
Adjustment Methods Applied to Precipitation Series with Different Starting Times of the Observation Day

 ,
,  , , and
, , and
Abstract
1. Introduction
- (i)
- To apply adjustment methods already tested in the literature to modern datasets;
- (ii)
- To test for the first time two further adjustment methods, based on reanalysis;
- (iii)
- To compare the alignment of the series adjusted to the original series of stations located near the target one;
- (iv)
- To determine the impact of all the methods considered on the identification of extreme days;
- (v)
- To explore the feasibility of the application of the adjustment methods considered to WM and AF series.
2. Materials and Methods
2.1. Datasets
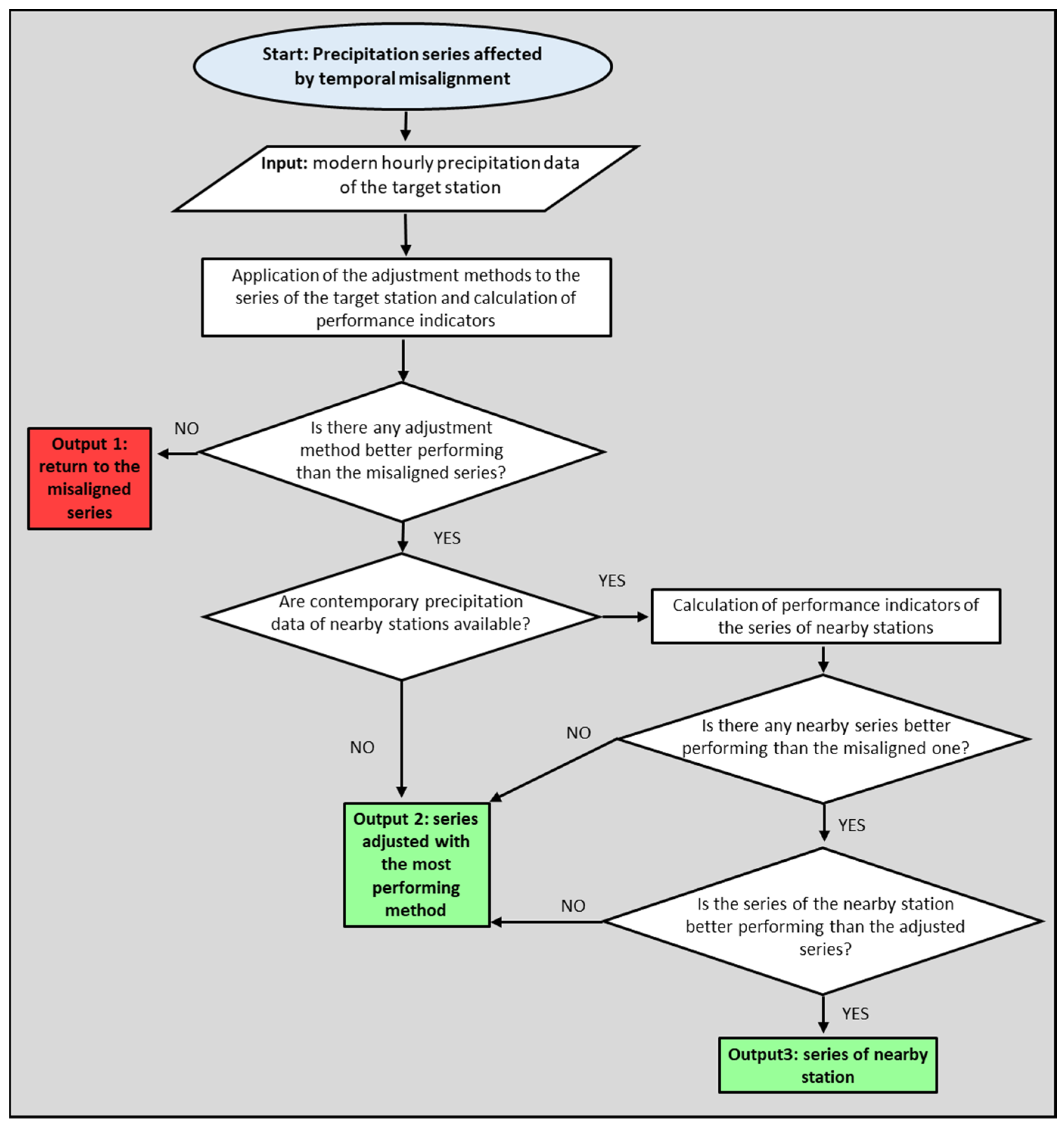
2.2. Methodology
- (i)
- Application of the selected adjustment methods to the series of the target station and calculation of performance indicators. Three out of five adjustment methods are derived from the literature while two further methods, based on reanalysis, are tested for the first time;
- (ii)
- If there is at least an adjustment method that is better performing than the misaligned series, go to the next step; otherwise, return to the misaligned series (output 1, end of process);
- (iii)
- If there are contemporary precipitation data of a nearby station available, go to the next step; otherwise, select the series adjusted with the best performing method (output 2, end of process);
- (iv)
- Calculate performance indicators of the series of nearby stations;
- (v)
- If there is at least one nearby series that is better performing than the misaligned series, go to the next step; otherwise, return to the series adjusted with the best performing method (output 2, end of process);
- (vi)
- If the series of the nearby station is better performing than the adjusted series, select the series of the nearby station (output 3, end of process); otherwise, select the series adjusted with the best performing method (output 2, end of process).
2.3. Homogeneity Tests
2.4. Adjustment Methods
- (1)
- 9–99–9 daily series is considered as is, i.e., daily precipitation total is the sum of the hourly amounts collected from 9 LT of dj−1 to 9 LT of dj.
- (2)
- 9–9 1-day shift (named simply “1 day” in the following) [13]This method shifts the daily amounts of the 9–9 series back one calendar day, because most of the daily amount of the 9–9 series is collected in the previous day. Therefore, the precipitation amount of the target day, dj, is simply associated with the previous day, dj−1.
- (3)
- 9–9 shift uniform (named simply “unif”) [15]This method reapportions 9–9 daily totals from a 2-day moving window surrounding the target date, P_adj_j = (Pj · Fj) + (Pj+1 · Fj+1), where P_adj_j is the adjusted amount for the target day j; Pj and Pj+1 are the original 9–9 reported daily totals for the target and next days, respectively; and Fj and Fj+1 are the fractions of Pj and Pj+1, respectively, to be included in the estimate of P_adj_j. Because the uniform method assumes that a reported daily total is distributed uniformly across all hours within its respective 24 h period, Fj and Fj+1 are determined directly by the number of hours of overlap between the 24 h periods, represented by Pj and Pj+1, and the new P_adj_j, i.e., Fj = 9 and Fj+1 = 15 (Figure 3).
- (4)
- 9–9 shift ERA5 (named “ERA5”) [29]Like method (3) but Fj and Fj+1 are determined by means of the reanalysis (0.25° resolution, 1940–today). The simulated 9–9 amount of the target day and of the day after is determined using hourly reconstructed data, and the fractions of precipitation that occurred on those days are calculated. Then, the fractions Fj and Fj+1, are multiplied by the 9–9 amount of day j and day j + 1, respectively, and the results are added to obtain the total amount of the target day j.
- (5)
- 9–9 shift NOAA (named “NOAA”) [30]Like method (4) but using the NOAA 20CRv3 reanalysis to determine the fractions Fj and Fj+1. Unlike ERA5, this dataset uses only pressure observations as input and monthly sea surface temperatures as boundary conditions, covers the period 1836–2015 (experimentally extended to 1806), has a coarser resolution (~0.75°), and provides 3-hourly data.
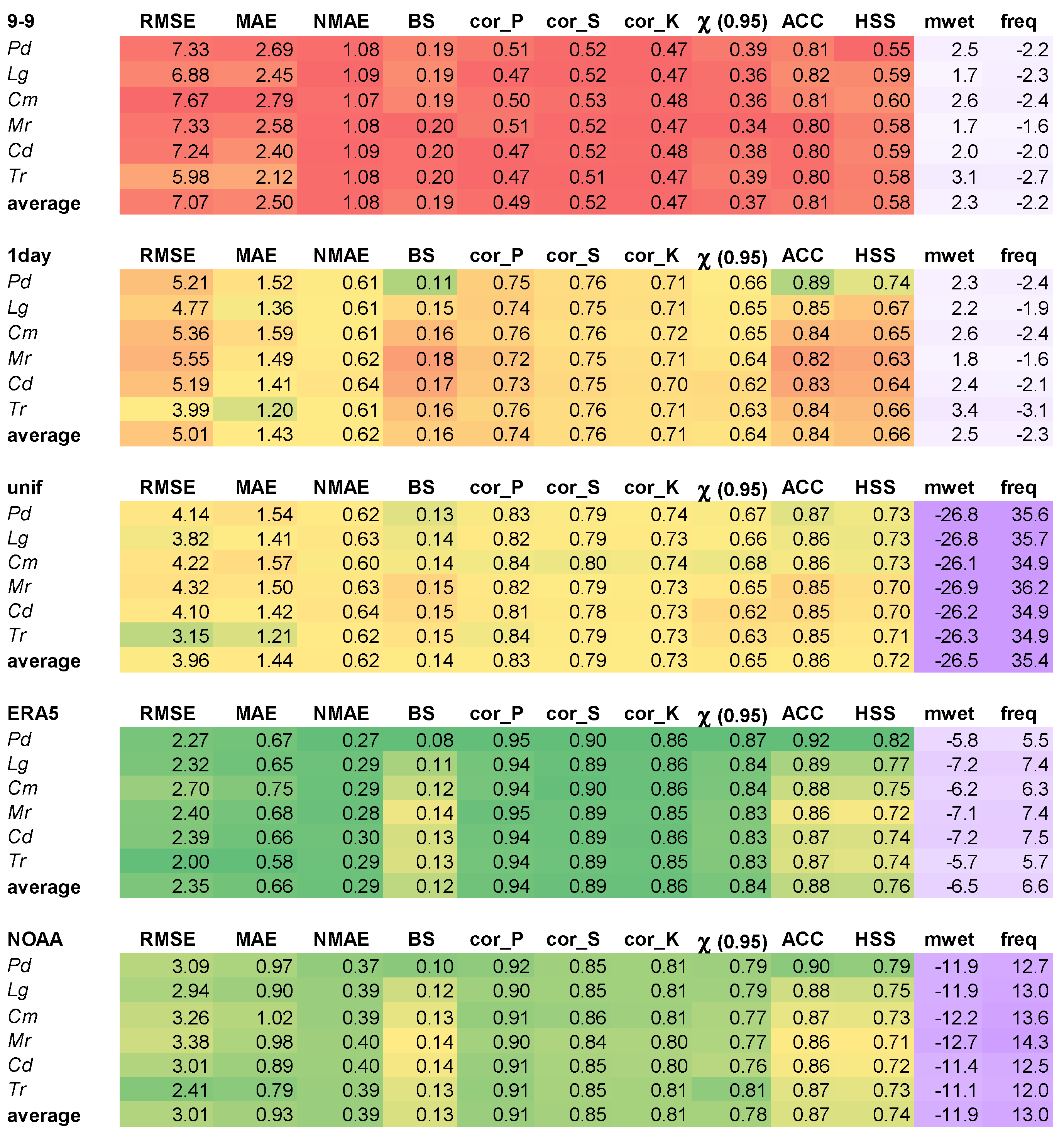
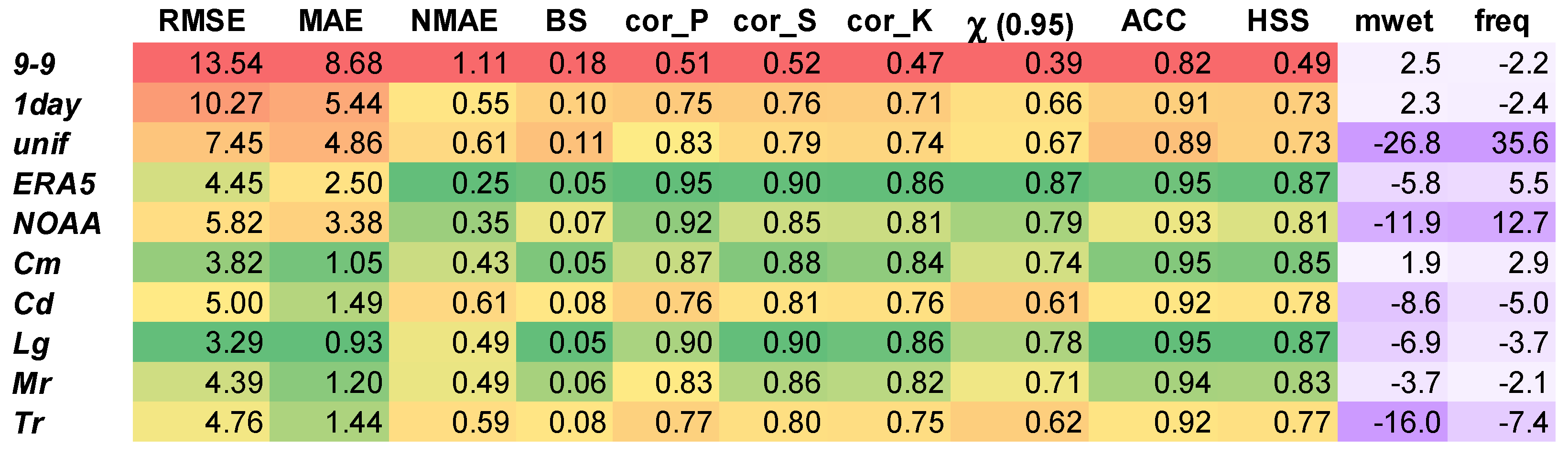
2.5. Performance Indicators
- ▪
- Root-Mean-Square Error (RMSE) is the quadratic mean of the differences between the observations and the values predicted by the model (in this case, the adjustment methods):where N is the number of observations, is the value predicted by the adjustment method considered, and is the observed one.
- ▪
- Mean Absolute Error (MAE) is a common indicator to measure the errors between values predicted by the model and the observations:
- ▪
- Normalized Mean Absolute Error (NMAE) is a validation metric to compare the MAE of (time) series with different scales. As the precipitation series of the stations listed in Tabel 1 have different temporal averages, both MAE and NMAE were calculated. NMAE is the ratio of MAE to mean daily precipitation:
- ▪
- Brier Score (BS) compares the predicted probability of an event to observations. As precipitation reconstruction does not provide probabilities, and are both binary with 1 = rain and 0 = no rain [31]. Therefore, BS is the percentage of time steps wrongly assigned as wet or dry, calculated asOnly the mismatches between and (wet the first and dry the second or viceversa) contribute with non-zero terms.
- ▪
- Pearson’s correlation coefficient:where is the covariance, and are the standard deviations of and , and and are the mean values and , respectively.
- ▪
- Spearman’s rank correlation coefficient is defined similarly but the variables and are converted to ranks and :
- ▪
- Kendall’s rank correlation coefficient measures the correspondence between the ranking of and : the number of possible pairings of and is ; if the pairs are ordered by the values, then, for each , we count the number of > (, total number of concordant pairs) and the number of < (, total number of discordant pairs); hence, the correlation coefficient is defined as
- ▪
- Tail dependence (χ) takes in input and and evaluates the dependence on the tail of the distribution of two series about a set quantile; therefore, it investigates how the adjustment method affects the temporal alignment of extreme days: in this work, 0.95 was chosen, following Oyler et al. [14] and Weller et al. [32]. It is defined asThis indicator is directly available in the R extRemes package [33], while new scripts were created to calculate the others.
- ▪
- Accuracy was derived by the confusion matrix [34], which takes the binary variables and as input and is defined aswhere P and N are the total positive (wet days) and negative (dry days) cases, and TP and TN are the true positive and true negative cases, respectively. A “true positive” is a day correctly identified by the adjustment method as a wet day, while a “true negative” is a day correctly identified as a dry day.
- ▪
- Heidke Skill Score (HSS) quantifies the alignment of precipitation occurrence and is defined aswhere FP and FN are the false positive and false negative cases, i.e., days incorrectly identified as wet or dry, respectively. The confusion matrix and the indicator ACC were calculated using the R caret package [35], while HSS was calculated using the elements of the confusion matrix.
- ▪
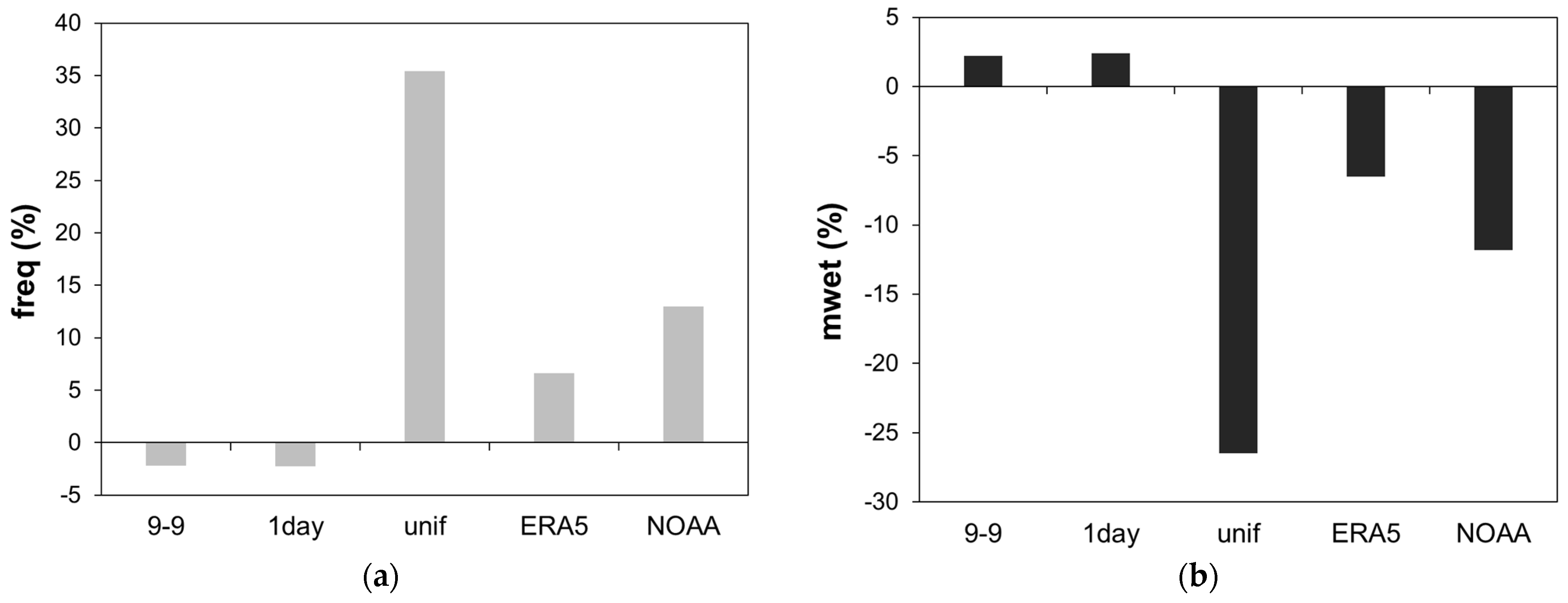
- Mean precipitation over wet days (mwet) is the difference between the mean of the predicted values and the mean of the observed values of precipitation. Mwet is expressed as a percentage, calculated with respect to the observed values ; since all 0 < < 1 are set to zero, for the reason explained in Section 2.3, the calculation of the mean values over only the wet days (when the binary variables are 1) is simplified:
- ▪
- Frequency over wet days (freq) is the percentage difference between the number of predicted wet days and the observed wet days. The percentage is calculated with respect to the observed wet days:
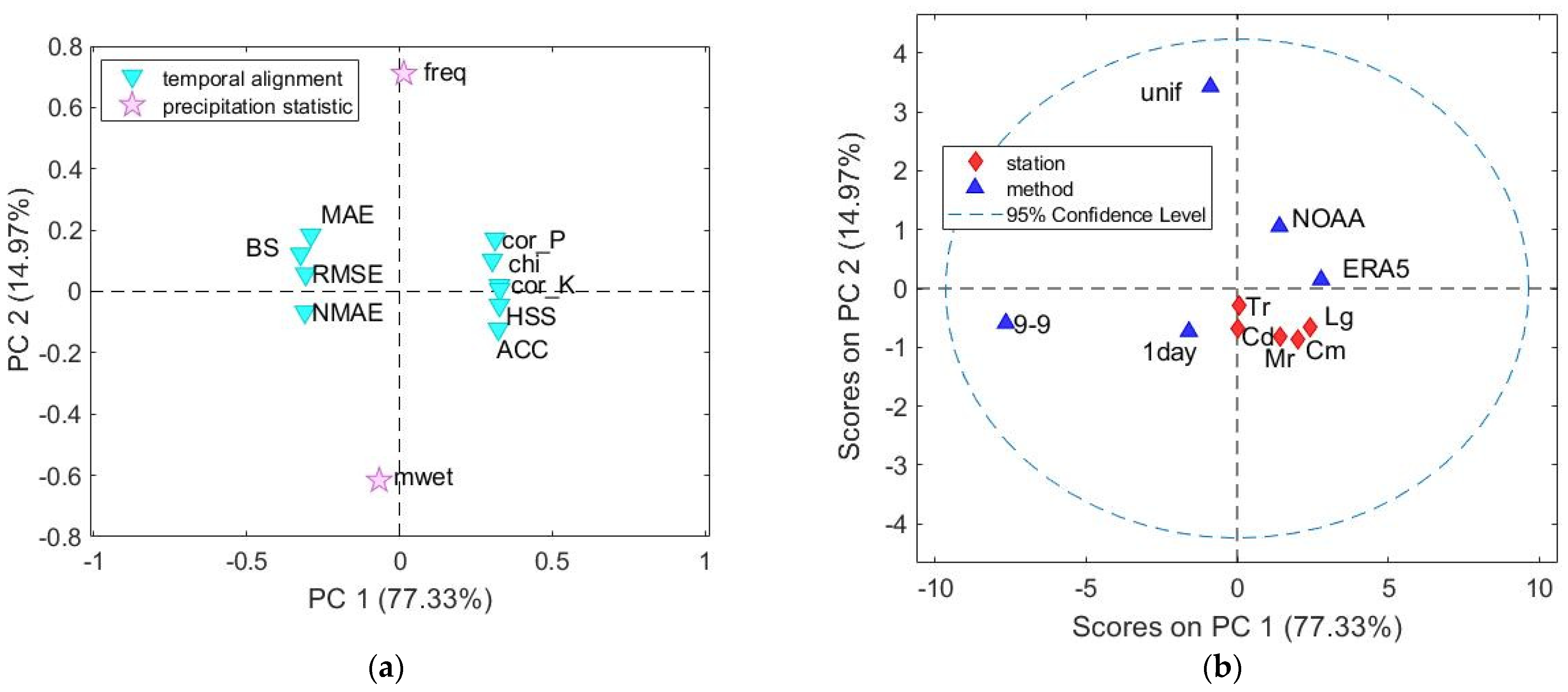
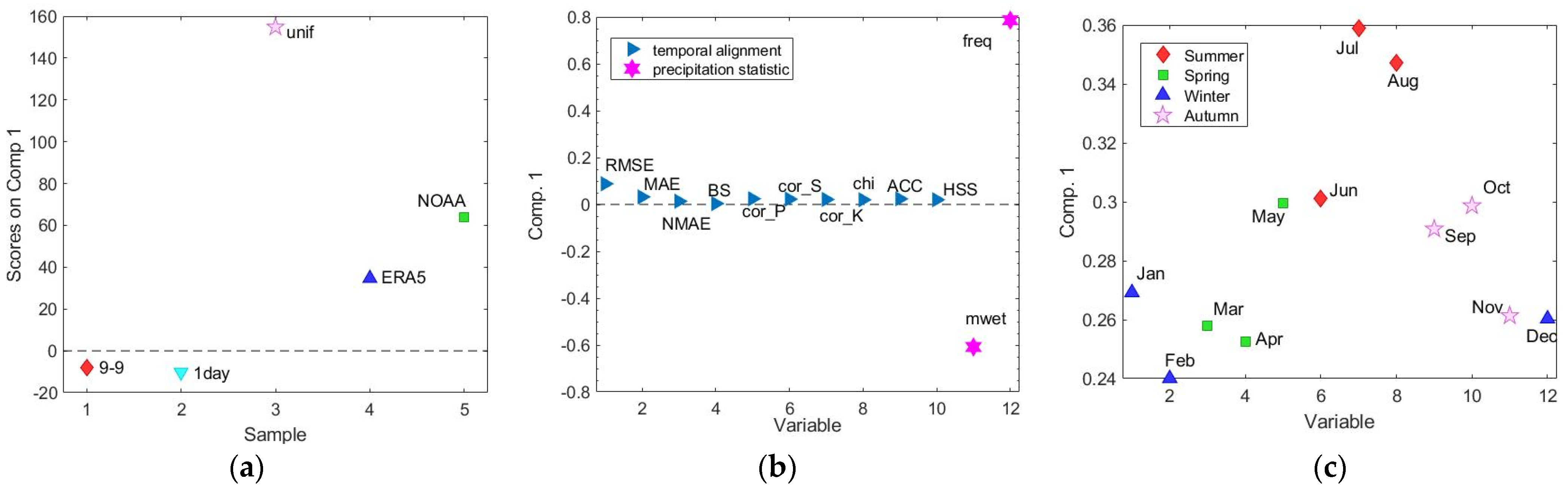
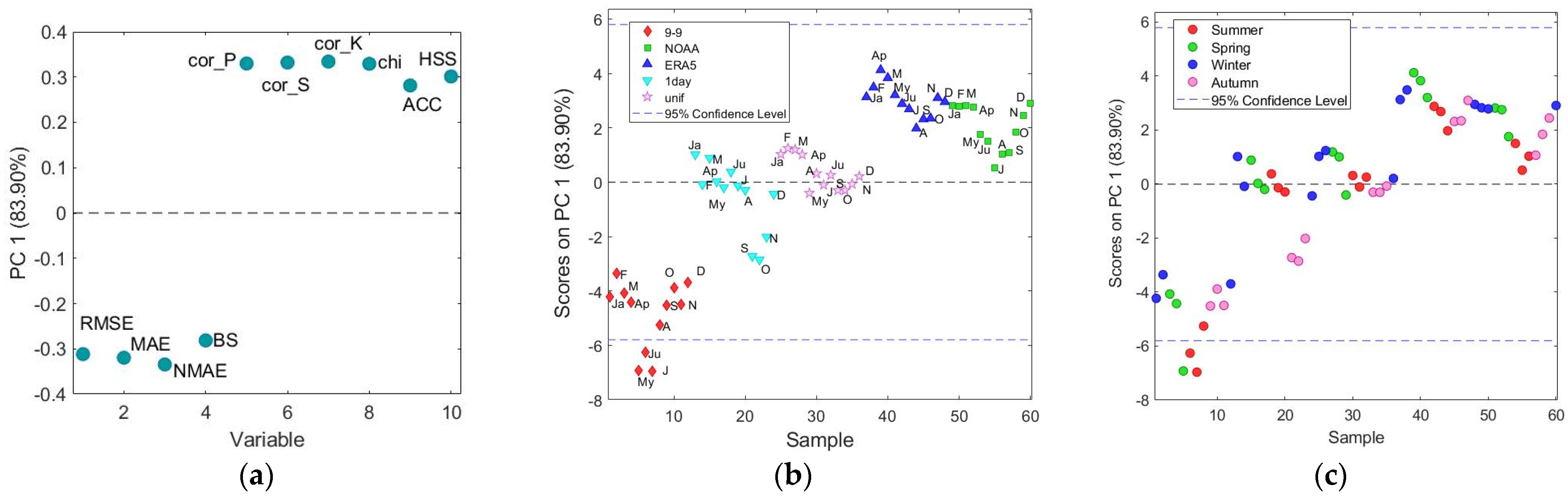
2.6. Multivariate Approach
3. Results
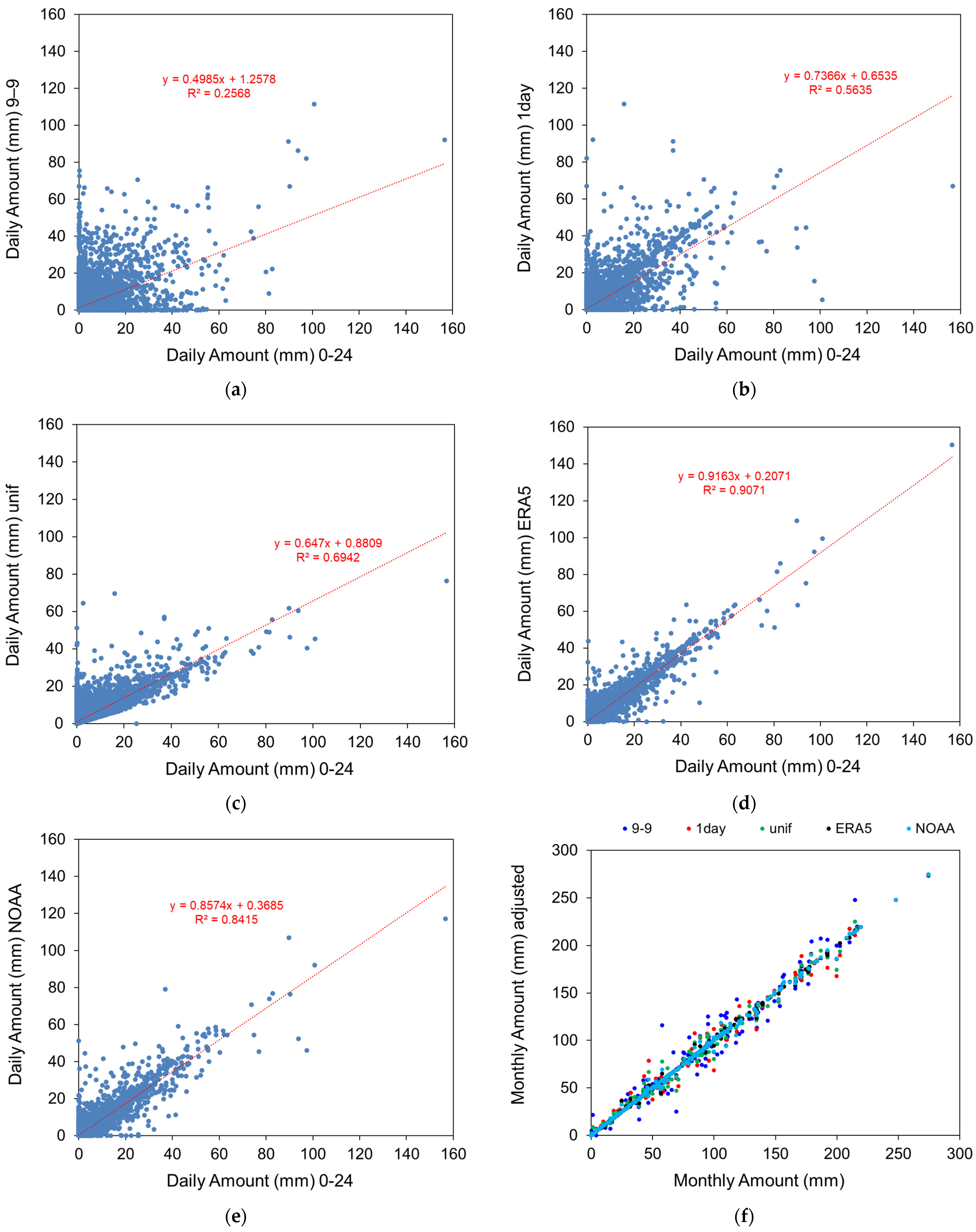
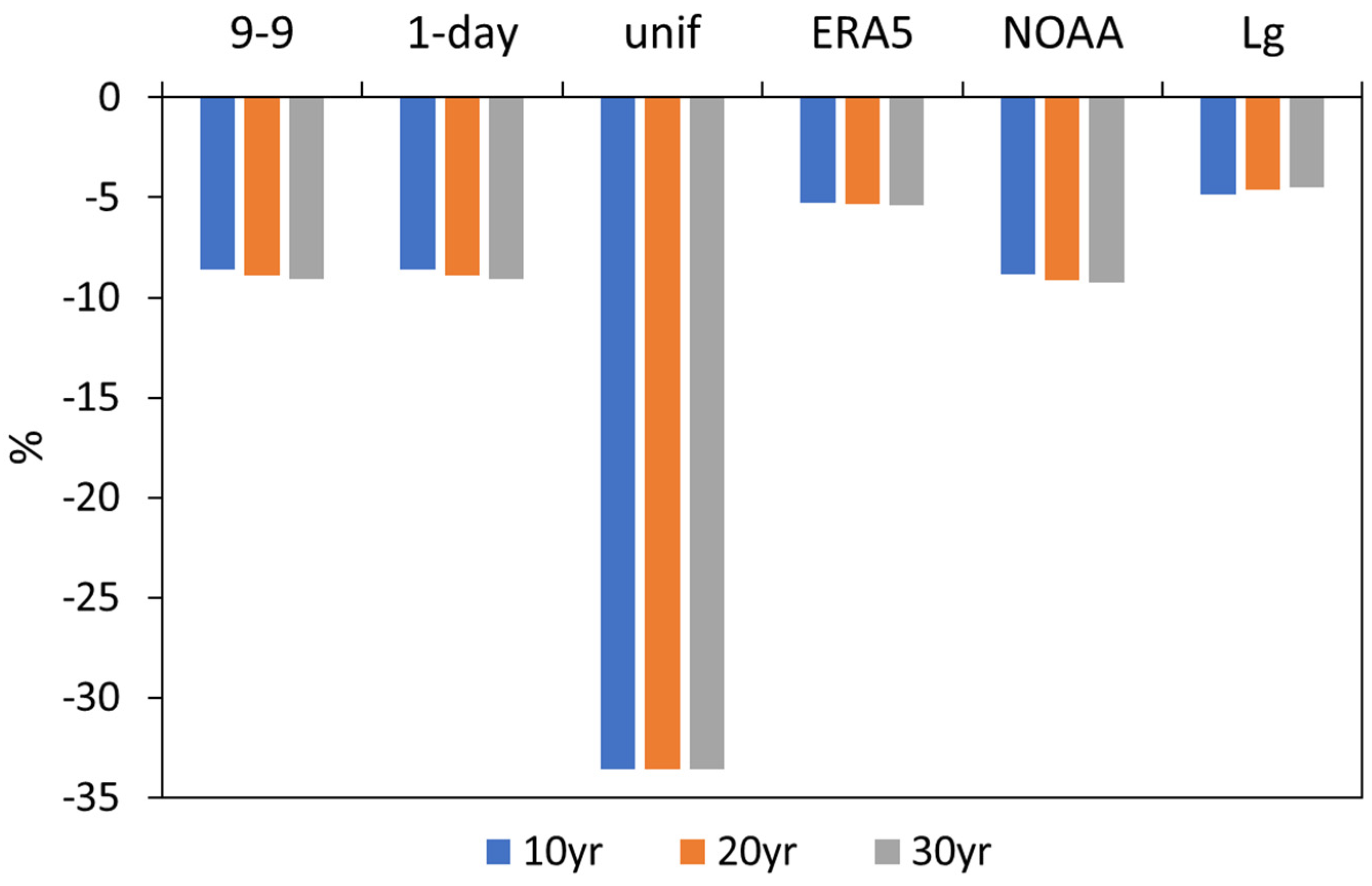
3.1. Comparison between Methods at Daily Resolution
3.2. Comparison between Methods and Stations at Daily Resolution
3.3. Monthly Analysis
3.4. Percentiles Distribution
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Coll, J.; Domonkos, P.; Guijarro, J.; Curley, M.; Rustemeier, E.; Aguilar, E.; Walsh, S.; Sweeney, J. Application of homogenization methods for Ireland’s monthly precipitation records: Comparison of break detection results. Int. J. Climatol. 2020, 40, 6169–6188. [Google Scholar] [CrossRef] [PubMed]
- Cristiano, E.; ten Veldhuis, M.-C.; van de Giesen, N. Spatial and temporal variability of rainfall and their effects on hydrological response in urban areas—A review. Hydrol. Earth Syst. Sci. 2017, 21, 3859–3878. [Google Scholar] [CrossRef]
- Hutchinson, M.F.; McKenney, D.W.; Lawrence, K.; Pedlar, J.H.; Hopkinson, R.F.; Milewska, E.; Papadopol, P. Development and Testing of Canada-Wide Interpolated Spatial Models of Daily Minimum–Maximum Temperature and Precipitation for 1961–2003. J. Appl. Meteorol. Climatol. 2009, 48, 725–741. [Google Scholar] [CrossRef]
- Werner, A.T.; Schnorbus, M.A.; Shrestha, R.R.; Cannon, A.J.; Zwiers, F.W.; Dayon, G.; Anslow, F. A long-term, temporally consistent, gridded daily meteorological dataset for northwestern North America. Sci. Data 2019, 6, 180299. [Google Scholar] [CrossRef] [PubMed]
- Poschlod, B.; Ludwig, R.; Sillmann, J. Ten-year return levels of sub-daily extreme precipitation over Europe. Earth Syst. Sci. Data 2021, 13, 983–1003. [Google Scholar] [CrossRef]
- Camuffo, D.; Becherini, F.; della Valle, A.; Zanini, V. Three centuries of daily precipitation in Padua, Italy, 1713–2018: History, relocations, gaps, homogeneity and raw data. Clim. Change 2020, 162, 923–942. [Google Scholar] [CrossRef]
- Morbidelli, R.; Saltalippi, C.; Dari, J.; Flammini, A. A Review on Rainfall Data Resolution and Its Role in the Hydrological Practice. Water 2021, 13, 1012. [Google Scholar] [CrossRef]
- Daly, C.; Doggett, M.K.; Smith, J.I.; Olson, K.V.; Halbleib, M.D.; Zlatko Dimcovic, Z.; Keon, D.; Loiselle, R.A.; Steinberg, B.; Ryan, A.D.; et al. Challenges in Observation-Based Mapping of Daily Precipitation across the Conterminous United States. J. Atmos. Ocean. Technol. 2021, 38, 1979–1992. [Google Scholar] [CrossRef]
- Guidelines on the Calculation of Climate Normal (WMO-No. 1203). Available online: https://library.wmo.int/records/item/55797-wmo-guidelines-on-the-calculation-of-climate-normals (accessed on 1 March 2024).
- Guidelines on the Definition and Characterization of Extreme Weather and Climate Event (WMO-No. 1310). Available online: https://library.wmo.int/records/item/58396-guidelines-on-the-definition-and-characterization-of-extreme-weather-and-climate-events (accessed on 5 July 2023).
- della Valle, A.; Camuffo, D.; Becherini, F.; Zanini, V. Recovering, correcting and reconstructing precipitation data affected by gaps and irregular readings: The Padua series from 1812 to 1864. Clim. Change 2023, 176, 9. [Google Scholar] [CrossRef]
- Camuffo, D.; Becherini, F.; della Valle, A.; Zanini, V. A comparison between different methods to fill gaps in early precipitation series. Environ. Earth Sci. 2022, 81, 345. [Google Scholar] [CrossRef]
- Holder, C.; Boyles, R.; Syed, A.; Niyogi, D.; Raman, S. Comparison of collocated automated (NCECONet) and manual (COOP) climate observations in North Carolina. J. Atmos. Ocean. Technol. 2006, 23, 671–682. [Google Scholar] [CrossRef]
- Oyler, J.W.; Nicholas, R.E. Time of observation adjustments to daily station precipitation may introduce undesired statistical issues. Int. J. Climatol. 2018, 38 (Suppl. S1), e364–e377. [Google Scholar] [CrossRef]
- Maurer, E.P.; Wood, A.W.; Adam, J.C.; Lettenmaier, D.P.; Nijssen, B. A Long-Term Hydrologically Based Dataset of Land Surface Fluxes and States for the Conterminous United States. J. Clim. 2002, 15, 3237–3251. [Google Scholar] [CrossRef]
- Kim, J.W.; Pachepsky, Y.A. Reconstructing missing daily precipitation data using regression trees and artificial neural networks for SWAT streamflow simulation. J. Hydrol. 2010, 394, 305–314. [Google Scholar] [CrossRef]
- Buishand, T.A. Some Methods for Testing the Homogeneity of Rainfall Records. J. Hydrol. 1982, 58, 11–27. [Google Scholar] [CrossRef]
- Pettitt, A.N. A Non-Parametric Approach to the Change-Point Detection. Appl. Stat. 1979, 28, 126–135. [Google Scholar] [CrossRef]
- von Neumann, J. Distribution of the Ratio of the Mean Square Successive Difference to the Variance. Ann. Math. Stat. 1941, 13, 367–395. [Google Scholar] [CrossRef]
- Peterson, T.C.; Easterling, D.R.; Karl, T.R.; Groisman, P.; Nicholls, N.; Plummer, N.; Torok, S.; Auer, I.; Boehm, R.; Gullett, D.; et al. Homogeneity Adjustments of in Situ Atmospheric Climate Data: A Review. Int. J. Climatol. 1998, 18, 1493–1517. [Google Scholar] [CrossRef]
- Yozgatligil, C.; Yazici, C. Comparison of homogeneity tests for temperature using a simulation study. Int. J. Climatol. 2016, 36, 62–81. [Google Scholar] [CrossRef]
- Guide to Climatological Practices (WMO-No. 100). Available online: https://library.wmo.int/records/item/60113-guide-to-climatological-practices (accessed on 1 March 2024).
- User’s Guide of the Climatol R Package (Version 4). Available online: https://www.climatol.eu/climatol4-en.pdf (accessed on 25 July 2023).
- Kuya, E.K.; Gjelten, H.M.; Tveito, O.E. Homogenization of Norwegian monthly precipitation series for the period 1961–2018. Adv. Sci. Res. 2022, 19, 73–80. [Google Scholar] [CrossRef]
- Alexandersson, H. A Homogeneity Test Applied to Precipitation Test. J. Climatol. 1986, 6, 661–675. [Google Scholar] [CrossRef]
- Hawkins, M. Testing a sequence of observations for a shift in location. J. Am. Stat. Assoc. 1977, 72, 180–186. [Google Scholar] [CrossRef]
- Camuffo, D.; della Valle, A.; Becherini, F. How the rain-gauge threshold affects the precipitation frequency and amount. Clim. Change 2022, 170, 7. [Google Scholar] [CrossRef]
- Strumenti e Criteri di Osservazione e di Gestione Dei Dati. La Serie Pluviometrica 1984–2010 Dell’arpav. Available online: https://www.arpa.veneto.it/temi-ambientali/agrometeo/file-e-allegati/atlante-precipitazioni/20_strumenti-e-criteri-di-osservazione-e-di-gestione-dei-dati---la-serie-pluviometrica-1984-2010-dell2019arpav.pdf/@@display-file/file (accessed on 1 March 2024).
- ERA5 Hourly Data on Single Levels from 1940 to Present. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/10.24381/cds.adbb2d47 (accessed on 7 March 2023).
- NOAA/CIRES/DOE 20th Century Reanalysis (V3). Available online: https://www.psl.noaa.gov/data/gridded/data.20thC_ReanV3.html (accessed on 7 March 2023).
- Pfister, L.; Brönnimann, S.; Schwander, M.; Isotta, F.A.; Horton, P.; Rohr, C. Statistical reconstruction of daily precipitation and temperature fields in Switzerland back to 1864. Clim. Past 2020, 16, 663–678. [Google Scholar] [CrossRef]
- Weller, G.B.; Cooley, D.S.; Sain, S.R. An investigation of the pineapple express phenomenon via bivariate extreme value theory. Environmetrics 2012, 23, 420–439. [Google Scholar] [CrossRef]
- Gilleland, E.; Katz, R.W. extRemes 2.0: An Extreme Value Analysis Package in R. J. Stat. Soft. 2016, 72, 1–39. [Google Scholar] [CrossRef]
- Ting, K.M. Confusion Matrix. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011; p. 209. [Google Scholar]
- confusionMatrix: Create a Confusion Matrix. Available online: https://rdrr.io/cran/caret/man/confusionMatrix.html (accessed on 7 March 2023).
- Aguilera, H.; Guardiola-Albert, C.; Serrano-Hidalgo, C. Estimating extremely large amounts of missing precipitation data. J. Hydroinform. 2020, 22, 578–592. [Google Scholar] [CrossRef]
- Bellido-Jiménez, J.A.; Gualda, J.E.; García-Marín, A.P. Assessing machine learning models for gap filling daily rainfall series in a semiarid region of Spain. Atmosphere 2021, 1, 1158. [Google Scholar] [CrossRef]
- Longman, R.J.; Newman, A.J.; Giambelluca, T.W.; Lucas, M. Characterizing the uncertainty and assessing the value of gap-filled daily rainfall data in Hawaii. J. Appl. Meteorol. Climatol. 2020, 59, 1261–1276. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Bro, R.; Andersson, C.A.; Kiers, H.A.L. N-way principal component analysis theory, algorithm and applications. J. Chemom. 1999, 13, 295–309. [Google Scholar] [CrossRef]
- Bro, R. PARAFAC. Tutorial and applications. Chemom. Intell. Lab. Syst. 1997, 38, 149–171. [Google Scholar] [CrossRef]
- Bro, R.; Smilde, A.K. Centering and scaling in component analysis. J. Chemom. 2003, 17, 16–33. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis (Springer Series in Statistics), 2nd ed.; Springer: New York, NY, USA, 2002; pp. 1–488. [Google Scholar]
- Camuffo, D.; Becherini, F.; della Valle, A. Relationship between selected percentiles and return periods of extreme events. Acta Geophys. 2020, 68, 4. [Google Scholar] [CrossRef]
- Hersbach, H.P.; de Rosnay, B.; Bell, D.; Schepers, A.; Simmons, C.; Soci, S.; Abdalla, M.; Alonso Balmaseda, G.; Balsamo, P.; Bechtold, P.; et al. Operational Global Reanalysis: Progress, Future directions and Synergies with NWP, ECMWF ERA Report Series 27. 2018. Available online: https://www.ecmwf.int/sites/default/files/elibrary/2018/18765-operational-global-reanalysis-progress-future-directions-and-synergies-nwp.pdf (accessed on 17 February 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Acronym | Elevation (m a.g.l.) | Lat | Long | Distance from OB (km) | Data Availability |
|---|---|---|---|---|---|---|
| Orto Botanico | Pd | 12 | 45.40 | 11.88 | 0 | October 1993–December 2022 (97.1%) |
| Padova CUS | 12 | 45.40 | 11.91 | 2.3 | ||
| Legnaro | Lg | 7 | 45.35 | 11.95 | 8.0 | January 1993–December 2022 (99.5%) |
| Campodarsego | Cm | 16 | 45.49 | 11.91 | 11.0 | January 1993–December 2022 (99.1%) |
| Codevigo | Cd | 0 | 45.24 | 12.10 | 24.4 | January 1993–December 2022 (99.4%) |
| Mira | Mr | 3 | 45.44 | 12.12 | 19.0 | January 1993–December 2022 (99.4%) |
| Tribano | Tr | 3 | 45.19 | 11.85 | 23.8 | January 1996–December 2022 (99.0%) |
| Name | Short Name | Formula | Range Values |
|---|---|---|---|
| Root-Mean-Square Error | RMSE | ≥0 (ideal) | |
| Mean Absolute Error | MAE | ≥0 (ideal) | |
| Normalized Mean Absolute Error | NMAE | ≥0 (ideal) | |
| Brier Score | BS | 0 (ideal)-–1 | |
| Pearson’s correlation coefficient | cor_P | 0–1 (ideal) | |
| Spearman’s rank correlation | cor_S | 0–1 (ideal) | |
| Kendall’s rank correlation | cor_K | 0–1 (ideal) | |
| Tail dependence measure | χ(u = 0.95) | P( > u| > u) | 0–1 (ideal) |
| Accuracy | ACC | 0–1 (ideal) | |
| Heidke Skill Score | HSS | ≤1 (ideal) |
| Name | Short Name | Formula | Range Values |
|---|---|---|---|
| mean precipitation value over wet days | mwet | ≥−100% (0 ideal) | |
| frequency of wet days | freq | ≥−100% (0 ideal) |
| Adjustment Method | R2 | RMSE (mm) |
|---|---|---|
| 9–9 | 0.979 | 7.9 |
| 1–day | 0.991 | 5.2 |
| unif | 0.994 | 4.2 |
| ERA5 | 0.998 | 2.3 |
| NOAA | 0.997 | 2.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Becherini, F.; Stefanini, C.; della Valle, A.; Rech, F.; Zecchini, F.; Camuffo, D. Adjustment Methods Applied to Precipitation Series with Different Starting Times of the Observation Day. Atmosphere 2024, 15, 412. https://doi.org/10.3390/atmos15040412
Becherini F, Stefanini C, della Valle A, Rech F, Zecchini F, Camuffo D. Adjustment Methods Applied to Precipitation Series with Different Starting Times of the Observation Day. Atmosphere. 2024; 15(4):412. https://doi.org/10.3390/atmos15040412
Chicago/Turabian StyleBecherini, Francesca, Claudio Stefanini, Antonio della Valle, Francesco Rech, Fabio Zecchini, and Dario Camuffo. 2024. "Adjustment Methods Applied to Precipitation Series with Different Starting Times of the Observation Day" Atmosphere 15, no. 4: 412. https://doi.org/10.3390/atmos15040412
APA StyleBecherini, F., Stefanini, C., della Valle, A., Rech, F., Zecchini, F., & Camuffo, D. (2024). Adjustment Methods Applied to Precipitation Series with Different Starting Times of the Observation Day. Atmosphere, 15(4), 412. https://doi.org/10.3390/atmos15040412