1. Introduction
Flood risk management includes flood risk analysis [
1,
2,
3], vulnerability analysis [
4,
5,
6], flood disaster assessment [
7,
8,
9,
10], and response [
11,
12,
13]. Several factors can influence the risk of flood disasters, such as astronomy, meteorology, hydrology, topography, landforms, and human activities. Obviously, the interaction between such heterogeneous factors cannot be described clearly by using only one variable and, therefore, the study of multivariable joint distribution models is a significant facet of research on flood risk analysis [
14,
15].
Multivariable joint distribution models can be divided into two types [
16] based on the characteristics of marginal distribution functions. There are models with the same marginal distributions (such as the multivariate normal model) [
17,
18,
19] and models with different marginal distributions (such as the meta-Gaussian model) [
20,
21,
22]. Considering the actual situation of a flood disaster, the second type of model is more appropriate, as choosing marginal distributions is more flexible. However, the requirement of correlation between variables in some models (such as the Farlie-Gumbel-Morgenstern model [
20]) limit the application range of such models. Consequently, the copula function, that has a more flexible structure, has been introduced in flood risk analysis. Then, researchers study the various aspects of the copula function, such as function type selection, parameter estimation, and the goodness-of-fit [
23,
24,
25,
26]. In hydrology, the application of copula function, generally, includes several parts, which are as follows: (1) frequency analysis of hydro-meteorological variables that have multi-feature attributes, such as flood duration, flood volume, and flood peaks [
27,
28]; (2) the encountering combination problem of different hydrological extreme events, such as an interval rainstorm combined with river flooding [
23,
24,
29]; and (3) bias correction techniques, that are used generally in climate and hydrological modeling [
30,
31,
32]. The study of flood risk analysis involves all these aspects.
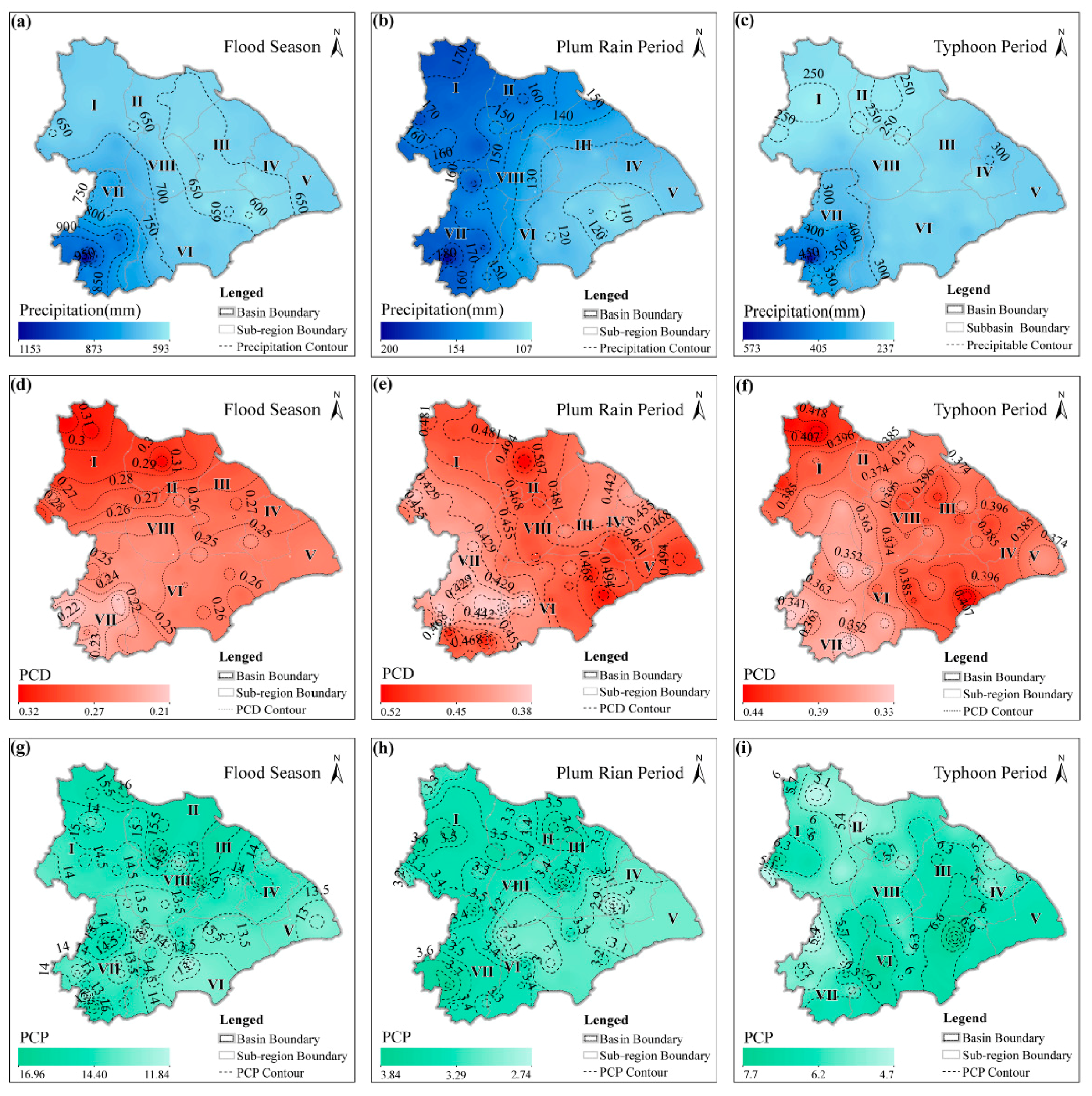
Under the influence of different climatic phenomena, the types of precipitation in the Taihu Basin are divided into plum rain and typhoon rain. Statistical data indicate that the duration of the plum rain differs each year, with the average being approximately 20 days. Generally, the plum rain period starts in the middle of June, and ends in early July. Mid-May is the earliest month when the typhoon rains starts to affect the Taihu Basin, with the latest being middle November. However, most typhoons occur between July and September and, particularly, between late August and early September.
The different types of precipitation bring about spatial and temporal differences in flood risk, which leads to significant challenges in flood management in the basin. Hu et al. [
33] constructed the joint distribution functions of typhoon and plum rain with the Gumbel copula function and pointed out that the encounter probability of typhoon and plum rain is 9.23% in the Taihu Basin. Taking into account a particular typhoon’s birthplace, movement path, and rainfall characteristics, Cui et al. [
34] put forward a concept of typhoon impacting the Taihu Basin. This concept points out that there are three kinds of typhoon which could affect the Taihu basin. It is useful information for typhoon emergency management. Liu et al. [
28] used the Frank copula function to study the correlation between the start time of the plum rain period and the rainfall amounts of this period in the Taihu Basin. The results showed that when the plum rain period started early, more attention would need to be paid to flooding.
The above-mentioned studies mainly estimate the hydrological variables encountering combination problems, and they focus on the entire flood season [
25,
35,
36]. However, compared with other situations, the encountering probability of hydrologically extreme events is small, as shown in previous study results. For example, in the Taihu Basin, the probability of only plum rain arising or only a typhoon occurring is 90.77%, compared with the occurance of plum rain and typhoons [
33]. Accordingly, the primary objectives of this research are; (1) to analyze the temporal characteristics of plum rain and typhoons in the research areas and to divide the flood season into the plum rain period and the typhoon period; (2) to study the precipitation heterogeneous in different climatic phenomena and identify the flood risk during the different periods; and (3) to build a proper copula-based Bayesian network model for flood control in the Taihu Basin.
3. Methodology
3.1. Flood Season Staging Based on the Different Climatic Phenomena
Under the influence of continental polar air masses, maritime tropical air masses, and tropical cyclones, the precipitation in the Taihu Basin include, plum rain and typhoon rain. The flood season can be divided into the plum rain period and the typhoon period according to the climatic phenomenon occurrence times. The intensity of rainfall is small in the plum rain period but the duration is long, whereas, during the typhoon period, the rainfall intensity is larger and the duration is short. Precipitation with such varying characteristics obviously leads to differing flood risks, as well as significant challenges to flood management in the basin.
3.1.1. Distribution Function of Plum Rain and Typhoon Occurrence Times
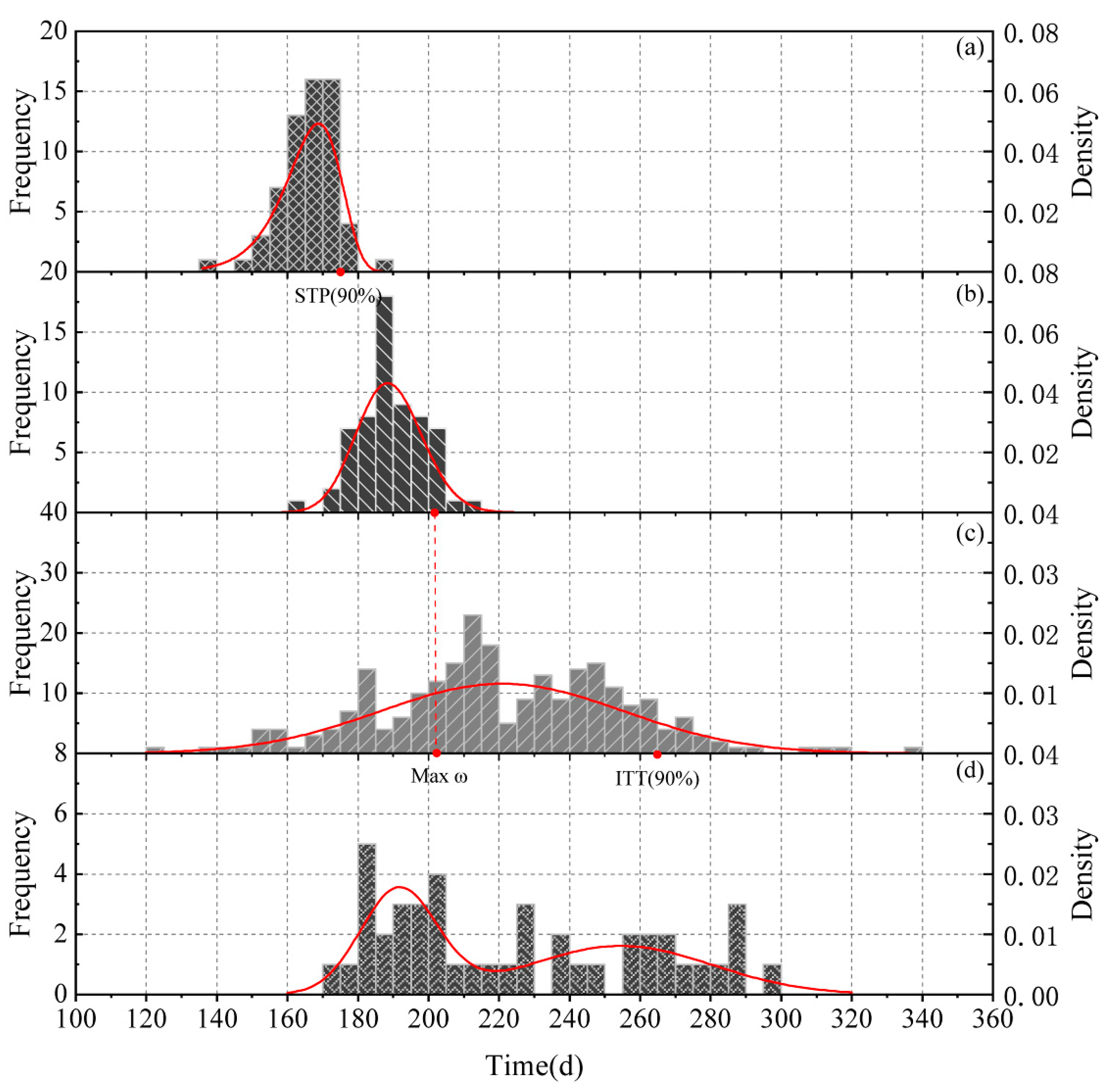
The start time of the plum rain period (STP) and end time of the plum rain period (ETP) and the initial time when typhoon begins to affect the Taihu Basin (ITT) were chosen as indices to describe the occurrence time rule of plum rain, and typhoon, respectively. Norm distribution, Log-norm distribution, Gamma distribution, Beta distribution, Logistics distribution, and Weibull distribution, the six distribution functions commonly used in hydrology and meteorology, were chosen as candidate functions, and the maximum likelihood method was used for parameter estimation. The Kolmogorov-Smirnov (K-S) goodness-of-fit hypothesis test was applied to test the six distribution functions. In addition, the Probability Point Correlation Coefficient (PPCC), Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and the Deterministic Coefficient (DC) were used to determine the most suitable probability density function (PDF) and cumulative distribution function (CDF) for relevant random variables (STP, ETP, and ITT). The definition of each test method is as follows:
where
xi and
yi represent the empirical frequency, and theoretical frequency, respectively;
and
are the mean of empirical frequency and theoretical frequency, respectively; and
n is the number of samples.
3.1.2. Flood Season Staging and Results Verification
We chose the point-in-time when the STP cumulative is 90% as the starting point of the plum rain period, and the point-in-time when the ITT cumulative distribution is 90%, as the end time of the typhoon period (the 90% percentile is the closest to the actual situation). The coefficient ω was proposed to calculate the time when the plum rain period ended and the typhoon period started. We determined the time node of the demarcation point between the plum rain period and the typhoon period using this coefficient. The time node with the maximum ω value was chosen. The coefficient ω can be calculated as follows:
where ω represents the contribution rate of plum rain and typhoon to precipitation,
is the CDF of the ETP, and
is the CDF of the ITT.
The flood season staging results were tested against the Taihu Lake water level, which is the response factor of precipitation. Considering the actual situation, we chose the mixture normal distribution to fit the time when the water level of the Taihu Lake exceeds the warning water level (TWL). The warning water level of Taihu Lake is 3.8 m (according to the flood control project of the Taihu Basin [
37]). The mixture normal distribution definition is as follows:
where
α1 and
α2 are the weight coefficients (
α1 +
α2 = 1),
μ1 and
μ2 are the means of the samples, and σ
1 and σ
2 are the mean square deviations of the samples.
3.2. Division of Precipitation Sub-Region Based on Hydrological Regionalization
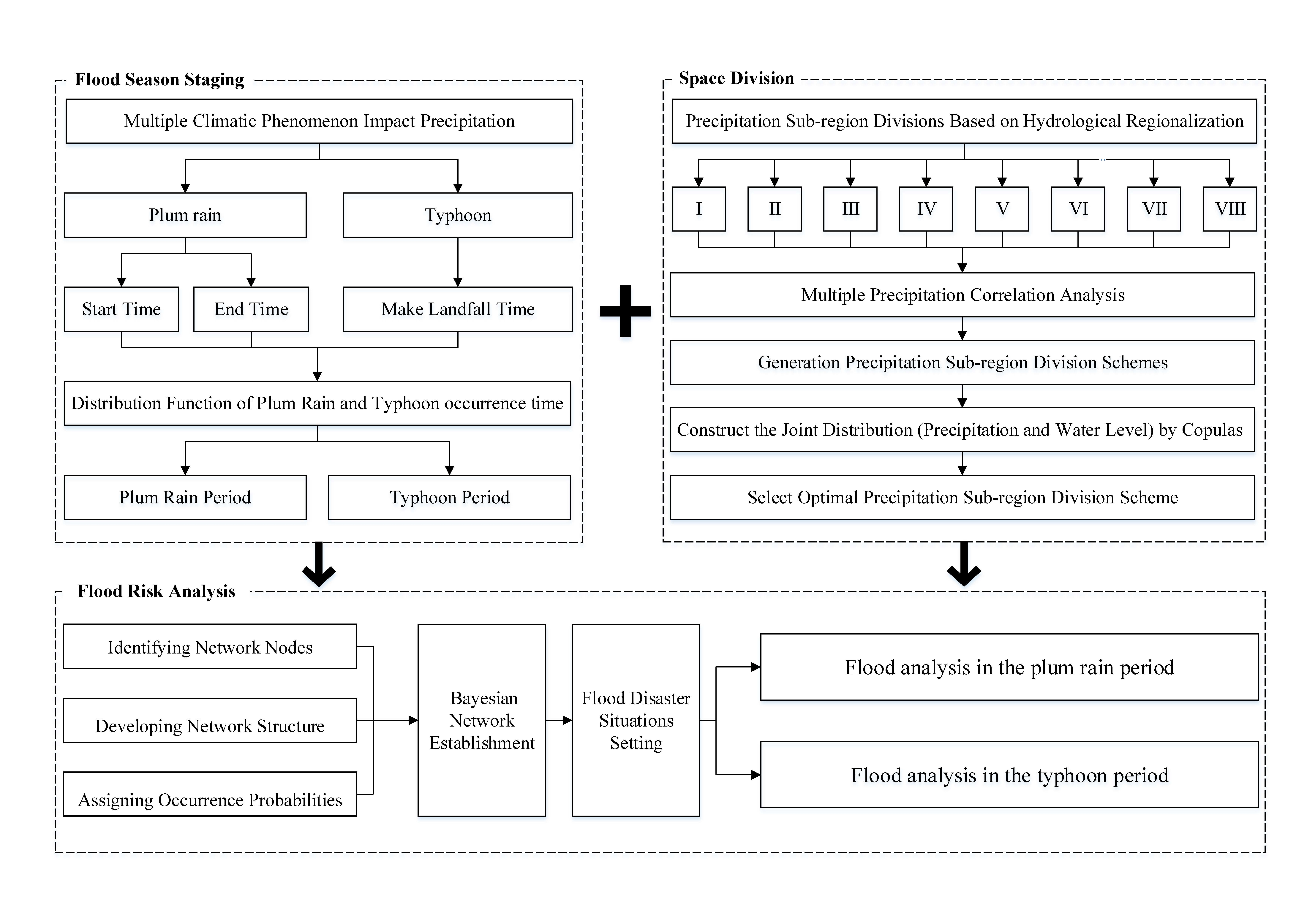
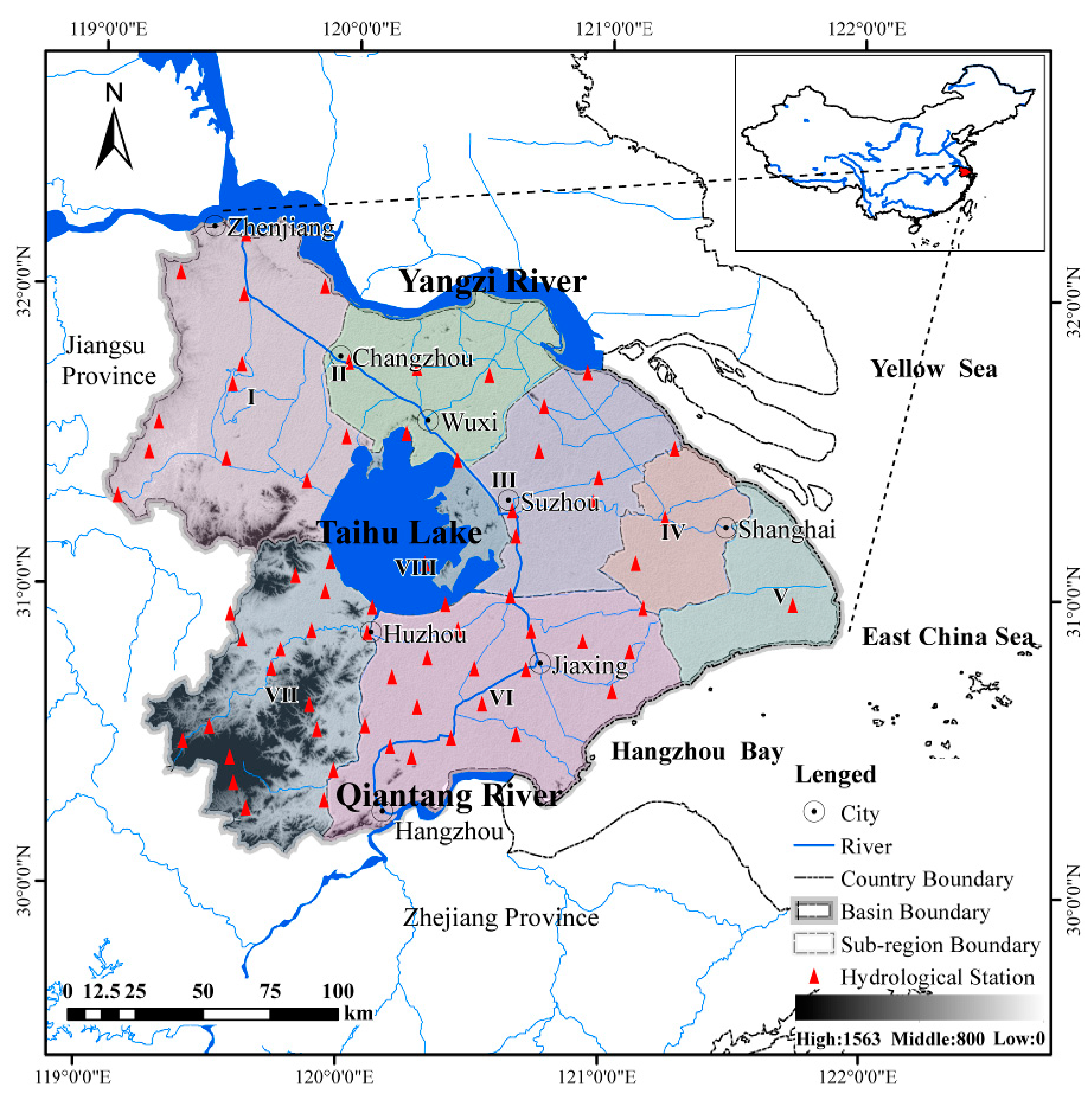
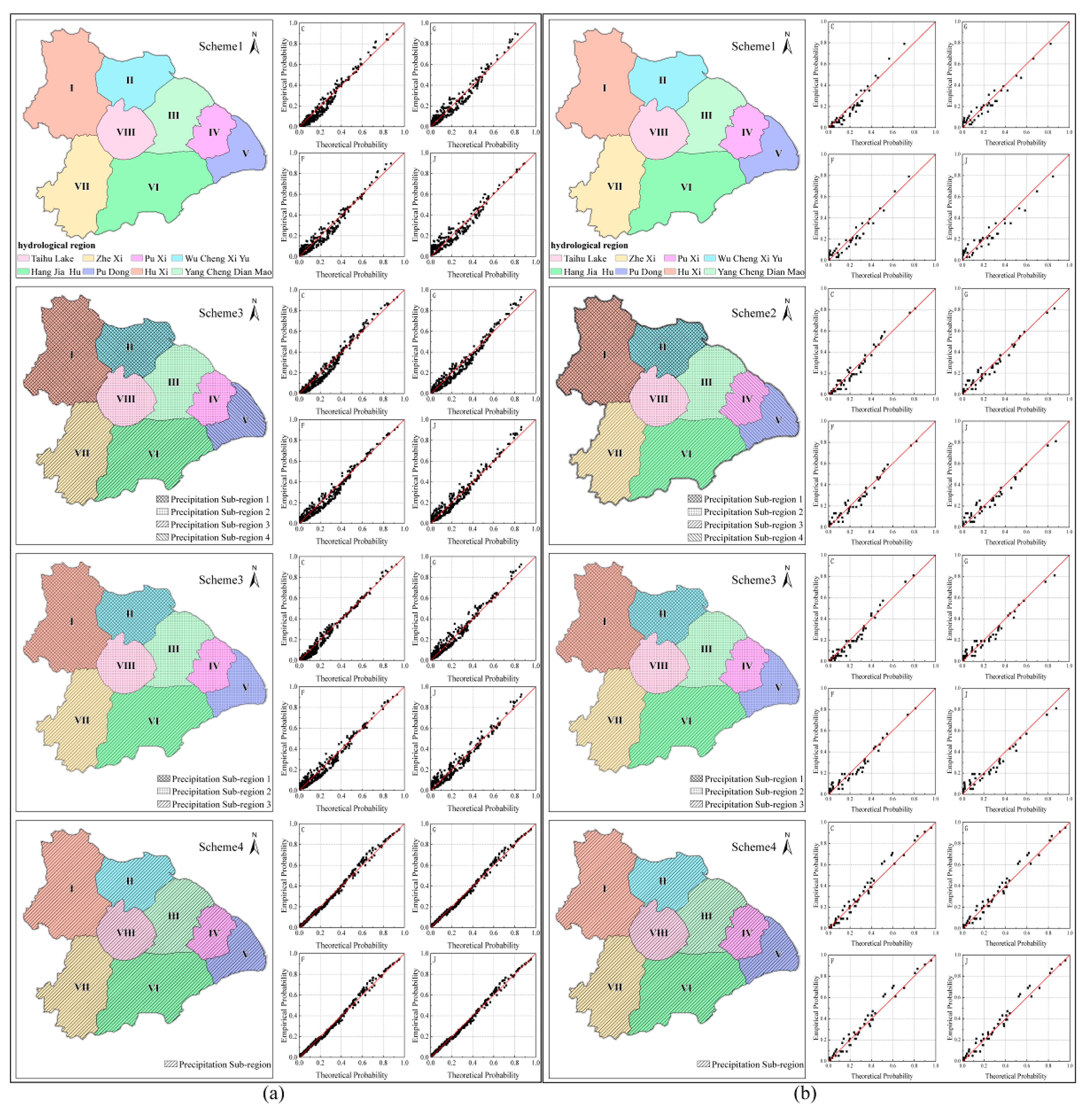
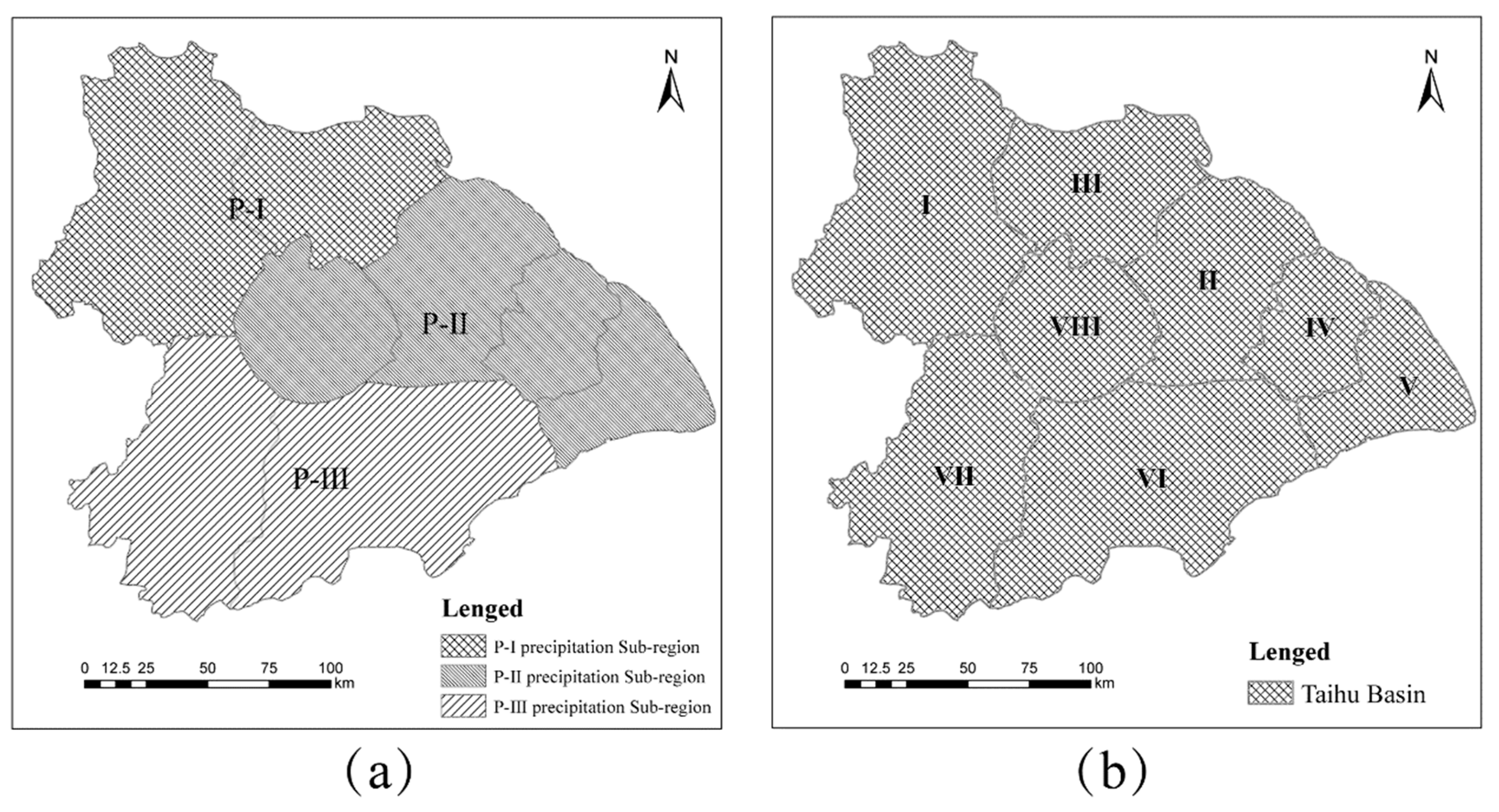
Optimal division of the precipitation sub-regions was carried out in two steps, namely; (1) clustering of the hydrological sub-region, and (2) selection of the optimal precipitation sub-region division. The first step is based on the division of eight sub-regions (I, II, III, IV, V, VI, VII, VIII), which is the result of hydrological regionalization. In any hydrological sub-region, the geographical and hydrological conditions are the same, and the construction and planning of the water conservancy projects are mutually compatible. However, the different hydrological sub-regions can have similar precipitation characteristics. To respectively divide the precipitation sub-regions in the plum rain period and the typhoon period, correlation analysis methods were used. The second step is based on the relationship of regional precipitation and the Taihu Lake water level, which plays a significant role in flood control. The Copula functions were applied in the selection of optimal precipitation sub-regions division. This method not only maintains the hydraulic connection between the sub-regions, but also considers the spatial distribution of precipitation.
3.2.1. Clustering of Hydrological Sub-Regions Based on the Correlation Analysis of Precipitation
First, the Thiessen polygon method was used to calculate precipitations of the eight sub-regions during the plum rain and typhoon periods. Next, Person correlation, Spearman correlation, Kendall correlation, which are the three correlation analysis methods generally used in hydrology and meteorology assessments, were chosen to analyze the precipitation correlation between each sub-region. Finally, the sub-regions with strong precipitation correlations were merged successively.
3.2.2. Select Optimal Precipitation Sub-Regions Division by Copula Functions
The optimal precipitation sub-region division, which best reflects the relationship between precipitation and water level, was selected using Copulas. Copulas are defined as multivariate distribution functions with uniform margins on the interval 0 to 1. Based on Sklar’s theorem [
38], copulas are capable of linking the joint CDF to its marginal distribution functions [
39].
The joint distribution of sub-region precipitations and the Taihu Lake water level can be expressed by a copula as follows:
where
H is a joint distribution,
n is the number of precipitation sub-region,
Fi(
xi) represents the marginal distribution of the
i-th sub-region precipitation,
F(
y) represents the marginal distribution of the Taihu Lake water level, and
Cθ is the copula CDF with parameter
θ.
We selected four widely used Archimedean copulas (Clayton, Gumbel, Frank, and Joe copulas) as the candidate functions to model the joint distribution of regional precipitation and the Taihu Lake water level. The four Archimedean copula functions are defined in
Table 2 [
39].
Estimating parameter
θ of the Archimedean copulas can be done by using different parametric and semi-parametric methods, such as Kendall’s
τ method, Spearman’s
ρ method and maximum likelihood-based methods (MLs). MLs include the full maximum likelihood method (FML), the inference for margins method (IFM), and the canonical maximum likelihood method (CML). We used the IFM for parameter estimation [
40,
41].
Several commonly evaluation criteria were used to select the optimal copula functions [
42], such as the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). The definition of the evaluation criteria are as follows:
where
L is the likelihood function,
k is the number of joint distribution function parameters, and
n is the number of samples.
The optimal precipitation sub-region division of the plum rain period and the typhoon period were determined by comparative analysis of the relationship between sub-region precipitations and the Taihu Lake water level under different hydrological sub-region clustering situations.
3.3. Flood Risk Management Based on Copula-Based Bayesian Network
Based on a posterior knowledge input, the backward reasoning function of the Bayesian network was utilized to conduct simulation calculations of the water level states in some certain precipitation situations that could occur in future during the plum rain and the typhoon periods [
43,
44].
3.3.1. Setting of Flood Disaster Situations
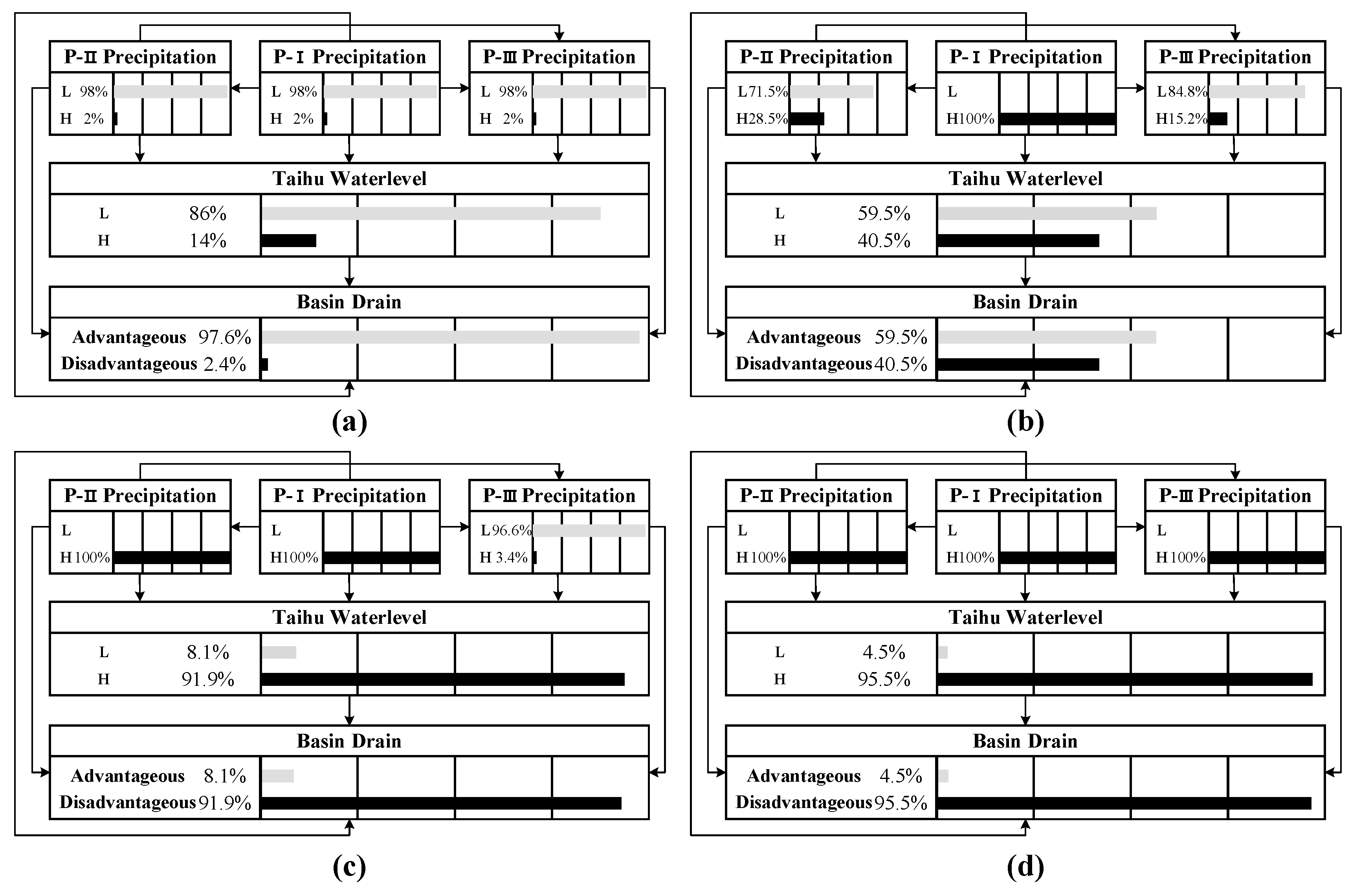
The flood control planning of the Taihu Basin indicates that, the flood control standards of the basin and sub-regions are 100, and 50 years, respectively after 2025. The warning water level of Taihu Lake is 3.8 m and the water level with safety guarantee of the Taihu Lake is 4.65 meters [
37]. The results of the precipitation sub-region division indicated two categories, namely: (1) the spatial distribution of precipitation of the entire basin is assumed homogeneous; therefore, we chose the basin flood control standard, the warning water level, and the water level with safety guarantee of Taihu Lake to design the flood disaster situation; (2) dividing the precipitation of the basin into different regions indicates that the spatial distribution of precipitation is heterogeneous; therefore, the flood control standards of those sub-regions and the warning water level of Taihu Lake should be used to design the flood disaster situation.
3.3.2. Establishment of Bayesian Network
Bayesian networks are probabilistic models that describe the conditional dependencies of a set of random variables by means of directed acyclic graphs (DAG) [
45]. The joint density for Bayesian networks can be expressed as follows: [
46,
47,
48]
where
XPa(Xi) =
x is a shorthand notation for
XPa1(Xi) =
xPa1(Xi), … ,
XPam(Xi) =
xPam(Xi) and
Pa(Xi) indicate the set containing
m parents of node
Xi. For nodes without parents,
Pa(Xi) is an empty set so that
f XiPa(Xi) =
fXi.
Identifying network nodes, developing the Bayesian network, and assigning occurrence probabilities to network nodes are three crucial steps to build a Bayesian network model. They can all be determined from expertise or calculated by machine learning methods. We conducted the three steps as follows:
Step 1: Identifying network nodes. The flood disasters in the Taihu Basin are caused mainly by heavy precipitation and high water levels. Therefore, we selected the water level of Taihu Lake and the precipitation of the Taihu Basin as the network nodes.
Step 2: Developing a network structure. As the terrain of Taihu Basin is unusual (high sides and low middle area) and a number of the flood disasters have occurred (1954, 1983, 1991, 1999), expertise, and not machine learning, was considered more suitable to construct the network.
Step 3: Assigning occurrence probabilities to network nodes. The future flood control standard of the basin is more than 100 years, implying limited observed data. Therefore, instead of expert experience, the copula functions (machine learning method) were used to calculate the occurrence probabilities of network nodes [
46].
This modeling work not only takes advantage of expertise but also avoids the limited knowledge of experts. It improves the efficiency of Bayesian network establishment and can reflect the actual situation with a limited amount of data.
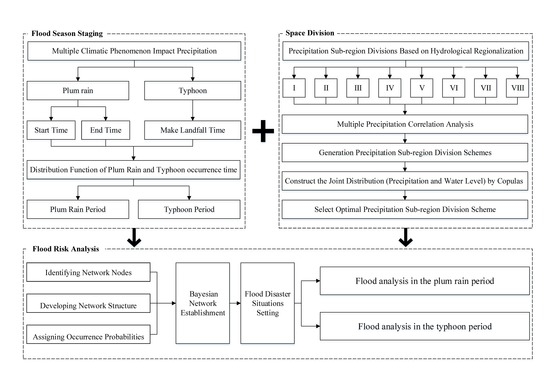
The framework of this study is shown in
Figure 2. The programs of this paper such as copula functions were implemented in R programming language.
6. Conclusions
To analyze the flood disaster risk in the Taihu Basin, we divided the flood season into the plum rain period and the typhoon period, due to different precipitation heterogeneous in different climatic phenomena. Subsequently, we divided the Taihu Basin into precipitation sub-regions by using Copula functions. Finally, based on Bayesian network theory, we proposed a risk management model for flood control in the Taihu Basin to analyze the flood disaster during the different periods. The main conclusions of this study are as follows:
Due to meteorological reasons, the occurrence time of plum rain and typhoon present regularity, resulting in uneven distribution of precipitation during the flood season. Our flood season staging indicated that the plum rain period is from June 24 to July 21 and the typhoon period is from July 22 to September 22.
The spatial heterogeneity of precipitation is different under the influence of the different climatic phenomena. In the plum rain period, the Taihu Basin is divided into three precipitation sub-regions (P-I, P-II, and P-III). In the typhoon period, the Taihu Basin serves as a whole for flood risk analysis.
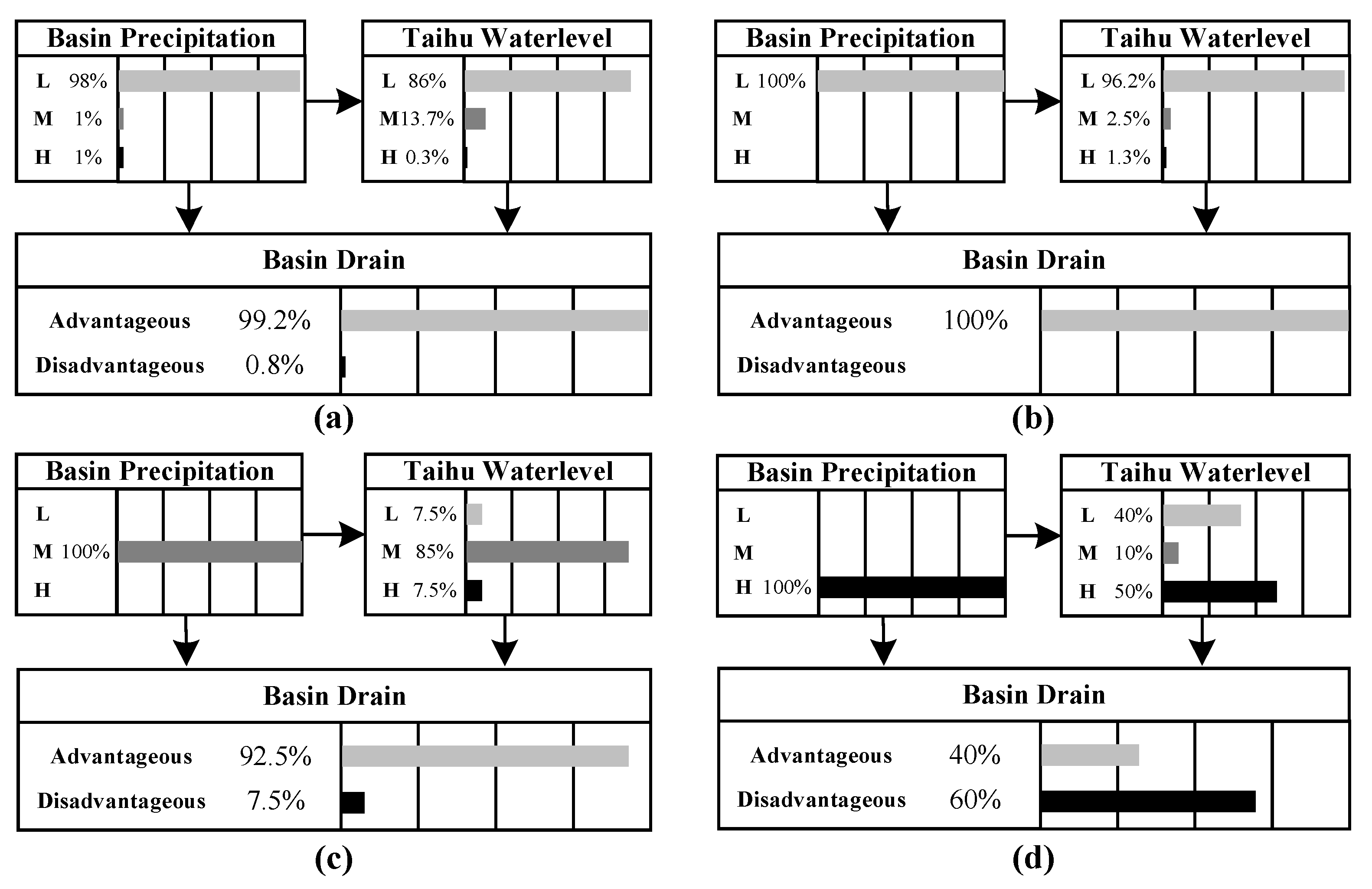
In future, the occurrence probability of adverse drainage situations in the Taihu Basin during the plum rain period and the typhoon period is 2.4%, and 0.8%, respectively. Furthermore, the risk increases rapidly as the Taihu Lake water level rises.
Although the annual precipitation of the Taihu Basin is concentrated in the flood season, the precipitation heterogeneous varies with the differing climatic phenomena. This implies that the risks of flood disaster also differs. Consequently, appropriate emergency plans should be developed to prevent and manage flood disasters occurring in the different periods during the flood season.
In this study, the Taihu Basin was used as a case study to analyze the flood risk of different climatic phenomena. Further research, employing the proposed methodology of our study, could be conducted in the coastal areas of East Asia, such as Taiwan, the Liaodong Peninsula, and Japan that are also affected by typhoons and plum rains. Given the considerable risk of flooding in the coastal areas of East Asia, it is crucial that flood season staging scheduling for flood control be implemented.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}