

Machine Learning for Global Bioclimatic Classification: Enhancing Land Cover Prediction through Random Forests


Abstract

1. Introduction
2. Materials and Methods
2.1. Predictors for Land Classification
2.2. Data
2.2.1. Land Cover Classification Data
2.2.2. Temperature and Precipitation Data
2.2.3. Topographic Data
2.2.4. Elevation Data
2.2.5. Climate Model Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Institution | Frequency | Nominal Resolution | Publication |
|---|---|---|---|---|
| CanESM5 | CCCma | mon | 100 km |
[42] [43] |
| CanESM5-CanOE | CCCma | mon | 100 km |
[44] [45] |
| CESM2 | NCAR | mon | 100 km |
[46] [47] |
| CESM2-WACCM | NCAR | mon | 100 km |
[48] [49] |
| IPSL-CM6A-LR | IPSL | mon | 100 km |
[50] [51] |
| UKESM1-0-LL | Met Office Hadley Centre | mon | 100 km |
[52] [53] |
| ACCESS-CM2 | CSIRO-ARCCSS | mon | 250 km |
[54] [55] |
| AWI-CM-1-1-MR | NCAR | mon | 100 km |
[56] [57] |
| CAS-ESM2-0 | UCI | mon | 100 km |
[58] [59] |
| EC-Earth3 | EC-Earth-Consortium | mon | 100 km |
[60] [61] |
| EC-Earth3-Veg | EC-Earth-Consortium | mon | 100 km |
[62] [63] |
| TaiESM1 | AS-RCEC | mon | 100 km | [64] [65] |
2.3. Random Forest Training
- 1.
- colsample_bylevel: This parameter controls the fraction of features to consider when constructing each level of a tree within the ensemble. A setting of “None” implies the utilisation of all features at each level.
- 2.
- colsample_bynode: Governing the fraction of features to consider for each split decision within a tree node, this parameter regulates the diversity of feature selection at each node. A value of 0.9 signifies that 90% of the features will be randomly sampled for each split.
- 3.
- colsample_bytree: Dictating the fraction of features to consider when constructing each tree in the ensemble, this parameter facilitates the introduction of randomness, thereby enhancing model robustness. A value of 0.9 indicates that 90% of features will be sampled for each tree.
- 4.
- early_stopping_rounds: Employed for preventing overfitting and improving computational efficiency, this parameter determines the number of rounds to continue training without improvement in the evaluation metric before halting. In this instance, early stopping is not activated (“None”).
- 5.
- learning_rate: Central to gradient descent optimisation, this parameter governs the step size at each iteration while traversing towards the minimum of the loss function. A learning rate of 0.2 signifies a moderate step size.
- 6.
- max_depth: Defining the maximum depth of each tree in the ensemble, this parameter regulates the complexity of individual trees and influences the model’s capacity to capture intricate patterns within the data. A high value of 63 suggests a potentially deep tree structure.
- 7.
- max_leaves: This parameter specifies the maximum number of terminal nodes (leaves) in a tree, thus indirectly controlling the tree’s depth. The absence of an upper limit (“None”) implies unrestricted growth of tree nodes.
- 8.
- n_estimators: Determining the total number of trees in the ensemble, this parameter profoundly influences model complexity and computational efficiency. A choice of 300 trees indicates a substantial ensemble size.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Payet, K.; Rouget, M.; Esler, K.J.; Reyers, B.; Rebelo, T.; Thompson, M.W.; Vlok, J.H.J. Effect of Land Cover and Ecosystem Mapping on Ecosystem-Risk Assessment in the Little Karoo, South Africa. Conserv. Biol. 2013, 27, 531–541. [Google Scholar] [CrossRef] [PubMed]
- Zimmermann, P.; Tasser, E.; Leitinger, G.; Tappeiner, U. Effects of land-use and land-cover pattern on landscape-scale biodiversity in the European Alps. Agric. Ecosyst. Environ. 2010, 139, 13–22. [Google Scholar] [CrossRef]
- Betts, R.A.; Falloon, P.D.; Goldewijk, K.K.; Ramankutty, N. Biogeophysical effects of land use on climate: Model simulations of radiative forcing and large-scale temperature change. Agric. For. Meteorol. 2007, 142, 216–233. [Google Scholar] [CrossRef]
- Bala, G.; Caldeira, K.; Wickett, M.; Phillips, T.J.; Lobell, D.B.; Delire, C.; Mirin, A. Combined climate and carbon-cycle effects of large-scale deforestation. Proc. Natl. Acad. Sci. USA 2007, 104, 6550–6555. [Google Scholar] [CrossRef] [PubMed]
- Feddema, J.J.; Oleson, K.W.; Bonan, G.B.; Mearns, L.O.; Buja, L.E.; Meehl, G.A.; Washington, W.M. The Importance of Land-Cover Change in Simulating Future Climates. Science 2005, 310, 1674–1678. [Google Scholar] [CrossRef] [PubMed]
- Veldkamp, A.; Lambin, E. Predicting land-use change. Agric. Ecosyst. Environ. 2001, 85, 1–6. [Google Scholar] [CrossRef]
- Welde, K.; Gebremariam, B. Effect of land use land cover dynamics on hydrological response of watershed: Case study of Tekeze Dam watershed, northern Ethiopia. Int. Soil Water Conserv. Res. 2017, 5, 1–16. [Google Scholar] [CrossRef]
- Yifru, B.A.; Chung, I.M.; Kim, M.G.; Chang, S.W. Assessing the Effect of Land/Use Land Cover and Climate Change on Water Yield and Groundwater Recharge in East African Rift Valley using Integrated Model. J. Hydrol. Reg. Stud. 2021, 37, 100926. [Google Scholar] [CrossRef]
- Estifanos, T.H.; Gebremariam, B. Modeling-impact of Land Use/Cover Change on Sediment Yield (Case Study on Omo-gibe Basin, Gilgel Gibe III Watershed, Ethiopia). Am. J. Mod. Energy 2020, 5, 84–93. [Google Scholar] [CrossRef]
- Li, C.; Managi, S. Land cover matters to human well-being. Sci. Rep. 2021, 11, 15957. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Paul, J.; Dupont, P. Inferring statistically significant features from random forests. Neurocomputing 2015, 150, 471–480. [Google Scholar] [CrossRef]
- Machova, K.; Puszta, M.; Barcák, F.; Bednár, P. A comparison of the bagging and the boosting methods using the decision trees classifiers. Comput. Sci. Inf. Syst. 2006, 3, 57–72. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GISci. Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef]
- Qian, Y.; Zhou, W.; Yan, J.; Li, W.; Han, L. Comparing Machine Learning Classifiers for Object-Based Land Cover Classification Using Very High Resolution Imagery. Remote Sens. 2015, 7, 153–168. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Zhang, F.; Yang, X. Improving land cover classification in an urbanized coastal area by random forests: The role of variable selection. Remote Sens. Environ. 2020, 251, 112105. [Google Scholar] [CrossRef]
- Sun, J.; Ongsomwang, S. Optimal parameters of random forest for land cover classification with suitable data type and dataset on Google Earth Engine. Front. Earth Sci. 2023, 11, 1188093. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Köppen, W. Die Wärmezonen der Erde, nach der Dauer der heissen, gem ässigten und kalten Zeit und nach der Wirkung der Wärme auf die organische Welt betrachtet. Meteorol. Z. 1884, 1, 215–226. [Google Scholar] [CrossRef]
- Whittaker, R. Communities and Ecosystems; MacMillan Publishing Co.: New York, NY, USA, 1975.
- National Geophysical Data Center; NESDIS; NOAA; U.S. Department of Commerce. TerrainBase, Global 5 Arc-Minute Ocean Depth and Land Elevation from the US National Geophysical Data Center (NGDC). 1995. Available online: https://rda.ucar.edu/datasets/ds759-2/ (accessed on 28 May 2024).
- Ojima, D.S.; Galvin, K.A.; Turner, B.L. The Global Impact of Land-Use Change. BioScience 1994, 44, 300–304. [Google Scholar] [CrossRef]
- Bucała-Hrabia, A. The impact of human activities on land use and land cover changes and environmental processes in the Gorce Mountains (Western Polish Carpathians) in the past 50 years. J. Environ. Manag. 2014, 138, 4–14. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Kohler, T.A.; Lenton, T.M.; Svenning, J.C.; Scheffer, M. Future of the human climate niche. Proc. Natl. Acad. Sci. USA 2020, 117, 11350–11355. [Google Scholar] [CrossRef] [PubMed]
- Roe, G.H. OROGRAPHIC PRECIPITATION. Annu. Rev. Earth Planet. Sci. 2005, 33, 645–671. [Google Scholar] [CrossRef]
- Pellet, C.; Hauck, C. Monitoring soil moisture from middle to high elevation in Switzerland: Set-up and first results from the SOMOMOUNT network. Hydrol. Earth Syst. Sci. 2017, 21, 3199–3220. [Google Scholar] [CrossRef]
- Körner, C. The use of ‘altitude’ in ecological research. Trends Ecol. Evol. 2007, 22, 569–574. [Google Scholar] [CrossRef]
- Herrmann, S.M.; Didan, K.; Barreto-Munoz, A.; Crimmins, M.A. Divergent responses of vegetation cover in Southwestern US ecosystems to dry and wet years at different elevations. Environ. Res. Lett. 2016, 11, 124005. [Google Scholar] [CrossRef]
- Rita, A.; Bonanomi, G.; Allevato, E.; Borghetti, M.; Cesarano, G.; Mogavero, V.; Rossi, S.; Saulino, L.; Zotti, M.; Saracino, A. Topography modulates near-ground microclimate in the Mediterranean Fagus sylvatica treeline. Sci. Rep. 2021, 11, 8122. [Google Scholar] [CrossRef] [PubMed]
- Gonçalves, R.V.S.; Cardoso, J.C.F.; Oliveira, P.E.; Raymundo, D.; de Oliveira, D.C. The role of topography, climate, soil and the surrounding matrix in the distribution of Veredas wetlands in central Brazil. Wetl. Ecol. Manag. 2022, 30, 1261–1279. [Google Scholar] [CrossRef]
- Chytrý, K.; Willner, W.; Chytrý, M.; Divíšek, J.; Dullinger, S. Central European forest–steppe: An ecosystem shaped by climate, topography and disturbances. J. Biogeogr. 2022, 49, 1006–1020. [Google Scholar] [CrossRef]
- Aguilar, C.; Herrero, J.; Polo, M.J. Topographic effects on solar radiation distribution in mountainous watersheds and their influence on reference evapotranspiration estimates at watershed scale. Hydrol. Earth Syst. Sci. 2010, 14, 2479–2494. [Google Scholar] [CrossRef]
- ESA. Land Cover CCI Product User Guide Version 2. 2017. Available online: https://maps.elie.ucl.ac.be/CCI/viewer/download/ESACCI-LC-Ph2-PUGv2_2.0.pdf (accessed on 28 May 2024).
- Harris, I.; Osborn, T.; Jones, P.; Lister, D. Version 4 of the CRU TS monthly high-resolution gridded multivariate climate dataset. Sci. Data 2020, 7, 109. [Google Scholar] [CrossRef] [PubMed]
- Marthews, T.R.; Dadson, S.J.; Lehner, B.; Abele, S.; Gedney, N. High-resolution global topographic index values for use in large-scale hydrological modelling. Hydrol. Earth Syst. Sci. 2015, 19, 91–104. [Google Scholar] [CrossRef]
- Defourny, P.; Kirches, G.; Brockmann, C.; Boettcher, M.; Peters, M.; Bontemps, S.; Lamarche, C.; Schlerf, M.; Santoro, M. Land cover CCI. Prod. User Guide Version 2012, 2, 10–1016. [Google Scholar]
- Eyring, V.; Bony, S.; Meehl, G.A.; Senior, C.A.; Stevens, B.; Stouffer, R.J.; Taylor, K.E. Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geosci. Model Dev. 2016, 9, 1937–1958. [Google Scholar] [CrossRef]
- Swart, N.C.; Cole, J.N.; Kharin, V.V.; Lazare, M.; Scinocca, J.F.; Gillett, N.P.; Anstey, J.; Arora, V.; Christian, J.R.; Jiao, Y.; et al. CCCma CanESM5 Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- Swart, N.C.; Cole, J.N.; Kharin, V.V.; Lazare, M.; Scinocca, J.F.; Gillett, N.P.; Anstey, J.; Arora, V.; Christian, J.R.; Jiao, Y.; et al. CCCma CanESM5 Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Swart, N.C.; Cole, J.N.; Kharin, V.V.; Lazare, M.; Scinocca, J.F.; Gillett, N.P.; Anstey, J.; Arora, V.; Christian, J.R.; Jiao, Y.; et al. CCCma CanESM5-CanOE Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- Swart, N.C.; Cole, J.N.; Kharin, V.V.; Lazare, M.; Scinocca, J.F.; Gillett, N.P.; Anstey, J.; Arora, V.; Christian, J.R.; Jiao, Y.; et al. CCCma CanESM5-CanOE Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Danabasoglu, G. NCAR CESM2 Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- Danabasoglu, G. NCAR CESM2 Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Danabasoglu, G. NCAR CESM2-WACCM Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- Danabasoglu, G. NCAR CESM2-WACCM Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Boucher, O.; Denvil, S.; Levavasseur, G.; Cozic, A.; Caubel, A.; Foujols, M.A.; Meurdesoif, Y.; Cadule, P.; Devilliers, M.; Ghattas, J.; et al. IPSL IPSL-CM6A-LR Model Output Prepared for CMIP6 CMIP Historical, 2018. [CrossRef]
- Boucher, O.; Denvil, S.; Levavasseur, G.; Cozic, A.; Caubel, A.; Foujols, M.A.; Meurdesoif, Y.; Cadule, P.; Devilliers, M.; Dupont, E.; et al. IPSL IPSL-CM6A-LR Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Tang, Y.; Rumbold, S.; Ellis, R.; Kelley, D.; Mulcahy, J.; Sellar, A.; Walton, J.; Jones, C. MOHC UKESM1.0-LL Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- Good, P.; Sellar, A.; Tang, Y.; Rumbold, S.; Ellis, R.; Kelley, D.; Kuhlbrodt, T. MOHC UKESM1.0-LL Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Dix, M.; Bi, D.; Dobrohotoff, P.; Fiedler, R.; Harman, I.; Law, R.; Mackallah, C.; Marsland, S.; O’Farrell, S.; Rashid, H.; et al. CSIRO-ARCCSS ACCESS-CM2 Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- Dix, M.; Bi, D.; Dobrohotoff, P.; Fiedler, R.; Harman, I.; Law, R.; Mackallah, C.; Marsland, S.; O’Farrell, S.; Rashid, H.; et al. CSIRO-ARCCSS ACCESS-CM2 Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Danek, C.; Shi, X.; Stepanek, C.; Yang, H.; Barbi, D.; Hegewald, J.; Lohmann, G. AWI AWI-ESM1.1LR Model Output Prepared for CMIP6 CMIP Historical, 2020. [CrossRef]
- Semmler, T.; Danilov, S.; Rackow, T.; Sidorenko, D.; Barbi, D.; Hegewald, J.; Pradhan, H.K.; Sein, D.; Wang, Q.; Jung, T. AWI AWI-CM1.1MR Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Chai, Z. CAS CAS-ESM1.0 Model Output Prepared for CMIP6 CMIP Historical, 2020. [CrossRef]
- CAS CAS-ESM1.0 Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2018.
- EC-Earth-Consortium. EC-Earth-Consortium EC-Earth3 Model Output Prepared for CMIP6 CMIP historical, 2019. [CrossRef]
- EC-Earth-Consortium. EC-Earth-Consortium EC-Earth3 Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- EC-Earth-Consortium. EC-Earth-Consortium EC-Earth3-Veg Model Output Prepared for CMIP6 CMIP Historical, 2019. [CrossRef]
- EC-Earth-Consortium. EC-Earth-Consortium EC-Earth3-Veg Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2019. [CrossRef]
- Lee, W.L.; Liang, H.C. AS-RCEC TaiESM1.0 Model Output Prepared for CMIP6 CMIP Historical, 2020. [CrossRef]
- Lee, W.L.; Liang, H.C. AS-RCEC TaiESM1.0 Model Output Prepared for CMIP6 ScenarioMIP ssp585, 2020. [CrossRef]
- Sillmann, J.; Kharin, V.V.; Zhang, X.; Zwiers, F.W.; Bronaugh, D. Climate extremes indices in the CMIP5 multimodel ensemble: Part 1. Model evaluation in the present climate. J. Geophys. Res. Atmos. 2013, 118, 1716–1733. [Google Scholar] [CrossRef]
- Kim, Y.H.; Min, S.K.; Zhang, X.; Sillmann, J.; Sandstad, M. Evaluation of the CMIP6 multi-model ensemble for climate extreme indices. Weather Clim. Extrem. 2020, 29, 100269. [Google Scholar] [CrossRef]
- Li, J.; Miao, C.; Wei, W.; Zhang, G.; Hua, L.; Chen, Y.; Wang, X. Evaluation of CMIP6 Global Climate Models for Simulating Land Surface Energy and Water Fluxes During 1979–2014. J. Adv. Model. Earth Syst. 2021, 13, e2021MS002515. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Wichansky, P.S.; Steyaert, L.T.; Walko, R.L.; Weaver, C.P. Evaluating the effects of historical land cover change on summertime weather and climate in New Jersey: Land cover and surface energy budget changes. J. Geophys. Res. Atmos. 2008, 113, D10107. [Google Scholar] [CrossRef]
- Lawrence, P.J.; Chase, T.N. Investigating the climate impacts of global land cover change in the community climate system model. Int. J. Climatol. 2010, 30, 2066–2087. [Google Scholar] [CrossRef]
- Gibbard, S.; Caldeira, K.; Bala, G.; Phillips, T.J.; Wickett, M. Climate effects of global land cover change. Geophys. Res. Lett. 2005, 32, L23705. [Google Scholar] [CrossRef]
- Feng, M.; Sexton, J.; Wang, P.; Montesano, P.; Calle, L.; Carvalhais, N.; Poulter, B.; Wooten, M.; Wagner, W.; Elders, A.; et al. Northward migration of the boreal forest confirmed by satellite record. Res. Sq. 2021, preprint. [Google Scholar] [CrossRef]
- Boulton, C.A.; Lenton, T.M.; Boers, N. Pronounced loss of Amazon rainforest resilience since the early 2000s. Nat. Clim. Chang. 2022, 12, 271–278. [Google Scholar] [CrossRef]
- Pausata, F.S.; Gaetani, M.; Messori, G.; Berg, A.; Maia de Souza, D.; Sage, R.F.; deMenocal, P.B. The Greening of the Sahara: Past Changes and Future Implications. ONE Earth 2020, 2, 235–250. [Google Scholar] [CrossRef]
- Sparey, M.; Cox, P.; Williamson, M.S. Bioclimatic change as a function of global warming from CMIP6 climate projections. Biogeosciences 2023, 20, 451–488. [Google Scholar] [CrossRef]
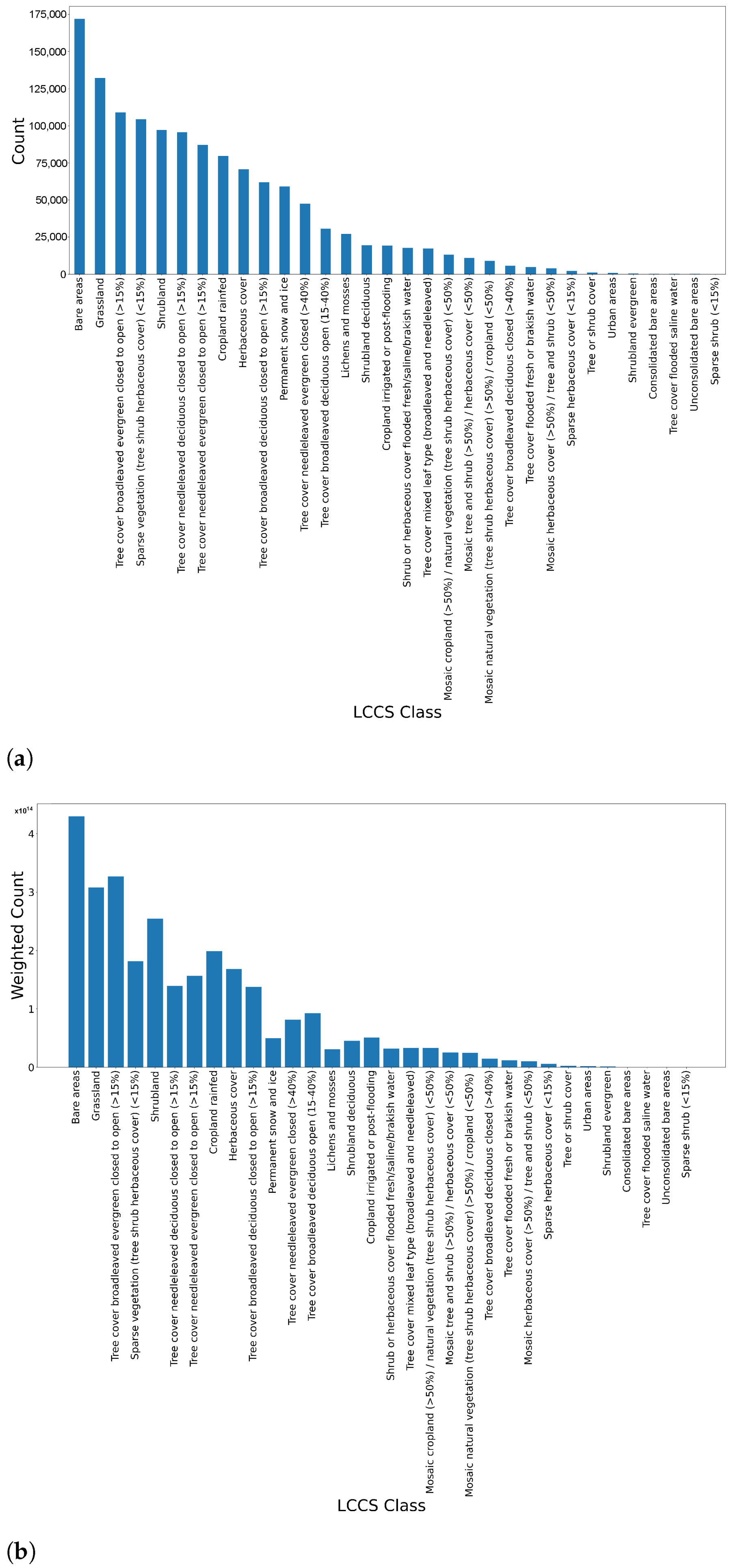
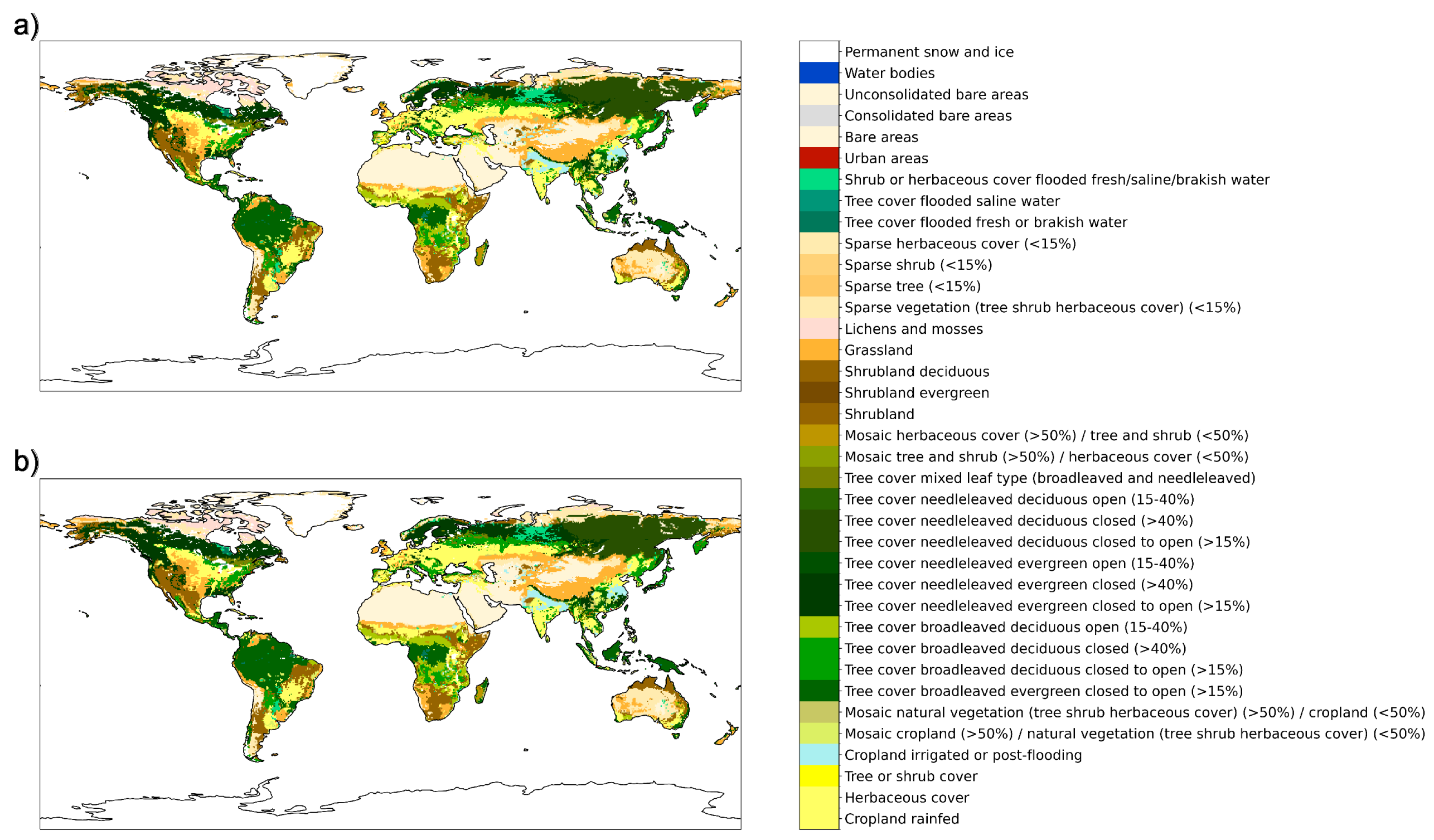
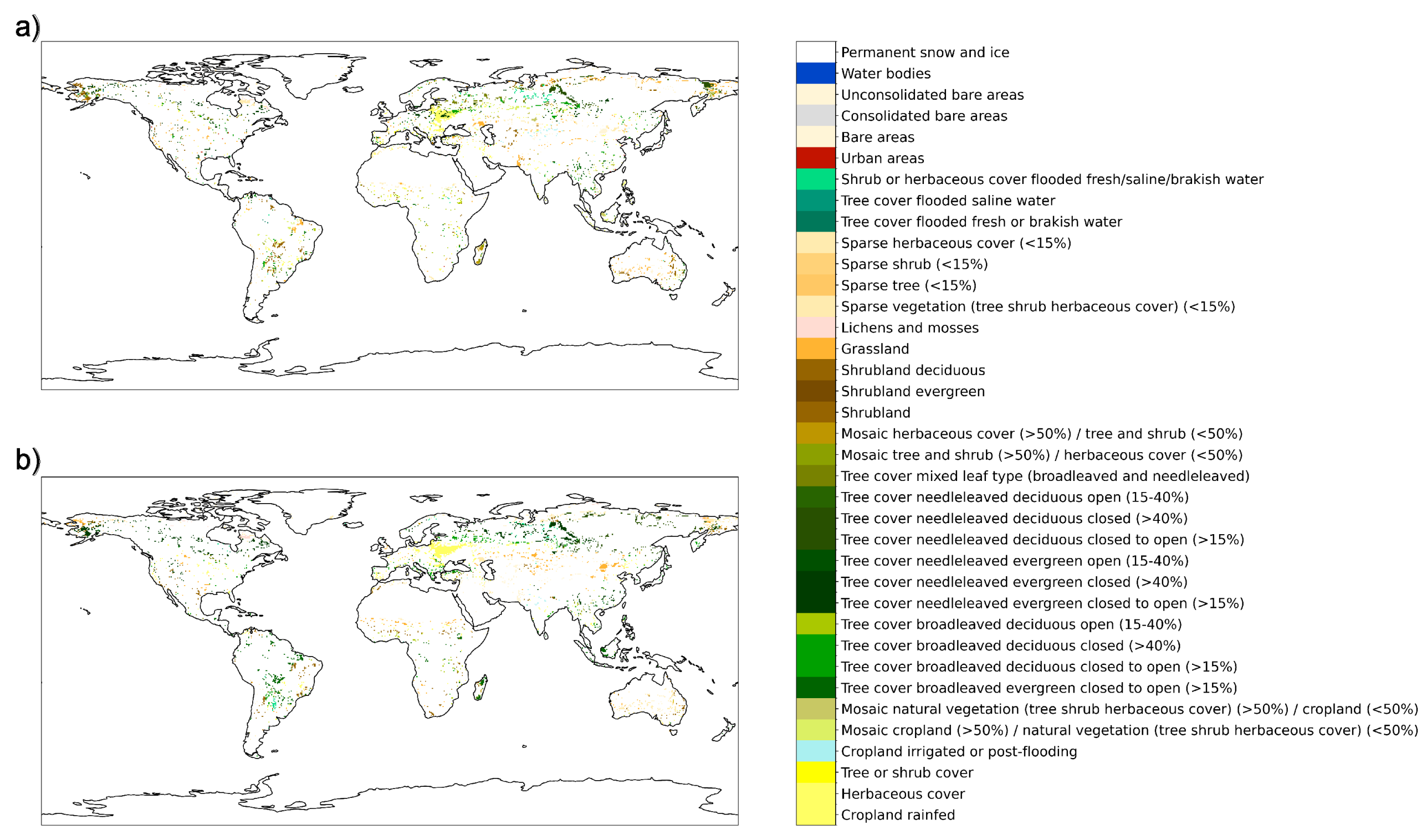
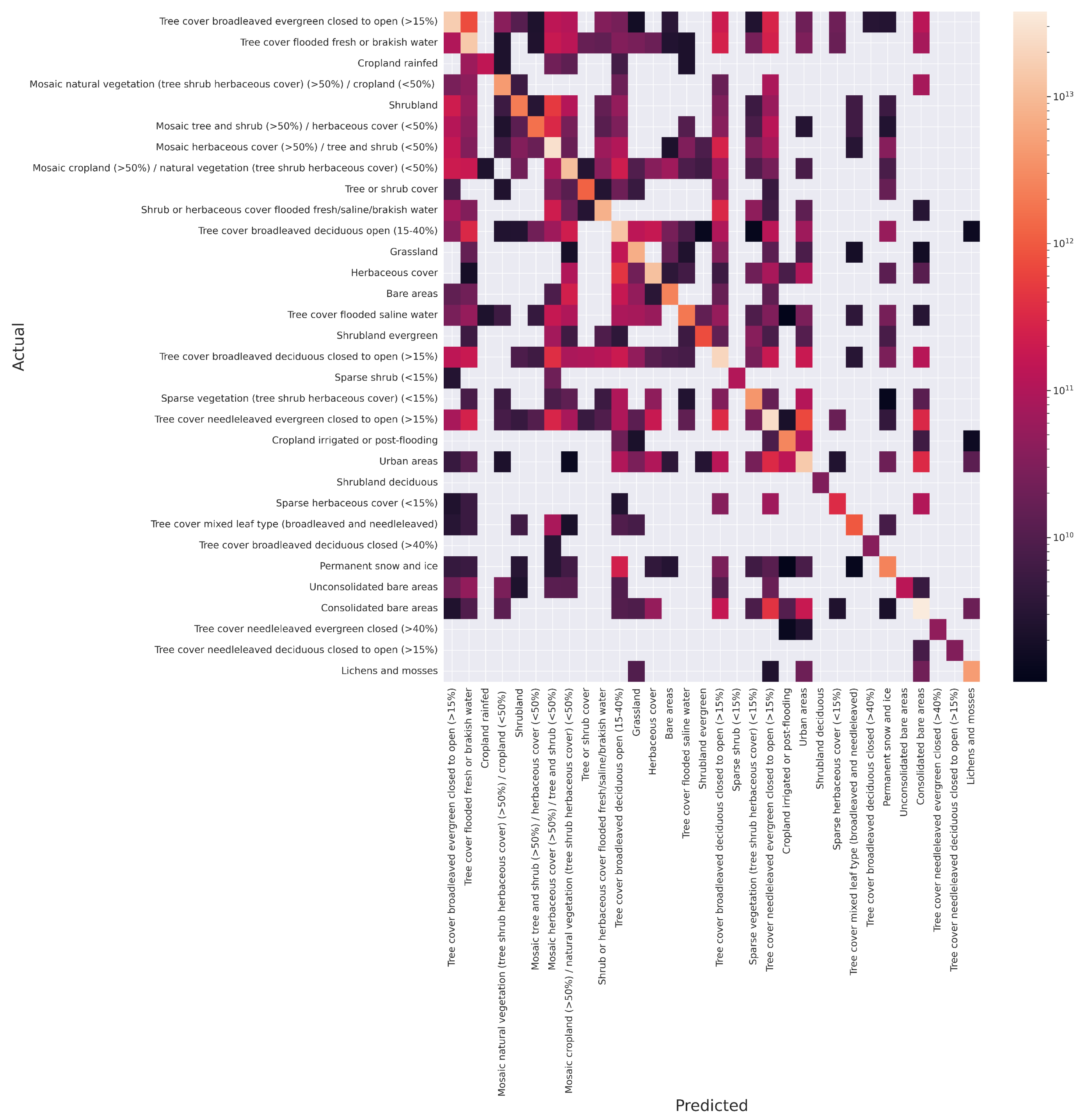
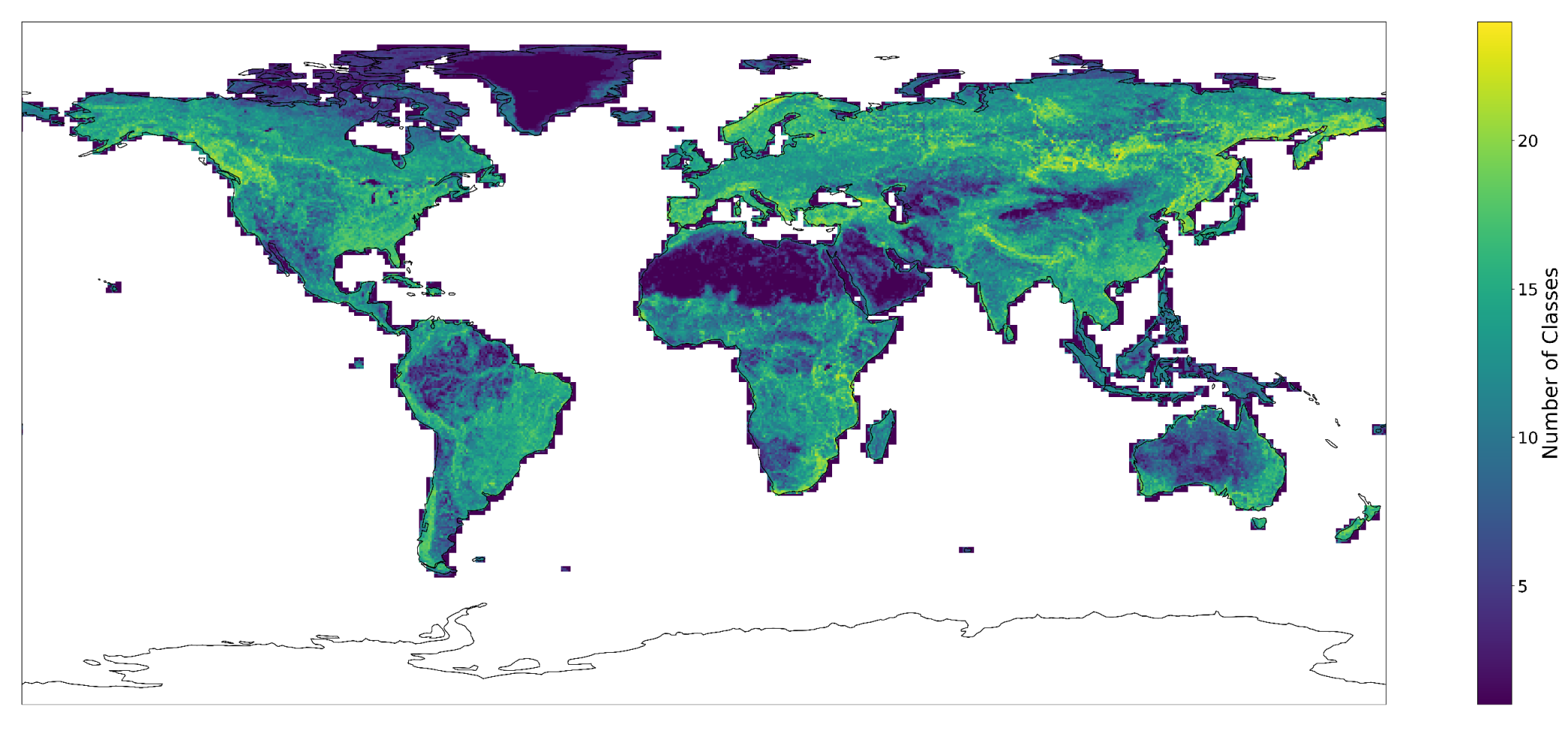
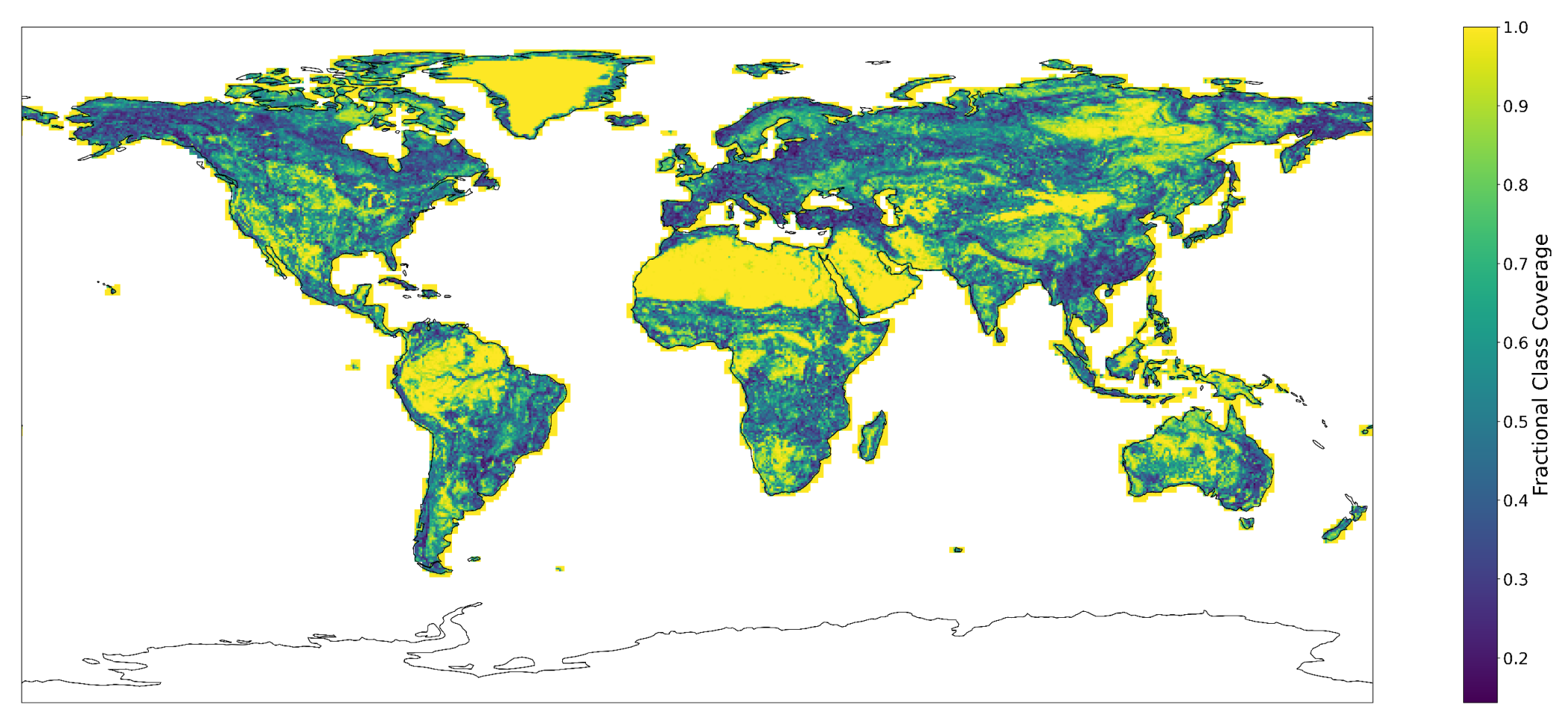

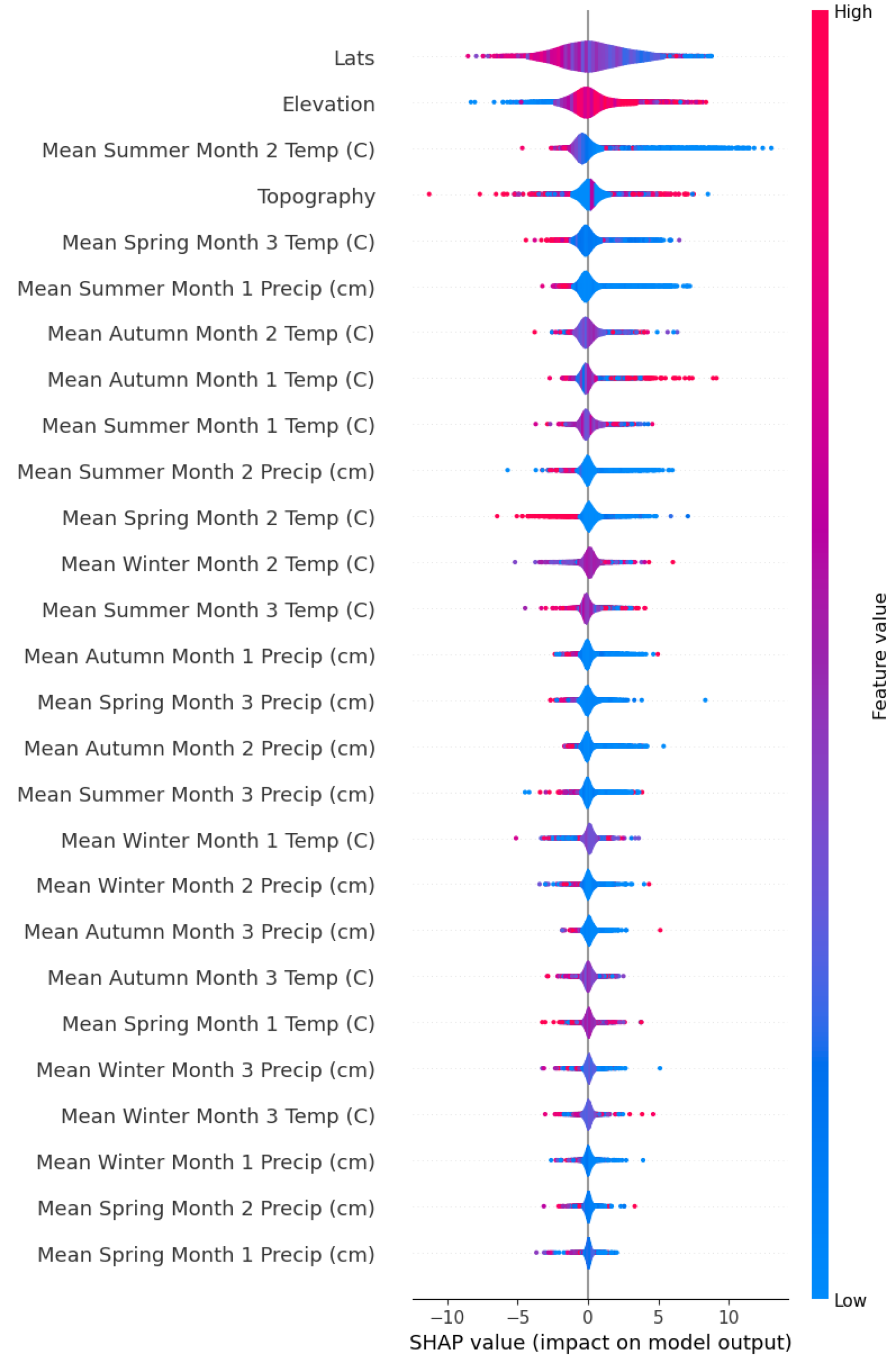
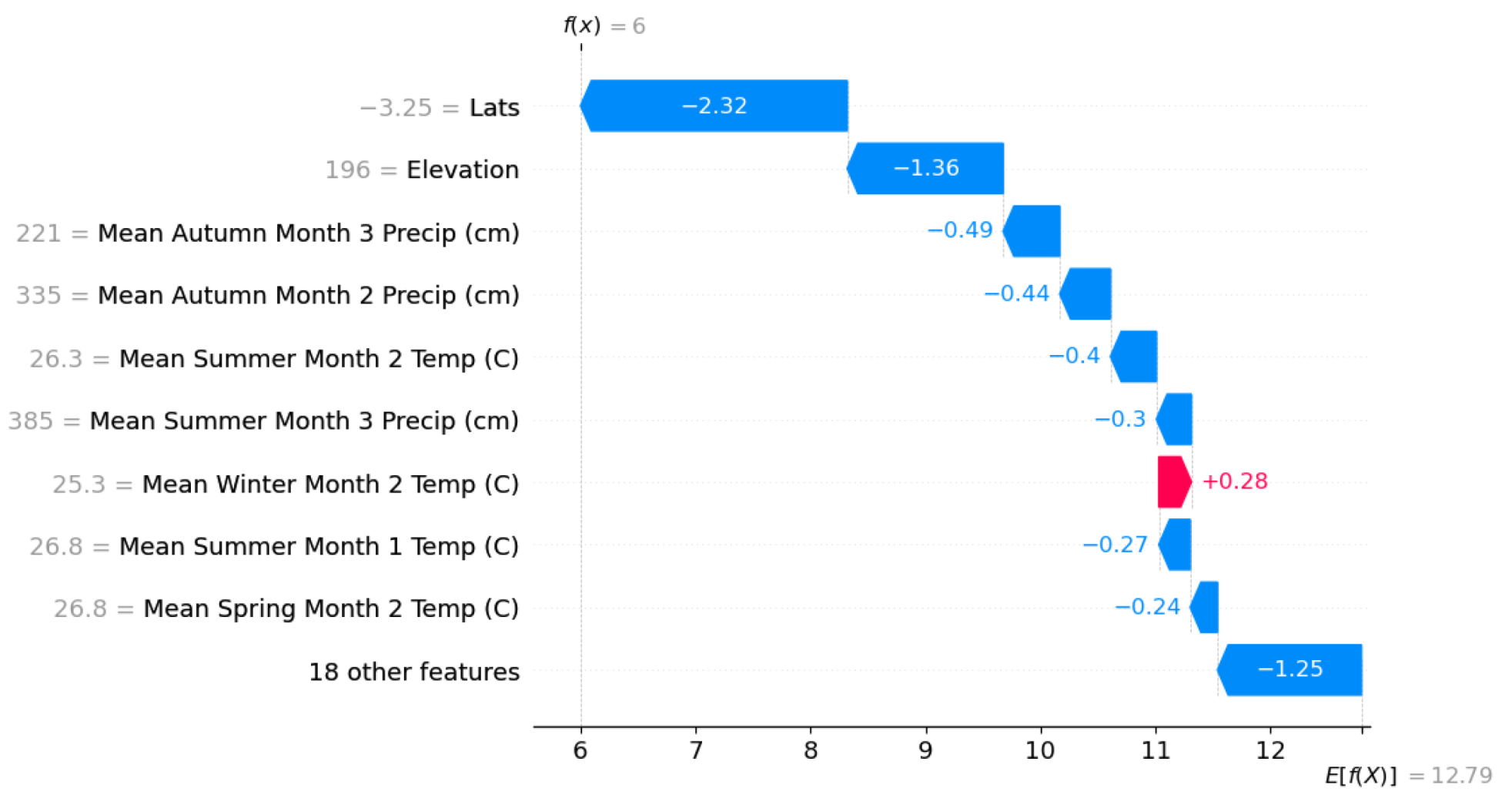
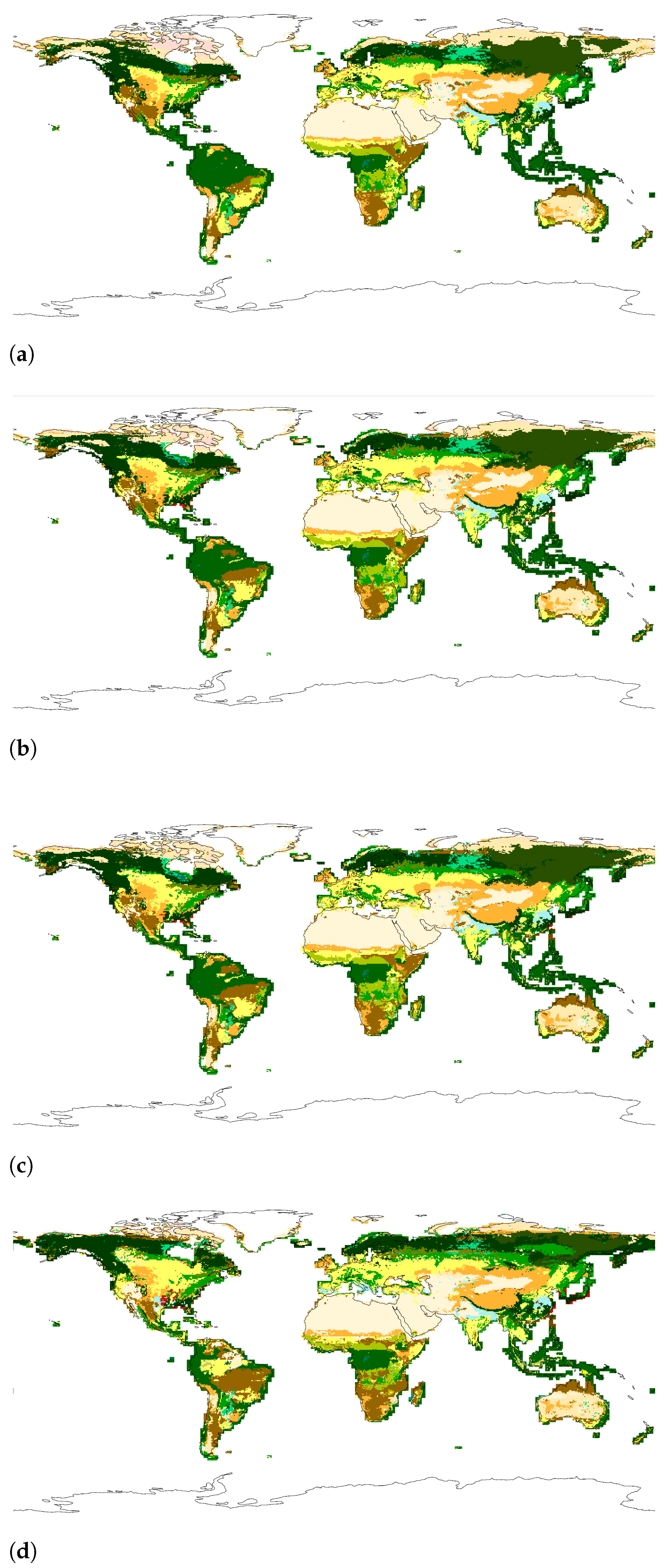
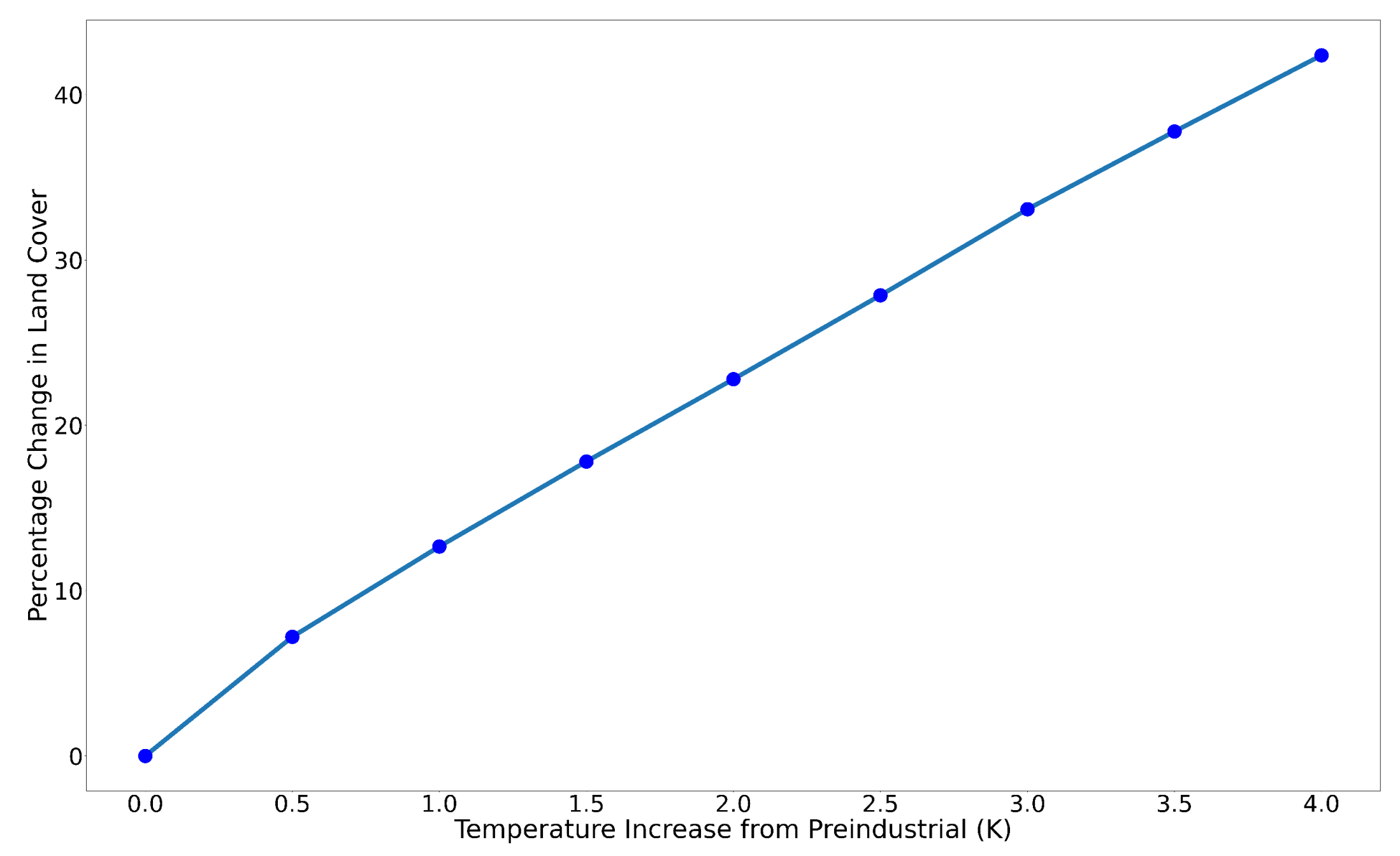
| Data | Frequency | Date Range | Initial Resolution | Publication |
|---|---|---|---|---|
| ESA Land Cover Data | Yearly | 1992–2015 | 0.002778° × 0.002778° | [37] |
| Temperature | Daily | 1901–2019 | 0.5° × 0.5° | [38] |
| Precipitation | Daily | 1901–2019 | 0.5° × 0.5° | [38] |
| Topographic Index | Singular | 2014 | 0.5° × 0.5° | [39] |
| Elevation | Singular | 1995 | 0.0833333° × 0.0833333° | [25] |
| Parameter | Value |
|---|---|
| colsample_bylevel | None |
| colsample_bynode | 0.9 |
| colsample_bytree | 0.9 |
| early_stopping_rounds | None |
| learning_rate | 0.2 |
| max_depth | 63 |
| max_leaves | None |
| n_estimators | 300 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sparey, M.; Williamson, M.S.; Cox, P.M. Machine Learning for Global Bioclimatic Classification: Enhancing Land Cover Prediction through Random Forests. Atmosphere 2024, 15, 700. https://doi.org/10.3390/atmos15060700
Sparey M, Williamson MS, Cox PM. Machine Learning for Global Bioclimatic Classification: Enhancing Land Cover Prediction through Random Forests. Atmosphere. 2024; 15(6):700. https://doi.org/10.3390/atmos15060700
Chicago/Turabian StyleSparey, Morgan, Mark S. Williamson, and Peter M. Cox. 2024. "Machine Learning for Global Bioclimatic Classification: Enhancing Land Cover Prediction through Random Forests" Atmosphere 15, no. 6: 700. https://doi.org/10.3390/atmos15060700
APA StyleSparey, M., Williamson, M. S., & Cox, P. M. (2024). Machine Learning for Global Bioclimatic Classification: Enhancing Land Cover Prediction through Random Forests. Atmosphere, 15(6), 700. https://doi.org/10.3390/atmos15060700