
Source Term Estimation for Puff Releases Using Machine Learning: A Case Study



Abstract
1. Introduction
2. Methods
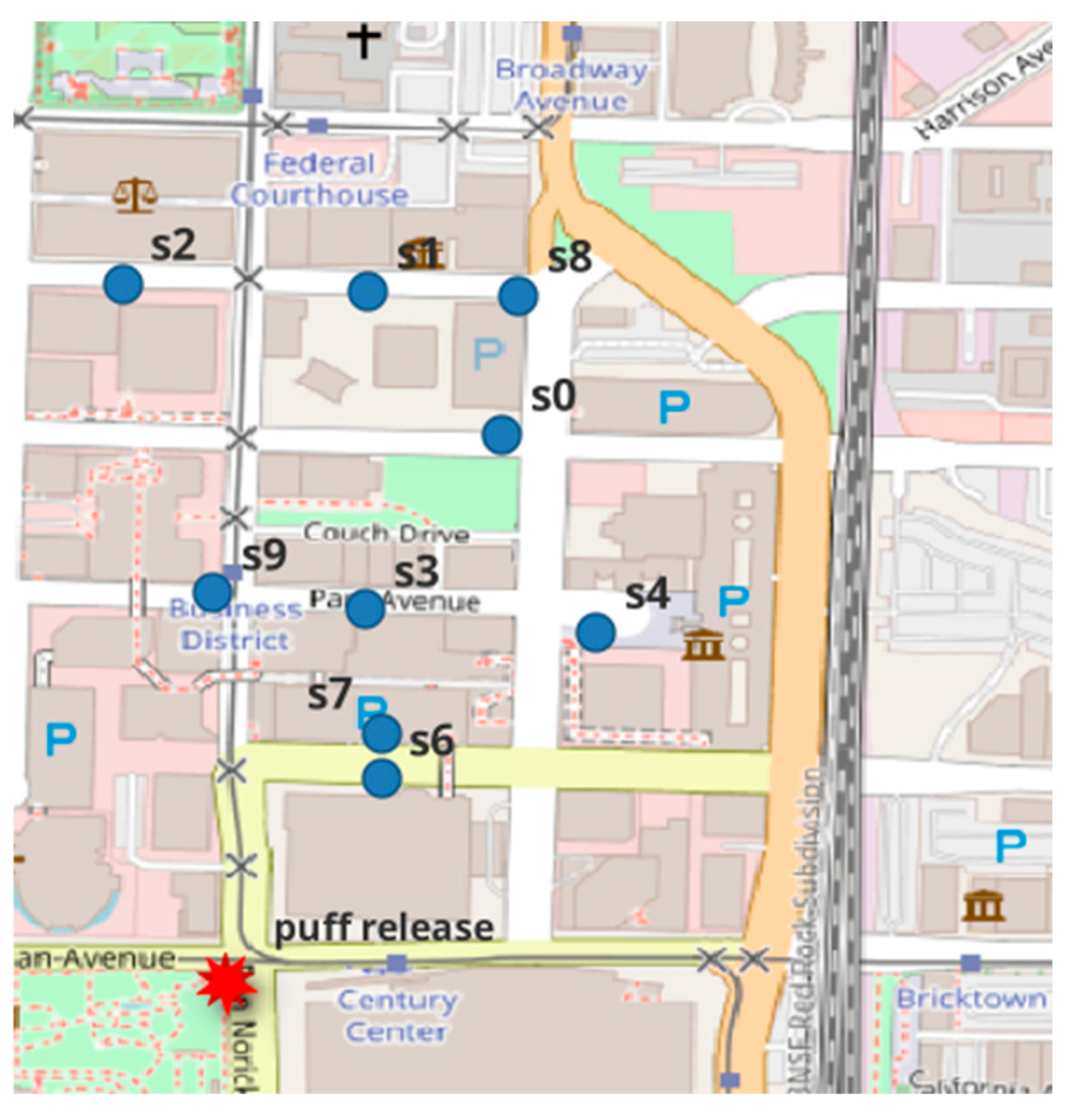
2.1. The Problem and the Case Study
2.2. The Methodology
2.2.1. The ML Algorithm
2.2.2. The Selected Variables
The Target
The Input Variables
3. The Case Study Application and Results
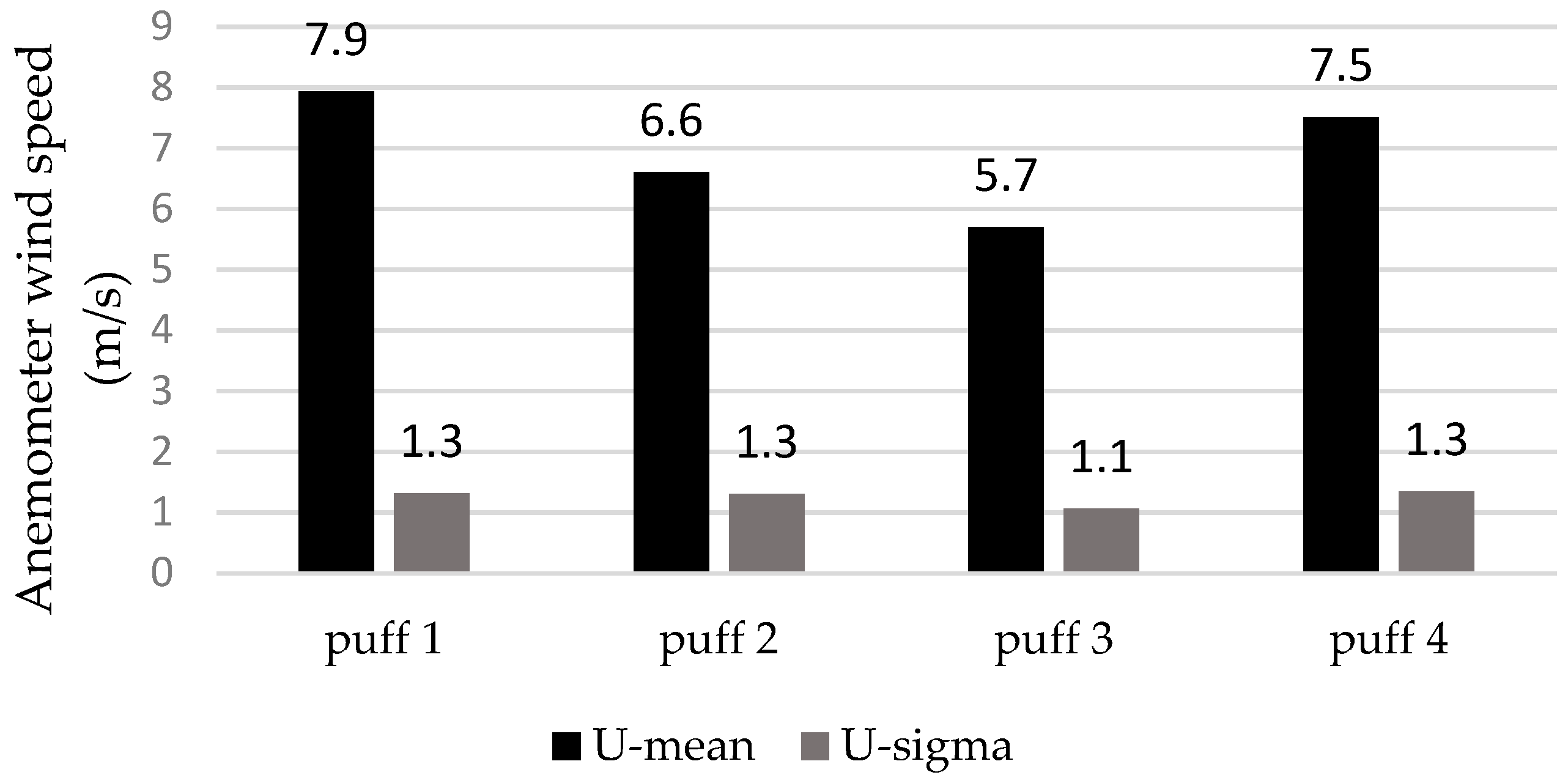
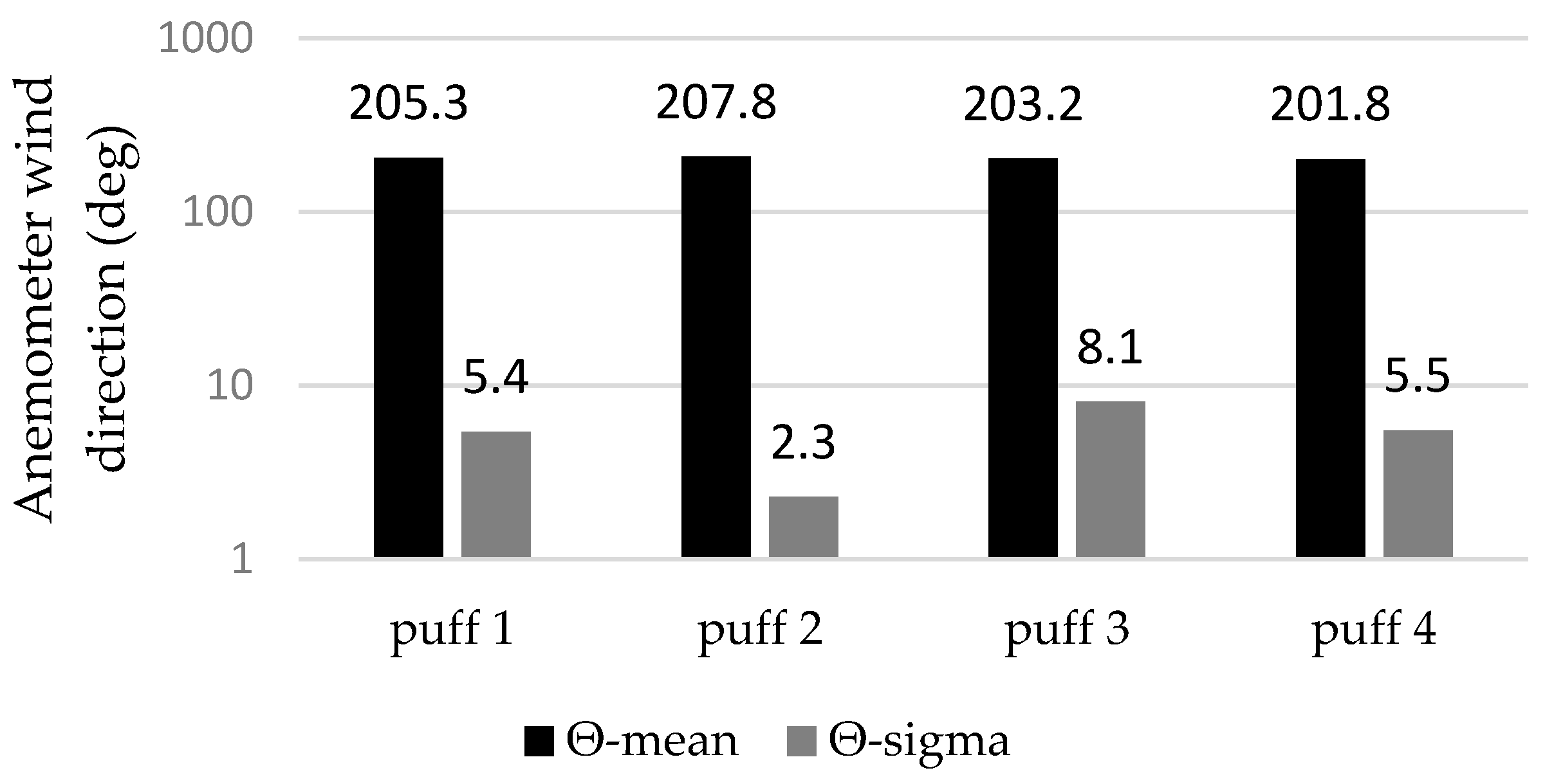
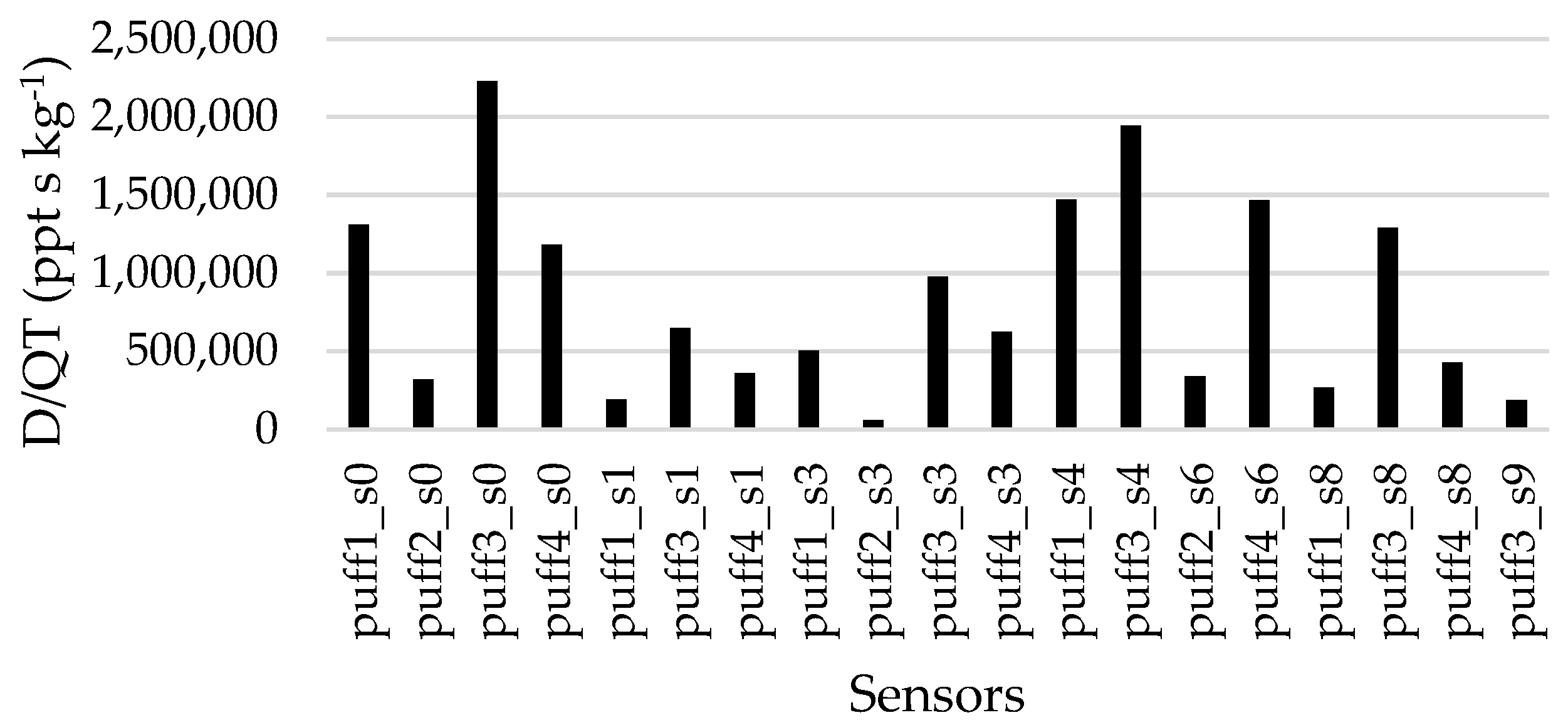
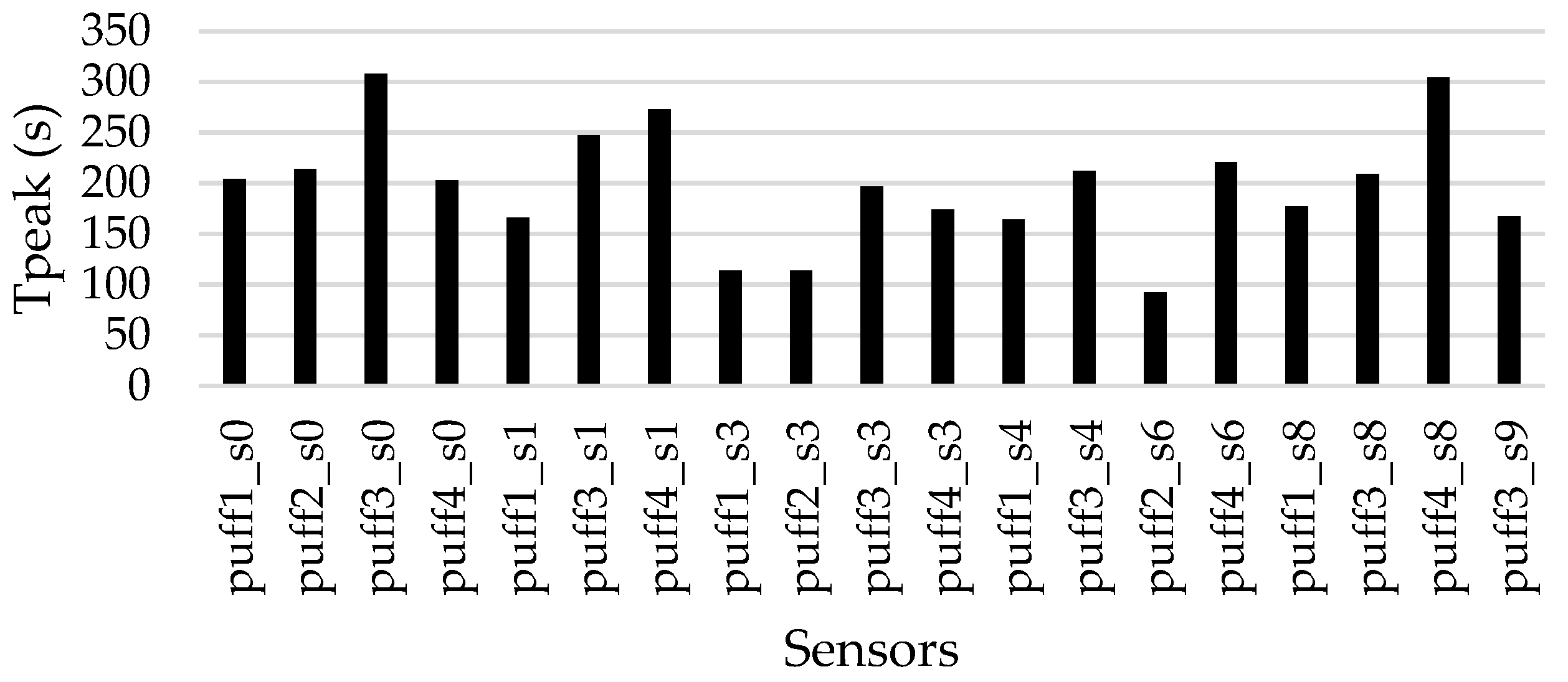
3.1. The Variables
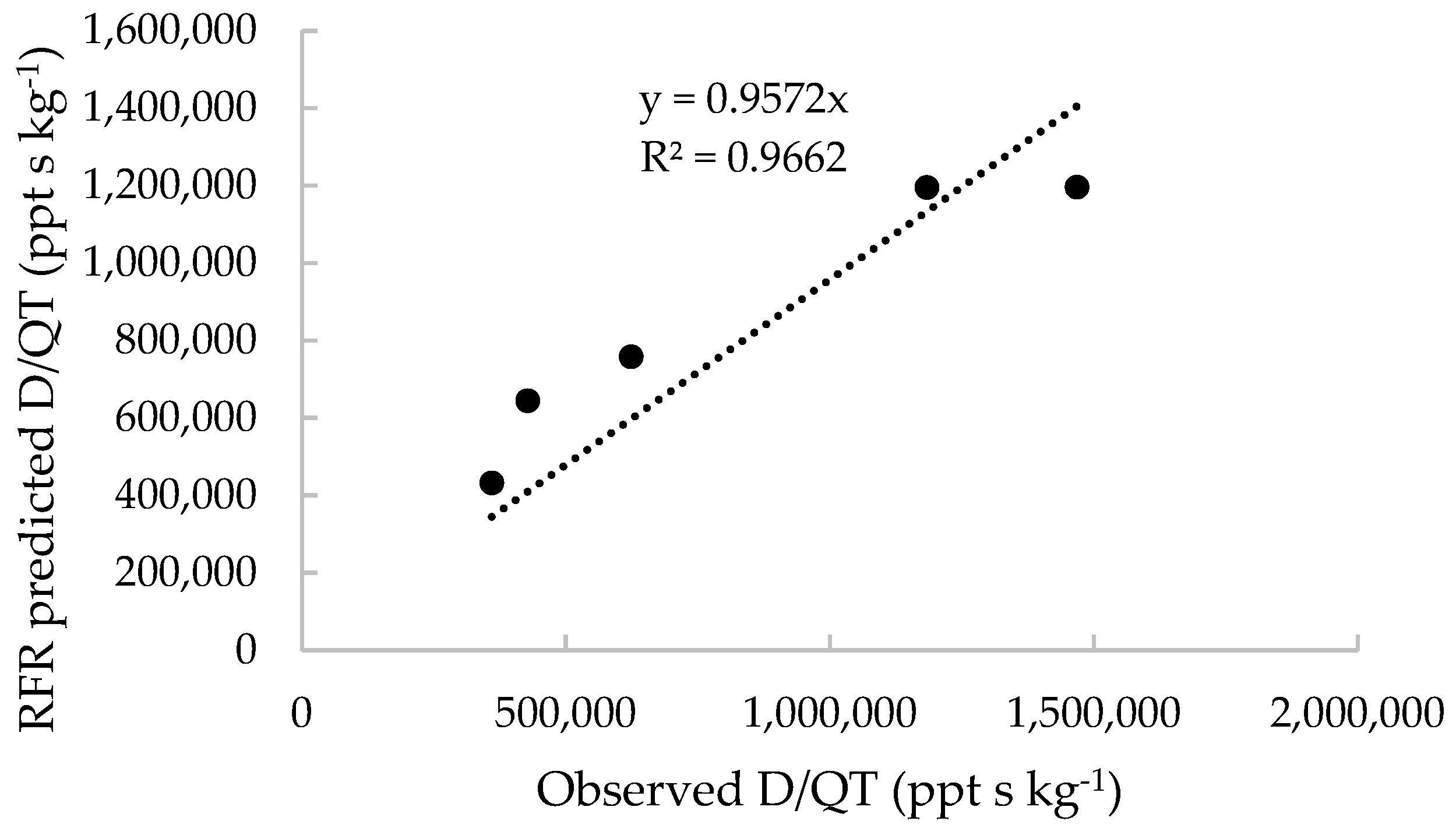
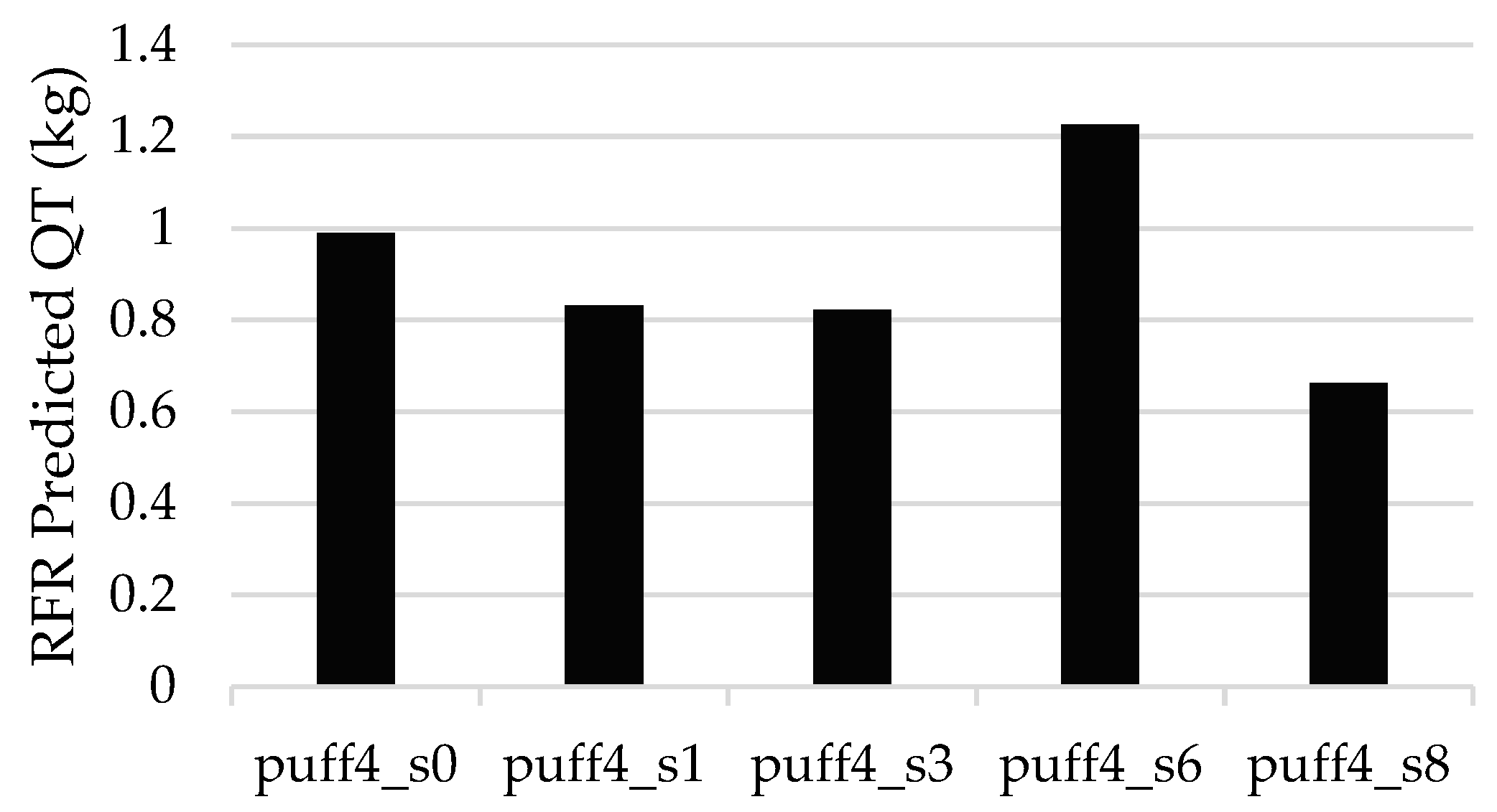
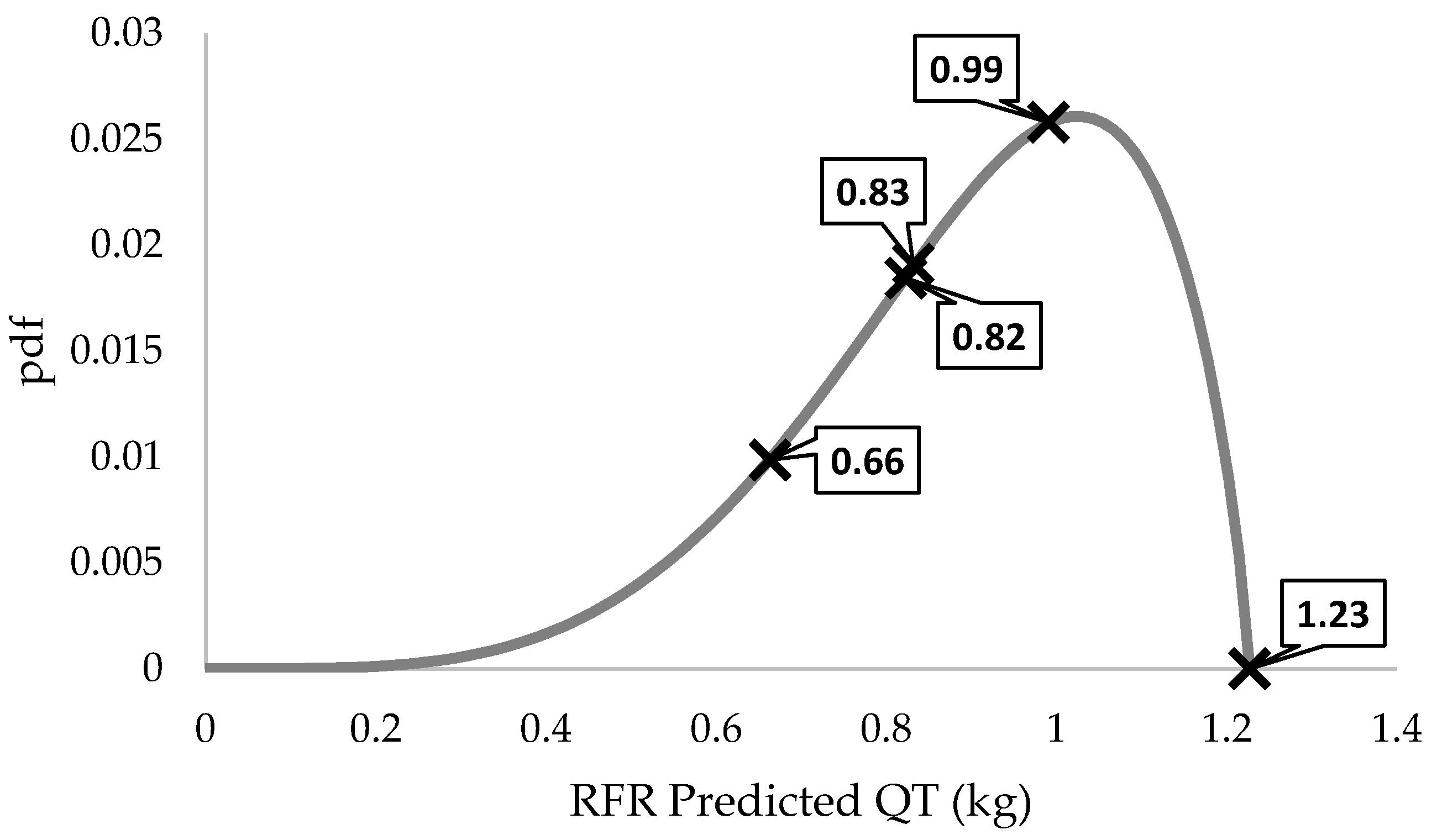
3.2. The Results
3.3. Study Imitations and the Way Forward
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, Q.; Ren, M.; Wu, S.; Sun, Y.; Wang, J.; Wang, Q.; Ma, Y.; Song, X.; Chen, Y. Applications of Artificial Intelligence in the Field of Air Pollution: A Bibliometric Analysis. Front. Public Health 2022, 10, 933665. [Google Scholar] [CrossRef] [PubMed]
- Brunton, S.L.; Noack, B.R.; Koumoutsakos, P. Machine Learning for Fluid Mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Farea, A.; Yli-Harja, O.; Emmert-Streib, F. Understanding Physics-Informed Neural Networks: Techniques, Applications, Trends, and Challenges. AI 2024, 5, 1534–1557. [Google Scholar] [CrossRef]
- Alessandrini, S.; Meech, S.; Cheng, W.; Rozoff, C.; Kumar, R. Comparing Machine Learning and Inverse Modeling Approaches for the Source Term Estimation. Air Qual. Atmos. Health 2024, 17, 2169–2186. [Google Scholar] [CrossRef]
- Wang, R.; Chen, B.; Qiu, S.; Ma, L.; Zhu, Z.; Wang, Y.; Qiu, X. Hazardous Source Estimation Using an Artificial Neural Network, Particle Swarm Optimization and a Simulated Annealing Algorithm. Atmosphere 2018, 9, 119. [Google Scholar] [CrossRef]
- Berbekar, E.; Harms, F.; Leitl, B. Dosage-Based Parameters for Characterization of Puff Dispersion Results. J. Hazard. Mater. 2015, 283, 178–185. [Google Scholar] [CrossRef] [PubMed]
- Bartzis, J.G.; Sakellaris, I.A.; Efthimiou, G. On Exposure Uncertainty Quantification from Accidental Airborne Point Releases. J. Hazard. Mater. Adv. 2022, 6, 100080. [Google Scholar] [CrossRef]
- Bartzis, J.G.; Sakellaris, I.A.; Andronopoulos, S.; Venetsanos, A.; Triantafyllou, A. Towards New Simplified Methodologies on Source Term Estimation and Associated Uncertainties from Accidental Airborne Releases. Build. Environ. 2024, 251, 111222. [Google Scholar] [CrossRef]
- Allwine, J.; Leach, M.; Stockham, L.; Shinn, J.; Hosker, R.; Bowers, J.; Pace, J. Overview of Joint Urban 2003: An Atmospheric Dispersion Study in Oklahoma City. In Proceedings of the Symposium on Planning, Nowcasting, and Forecasting in the Urban Zone, Seattle, WA, USA, 12 January 2004. [Google Scholar]
- Hernández-Ceballos, M.A.; Hanna, S.; Bianconi, R.; Bellasio, R.; Chang, J.; Mazzola, T.; Andronopoulos, S.; Armand, P.; Benbouta, N.; Čarný, P.; et al. UDINEE: Evaluation of Multiple Models with Data from the JU2003 Puff Releases in Oklahoma City. Part II: Simulation of Puff Parameters. Bound.-Layer Meteorol. 2019, 171, 351–376. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; pp. 157–175. ISBN 978-1-4419-9326-7. [Google Scholar]
- Balogun, A.-L.; Tella, A.; Baloo, L.; Adebisi, N. A Review of the Inter-Correlation of Climate Change, Air Pollution and Urban Sustainability Using Novel Machine Learning Algorithms and Spatial Information Science. Urban Clim. 2021, 40, 100989. [Google Scholar] [CrossRef]
- Gariazzo, C.; Carlino, G.; Silibello, C.; Renzi, M.; Finardi, S.; Pepe, N.; Radice, P.; Forastiere, F.; Michelozzi, P.; Viegi, G.; et al. A Multi-City Air Pollution Population Exposure Study: Combined Use of Chemical-Transport and Random-Forest Models with Dynamic Population Data. Sci. Total Environ. 2020, 724, 138102. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.-X.; Wu, J.-L.; Xiao, H. Physics-Informed Machine Learning Approach for Reconstructing Reynolds Stress Modeling Discrepancies Based on DNS Data. Phys. Rev. Fluids 2017, 2, 034603. [Google Scholar] [CrossRef]
- Hinder, F.; Brinkrolf, J.; Hammer, B. Feature Selection for Trustworthy Regression Using Higher Moments. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2022; Pimenidis, E., Angelov, P., Jayne, C., Papaleonidas, A., Aydin, M., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 76–87. [Google Scholar]
- Bartzis, J.G.; Varvayanni, M.; Venetsanos, A.; Catsaros, N.; Housiadas, C.; Horsch, G.; Statharas, J.; Amanatidis, G.T.; Megaritou, A.; Konte, K. ADREA-I: A Three-Dimensional Finite Volume Transport Code for Mesoscale Atmospheric Transport (The Cartesian Version) Part I: The Model Description. NCSR Demokritos Demo 1993, 93. [Google Scholar] [CrossRef]
- Andronopoulos, S.; Bartzis, J.G.; Würtz, J.; Asimakopoulos, D. Modelling the Effects of Obstacles on the Dispersion of Denser-than-Air Gases. J. Hazard. Mater. 1994, 37, 327–352. [Google Scholar] [CrossRef]
- Andronopoulos, S.; Grigoriadis, D.; Robins, A.; Venetsanos, A.; Rafailidis, S.; Bartzis, J.G. Three-Dimensional Modelling of Concentration Fluctuations in Complicated Geometry. Environ. Fluid Mech. 2001, 1, 415–440. [Google Scholar] [CrossRef]
- Venetsanos, A.G.; Papanikolaou, E.; Bartzis, J.G. The ADREA-HF CFD Code for Consequence Assessment of Hydrogen Applications. Int. J. Hydrog. Energy 2010, 35, 3908–3918. [Google Scholar] [CrossRef]
- Andronopoulos, S.; Bartzis, J.G.; Efthimiou, G.C.; Venetsanos, A.G. Assessment of Puff-Dispersion Variability Through Lagrangian and Eulerian Modelling Based on the JU2003 Campaign. Bound.-Layer Meteorol. 2019, 171, 395–422. [Google Scholar] [CrossRef]
- Bartzis, J.G.; Efthimiou, G.C.; Andronopoulos, S. Modelling Short Term Individual Exposure from Airborne Hazardous Releases in Urban Environments. J. Hazard. Mater. 2015, 300, 182–188. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min | Max | Mean | Sigma | Beta Mode |
|---|---|---|---|---|
| 0.663 | 1.227 | 0.907 | 0.213 | 1.024 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bartzis, J.; Andronopoulos, S.; Sakellaris, I. Source Term Estimation for Puff Releases Using Machine Learning: A Case Study. Atmosphere 2025, 16, 697. https://doi.org/10.3390/atmos16060697
Bartzis J, Andronopoulos S, Sakellaris I. Source Term Estimation for Puff Releases Using Machine Learning: A Case Study. Atmosphere. 2025; 16(6):697. https://doi.org/10.3390/atmos16060697
Chicago/Turabian StyleBartzis, John, Spyros Andronopoulos, and Ioannis Sakellaris. 2025. "Source Term Estimation for Puff Releases Using Machine Learning: A Case Study" Atmosphere 16, no. 6: 697. https://doi.org/10.3390/atmos16060697
APA StyleBartzis, J., Andronopoulos, S., & Sakellaris, I. (2025). Source Term Estimation for Puff Releases Using Machine Learning: A Case Study. Atmosphere, 16(6), 697. https://doi.org/10.3390/atmos16060697