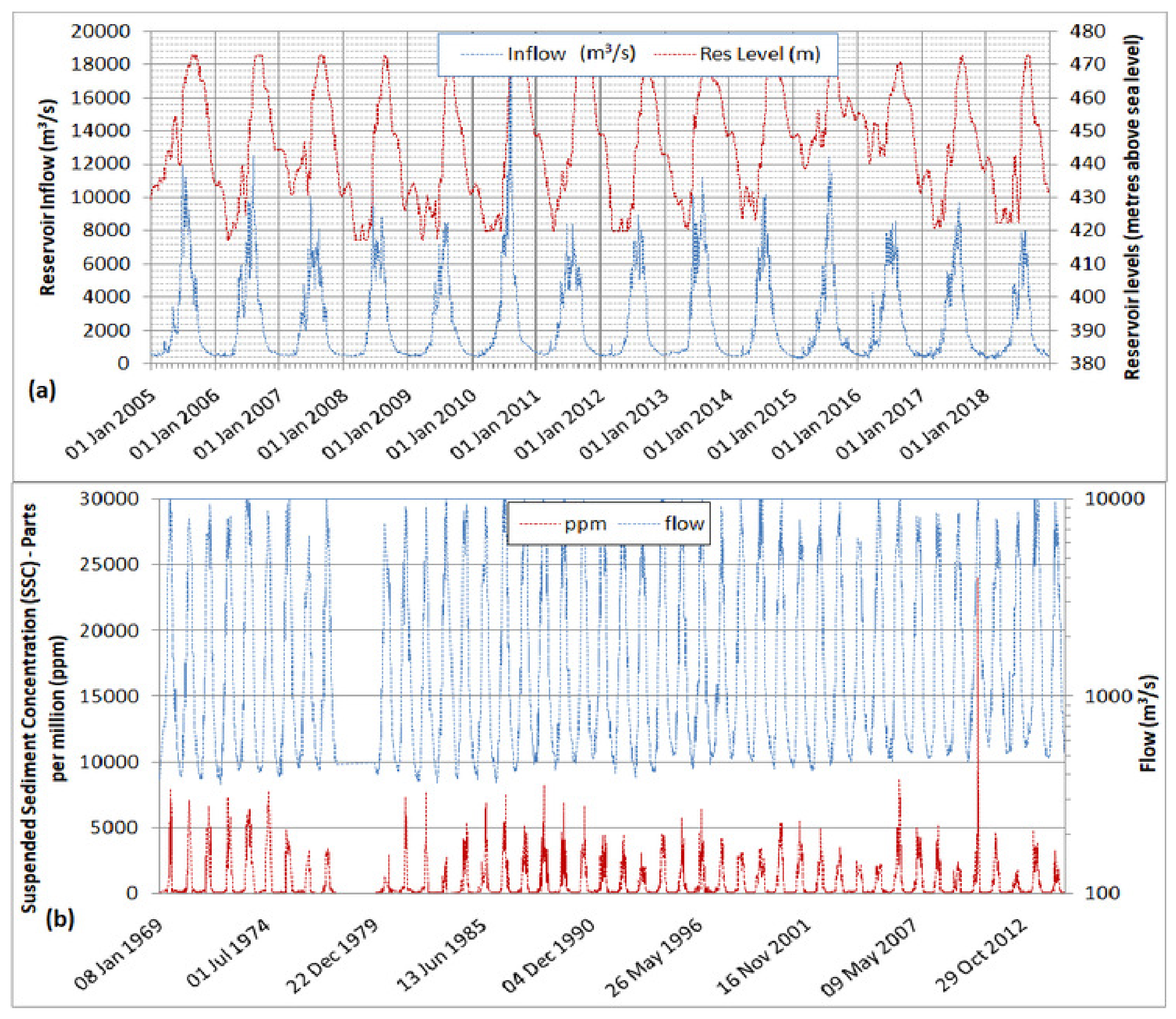
Actual daily inflows of 14 years (2005–2018) were given as the upper flow boundary condition for running the model with the SRC-based sediment loads and were repeated thereafter up to 2030. For running the model with the WA-ANN-based sediment loads, actual daily inflows from 2005–2018 and thereafter futuristic flows from 2019–2030 as projected by [
35] under plausible near-future climatic conditions were applied as upper boundary conditions. Actual daily RWLs of the Tarbela Reservoir were given as the downstream boundary condition up to 2018 and repeated thereafter for both SRC and WA-ANN runs of the model.
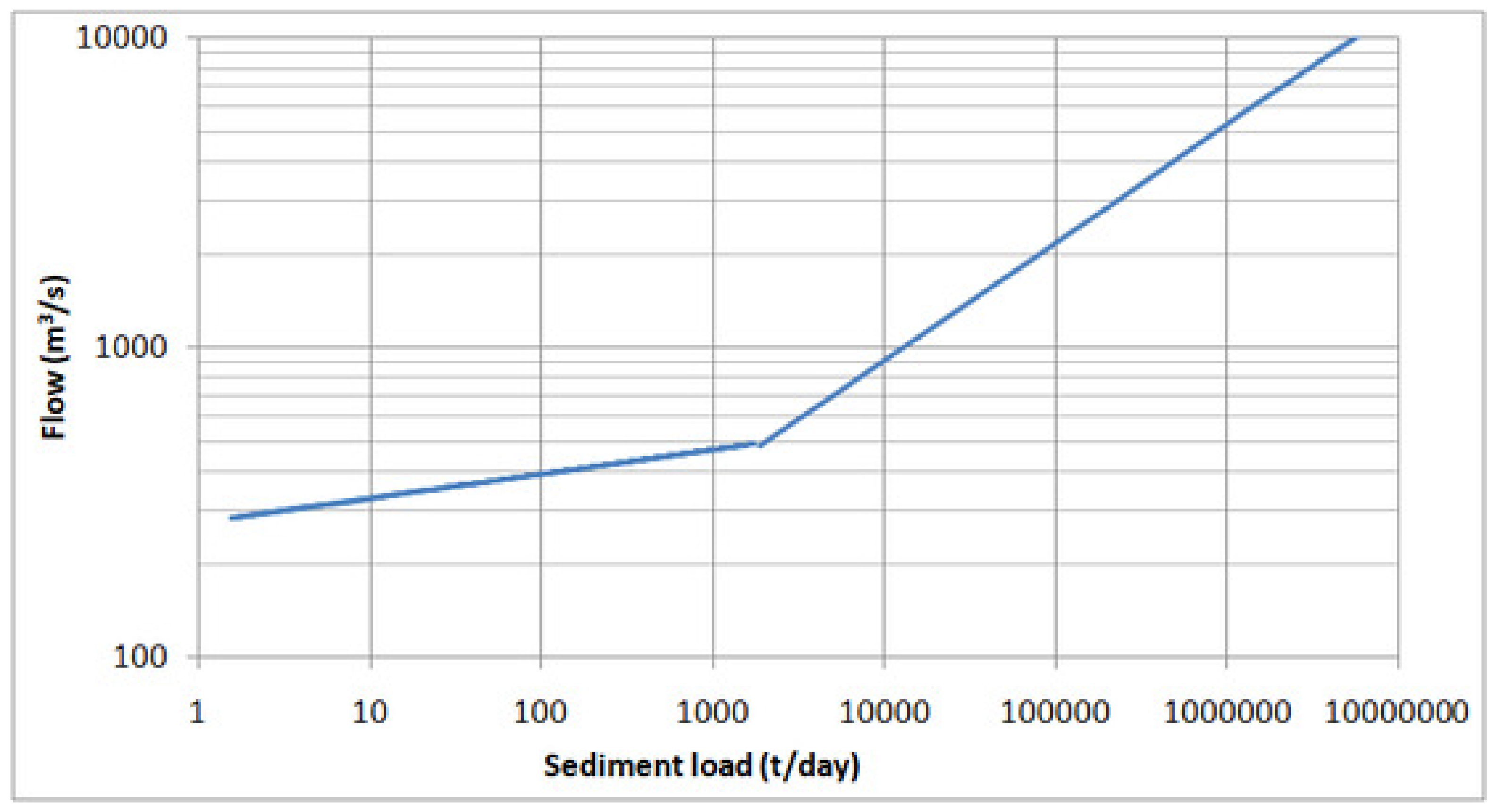
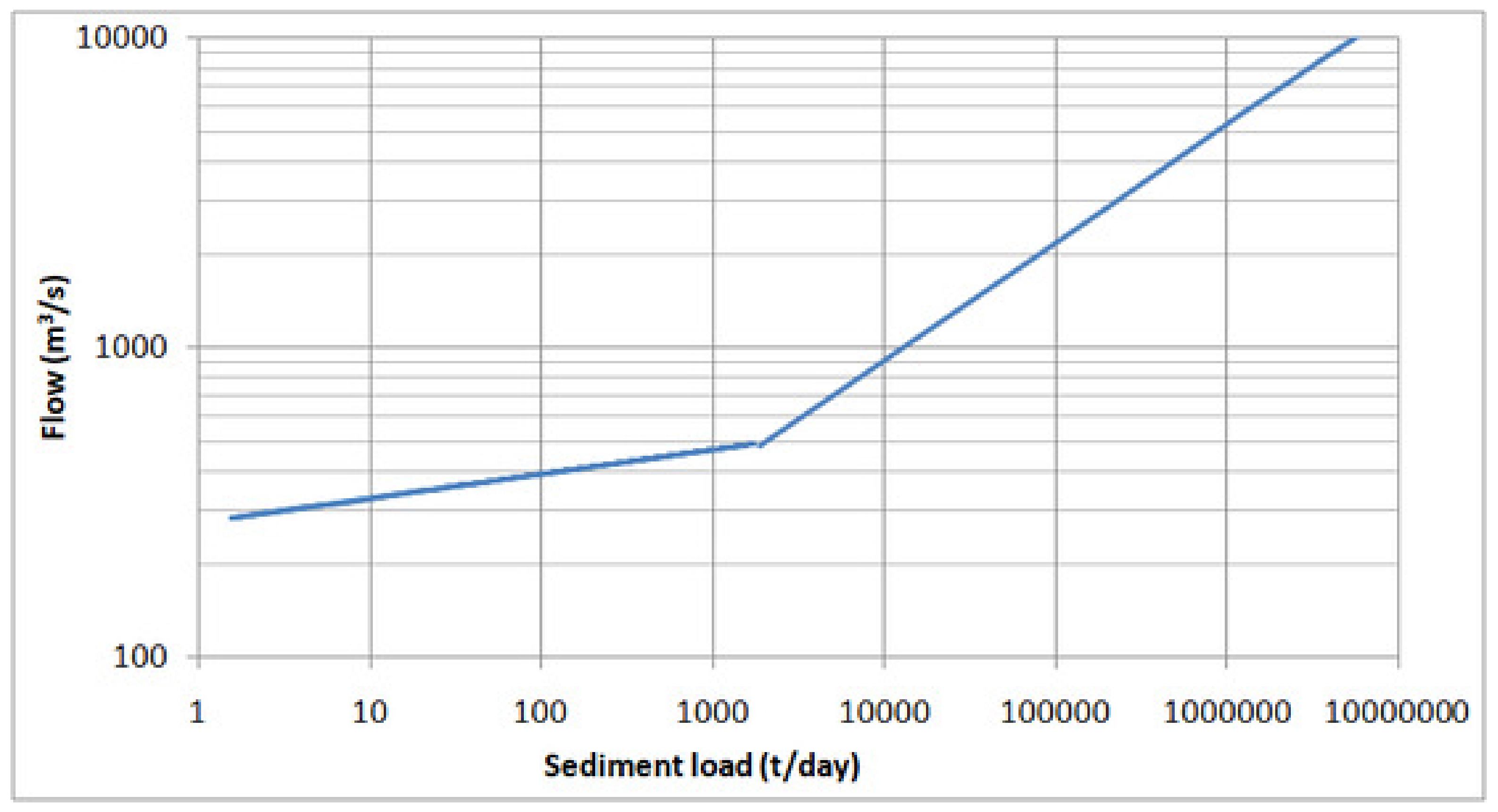
To check the performance of the SRC method (Equations (1) and (2)), sediment loads were generated and matched against observed sediment loads. The sediment equations output sediment load in t/day by the input of flow in m3/s. The generated/estimated sediment load was matched against observed sediment load entering the reservoir for that particular day. The observed sediment load was calculated by converting observed sedimentation concentration in mg/L for that day into t/day by carrying out a dimensional analysis. The calculated values of NSE, R2, and RSR were 0.635, 0.655, and 0.076, respectively, amply proving that the SRC technique, although in vogue, predicted output with an unacceptable level of certainty.
Applying the concept of data preprocessing on Besham Qila gauge station’s data developed by [
41], where he found the best relationship by selecting 70% of the input data for training, 15% for testing, and 15% for validation, we also obtained better results for the time period 1969–2014. The 70%, 15%, and 15% data from the entire available series was randomly selected for training, testing, and validation processes, respectively. It is also worthwhile to mention here that data pre-processing plays an important role where a short duration data series is available; however, our data series of more than 40 years also provided us the best results on even specifying 60% of data for training, 20% for testing, and the remaining 20% for validation. The coefficient of determination (R
2) for the training and testing datasets was 0.780 and 0.743, respectively. The Nash–Sutcliffe efficiency (NSE) was also 0.780 and 0.742 for training and testing, respectively. As our ANN trained best using single decomposition on Q(t), the inputs were only detailed and approximated coefficients of discharge without lag-time. The best trained WA-ANN used “tainsig” transfer functions in both the hidden and output layers. The number of hidden neurons in the single hidden layer of ANN was only five compared to seven for the same gauge station in [
41]. As the Levenberg–Marquardt algorithm has fast convergence and also performed well for the Indus River [
4], it also performed best in our training. The simulations stopped when the difference between the last and second to last simulation was less than 1/1000 or it reached maximum epochs of 1000 iterations. The work in [
41] used the data series from 1969–2008 and reconstructed missing data for the Tarbela Reservoir with R
2 = 0.773 and 0.794 for testing and training, respectively. The statistical performance of our WA-ANN with a larger data series up to 2014 was slightly better for training data; however, it was slightly lower for testing data, which may be due to the inclusion of the exceptionally high flood of 2010. Similarly, increasing the decomposition levels slightly affected the model performance, which, interestingly, was significantly improved in [
41]. In addition, the WA-ANN-generated sediment series showed an annual 160 Mt of suspended sediment load (excluding 10% bed load) entering the Tarbela Reservoir, which was similar to the estimate of [
41].
3.1. Model Calibration
The model was calibrated for a period of nine years (2005–2013). The gradational analysis showed that on average, the Indus River transported silt (56.68%) as compared to sand (33.94%) and clay (9.78%).
Further, an extensive analysis of available particle size data of Besham Qila gauging station for 1983, 1989, 1991, 1994, and from 2002–2012 was conducted to calculate its variations with flow. Firstly, as mentioned in the previous paragraph, the average percentages for sand-, silt-, and clay-sized particles were calculated for all flow conditions. Then, the data were segregated into different sets corresponding to the indicated flow ranges in
Table 4, and average percentages for sand-, silt-, and clay-sized particles were calculated for those particular flow ranges/bands. The analysis showed conclusively that the percentages of gradations across the sediment classes changed significantly with changing flow bands and were liable to affect sediment transport behavior as the flows increase/decrease. This analysis was important to study and model the morphodynamics across changing low and high flow bands accurately. The results are shown in
Table 4 and entered in the sediment module of HEC-RAS as an adjunct to SRC and WA-ANN load series.
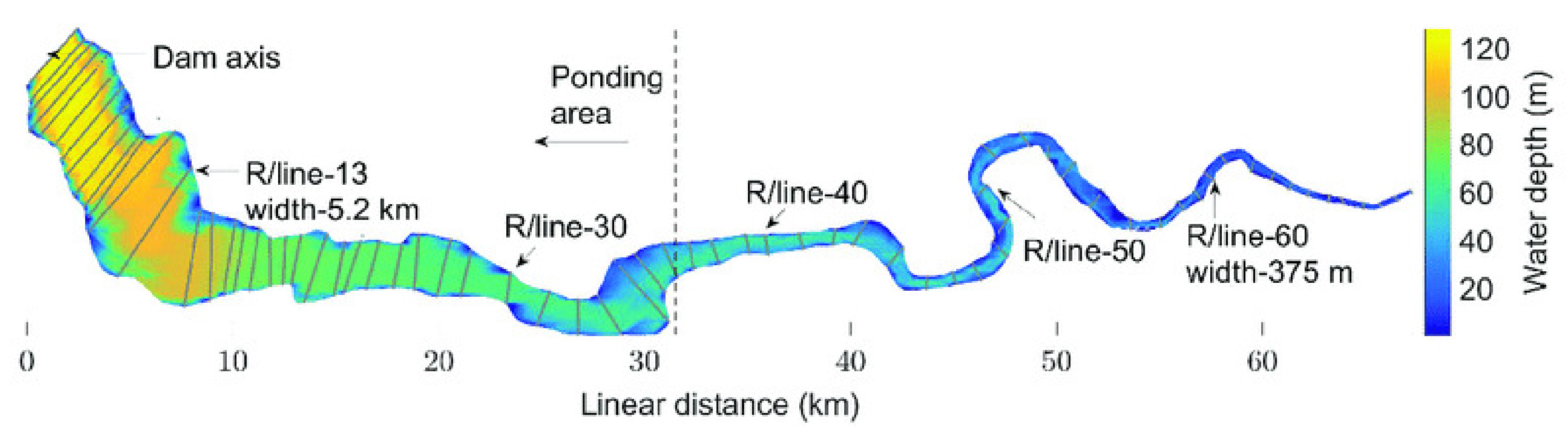
First, only hydrodynamic calibration was carried out up to 2013 by changing the value of Manning’s roughness (n) throughout the length of the reservoir and comparing the calculated water levels with the observed water levels at different locations along the 66 available cross-sections. Initially, a uniform hydraulic roughness n = 0.04 from the literature [
42,
43] was adopted and subsequently adjusted in a plausible range of 0.035–0.04, throughout the 73 R/Lines of the reservoir and by comparing with available observed water levels, achieving an NSE and R
2 of 0.916 and 0.940, respectively. Next, hydro-morphodynamic calibration was attempted by varying both bed roughness and sediment parameters in the model.
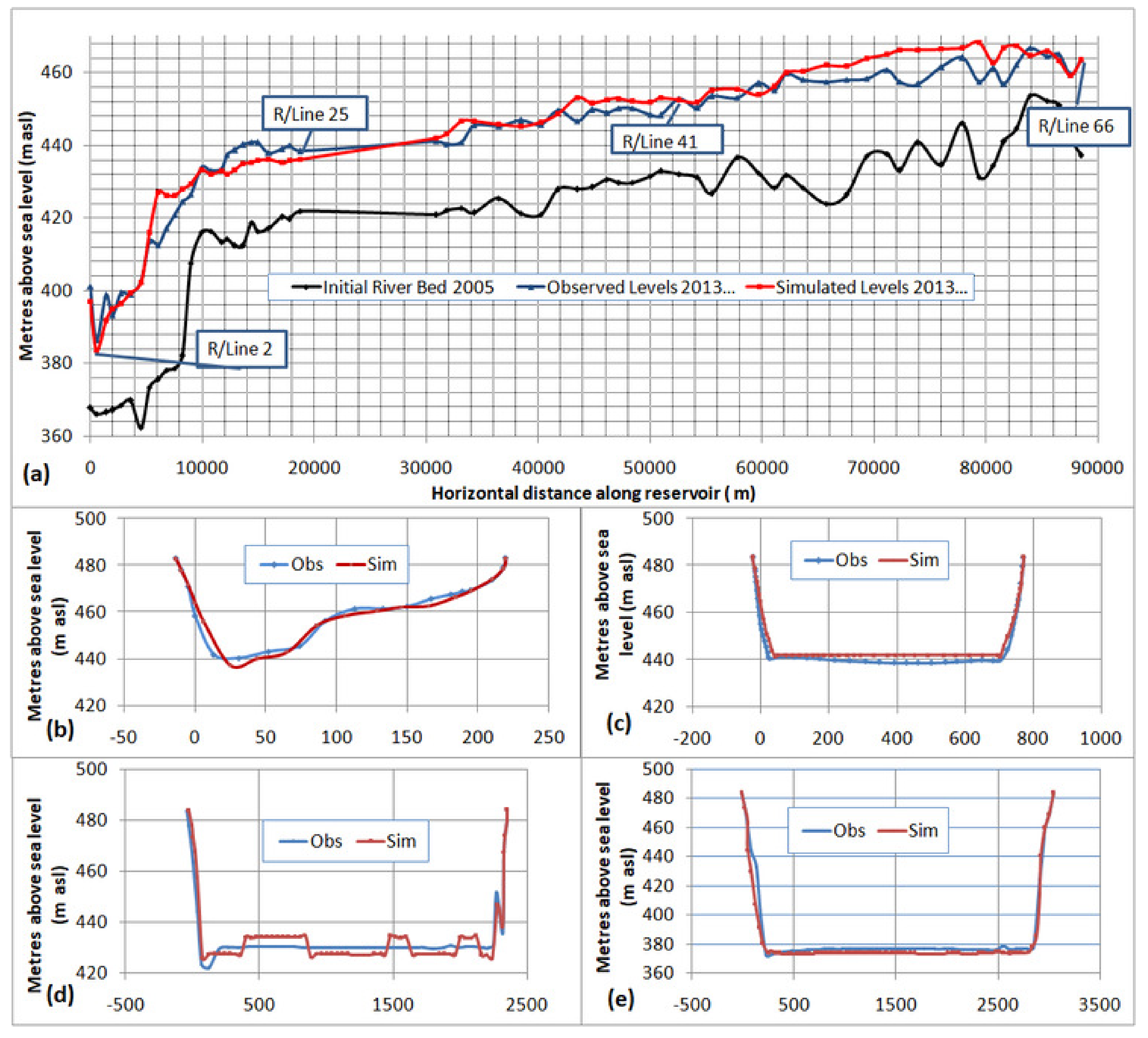
Applying SRC sediment load at the inlet, it was noticed that the Ackers–White transport formula with the sorting method of Exner (7) was producing somewhat higher values of NSE and R2. Exner (5) and Exner (7) are common bed sorting methods (sometimes called the mixing or armoring methods), which keep track of the bed gradation used by HEC-RAS to compute grain size-specific capacities and also to simulate armoring processes. Exner (5) uses a three-layer bed model that forms an independent coarse armor layer, which limits the erosion of deeper layers, whereas Exner (7) is an alternate version of Exner (5) designed for sand bed rivers as it forms armor layers more slowly and computes more erosion.
Hence, by keeping the combination of Ackers–White + Exner (7) constant, different fall velocities were tested to better the results. Amongst provisions to input commonly-used fall velocity methods like van Rijn, Ruby, and Tofaletti, HEC-RAS has an option to input the Report 12 fall velocity method, which finds solution iteratively by using the same curves as van Rijn, but using the computed fall velocity to compute the new Reynolds number until the assumed velocity matches with the computed velocity within tolerable limits. Consequently, a third tier calibration effort was attempted by varying scaling factors for transport and mobility functions of the transport formula as allowed by the HEC-RAS model for calibration fine-tuning, the result of which emerged with NSE and R
2 of 0.943 and 0.959, respectively. The default value of scaling factors was one, which was manipulated to achieve the maximum hydrodynamic calibration of NSE and R
2 of 0.996. It is worth mentioning here that for the sediment simulation and management study in Tarbela Reservoir in 1998 [
44], the Ackers–White transport formula [
45] was selected. The work in [
43] also suggested the adoption of the Ackers–White formula, for the total load transport capacity of sand-sized fractions. However, other formulas were also tested in the calibration process as detailed in
Table 5. A comparison with observed bed levels of 2013 was made and presented in
Figure 7.
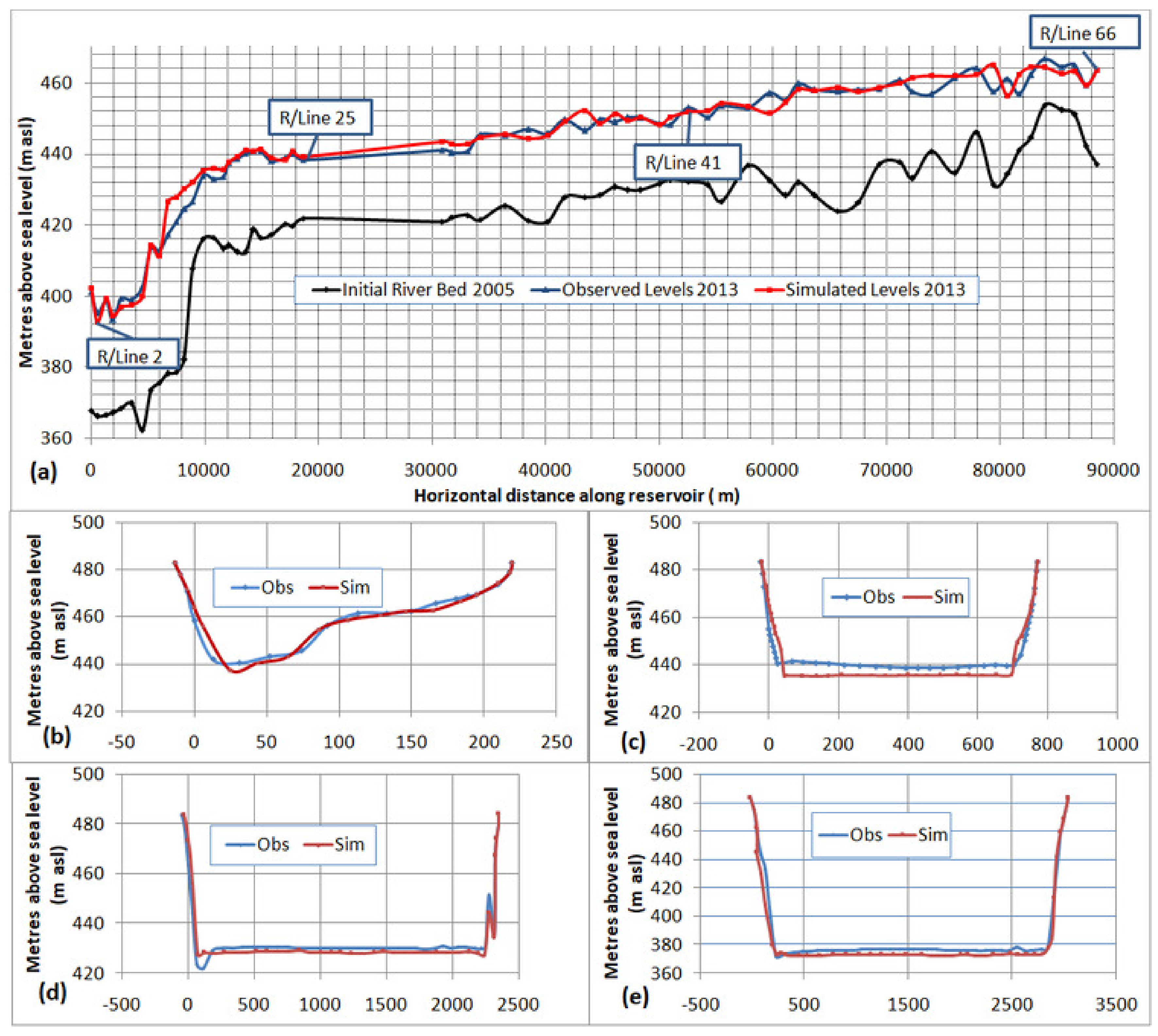
Further, another extensive calibration exercise was carried out applying WA-ANN-based boundary conditions. Again, the Ackers–White transport formula with the sorting method of Exner (5) showed better results. Next, the above combination (Ackers–White + Exner-5) was evaluated by changing the fall velocity equations. Similar to the SRC case, the Tofaletti technique showed the best results hitherto, prior to application of scaling factors. Consequently, the best combination of input parameters (Ackers–White + Exner-7 + Tofaletti) was subjected to rigorous scaling of transport formula parameters. Hence, the highest NSE of 0.979 was achieved during calibration, and the results of the exercise tabulated in
Table 6 in increasing order of NSE values. A comparison with observed bed levels of 2013 was made and presented in
Figure 8.
3.2. Model Validation
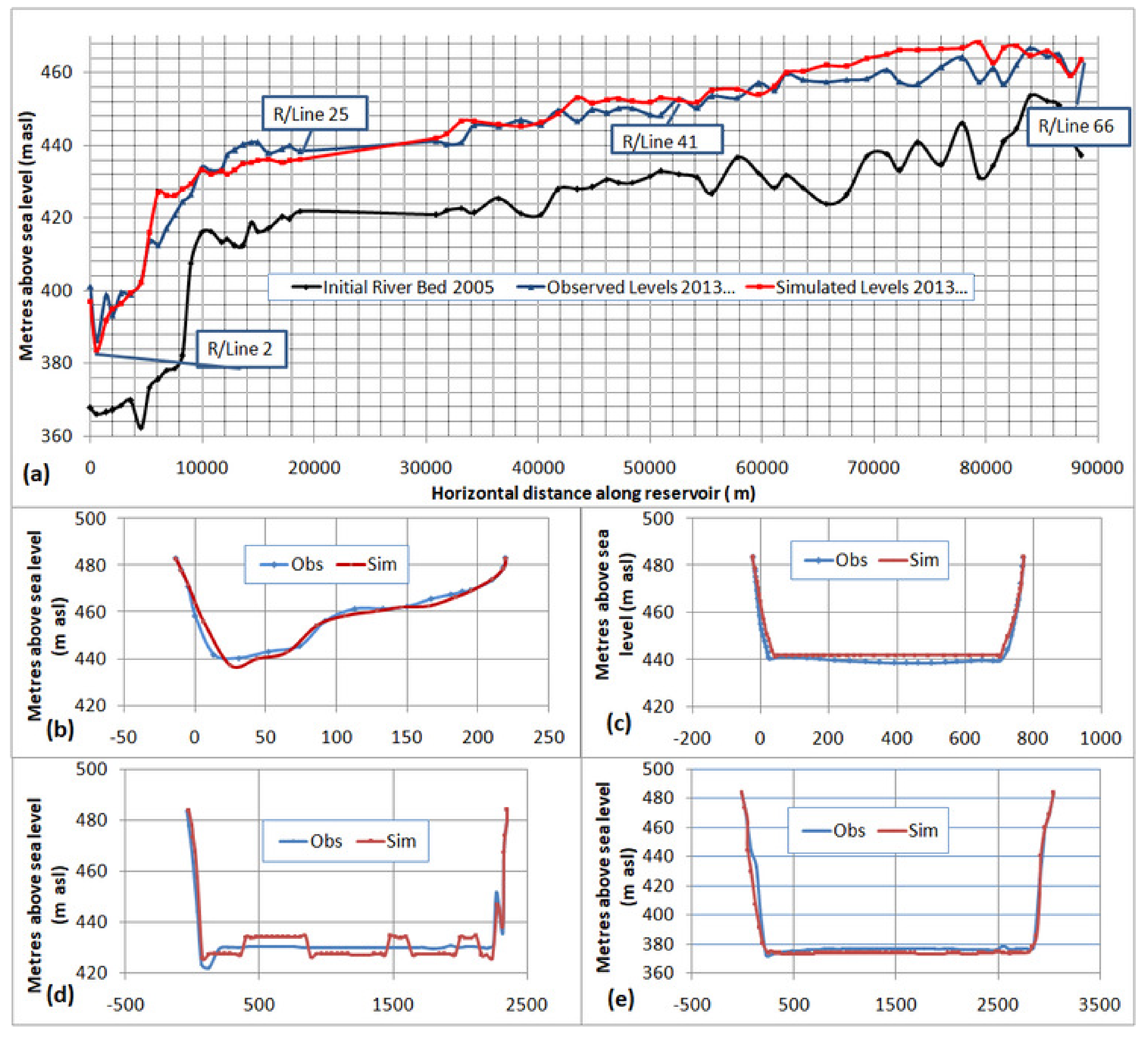
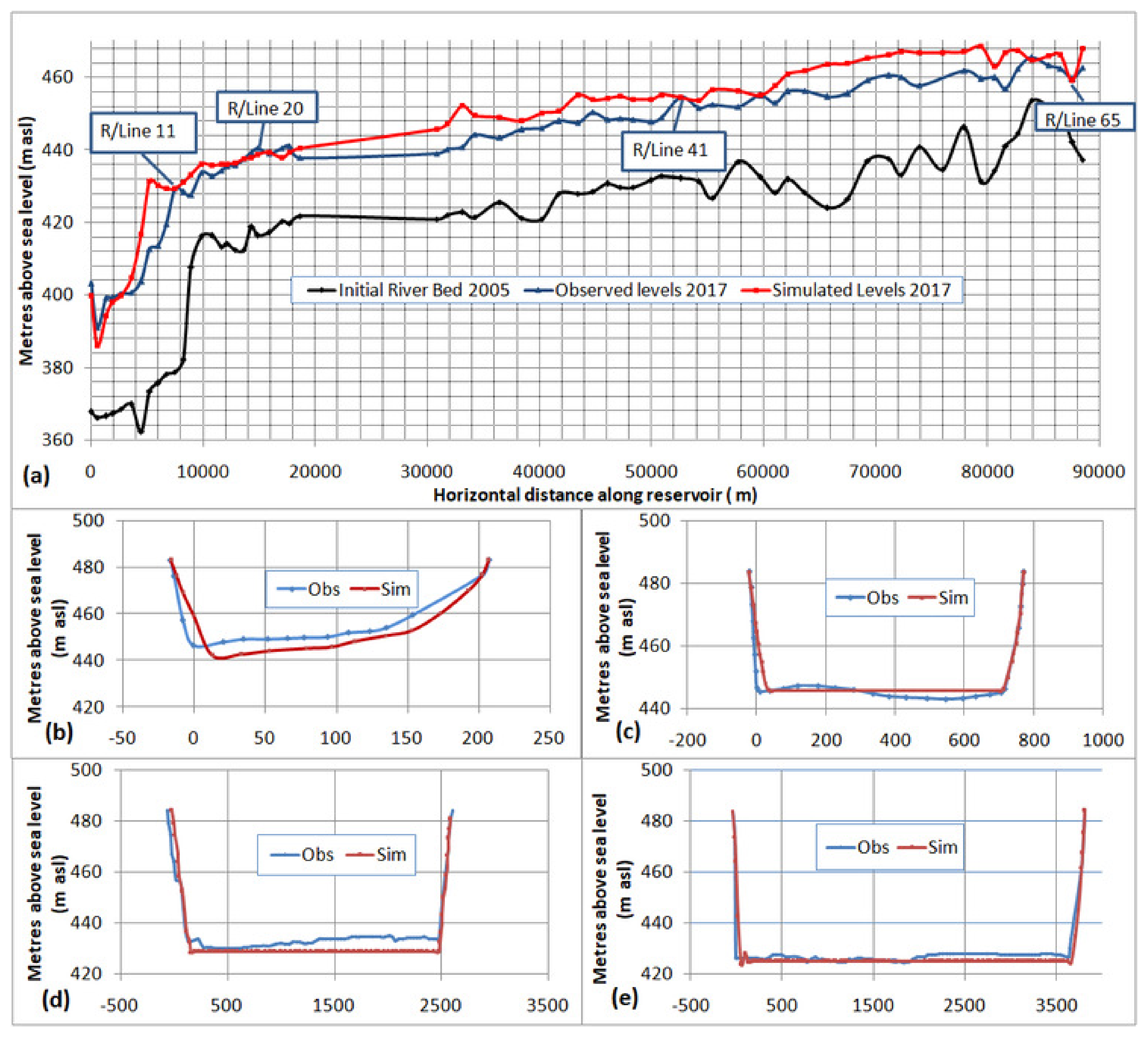
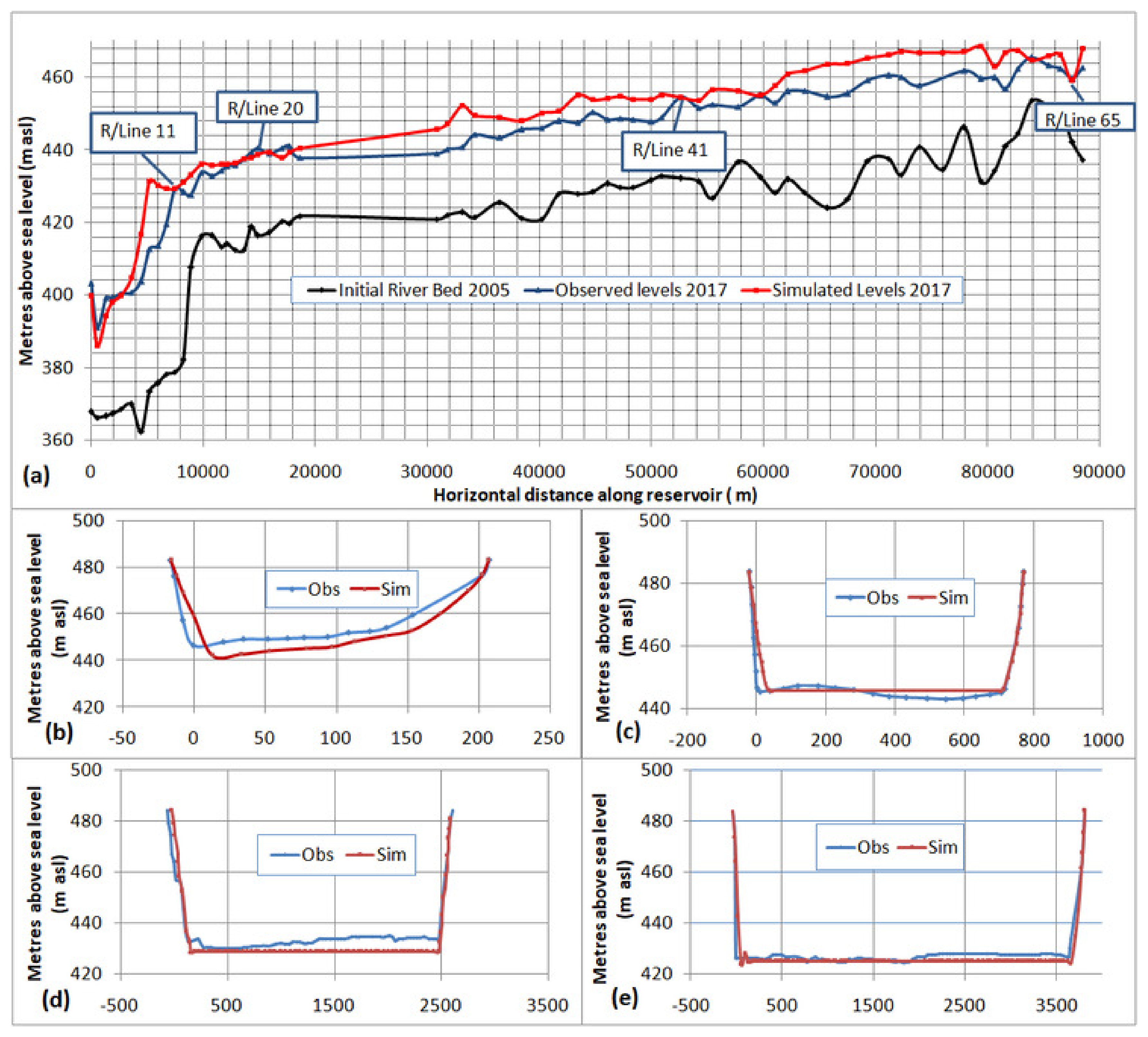
To validate the HEC-RAS model with the SRC technique, it was run for another four years up to 2017. The output was compared with observed sediment deposits of 2017 and is presented in
Figure 9.
The R
2 and NSE in the validation process were 0.950 and 0.893, respectively. The observed standard deviation was at 0.041. In a recent study [
46], the HEC-RAS model was validated for the Tarbela Reservoir by simulating it only for one year, and an approximately 20-m difference between the observed and simulated river beds for the sediment delta in the year 2000 was found. However, in the present study, the difference of four years of simulation was only 4–5 m in the whole longitudinal profile (
Figure 9). A better modeling performance might be due to more accurate sediment load boundary conditions generated using a long-term data series, i.e., 1969–2014, whereas [
46] used only a 28-year data series, i.e., 1979–2006.
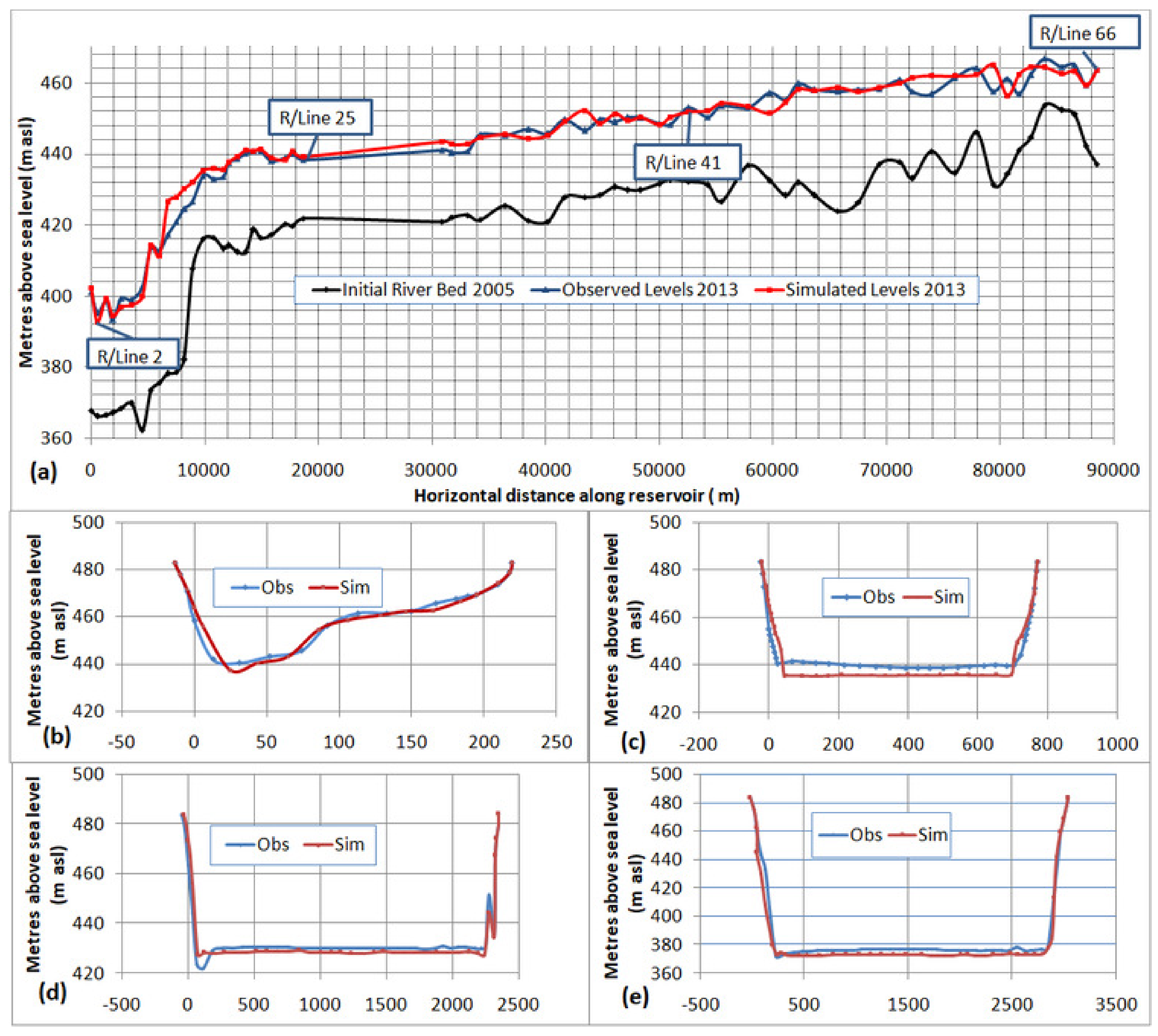
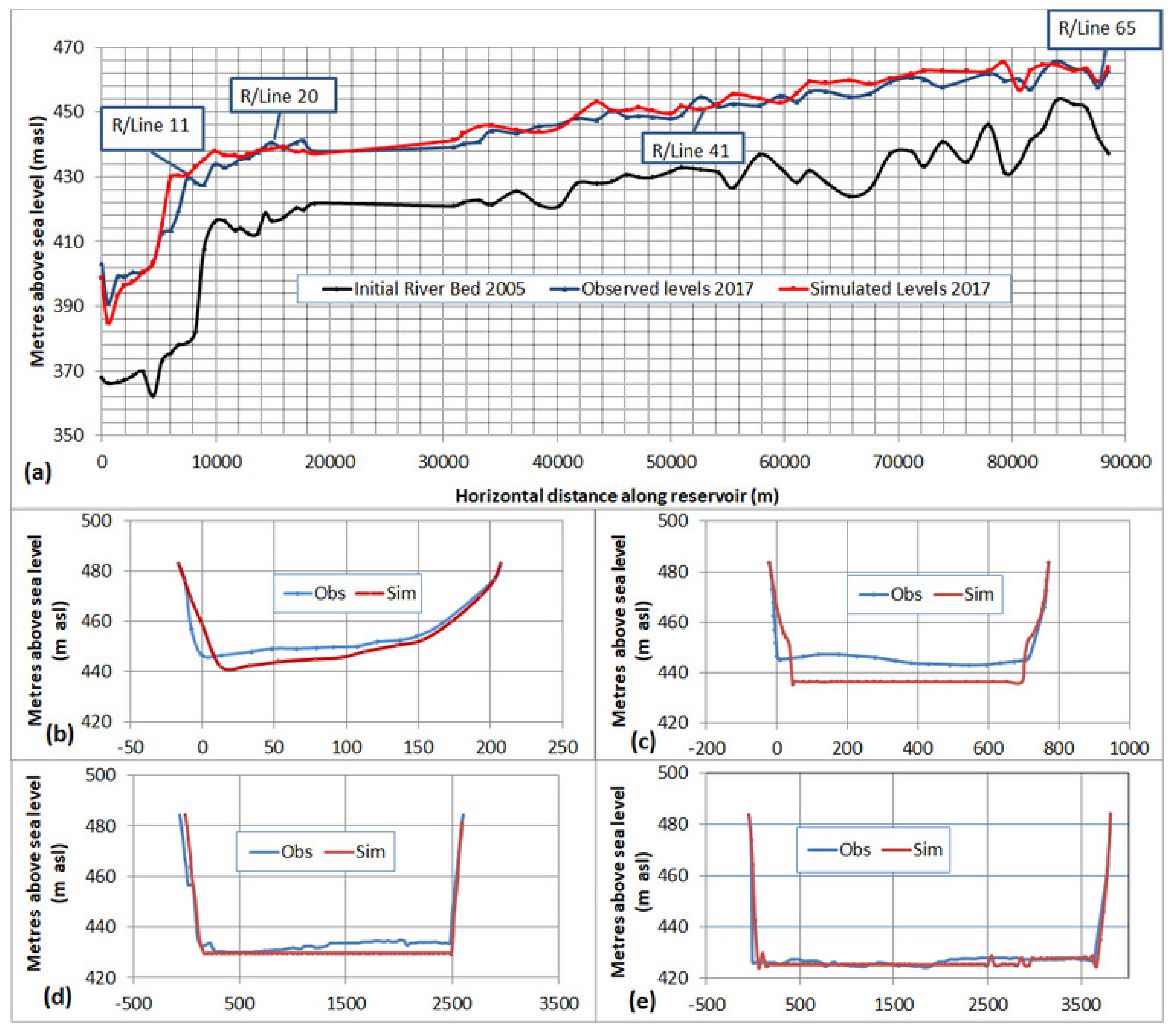
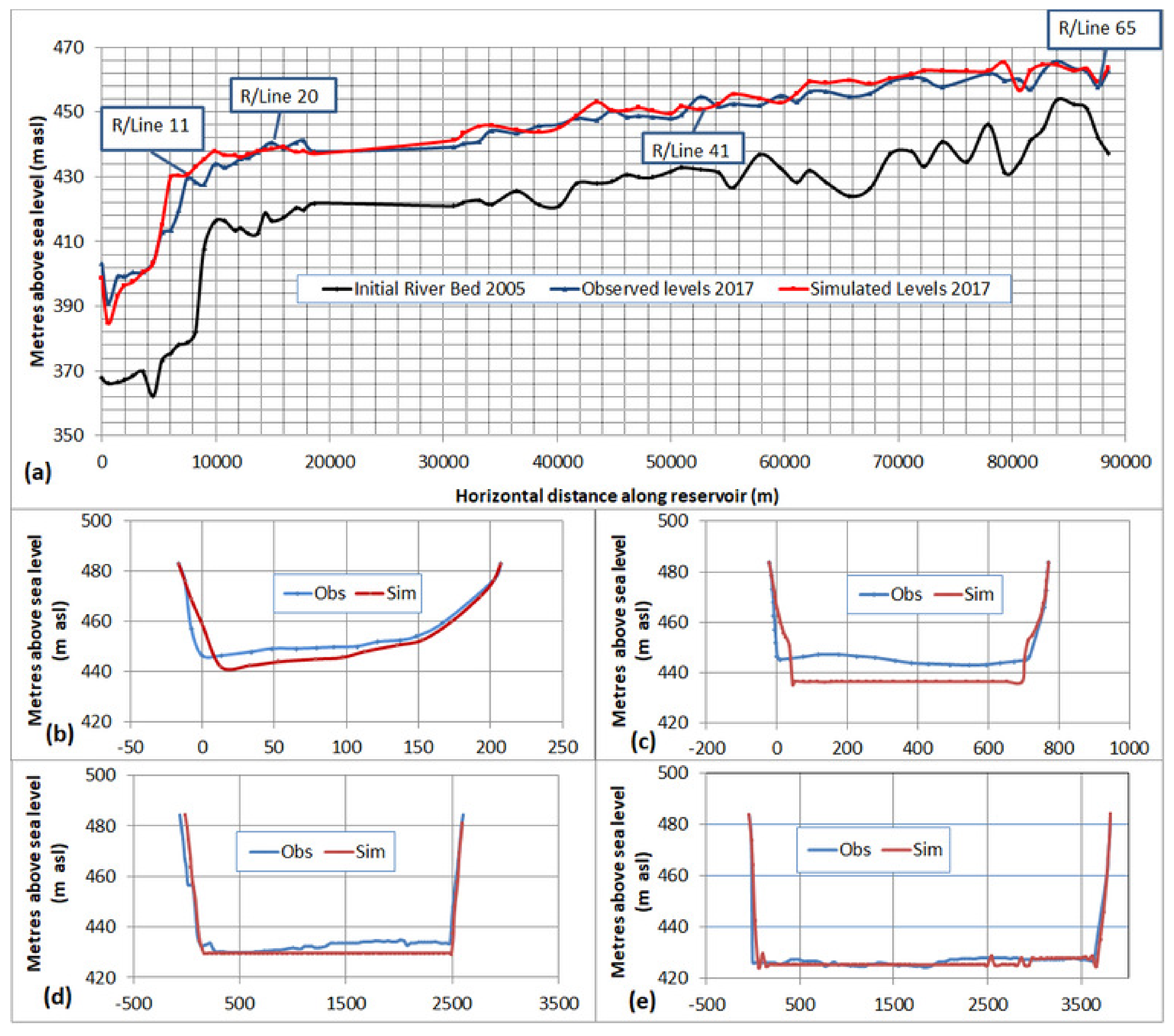
To validate the HEC-RAS model with the above calibrated WA-ANN sediment series, it was run for another four years up to 2017, similar to the SRC model. The output was compared with observed sediment deposits of 2017 and presented in
Figure 10. The R
2 and NSE in the validation process were 0.968 and 0.959, respectively. The observed standard deviation was at 0.025.
3.3. HEC-RAS Model Performance with the SRC and WA-ANN Techniques
To sum up the above-elaborated calibration and validation exercises using SRC and WA-ANN-based boundary conditions, their statistical performance was compared and tabulated in
Table 7. The statistical results (
Table 7) clearly indicated a preferable performance of the model using WA-ANN-based sediment load boundary conditions. As SRC reconstructed the missing sediment load data with R
2 and NSE at 0.635 and 0.655, respectively, the model calibration took a long time to adjust transport parameters for attaining stability. However, due to better recondition accuracy using WA-ANN (R
2 = 0.771 and NSE = 0.771), the HEC-RAS model simulated the bed-levels changes with great stability. As the SRC overestimated sediment load, therefore to flush extra sediments, we needed to adjust the transport parameters that might not represent the correct physics of the transport processes in the reservoir. Therefore, more accurate boundary conditions played a vital role in precise modeling of the transport processes by keeping transport parameters within the physical limits.
3.4. Models’ Application for Sediment Delta Prediction
More than 200 million people of Pakistan directly or indirectly depend on the irrigation supply and power generation from the Tarbela Dam. Therefore, it is very important to assess the future delta movement and sedimentation scenarios in the reservoir. It is pertinent to mention here that SRC-generated sediment load boundary conditions are being used for all types of sedimentation modeling in the upper Indus River projects [
21,
42]. Therefore, to check and ascertain the long-term application of the SRC and WA-ANN techniques, the HEC-RAS model was run up to the year 2030 using future discharges calculated by [
35] employing the University of British Columbia (UBC) watershed model. UBC is a less data-extensive semi-distributed watershed model developed by the University of British Columbia. As discharge alone with one level of decomposition represents more accurately the transport processes at Besham Qila, calculated future discharges by [
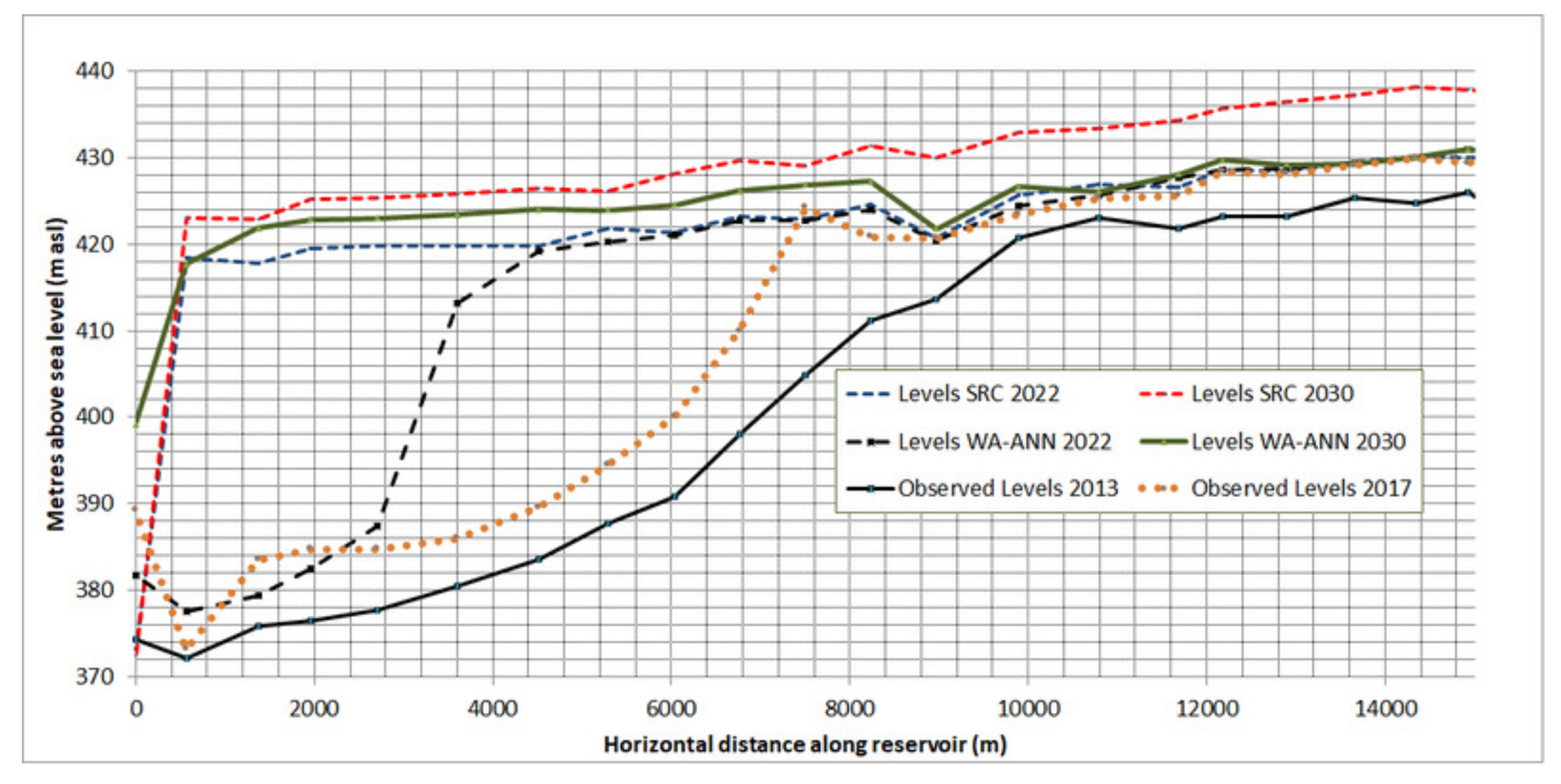
35] were used in the trained WA-ANN model for obtaining future sediment loads. Reservoir water levels from 2005–2018 were repeated for 2019–2030. The simulated/forecasted levels of the Tarbela Reservoir for 2022 and 2030 along with observed levels of 2013 and 2017 showed a huge volume lost due to sedimentation (see
Figure 11). As SRC showed overestimation (190 Mt of suspended sediment load (SSL) compared to 160 Mt SSL using WA-ANN) for the Indus River (
Table 1), therefore, using SRC as the boundary condition in the modeling process also overestimated the bed level variations in the major ponding area of the reservoir near the dam. As SRC has been used for sedimentation modeling of all studies of the Upper Indus River, and it has been predicting similar results. For example, the 4320-MW Dasu Hydropower Project, which is under construction upstream of Tarbela Dam, will be silted up just 20–25 years after its commissioning without conducting yearly flushing operations [
21,
41]. The predicted short life of the Dasu project could very likely be a result of the overestimation of sediment load using SRCs. Initially, the work in [
13] in 1970 also estimated 400 Mt of sediment load using SRC for the Tarbela Reservoir, which showed a shorter life of the reservoir. However, later studies estimated 50% lower sediment load for the Indus River at Tarbela Dam (see
Table 1). Due to less sediments entering the reservoir, it is still operational and not silted-up. It might be possible that in 1970, very limited sediment concentration data were available, which might have consisted of high-flow hydrological years. However, the availability of long data series of sediment sampling cannot help SRC to model the hysteresis phenomenon and hydrological variations related to shifting in high flows from summer to post- and pre-summer months at the Upper Indus Basin [
41]. Therefore, the WA-ANN-generated sediment load boundary condition, using future projected discharges, can more precisely represent the sedimentation modeling processes.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}