
Based on the Improved PSO-TPA-LSTM Model Chaotic Time Series Prediction


Abstract
:1. Introduction
2. IPSO-TPA-LSTM
2.1. Improved Particle Group Optimization Algorithm (IPSO)
2.1.1. The Inertia of Non-Linear Change
2.1.2. Improve Learning Factor Adjustment Strategy
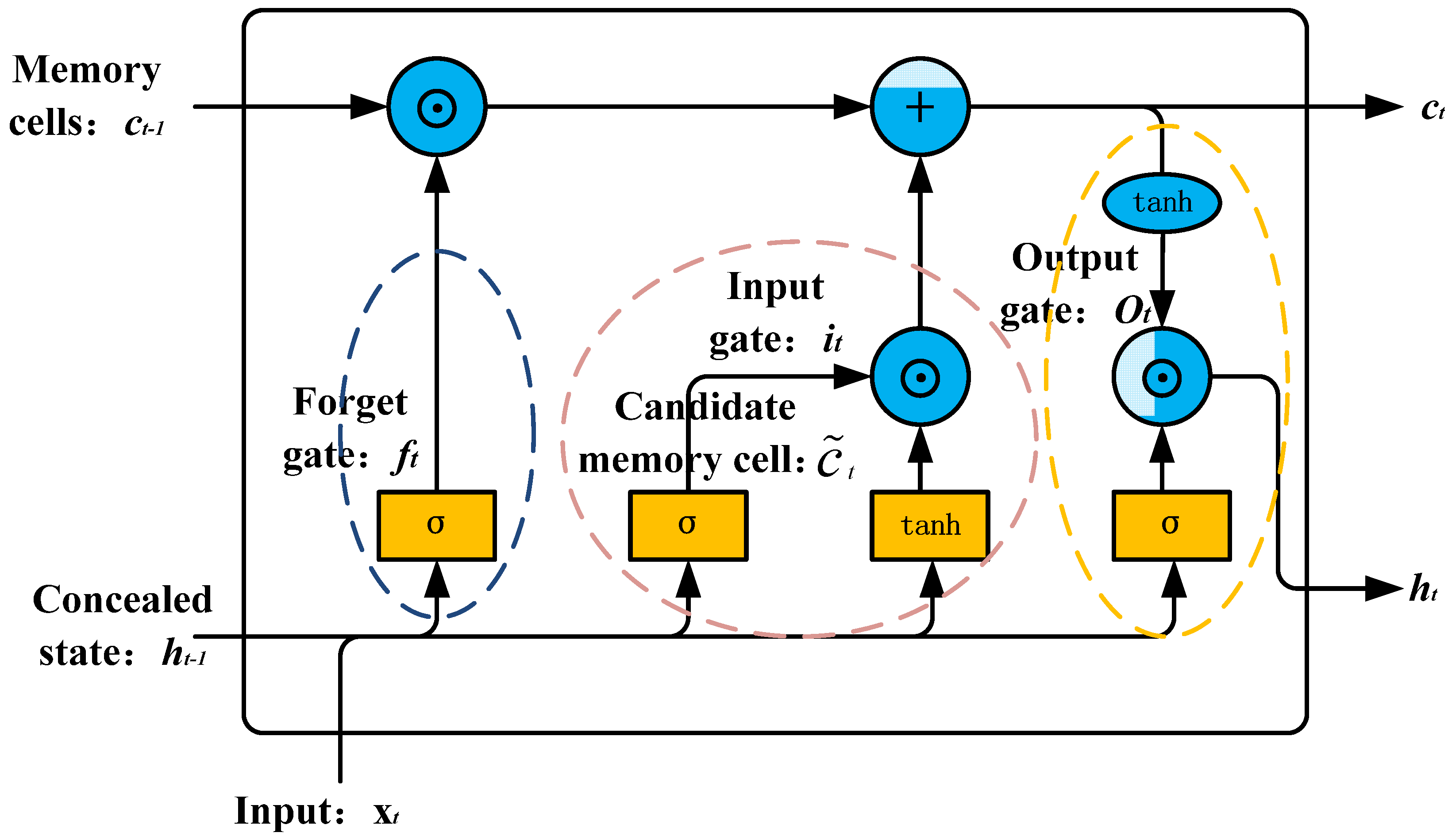
2.2. Long Short-Term Memory Network (LSTM)
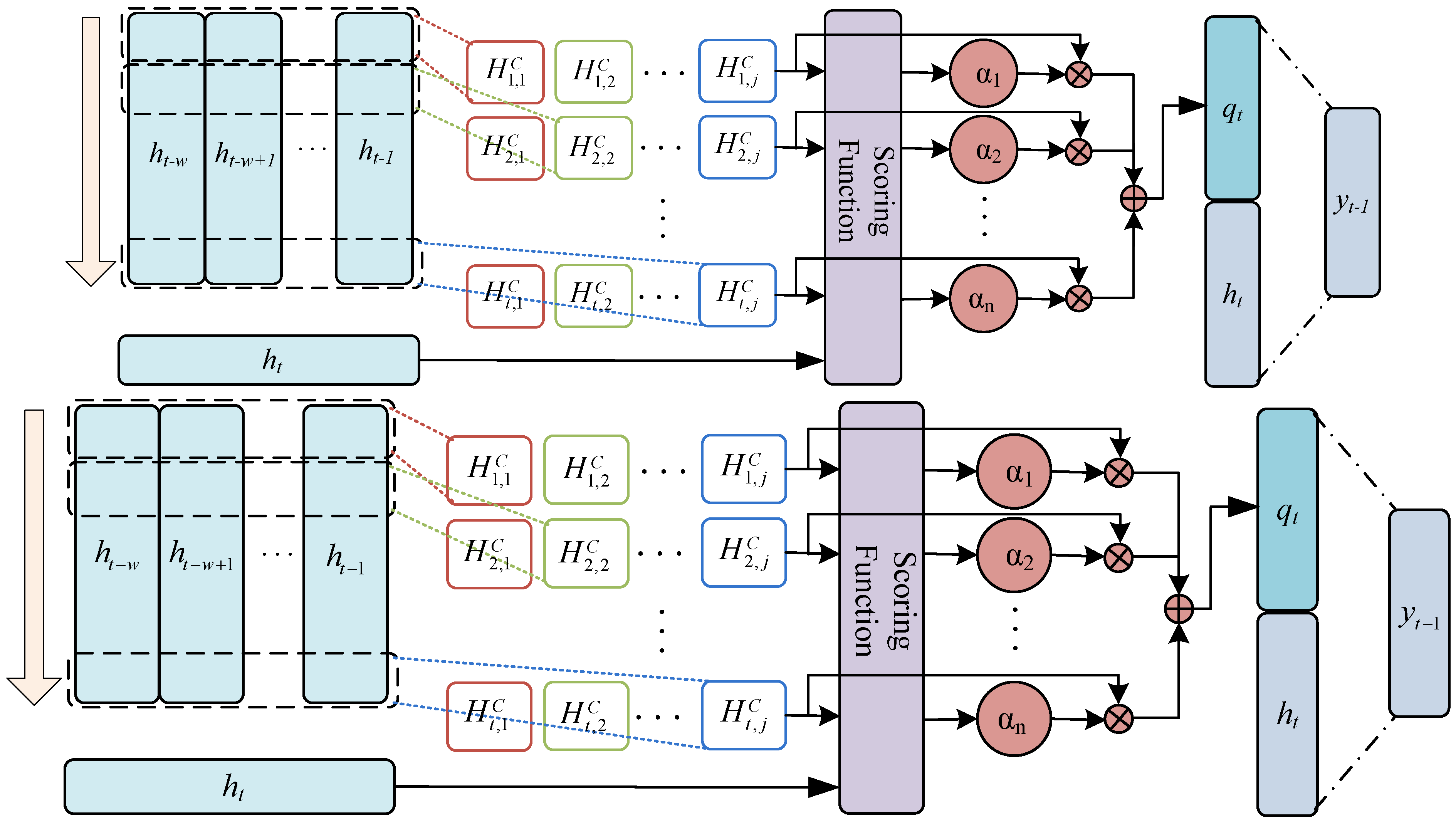
2.3. Time Mode Attention Mechanism (TPA)
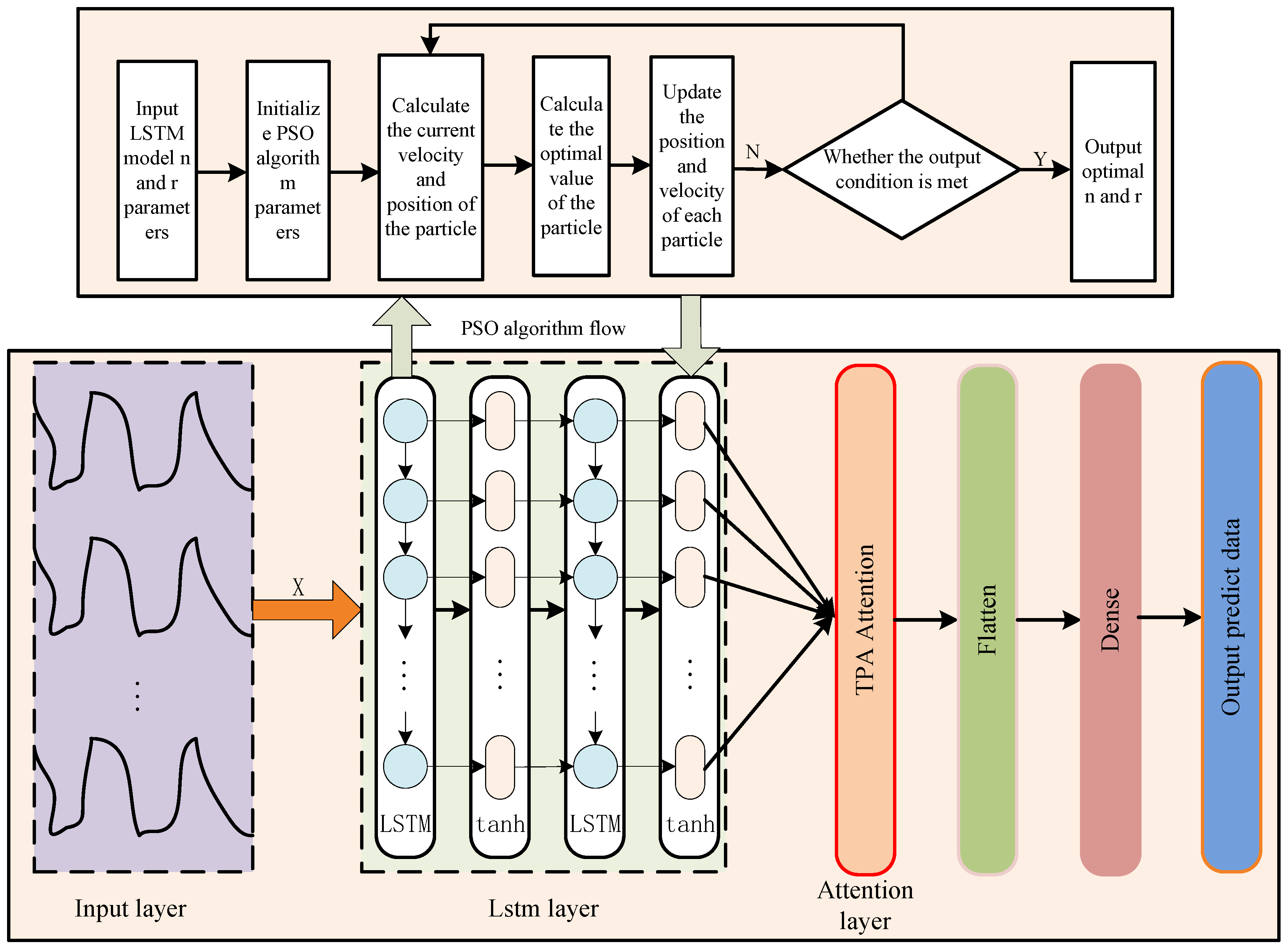
3. Build an IPSO-TPA-LSTM Chaos Data Prediction Model
3.1. Input Layer
3.2. LSTM Layer
3.3. Attention Layer
4. Chaos Data Sources
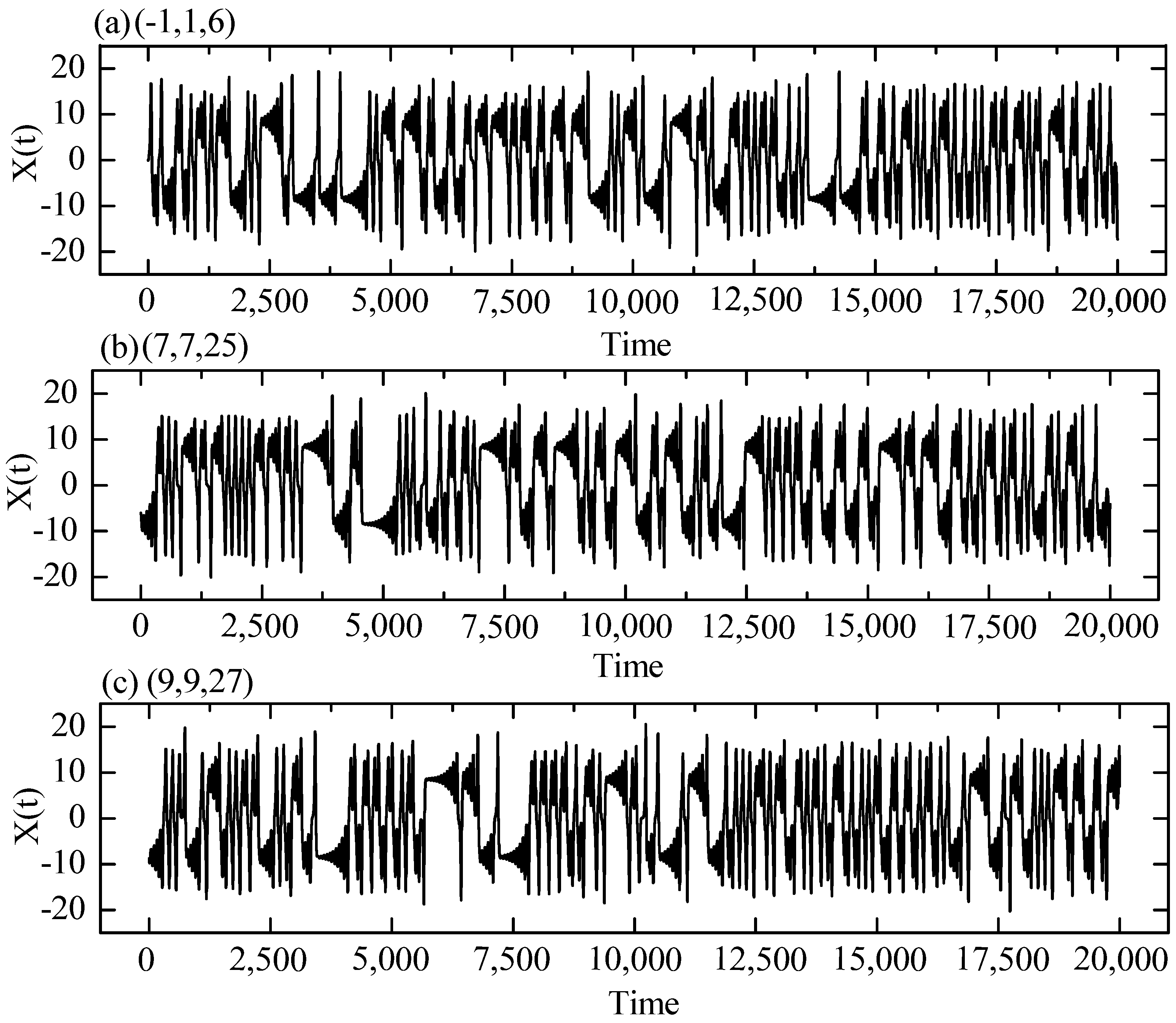
4.1. Lorenz Systems
4.2. Evaluation Index of the Chaotic Data Model
5. Experimental Design and Analysis
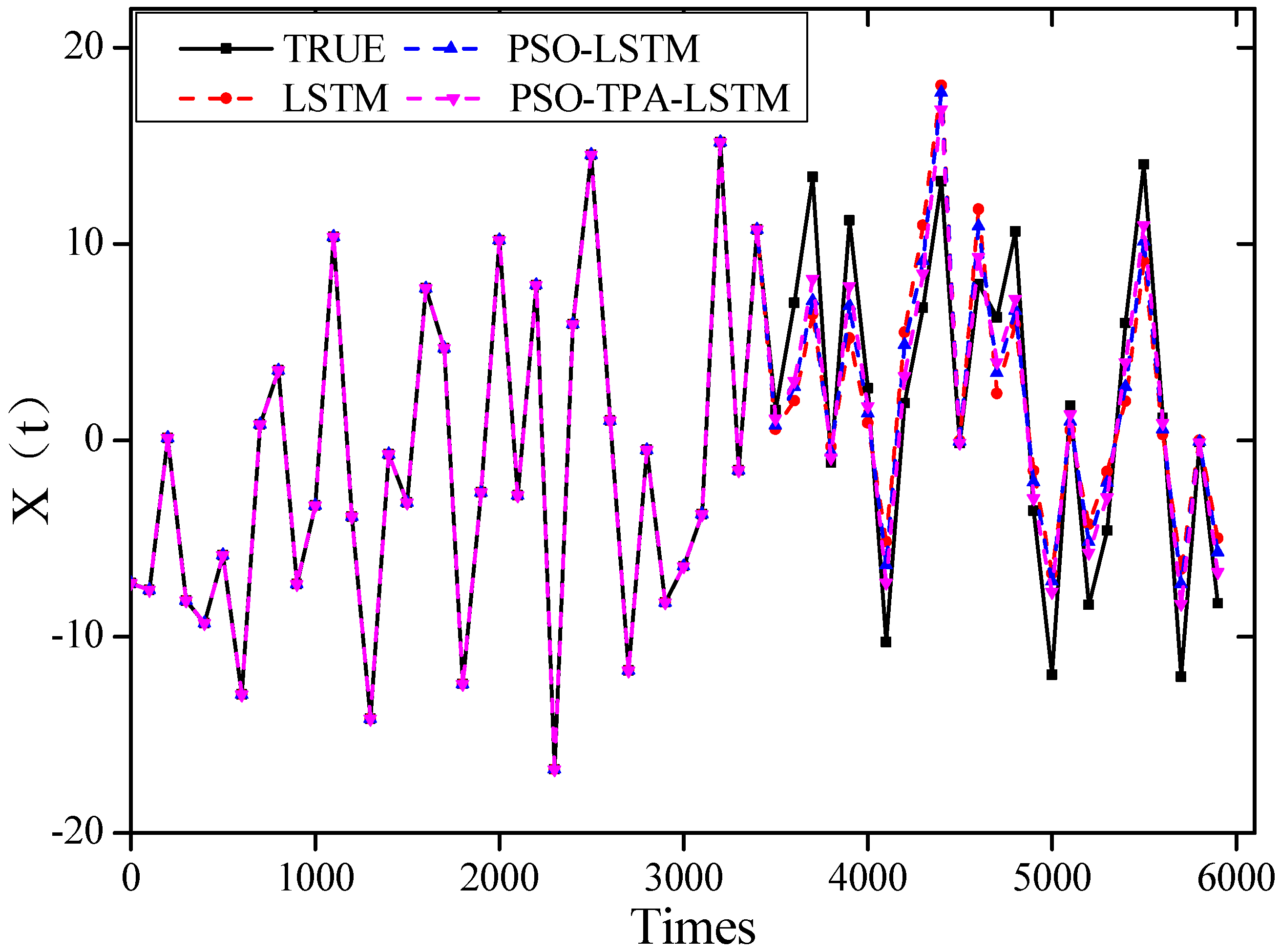
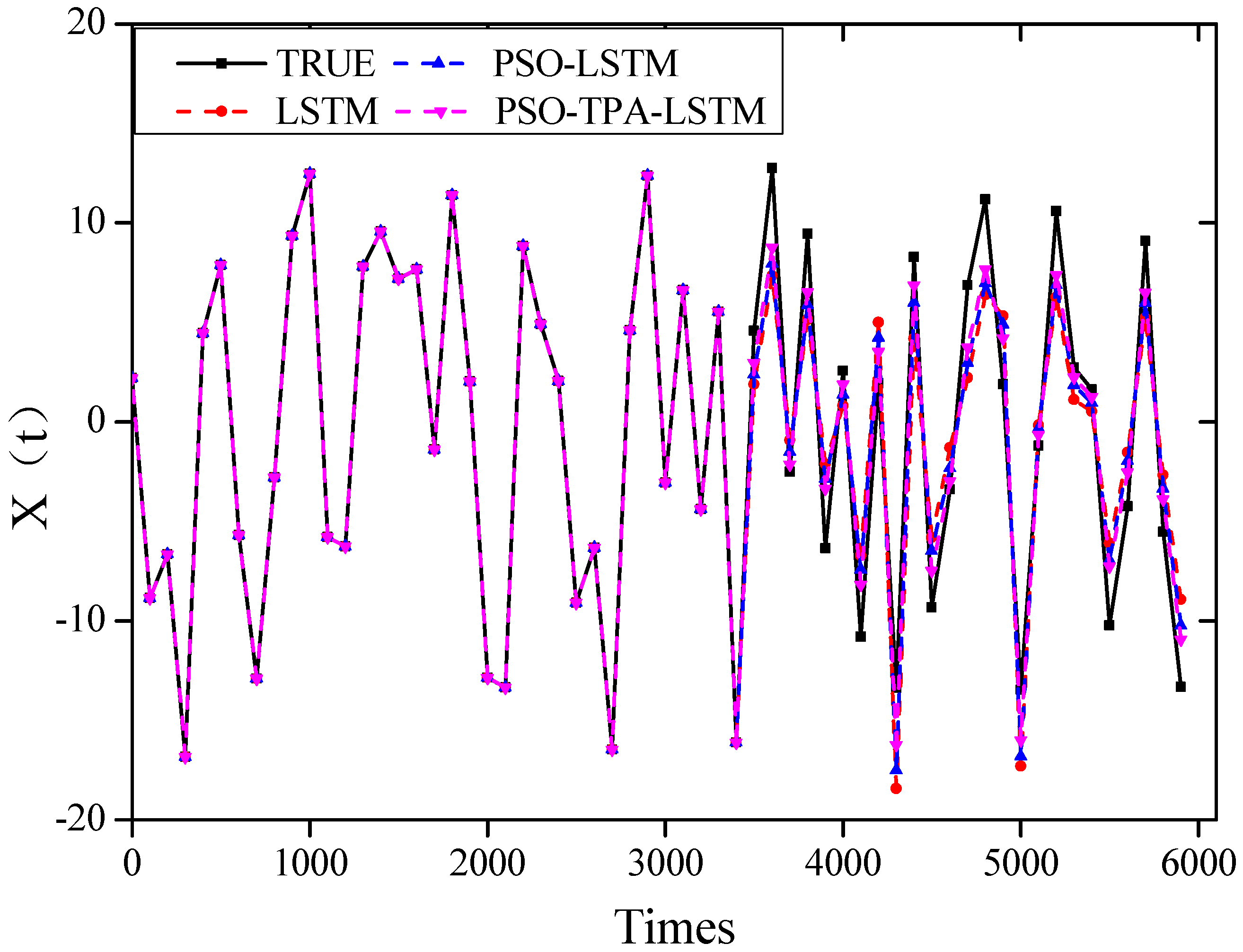
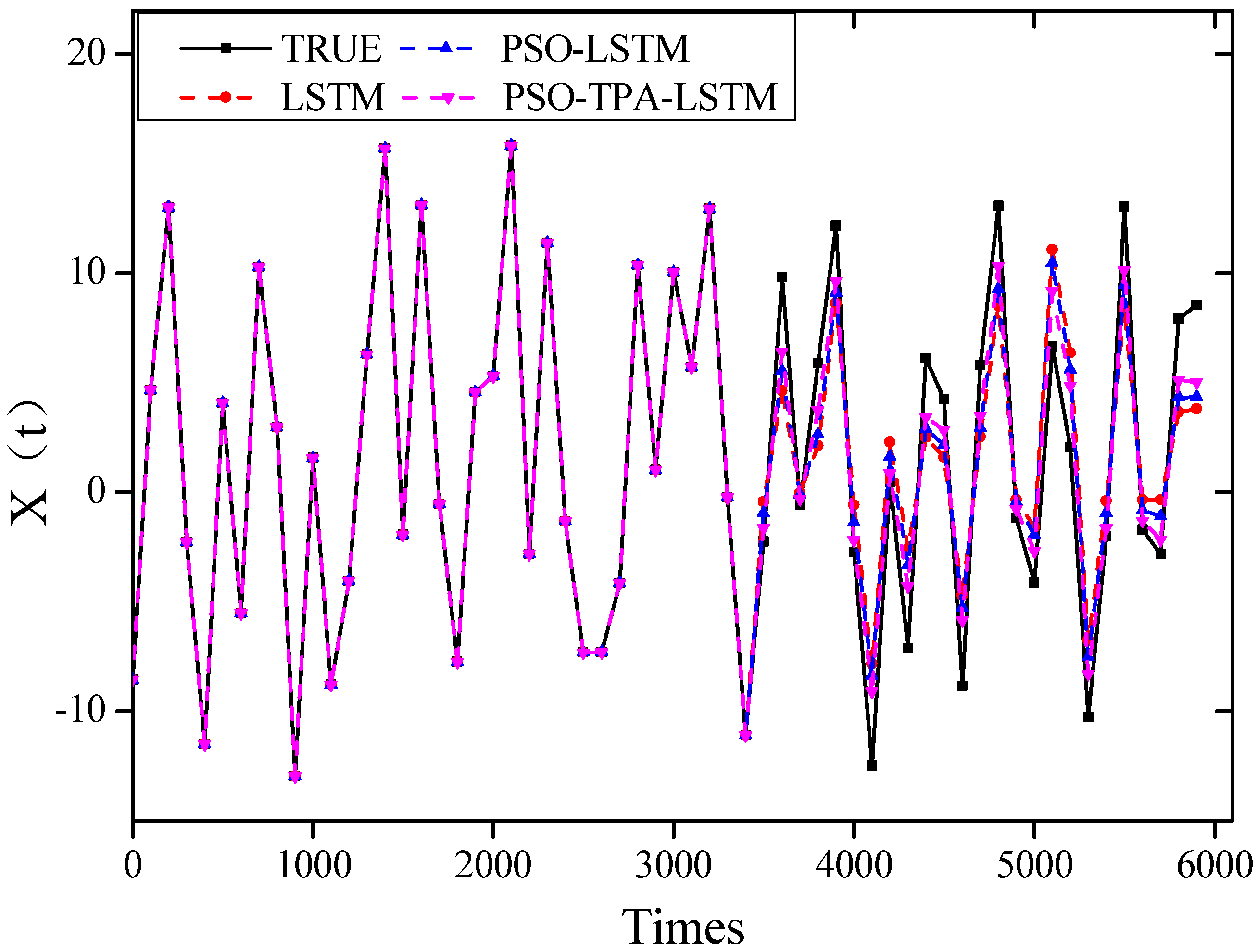
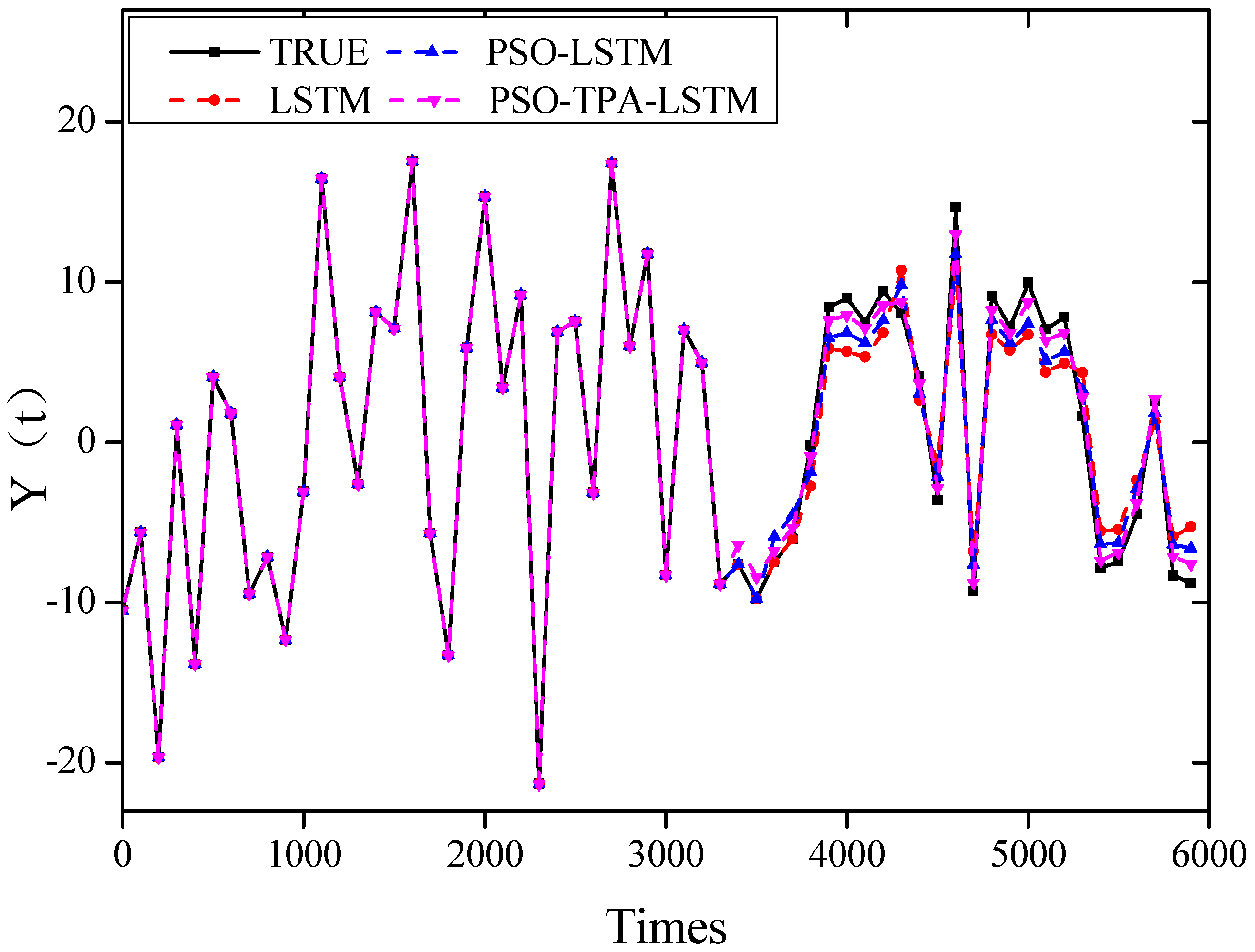
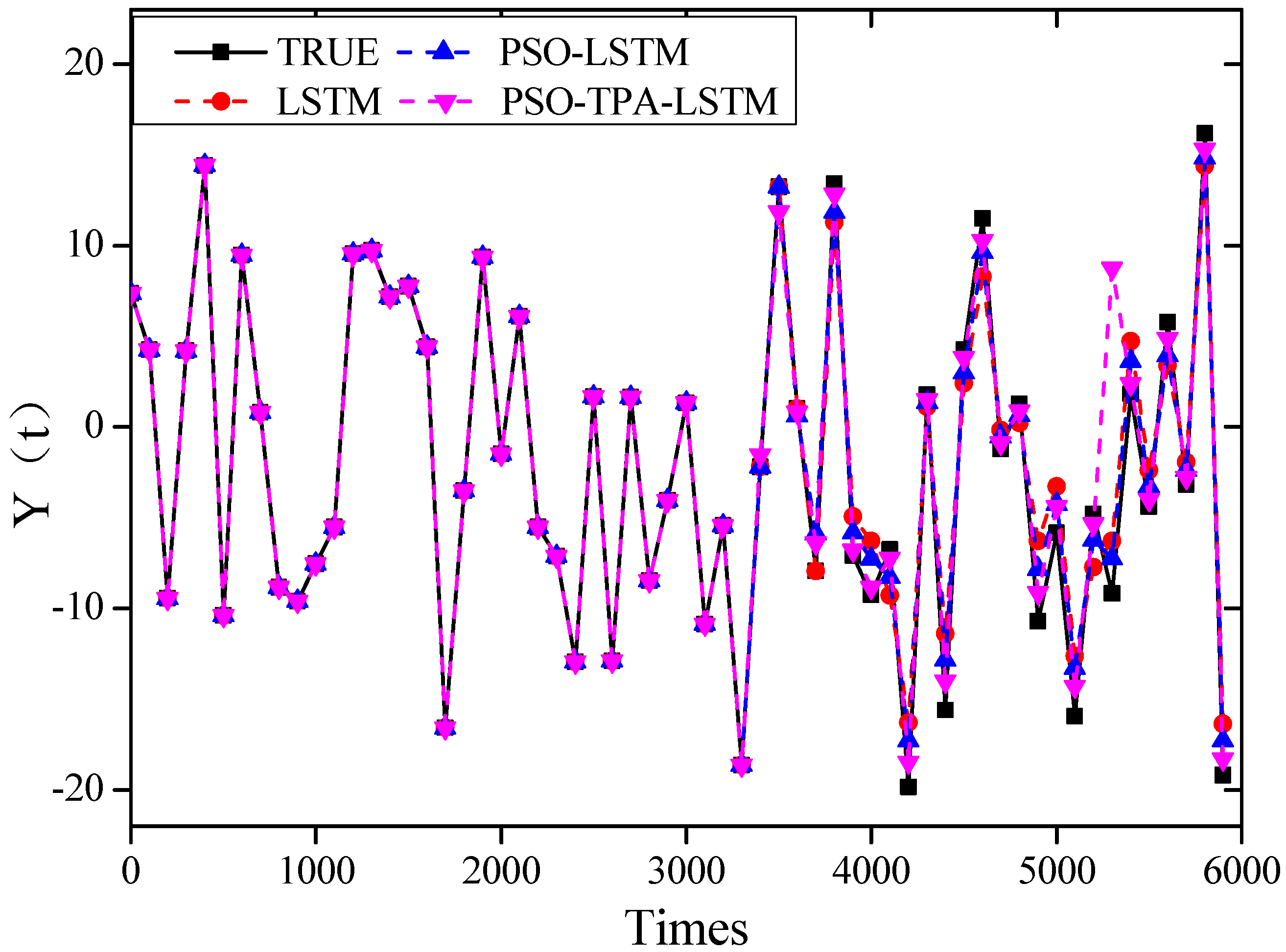
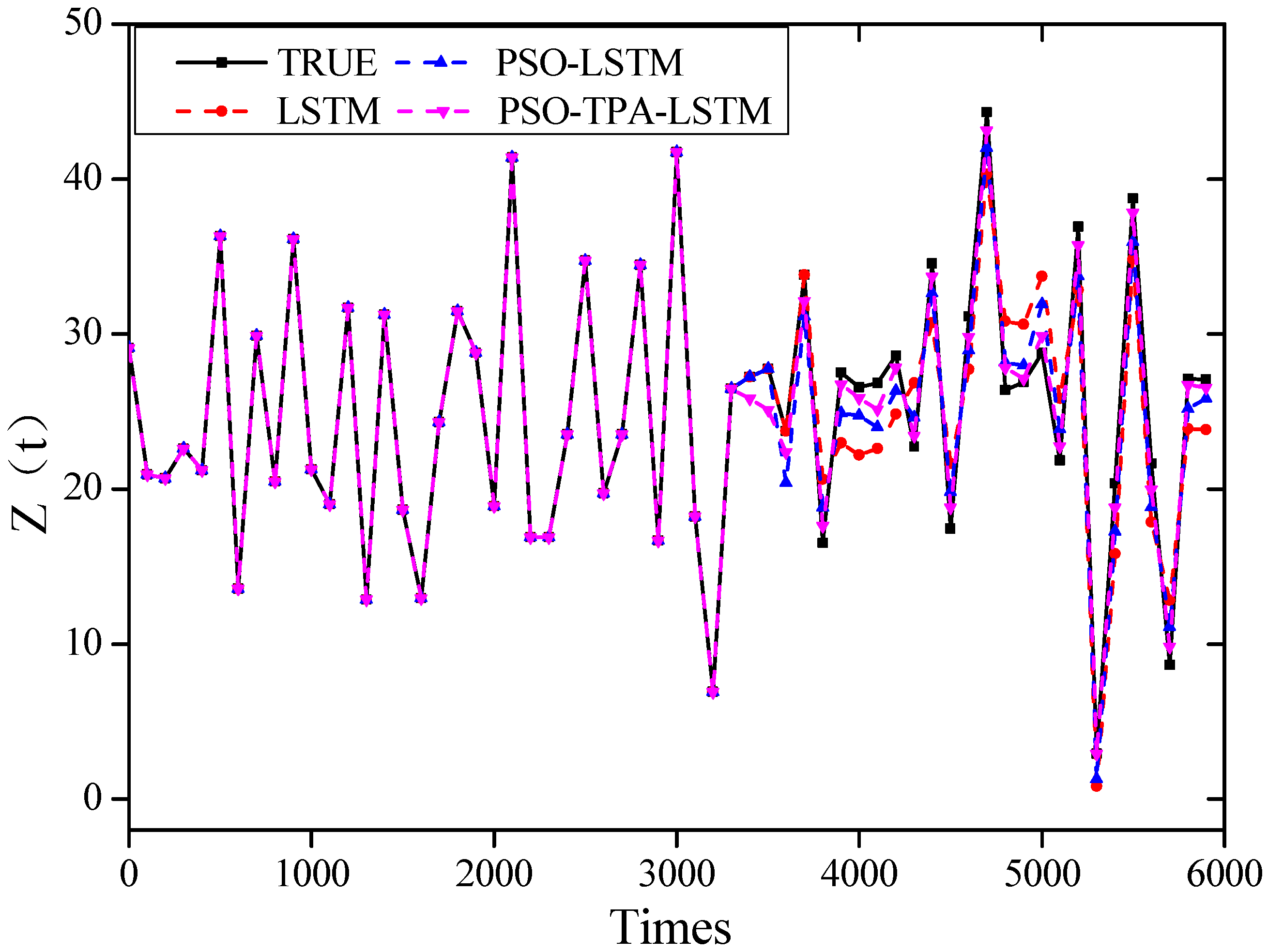
5.1. Prediction of Chaotic Data for Different Algorithmic Models
5.2. Comparison of Accuracy of Different Prediction Models
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, U.; Jain, V.K. ARIMA forecasting of ambient air pollutants (O3, NO, NO2 and CO). Stoch. Environ. Res. Risk Assess. 2010, 24, 751–760. [Google Scholar] [CrossRef]
- Garcia, R.C.; Contreras, J.; Van Akkeren, M.; Garcia, J.B.C. A GARCH forecasting model to predict day-ahead electricity prices. IEEE Trans. Power Syst. 2005, 20, 867–874. [Google Scholar] [CrossRef]
- Su, L.; Li, C. Local prediction of chaotic time series based on polynomial coefficient autoregressive model. Math. Probl. Eng. 2015, 2015, 901807. [Google Scholar] [CrossRef]
- Tian, Z.D.; Gao, X.W.; Shi, T. Combination kernel function least squares support vector machine for chaotic time series prediction. Acta Phys. Sin. 2014, 63, 160508. [Google Scholar] [CrossRef]
- Wang, S.Y.; Shi, C.F.; Qian, G.B.; Wang, W.L. Prediction of chaotic time series based on the fractional-order maximum correntropy criterion algorithm. Acta Phys. Sin. 2018, 67, 018401. [Google Scholar] [CrossRef]
- He, Y.; Xu, Q.; Wan, J.; Yang, S. Electrical load forecasting based on self-adaptive chaotic neural network using Chebyshev map. Neural Comput. Appl. 2018, 29, 603–612. [Google Scholar] [CrossRef]
- Cheng, W.; Wang, Y.; Peng, Z.; Ren, X.; Shuai, Y.; Zang, S.; Liu, H.; Cheng, H.; Wu, J. High-efficiency chaotic time series prediction based on time convolution neural network. Chaos Solitons Fractals 2021, 152, 111304. [Google Scholar] [CrossRef]
- Nguyen, N.P.; Duong, T.A.; Jan, P. Strategies of Multi-Step-ahead Forecasting for Chaotic Time Series using Autoencoder and LSTM Neural Networks: A Comparative Study. In Proceedings of the 2023 5th International Conference on Image Processing and Machine Vision, Macau, China, 13–15 January 2023; pp. 55–61. [Google Scholar]
- Yan, J.C.; Zheng, J.Y.; Sun, S.Y. Chaotic time series prediction based on maximum information mining broad learning system. Comput. Appl. Softw. 2023, 40, 253–260. [Google Scholar]
- Sun, T.B.; Liu, Y.H. Chaotic Time Series Prediction Based on Fuzzy Information Granulation and Hybrid Neural Network. Inf. Control 2022, 51, 671–679. [Google Scholar]
- Wang, L.; Wang, X.; Li, H.Q. Chaotic time series prediction model of wind power power based on phase space reconstruction and error compensation. Proc. CSU-EPSA 2017, 29, 65–69. [Google Scholar]
- Li, K.; Han, Y.; Huang, H.Q. Chaotic Time Series Prediction Based on IBH-LSSVM and Its Application to Short-term Prediction of Dynamic Fluid Level in Oil Wells. Inf. Control 2016, 45, 241–247, 256. [Google Scholar]
- Sareminia, S. A Support Vector Based Hybrid Forecasting Model for Chaotic Time Series: Spare Part Consumption Prediction. Neural Process Lett. 2023, 55, 2825–2841. [Google Scholar] [CrossRef]
- Wei, A.; Li, X.; Yan, L.; Wang, Z.; Yu, X. Machine learning models combined with wavelet transform and phase space reconstruction for groundwater level forecasting. Comput. Geosci. 2023, 177, 105386. [Google Scholar]
- Wang, H.; Zhang, Y.; Liang, J.; Liu, L. DAFA-BiLSTM: Deep Autoregression Feature Augmented Bidirectional LSTM network for time series prediction. Neural Netw. 2023, 157, 240–256. [Google Scholar] [CrossRef] [PubMed]
- Nasiri, H.; Ebadzadeh, M.M. MFRFNN: Multi-functional recurrent fuzzy neural network for chaotic time series prediction. Neurocomputing 2022, 507, 292–310. [Google Scholar] [CrossRef]
- Wang, L.; Dai, L. Chaotic Time Series Prediction of Multi-Dimensional Nonlinear System Based on Bidirectional LSTM Model. Adv. Theory Simul. 2023, 6, 2300148. [Google Scholar] [CrossRef]
- Huang, W.J.; Li, Y.T.; Huang, Y. Prediction of chaotic time series using hybrid neural network and attention mechanism. Acta Phys. Sin. 2021, 70, 010501. [Google Scholar] [CrossRef]
- Fu, K.; Li, H.; Deng, P. Chaotic time series prediction using DTIGNet based on improved temporal-inception and GRU. Chaos Solitons Fractals 2022, 159, 112183. [Google Scholar] [CrossRef]
- Qi, L.T.; Wang, S.Y.; Shen, M.L.; Huang, G.Y. Prediction of chaotic time series based on Nyström Cauchy kernel conjugate gradient algorithm. Acta Phys. Sin. 2022, 71, 108401. [Google Scholar] [CrossRef]
- Ong, P.; Zainuddin, Z. An optimized wavelet neural networks using cuckoo search algorithm for function approximation and chaotic time series prediction. Decis. Anal. J. 2023, 6, 100188. [Google Scholar] [CrossRef]
- Ong, P.; Zainuddin, Z. Optimizing wavelet neural networks using modified cuckoo search for multi-step ahead chaotic time series prediction. Appl. Soft Comput. 2019, 80, 374–386. [Google Scholar] [CrossRef]
- Jiang, P.; Wang, B.; Li, H.; Lu, H. Modeling for chaotic time series based on linear and nonlinear framework: Application to wind speed forecasting. Energy 2019, 173, 468–482. [Google Scholar] [CrossRef]
- Mei, Y.; Tan, G.Z.; Liu, Z.T.; Wu, H. Chaotic time series prediction based on brain emotional learning model and self-adaptive genetic algorithm. Acta Phys. Sin. 2018, 67, 080502. [Google Scholar]
- Awad, M. Forecasting of Chaotic Time Series Using RBF Neural Networks Optimized by Genetic Algorithms. Int. Arab. J. Inf. Technol. 2017, 14, 826–834. [Google Scholar]
- Long, W.; Zhang, W.Z. Parameter estimation of heavy oil pyrolysis model based on adaptive particle swarm algorithm. J. Chongqing Norm. Univ. Nat. Sci. 2023, 30, 128–133. [Google Scholar]
- Xu, S.B.; Xia, W.J.; Dai, A.D. A particle swarm algorithm that improves learning factors. Inf. Secur. Technol. 2012, 3, 17–19. [Google Scholar]
- Li, G.; Li, X.J.; Yang, W.X.; Han, D. Research on TBM boring parameter prediction based on deep learning. Mod. Tunn. Technol. 2020, 57, 154–159. [Google Scholar]
- Feng, Y.T.; Wu, X.; Xu, X.; Zhang, R.Q. Research on ionospheric parameter prediction based on deep learning. J. Commun. 2021, 42, 202–206. [Google Scholar]
- Park, J.; Jungsik, J.; Park, Y. Ship trajectory prediction based on Bi-LSTM using spectral-clustered AIS data. J. Mar. Sci. Eng. 2021, 9, 1037. [Google Scholar] [CrossRef]
- Lorenz, E.N. Deterministic Nonperiodic Flow. J. Atmos. Sci. 2004, 20, 130–141. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAE | RMSE | R2 | |
|---|---|---|---|
| LSTM | 3.874 | 2.736 | 0.83 |
| PSO-LSTM | 3.337 | 2.652 | 0.88 |
| PSO-TPA-LSTM | 2.983 | 2.231 | 0.92 |
| MAE | RMSE | R2 | |
|---|---|---|---|
| LSTM | 6.644 | 4.3822 | 0.87 |
| PSO-LSTM | 5.261 | 3.872 | 0.89 |
| PSO-TPA-LSTM | 3.823 | 3.523 | 0.93 |
| MAE | RMSE | R2 | |
|---|---|---|---|
| LSTM | 5.837 | 4.542 | 0.85 |
| PSO-LSTM | 3.982 | 2.953 | 0.86 |
| PSO-TPA-LSTM | 2.983 | 2.231 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Z.; Feng, G.; Wang, Q. Based on the Improved PSO-TPA-LSTM Model Chaotic Time Series Prediction. Atmosphere 2023, 14, 1696. https://doi.org/10.3390/atmos14111696
Cai Z, Feng G, Wang Q. Based on the Improved PSO-TPA-LSTM Model Chaotic Time Series Prediction. Atmosphere. 2023; 14(11):1696. https://doi.org/10.3390/atmos14111696
Chicago/Turabian StyleCai, Zijian, Guolin Feng, and Qiguang Wang. 2023. "Based on the Improved PSO-TPA-LSTM Model Chaotic Time Series Prediction" Atmosphere 14, no. 11: 1696. https://doi.org/10.3390/atmos14111696
APA StyleCai, Z., Feng, G., & Wang, Q. (2023). Based on the Improved PSO-TPA-LSTM Model Chaotic Time Series Prediction. Atmosphere, 14(11), 1696. https://doi.org/10.3390/atmos14111696