1. Introduction
Trend analysis tools, both parametric and nonparametric, are very helpful in understanding climate change in hydrologic and atmospheric research. In contrast to non-parametric trend tests (for e.g., Mann–Kendall test and Spearman’s rho test), parametric tests (e.g., generalized least-square method) are more efficient [
1] but require independent and Gaussian distributed datasets. Nonparametric trend tests, on the other hand, only assume data independence, can tolerate outliers [
2] and deviations from the Gaussian distribution in the data [
3], and are more suitable for atmospheric measurements [
4].
The Mann–Kendall (MK) test is a very widely used distribution-free test proposed by [
5,
6], based on the rank correlation between the observed value and their respective observed time. Even though the MK test is fairly efficient and robust, it still requires the data to be independent [
7], which is why the MK statistics are based on the widely accepted presumption that the data are serially uncorrelated. Unfortunately, most of the atmospheric time series do not meet this condition of serial independence and may possess multiple orders of autocorrelation [
8]. Several previous studies [
8,
9,
10,
11] reported that autocorrelation in the time series increases the probability of rejecting the null hypothesis even if there is no statistical trend. Refs. [
1,
12] also found that positive autocorrelation tends to inflate the variance of the MK statistic, increases the Type-I errors, and may lead to the false positive outcome. Conversely, negative autocorrelation can deflate the variance of the test statistic, potentially reducing the power to detect trends. Therefore, it is crucial to consider and address autocorrelation when analyzing trends in time series data to ensure accurate and reliable results.
To mitigate the influence of serial correlation on trend analysis, one prominent technique known as ‘prewhitening’ is generally applied, which removes autocorrelation from datasets. assuming a certain correlation model, typically the lag-1 autoregressive (AR(1)) model [
8]. The Effective Sample Size (ESS) is another approach that accounts for the autocorrelation by computing the effective size of samples. Hamed and Ramachandra Rao [
1] provided an empirical formula for computing the ESS that modifies the variance of the MK test to eliminate the effect of autocorrelation. Yue et al. [
9] investigated the capability of this variance-corrected approach in removing the lag-1 autocorrelation from the data. He found that the approach can remove the lag-1 autocorrelation significantly, but the Type-I error after correction was still much higher than the significance level of the test. On the other hand, von Storch [
8] and Yue and Wang [
10] showed that AR(1) model is quite capable of removing the lag-1 autocorrelation from the data, which is why the PW technique is one of the most popular techniques in removing the autocorrelation from the atmospheric and hydrological datasets. Although, for the time series with time granularity ≤3 months, the seasonal correlation would affect the efficiency of the AR(1) model. However, employing seasonal MK (or MK test on deseasonalized data) is quite useful in mitigating the negative effect of seasonality in trend detection. Numerous AR(1) model-based PW schemes [
8,
9,
11,
13] have been proposed to nullify the influence of autocorrelation in the MK statistics.
In the present work, we propose a new PW scheme based on the AR(1) process. The main objectives of this study are (i) to understand the sensitivity of serial autocorrelation with the exiting trend in the time series; (ii) to examine the effects of various prewhitening schemes on the statistical significance of MK test and the magnitude of Sen’s slope; (iii) to examine and compare the performance of various prewhitening schemes in relation to the sample size, lag-1 autocorrelation, and the existing trend in the time series.
2. Materials and Methods
2.1. The Mann–Kendall Test with Sen’s Slope
The MK test, a rank-based statistical approach, is widely used to check any monotonic upward or downward trend in the time series of interest [
5,
6,
14]. It is a nonparametric test, which means it does not require distributional assumptions. The MK test is very useful in atmospheric studies, where most atmospheric measurements deviate from the Gaussian distribution. The MK test for a time series y
k {k = 1, 2, …, n} of length ‘n’ is computed mathematically as follows [
14]:
where,
If n ≤ 10, the exact S statistic is applied using the probability table available in Gilbert [
14] (Table A18, page 272). For n > 10, the MK standardized test statistic (Z
MK) is computed using the variance of S (Var(S)) as follows:
in the presence of ties in the data, the Var(S) is modified as:
where p is the total number of tied groups in the dataset, and q
k is the number of data points contained in the kth tied group.
The positive (negative) refers to a monotonic upward (downward) trend. The MK test is used to test the null hypothesis (H
0) of no trend against the alternative hypothesis (H
1) of the presence of the monotonic trend. The significance of any trend with significance level α is tested by a two-tailed test. If |Z
MK| ≥ Z
1-α/2, the H
0 is rejected, and H
1 is accepted. For a significant trend, Sen’s slope [
15] can be used to estimate the slope as follows:
The MK test is based on the assumption that observations are serially independent over time, even though the majority of the atmospheric measurements contain positive autocorrelation. Many previous studies [
1,
9,
10,
11,
13,
16,
17] have shown that the positive autocorrelation in the time series significantly increases the Type-I error and thus increases the probability of a false positive outcome. Therefore, to achieve robust test results, there should be no autocorrelation in the time series.
2.2. The Prewhitening Methods
The first prewhitening method was proposed by von Storch [
8] (referred to as PW-S), which basically removes the lag-1 autocorrelation (ρ
1) from the original data Y at the time t:
This PW method results in a low number of Type-I errors and only works well when there is no trend in the time series [
9,
10]. If any trend exists in the time series, this method will erase a considerable portion of the existing trend and reduce the power of the MK test.
To handle this problem, ref. [
9] suggested the removal of AR(1) process on the detrended time series with steps as: (i) estimating Sen’s slope (β
Y) on the original data; (ii) removing the trend to generate a trend free (detrended) time series A
tTF (Equation (8)); (iii) removing the lag-1 autocorrelation ρ
1 on A
tTF to obtain a trend-free prewhitened time series A
tTFPW (Equation (9)); and (iv) adding the trend back in to generate the Yue’s trend-free prewhitened time series Y
tTFPW (Equation (10)):
This approach recovers the power of test at the cost of increased number of false positive cases.
During that time, ref. [
13] proposed an iterative TFPW (TFPW-WS) applied the MK test on the prewhitened series with a correction factor of (1-ρ
1)
−1 for the unbiased calculation of slope. This correction factor is also applied in another prewhitening (known as TFPW-Cor) to preserve the same trend between the original and prewhitened time series. TFPW-WS method restores the Type-I error without compromising the power of the test and sustains the same trend as the original time series. However, the main hurdle in detecting trends in the real-time series data is that the trend and the serial correlation are interconnected, and thus the presence of one parameter alters the estimation of the other parameter [
9], which is why the MK test on the original time series with positive autocorrelation tends to overestimate the trend. The previously mentioned PW methods failed to reduce the high variance of slope estimators caused by the serial correlation.
The authors of [
11] proposed a variance-corrected TFPW (VCTFPW) approach to address this problem. This method corrects both the serial and slope variances and provides unbiased slope estimates at the expense of medium Type-I and -II errors.
2.3. A New Joint PW Algorithm
In the previous section, the advantages and disadvantages of various existing prewhitening methods were described. The Storch PW method (also known as PW) has low Type-I error, but it removes a significant portion of the trend and can cause false negative results. The TFPW-Y method is quite the opposite of the PW approach—it increases the power of the test at the cost of the Type-I error and therefore enhances the probability of false positive outcomes.
TFPW-WS keeps low Type-I errors and high test power but lacks the ability to estimate the actual trend. On the other hand, the VCTFPW approach works well for unbiased slope estimation but cannot restore the low Type-I and Type-II errors [
4]. In this study, we propose a new algorithm (Joint-PW) that involves the PW, TFPW-Y, TFPW-WS, and VCTFPW methods and contains the benefits of all approaches. The procedure of the Joint-PW method is as follows.
Step 1: To estimate the effect of correlation, we first calculate that partial correlation for lag = 1, 2, …, 20 of the time series (Y
t) and confirm that autocorrelations at lag > 1 are not significant at 95% confidence level. If the lag-1 autocorrelation (ρ
1) is negligible (<0.05) [
4], we do not apply any prewhitened scheme and use the MK test on the original time series. Otherwise, the ρ
1 is removed from the original time series, and its slope is corrected to obtain a trend-corrected prewhitened time series Y
tPW-Cor following [
13] as:
Step 2: Estimate the Sen’s slope on the Y
tPW-Cor time series β
1PW and remove that slope from the original time series to obtain the corrected prewhitened trend free time series Y
tTF-Cor as follows:
Step 3: We replace the original time series with YtTF-Cor and repeat steps 1 and 2 until the difference between ρ1 as well as β1PW of the two successive iterations becomes less than 0.001. Suppose that after n iterations, ρ1n−1 − ρ1n < 0.001 and β1PW,n−1 − β1PW,n < 0.001, we stop the further iteration process and use YtPW-Cor,n as YtPW for further processing.
Step 4: Detrend the Y
tPW series to obtain the processed trend-free prewhitened series Y
tTFPW as:
Step 5: Previous publications have reported that all PW approaches greatly increase the variance of the time series. To correct the variance of transformed PW series for lag-1 autocorrelation, ref. [
12] calculate the limiting values of variance inflation factor (VIF) for an infinite sample size (Equation (14)) and correct the trend estimate (Equation (15)) as follows:
For the original time series, the modified slope estimator is:
Step 6: Add the corrected slope estimator of the original time series (β
Mod) to the Y
tTFPW data, and we will obtain the detrended prewhitened with modified trend added (DPWMT) time series for the trend analysis:
2.4. Monte Carlo Simulation
To understand the performance of the new method in comparison to previous PW schemes, we construct various linear trend superimposed (β) AR(1) time series (Y
t) with lag-1 autocorrelation (ρ
1) using the Monte Carlo simulation as follows:
where μ
A = mean of A
t and ξ
t = white noise series following normal distribution with mean μ
ξ = 0 and variance σ
ξ2 = 1.
The simulation generated N = 5000 time series of AR(1) processes with μA = 1 and σA = 0.25 for each sample size n = 20 (+10) + 100 with different given ρ1 = 0 (+0.1) + 0.9. Then, a trend with slope β = 0.00 (±0.001) ± 0.01 is superimposed onto each of the generated series.
The two-tailed rejection ratio for each prewhitening method can be calculated by:
where N = 5000 is the total number of AR(1) simulated time series, and N
rej is the number of series for which the null hypothesis of assuming the nonexistence of trend is rejected by the test. To assess the accuracy of the estimators, root-mean-square errors (RMSEs) are employed, defined as
, where β′ is the slope estimated from PWs, providing a measure of the combined squared bias and variance of the estimators.
3. Results and Discussion
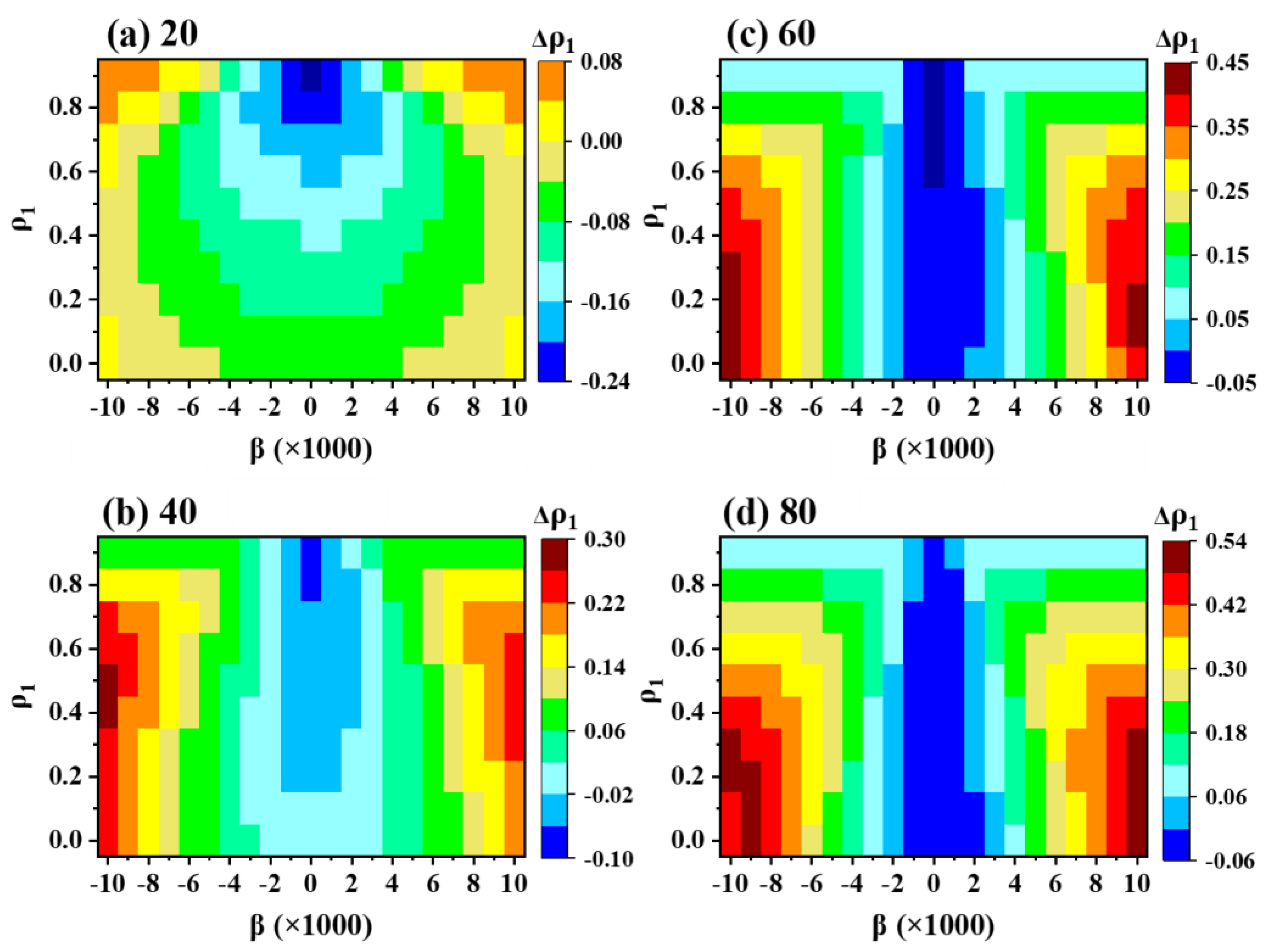
3.1. Effect of Trend on the Autocorrelation
Figure 1 demonstrates the relationship between the trend and the lag-1 autocorrelation (∆ρ
1 = ρ
T − ρ
1; where ρ
T represents the lag-1 autocorrelation after incorporating the trend in the AR(1) series). The findings indicate that weak trends (less than 0.003) have a minimal impact on ρ
1. However, a medium-to-strong trend exhibits a notable impact on ρ
1. The significance of this effect varies depending on the sample size, with a more pronounced impact observed in larger series.
For small samples, the effect of a strong trend on ρ1 is not particularly significant. However, as the series size increases, the influence becomes considerably more prominent. In the case of medium ρ1 values (ranging from 0.3 to 0.6), a strong trend (β > 0.006) leads to an almost twofold increase in the lag-1 autocorrelation. Furthermore, for low ρ1 values (ranging from 0.0 to 0.3), the inclusion of a strong trend results in ρ1 shifting to the upper medium range (0.4 to 0.6).
It is worth noting that when examining detrended data that already exhibited a high level of correlation (greater than 0.8), the resulting ρT values were very high (>0.95). The instances where ρ1 = 0.9 and ρT surpassed 0.98 for medium to high trends highlight a potential challenge for trend analysis using the Mann–Kendall (MK) statistic, even after prewhitening the time series.
Figure 1 highlights the sensitivity and complexity of the lag-1 autocorrelation to both the magnitude of the trend and the length of the time series, and derive a definitive empirical formula to precisely remove the effect of autocorrelation in such cases is very challenging.
3.2. Performance of Prewhitening Schemes
3.2.1. Slope Estimation
Figure 2 presents the Sen’s slope estimated using different prewhitening (PW) methods. It is observed that at weak trends, none of the mentioned time series is able to accurately reproduce the actual slope value. Instead, they tend to overestimate the trend, especially when the sample size is small. This overestimation is a result of errors introduced by the series due to the combination of small trends (β = 0.002) and limited sample size (n = 30).
As the actual trend of the series increases, the performance of all PW methods improves as the rejection rate increases. For series with moderate to high trends and a sufficient sample length (β ≥ 0.006 and n ≥ 60), the slopes estimated from the original (ORG), VCTFPW, and DPWMT series are close (within a ±20% range) to the actual trend. However, PW-S struggles to maintain the actual trend when confronted with high serial autocorrelation, resulting in a significant underestimation of the slope due to the loss of prominent trends during the ρ1 removal process.
PW-Cor preserves the trend of the original series until ρ
1 > 0.5, after which it begins to deviate as the serial correlation increases. TFPW-WS follows a similar pattern to PW-Cor but exhibits extraordinary divergence at ρ
1 ≥ 0.7. To maintain the figure scale, this pronounced deviation is depicted separately (see
Figure 3).
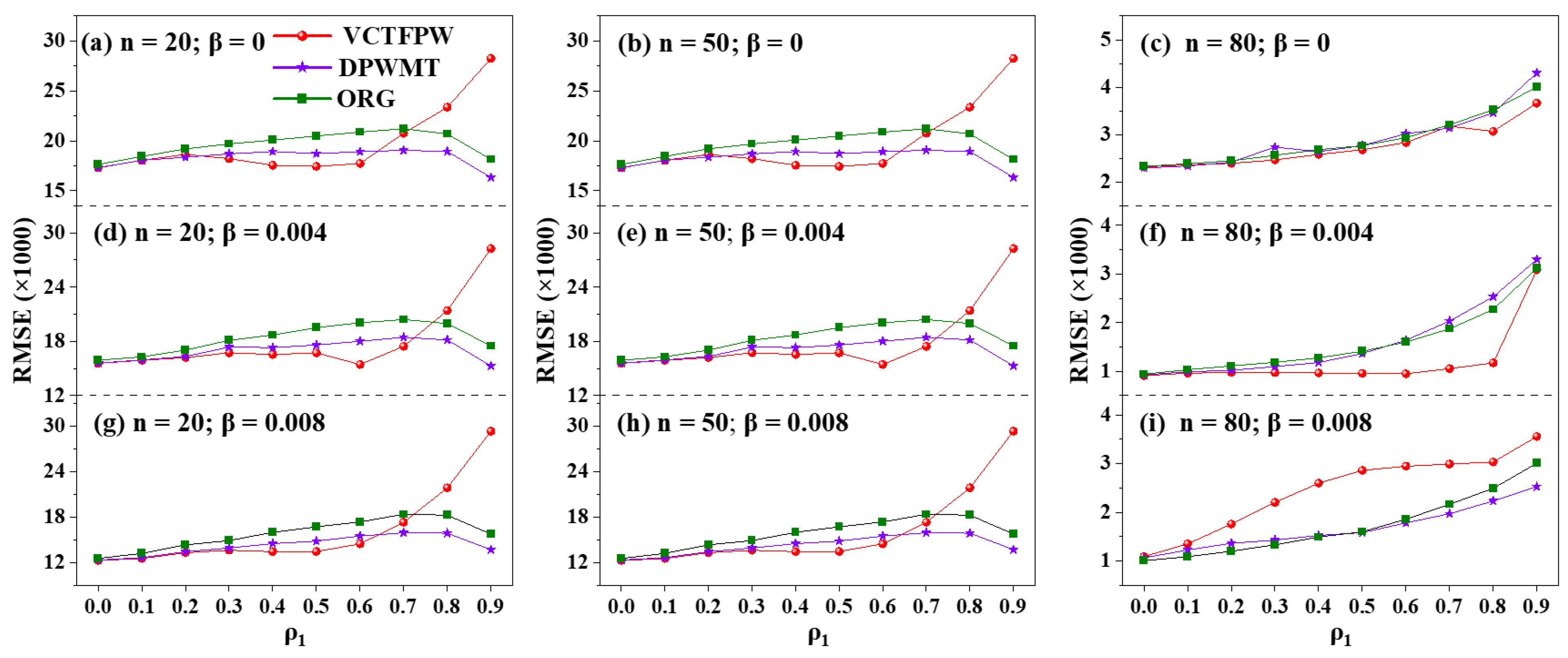
Figure 3 showcases the RMSE calculated from the TFPW-WS slope estimator. The RMSE remains relatively low for TFPW-WS when the lag-1 autocorrelation is low (ρ
1 > 0.5). However, the error escalates exponentially as ρ
1 increases. This divergence in slope estimation is particularly pronounced in series with limited sample sizes, potentially stemming from the iterative process of TFPW-WS on highly correlated data. Consequently, a sufficiently large sample size is necessary to mitigate this issue.
Figure 4 compares the root-mean-square error (RMSE) of the three slope estimators: original series (ORG), VCTFPW, and DPWMT. The results show that VCTFPW performs better than both ORG and DPWMT when the series has moderate lag-1 autocorrelation (ρ
1 between 0.3 and 0.6). However, VCTFPW’s RMSE increases significantly when ρ
1 exceeds 0.6. Conversely, the DPWMT exhibits stable performance across varying levels of ρ
1 and often has a lower RMSE compared to ORG. While VCTFPW yields lower RMSE than DPWMT for mid-range values of lag-1 autocorrelation, the difference is not large enough to outweigh the fluctuations observed in the slope estimation of VCTFPW at mid-high ρ
1.
These fluctuations indicate the underestimation of the slope as ρ
1 increases (as shown in
Figure 2). In addition, it is also noted that the length of the series significantly influences RMSE, with longer time series exhibiting notably lower RMSE compared to shorter ones. This indicates an enhanced accuracy in both the estimated slope (β′) and the actual slope (β) for time series with a large sample size. Overall, the DPWMT time series should be used to estimate the trend of a series to obtain an unbiased slope estimation.
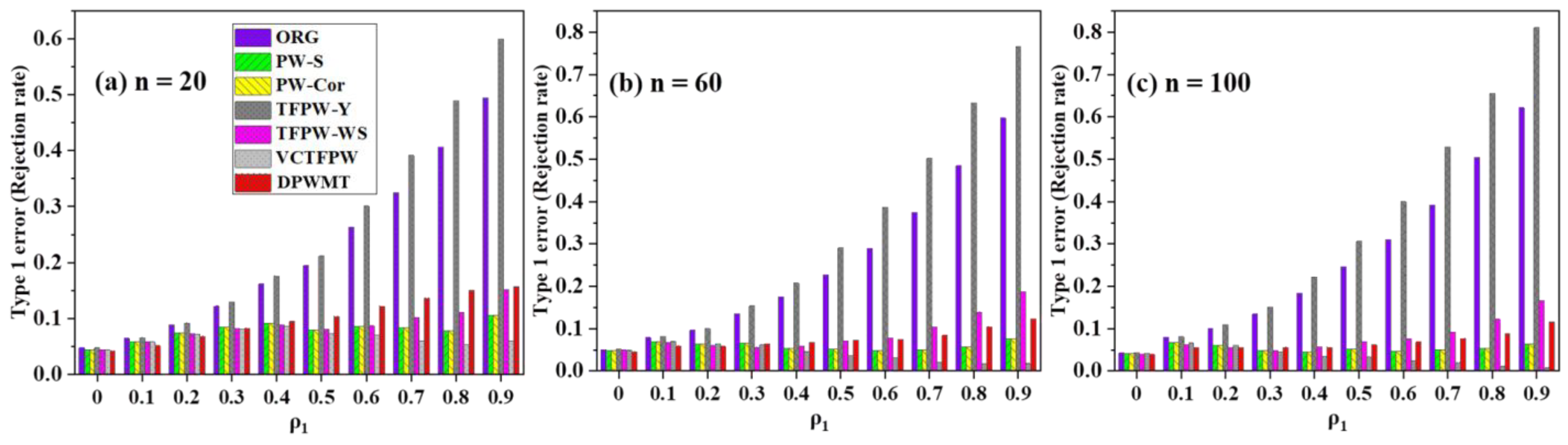
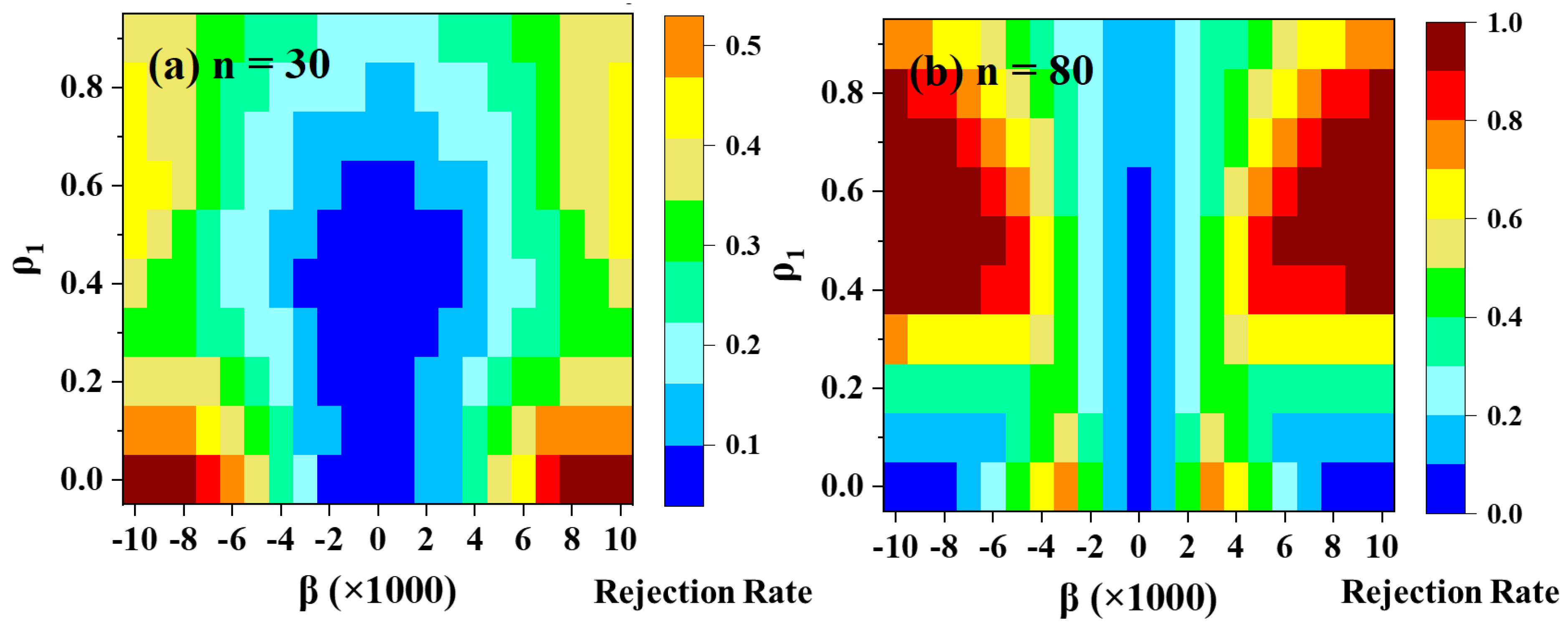
3.2.2. Type-I Error
Figure 5 presents the performance evaluation of different PWs in terms of their ability to reject the null hypothesis that assumes the presence of a statistically significant trend. Among the evaluated methods, all series except the original (ORG) and TFPW-Y demonstrate satisfactory results. However, the ORG and TFPW-Y series are more likely to reject the null hypothesis, leading to false positive results. Both the ORG and TFPW-Y series are particularly sensitive to serial correlation, and their Type-I error rates increase significantly as the lag-1 autocorrelation coefficient rises. This means that these series are more prone to incorrectly detecting a trend when none exists due to the influence of autocorrelation.
PW-S and VCTFPW exhibit Type-I error rates that remain consistently below the significance level (α = 0.05). However, the other prewhitening methods, such as PW-Cor, TFPW-WS, and DPWMT, have Type-I error rates slightly higher than the predetermined significance level for the smaller sample sizes. However, as the sample size increases, the Type-I error rates converge to an acceptable level, suggesting improved performance and better control over false positives with larger datasets.
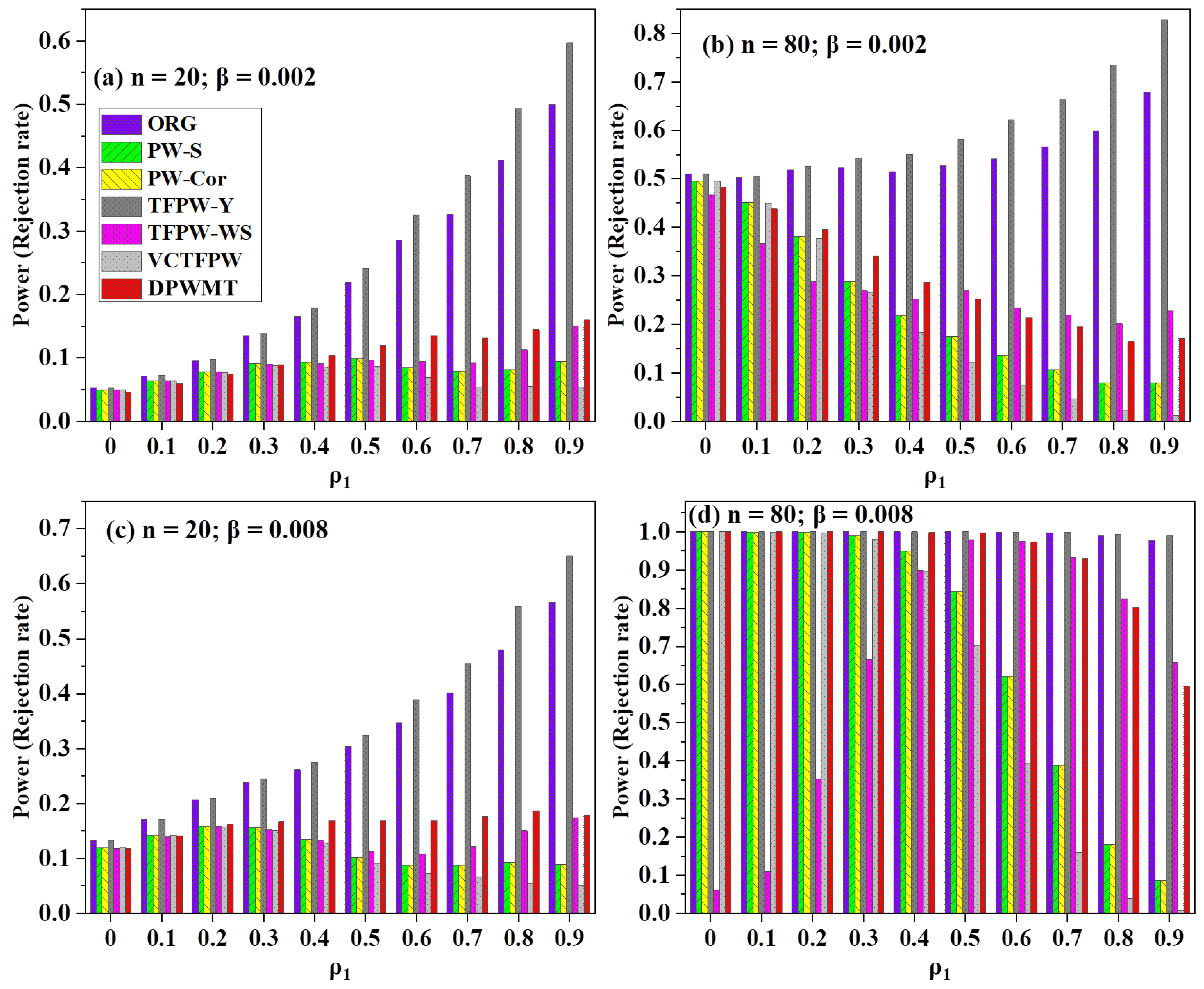
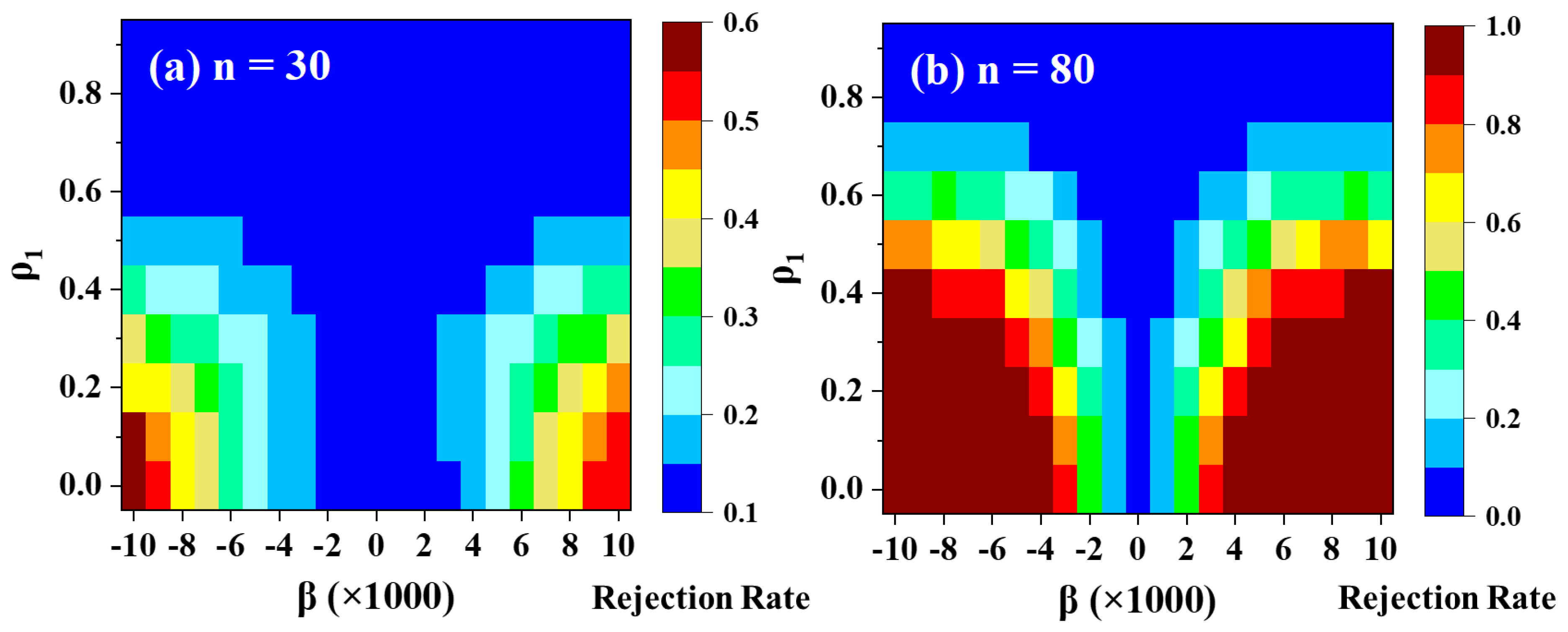
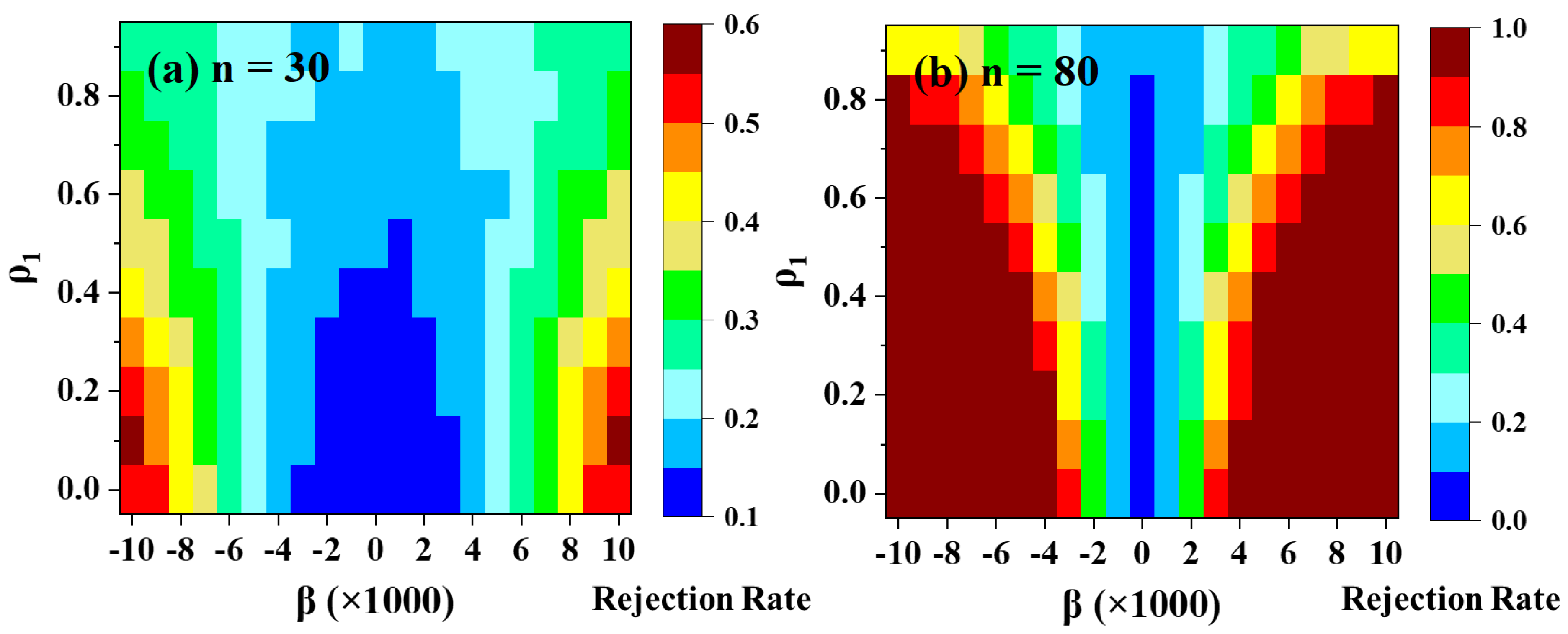
3.2.3. Power of the Test
The statistical powers of different prewhitening (PW) methods in detecting significant trends were assessed (
Figure 6). The results show that the methods varied in their ability to detect trends. The original series (ORG) and TFPW-Y exhibit moderate power at low sample sizes, but their power exhibits considerable fluctuations as the lag-1 autocorrelation (ρ
1) increases, particularly demonstrating reduced power for weak autocorrelated series. Conversely, the remaining PW methods fail to provide sufficient power for weak trend slopes and short time series.
As the sample size increases, all PW methods exhibit a notable improvement in power for weak serial autocorrelation (ρ1) but experience a subsequent decrease in power as ρ1 continues to rise. Notably, the DPWMT and TFPW-WS methods demonstrate relatively higher power retention as the serial correlation increases compared to PW-S, PW-Cor, and VCTFPW. However, for strong trends and longer time series, PW-S, PW-Cor, and VCTFPW struggle to sustain power as ρ1 increases, with power levels dropping to less than 40% at ρ1 ≥ 0.7. In contrast, the new method remains suboptimal but maintains approximately 80% power at ρ1 = 0.8 and around 60% power at ρ1 = 0.9, enabling the detection of the most significant trends.
A detailed analysis of TFPW-WS, VCTFPW, and the new method is presented in
Figure 7,
Figure 8 and
Figure 9, focusing on their performance relative to lag-1 autocorrelation, trend size, and the length of the series. For short time series (n = 30), TFPW-WS and DPWMT exhibit limited power for low trends (β = ±0.001 to ±0.004), gradually improving to moderate power for medium to strong trends (β = ±0.004 to ±0.01). In contrast, VCTFPW demonstrates weak power across the entire range of trends, except for scenarios involving weak lag-1 autocorrelation combined with strong trends.
The behavior of the aforementioned methods in longer time series (n = 80) presents intriguing findings. TFPW-WS displays strong power for medium to high serial correlation (ρ1 > 0.5) in the presence of strong trends yet struggles to maintain power for weak ρ1. Conversely, VCTFPW exhibits a reversed pattern, with higher power observed at low ρ1, gradually diminishing to moderate levels as ρ1 increases. The increased test power of TFPW-WS at ρ1 > 0.5 can be attributed to its divergent behavior at high ρ1, resulting in elevated slope values, as previously discussed. On the other hand, VCTFPW’s failure to restore power at high ρ1 may stem from its tendency to underestimate trend magnitudes for highly autocorrelated samples.
Ultimately, the new method proves superior, consistently maintaining the highest power across the entire range of ρ1 for medium to high trends, making it the recommended approach for unbiased slope estimation and accurate trend detection.
3.3. Case Study
The new PW scheme, along with other PWs, is tested for the particle size distribution and black carbon mass concentration over Mukteshwar (MUK) (29.47° N, 79.6° S; 2.18 km above mean sea level) in India. Further, we analyzed the size distribution data measured at the Pallas-Sodankylä Global Atmosphere Watch (GAW) Station (67.97° N, 24.12° S; 0.56 km above mean sea level) in northern Finland in the subarctic region. The particle size distribution was measured using a differential mobility particle sizer (DMPS assembled by the Finnish Meteorological Institute). The particle number concentrations were calculated in three size bins: nucleation mode N
Nuc (7 to 25 nm particles), Aitken mode N
Ait (25 to 90 nm particles), and accumulation mode N
Acc (90 to 800 nm particles). The black carbon (BC) concentration was calculated using a seven-wavelength aethalometer (Magee Scientific AE-31). The details of the instrument and measurement are available in the previous publications [
18].
To address the seasonality in the data, the seasonal MK test [
19] is utilized for four seasons: winter (December–February); spring (March–May); summer (June–August); and Autumn (September–November). The annual trends were calculated from the average of seasonal trends and considered statically significant (SS) only if the trends of all seasons were homogeneous at a 90% confidence level and SS at a 95% confidence level [
14].
Table 1 summarizes the results of the MK test performed using various prewhitening (PW) techniques. PW-Cor effectively preserves the underlying trend of the original series. TFPW-Y and TFPW-WS exhibit similar patterns to PW-Cor, mainly because the lag-1 autocorrelation is weak in the original time series, as explained in
Section 3.2.1. It is important to note that the low-to-lower-medium lag-1 autocorrelation (ρ1) estimated from the original time series, as presented in
Table 1, does not accurately represent the true serial autocorrelation due to the presence of a trend component in the series, as discussed in detail in
Section 3.1. Therefore, the actual ρ1 values are expected to be considerably lower than the estimates. Furthermore, TFPW-WS may produce unrealistically high estimates for the slope when dealing with datasets containing high serial correlation, as illustrated in
Figure 3. The results in
Table 1 suggest that the VCTFPW and DPWMT tests yield a lower-moderate slope estimator of the trend, which is overestimated and underestimated by the ORG and PW-S tests, respectively. This pattern aligns with findings reported by Wang et al. [
11].
The Z-statistic, an indicator of both Type-I and Type-II errors (test power), has been calculated to assess the performance of the PW schemes. The TFPW-Y yields the largest absolute value of Z followed by the ORG series and thus indicates the highest Type-I error. However, Type-I errors and the power of the test are complementary to each other; therefore, it may be argued that the time series actually consists of an SS trend and that TFPW-Y and ORG have higher test power than high Type-I errors. However, this rationale does not apply when the number of samples used for the MK test is sufficiently large and the ρ
1 is low to medium, resulting in similar powers of the test as found in VCTFPW and DPWMT (See
Figure 6b,d).
The results demonstrate that PW-S exhibits the lowest |Z| values, followed by VCTFPW and DPWMT. It is noteworthy that TFPW-WS yields comparable |Z| values to VCTFPW and DPWMT despite the initially weak autocorrelation. This unexpected outcome can be attributed to the utilization of a large sample size (exceeding 500 in the present cases). Large sample sizes have the effect of inflating |Z| values and significantly enhancing the test power [
4]. The DPWMT results match those of the VCTFPW in terms of the trend and the |Z| value, and they support the outcomes derived from the Monte Carlo simulation. Furthermore, the low RMSE value associated with the DPWMT slope estimator, in comparison to VCTFPW, suggests the DPWMT method for unbiased slope estimation.
3.4. Discussion
The prewhitening methods discussed here focus solely on lag-1 autocorrelation. However, atmospheric processes might sometimes be more accurately represented by higher-order autoregressive models that incorporate partial correlations at lags greater than 1 [
4]. While considering that these higher-order lag correlations could potentially enhance prewhitening by incorporating the appropriate number of lags, this approach was not examined in this study. Klaus et al. [
20] utilized higher-order autoregressive prewhitening for stable oxygen and hydrogen isotopes in precipitation and found that while higher-order lags significantly reduced the variance of the series, the trend slope was relatively unaffected. Moreover, Hardison et al. [
21] demonstrated through Monte Carlo simulations involving 124 ecosystem time series that AR(2) autocorrelation (with a coefficient of 0.2) produced similar Type-I and -II error rates for the Mann–Kendall (MK) test and the TFPW-Y as strong AR(1) autocorrelation.
Time series with noticeable seasonality may also show seasonality in lag-1 autocorrelation. Attempts were made to compute lag-1 autocorrelation for various temporal segments rather than the entire series. However, this approach was not pursued further due to the challenges in applying seasonal lag-1 autocorrelation consistently, which resulted in erratic outcomes and precluded the application of the prewhitening method uniformly across all temporal segments.
These prewhitening methods rely on the assumption of linear trends within the time series but do not account for the sensitivity of power to the shape of these trends. Despite this, the linear trend tests offer a reference point for assessing the significance of monotonic nonlinear trends and provide insight into the magnitude of change [
11].
The AR(1) model is recognized for its capacity to maintain essential statistical characteristics of hydrometeorological time series, including serial mean, variance, and autocorrelation [
22]. However, some research has employed the PW approach with different autocorrelation models, such as the Auto-Regressive Moving Average (ARMA(1,1)). In such cases, more generalized formulas for calculating Variance Inflation Factors (VIFs) that accommodate various autocorrelation structures can be referred to as those proposed by Matalas and Sankarasubramanian [
12].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}