Identifying Data Dependencies as First Step to Obtain a Proactive Historian: Test Scenario in the Water Industry 4.0



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Industrial Internet of Things (IIoT)
1.2. Interoperability and Historian
1.3. Towards a Proactive Historian Application in the Water Industry
2. Materials and Methods
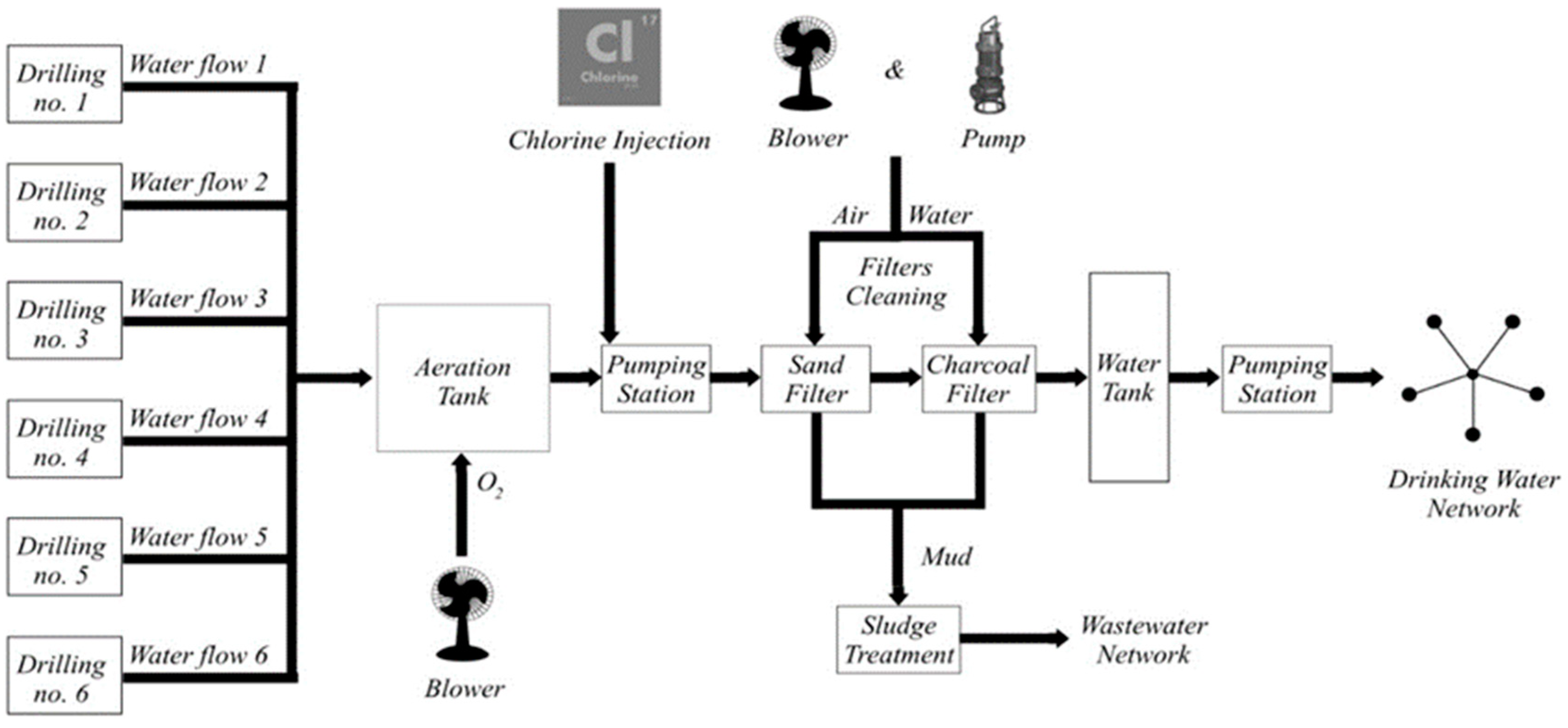
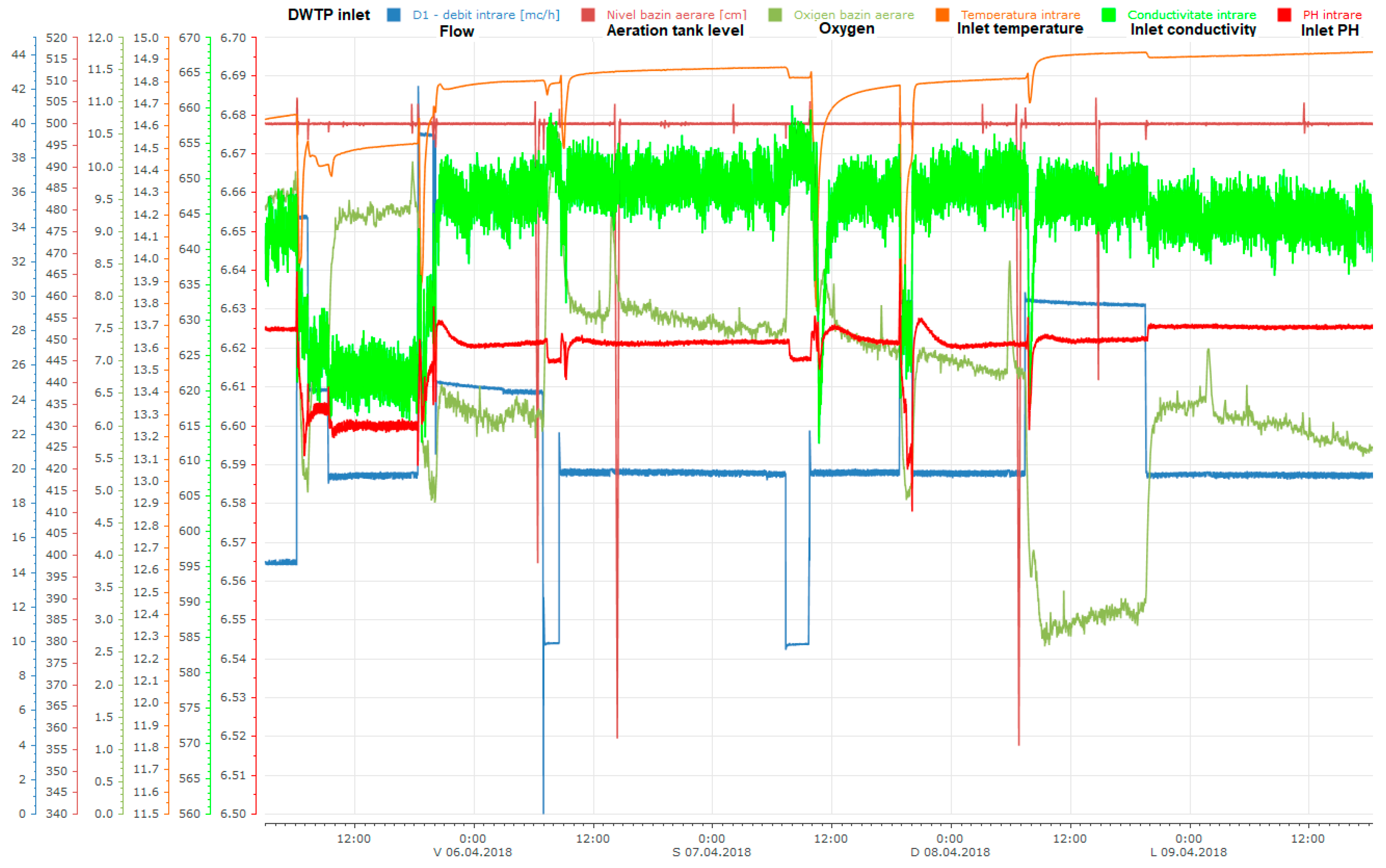
2.1. Drinking Water Treatment Plant (DWTP) Typical Processes
- Growth of water acidity/alkalinity (pH) and lowering conductivity levels are implicitly assured through energy and chlorine consumption (e.g., aeration blowers, chlorine station, and maintenance of charcoal filters).
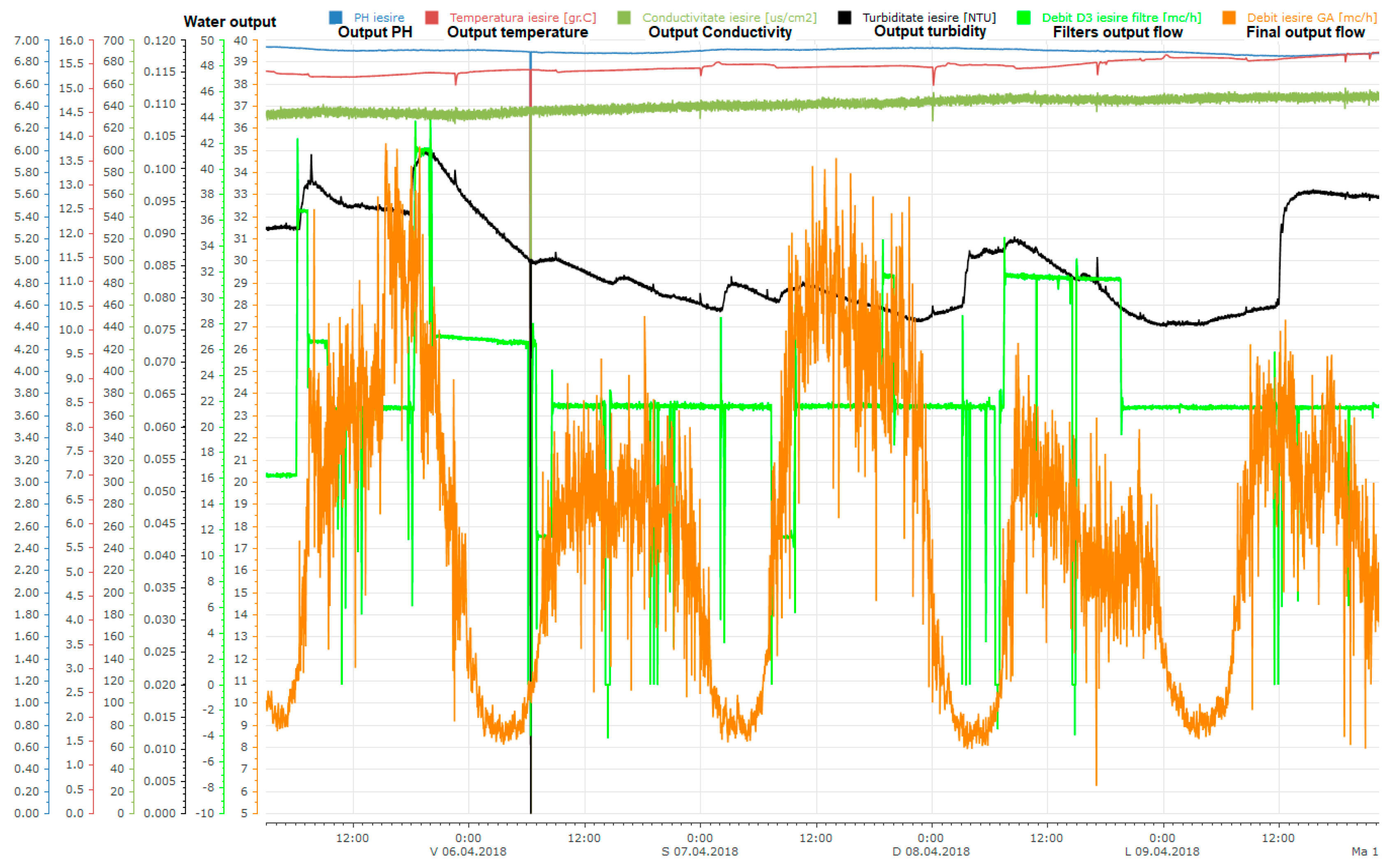
- A high turbidity level implicates possible clogging, respectively high energy consumption and water losses, which result from cleaning the filters with air and water.
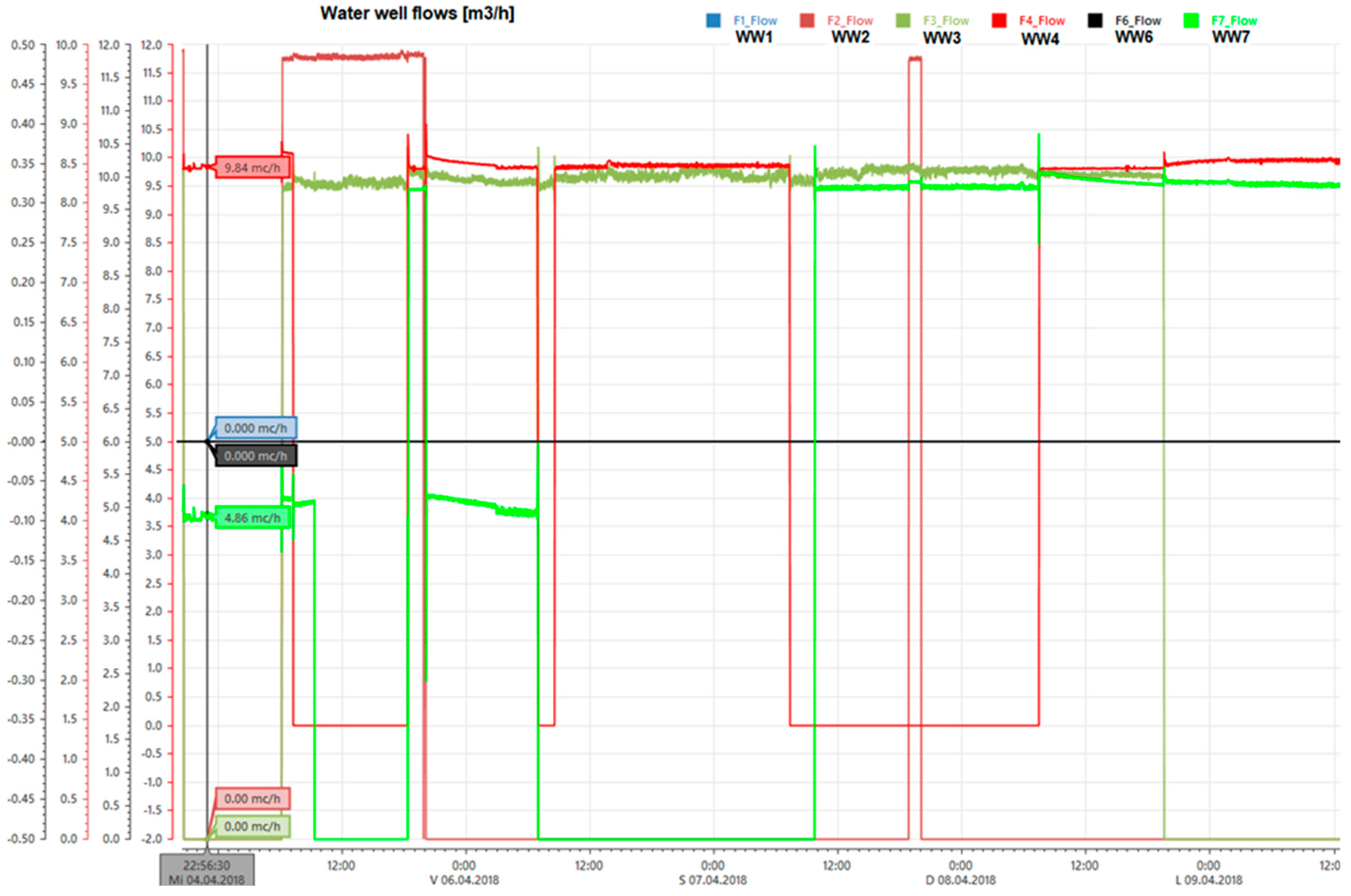
- A level control loop in the water distribution tank complemented with a flow-based control loop, which calls water sources according to the actual flow demand from the water distribution network, assures a very useful, anticipative character of the entire water distribution when high water consumption is identified in critical periods of a day. At night, however, water sources are usually stopped when the upper hysteresis limit is achieved in the water tank. If water losses are present in the water distribution network, then the flow control loop will activate water sources. If the flow setpoints in the flow-based closed-loop control algorithms at the water sources are too high, or are set at fixed values, the water source pumps may start and stop multiple times during the night, causing pump and water source wear out.
- Besides the previously mentioned problem, successive starting and stopping of the water sources causes activation/deactivation of the entire DWTP for short periods. This leads to perturbed filtering and chlorination processes.
- Water sources have different characteristics; therefore, some of them may provide higher flow values and some better water quality. Monitoring residual chlorine, blower functioning times, and filter washing cycles over longer periods of time, together with chosen water sources that are currently functioning (provided water flow values), water source quality indicators can be identified. Using suitable water sources, specific consumptions can be reduced (flow distribution).
- Water source quality indicators change over time.
- The water level in the water distribution tank cannot be kept inside two hysteresis limits because water consumption variation in the distribution network perturbs the level control algorithm. Consequently, inconsistencies of water reserves in the tank may be identified including higher energy consumption and possible water treatment process disturbances.
- Proper equipment functioning hours and number of starts is essential to consider because maintenance/replacement is expensive.
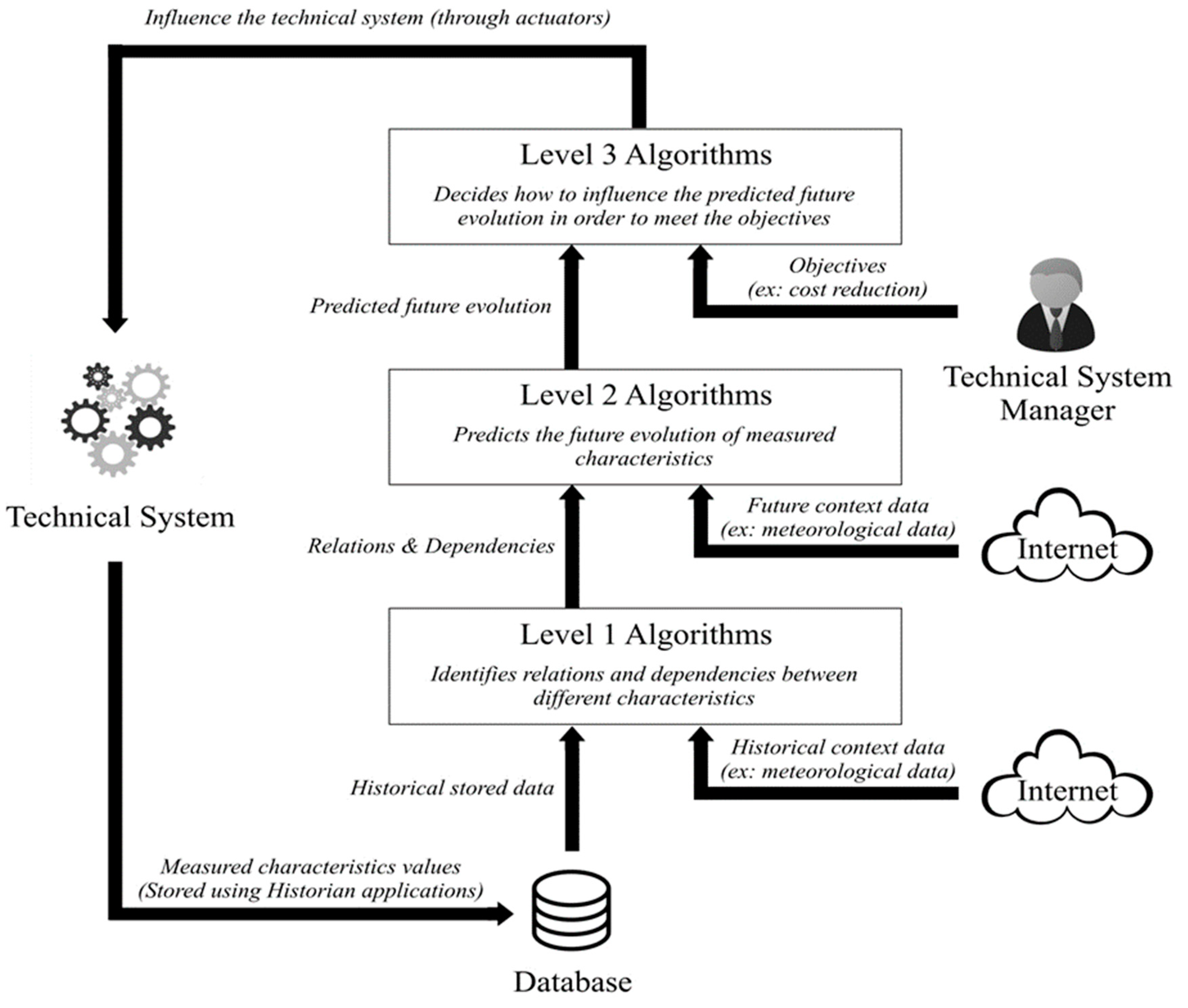
2.2. The Reference Architecture
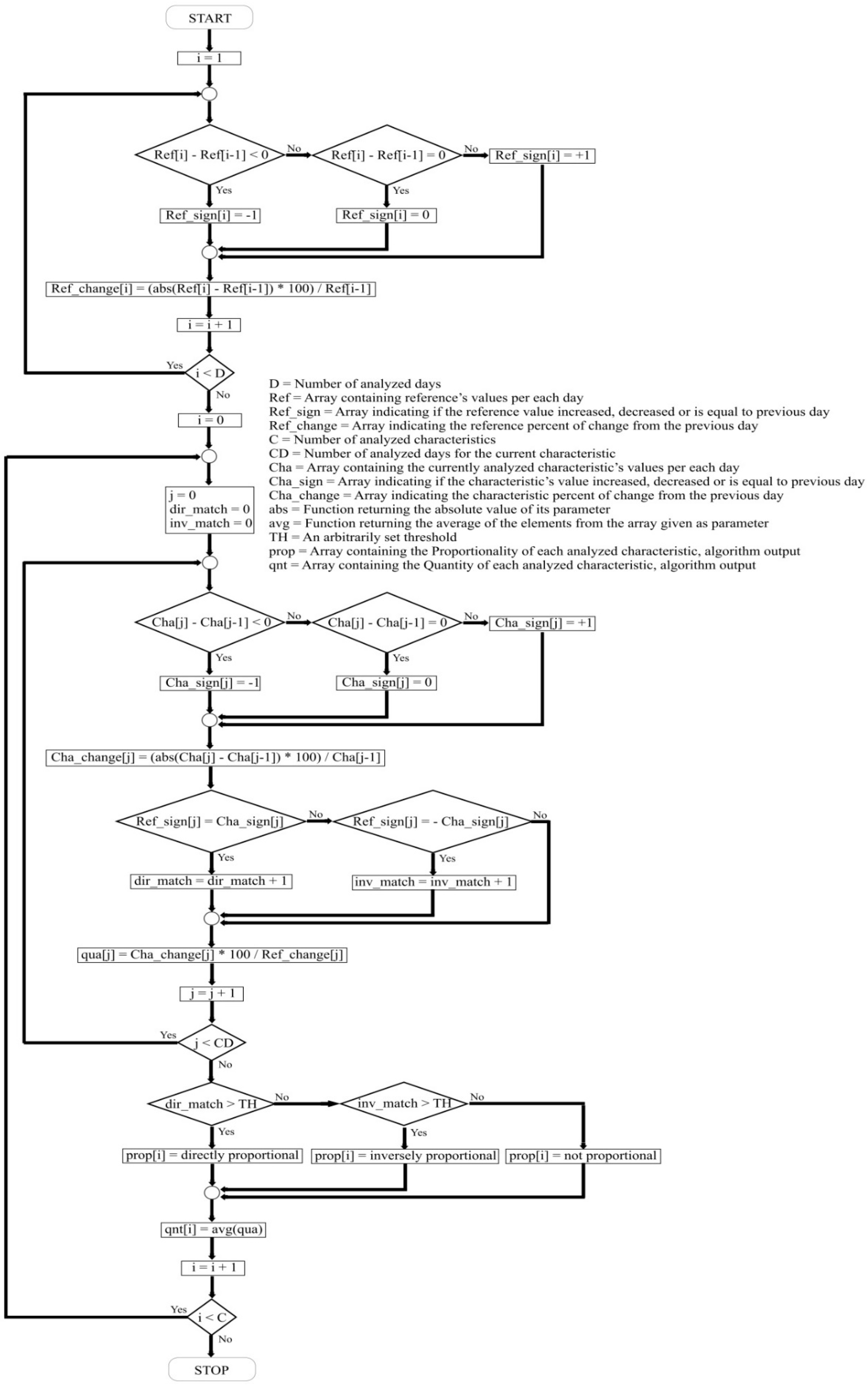
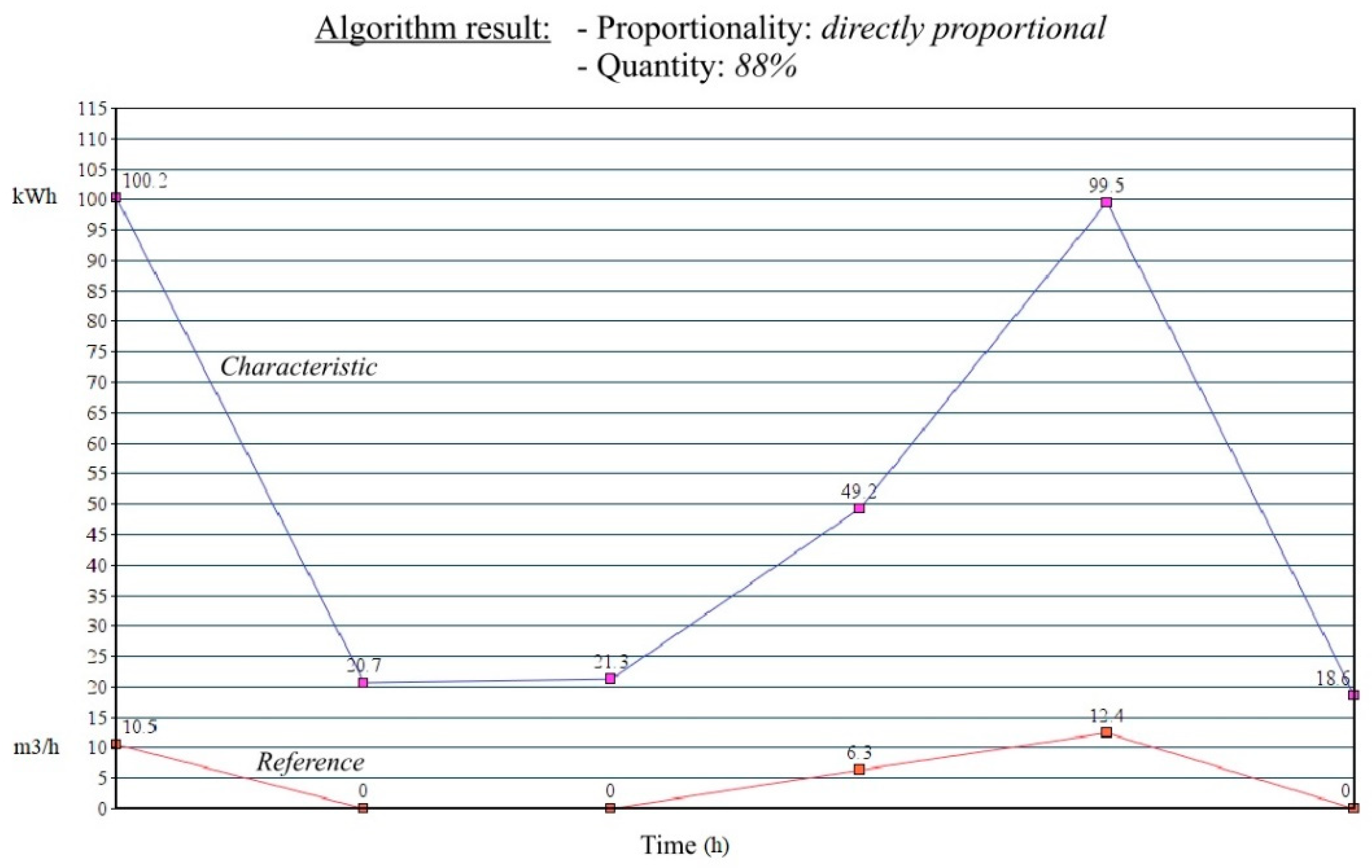
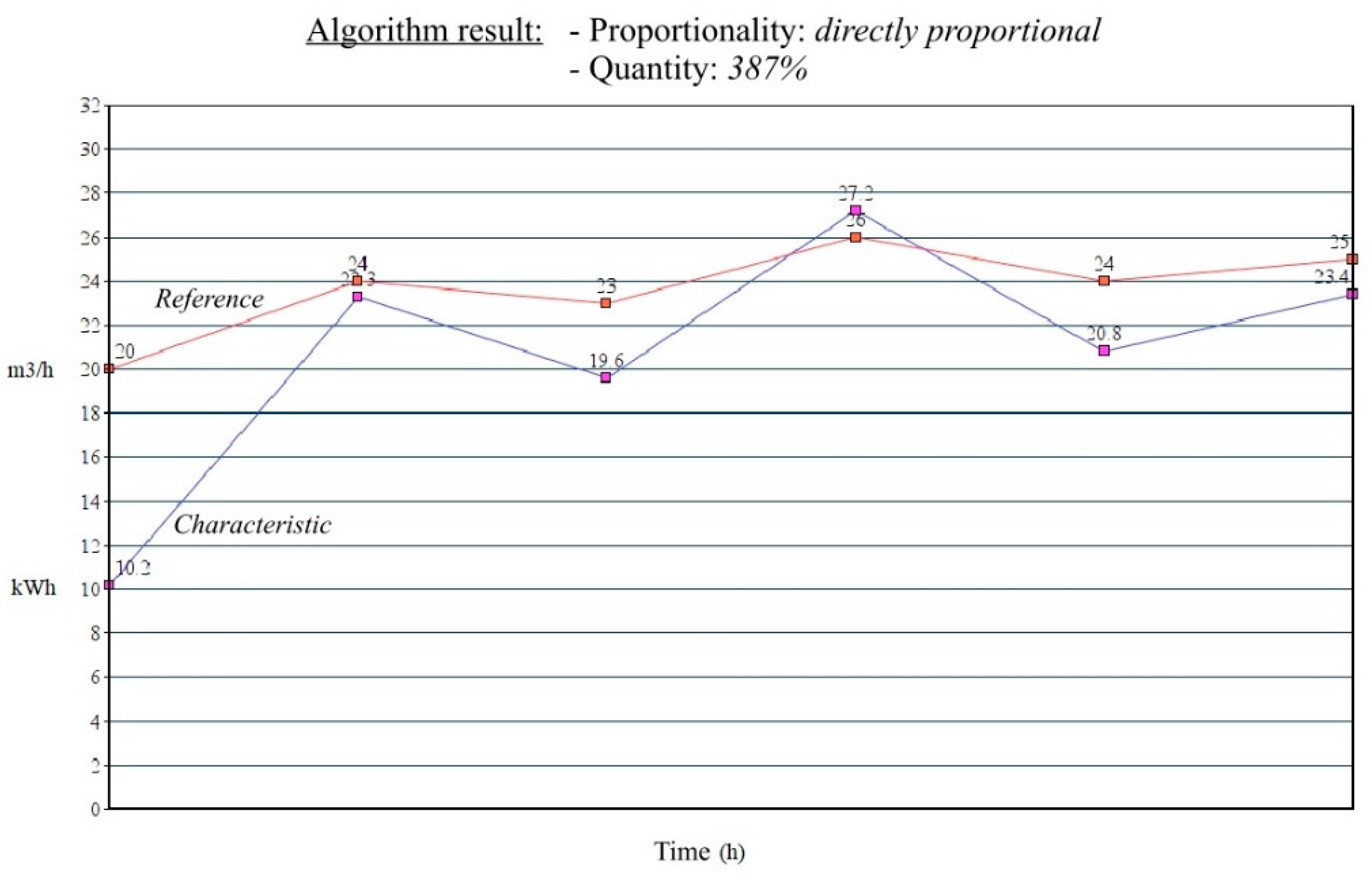
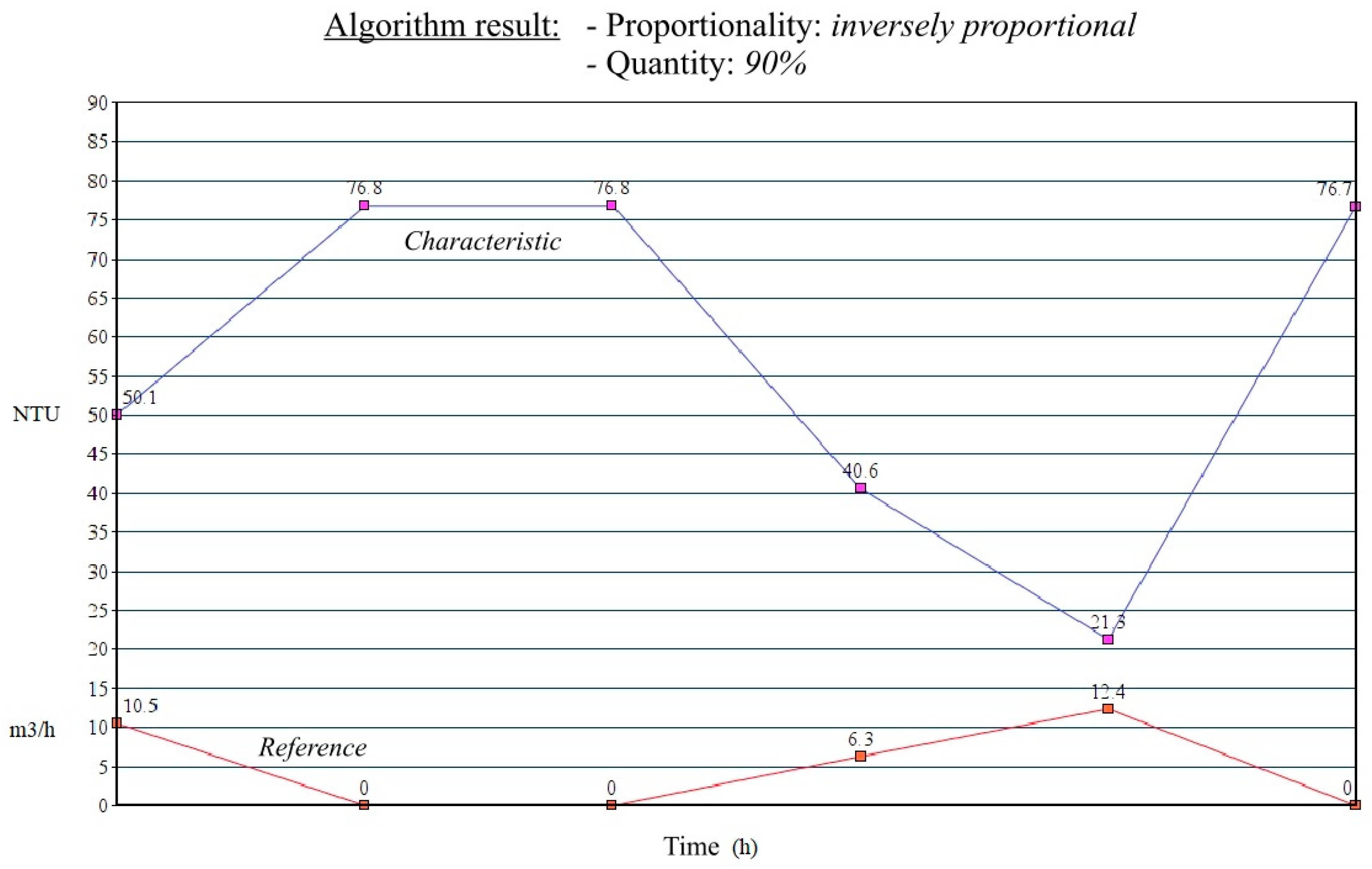
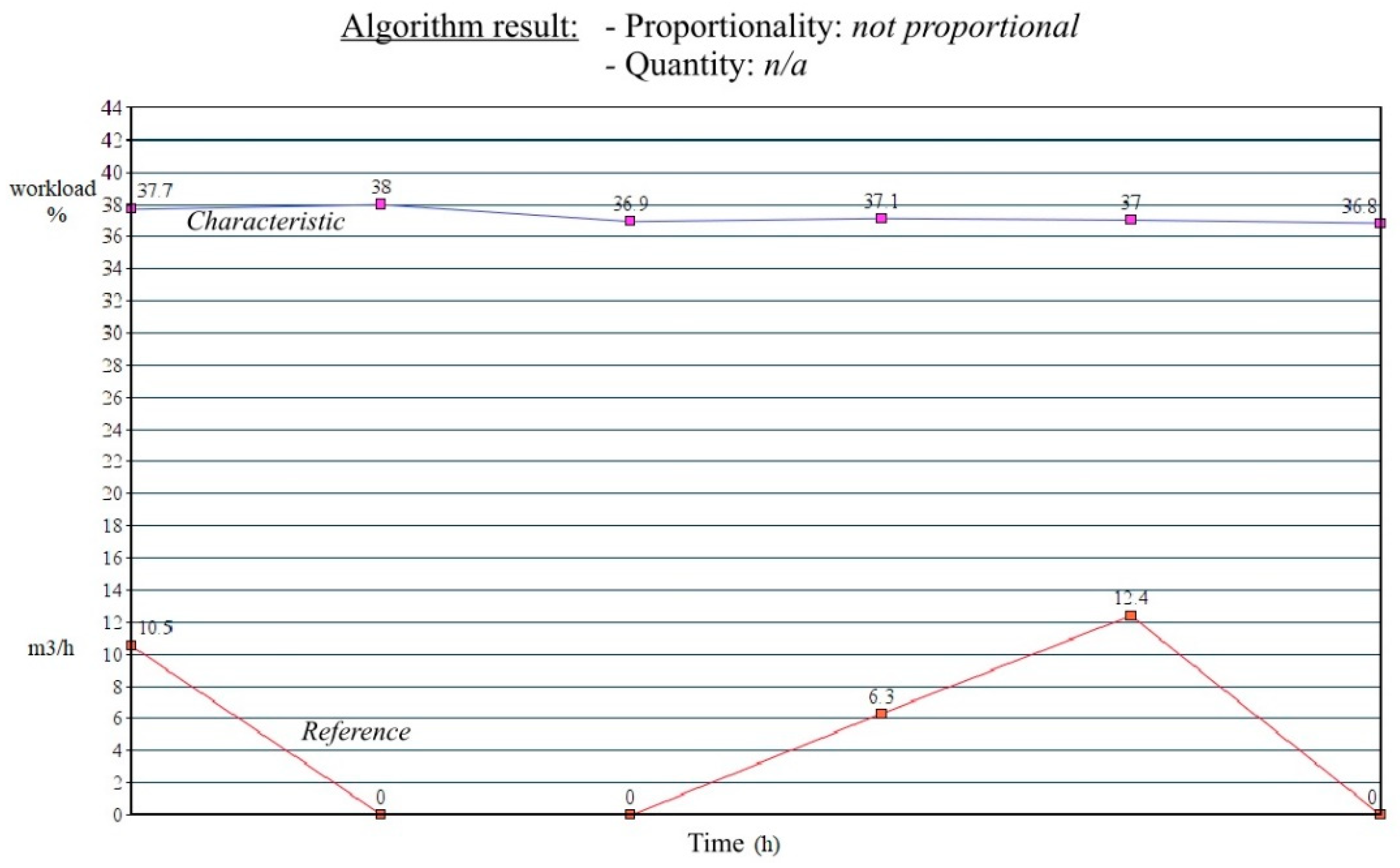
2.3. The Implemented Solution—Algorithm Description
- Quantity information is 100%—indicates a 1:1 ratio between the analyzed characteristic and the reference, meaning that if the reference value changes by 20%, then the analyzed characteristic value also changes by 20%.
- Quantity information is 50%–150%—if the reference value changes by 20%, then the analyzed characteristic value changes by 10%–30%.
3. Results
3.1. Water Industry Application
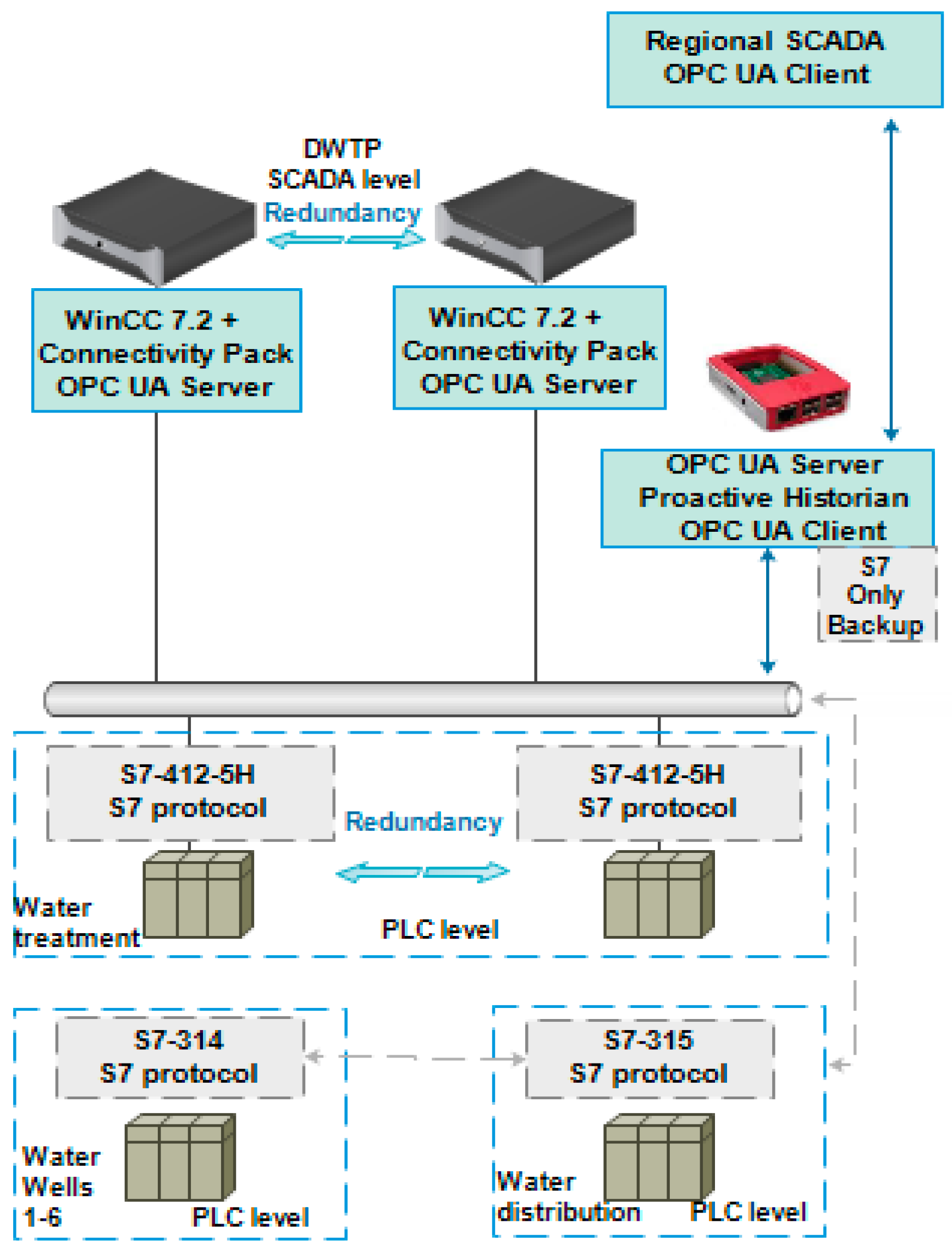
- Water wells S7-314 type PLCs were all integrated in the S7-315 PLC, which was responsible for water distribution using the S7 protocol. Level- and flow-based control loops that were responsible for automatic water requests from the wells were implemented in the S7-315. Local flow-based control loops were implemented at each S7-314 PLC.
- The entire water treatment process was guided by two redundant S7-412-5H type PLCs.
- The S7-315 PLC responsible for water distribution and the redundant PLCs responsible for the water treatment process were integrated in the WinCC 7.2-based SCADA system, which consisted of two redundant servers and two clients. Since connectivity packs were configured at each server, OPC UA servers were available and assured interoperability.
- The solution was implemented on a Raspberry Pi 3 B (because of its reduced physical dimensions and the availability of industrial cases, which makes it suitable for industrial environments) using the Node-RED environment and an embedded Java application. The OPC UA client (several nodes were used: OpcUa-Browser, OpcUa-Client, TCP, etc.) was used to interface the entire system for data gathering and for noninvasive interventions over the local process. Having a complete local redundancy for the water treatment control structures, the Historian connection to the SCADA system was enough, but the S7 node was prepared for backup interfacing in case of a total SCADA failure. S7 protocol allowed for the current study to interface all PLCs. Details about the already developed Historian application can be found in [22]. This application was used as a starting point, to which the data dependencies identification algorithm was added.
- An OPC UA server (Node-RED flow was created to define the OPC UA folder/tag structuring inside the secured endpoint in order to constantly populate the address space with values and to propagate an eventual tag change) was implemented to assure higher-level interoperability of the Historian.
3.2. Test Scenario
3.3. One Step Further to Improve a Drinking Water Facility
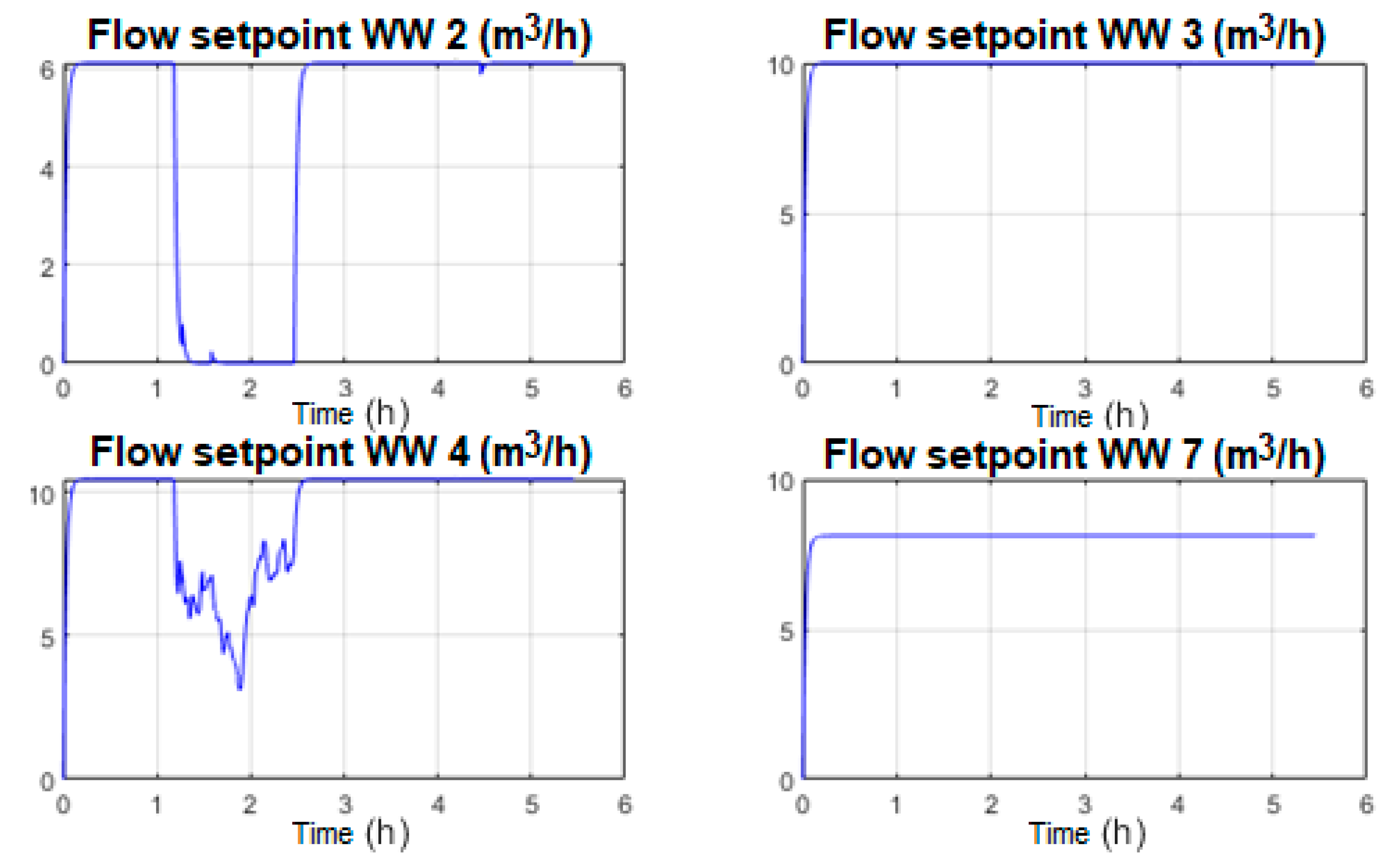
- After analyzing the accumulated data using the presented solution, patterns were identified, and quality indicators for the water sources were conceived and set.
- Other research activity results (not published yet) were used to convert the water source quality indicators and the functioning hours into priorities that influenced the requested amount of water from each source in order to optimize water treatment. According to the determined priorities for the water sources, flow references were calculated and considered for each well.
- DWTP output water quality indicators that were kept inside limits: pH, conductivity, and turbidity.
- Overall energy consumption was the cost reduction objective.
- Chlorine consumption was kept under a limit.
- Filters were washed no more than 1 cycle/filter/day.
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gilchrist, A. Industry 4.0: The Industrial Internet of Things; Springer: Berkeley, CA, USA, 2016. [Google Scholar]
- Jeschke, S.; Brecher, C.; Meisen, T.; Ozdemir, D.; Eschert, T. Industrial Internet of Things and Cyber Manufacturing Systems. In Industrial Internet of Things; Jensche, S., Brecher, C., Song, H., Rawat, D.B., Eds.; Springer: Boston, MA, USA, 2016; pp. 3–19. [Google Scholar]
- Vandikas, K.; Tsiatsis, V. Performance evaluation of an IoT platform. In Proceedings of the IEEE Eighth International Conference on Next Generation Mobile Apps, Services and Technologies (NGMAST), Oxford, UK, 10–12 September 2014. [Google Scholar]
- Khan, W.A.; Wisniewski, L.; Lang, D.; Jasperneite, J. Analysis of the requirements for offering industry 4.0 applications as a cloud service. In Proceedings of the 26th IEEE International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017. [Google Scholar]
- Huh, J.H. PLC-based design of monitoring system for ICT-integrated vertical fish farm. Human-centric Comput. Inf. Sci. 2017, 7, 20. [Google Scholar] [CrossRef]
- Lee, H.G.; Huh, J.H. A Cost-Effective Redundant Digital Excitation Control System and Test Bed Experiment for Safe Power Supply for Process Industry 4.0. Processes 2018, 6, 85. [Google Scholar] [CrossRef]
- Wang, S.; Wan, J.; Zhang, D.; Li, D.; Zhang, C. Towards smart factory for industry 4.0: a self-organized multi-agent system with big data based feedback and coordination. Comput. Networks J. 2016, 101, 158–168. [Google Scholar] [CrossRef]
- Ożadowicz, A.; Grela, J.; Wisniewski, L.; Smok, K. Application of the Internet of Things (IoT) technology in consumer electronics–case study. In Proceedings of the IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Torino, Italy, 4–7 September 2018; pp. 1037–1042. [Google Scholar]
- Borgia, E. The Internet of Things vision: Key features, applications and open issues. Comput. Commun. 2014, 54, 1–31. [Google Scholar] [CrossRef]
- Kim, H.K.; So, W.Y.; Je, S.M. A big data framework for network security of small and medium enterprises for future computing. J. Supercomputing 2019, 75, 3334–3367. [Google Scholar] [CrossRef]
- Huh, J.H.; Seo, K. An indoor location-based control system using bluetooth beacons for IoT systems. Sens. J. 2017, 17, 2917. [Google Scholar] [CrossRef]
- Fysarakis, K.; Askoxylakis, I.; Soultatos, O.; Papaefstathiou, I.; Manifavas, C.; Katos, V. Which IoT Protocol? Comparing Standardized Approaches over a Common M2M Application. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- Haskamp, H.; Meyer, M.; Mollmann, R.; Orth, F.; Colombo, A. Benchmarking of existing OPC UA implementations for Industry 4.0-compliant digitalization solutions. In Proceedings of the 15th IEEE International Conference on Industrial Informatics (INDIN), Emden, Germany, 24–26 July 2017; pp. 589–594. [Google Scholar]
- Moraes, E.; Lepikson, H.; Konstantinov, S. Improving connectivity for runtime simulation of automation systems via OPC UA. In Proceedings of the 13th IEEE International Conference on Industrial Informatics (INDIN), Cambridge, UK, 22–24 July 2015. [Google Scholar]
- Dai, W.; Vyatkin, V.; Christensen, J.H.; Dubinin, V.N. Bridging Service-Oriented Architecture and IEC 61499 for Flexibility and Interoperability. IEEE Trans. Ind. Inf. 2015, 11, 771–781. [Google Scholar] [CrossRef]
- Cavalieri, S.; Regalbuto, A. Integration of IEC 61850 SCL and OPC UA to improve interoperability in Smart Grid environment. Comput. Stand. Interfaces 2016, 47, 77–99. [Google Scholar] [CrossRef]
- Derhamy, H.; Ronnholm, J.; Delsing, J.; Eliasson, J.; van Deventer, J. Protocol interoperability of OPC UA in Service Oriented Architectures. In Proceedings of the 15th IEEE International Conference on Industrial Informatics (INDIN), Emden, Germany, 24–26 July 2017. [Google Scholar]
- Muller, M.; Wings, E.; Bergmann, L. Developing Open Source Cyber-Physical Systems for Service-Oriented Architectures using OPC UA. In Proceedings of the 15th IEEE International Conference on Industrial Informatics (INDIN), Emden, Germany, 24–26 July 2017. [Google Scholar]
- Leszczynski, I. OPC UA App Development for Android. Master’ Thesis, Aalto University, Helsinki, Finland, 2015. [Google Scholar]
- Korodi, A.; Silea, I. Achieving Interoperability Using Low-Cost Middleware OPC UA Wrapping Structure. Case Study in the Water Industry. In Proceedings of the 15th IEEE International Conference on Industrial Informatics (INDIN), Emden, Germany, 24–26 July 2017; pp. 1223–1228. [Google Scholar]
- Toc, S.I.; Korodi, A. Modbus-OPC UA Wrapper using Node-RED and IoT-2040 with application in the water industry. In Proceedings of the 16th IEEE International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018. [Google Scholar]
- Veichtlbauer, A.; Ortmayer, M.; Heistracher, T. OPC UA Integration for Field Devices. In Proceedings of the 15th IEEE International Conference on Industrial Informatics (INDIN), Emden, Germany, 24–26 July 2017; pp. 419–424. [Google Scholar]
- Seilonen, I.; Tuovinen, T. Aggregating OPC UA servers for monitoring manufacturing systems and mobile work machines. In Proceedings of the IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016. [Google Scholar]
- Korodi, A.; Radu, M.A.; Crisan, R. Non-Invasive Control Solution inside Higher-Level OPC UA based Wrapper for Optimizing Groups of Wastewater Systems. In Proceedings of the IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Torino, Italy, 4–7 September 2018; pp. 597–604. [Google Scholar]
- Crisan, R.; Korodi, A. Noninvasive control solution for energy efficiency in wastewater treatment plants. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018; pp. 1604–1609. [Google Scholar]
- Gray, A.D.L.; Pisica, I.; Taylor, G.A.; Whitehurst, L. A Standardised Modular Approach for Site SCADA, Applications Within a Water Utility. IEEE Access 2017, 5, 17177–17187. [Google Scholar] [CrossRef]
- Mazur, D.C.; Entzminger, R.A.; Kay, J.A. Enhancing Traditional Process SCADA and Historians for Industrial and Commercial Power Systems with Energy (Via IEC 61850). IEEE Trans. Ind. Appl. 2016, 52, 76–82. [Google Scholar] [CrossRef]
- Nicolae, A.; Korodi, A. Node-Red and OPC UA Based Lightweight and Low-Cost Historian with Application in the Water Industry. In Proceedings of the IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018. [Google Scholar]
- McGreevy, R.J.; Sadowski, D.A.; Herbst, R.J.; Hartman, J.R. Historian Module for Use in an Industrial Automation Controller. U.S. Patent 762,738,5B2, 1 December 2009. [Google Scholar]
- Yan, Q.; Wang, Y. A Kind of Efficient Data Archiving Method for Historical Sensor Data. In Proceedings of the 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016. [Google Scholar]
- Dwivedi, A.; Pant, R.P.; Pandey, S.; Kumar, K. Internet of Things’ (IoT’s) Impact on Decision Oriented Applications of Big Data Sentiment Analysis. In Proceedings of the 3rd International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Bhimtal, India, 24 February 2018. [Google Scholar]
- Kaur, H.; Kushwaha, A.S. A Review on Integration of Big Data and IoT. In Proceedings of the 4th International Conference on Computational Sciences (ICCS), Wuxi, China, 11–13 June 2018. [Google Scholar]
- Node-RED. Available online: https://nodered.org/ (accessed on 21 May 2019).
- Stang, S.; Wang, H.Y.; Gardner, K.H.; Mo, W.W. Influences of water quality and climate on the water-energy nexus: A spatial comparison of two water systems. J. Environ. Manag. 2018, 218, 613–621. [Google Scholar] [CrossRef] [PubMed]
- Rosinska, A.; Dabrowska, L. Selection of Coagulants for the Removal of Chosen PAH from Drinking Water. Water 2018, 10, 7. [Google Scholar] [CrossRef]
- Shan, W.; Cai, S.; Liu, C. A New Comprehensive Evaluation Method for Water Quality: Improved Fuzzy Support Vector Machine. Water 2018, 10, 1303. [Google Scholar] [CrossRef]
- Tsagarakis, K.P. Operating Cost Coverage vs. Water Utility Complaints. Water 2018, 10, 27. [Google Scholar] [CrossRef]
- Wu, W.; Simpson, A.R.; Maier, H.R.; Marchi, A. Incorporation of variable-speed pumping in multiobjective genetic algorithm optimization of the design of water transmission systems. J. Water Resour. Plan. Manag. ASCE 2012, 138, 543–552. [Google Scholar] [CrossRef]
- Mala-Jetmarova, H.; Sultanova, N.; Savic, D. Lost in Optimisation of Water Distribution Systems? A Literature Review of System Design. Water 2018, 10, 307. [Google Scholar] [CrossRef]
- Ciolofan, S.; Militaru, G.; Draghia, A.; Drobot, R.; Dragoicea, M. Optimization of Water Reservoir Operation to Minimize the Economic Losses Caused by Pollution. IEEE Access 2018, 6, 67562–67580. [Google Scholar] [CrossRef]
- Diaz-Perez, F.J.; Pino-Otin, M.R.; Mouhaffel, A.G.; Martín, R.D.; Chinarro, D. Energy and Water Consumption and Carbon Footprint in Tourist Pools Supplied by Desalination Plants: Case Study, the Canary Islands. IEEE Access 2018, 6, 1727–11737. [Google Scholar] [CrossRef]
- Wang, D.S. Raw water quality assessment for the treatment of drinking water. Environ. Earth Sci. 2016, 75, 19. [Google Scholar] [CrossRef]
- Chowdhury, S. Water quality degradation in the sources of drinking water: an assessment based on 18 years of data from 441 water supply systems. Environ. Monit. Assess. 2018, 190, 7. [Google Scholar] [CrossRef]
- Delpla, I.; Florea, M.; Rodriguez, M.J. Drinking Water Source Monitoring Using Early Warning Systems Based on Data Mining Techniques. Water Resour. Manag. 2019, 33, 129–140. [Google Scholar] [CrossRef]
- Huang, P.; Zhu, N.; Hou, D.; Chen, J.; Xiao, Y.; Yu, J.; Zhang, H. Real-Time Burst Detection in District Metering Areas in Water Distribution System Based on Patterns of Water Demand with Supervised Learning. Water 2018, 10, 1765. [Google Scholar] [CrossRef]
- Cheng, W.; Fang, H.; Xu, G.; Chen, M. Using SCADA to Detect and Locate Bursts in a Long-Distance Water Pipeline. Water 2018, 10, 1727. [Google Scholar] [CrossRef]
- Osman, M.; Ab-Mahfouz, A.; Page, P. A Survey on Data Imputation Techniques: Water Distribution System as a Use Case. IEEE Access 2018, 6, 63279–63291. [Google Scholar] [CrossRef]
- Kuriqi, A.; Ardiclioglu, M. Investigation of hydraulic regime at middle part of the Loire River in context of floods and low flow events. Pollack Periodica 2018, 13, 145–156. [Google Scholar] [CrossRef]
- Angelakis, A.N.; Zheng, X.Y. Evolution of Water Supply, Sanitation, Wastewater, and Stormwater Technologies Globally. Water 2015, 7, 455–463. [Google Scholar] [CrossRef]
- Kuriqi, A. Assessment and quantification of meteorological data for implementation of weather radar in mountainous regions. MAUSAM 2016, 67, 789–802. [Google Scholar]
- Kuriqi, A.; Ardiclioglu, M.; Muceku, Y. Investigation of seepage effect on river dike’s stability under steady state and transient conditions. Pollack Periodica 2016, 11, 87–104. [Google Scholar] [CrossRef]
- Sooley, B.; Little, C. Reinventing the Role of the SCADA Historian. In Proceedings of the ISA Water/Wasterwater and Automatic Controls Symposium (WWAC), Orlando, FL, USA, 6–8 August 2013. [Google Scholar]
- Chardin, B.; Lacombe, J.M.; Petit, J. M Data Historians in the Data Management Landscape. In Proceedings of the 4th TPC Technology Conference (TPCTC), Istanbul, Turkey, 27 August 2012. [Google Scholar]
- Lee, J.; Bagheri, B.; Kao, H.A. A Cyber-Physical Systems architecture for Industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]














© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nicolae, A.; Korodi, A.; Silea, I. Identifying Data Dependencies as First Step to Obtain a Proactive Historian: Test Scenario in the Water Industry 4.0. Water 2019, 11, 1144. https://doi.org/10.3390/w11061144
Nicolae A, Korodi A, Silea I. Identifying Data Dependencies as First Step to Obtain a Proactive Historian: Test Scenario in the Water Industry 4.0. Water. 2019; 11(6):1144. https://doi.org/10.3390/w11061144
Chicago/Turabian StyleNicolae, Andrei, Adrian Korodi, and Ioan Silea. 2019. "Identifying Data Dependencies as First Step to Obtain a Proactive Historian: Test Scenario in the Water Industry 4.0" Water 11, no. 6: 1144. https://doi.org/10.3390/w11061144
APA StyleNicolae, A., Korodi, A., & Silea, I. (2019). Identifying Data Dependencies as First Step to Obtain a Proactive Historian: Test Scenario in the Water Industry 4.0. Water, 11(6), 1144. https://doi.org/10.3390/w11061144