
Modeling the Interdependence Structure between Rain and Radar Variables Using Copulas: Applications to Heavy Rainfall Estimation by Weather Radar


Abstract
1. Introduction
2. Methodological Background: Basics of Copulas Theory
2.1. Definitions and Properties
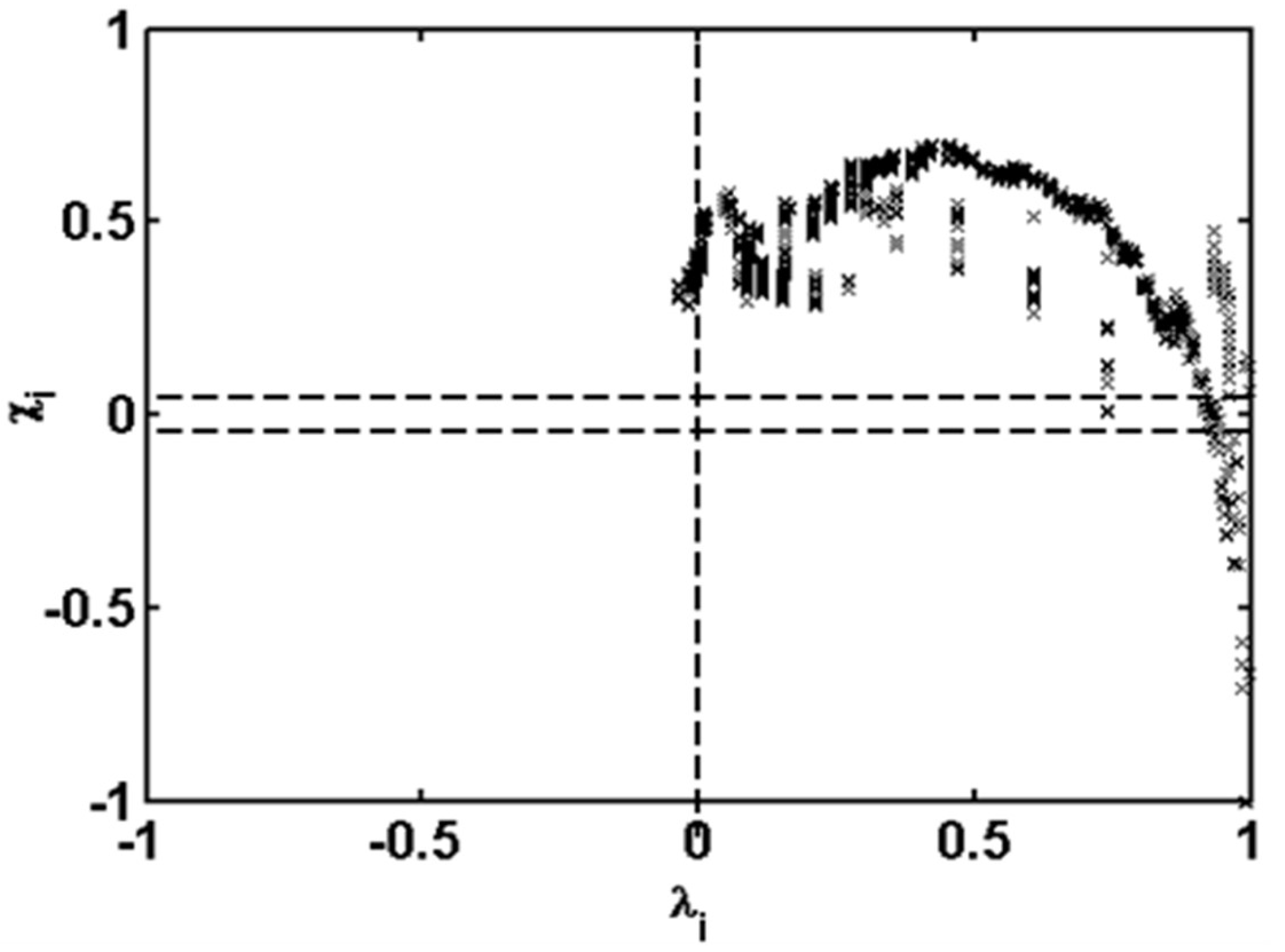
2.2. Measure of Dependence
2.3. Types and Criteria Choice of Copula
2.4. Copula Estimation Strategy
- (1)
- Estimate , by maximizing the log-likelihood of the two univariate marginal distributions separately (the two last terms in Equation (15)) [39]:
- (2)
- Estimate the association parameter given the previous estimates of , :
2.5. Implementation of Simulations from Copula
- Simulate uniform random variables ( and for a bivariate case) for a given copula;
- Transform the random uniform numbers to variable data ( and ) using univariate marginals and , whose parameters have been previously determined. This approach can help in generating synthetic datasets using the copula method.
- Generate two independent uniform random variables, and . Denote them as and , respectively.
- Set .
- Recursively generate using the conditional distribution of the copula given, , which is defined as follows:
3. Materials and Methods
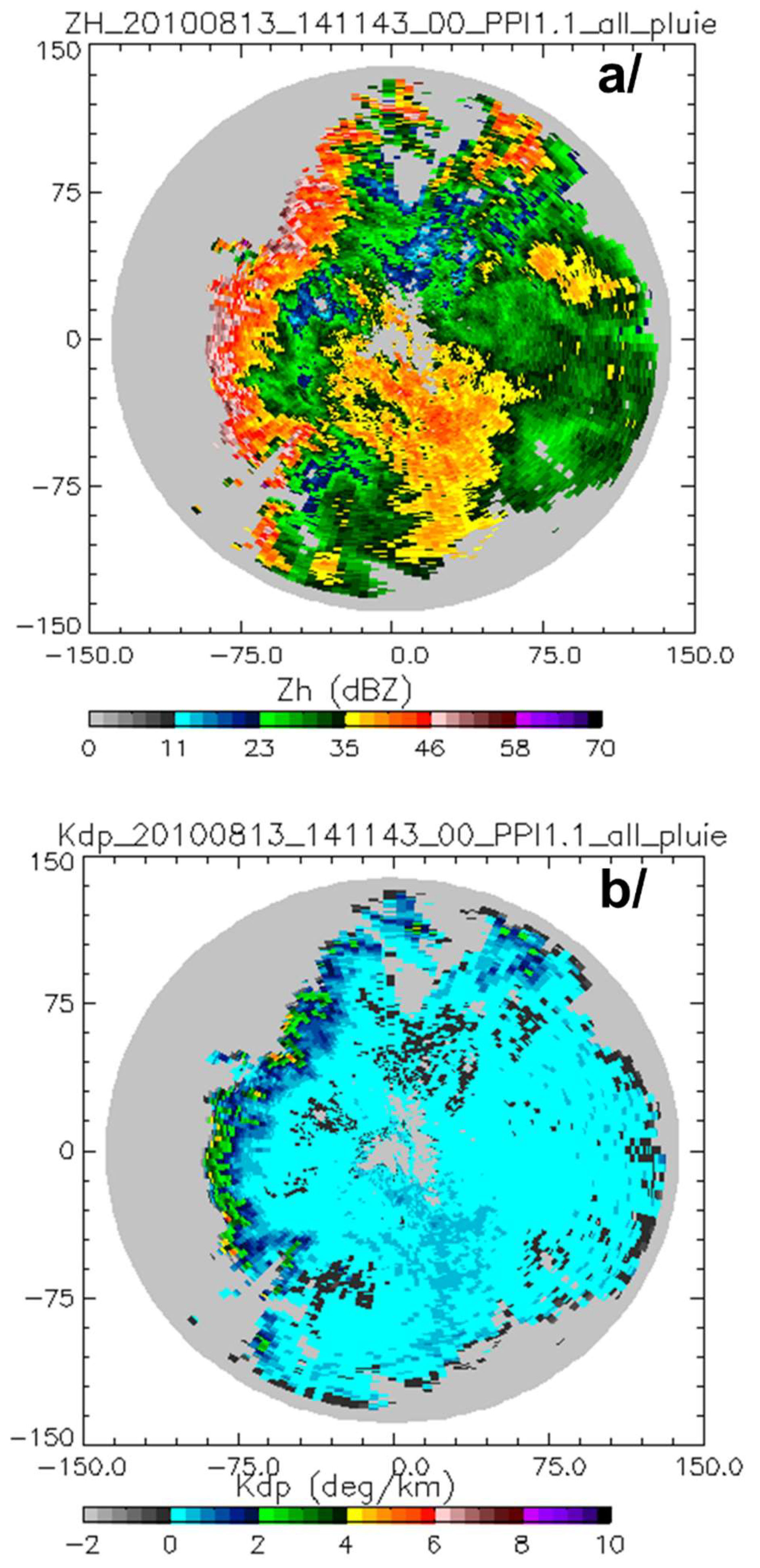
3.1. Original Datasets and Methodology
3.2. Copulas Simulations Datasets
3.3. Quantile Regression Method
4. Results
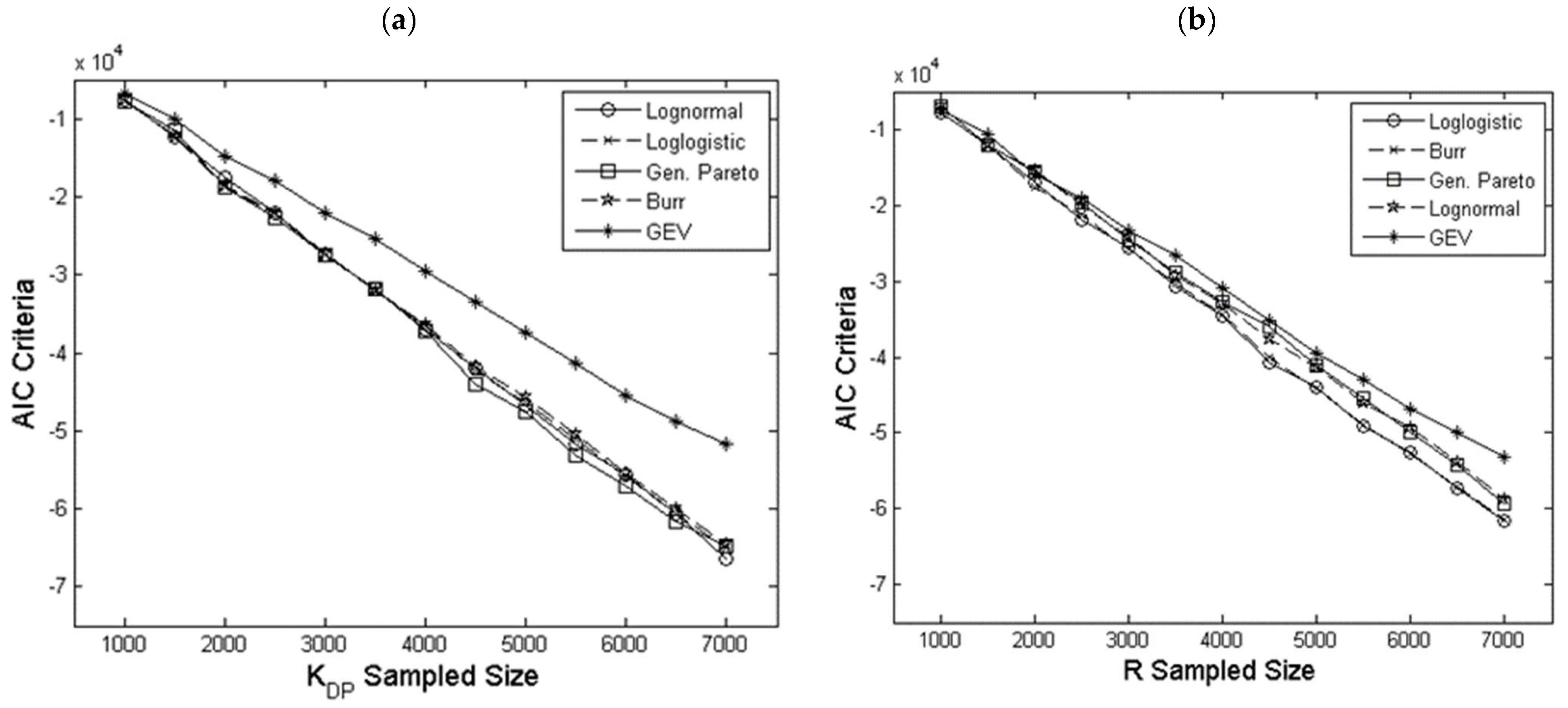
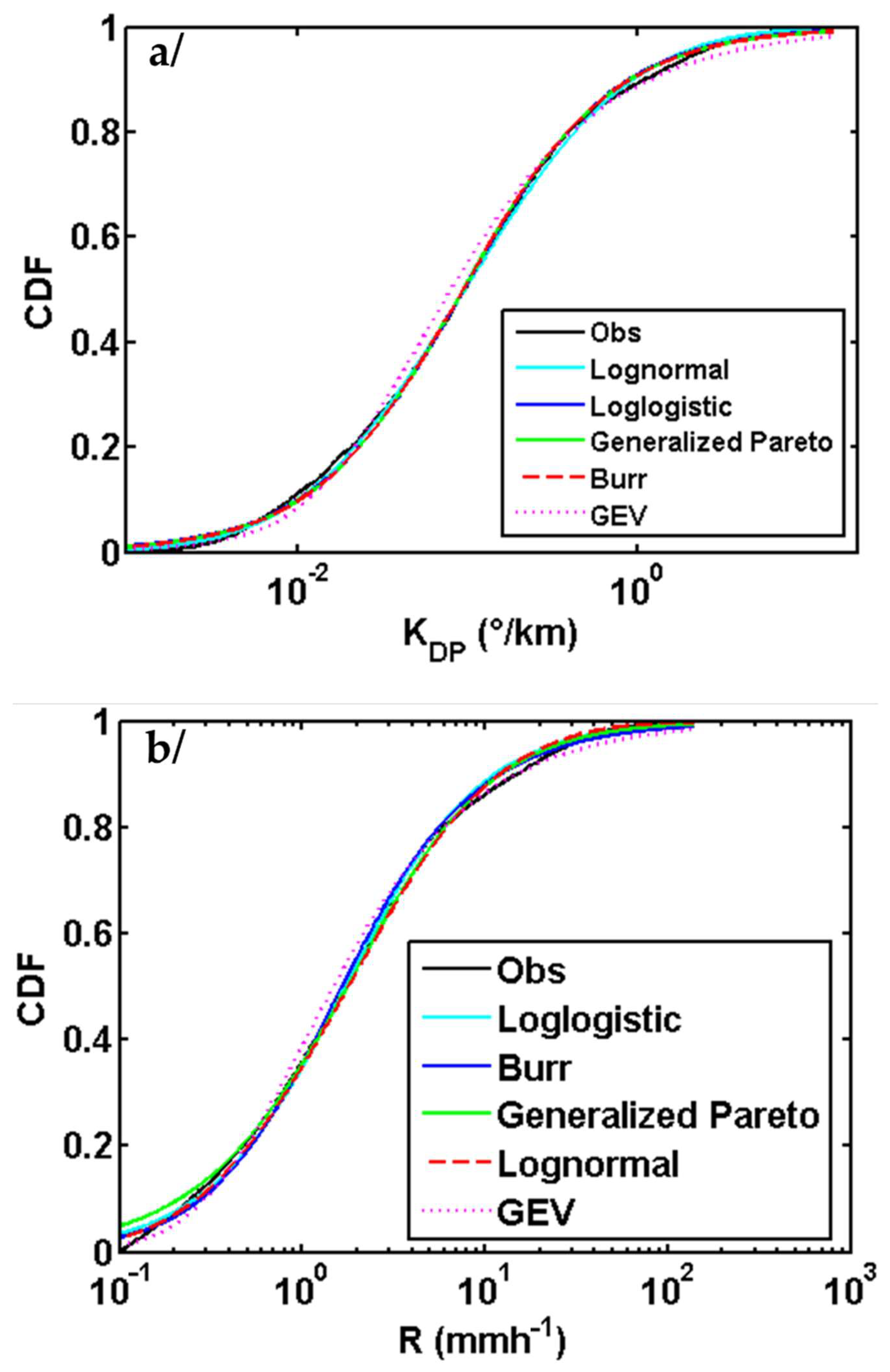
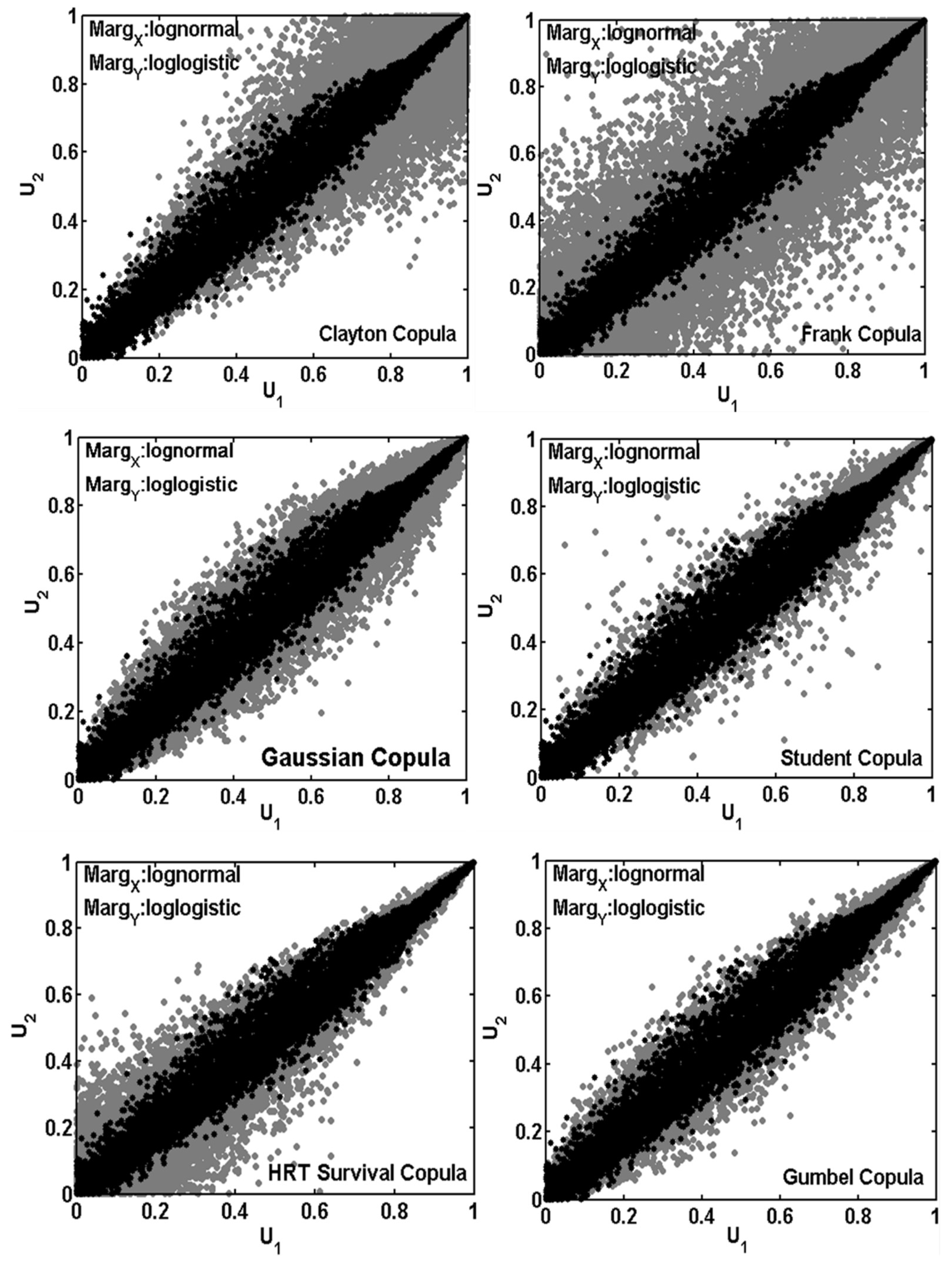
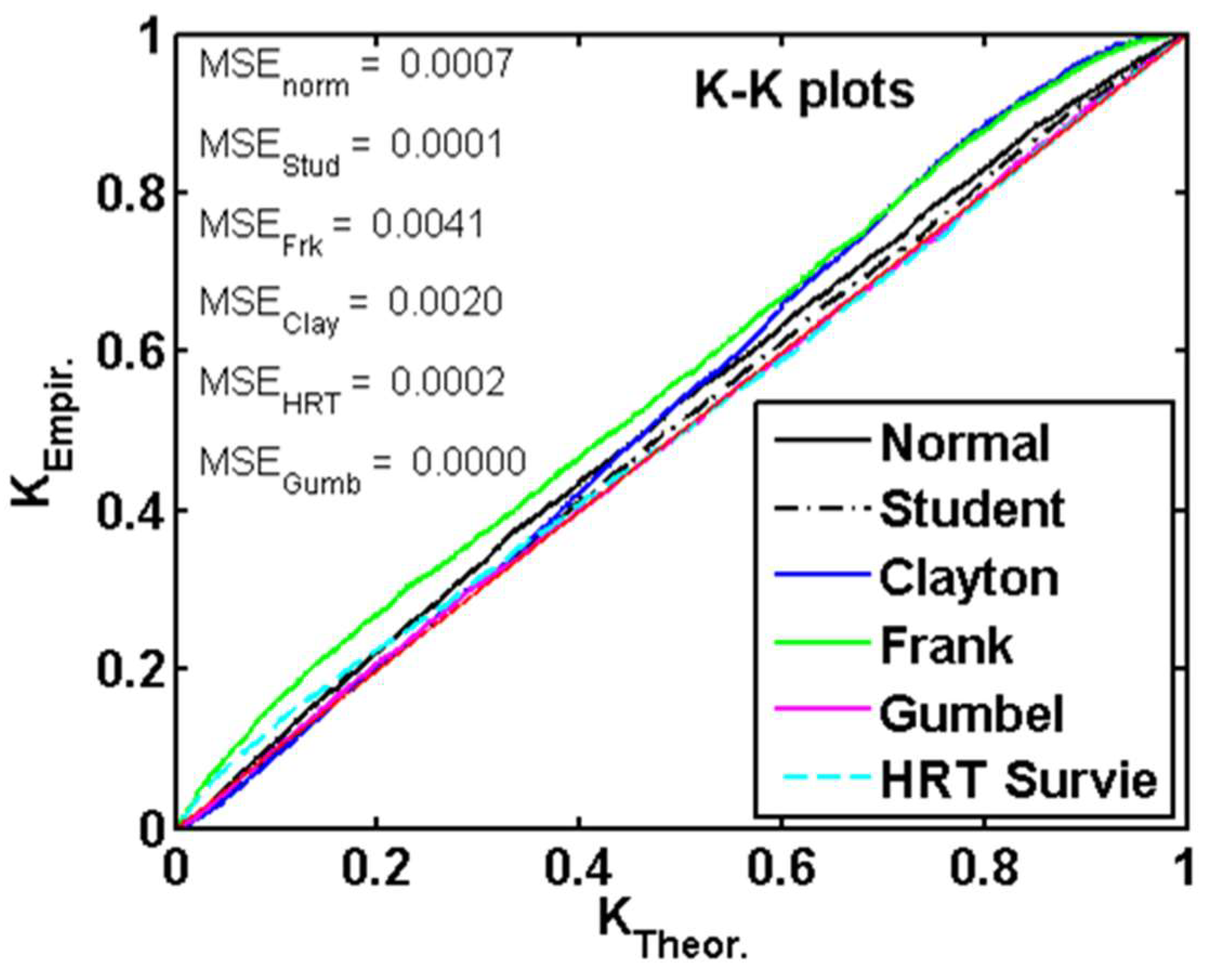
4.1. Copulas Simulation Datasets Assessment
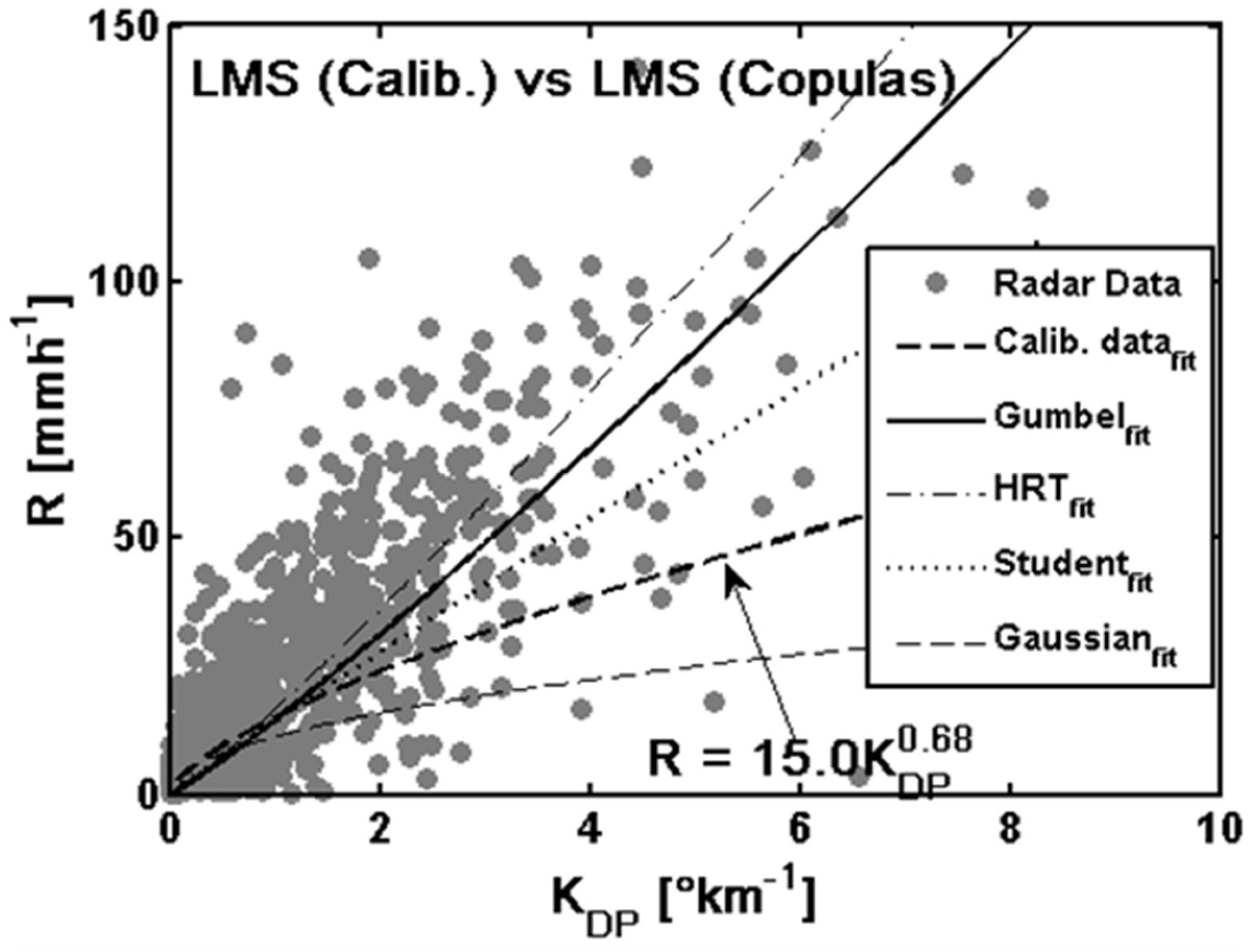
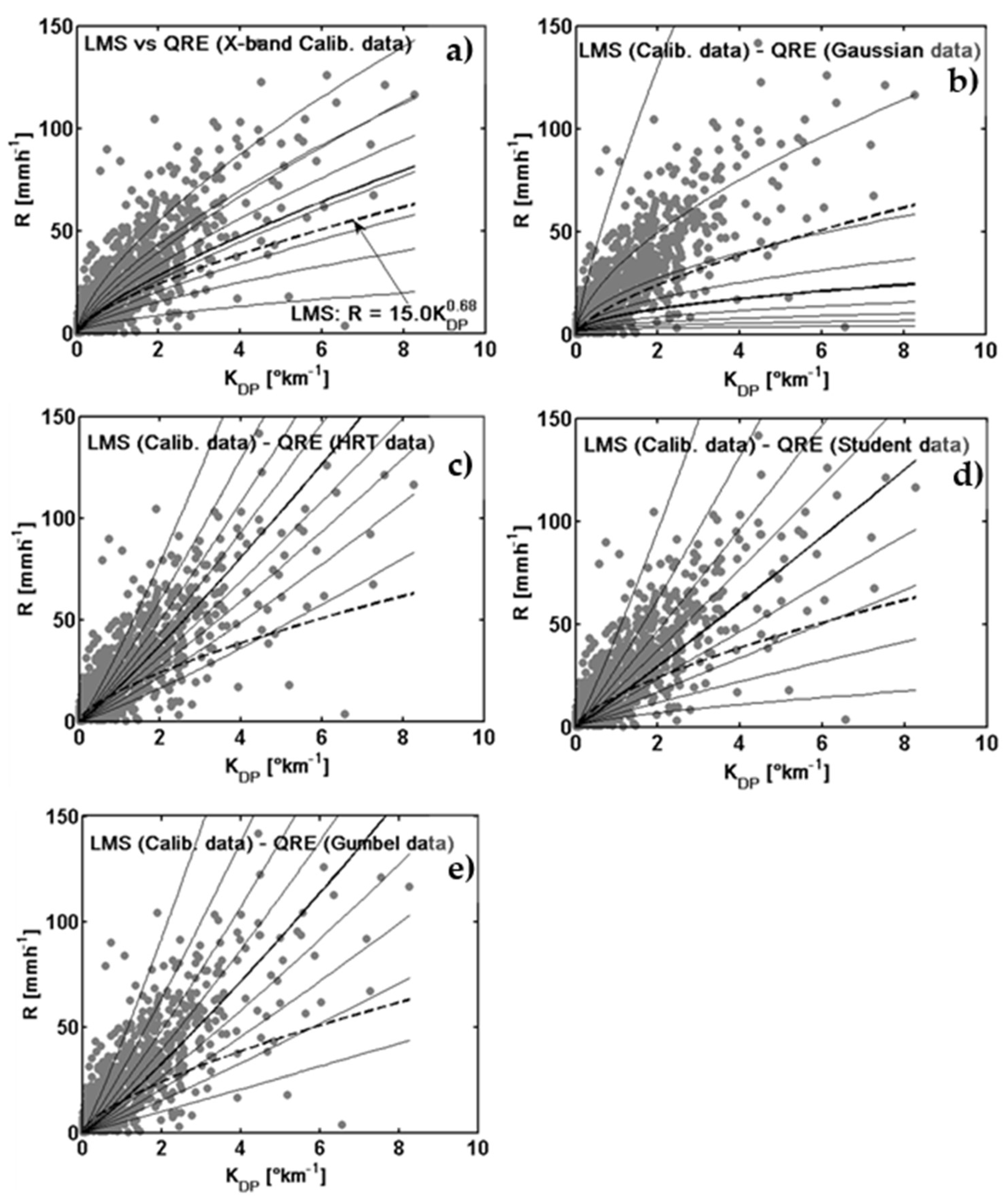
4.2. Statistical Rainfall Regression Estimators
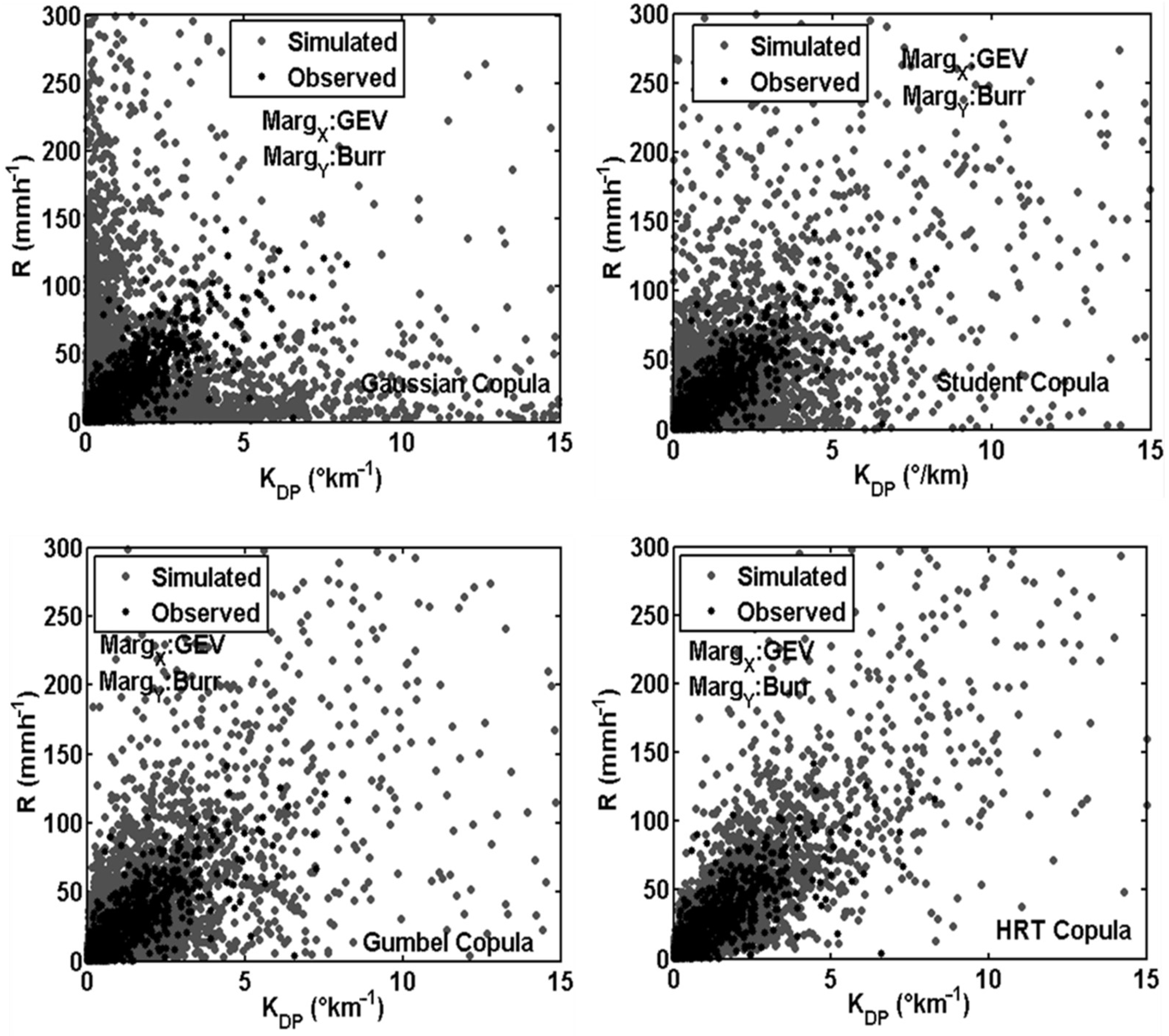
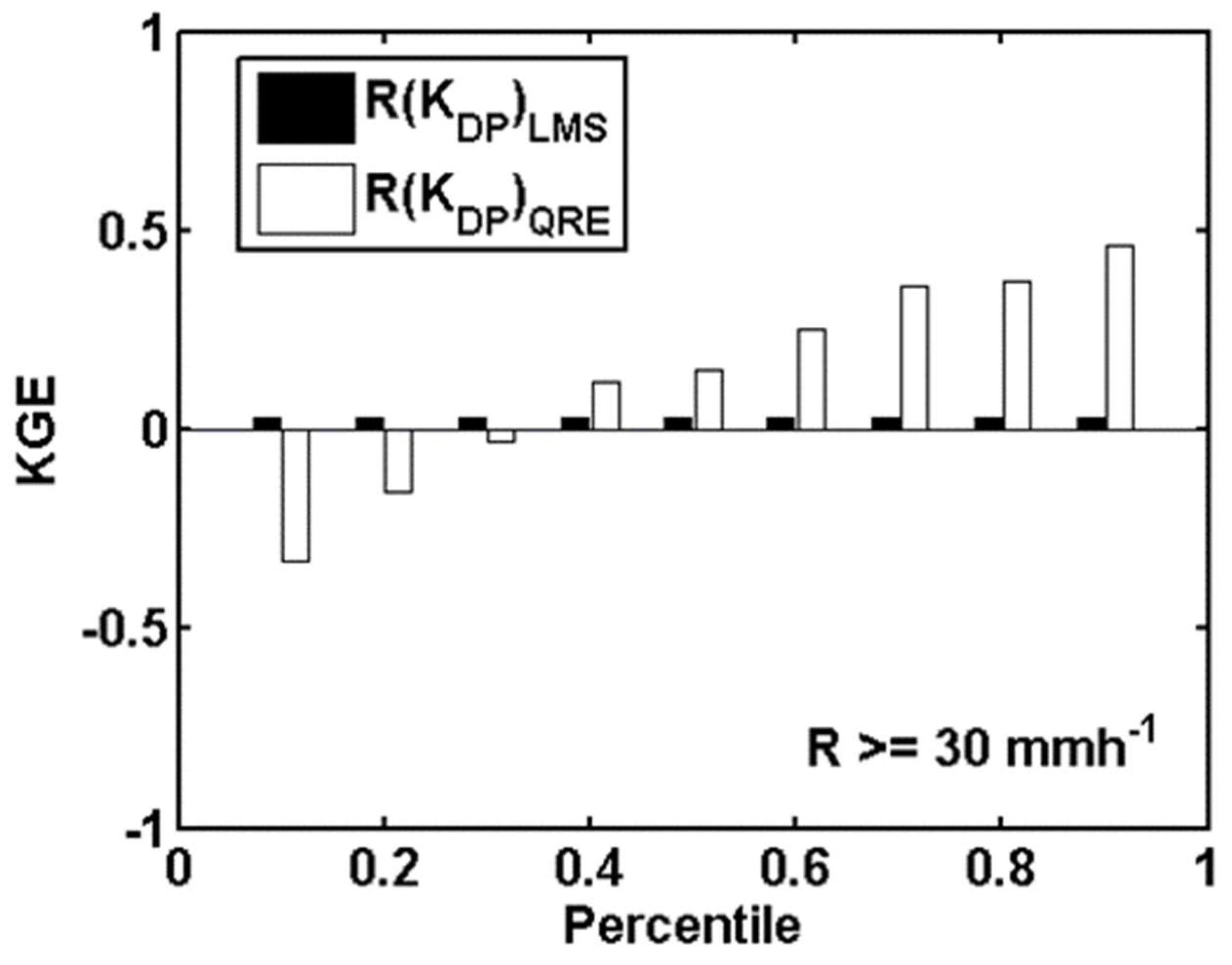
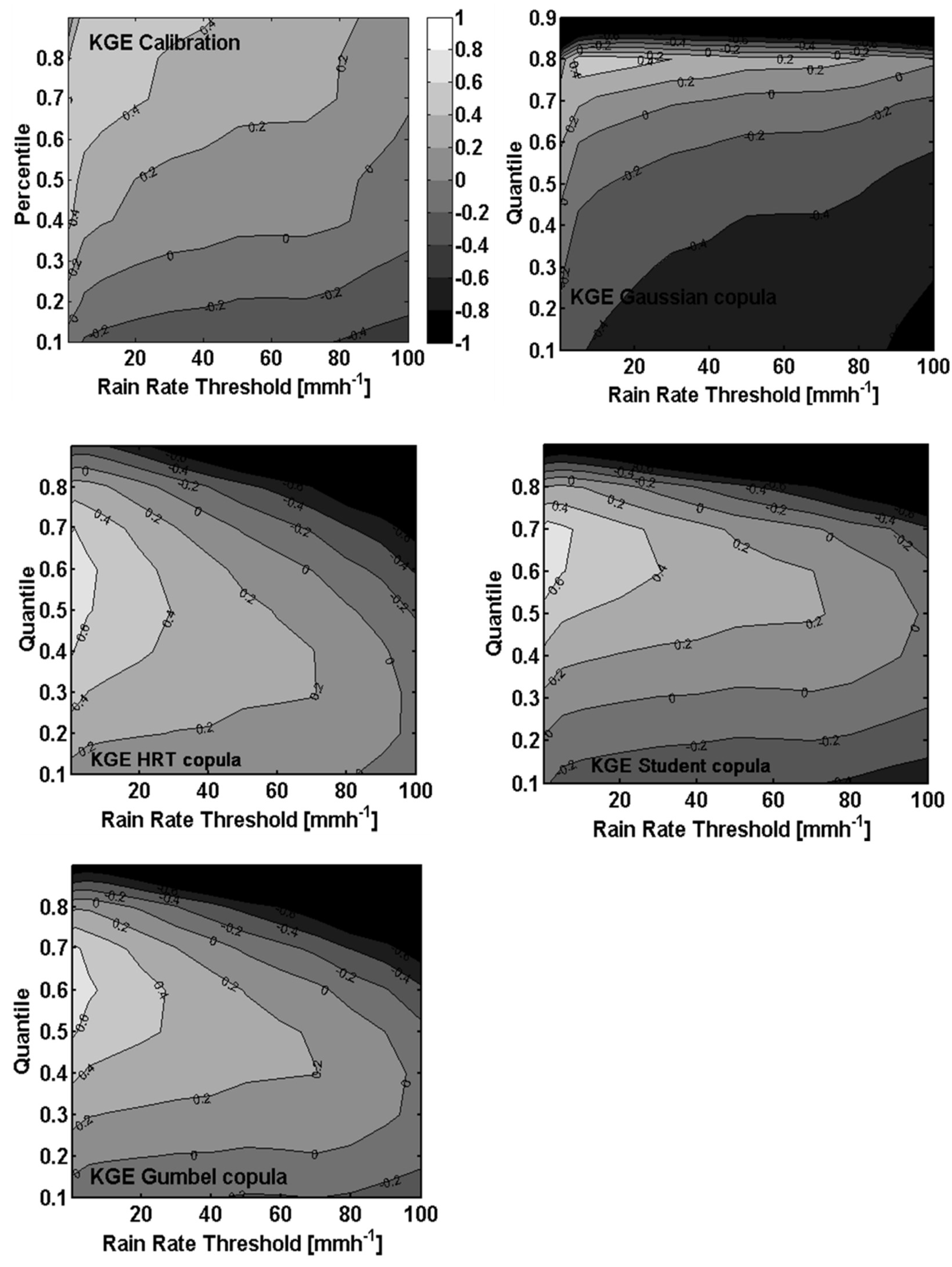
4.3. Evaluation of Rainfall Estimation
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chapon, B.; Delrieu, G. Variability of rain drop size distribution and its effect on the Z-R relationship: A case study for intense Mediterranean rainfall. Atmos. Res. 2008, 87, 52–65. [Google Scholar] [CrossRef]
- Zawadzki, I. Factors Affecting the Precision of Radar Measurement of Rain. In Proceedings of the 22th Conference on Radar Meteorology, AMS, Zurich, Switzerland, 10–13 September 1984; pp. 251–256. [Google Scholar]
- Pellarin, T.; Delrieu, G.; Saulnier, G.-M.; Andrieu, H.; Vignal, B.; Creutin, J.-D. Hydrologic Visibility of Weather radar systems operating in mountainous regions: Case study for the Ardèche Catchment (France). J. Hydrometeor. 2002, 3, 539–555. [Google Scholar] [CrossRef]
- Steiner, M.; Smith, J.; Uijlenenhoet, R. A microphysical interpretation of Radar Reflectivity-Rain rate relationships. J. Atmos. Sci. 2004, 61, 1114–1131. [Google Scholar] [CrossRef]
- Lee, G.W.; Zawadzki, I. Variability of drop size distributions: Time-scale dependence of the variability and its effects on rain estimation. J. Appl. Meteorol. 2005, 44, 241–255. [Google Scholar] [CrossRef]
- Berne, A.D.; Uijlenenhoet, R. A stochastic model of range profiles of raindrop size distributions: Application to radar attenuation correction. Geophys. Res. Lett. 2005, 32. [Google Scholar] [CrossRef]
- Moumouni, S.; Gosset, M.; Houngninou, E. Main features of rain drop size distributions observed in Benin, West Africa, with optical disdrometers. Geophys. Res. Lett. 2008. [Google Scholar] [CrossRef]
- Gosset, M.; Zahiri, E.-P.; Moumouni, S. Rain drop size distribution variability and impact on X-band polarimetric radar retrieval: Results from the AMMA campaign in Benin. Q. J. R. Meteorol. Soc. 2010, 136, 243–256. [Google Scholar] [CrossRef]
- Ochou, A.D.; Zahiri, E.-P.; Bamba, B.; Koffi, M. Understanding the variability of Z-R relationships caused by natural variations in raindrop size distributions (DSD): Implication of drop size and number. Atmos. Clim. Sci. 2011, 1, 147–164. [Google Scholar] [CrossRef]
- Bamba, B.; Ochou, A.D.; Zahiri, E.-P.; Kacou, M. Consistency in Z-R relationship variability regardless precipitating systems, climatic zones observed from two types of disdrometer. Atmos. Clim. Sci. 2014, 4, 941–955. [Google Scholar] [CrossRef]
- Sauvageot, H.; Lacaux, J.P. The shape of averaged drop size distributions. J. Atmos. Sci. 1995, 52, 1070–1083. [Google Scholar] [CrossRef]
- Tokay, A.; Short, D.A. Evidence from tropical raindrop spectra of the origin of rain from stratiform versus convective clouds. J. Appl. Meteorol. 1996, 35, 355–371. [Google Scholar] [CrossRef]
- Yuter, S.E.; Houze, R.A. Measurements of raindrop size distribution over the pacific warm pool and implementations for Z-R relations. J. Appl. Meteorol. 1997, 36, 847–867. [Google Scholar] [CrossRef]
- Tenorio, R.S.; Moraes, M.C.S.; Sauvageot, H. Raindrop size distribution radar parameters in coastal tropical rain systems of northeastern Brazil. J. Appl. Meteorol. Clim. 2012, 51, 1960–1970. [Google Scholar] [CrossRef]
- Campos, E.; Zawadzki, I. Instrumental Uncertainties in Z–R Relations. J. Appl. Meteorol. 2000, 39, 1088–1102. [Google Scholar] [CrossRef]
- Bringi, V.; Rico-Ramirez, M.; Thurai, M. Rainfall estimation with an operational polarimetric C-band radar in the United Kingdom: Comparison with a gauge network and error analysis. J. Hydrometeor. 2011, 12, 935–954. [Google Scholar] [CrossRef]
- Hasan, M.M.; Sharma, A.; Johnson, F.; Mariethoz, G.; Seed, A. Correcting bias in radar Z–R relationships due to uncertainty in point rain gauge networks. J. Hydrol. 2014, 519, 1668–1676. [Google Scholar] [CrossRef]
- Dai, Q.; Yang, Q.; Zhang, J.; Zhang, S. Impact of gauge representative error on a radar rainfall uncertainty model. J. Appl. Meteorol. Clim. 2018, 57, 2769–2787. [Google Scholar] [CrossRef]
- Steiner, M.; Houze, R.A., Jr. Sensitivity of the estimated monthly convective rain fraction to the choice of Z-R relation. J. Appl. Meteorol. Clim. 1997, 36, 452–462. [Google Scholar] [CrossRef]
- Seliga, T.A.; Bringi, V.N.; Al-Khatib, H.H. A preliminary study of comparative measurements of rainfall rate using the differential reflectivity radar technique and a raingage network. J. Appl. Meteorol. 1981, 20, 1362–1368. [Google Scholar] [CrossRef]
- Seliga, T.A.; Aydin, K.; Direskeneli, H. Disdrometer measurements during na intense rainfall event in central Illinois: Implications for differential reflectivity radar observations. J. Clim. Appl. Meteor. 1986, 25, 835–846. [Google Scholar] [CrossRef]
- Gorgucci, E.; Scarchilli, G.; Chandrasekar, V. A robust estimator of rainfall rate using differential reflectivity. J. Atmos. Oceanic Technol. 1994, 11, 586–592. [Google Scholar] [CrossRef]
- Gorgucci, E.; Chandrasekar, V.; Baldini, L. Rainfall estimation from X-band dual polarization radar using reflectivity and differential reflectivity. Atmos. Res. 2006, 82, 164–172. [Google Scholar] [CrossRef]
- Jameson, A.R. A comparison of microwave techniques for measuring rainfall. J. Appl. Meteorol. 1991, 30, 32–54. [Google Scholar] [CrossRef]
- Ryzhkov, A.V.; Zrnic, D.S. Comparison of dual-polarisation radar estimators of rain. J. Atmos. Oceanic Technol. 1995, 12, 249–256. [Google Scholar] [CrossRef]
- Ryzhkov, A.V.; Zrnic, D.S. Assessment of rainfall measurement that uses specific differential phase. J. Appl. Meteor. 1996, 35, 2080–2090. [Google Scholar] [CrossRef]
- Matrosov, S.Y.; Clark, K.A.; Martner, B.E.; Tokay, A. X-band polarimetric radar measurements of rainfall. J. Appl. Meteor. 2002, 41, 941–952. [Google Scholar] [CrossRef]
- Matrosov, S.Y.; Kingsmill, D.E.; Martner, B.E.; Ralph, F.M. The utility of X-band radar for quantitative estimates of rainfall parameters. J. Hydrometeorol. 2005, 6, 248–262. [Google Scholar] [CrossRef]
- Koffi, A.K.; Gosset, M.; Zahiri, E.-P.; Ochou, A.D.; Kacou, M.; Cazenave, F.; Assamoi, P. Evaluation of X-band polarimetric radar estimation of rainfall and rain drop size distribution parameters in West Africa. Atmos. Res. 2014, 143, 438–461. [Google Scholar] [CrossRef]
- Bringi, V.N.; Chandrasekar, V.; Balakrishnan, N.; Zrnic, D.S. An examination of propagation effects in rainfall on radar measurements at microwave frequencies. J. Atmos. Oceanic Technol. 1990, 7, 829–840. [Google Scholar] [CrossRef]
- Bringi, V.N.; Chandrasekar, V. Polarimetric Doppler Weather Radar: Principles and Applications; Cambridge University Press: Cambridge, UK, 2001; p. 636. [Google Scholar]
- Zahiri, E.-P.; Gosset, M.; Lafore, J.P.; Gouget, V. Use of a radar simulator on the output fields from a numerical mesoscale model to analyse X-band rain estimators. J. Atmos. Oceanic Technol. 2008, 25, 341–367. [Google Scholar] [CrossRef]
- Bouyé, E.; Durrleman, V.; Nikeghbali, A.; Riboulet, G.; Roncalli, T. Copulas for Finance a Reading Guide and Some Applications; Working Paper; Groupe de Recherche Operationnelle, Credit Lyonnais: Paris, France, 2000. [Google Scholar]
- Embrechts, P.; McNeil, A.; Straumann, D. Correlation and Dependence in Risk Management: Properties and Pitfalls, in Risk Management: Value at Risk and Beyond; Cambridge University Press: Cambridge, UK, 2002; pp. 176–223. [Google Scholar]
- Frees, E.W.; Valdez, E.A. Understanding relationships using copulas. N. Am. Actuar. J. 1998, 2, 1–25. [Google Scholar] [CrossRef]
- Grimaldi, S.; Serinaldi, F. Asymmetric copula in multivariate flood frequency analysis. Adv. Water Res. 2006, 29, 1155–1167. [Google Scholar] [CrossRef]
- Poulin, A.; Huard, D.; Favre, A.-C.; Pugin, S. Importance of tail dependence in bivariate frequency analysis. J. Hydrol. Eng. 2007, 12, 394–403. [Google Scholar] [CrossRef]
- Tianyuan, L.; Guo, S.; Chen, L.; Guo, J. Bivariate flood frequency analysis with historical information based on copula. J. Hydrol. Eng. 2013, 18, 1018–1030. [Google Scholar] [CrossRef]
- Favre, A.-C.; El Adlouni, S.; Perreault, L.; Thiémonge, N.; Bobée, B. Multivariate hydrological frequency analysis using copulas. Water Resour. Res. 2004, 40, 1–12. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Frequency analysis via copulas: Theoretical aspects and applications to hydrological events. Water Resour. Res. 2004, 40, W12511. [Google Scholar] [CrossRef]
- De Michele, C.; Salvadori, G.; Canossi, M.; Petaccia, A.; Rosso, R. Bivariate statistical approach to check adequacy of dam spillway. J. Hydrol. Eng. 2005, 10, 50–57. [Google Scholar] [CrossRef]
- Hooshyaripor, F.; Tahershamsi, A.; Golian, S. Application of copula method and neural networks for predicting peak outflow from breached embankments. J. Hydro-Environ. Res. 2013, 8, 292–302. [Google Scholar] [CrossRef]
- Shiau, J.T. Fitting drought duration and severity with two-dimensional copulas. Water Resour. Manag. 2006, 20, 795–815. [Google Scholar] [CrossRef]
- Reddy, M.J.; Ganguli, P. Application of copulas for derivation of drought severity-duration-frequency curves. Hydrol. Process. 2012, 26, 1672–1685. [Google Scholar] [CrossRef]
- Mirabbasi, R.; Fakheri-Fard, A.; Dinpashoh, Y. Bivariate drought frequency analysis using the copula method. Theor. Appl. Climatol. 2011, 108, 191–206. [Google Scholar] [CrossRef]
- Vandenberghe, S.; Verhoest, N.E.C.; De Baets, B. Fitting bivariate copulas to the dependence structure between storm characteristics: A detailed analysis based on 105 year 10 min rainfall. Water Resour. Res. 2010, 46, W011512. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Statistical characterization of temporal structure of storms. Adv. Water Res. 2006, 29, 827–842. [Google Scholar] [CrossRef]
- Schölzel, C.; Friederichs, P. Multivariate non-normally distributed random variables in climate research—Introduction to the copula approach. Nonlin. Processes Geophys. 2008, 15, 761–772. [Google Scholar] [CrossRef]
- Maity, R.; Dey, S.; Varum, P. Alternative approach for estimation of precipitation using Doppler weather radar data. J. Hydrol. Eng. 2015, 20, 04015006. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de repartitions à n dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Genest, C.; Favre, A.C. Everything you always wanted to know about copula modeling but were afraid to as. J. Hydrol. Eng. 2007, 12, 347–368. [Google Scholar] [CrossRef]
- Schweizer, B.; Wolff, E. nonparametric measures of dependence for random variables. Ann. Statist. 1981, 9, 879–885. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas; Springer Lecture Notes in Statistics; Springer: New York, NY, USA, 1999; p. 139. [Google Scholar]
- Fang, H.-B.; Fang, K.-T.; Kotz, S. The meta-elliptical distributions with given marginals. J. Multi. Anal. 2002, 82, 1–16. [Google Scholar] [CrossRef]
- Genest, C.; MacKay, J. The joy of copulas: Bivariate distributions with uniform marginals. Am. Stat. 1986, 40, 280–283. [Google Scholar] [CrossRef]
- Genest, C.; Rivest, L.-P. Statistical inference procedures for bivariate Archimedean copulas. J. Am. Statist. Assoc. 1987, 88, 1034–1043. [Google Scholar] [CrossRef]
- Genest, C.; Ghoudi, K.; Rivest, L.-P. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika 1995, 82, 543–552. [Google Scholar] [CrossRef]
- Juri, A.; Wüthrich, M.V. Copula convergence theorems for tail events. Insur. Math. Econ. 2002, 24, 139–148. [Google Scholar] [CrossRef]
- Juri, A.; Wüthrich, M.V. Tail dependence from a distributional point of view. Extremes 2004, 6, 213–246. [Google Scholar] [CrossRef]
- Li, C.; Singh, V.P.; Mishra, A.K. A bivariate mixed distribution with a heavy-tailed component and its application to single-site daily rainfall simulation. Water Resour. Res. 2013, 49, 767–789. [Google Scholar] [CrossRef]
- Joe, H.; Xu, J. The Estimation Method of Inference Functions for Margins for Multivariate Models; Technical Report, No. 166; Department of Statistics, University of British Columbia: Vancouver, Canada, 1996. [Google Scholar]
- Wang, C.; Chang, N.B.; Yeh, G.-T. Copula-based flood frequency (COFF) analysis at the confluences of river systems. Hydrol. Process. 2009, 23, 1471–1486. [Google Scholar] [CrossRef]
- Mishchenko, M.I.; Travis, L.D. Capabilities and limitations of a current FORTRAN implementation of the T-matrix method for randomly oriented, rotationally symmetric scatters. J. Quant. Spectrosc. Radiat. Transfer. 1998, 60, 309–324. [Google Scholar] [CrossRef]
- Cazenave, F.; Gosset, M.; Kacou, M.; Alcoba, M.; Fontaine, E. Characterization of hydrometeors in Sahelian convective systems with an X-band radar and comparison with in situ measurements. Part I: Sensitivity of polarimetric radar particle identification retrieval and case study evaluation. J. Appl. Meteor. Climatol. 2016, 55, 241–249. [Google Scholar] [CrossRef]
- Alcoba, M.; Gosset, M.; Kacou, M.; Cazenave, F.; Fontaine, E. Characterization of hydrometeors in Sahelian convective systems with an X-band radar and comparison with in situ measurements. Part II: A simple brightband method to infer the density of ice hydrometeors. J. Appl. Meteor. Climatol. 2016, 55, 251–263. [Google Scholar] [CrossRef]
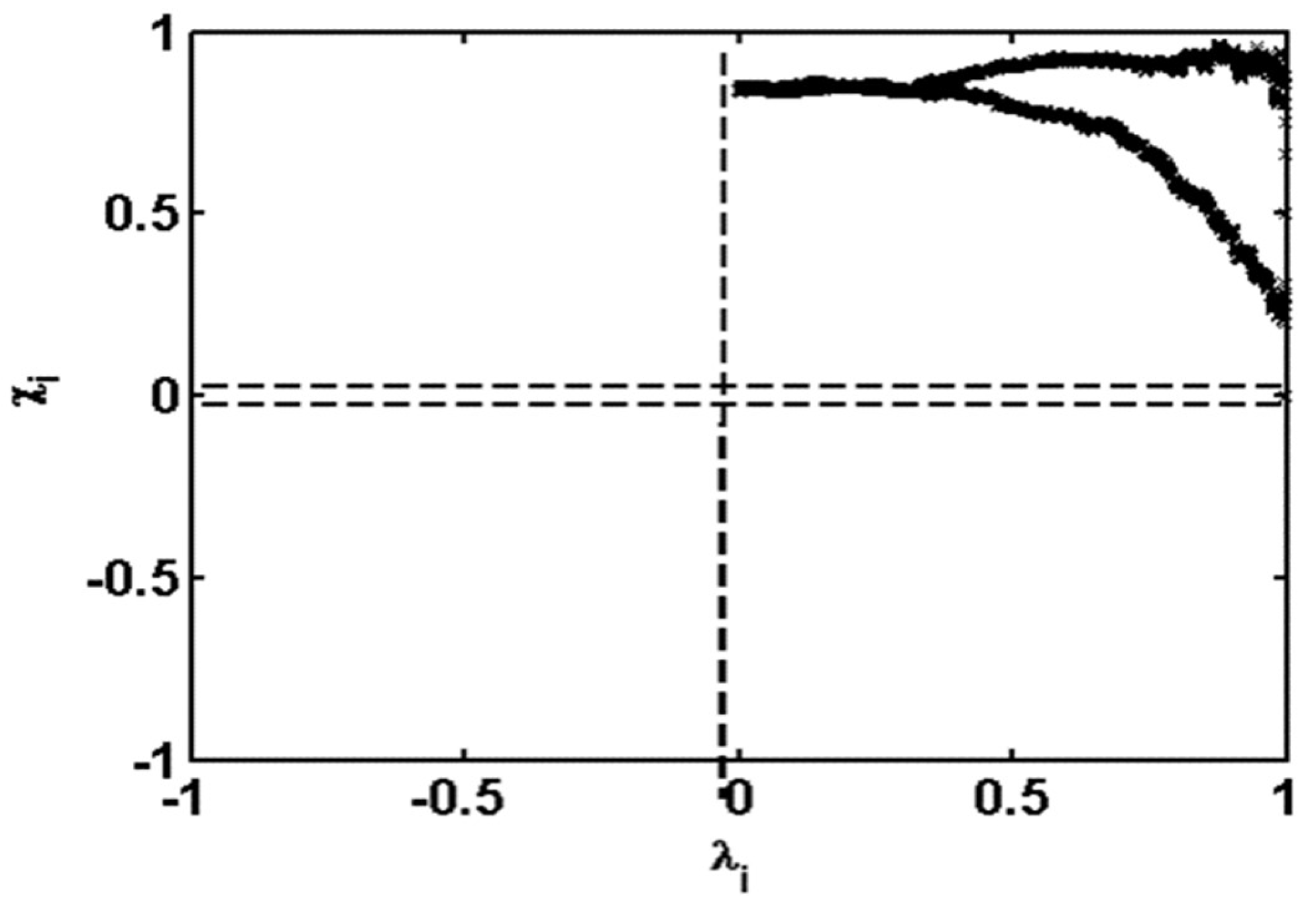
- Fisher, N.I.; Switzer, P. Chi-plots for assessing dependence. Biometrika 1985, 722, 253–265. [Google Scholar] [CrossRef]
- Fisher, N.I.; Switzer, P. Graphical assessment of dependence: I s a picture worth 100 tests. Am. Stat. 2001, 553, 233–239. [Google Scholar] [CrossRef]
- Koenker, R.; Hallock, K.F. Quantile Regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]
- Givor, P.; D’Haultfoeuille, X. La Regression Quantile en Pratique, Documents de Travail de la DMCSI; Working Papers of the DMCSI M 2013/01; Institut National de la Statistique et des Etudes Economiques, DMCSI: Paris, France, 2013. [Google Scholar]
- Bouyé, E.; Salmon, M. Dynamic copula quantile regressions and tail area dynamic dependence in Forex markets. Eur. J. Financ. 2009, 15, 721–750. [Google Scholar] [CrossRef]
- Genest, C.; Rémillard, B.; Beaudoin, D. Goodness-of-fit tests for copulas: A review and a power study. Insurance Math. Econom. 2009, 44, 199–213. [Google Scholar] [CrossRef]
- Fermanian, J.-D. Goodness-of-fit tests for copulas. J. Multivariate Anal. 2005, 95, 119–152. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modeling. J. Hydrol. 2009, 377, 80–89. [Google Scholar] [CrossRef]
- Anagnostou, M.N.; Kalogiros, J.; Marzano, F.S.; Anagnostou, E.N.; Montopoli, M.; Picciotti, E. Performance Evaluation of a New Dual-Polarization Microphysical Algorithm Based of Long-Term X-Band Radar and Disdrometer Observations. J. Hydrometeorol. 2013, 14, 560–576. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Copula | Range of Dependence Parameter | |
|---|---|---|
| Clayton | ||
| Franck | ||
| HRT (Survival Clayton) | ||
| Gumbel | ||
| Normal (Gaussian) | ||
| Student’s | ||
| is quantile function of the Student’s distribution | ||
| with degrees of freedom, and | ||
| is the correlation matrix |
| Copula | ||
|---|---|---|
| Clayton | 0 | |
| Frank | 0 | 0 |
| HRT (Survival Clayton) | 0 | |
| Gumbel | 0 | |
| Normal (Gaussian) | 0 | 0 |
| Student’s |
| Copula | ||
|---|---|---|
| Clayton | 7.728 | 6.574 |
| Frank | 9.620 | 9.678 |
| HRT (Survival Clayton) | 11.001 | 13.287 |
| Gumbel | 8.552 | 9.251 |
| Normal (Gaussian) | 0.983 | 0.980 |
| Student’s | 0.984 | 0.983 |
| Copula | ||
|---|---|---|
| Clayton | 1.165 | 1.526 |
| Frank | 11.474 | 11.474 |
| HRT (Survival Clayton) | 3.084 | 2.682 |
| Gumbel | 2.616 | 2.601 |
| Normal (Gaussian) | 0.754 | 0.790 |
| Student’s | 0.793 | 0.816 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zahiri, E.-P.; Kacou, M.; Gosset, M.; Ouattara, S.A. Modeling the Interdependence Structure between Rain and Radar Variables Using Copulas: Applications to Heavy Rainfall Estimation by Weather Radar. Atmosphere 2022, 13, 1298. https://doi.org/10.3390/atmos13081298
Zahiri E-P, Kacou M, Gosset M, Ouattara SA. Modeling the Interdependence Structure between Rain and Radar Variables Using Copulas: Applications to Heavy Rainfall Estimation by Weather Radar. Atmosphere. 2022; 13(8):1298. https://doi.org/10.3390/atmos13081298
Chicago/Turabian StyleZahiri, Eric-Pascal, Modeste Kacou, Marielle Gosset, and Sahouarizié Adama Ouattara. 2022. "Modeling the Interdependence Structure between Rain and Radar Variables Using Copulas: Applications to Heavy Rainfall Estimation by Weather Radar" Atmosphere 13, no. 8: 1298. https://doi.org/10.3390/atmos13081298
APA StyleZahiri, E.-P., Kacou, M., Gosset, M., & Ouattara, S. A. (2022). Modeling the Interdependence Structure between Rain and Radar Variables Using Copulas: Applications to Heavy Rainfall Estimation by Weather Radar. Atmosphere, 13(8), 1298. https://doi.org/10.3390/atmos13081298