2.4. Multivariate Analysis Tool
Classifiers for multivariate analysis can be obtained by several techniques, including artificial intelligence (AI) [
21,
34,
41]. These techniques allow for the identification of classes that, after being approved by experts, represent the functional states of the process or system under study. In addition to the important task of making decisions, knowledge of the functional states allows for a detailed understanding of the relationships between the classes and the descriptors (variables) on the basis of which they are formed [
42].
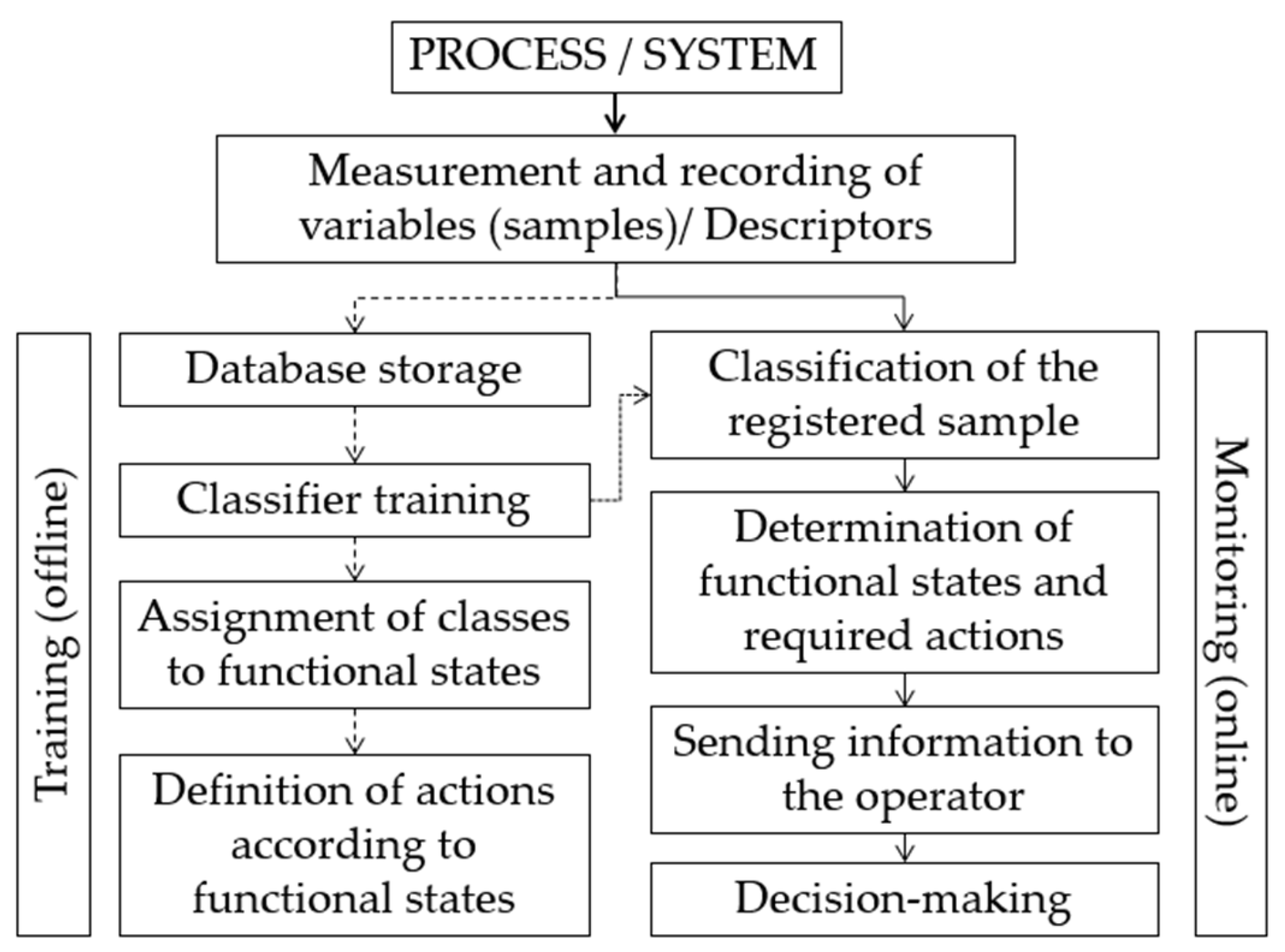
Figure 2 presents a typical framework for data-driven process supervision and diagnosis using classifiers. This data monitoring scheme is shown for the offline training stage, while the process information obtained by physical measurements is stored in a historical file (historical data). In the learning stage, the historical process data are used to train a classifier, which assigns a class to each signal sample or set of descriptors. The historical dataset for this study contains information on five descriptors (PM
2.5, management of air quality episodes, PANDEMIC, strict lockdown, and relaxed lockdown) and includes 244 samples. In the learning stage, the historical data of the process are used to train a classifier, which assigns a class to each signal sample or set of descriptors. These classes, after being analyzed by the process expert, are associated with functional states, and it is necessary to determine the actions that are required and should be suggested to the process operator. Monitoring and supervision of each new sample processed by the classifier are carried out online. According to the classification, the corresponding functional state is identified; next, this state and the required actions are presented to the operator. The overall aim is to identify the state of the process at each instant, providing the operator with an analytical element for decision-making.
For this research development, the training stage is carried out using a supervised learning scheme, since the classes or functional states are known. The classifier training will allow us to determine how the different descriptors are associated with the pre-existing states and propose a way to visualize the information related to air quality data (PM2.5) based on the correspondence of classes for each temporal record.
One method used in monitoring and supervision, based on classifiers, is fuzzy clustering. Unlike hard clustering, this technique not only identifies the class or functional state to which the sample belongs but also assesses the degree of membership of a sample in each class or state. These degrees of membership enable the analysis and validation of the classifications [
42,
43]. Among the classification methods used in monitoring and supervision is the K-means. This is one of the simplest and most popular unsupervised machine learning algorithms, requiring the initial centroids as parameters and the number of class (
K) for training [
44]. An optimization criterion allows clustering data according to their similarity; in this case, the distance measures the separation of a data point from the center of a class.
Fuzzy C-Means (FCM) is another commonly used method, which is based on the minimization of the Euclidean distance
dij (dij =|xi − ci|) between the data of a sample (register),
xi, and the centers of classes
cj. The value
uij in the range [0, 1] represents the degree of membership assigned for each sample,
xi, with respect to each class or Cluster
j. The minimization function
J is defined in terms of the degree of membership matrix
U[uij] and the centers
cj Equation (1). The class clustering for this method is shaped like hyperspheres [
45,
46].
Furthermore, the GK-means method, derived from FCM, uses the Mahalanobis
dij (dij = (xi − cj)V−1(xi − ci)) distance measurement, where
V−1 is the inverse of the covariance matrix and allows making the clustering of classes in the shape of hyperellipsoids [
47]. Lastly, the LAMDA method, from its English name “Learning Algorithm Multivariable and Data Analysis” [
48], allows working with class updating. Unlike the previous methods, it can process both quantitative and qualitative data and estimate the degree of adaptation of each data point to the classes. Adaptation is established in the possibilistic sense. The Marginal Adequacy Degree (MAD) of each descriptor
xj to each class is analyzed by LAMDA. From an interpolation of T-Norm and S-Norm, the global adequacy degree (GAD) of each data point
x (set of descriptors or variables in a sampling time) is obtained for each class. For class adequacy, the Non-Informative Class (NIC) is used as the minimum threshold to determine whether an element belongs to a class.
When the descriptor is numerical, the MAD is calculated by selecting one of the different functions, including the fuzzy extension of the binomial function Equation (2) and the Gaussian function Equation (3), which are commonly used.
where
xg is the normalized variable, and
ρjg corresponds to the mean value for the variable
xg in the class
j.
where
σ is the standard deviation, and
m is the mean, and
(xg − mjg) the parameter measures the proximity to the prototype. When the descriptor is qualitative, the observed frequency of its attribute modality is used to assess the MAD.
The aggregate function is a linear interpolation between t-norm (
γ) and t-conorm (
β) as shown in Equation (4), where the parameter
α, 0
≤ α ≤ 1, is called exigency.
where
is the vector of normalized registers with
n descriptors, and
C corresponds to the class (
C = [1, 2, …, #classes]).
The most common fuzzy logic operators are {γ(a,b) = a*b; β(a,b) = a + b − a*b} and {γ(a,b) = min(a,b); β(a,b) = max(a,b)}, where a and b are fuzzy values. Each data point x’ is assigned the class C according to the maximum value of GAD.
Isaza et al. [
49] conducted a comparative analysis of various representative classification techniques. These included fuzzy clustering methods such as GK-means and LAMDA, radial basis functions for artificial neural networks (ANNs), Fisher linear discriminant, and the k-nearest neighbor method, which represent statistical approaches. In addition, CART decision trees were considered by Breiman et al. [
50].
Table 2 summarizes the key characteristics of these classification methods and the parameters defined by the user.
For the comparative analysis, four well-known benchmark datasets from the UCI Repository were used: Iris, Australian Credit, Heart Disease, and Wastewater Treatment Plant [
51]. The selection of these datasets allowed for a comprehensive evaluation of the LAMDA method across diverse data characteristics. The training datasets selected exhibit high variability in several aspects: dataset size (ranging from 150 to 1000 records), number of classes (from 2 to 13), number of descriptors (from 4 to 38), and the presence of symbolic descriptors. This variability allows for a comprehensive evaluation of the generalization capability of the LAMDA model, which is a significant advantage, as strong generalization performance is crucial for real-world applications beyond the training dataset.
In general, when appropriate parameters were selected, the methods demonstrated acceptable performance in both training and testing phases. However, for the Australian Credit and Wastewater Treatment Plant datasets, achieving a classifier with satisfactory performance was not possible using RBF and GK-means, respectively. In contrast, LAMDA consistently exhibited strong generalization capability, as its test performance closely matched its training performance.
LAMDA offers several advantages, including ease of result interpretation and a fast training algorithm that does not rely on error minimization, yielding results in the first iteration. Additionally, it enables unsupervised classification without requiring a predefined number of classes and can handle mixed data types (qualitative and quantitative). This method not only facilitates knowledge extraction from the training dataset but also allows for the addition of new classes without requiring a new learning phase—an advantage not found in other methods.
LAMDA is frequently compared to GK-means, as both are considered unsupervised learning algorithms. However, GK-means requires a predefined number of classes and is highly sensitive to parameter selection. Moreover, since GK-means is an optimization-based method, its results are significantly influenced by the random initialization of class centers, leading to variability in classification outcomes.
The LAMDA methodology, implemented in the SALSA software [
52,
53], allows passive recognition, self-learning (which does not require knowing the number of groups in advance), and supervised learning. This technique processes quantitative, qualitative, and interval data, and it is not an iterative algorithm. The recognition classification mode allows the inclusion of a class for each record to be considered when running the algorithm; the learning process ensures that the obtained distribution matches the predefined classification to the extent allowed by the variation of the algorithm parameters [
54].
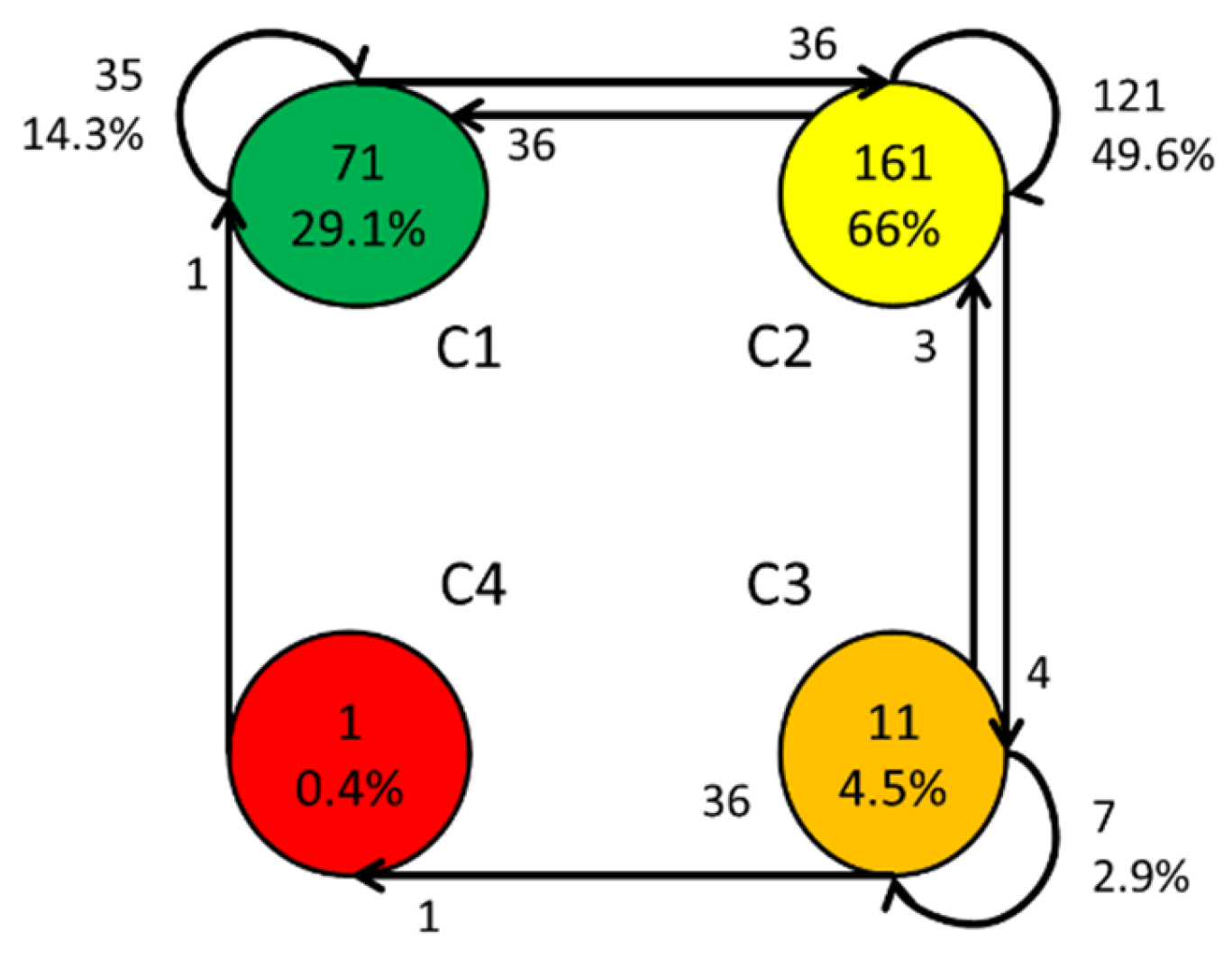
Once the clusters have been defined by fuzzy partitioning, where each group corresponds to a class, it is possible to create transition matrices. These matrices are defined as an array Tj,k, where elements are estimated based on the occurrence of transitions (classes registered in consecutive registers) in the database. The following three (3) transition matrices can be considered:
A raw transition matrix RT = [RTj k], where RTj k is the number of transitions observed of class j and class k Equation (5). The diagonal terms RTj j indicate the number of records in class j, i.e., the number of instants or recording times the system was in this class.
The diagonal terms of the matrices
DT and
AT are, respectively, the number of outputs from and inputs to a class. From these matrices, it is possible to obtain the graph or automaton where the states correspond to the classes, making it possible to present the information on the dynamics of the system in a visual, simple, and easily understandable way [
24,
55].
In
Figure 2, after “Measurement and Recording of Variables (samples) or Descriptors”, normalization is required to ensure equal importance for each descriptor in the classification. Equation (8) corresponds to the normalization of each descriptor (
v), where
v_minimum and
v_maximum represent the minimum and maximum values of the corresponding descriptor. By applying Equation (8) to each descriptor, all sample values will be scaled within the range [0, 1], including the boundary values 0 and 1.
2.5. Information for Classifier Training
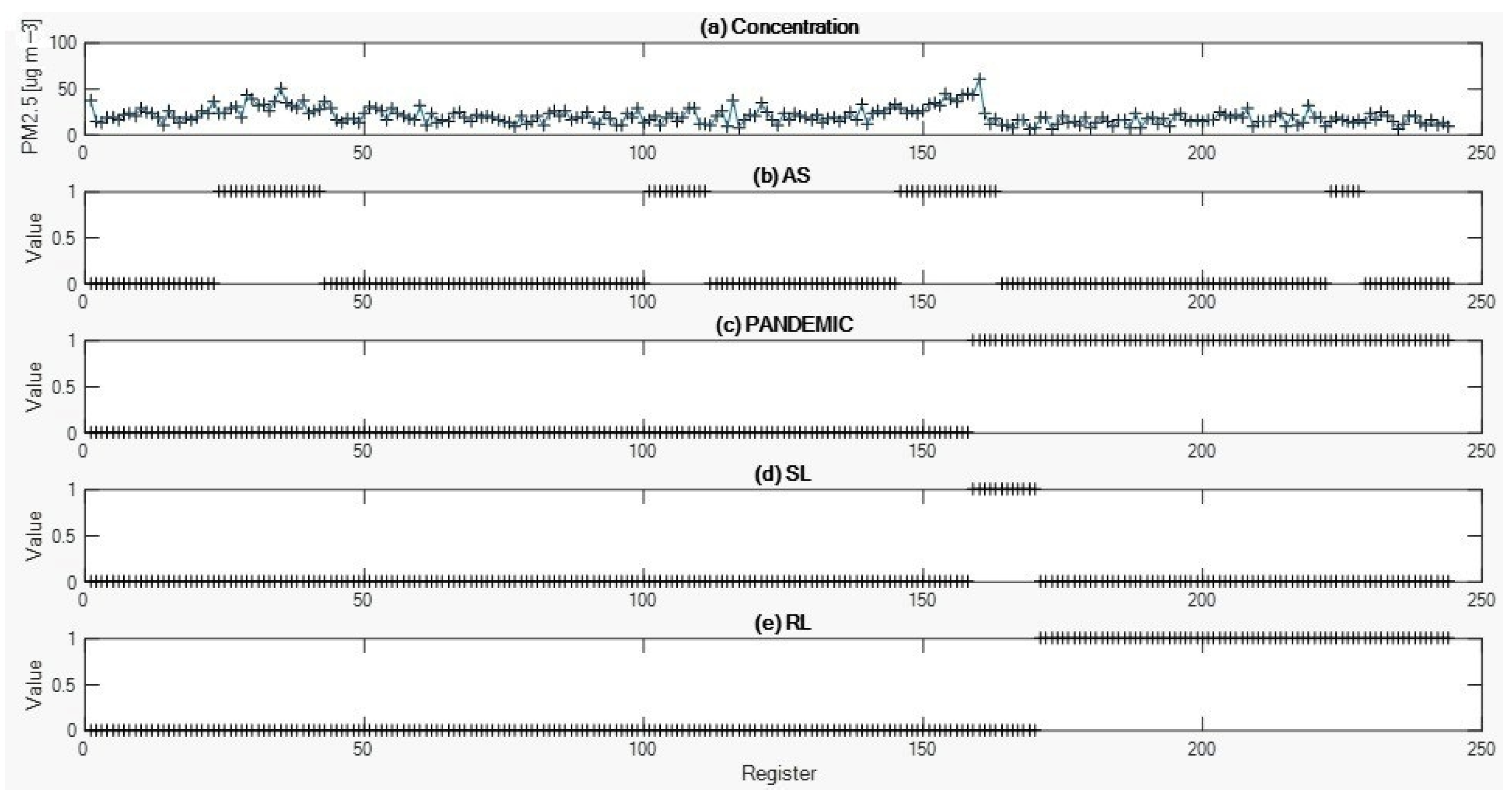
Figure 3 shows the five (5) descriptors used with their respective temporal registers for classifier definition and data analysis. From the temporal register of the data, it can be observed that in the case of the AS descriptor (
Figure 3b), four periods were recorded with value 1 due to its occurrence. For the PANDEMIC descriptor (
Figure 3c), the event wasstarted from the concentration record of sample 159, with an occurrence value of 1. For the SL descriptor (
Figure 3d), the event was recorded a single time and included the smallest number of samples (12 of 244), with an occurrence value of 1. Finally, for the RL descriptor (
Figure 3e), the event started from the recording of data number 171, with an occurrence value of 1.
Furthermore, in
Table 3, the five descriptors and their contexts, i.e., maximum and minimum corresponding values, are presented, which are used for normalization according to Equation (8). The five variables were normalized and then processed in the LAMDA algorithm.
Four classes were defined within which each of the 244 environmental PM
2.5 samples was associated according to the cut-off points (concentration) of the AQI established in the environmental regulations [
34].
Table 4 shows these classes with their respective ranges and categories of air quality and their effect on health.
The well-known and straightforward methodology for evaluating air quality indicators, such as the air quality index (AQI), is based on existing regulations. However, decision-makers and other non-expert professionals in this field must always keep in mind the standard limits that define the various categories as a criterion for analysis.
As an alternative, using and analyzing classifiers equivalent to the AQI allows for an additional assessment of air quality issues. This method evaluates the frequency of events in each class or category and the transitions between them, especially in relation to how one class increases or decreases compared to another. This makes it possible to estimate the changing exposure time (in days) to specific health risks, which is crucial for health impact studies.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}